非正交多址系統中基于Raptor碼的下行傳輸設計與優化
2021-08-24 06:53:20盧為黨
小型微型計算機系統 2021年8期
張 昱,李 昊,彭 宏,盧為黨
1(浙江工業大學 信息工程學院,杭州 310023)
2(東南大學 移動通信國家重點實驗室,南京 210096)
1 引 言
當前移動通信系統面臨著用戶數量及其數據需求的快速增長,需要研究新型移動通信技術以應對上述挑戰.非正交多址[1,2](Non-orthogonal Multiple Access,NOMA)技術是一種新型多址技術.在NOMA中,各用戶可以占用重疊時頻資源,接收端通過各類信號處理技術處理用戶間干擾,可以有效提升頻譜效率、服務用戶數量等.
當前工業界以及學術界已經提出了多種NOMA方式,例如功率域非正交多址[3](Power Domain Non-orthogonal Multiple Access,PD-NOMA)、低密度蔓延[4]、稀疏碼多址[5]、交織多址[6]、多用戶共享接入[7]、圖樣分割多址[8]等.對于下行PD-NOMA而言,在發射機端,根據用戶的信道狀態為用戶分配不同的功率,基站可以在相同的通信資源上廣播疊加的用戶信號.在用戶端,可以采用串行干擾消除[9](SIC)技術消除來自其他用戶的干擾,以獲取用戶自身所需的信息.
Liu Y和Chen Z等人將傳統正交多址接入(Orthogonal Multiple Access,OMA)和PD-NOMA進行比較,并通過仿真表明,PD-NOMA都具有較好的總傳輸速率性能[10,11].因此,當考慮到高頻譜效率和大規模連接性的需求時,PD-NOMA比OMA更有優勢.目前已有一系列文獻研究了PD-NOMA系統中的編碼傳輸設計與優化.Chida Y等人研究了低密度奇偶校驗碼(Low Density Parity Check,LDPC)在PD-NOMA系統中的傳輸機制以及性能[12,13].Wang X等人提出了Turbo碼和多用戶檢測聯合優化的方法,顯著提高了NOMA系統性能[14-16].Dizdar O等人提出了一種基于Polar碼的NOMA傳輸方法[17,18],該方法可以在多路復用用戶接收功率相似的情況下降低NOMA的誤碼率,對疊加編碼功率分配具有較強的魯棒性.
在NOMA中采用傳統的固定速率信道編碼面臨以下挑戰:一是發射端需要實時的信道狀態信息反饋來確定信道編碼碼率,二是當接收端譯碼失敗時采用混合重傳機制(Hybrid Automatic Repeat Request,HARQ),這會進一步增加系統開銷.Bonello N等人[19]比較了無速率碼與固定速率編碼,與LDPC碼基于增量冗余的HARQ方案相比,Raptor碼[20,21]能夠提供更大的吞吐量,Raptor碼能夠自適應信道,并且在發射機處不具備實時信道狀態信息(Channel State Information,CSI)下,仍能接近平均信道容量[22,23].Zhang Y等人表明,與使用固定速率編碼相比,使用Raptor碼可以顯著地提升系統吞吐量[24].
本文主要研究以下內容:1)設計了塊衰落信道下非正交多址系統基于Raptor碼下行傳輸方案,首先,基站使用LDPC碼作為外碼將用戶消息分別進行預編碼,再通過LT碼[25,26]作為內碼編碼,得到Raptor碼碼字,將碼字經過調制后采用一定功率分配因子進行疊加編碼后發送給每個用戶,用戶接收到信號后,對接收的信號進行置信傳播(BP)譯碼[27,28],從而恢復出用戶所需的信息;2)針對塊衰落信道,提出了功率分配和Raptor碼度數分布聯合優化算法.通過外信息傳遞分析(Extrinsic Information Transfer,EXIT)譯碼過程,以最大化系統平均傳輸速率為目標,僅依據系統統計信道信息(CSI),對各用戶無速率碼度數分布和基站功率分配進行聯合優化.通過仿真驗證優化得到的結果具有較好的誤碼率及傳輸速率性能.
2 系統模型
如圖1所示,本文考慮兩用戶下行NOMA系統,在該系統中,基站與兩用戶之間進行下行通信,hi表示用戶i(i∈{1,2})到基站的信道增益.

圖1 系統模型
我們假設各節點間鏈路經歷塊衰落,各鏈路的信道增益在每輪的信息傳輸期間保持恒定,在各輪之間是獨立且隨機變化的,滿足一定的概率分布.對于接收方兩個用戶而言,基站到本用戶的信道狀態信息是已知的.而利用無速率傳輸,基站并不需要知道當前信道信息.在每一輪傳輸過程中,基站持續將信號傳輸給兩個用戶,直到兩個用戶正確譯碼恢復信息并反饋確認(Acknowledgement,ACK)為止.每輪傳輸的詳細過程如下:
首先,在發送端基站處,對用戶i長度為K的消息mi進行Raptor編碼(兩用戶消息長度一致),以獲得編碼比特ci,然后經過調制得到信號xi,i∈{1,2},注意,由于基站無法獲得實時CSI,Raptor碼的度數分布是固定不變的.
基站將用戶i,i∈{1,2}的信號進行疊加編碼,得到發送信號:
(1)
其中分配給用戶1信號的功率P1為:
P1=(1-α)P
(2)
分配給用戶2信號的功率P2為:
P2=αP
(3)
其中P表示基站的總發送功率,α表示功率分配因子.
用戶i(i∈{1,2})收到的信號分別為:
(4)

兩用戶采用SIC以及BP譯碼恢復所需信息.當成功恢復后,用戶會反饋ACK,以通知基站停止本輪傳輸.
3 非正交多址系統下行Raptor碼傳輸方案
3.1 Raptor碼編碼方案
基站將各用戶下行信息先通過LDPC編碼器進行Raptor碼的預編碼,再進行LT編碼.基站對各用戶信息向采用相同的LDPC編碼,但LT碼各不相同.對于用戶i(i∈{1,2})來說,Raptor碼度數分布為:
Ωi(x)=Ωi,1x+Ωi,1x2+…+Ωi,DxD
(5)
其中i∈{1,2},Ωi,k是用戶i碼字比特度數為k的概率,k=1,…,D;
每個碼字比特按如下方法生成:首先,根據度數分布隨機選擇每個碼字比特的度數.對于度數為d的碼字比特,從LDPC預編碼碼字中隨機選擇d個比特,進行異或運算.通過上述編碼過程,可以無限生成隨機碼字比特.為簡單起見,采用二進制相移鍵控調制(Binary Phase Shift Keying,BPSK),即將Raptor碼字比特0和1映射為發送符號1和-1,以此得到各用戶i的發送信號xi.
3.2 用戶端基于SIC的BP譯碼
傳輸開始前,各用戶從基站處已經獲知Raptor碼度數分布以及功率分配因子.事實上,由于兩者在所有傳輸輪次中保持不變,基站只需告知一次,信令開銷極小.我們首先對功率分配因子α>0.5的情況展開討論.此時由公式(3)可知,基站疊加編碼時對用戶2分配更多的功率.另一方面,基站發送給各用戶的消息長度相等,因此對各用戶消息的實際編碼速率是相等的.在各用戶處,用戶2信息對應的信干噪比更大,更容易被恢復.因此用戶1需要利用SIC,先恢復用戶2的信息,再將其從接收信號中去除,然后恢復用戶1自身的信息.
對于用戶1而言,用戶1從接收信號中獲得關于x2的對數似然比(Log-likehood Ratio,LLR)表示為:

(6)
基于式(6)的LLR,用戶1采用BP譯碼恢復用戶2消息.在BP算法中,“消息”在變量節點和校驗節點之間沿著其相連邊進行交換.每個“消息”是由該邊連接的相應變量節點的LLR.整個譯碼過程中可分為兩個階段.如圖2所示,在第1階段,對整個譯碼圖執行譯碼迭代,直到輸入節點的平均LLR超過預定閾值mth,這是LDPC成功譯碼的最小要求.該閾值可以通過Peng H等人提出的方法[29]獲得.在第2階段中,在上半部分LDPC子圖上單獨執行譯碼迭代以去除殘留誤差.下面給出第一譯碼階段的詳細過程,對于l次迭代:

圖2 Raptor碼譯碼圖
步驟1.從輸入節點i到LDPC校驗節點c的消息是:
(7)

步驟2.從LDPC校驗節點c到輸入節點i的消息是:
(8)

步驟3.從輸入節點i到LT輸出節點o的消息是:
(9)

步驟4.從LT輸出節點o到輸入節點i的消息是:
(10)
其中z為根據LLR公式(7)計算出的的信道LLR消息.累乘部分是除本身之外的所有與LT輸出節點o相鄰的輸入節點.
步驟5.在輸入節點i的LLR更新如下:
(11)
第2階段,在每個用戶的LDPC譯碼圖上單獨執行消息交換.該階段的具體過程與步驟1-步驟2類似,不再進行贅述.
當譯碼迭代達到最大次數或譯碼滿足LDPC碼的所有校驗約束時,譯碼終止.

(12)
(13)
由此得出關于x1的LLR,表示為:
(14)
用戶1利用上述LLR再進行BP譯碼來恢復本用戶信息.
另一方面,對于用戶2而言,無需采用SIC,直接利用BP譯碼恢復本用戶信息.用戶2從接收信號獲取的關于x2的LLR為:
(15)
最后,對功率分配因子α<0.5的情況,此時用戶2需要進行SIC而用戶1不需要.對于功率分配因子α=0.5的情況,由于各用戶消息的實際編碼速率相等,各用戶都不需要SIC.
4 Raptor碼輸出度數分布設計
4.1 譯碼過程的EXIT分析
首先我們分析用戶BP譯碼過程中外信息傳遞(EXIT)過程[30].這里的外信息指的是編碼比特(或等效的編碼符號)與其LLR之間的互信息.
如圖3所示,我們以α>0.5時,用戶2恢復本用戶信息的BP譯碼過程為例,對于第l輪迭代:

圖3 Raptor譯碼圖外信息傳遞過程
步驟1.LLR消息從LT輸入節點傳送到LDPC校驗節點,其攜帶的平均外信息為:
(16)

(17)
步驟2.從所有LDPC校驗節點到輸入節點的平均外信息是:
(18)

步驟3.輸入節點到輸出節點的平均外信息是:
(19)

步驟4.輸出節點到輸入節點的外信息更新:
(20)
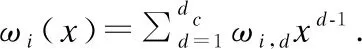
同樣地,我們可以得到用戶1譯碼用戶2信息的外信息更新過程為:
(21)
以及用戶1進行SIC后,譯碼本用戶信息的外信息更新過程為:
(22)
上述各式中,I1,2和I2,2分別表示用戶1(用戶2)從原始接收信號中(即不是SIC后的信號)獲得的關于x2的LLR所對應的外信息,即:
Ii,j=I(xj;L(xj|ri))
(23)
其中i∈{1,2},j∈{1,2},我們可以根據蒙特卡洛法獲得上述互信息,具體過程描述如下:以用戶2直接譯碼x2,即獲得I2,2為例.首先,設置基站發送的用戶2信號x1為1,用戶1信號x1隨機等概率地產生1或-1.根據公式(4)產生高斯噪聲以此得到r1和r2.根據公式(6),我們可以得到L(x2|r2).通過生成大量的隨機樣本,利用蒙特卡洛法我們可以近似得到概率密度P(L(x2|r2)|x2=1).利用類似的方法,當我們可以得到其余的條件概率密度,以此近似地計算出式(23)的互信息.另一方面,對于用戶1從SIC后的信號獲得關于其本身所需消息的信道輸出外信息I1,1可以根據式(14)和式(17)直接計算獲得.
4.2 度數分布優化
基于上述EXIT分析,我們聯合優化各用戶Raptor碼度數分布以及基站功率分配因子.目標是在保證每輪各用戶成功譯碼基礎上,最大化平均下行總傳輸速率,在發送消息長度固定下,等價于最小化平均碼長.
在每一輪傳輸過程中,基站向兩個用戶連續發送疊加編碼碼字,直到兩用戶成功譯碼出各自的信息.我們以α>0.5為例,用戶1恢復用戶2消息所需的碼字長度可以表示為:
(24)

類似地,用戶1恢復本用戶消息所需的碼字長度為:
(25)
用戶2恢復本用戶消息所需的碼字長度為:
(26)
基站所需傳輸的碼字長度為上述三者的最大值,即:
t(H,α)=max(L1,1,L1,2,L2,2)
(27)
通常,信道矩陣空間H是連續的.為了建立可解的優化問題,我們將空間離散為Q狀態:Hq,q=1,…,Q.每個狀態出現的概率表示為Pq.平均碼長表示如下:
(28)
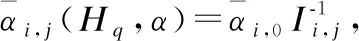
(29)
由于α取值影響到用戶端的SIC過程,影響其成功譯碼條件,因此需要分情況討論.對于α>0.5:
(30)
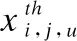

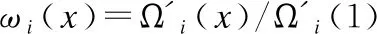
5 仿真結果

5.1 BER性能
首先,分別仿真了以上3種信道狀態下的誤碼率.基站的總發送功率為P=2.5.
通過上一節的聯合優化方法,得到功率分配因子α=0.64以及各用戶最優度數分布為:
Ωopt1(x)=0.0127x+0.3961x2+0.3044x3+0.0845x6+
0.1062x7+0.0678x17+0.0174x18+0.0109x60
(31)
Ωopt2(x)=0.0127x+0.3914x2+0.3199x3+0.0664x6+
0.1220x7+0.0843x17+0.0113x60
(32)
此外我們還仿真了二進制擦除信道(Binary Erasure Channel,BEC)下的最優度數作為對比方案:
ΩBEC(x)=0.0008x+0.494x2+0.166x3+0.073x6+0.083x7+
0.056x17+0.037x60+0.056x19+0.025x65+
0.003x66
(33)
我們仿真了不同譯碼開銷下的兩用戶總誤碼率.當α>0.5時,譯碼開銷定義為:
(34)
其中N是基站實際發送的碼長,K是用戶消息長度,min(I1,1,I1,2,I2,2)/K是由信息論所得基站理論所需發送碼長.更大的譯碼開銷意味著基站發送更長的碼長,即等價于更低的實際傳輸速率.開銷為0即為理論上限.圖4-圖6這3個圖分別給出度數優化以及BEC度數在信道矩陣H1、H2、H3下的誤碼率.值得注意的是,盡管本文方法針對平均系統性能優化Raptor碼度數分布,但其在各信道狀態下的誤碼率性能仍然很好.與BEC度數分布相比,達到相同誤碼率下的開銷更小.

圖4 信道矩陣為H1的誤碼率

圖5 信道矩陣為H2的誤碼率

圖6 信道矩陣為H3的誤碼率
5.2 吞吐量性能
我們仿真了在不同信噪比下的系統平均傳輸速率.對于不同的信噪比,我們固定噪聲功率,調整基站總發送功率P.我們在各信噪比下分別優化了Raptor碼的度數分布以及基站功率分配因子.仿真結果如圖7所示,除了本文提出的優化方法,我們還考慮兩種對比方法.

圖7 本文方法與其他對比方法的系統下行吞吐量
對比方法1.基站對于兩用戶信息的Raptor編碼采用公式(33)給出的BEC最優度數分布,功率分配因子按下述方法獲得:固定優化問題公式(30)中的邊度數分布{ωi,d}為BEC最優度數分布對應的邊分布,然后利用窮舉搜索求解該問題,得到邊度數分布固定下的最優功率分配因子α.
對比方法2.基站對于兩用戶信息的Raptor編碼采用與按本文方法優化的度數分布,但功率分配因子選取α=0.5.
對于圖4-圖6中的每個點,仿真了100輪的傳輸,每輪都是從H1、H2、H3中均勻隨機選取信道矩陣.從圖中可以看出,通過與各方法對比的結果顯示,優化的Raptor碼度數分布以及優化的功率分配因子都能帶來傳輸速率的提升,且優化后與信息論理論極限相差11%左右.
6 結 論
本文設計了塊衰落信道下非正交多址接入系統中兩用戶下行場景的Raptor碼傳輸方案.為了最大化系統平均傳輸速率,本文基于外信息傳遞分析(EXIT)提出了功率分配和Raptor碼輸出度數分布聯合優化的設計方法.計算機仿真結果表明,基站采用本文的優化方法獲得的功率分配因子以及Raptor碼度數分布,能夠達到降低系統誤碼率,并提高系統平均下行傳輸速率的效果.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
