一種加權圖卷積神經網絡的新浪微博謠言檢測方法
2021-08-24 06:53:22王昕巖宋玉蓉
小型微型計算機系統 2021年8期
王昕巖,宋玉蓉,宋 波
1(南京郵電大學 自動化學院、人工智能學院,南京 210023)
2(南京郵電大學 現代郵政學院,南京 210003)
1 引 言
謠言是在人和人之間傳播的,含有公眾關心信息的一種特殊陳述,而其真實性不能及時得到證明或是無法證明[1],往往會帶來惡劣的影響.例如新冠肺炎期間,美國總統特朗普在得知消毒劑能夠在一分鐘之內殺死病毒后,呼吁給新冠病毒患者直接注射消毒劑,或者用強光照射,以起到殺死病毒的作用.據美國疾控中心報告顯示,家用清潔劑產品中毒的數量在幾周內都在上升.在人們的日常生活中,這類誤導性的謠言比比皆是,因此為了避免謠言可能造成的傷害,采取謠言檢測的措施是十分必要的.
謠言能夠在社會中快速而廣泛地傳播,與社交媒體的快速發展是密切相關的.社交媒體在提高人們信息獲取效率的同時,也產生了許多與真實信息相背的謠言信息[2].由于每個普通人都可以成為信息的發布源,就會造成信息質量的良莠不齊,不可避免地會有不法分子為了達到目的惡意地發布謠言信息誤導民眾,使其做出符合謠言散布者期望的舉動,影響了社會的穩定.近年來,社交媒體的謠言治理已經成為熱門研究課題,引起了國內外學者的廣泛關注.對社交媒體的謠言檢測任務,通過收集與事件相關的各種信息,自動地完成檢測任務來判斷被檢測事件的真偽.對謠言事件的自動檢測方法,一方面減輕了人工辟謠的資源消耗,另一方面能更快地檢測出流散的謠言,從而能夠營造積極健康的網絡環境,維護社會的穩定[3].
目前針對社交媒體的謠言檢測方法,如傳統的機器學習方法,以及深度學習方法包括卷積神經網絡(Convolutional Neural Network,CNN)[4]、循環神經網絡(Recurrent Neural Network,RNN)[5]等,對事件的學習只是將這些事件看作成獨立的個體,平等地學習事件的特征.然而在社交媒體中,事件之間的關系并不是獨立的,而是具有拓撲關系的.社交媒體中的每個事件和與該事件有關的用戶都存在著聯系,包括發布、評論、轉發等,并且這些用戶之間的交互關系,也是與這些用戶有關的事件之間關系的體現.只考慮每個事件本身的特征而忽略事件之間的聯系,會對檢測效果造成影響.因此有學者考慮了事件之間的聯系,提出使用圖網絡模型來進行謠言檢測,但是他們忽略了事件之間聯系的緊密程度,也會對檢測效果造成一定的影響.在社交網絡中,事件之間的聯系具有異質性,其緊密程度存在著差異.謠言事件往往具有鼓動性,這是由于大部分的謠言事件的發布者在發布謠言時,擅長使用一些煽動性的語句來激發人們的情緒.往往對這些事件進行評論和轉發的用戶,更加容易受到這些刺激性語句的蠱惑,也會受到其他謠言事件中這類語句的鼓動.與非謠言相比,謠言的發布者更加希望所發布的謠言信息能夠有更多轉發和評論,來引起人們的關注.于是許多謠言發布者為了達到這一目的,會有意識地組織用戶進行轉發、評論來提高事件的熱度,而這些用戶也更易受到其他謠言發布者的利用.因此本文考慮事件之間相同數量的評論者或轉發者,來確定事件之間聯系的緊密程度.
為了充分考慮事件之間的聯系及其異質性,本文提出了一種基于加權圖卷積神經網絡(Weighted-Graph Convolutional Network,W-GCN)模型的謠言檢測方法.該方法以事件作為節點,以事件之間是否有聯系構建連邊并根據事件之間聯系的緊密程度,賦予連邊不同的權重.接著通過BERT(Bidirectional Encoder Representation from Transformers)模型和CNN模型對事件的文本提取特征,并將該特征作為W-GCN模型中節點的特征向量,來完成模型的訓練,從而完成對社交媒體中事件的謠言檢測任務.考慮到新浪微博是一種基于用戶關系信息分享、傳播以及獲取的實時社交媒體,是中國最大的社交媒體平臺,因此本文選擇新浪微博作為研究對象來完成謠言檢測的任務.實驗結果表明,與傳統的機器學習模型以及GRU-2[5]、PPC-RNN+CNN[6]等深度學習模型相比,本文提出的W-GCN模型能更有效地完成新浪微博中謠言的檢測任務.并且與這些方法相比,本文方法同樣能更加有效地完成新浪微博中謠言的早期檢測任務.
本文剩余章節安排如下:第2節介紹社交媒體謠言檢測的相關研究工作;第3節介紹本文提出的新的謠言檢測模型;第4節通過實驗及分析,驗證本文提出的新的謠言檢測方法的有效性;第5節為結束語.
2 相關工作
目前國內外對于謠言檢測的工作主要分為兩個方面,一個是使用傳統的機器學習方法,另一個是使用深度學習的方法.使用傳統的機器學習方法大多是通過選取人工特征,主要包括文本特征、用戶特征以及傳播特征,并使用包括貝葉斯[7]、支持向量機(Support Vector Machine,SVM)、決策樹[8]等分類器來對事件進行學習分類.Qazvinian等[9]使用了貝葉斯分類器,提取了用戶行為特征及文本特征等特征.Yang等[10]使用了SVM分類器,提取了發布微博的客戶端及其所在的地理位置等特征.Liang等[11]提取了質疑文本特征以及用戶行為等特征.Yang等[12]提取了熱門話題等特征.Wu等[13]提出了基于圖核的混合SVM分類器,提取了語義特征以及高階傳播特征.Ma等[14]提出了傳播樹模型來獲取事件的特征表示.
近年來隨著深度學習的快速發展,深度學習模型包括卷積神經網絡(CNN)、循環神經網絡(RNN)等在計算機視覺[15]等領域上的應用得到了快速發展,使用深度學習模型來解決自然語言處理(Natural Language Processing,NLP)任務[16],逐步取得了顯著的成果.并且與傳統的機器學習模型相比,深度學習模型對人工特征的依賴較小.因此在NLP任務中,使用深度學習模型可以減少設計特征帶來的人力、物力的消耗,并能提高模型的魯棒性.Ma等[5]首次提出將深度學習模型RNN應用于社交媒體的謠言檢測,首先通過TF-IDF(Term Frequency-Inverse Document Frequency)算法來獲取時間段內的微博文本向量,接著通過RNN模型的學習,最后獲取文本向量的特征表示.Yu等[17]使用生成句向量的方法來獲取微博文本向量,再用CNN模型來學習獲取文本向量的特征表示.Liao等[18]提取文本特征和用戶局部特征,使用GRU(Gated Recurrent Unit)網絡和注意力機制來獲取微博事件的特征表示.Hu等[19]使用圖卷積神經網絡(Graph Convolutional Network,GCN)模型,根據新聞的相似性構建連邊,并提取歷史信用特征對新聞進行分類.Tian[20]等人使用GCN模型,根據謠言傳播的方向性構建連邊對事件進行分類.雖然這些方法在分類效果上比傳統的機器學習方法更加出色,但是它們沒有考慮事件之間的聯系或事件之間聯系的異質性,對謠言檢測的效果造成了一定的影響.
3 模型方法
3.1 問題描述
對新浪微博平臺的謠言檢測任務,實際上是一個對事件進行二分類的問題.對于給定的事件組E={e1;e2;e3;e4;…;ei;…;en}和標簽組L={l1;l2;l3;l4;…;li;…;ln}.在事件組E中,ei表示第i個事件,包括所有與這個事件相關的微博原文以及轉發、評論等信息,n表示事件總數;在標簽組L中,li表示第i個事件的標簽,分為謠言標簽和非謠言標簽.在新浪微博平臺的謠言檢測任務中,首先將事件組E分為事件訓練集Etrain和事件測試集Etest,將標簽組分為訓練集標簽Ltrain和測試集標簽Ltest.讓模型對事件訓練集Etrain以及它們對應的訓練集標簽Ltrain進行學習,構建出一個以事件信息ei作為輸入,分類標簽li作為輸出的映射模型.接著將事件測試集Etest輸入該模型,輸出對應的預測標簽組Lpred.最后根據預測標簽組Lpred與實際標簽組Ltest的相符程度,來衡量該謠言檢測模型的檢測效果.
3.2 模型介紹
1)BERT預訓練模型
自然語言處理(NLP)任務一般分為上游任務和下游任務.上游任務主要對數據進行預處理,將文本數據轉化為向量表示.下游任務主要對轉化后的向量進行操作.上游任務使用的模型主要包括Word2Vec[21]、ELMo[22]等.Word2Vec模型將單詞通過高維空間映射成詞向量,可以表征現實生活中詞語之間的關系.但是通過Word2Vec模型,每個單詞與一個固定的詞向量相對應,使得每個單詞無法理解上下文的語義.ELMo模型通過雙向語言模型,并根據具體的輸入來得到上下文依賴的詞向量表示,將NLP的一部分下游任務轉移到了上游任務中,增強了向量的特征表示能力.但是該模型的工作效率低,并且只能將數據用詞向量來表示.BERT模型[23]作為一個語言表征模型,由谷歌團隊使用雙向編碼操作,通過大量數據和多層模型訓練而成.該模型的并行性好,效率高.并且該模型可以將數據轉化為維度具有一致性的句向量,因此本文采用BERT模型對新浪微博中的文本數據進行預處理操作.
2)卷積神經網絡(CNN)模型
卷積神經網絡(CNN)模型[24]可以使用通過BERT模型轉化后的向量,來作為模型的輸入,進而完成模型的訓練,如圖1所示.CNN模型由4部分構成:輸入層(Input Layer)、卷積層(Convolution Layer)、池化層(Pooling Layer)和全連接層(Fully Connected Layer).

圖1 卷積神經網絡(CNN)結構圖
CNN模型將事件ei轉化后的向量vi作為輸入,通過卷積層(Convolution Layer)選取寬度與向量vi維度等長的卷積核,使該卷積核始終保持在豎直方向滑動,來完成對向量的卷積操作,繼而得到與卷積核數量相同的特征向量ci.接著通過池化層(Pooling Layer)對特征向量ci進行最大池化(Max-Pooling)操作,提取局部接受域中向量的最大值,得到特征向量pi.最后通過全連接層,將最大池化操作后提取的特征向量pi,在全連接層中與分類標簽進行全連接(Fully Connected)操作,得到該事件ei的預測標簽li,最終完成謠言的檢測任務.本文提出的模型將最大池化操作后的特征向量pi作為事件ei的特征向量.
3)圖卷積神經網絡(GCN)
圖卷積神經網絡[25](GCN)是一種多層神經網絡,可以通過圖中的節點和連邊信息直接對圖中的節點進行端對端的學習并完成分類任務.給定一個圖G=(N,E),其中N表示節點,E表示連邊.GCN模型的輸入包括特征矩陣X∈Rn×m,鄰接矩陣A∈Rn×n以及標簽組L∈Rn×2.其中特征矩陣X包括圖中的所有節點n以及每個節點特征向量的維數m.鄰接矩陣A表示圖中各節點之間的連邊關系.如果節點ni和節點nj之間有連邊,則Aij=α,其中α為該連邊的權重,否則Aij=0.GCN模型通過節點的相鄰節點信息來更新該節點的隱層信息,每一層只捕獲該節點的最近鄰節點的信息.當GCN模型有多個層數時,模型會整合更多的鄰居節點信息.因此GCN模型中的第i個隱藏層的特征矩陣Hi,如式(1)所示.
Hi=f(Hi-1,A)
(1)
其中,H0=X,f是傳播函數.
GCN模型的第i個隱藏層的特征矩陣Hi,與特征矩陣Hi∈Rn×m相對應,代表這個節點在該層的特征表示.第i個隱藏層的特征矩陣Hi中節點的特征被聚合后再通過傳播函數f,得到該節點在下個隱藏層中的特征表示.對于只含有一個隱藏層的GCN模型,節點的k維特征矩陣H1∈Rn×k如式(2)所示.
(2)

(3)
對于多層GCN模型,下一個隱藏層的特征矩陣Hi+1可以通過上一個隱藏層的特征矩陣Hi及權重矩陣Wi,如式(4)所示.
(4)
3.3 加權圖卷積神經網絡(W-GCN)模型
1)W-GCN模型介紹
本文在考慮事件之間聯系的基礎上,充分考慮了事件之間聯系的異質性,即事件之間聯系的緊密程度,賦予了GCN模型中連邊的權重,提出了一種新型社交網絡的謠言檢測方法.該方法對微博事件中的用戶信息以及文本信息進行提取處理.對于用戶信息,通過考慮用戶與事件之間的評論與轉發行為來確定事件與事件之間是否有聯系關系,并根據事件之間相同的評論者或轉發者數量來確定事件之間聯系的緊密程度.將新浪微博中的事件作為節點,事件之間的聯系作為連邊,聯系的緊密程度作為連邊的權重,從而搭建了一個加權圖卷積神經網絡(W-GCN)模型,如圖2所示.對于微博事件中的文本信息,首先通過BERT模型將文本信息進行預處理操作,將文本信息轉化成維數為768的向量表示,緊接著使用CNN模型對轉化后向量進行特征提取.最后將CNN模型中最大池化(Max-Pooling)操作后得到的特征輸入到W-GCN模型中,最后模型學習得到事件的隱層表達,進而實現對事件的分類操作,最終完成新浪微博中謠言的檢測任務.

圖2 加權圖卷積神經網絡(W-GCN)結構圖
本文提出的加權圖卷積神經網絡模型W-GCN的輸入包括兩個部分:由所有事件的特征向量組成的節點的特征矩陣X,以及根據事件之間的聯系及其緊密程度構建的W-GCN中的鄰接矩陣A.
2)W-GCN模型的節點特征矩陣
考慮到GCN中,每個節點的特征向量需為固定的長度.僅使用預訓練模型對一個微博事件的所有文本信息進行預處理轉化為向量,無疑會破壞文本的結構特征,會對檢測效果造成巨大影響.經過實驗,僅通過預訓練模型對一個微博事件的所有文本信息進行預處理,不具有很好的分類特征.考慮到現有的深度學習模型中,CNN模型在經過最大池化(Max-Pooling)操作后得到的特征向量,維度相同并且維數較少,可以最大程度地保留文本的結構特征,因此本文使用卷積神經網絡模型(CNN)對事件文本進行特征提取.對于圖網絡模型中作為節點ni的事件ei,首先將事件ei的文本信息,逐條通過BERT模型轉化為向量表示,并作為CNN模型的輸入.經過CNN的卷積和池化操作后得到特征pi,將其作為W-GCN模型中節點的特征向量xi.
3)W-GCN模型的鄰接矩陣
W-GCN模型中節點ni和節點nj之間的連邊,由對應的事件ei和事件ej之間的聯系來確定.對于事件ei和事件ej,根據這兩個事件之間是否有相同的評論者或轉發者來確定兩個事件之間是否存在聯系,繼而決定圖網絡模型中節點ni和節點nj之間是否存在連邊.節點之間的連邊通過鄰接矩陣A來表示,為了簡便起見,本文不考慮事件傳播的方向,即不考慮連邊的有向性.如果事件ei和事件ej之間沒有相同的評論者或轉發者,那么這兩個事件之間不構成傳播關系,即事件ei和事件ej之間不存在聯系,定義節點ni和節點nj之間不存在連邊,令Aij=0;如果事件ei和事件ej之間含有相同的評論者或轉發者,那么事件ei和事件ej之間就可能存在傳播關系,對此定義節點ni和節點nj之間存在連邊,那么Aij的值至少為1.再通過考慮事件ei和事件ej之間聯系的緊密程度,即事件ei和事件ej之間相同的評論者或轉發者數量α,給Aij賦予不同的值來定義節點ni和節點nj之間連邊的權重,即:
4 實驗結果及分析
4.1 參數及評價指標
1)實驗數據集及模型參數設置
本文選用的數據集是Ma等[5]使用的用于新浪微博平臺的謠言檢測數據集.該數據集包括4664個事件,每個事件對應的標簽,事件信息包括微博用戶信息、文本信息、時間等信息,如表1所示.
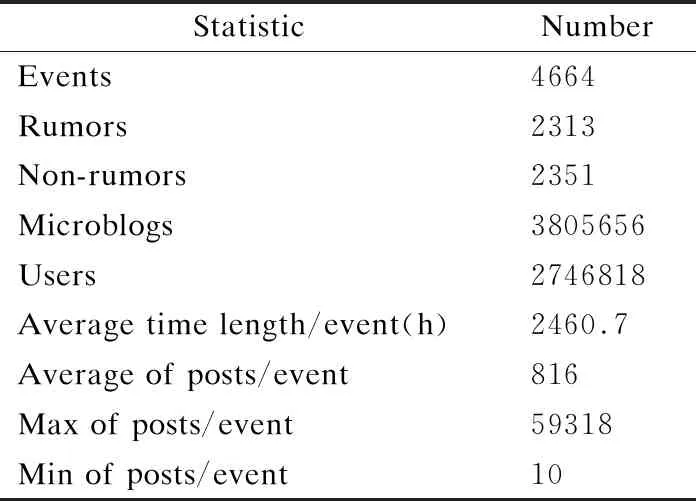
表1 數據集參數表
在模型的參數設置上,本文將該數據集4664個事件中的85%作為訓練集,15%作為測試集,并完成了5次5折交叉驗證.對BERT模型,設置向量的維度為768;對卷積神經網絡(CNN)模型,設置卷積核的寬度設為3,長度為768,卷積核數量為300,dropout為0.5.對加權圖卷積神經網絡(W-GCN)模型,沿用Kipf等[25]的設置,第一個隱藏層單元數為16,第二個隱藏層單元數為7,dropout設置為0.5.模型在學習時,在每個Epoch中迭代訓練所有的訓練集事件,直到模型收斂或者Epoch數量達到最大值為止.此外,本文選取了以小時作為單位的9個時間點,分別為1,3,6,12,24,36,48,72,96.從事件中微博原文發出的時間算起,在以上的時間節點內,分別通過W-GCN模型來完成新浪微博的謠言檢測任務,來檢驗該模型在謠言早期檢測方面的有效性.
2)實驗評估參數
謠言檢測任務實際上是一個文本分類的子任務,是一種二分類的文本分類問題,輸出的結果為謠言及非謠言的概率,選取概率較大的一類作為模型預測的類別.模型的預測類別與實際類別的分類依據,如表2所示.

表2 分類依據
本文選取了評價分類器優良最常見的4個指標:正確率(Accuracy,Acc)、精確率(Precision,Pre)、召回率(Recall,Rec)、F1值(F1-Measure,F1),來評價本文提出的W-GCN模型的有效性.正確率表示被模型正確分類的事件數量與事件總數的比值,如式(5)所示;精確率表示被模型正確分類為謠言(或非謠言)的事件數量與被分類為謠言(或非謠言)的事件總數的比值,如式(6)所示;召回率表示被模型正確分類為謠言(或非謠言)的事件數量與實際為謠言(或非謠言)的事件總數的比值,如式(7)所示;F1值表示準確率和召回率加權調和平均,是對準確率和召回率的綜合考慮,如式(8)所示.
(5)
(6)
(7)
(8)
4.2 實驗對比模型
本文將本文方法與同樣使用該數據集的基準方法進行對比,所選取的基準方法如下:
1)DT-Rank 模型[26].該模型通過搜索微博文本中有爭議的事實性聲明,將它們按相似度進行聚類并根據統計特征,使用決策樹的排名方法對聚類結果進行排名,來完成微博事件的分類任務.
2)SVM-TS 模型[27].該模型通過使用事件的時間序列來得到隨時間變化的事件特征,使用線性SVM分類模型來完成微博事件的分類任務.
3)GRU-2模型[5].該模型基于樹結構遞歸神經網絡,捕捉相關帖子隨時間變化的上下文信息,使用GRU模型通過傳播結構學習事件特征,來完成微博事件的分類任務.
4)PPC_RNN+CNN模型[6].該模型根據事件的傳播路徑,將循環神經網絡(RNN)模型與卷積神經網絡(CNN)模型進行模型融合,使用融合后的模型學習事件特征,來完成微博事件的分類任務.
4.3 實驗結果
1)謠言檢測效果對比
由于GCN的特性,本文在具體實驗時,對事件的訓練集Etrain只將其中的150個微博事件的標簽設置為已知標簽,實驗結果如表3所示.表格中,第1列為所選取的基準方法的模型及本文的模型,從上至下分別為:DT-Rank,SVM-TS,GRU-2,PPC_RNN+CNN和W-GCN模型;第2列為事件的類別,其中R表示謠言(Rumor),N表示非謠言(Non-rumor);第3列為正確率;第4列為精確率;第5列為召回率;第6列為F1值.

表3 謠言檢測結果
從結果中可以看到在基準方法中,傳統的機器學習方法中SVM-TS模型的檢測效果最好,可以達到0.857的正確率;深度學習方法中PPC_RNN+CNN模型的檢測效果最好,可以達到0.916的正確率,可見在謠言檢測任務中,使用深度學習的模型可以取得比傳統的機器學習方法更加顯著的效果.而本文提出的W-GCN模型在檢測結果上,正確率達到了0.956,且各項評估指標均優于上述基準方法.而本文在謠言檢測的評估指標中,召回率可以達到0.977,表明本文方法對謠言事件有更高的敏感性.因此本文模型在謠言檢測的任務上,降低了謠言事件的誤判率,能夠盡可能多地識別出可能的謠言事件.模型的謠言檢測評估指標中的召回率數值更高,意味著更多的謠言事件被篩選出來,能夠更大程度地識別出社交網絡中潛藏的謠言事件,來減少潛藏謠言事件帶來的不利影響,這對社交媒體是十分必要的.綜上所述,本文方法在對新浪微博中的謠言檢測任務中表現出了更好的檢測效果.
與此同時,由于社交媒體信息量的快速增長,對社交媒體中的事件予以謠言或非謠言的標簽,往往需要花費大量的時間與精力.因此社交媒體中的事件,擁有標簽的事件大多數是已經過時的事件,只有極少部分的事件是較新的事件.因此在對新浪微博的謠言檢測任務中,傳統的機器學習方法和深度學習方法包括CNN、RNN等在事件標簽數量不足的情況下,檢測效果會大幅下降,泛化能力較弱.本文提出的模型能夠在標簽數量有限的情況下,達到同樣的檢測效果.綜上所述,與現有的謠言檢測方法相比,本文提出的模型在新浪微博的謠言檢測任務中具有更好的實用性.
2)5折交叉驗證結果
本文使用5次5折交叉驗證,進一步驗證本文模型的謠言檢測效果.在對數據集的劃分中,本文將數據集中的85%劃分為訓練集,15%劃分為測試集.在交叉驗證環節中,本文將訓練集的數據平均分成5份,每次驗證實驗只取其中的1份,并將其作為測試集,其余4份作為訓練集,通過W-GCN模型來得到這份數據的謠言檢測結果,并記錄各項評估指標.將該過程重復進行5次,最終得到所有作為本文訓練集數據的檢測結果,并記錄各項評估指標,結果如表4所示.

表4 5折交叉驗證結果
結果顯示,5次5折的交叉驗證結果中,正確率最大值為0.966,最小值為0.942,相差2.4%,正確率的平均值為0.952.本文測試集實驗結果的正確率高于這5次交叉驗證結果的最小值,低于這5次交叉驗證結果的最大值,略高于這5次交叉驗證結果的平均值.由此可見本文模型在新浪微博的謠言檢測任務中具有較強的泛化能力.
3)早期謠言檢測效果對比
本文在謠言的早期檢測方面與其他基準方法進行了對比,結果如圖3所示.

圖3 謠言的早期檢測結果
在謠言的早期檢測任務中,只能使用從微博原文發布的時間算起之后的若干小時內的微博信息.為了評估本文模型與其他基準方法在謠言檢測早期性的表現,本文選取了以小時作為單位的9個時間點,分別為1,3,6,12,24,36,48,72,96小時.可以看出與現有的謠言檢測方法相比,本文提出的模型在謠言的早期檢測任務上同樣表現出了更好的效果.
4)與無權圖卷積神經網絡模型的效果對比
為了分析連邊的權重對檢測效果的影響,我們將本文模型與無權圖卷積神經網絡(Unweighted-Graph Convolutional Network,UW-GCN)模型進行對比,實驗結果如圖4所示.通過比較W-GCN模型與UW-GCN模型在選取的9個時間點上謠言檢測的正確率,不難看出考慮事件之間聯系的緊密程度,能夠對謠言檢測的效果有較大提升.
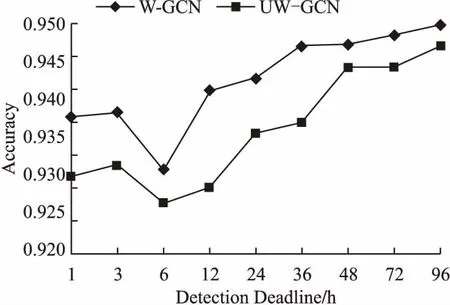
圖4 加權圖卷積神經網絡(W-GCN)模型與無權圖卷積神經網絡(UW-GCN)模型的謠言檢測結果
5)模型訓練的Epoch數量對謠言檢測效果的影響
對W-GCN模型,不同的Epoch數量下訓練集事件與測試集事件的謠言檢測效果進行實驗,設置了25個不同的Epoch數量,結果如圖5所示.
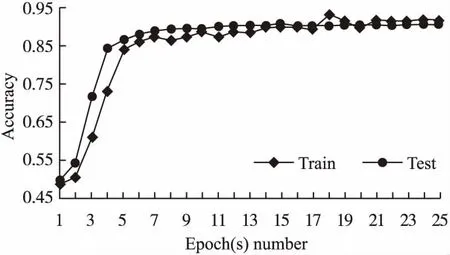
圖5 Epoch(s)數量對謠言檢測效果的影響
可以看出,當模型訓練1個Epoch時,訓練集和測試集數據的檢測正確率都比較低,此時的模型無法學習到微博事件的隱層特征,模型的謠言檢測效果較低.當模型訓練到了第5個Epochs時,訓練集和測試集數據的檢測正確率均快速上升,此時的模型已經初步完成了對微博事件隱層特征的學習,模型的謠言檢測效果一般.隨著模型訓練到第25個Epochs時,訓練集和測試集數據的檢測正確率在一定范圍內波動,總體呈上升趨勢,此時的模型已經具有比較良好的謠言檢測效果.而隨著Epoch(s)數量的進一步增加,模型最終會收斂,對謠言事件的檢測效果會達到最優值.
5 結束語
目前傳統的機器學習方法以及深度學習方法被廣泛地應用于社交媒體的謠言檢測中,但是這些方法忽略了事件之間的聯系或者事件之間聯系的緊密程度,會影響檢測的效果.因此本文充分考慮了事件之間聯系的異質性,基于圖卷積神經網絡(GCN)提出了一種新型的新浪微博平臺謠言檢測的方法.該方法通過將事件作為節點,事件之間的聯系作為連邊,并且考慮了連邊的權重,構建出了一個加權圖卷積神經網絡模型W-GCN.接著使用BERT模型和卷積神經網絡(CNN)模型得到微博事件的特征表示,并將該特征輸入到W-GCN模型中,對W-GCN中的節點完成分類,最終完成新浪微博的謠言檢測任務.與所選的基準方法相比,本文的方法在謠言事件的檢測上取得了最好的效果,體現了本文模型在新浪微博謠言檢測問題中對謠言事件檢測的有效性.同時在謠言的早期檢測方面,本文的方法也高于基準方法,體現了本文提出的模型在新浪微博謠言的早期檢測方面的有效性.為了提高模型檢測的性能,在之后的研究中,可以考慮使用其他事件之間的聯系作為GCN模型中節點之間的連邊,或考慮使用不同的圖網絡模型,在節點的特征向量中,融入一些代表性的微博事件特征等方法,來進一步增強模型的謠言檢測性能.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
