基于多任務學習的無參考超分辨圖像質量評估
2021-08-24 08:41:02劉錫澤李志龍何欣澤
網絡安全與數據管理 2021年8期
劉錫澤 ,李志龍 ,何欣澤 ,范 紅
(1.東華大學 信息科學與技術學院,上海 201620;2.OPPO研究院,上海 200030;3.上海大學 通信與信息工程學院,上海 200444)
0 引言
單幅圖像超分辨率重建(Single Image Super-Resolution Reconstruction,SISR)是圖像復原的一種,其通過信號處理或者圖像處理的方法,將低分辨率(Low-Resolution,LR)圖像轉化為高分辨率(High-Resolution,HR)圖像[1]。目前,SISR被廣泛應用在醫學影像、遙感圖像、視頻監控等領域當中。近年來,許多SISR算法相繼被提出,因此需要一種可靠的方式來衡量各種算法重建圖像的質量好壞。
最可靠的圖像質量評估方式是主觀評分,但這種方式需要耗費大量的人力和時間,所以往往使用客觀評價指標來對超分辨(Super-Resolution,SR)圖像進行質量評估。最常用的圖像客觀評價指標是峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和結構相似度(Structural Similarity,SSIM)。但在 SISR領域中,這兩個指標與人眼感知的一致性較低[2]。因此研究者們提出了一系列基于人類視覺系統(Human Visual System,HVS)的圖像質量評估算法,如信息保真度(Information Fidelity Criterion,IFC)[3]、特征相似度(Feature Similarity,FSIM)[4]等算法,在圖像質量評估數據庫中的性能超過了PSNR、SSIM等傳統算法。
由于以上算法都是全參考圖像質量評估算法,需要HR圖像的信息,在顯示中HR圖像往往是不可獲得的,因此需要開發一種有效的無參考圖像質量評估算法。Ma等人[5]針對SR圖像提出了一種基于兩階段回歸模型的圖像質量評估算法,并創建了第一個SR圖像質量評估數據庫,包含用9種SR算法重建的1 680張SR圖像與每張圖像的主觀質量分數。近年來,卷積神經網絡(Convolutional Neural Network,CNN)被廣泛應用在圖像質量評估任務當中:Fang等人[6]首先提出了基于 CNN的 SR圖像質量評估網絡,Bare等人[7]和 Lin等人[8]分別在 CNN中引入殘差連接和注意力機制,并取得了先進的性能。最近,Zhou等人[9]提出了用于SR圖像質量評估的QADS數據集,包含用21種SR算法重建的980張SR圖像。
本文提出一種基于多任務學習的無參考SR圖像質量評估網絡,并在其中融合先進的協調注意力模塊,在QADS數據集中的結果表明,本文算法的結果與圖像主觀評分保持了較高的一致性。
1 提出方法
1.1 網絡結構
本文提出的網絡結構如圖1所示。網絡的輸入是從SR圖像中裁剪的大小為32×32的小塊,小塊首先經過由8個卷積層、3個最大池化層、4個協調注意力模塊(Coordinate Attention Block,CAB)組成的特征提取階段,此階段輸出大小為 256×4×4的特征圖張量,然后按通道維度進行全局平均池化、全局最大池化、全局最小池化操作,再在通道維度進行拼接,輸出大小為 768×1×1的張量,之后輸入到全連接層,進行兩個任務的預測。

圖1 網絡總體結構圖
其中,任務2用來預測每個小塊的質量分數,是網絡的主要任務。在預測一張圖像的分數時,用圖像裁剪出的所有32×32小塊的質量分數的平均值作為整張圖像的質量分數。任務1用來預測每個小塊的局部頻率特征,輸出為27維的特征向量,任務1中第一個全連接層會與任務2中的第一個全連接層進行拼接操作。任務1的目的是用圖像的局部頻域特征來輔助網絡進行圖像質量分數的預測,實驗證明這種多任務學習的方式可以使網絡預測的分數有更好的準確性和泛化性。
1.2 局部頻率特征
Ma等人[5]預測SR圖像質量分數時,將圖像分為不重疊的7×7大小的小塊,進行離散余弦變換(Discrete Cosine Transform,DCT),并用廣義高斯分布(Generalized Gaussian Distribution,GGD)[10]擬合 DCT 系數,最后取所有小塊DCT特征的平均值作為圖像的局部頻率特征。對每個訓練圖像都計算其局部頻率特征當作模型任務1的標簽。用GGD擬合DCT系數的過程如式(1)所示:


進一步,將每個小塊按圖2分為三組,計算每組 的 歸 一 化 偏 差(i=1,2,3),然 后 計 算的 方 差 作為DCT塊的第三個統計特征。

圖2 DCT小塊分塊示意圖
分別在原始訓練圖像、經σ=0.5的高斯濾波器濾波一次和兩次的訓練圖像中以7×7大小分塊提取三種DCT特征,再取所有小塊的平均值、前10%平均值、后10%平均值作為最終的局部頻率特征,最終的特征為27維的向量。
1.3 協調注意力模塊
SE-block[11]、CBAM[12]等注意力模塊已經被證明能在圖像分類、圖像超分辨率等任務中提高網絡的性能[13-14]。文獻[8]首先將 SE-block模塊融合到 SR圖像質量評估網絡當中。為解決傳統的SE-block等注意力模塊只考慮圖像的通道信息,忽略空間信息、使用全局池化導致丟失過多信息等缺點,文獻[15]提出了一種新的協調注意力模塊(Coordinate Attention Block,CAB)。本文將協調注意力模塊融合到提出的網絡中,提高了預測分數的準確率。協調注意力模塊如圖3所示。
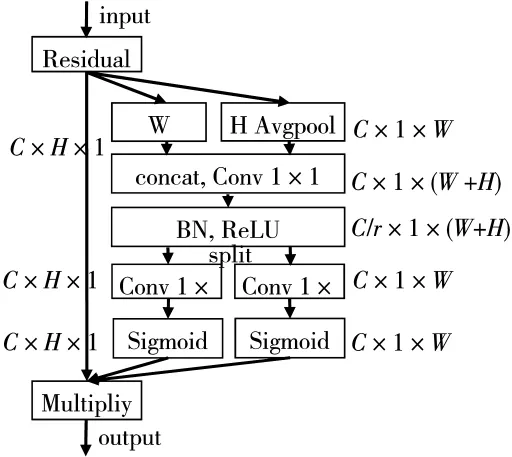
圖3 CAB示意圖
與傳統的SE-block不同,CAB在第一步將二維的全局平均池化操作分解成兩個一維的池化操作,生成W、H兩個方向上的特征描述符。這樣做可以保留特征的空間位置信息,使網絡更精確地捕捉感興趣的目標。高度為h時第c個通道的輸出可以用式(2)表示:

寬度為w時第c個通道的輸出可以用式(3)表示:
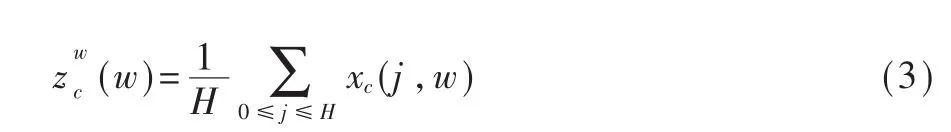
第二步,CAB將兩個方向上的特征描述符連接起來,用收縮率為r的1×1卷積層進行卷積操作,此過程如式(4)所示:

其中,f為包含 W、H兩個方向信息的特征圖,δ為ReLU函數,F1為 1×1卷積操作。
第三步,將f按空間維度分解成兩個特征張量fh和fw,再用兩組1×1卷積層對特征圖進行卷積,形成W、H兩個方向上的注意力權重 gh與 gw,此過程如式(5)、式(6)所示:

其中 Fh與 Fw為 1×1卷積操作,σ為 Sigmoid激活函數。
最后,將W、H兩個方向上的注意力權重與CAB的輸入進行加權,最終的輸出如式(7)所示:
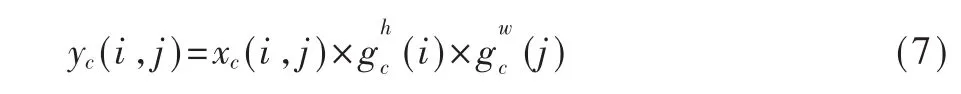
2 實驗結果及分析
2.1 數據與實驗準備
本次實驗采用QADS數據集作為訓練和測試數據集。數據集包括20張原始 HR圖像,包含 2、3、4三種放大倍數,21種SISR方法重建的980張SR圖像和它們的主觀質量分數,質量分數區間在[0,1]區間內,分數越高表明圖片質量越好。
實驗前,先將QADS數據集中的980張SR圖像裁剪為不重疊的 32×32小塊,再按文獻[7]種提出的標簽分發方式計算每一個小塊的質量分數,計算方式如式(8)所示:
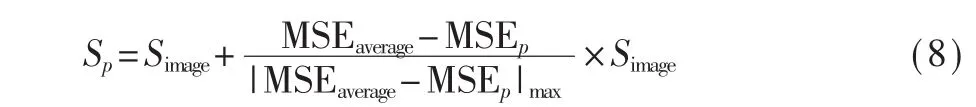
其中Sp為小塊的質量分數,Simage為SR圖像的質量分數,MSEp為原始HR圖像和SR圖像在小塊的32×32區域上的均方誤差,MSEaverage為一張 SR圖像所有小塊與原始HR圖像均方誤差的平均值。在數據集中隨機選取90%圖像作為訓練集,10%圖像作為測試集,進行10折交叉驗證,最后記錄所有實驗的平均結果。
實驗采用Windows 10操作系統,PyTorch 1.7.1深度學習框架,結合并行計算框架CUDA10.1對實驗進行加速。采用的硬件設備為運行內存為8 GB的 Intel?Xeon?CPU E5-2678 v3@2.50 GHz處理器,顯存為12 GB的NVIDIA Tesla K80顯卡。
模型訓練時,設置每次迭代的batch size為32,總共迭代 40個 epoch,每迭代 10個 epoch將學習率將為原來的十分之一。模型使用帶動量項的SGD作為優化器,初始學習率設置為0.01,momentum參數設置為 0.9,weight_decay參數設置為 0.000 1,為了防止梯度爆炸,將超過0.1的梯度值固定為0.1。
訓練時,損失函數使用L1損失,表達式如式(9)所示:
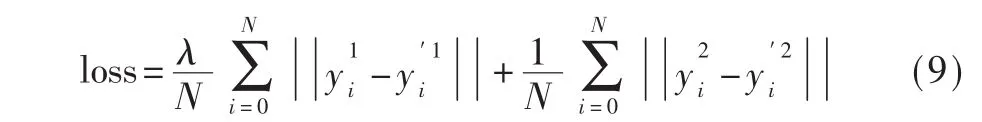
其中 N 為 batch size,y1、y′1分別代表任務 1 的實際值和預測值,y2、y′2分別代表任務 2的實際值和預測值。λ為控制任務1所占權重的超參數。
2.2 對比實驗分析
實驗選擇使用斯皮爾曼等級相關系數(Spearman Rank Order Coefficient,SROCC)、 肯 德 爾 等 級 相 關 系(Kendal Rank Order Coefficient,KROCC)、皮 爾 遜 線 性相關系數(Pearson Linear Correlation Coefficient,PLCC)來評估算法結果與真實標簽的一致性,三種系數越大,表明一致性越好。
2.2.1 消融研究
為了研究多任務學習和協調注意力模塊對模型性能的影響,采用不含多任務學習與協調注意力模塊的模型作為第一種基線模型,在此基礎上加入協調注意力模塊作為第二種注意力模型,用兩種模型與本文提出的模型在相同的訓練數據與參數對比下進行實驗,結果如表1所示。
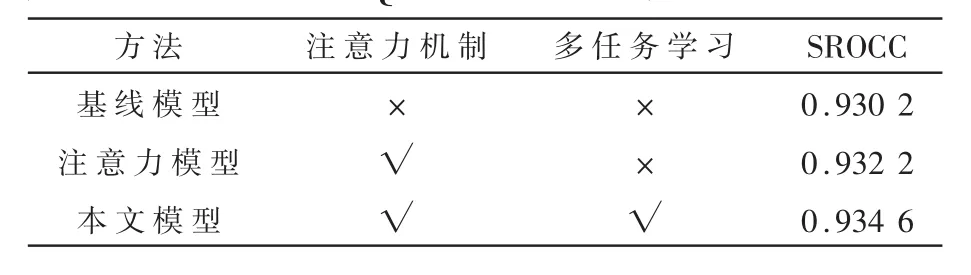
表1 三種模型在QADS數據集中的平均SROCC
結果顯示,含有注意力機制和多任務學習的模型效果最好,僅含有注意力機制的模型次之,基線模型效果最差,表明在網絡中加入協調注意力模塊與多任務學習均可提升模型的預測效果。
2.2.2 值選取
在損失函數中,λ為控制兩種任務權重的超參數,λ越大,任務1在模型訓練時所占的權重越高。為了選取最佳權重,本文對不同λ值的模型進行對比實驗,結果如表2所示。
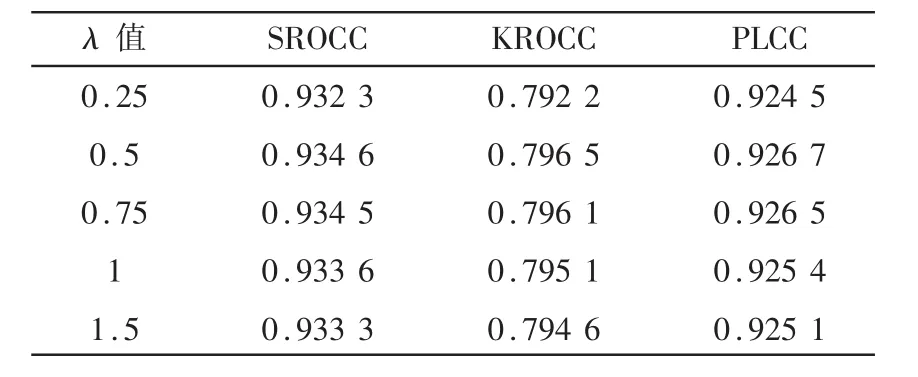
表2 不同λ值的模型在數據集中的各種指標對比
結果顯示,λ值取0.5時,模型性能達到了最優。原因可能是當λ值太大時,局部頻率特征預測任務所占權重越高,對質量分數預測任務產生不良的影響;當λ值太小時,局部頻率特征預測任務對質量分數預測任務的幫助有限。因此本文最終選擇的λ值為 0.5。
2.3 與其他算法的對比
本文選取了文獻[6]、文獻[7]、文獻[8]三種目前有先進性能的無參考SR圖像質量評估算法作為對比算法,為了保持訓練數據和訓練環境的一致,按原始論文參數設置在我們的環境中重新訓練網絡,在10折交叉驗證中每折的訓練數據是一致的。最終的實驗結果如表3所示。

表3 不同方法在數據集中的各種指標對比
結果顯示,本文算法在各種指標上的結果都明顯超過了對比的三種算法,表明本文算法與人眼主觀打分保持了最優的一致性。
3 結論
本文提出了一種基于多任務學習的無參考SR圖像質量評估網絡,將局部頻率特征預測任務融合到模型當中,輔助模型進行圖像質量分數的預測,提升模型預測準確率。進一步,本文在模型中加入先進的協調注意力模塊,使模型可以更精確地定位到對分數預測影響更大的目標像素。本文對比實驗證明了將多任務學習與注意力模塊加入到模型當中的有效性,與其他算法的對比結果證明了本文算法與主觀打分保持了較高的一致性。下一步的工作目標是發掘更有效的圖像特征來進行多任務學習的預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國生殖健康(2019年2期)2019-08-23 08:12:08
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
