基于可視化分析的我國大數據產業研究現狀綜述
2021-08-28 02:04:49楊子江單鐵城李晨李憲毅杜陽
中小企業管理與科技·中旬刊 2021年9期
楊子江 單鐵城 李晨 李憲毅 杜陽

【摘? 要】論文基于CNKI數據庫,運用文獻計量、信息可視化和社會網絡分析的方法,對我國2012-2020年大數據產業研究的核心期刊文獻進行梳理,用Citespace構建了共現圖譜,分析了該領域的發文趨勢和主要研究機構;通過Ucinet進行社會網絡分析,探討了我國大數據產業研究的發展特點和高頻關鍵詞之間的聯系情況。
【Abstract】Based on CNKI database, this paper uses the methods of bibliometrics, information visualization and social network analysis to sort out the literatures of the core journals of big data industry research in China from 2012 to 2020. Citespace is used to construct the co-occurrence map and analyze the publishing trend and major research institutions in this field. Through social network analysis by Ucinet, this paper discusses the development characteristics of China's big data industry research and the relationship between high-frequency keywords.
【關鍵詞】大數據產業;可視化分析;社會網絡分析;知識圖譜
【Keywords】big data industry; visual analysis; social network analysis; knowledge map
【中圖分類號】F49? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 【文獻標志碼】A? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?【文章編號】1673-1069(2021)09-0040-04
1 引言
隨著數據量的飛速增長,人們邁入了大數據時代,新型信息發布方式不斷涌現,數據正成為另一種重要的戰略資源。大數據是眾多關鍵行業關注的問題。“大數據”這一概念從被提出到獲得普遍認可并成為全球熱詞,伴隨的是數據在各行業領域的深層滲透與應用。作為復雜而龐大的數據集,它具備強大的分析與挖掘價值,是影響競爭和發展的重要因素。在信息化發展的新階段,大數據對經濟發展、社會秩序、國家治理、人民生活都會產生重大影響。
為推動我國大數據產業有效、健康發展,本文運用文獻計量和信息可視化的方法,對我國大數據產業相關研究的核心期刊文獻進行梳理,分析了該領域的發文趨勢和主要研究機構;通過共詞分析、知識圖譜和社會網絡分析,探討新時期互聯網和大數據環境下,大數據產業的發展特點和主題演化,以期為之后研究工作的開展提供參考。
本文運用文獻計量和信息可視化的方法,對我國大數據產業相關研究的核心期刊文獻進行梳理,分析了該領域的發文趨勢和主要研究機構,以期為之后研究工作的開展提供參考。
2 數據來源與研究步驟
2.1 數據來源
本文選用CNKI平臺中國學術期刊網絡出版總庫(CAJD)作為數據源,以“大數據產業OR大數據行業”為檢索詞進行主題檢索,檢索年限字段從2012年開始,截至2020年,根據布拉德福文獻離散分布規律,為保證研究的有效性,研究論文數據1165條(檢索時間為2021年3月27日)。
2.2 研究步驟
運用文獻計量的理論和方法,對收集所得的大數據產業研究文獻進行統計分析。基于詞頻分析法,利用SATI、Excel軟件處理文獻數據,從文獻數量、作者和機構分布、關鍵詞等角度進行了社會網絡分析,探討參與大數據產業相關研究的作者和機構的合作情況以及該領域的研究熱點和前沿。將期刊來源類別字段設定為核心期刊及CSSCI來源期刊。通過人工篩選、去重、整理,共得到大數據產業相關研究論文數據1165條(檢索時間為2021年3月27日)。
3 分析討論
3.1 大數據產業相關研究發文的時間分布
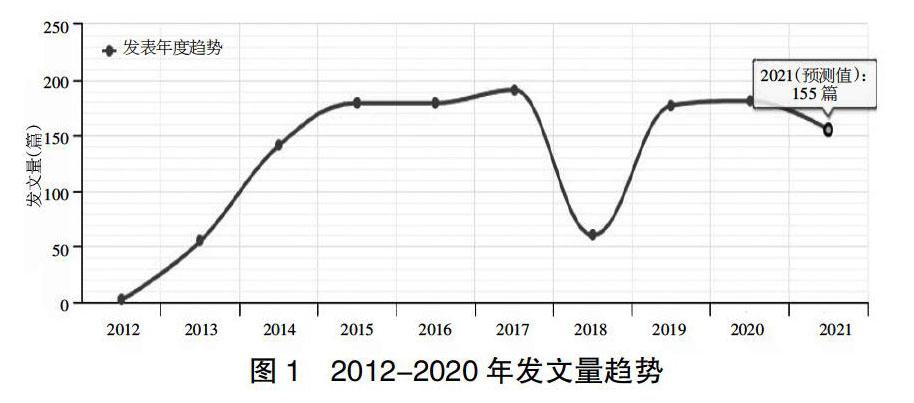
我國2012年均發表在圖書情報學相關期刊上,指出了大數據時代的來臨和對數據進行創新分析的重要性。大數據的研發與應用開始被重視起來。截至2020年,該領域共發表核心期刊論文1165篇,其發文趨勢見圖1。
工業4.0代表了第四次工業革命,代表了生產中自主和非集中控制的新范式。產品和生產系統被增強為具有相互通信、構建自組織網絡、自我控制和自我優化能力的網絡物理系統。從IT的角度來看,這涉及一個新層次的網絡、數據集成和生產中的數據處理。物聯網、大數據等成熟技術是工業4.0的傳播解決方案組件。到目前為止,還沒有對IT需求進行有根據的詳細闡述,也沒有對解決方案組件如何滿足這些需求進行有區別的討論。本研究采用內容分析的方法,從現有的研究文獻中提取工業4.0的需求。分析的目標是數據處理需求的結構化匯編。由此產生的分類方案支持在工業4.0的應用領域中進一步開發解決方案組件。此外,本文還展示了如何將需求與大數據軟件解決方案的能力相匹配。因此,確定并描述了工業4.0中大數據應用程序的2個通用用例。我們可以看到2012-2020年大數據產業相關研究從2012年至2015年呈指數增長。與此同時,該行業在管理大量可用于執行大數據項目的技術方面面臨巨大挑戰。在初步調查的基礎上,有一個空白的文獻清楚地審視了銀行業是如何利用大數據的潛力和面臨的挑戰。本研究以3家選定銀行為樣本進行個案研究,旨在通過更細致地調查如何使用和管理大數據來填補這一空白。這些發現將有助于我們從技術的角度加深對大數據實施和管理技術的理解,因此,2015年我國大數據產業相關研究發生了“大爆炸”。雖然2015-2017年發文量增長趨于平穩,但發文量一直較高,這段時間,我國相繼出臺了各種相關政策。2018年,大數據行業發展達到了一個“瓶頸”,發文量有明顯的下降,國家出臺的相關政策也較少。2018年之后,相關研究繼續增長。由此可以看出,該領域的研究與國家政策的支持有較大關系。近年來,各種網絡物理系統(CPS)的開發和實現呈爆炸式增長。因此,與CPS相關的研究和CPS技術的進步越來越成為物聯網(IoT)、大數據、云計算和工業4.0等IT領域新興趨勢的一部分。然而,只有很少的研究工作能夠確定與新興IT趨勢相關的綜合CPS研究趨勢。因此,本文的目的是探討什么樣的CPS研究主題與新興的IT趨勢相關,以及產業如何實施CPS技術。
3.2 大數據產業相關研究的熱點和前沿分析
2012-2020年大數據產業相關研究涉及的關鍵詞及其頻次統計顯示,1162篇文獻共涉及關鍵詞5112個,其中占該領域關鍵詞總數55.01%的2812個關鍵詞出現過1次(見圖2)。
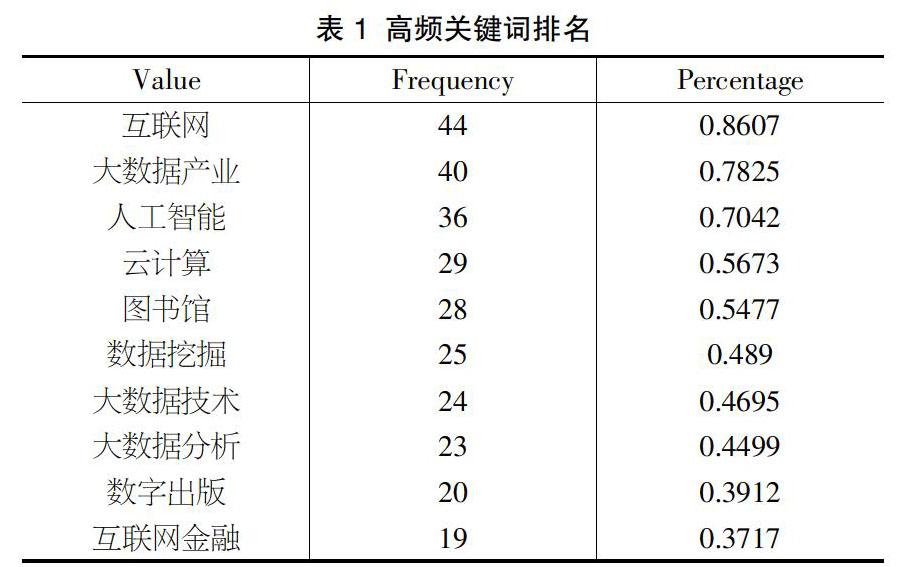
將CNKI的論文以endnote形式導入文獻題錄信息統計分析工具SATI軟件,對文檔提取關鍵詞,其中TOP10高頻關鍵詞如表1所示。
首先將從中國知網下載的endnote格式文檔輸入SATI軟件中,變成了50×50的共詞矩陣,計算共詞矩陣的Ochiai(相似)系數,并得到相似矩陣,如圖3所示。
接下來,運用Ucinet軟件對關鍵詞相關矩陣進行社會網絡分析。人工刪掉了“大數據”“大數據時代”等過大的節點,得到高頻關鍵詞網絡圖,如圖4所示。
對該網絡進行中心度分析,節點之間的連線越多,顏色越深,代表其相互關系作用越強。根據圖5可知,節點中心度由大到小依次為“人工智能”“數據挖掘”“云計算”“大數據分析”“數據共享”等。
數據挖掘技術是如何在Hadoop中用于云數據的,技術融入日常生活中已經變得非常流行。數據挖掘有助于提高業務領域的效率,降低成本。在云計算范式中,最需要的是數據挖掘的應用和技術。用戶可以從虛擬集成的數據倉庫中獲取有意義的信息,通過在云計算中實現數據挖掘來降低存儲和基礎設施的成本。本文以電信行業客戶流失預測為研究對象,將數據集存儲在云端,利用Hadoop中的數據挖掘技術實現。本文采用分類的方法對電信行業的數據集進行分析,對數字數據和文本數據進行分類,并對可能從現有網絡中切換的用戶進行預測,在Hadoop環境下,利用聚類方法對給定數據集的分類結果進行分組,以達到對數字和文本數據的最佳預測。Hadoop是一個易于實現分類的環境。按照“網絡—凝聚力—密度—密度”的路徑進行網絡密度分析,結果顯示網絡密度為0.0016,通過比較,該網絡密度較低,關鍵詞之間的聯系較弱。
鑒于此,為進一步研究我國大數據研究的發展趨勢,運行CiteSpace,參數設置“Burst items”,得到關鍵詞突現圖(見圖6)。
由圖6可看出,2012年,大數據產業研究起步階段,研究多在情報學領域和數據分析領域,而后,大數據產業的研究可以融入許多原本存在的和新出現的行業中。最后,2018-2020年突變詞為“產業融合”,說明大數據產業在“產業融合”方面的研究將是一種發展趨勢,大數據將更好地促進各個產業進行融合發展。面向流程工業領域的跨部門大數據平臺的體系結構。主要目標是設計一個可擴展的分析平臺,支持多個行業領域數據的收集、存儲和處理。這樣一個平臺應該能夠連接到工廠的現有環境,并使用收集到的數據建立預測功能,以優化生產過程。分析平臺將包含用于構建這些功能的開發環境,以及用于評估模型的仿真環境。該平臺將在不同行業的多個網站之間共享。跨部門共享將使知識能夠在不同領域之間進行轉移。在開發過程中,我們采用了以用戶為中心的方法來收集來自不同涉眾的需求,這些涉眾用于從不同的角度(從上下文到部署)設計體系結構模型。部署的架構在2個過程工業領域進行了測試,一個來自鋁生產,另一個來自塑料成型行業。
4 結論與不足
由于大數據概念比較廣泛,大數據產業涉及的領域也較多,使得對大數據產業研究現狀分析不夠系統和完整。
我國大數據產業研究與國家政策的支持有較大關系,相關研究起步于2012年,2012-2015年發文量呈指數增長,2015-2017年發文量增長趨于平穩,但發文量一直較高,2018年,大數據行業發展達到了一個“瓶頸”,發文量有明顯的下降,2018年之后,相關研究繼續增加。研究還發現,我國大數據產業研究熱點主要集中在“人工智能”“數據挖掘”“云計算”“大數據分析”“數據共享”等方面,通過對該網絡的密度進行分析,發現關鍵詞整體網絡密度較低,關鍵詞之間的聯系較弱,對關鍵詞進行小團體分析,最終將50個關鍵詞分為10個小團體,表明關鍵詞之間較分散。通過對突變詞的研究,說明大數據產業在“產業融合”方面的研究將是一種發展趨勢。
【參考文獻】
【1】李后卿,樊津妍,印翠群.中國大數據戰略發展狀況探析[J].圖書館,2019(12):30-35.
【2】習近平:實施國家大數據戰略加快建設數字中國[J].中國衛生信息管理雜志,2018,15(01):5-6.
【3】國發〔2015〕50號.國務院關于印發促進大數據發展行動綱要的通知[Z].
【4】工信部規[2016]412號.工業和信息化部關于印發大數據產業發展規劃(2016-2020年)的通知[Z].
【5】邱均平.信息計量學(四) 第四講? 文獻信息離散分布規律——布拉德福定律[J].情報理論與實踐,2000(04):315-314+316-320.
【6】林德明,陳超美,劉則淵.共被引網絡中介中心性的Zipf-Pareto分布研究[J].情報學報,2011(1):76-82.
【7】黃曉斌,鐘輝新.大數據時代企業競爭情報研究的創新與發展[J].圖書與情報,2012(06):9-14.
【8】張文彥,武瑞原,于潔.大數據時代的圖書館初探[J].圖書與情報,2012(06):15-21.
【9】季忠洋,李北偉,朱婧祎.大數據生態系統形成機理與模型構建研究[J].圖書館學研究,2018(05):9-13+8.
