Wrapper特征選擇下的序貫三支分類方法
2021-08-24 07:22:36張璐,劉盾,楊新
小型微型計算機系統 2021年8期
張 璐,劉 盾,楊 新
1(西南交通大學 經濟管理學院,成都 610031)
2(西南財經大學 經濟信息工程學院,成都 611130)
1 引 言
隨著科學技術的不斷進步和互聯網的飛速發展,人類開始邁入大數據時代.面對數據的爆發式增長,人類需要有效的方法對多源異構數據進行分析處理,各種機器學習算法應運而生.機器學習方法的出現適應了大數據時代的迫切需求,因而被廣泛的應用于諸多領域,并取得了巨大的成功.分類作為機器學習的重點研究領域之一,一直受到國內外學者的廣泛關注.目前,靜態分類器大多是根據給定的屬性集合對樣本進行分類,在分類過程中沒有考慮樣本之間的差異性,這會導致信息獲取成本大幅增加,整體分類成本過高.例如,在人臉識別任務中,面部特征明顯的個體使用清晰度較低的圖像就能進行準確判別;面部特征隱晦的個體才需要高清圖像進行識別.靜態分類器往往只能根據同一粒度的圖像對全體樣本進行判別.這種無差異的靜態判別方法可能會造成信息資源的浪費,增加圖像的獲取成本.在實際生活中,理性決策者往往可以先利用少量信息對容易分類的樣本進行判別;之后再獲取更多信息對難以分類的樣本進行進一步識別,即:利用不同粒度信息對不同樣本進行分類.
三支決策[1-4]是一種以“三分而治”(Trisecting and Acting)為核心思想的決策方法.Yao[5,6]將粒計算的思想引入三支決策,基于粒度由粗到細的多層粒結構,提出了序貫三支決策方法,其核心思想為:隨著粒度的增加,利用一系列分治策略對樣本進行動態處理.一系列研究表明:序貫三支決策方法可以顯著降低決策成本[7-9].一般而言,實現序貫三支決策的關鍵步驟是構造多層次的粒結構.現有研究主要是通過逐步添加樣本屬性的方式來構造不同層次粒結構[10-12].然而,已有研究忽略了添加過程中屬性的冗余性問題,也沒有考慮添加順序對分類結果的影響.
Wrapper特征選擇框架是將特征選擇過程與學習器預測結果結合起來的一種學習框架[13],它將學習器作為一個黑箱,利用學習器的精度對一個特征子集的優劣進行評價,并采用一定的搜索策略對特征子集不斷優化.大量研究表明,Wrapper特征選擇框架能大幅提高學習器精度[14-16].與其他特征選擇方法相比,它通常可以獲得更好的特征子集[17].目前,Wrapper特征選擇框架的優化搜索策略主要分為3類:精確搜索算法,序列搜索算法和隨機搜索算法[13,17].精確搜索算法可以保證找到全局最優解,但隨著特征數目的數量增加,算法時間復雜度成指數形式上升;序列搜索僅能在很小的解空間進行搜索,通常會導致得到的屬性子集距離最優解較遠;隨機搜索算法根據一定的啟發式搜索規則,同時在局部和整體進行搜索,既能保證一定的搜索范圍,也能保證較低的時間復雜度.遺傳算法作為一種經典的隨機搜索算法,對優化問題的數學性質要求較低,能夠很好地適用于隱式函數目標.因此,本文采用遺傳算法作為Wrapper特征選擇框架的搜索策略.
基于上述分析,為了彌補靜態分類器的缺陷,本文將序貫三支決策的思想引入分類過程中,利用“三分而治”的動態分類策略和多粒度的靜態分類器對樣本進行差異化分類;同時考慮到冗余屬性和屬性添加順序對分類結果的影響,將Wrapper特征選擇框架引入粒化過程中,提出了一種Wrapper特征選擇下的序貫三支分類方法,最后通過實驗分析來驗證所提出方法的有效性.
2 相關理論
2.1 三支決策和序貫三支決策理論
三支決策(Three-way decision)是 Yao[1-4]提出的一種重要的粒計算和不確定性決策方法.作為決策粗糙集的延伸與擴展[18-20],三支決策能很好的處理不確定性問題和代價敏感問題,并在信息、醫學、管理和工程領域得到了廣泛應用[18].隨著研究的不斷深入,三支決策逐漸從狹義擴展到廣義[20,21],從粗糙集[22,23]擴展到區間集,模糊集[24],陰影集,概念分析,機器學習[25,26]等各方面.Yang[27]和Liu[28]對三支決策的發展進行了全面的總結和回顧,并且指出了未來的新機遇和新挑戰.
在三支決策理論中,決策者可以根據決策目標將整體論域分為正域、負域和邊界域3個部分.對于3個區域,決策者可以進一步采用接受、拒絕和延遲策略.下面,通過一個評價函數和一對閾值給出三支決策模型中“三分“的定義[18]:
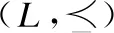
(1)
可以看到,當POS,BND和NEG中當且僅有一個區域為空集時,三支決策退化為二支決策。圖1為三支決策的基本模型.
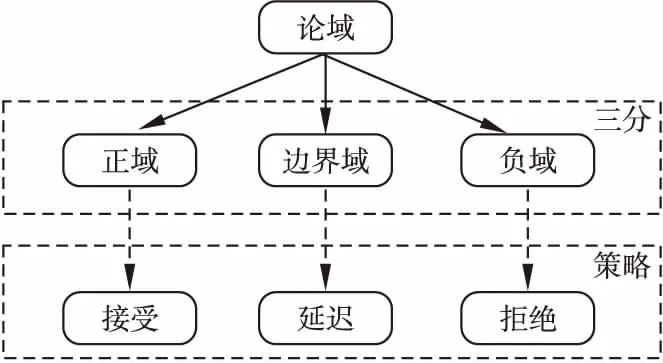
圖1 三支決策基本模型
在實際的決策過程中,三支決策的過程往往呈現出動態特征.針對于動態三支決策過程中多層次的粒結構特點,Yao[5-6]提出了序貫三支決策方法.在序貫三支決策模型的每個粒層,每個對象將被劃分到正域,負域或邊界域中的某一個區域里面.劃分到正域和負域的對象能夠在該粒層立刻做出接受或拒絕的判斷,而劃分到邊界域的對象將被移動到更細的粒層去做進一步判斷,直到最終決策目標實現.
2.2 粒計算
粒計算(Granular computing)是一種模擬人類思維、研究人腦認知和解決復雜信息處理問題的新興不確定性理論.在序貫三支決策方法中通常需要一個多層次的粒結構實現其動態決策過程.一個粒結構由粒子、粒層和層次結構3個元素組成.粒子是構成粒計算模型的基本單位,是一個問題的抽象模型.粒層是由具有相同粒度的所有粒子所構成的整體,是問題空間在某一粒度下的一種抽象描述.粒度是描述粒子大小的概念.若根據一個有序的粒度關系對層進行排列,則會得到一個層次結構.通常根據粒度的不同序關系,層次結構分為自頂向下,自底向上和自中向外.本文主要采用自頂向下的多層次粒結構.
2.3 基于遺傳算法的Wrapper特征選擇框架
Wrapper特征選擇框架中主要有兩個主體部分:一是搜索策略,二是分類器.本文選用遺傳算法作為Wrapper框架的搜索策略.分類器需要根據實際需求進行選擇,本文選取邏輯回歸(LOG)和支持向量機(SVM)兩種分類方法進行實驗.
在20世紀70年代,John Holland提出了遺傳算法(Genetic Algorithm,GA).遺傳算法是以達爾文的進化論以及遺傳學為基礎而提出的元啟發式算法,通過優勝劣汰的進化過程來獲得問題的最優解.遺傳算法對求解問題的性質要求很低,對函數的連續性和可導性沒有要求,甚至對沒有明確解析式的優化問題也保持良好的全局尋優能力.由于遺傳算法良好的適應性,它被廣泛應用于人工智能的各個領域[29,30].
基于遺傳算法的Wrapper特征選擇框架對屬性子集變量進行合理編碼,產生初始種群,并利用分類器的精度作為屬性子集的評價指標,通過精英保留,選擇,交叉,變異等遺傳算子不斷搜索更優屬性子集并進行記錄,直至收斂或達到迭代次數,最終得到優化后的屬性子集.
2.4 等價關系和等價類
假設S=(U,C∪D)是一個信息系統,其中U為論域,C為條件屬性,D為決策屬性。對于?a∈C∪D,定義映射fa:U→Va,Va表示屬性a的值域。下面給出等價關系與等價粒子的定義[11].
定義 2.給定一個信息系統S=(U,C∪D),A?C∪D,則論域U上的等價關系可定義為:
RA={(x,y)∈U×U|?a∈A,fa(x)=fa(y)}
通過等價關系RA可以定義論域U的一個劃分U/RA={[x]|x∈U},[x]為等價類,也稱等價粒子。等價粒子中的對象存在不可分辨關系。
如果兩個等價關系R1,R2之間存在關系R1?R2,則通過R1誘導出的等價類[x]1和R2誘導出的等價類[x]2滿足:[x]1?[x]2。通常地,可以通過一組有序的條件屬性集合定義一組有序的等價關系,實現對論域的多層次劃分,進而構造一個多層次粒結構。
3 基于Wrapper特征選擇的粒化方法
實現序貫三支分類方法的首要工作就是要建立一個多層次的粒結構.本文將Wrapper特征選擇框架引入粒化過程中,提出了基于Wrapper特征選擇的粒化方法(Wrapper based Granulation method,WG).
該算法主要分為3個步驟:屬性選擇,屬性排序,基于等價關系構造多層次粒結構.原始條件屬性集首先對冗余屬性和不相關屬性進行約簡,之后對屬性的添加順序進行排列,進而構造出一組存在有序關系的條件屬性集,最后根據等價關系構造出一個多層次的粒結構,其過程如圖2所示.
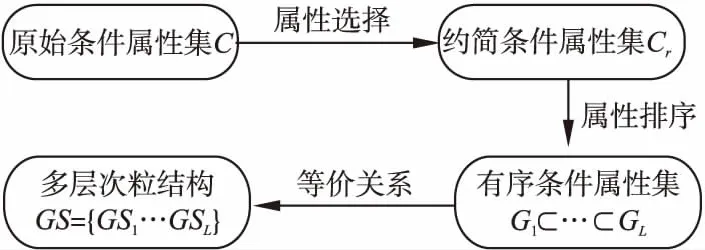
圖2 基于Wrapper特征選擇的粒化方法
3.1 屬性選擇
為了消除冗余屬性對后續粒化過程的影響,首先利用基于遺傳算法的Wrapper特征選擇框架進行屬性選擇,其流程如算法1所示.
算法 1.屬性選擇算法
輸入:信息系統Strain=(U,C∪D),遺傳算法參數集GAP(交叉率cp,變異率mp,種群數m,迭代次數n,停止次數q),分類器ψ.
輸出:條件屬性子集Cr
1.BI=?BF=0BA=0i=1
//編碼1代表選取該屬性,0表示不選取
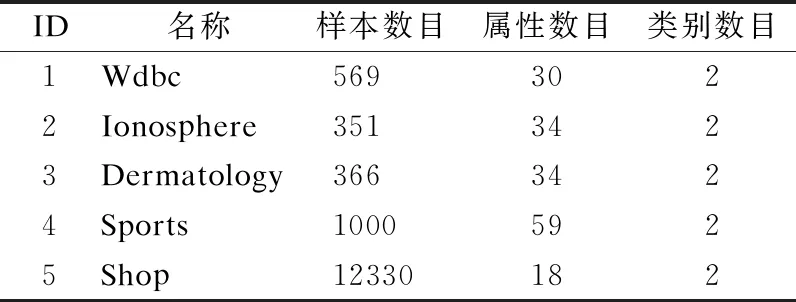
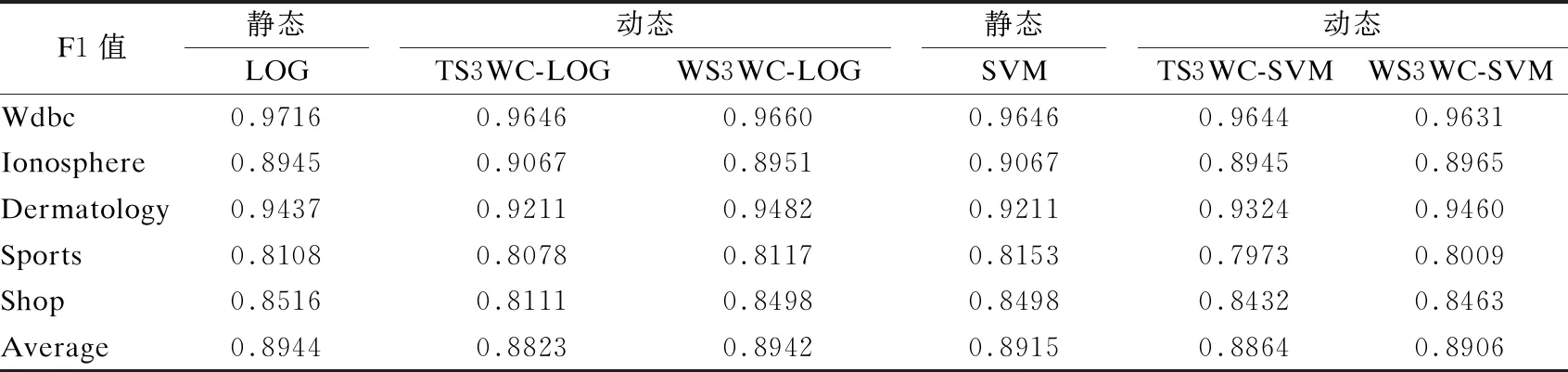
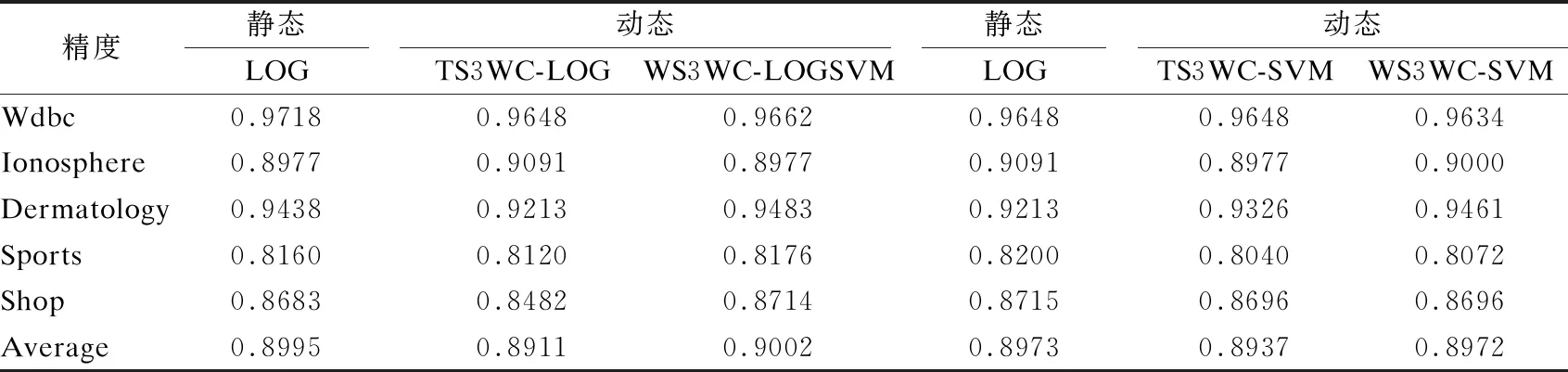
3.while1≤i≤nor|i-BA| 3.1.for1≤j≤mdo 3.1.1.Ej=Crossvalidation(ψ(Sj=(U,Ij∪D)) //對屬性子集進行交叉驗證 3.1.2.j=j+1 3.2.endfor 3.3.ifmax(Ej)>BF 3.3.1.BI=Imax(Ej)//更新歷史最優個體 3.3.2.BF=max(Ej) //更新歷史最優適應度 3.3.3.BA=i//更新歷史最優輪次 3.4.ifmax(Ej) 3.4.1.Imin(Ej)=BI//精英保留 3.9.i=i+1 4.endwhile 5.returnBI 在屬性約簡后,如何決定屬性的添加順序也是十分重要的問題.對于每一粒層,都會添加一部分屬性以確保下一粒層粒子的粒度更細.如果一些分類能力比較差的屬性被優先添加,則會導致分類器在粗粒度的精度很低,誤分類成本和延遲成本增加.每一粒層添加的屬性均由基于遺傳算法的Wrapper特征選擇框架選出,其流程與算法1相似,算法2只列出不同的部分. 算法2.單粒層待添加屬性的選擇算法 輸出:本粒層添加的屬性集TC … //編碼1代表選取該屬性,0表示不選取 … 3.1.1.Ej=Crossvalidation(ψ(Sj=(U,(Ij+EC)∪D))) … 算法3.屬性排序算法 1.EC=?LC=Cri=1 2.while1≤i≤L-1 2.2.Gi=EC=TC∪EC 2.3.LC=Cr-EC 2.4.i=i+1 3.endwhile 4.ifi=L 4.1.Gi=Cr 5.endif 通過3.2節,可以得到一組有序的條件屬性集G1?G2?…?Gi?…?GL,據此可以定義一組有序的等價關系EL?…?Ei?…?E2?E1,進一步地,可以得到其等價粒子存在如下關系: [x]EL?…?[x]Ei?…?[x]E2?[x]E1 (2) 基于上述分析,可以定義如下多層次粒結構: GS=(GS1,GS2,…,GSL)GSi=(Ui,Ei,Gi,[x]Gi) (3) 為了實現樣本的差異化分類,減少分類成本,本文將序貫三支決策的思想引入分類過程中,提出了一種序貫三支分類方法,其基本框架如圖3所示. 圖3 序貫三支分類方法的基本框架 為了進一步說明序貫三支分類方法的具體過程,第4.1節對動態分類過程中涉及的分類策略進行介紹.第4.2節,結合第3節粒化方法得到的多層次粒結構,提出一種Wrapper特征選擇下的序貫三支分類方法. 根據圖3的模型框架,對于粒層i(0 接著,對粒層i的三支分類策略進行定義. (4) 其中,正域表示預測屬于正類的對象集合,負域表示預測屬于負類的對象集合,邊界域表示暫時不能劃分的對象集合.對于正域POSi(X)對象采取行動aP,即標記為正類,對于負域NEGi(X)對象采取行動aN,即標記為負類,對于邊界域BNDi(X)對象采取行動aB,即暫不分類. 然后,分析閾值αi和βi的計算過程.根據表1中的代價矩陣,基于貝葉斯風險最小化原則,可以對三支分類策略的閾值進行計算. 表1 三支分類代價矩陣 在粒層i(0 (5) 根據貝葉斯準則,最佳的行動方案應該是期望損失最小的行動集,于是閾值的計算應該滿足如下三條決策準則: (P)若Ri(aP|x)≤Ri(aB|x)Ri(aP|x)≤Ri(aN|x)同時成立,則x∈POSi(X); (B)若Ri(aB|x)≤Ri(aP|x)Ri(aB|x)≤Ri(aN|x)同時成立,則x∈BNDi(X); (N)若Ri(aN|x)≤Ri(aP|x)Ri(aN|x)≤Ri(aB|x)同時成立,則x∈NEGi(X). 最后,結合決策規則(P)-(N),可得到αi和βi的計算公式: (6) (7) 特別地,如果在前L-1粒層不能完全劃分樣本,則在粒層L使用二支分類策略,二支分類策略定義如下: (8) 其中,正域POSL表示預測屬于正類的對象集合,負域NEGL表示預測屬于負類的對象集合.對于正域POSL對象,我們采取aP,即標記為正類,對于負NEGL對象,我們采取aB,即標記為負類. 對于閾值γL,可以根據表2的代價矩陣進行計算. 表2 二支分類代價矩陣 則采取aP,aN兩種行動下的期望損失可分別表示為: (9) 根據貝葉斯風險最小化原則: (P1)若RL(aP|x)≤RL(aN|x)成立,則x∈POSL(X); (N1)若RL(aN|x)≤RL(aP|x)成立,則x∈NEGL(X). 結合決策規則(P1)-(N1),可以得到γL的計算公式: (10) 基于上述討論,結合第3節基于Wrapper特征選擇的粒化方法,本文提出一種wrapper特征選擇下的序貫三支分類方法,其具體實現步驟如算法4所示. 算法 4.Wrapper特征選擇下的序貫三支分類方法 輸出:分類結果 //基于Wrapper框架構造多層次粒結構 //訓練多粒度分類器,計算分類閾值 2.for1≤i≤L 2.1.Si=(U,Gi∪D) 2.2.ψi′=train(ψ,Si) 2.3.i=i+1 3. (αi,βi)=threshold(Mi),1≤i≤L-1,byEq(6),(7) γL=threshold(ML),byEq(10) //序貫三支分類方法 4.U1=U′POS=?NEG=?BND=?i=1 5.while1≤i≤L-1 5.1.foreachx∈Uido 5.1.1.POSi={x∈Ui|ψi′(x)≥αi} 5.1.2.BNDi={x∈Ui|βi<ψi′(x)<αi} 5.1.3.NEGi={x∈Ui|ψi′(x)≤βi} 5.2.POS=POS∪POSi 5.3.BND=BNDi 5.4.NEG=NEG∪NEGi 5.5.Ui+1=BND 5.6.ifUi+1=? 5.6.1.returnPOS,NEG;break 5.7.elsei=i+1 6.endwhile 7.ifi=L 7.3.POS=POS∪POSL 7.4.NEG=NEG∪NEGL 8.endif 9.returnPOS,NEG 為了驗證本文所提出方法的有效性,表3選取了5個經典的UCI數據集進行實驗驗證.實驗運行環境為Windows 10,運行實驗的處理器為Intel i5-8250U,1.6GHz CPU,內存為8G,編程語言為Python 3.7.在本節中,首先介紹數據集的一些基本信息,評價指標,參數和實驗的設計;然后對各算法的分類質量進行對比分析;最后對分類的成本進行評估. 表3 數據集描述 本文主要評估評分類質量和分類成本兩個方面.在分類質量方面,選用F1值和精度來對方法進行評估. 關于序貫三支分類方法中的參數設置,本文以三層粒結構為例進行對比試驗.每層添加屬性數目為(|Cr|/2,|Cr|/4,|Cr|/4),其分類代價矩陣設置如表4所示.其中λBP和λBN由延遲成本和信息獲取成本兩部分構成.進一步地,通過式(6),式(7)和式(10),可以計算得出每層的分類閾值.為了方便起見,我們設置遺傳算法參數為:種群數50,交叉率0.9,變異率0.3,迭代次數的停止條件為10次.因為遺傳算法具有一定的隨機性,所以本文重復運行5次計算平均值.此外,我們假定表3中各數據集屬性的測試代價相同.關于WS3WC中分類器ψ的選擇,本文以邏輯回歸(LOG)和支持向量機(SVM)為例來進行試驗. 表4 各粒層分類代價矩陣 為了進一步說明本文方法的有效性,我們選擇靜態分類器和TS3WC作為基準算法,設計了兩組對比實驗,具體如表5所示.其中靜態分類器是指靜態二支分類器; TS3WC引入了序貫三支決策的思想,對樣本進行差異化分類,但在粒化過程中不對屬性進行約簡和排序. 表5 實驗設計 表6、表7給出了各方法在每個數據集下的F1值和精度值,以及在5個數據集下的平均F1值和平均精度值.從表6-表7可以看出,3種方法在不同數據集上的分類質量各有高低.當選取LOG分類器時,WS3WC-LOG的表現要略好一些.當選取SVM分類器時,靜態分類的表現更好.通過觀察3種方法在5個UCI數據集下的平均F1值和平均精度值可以看出:WS3WC和靜態分類器的平均F1值和平均精度相差不大,但都優于TS3WC. 表6 算法在各數據集下的的F1值 表7 算法在各數據集下的精度 綜上所述,WS3WC與靜態分類器在分類質量上差距不大,能夠保持較好的分類質量,TS3WC的分類質量要略低于靜態分類器和WS3WC.這說明WS3WC能夠保持較好分類質量的主要原因在于其粒化方法的優勢,將Wrapper特征選擇框架引入粒化過程是合理的. 圖4(a)-圖4(e)給出了各算法在5個數據集上的分類成本,其中分類成本由誤分成本,延遲成本和信息處理成本3部分構成.圖4(f)給出了各算法在所有數據集上的平均分類成本.為了方便比較,本文將靜態分類器的平均分類成本設置為1.從圖4中可以看出,相較于靜態分類器,WS3WC的分類成本在各個數據集上均有大幅度的下降;TS3WC的分類成本在4個數據集上有較大幅度的降低;同時WS3WC與TS3WC的平均分類成本明顯減少,這充分說明了引入序貫三支決策思想可以有效降低靜態分類器的分類成本.與此同時,我們注意到粒化方法對分類成本也有極其重要的影響.在Wdbc和Dermatology數據集上, TS3WC的分類成本明顯比WS3WC升高;在Shop數據集上,TS3WC的分類成本甚至超過了靜態分類器;只有在Ionosphere和Sports數據集上TS3WC和WS3WC的分類成本比較相近;此外,WS3WC的平均分類成本低于TS3WC.通過上述分析可以看出:在粒化過程中考慮冗余屬性和屬性添加順序是十分必要的,本文提出的粒化方法能夠有效的降低分類成本. 圖4 算法在各數據集上的分類成本與平均分類成本 如何降低靜態分類器的分類成本,以便更好地解決代價敏感分類問題是本文的研究動機和最終目標.本文將序貫三支決策的思想引入分類過程中,對樣本進行差異化分類;同時利用Wrapper特征選擇框架消除粒化過程中的冗余屬性并且確定屬性的添加順序,提出了一種Wrapper特征選擇下的序貫三支分類方法.實驗表明,WS3WC不僅保持了良好的分類質量,而且能夠大幅降低分類成本. 本文提出的WS3WC方法只是一個基本框架,還有許多問題值得深入研究.三支決策理論在處理多類問題時具有一定的局限性,因此如何解決多分類問題是未來研究方向之一.此外,本文主要關注應用過程中的分類成本,忽略了訓練成本,如何將二者綜合考慮也是值得進一步研究的問題.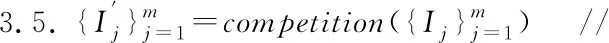
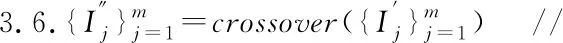
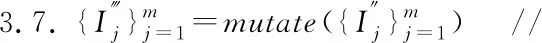

3.2 屬性排序
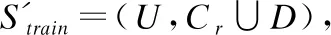
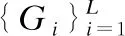
3.3 多層次粒結構
4 序貫三支分類方法
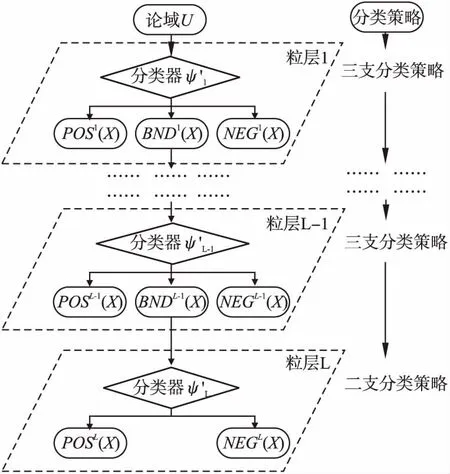
4.1 動態分類策略

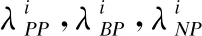
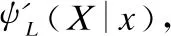

4.2 Wrapper特征選擇下的序貫三支分類方法
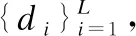
5 實驗分析
5.1 評估指標的選擇
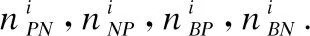
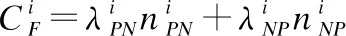
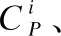
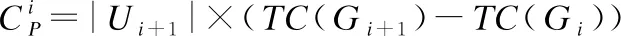
5.2 參數設置和實驗設計

5.3 分類質量評估
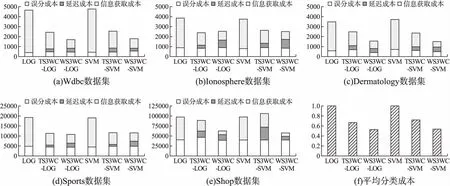
5.4 分類成本評估
5 結 論
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56河南電力(2021年5期)2021-05-29 02:10:00中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32電影(2018年12期)2018-12-23 02:18:48中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56俄羅斯問題研究(2012年1期)2012-03-25 09:54:48
