基于深度學(xué)習(xí)的礦井下作業(yè)人員安全帽佩戴檢測
2021-09-01 14:18:34石永恒楊超宇
綏化學(xué)院學(xué)報 2021年9期
石永恒 楊超宇
(安徽理工大學(xué)經(jīng)濟與管理學(xué)院 安徽淮南 232001)
煤礦員工在礦井下進行生產(chǎn)作業(yè)時,佩戴安全帽是有效保護員工生命安全、有效降低事故危害的防護措施;但根據(jù)近年來所發(fā)生的種種煤礦安全事故來看,由于未佩戴安全帽行為導(dǎo)致事故危害升級的案例屢見不鮮;因此,對煤礦員工安全帽佩戴進行檢測十分重要。目前來看,煤礦企業(yè)中對于是否佩戴安全帽的檢查方式主要包括兩種:一是通過對監(jiān)控視頻的回放查看,發(fā)現(xiàn)作業(yè)人員未佩戴安全帽的違規(guī)行為;二是通過人工實時檢查的方式,發(fā)現(xiàn)未佩戴安全帽的違規(guī)行為。但上述兩種檢測方式存在滯后性和低效性的問題,并不能在事故發(fā)生前及時消除安全隱患;因此,運用深度學(xué)習(xí)的方法對煤礦員工的安全帽佩戴情況進行實時檢測具有十分重要的現(xiàn)實意義和實用價值。
傳統(tǒng)的目標(biāo)檢測都是通過手工設(shè)計特征來實現(xiàn)對目標(biāo)對象的檢測,這就導(dǎo)致了在進行實際的目標(biāo)檢測時,出現(xiàn)目標(biāo)檢測準(zhǔn)確率低的問題且模型的泛化性較差,不具備魯棒性。近年來,隨著卷積神經(jīng)網(wǎng)絡(luò)(CNN)的提出,使得深度學(xué)習(xí)在進行特征提取時有效地解決了手工設(shè)計特征的缺陷。基于此,一些學(xué)者提出了一系列的基于深度學(xué)習(xí)的目標(biāo)檢測算法。Girshick等[1]在2014年提出了R-CNN(區(qū)域卷積神經(jīng)網(wǎng)絡(luò))算法,采用Region Proposal(候選區(qū)域)方法實現(xiàn)目標(biāo)檢測問題,代替了傳統(tǒng)目標(biāo)檢測方法中手工設(shè)計特征的方式,使得基于深度學(xué)習(xí)進行目標(biāo)檢測的方法獲得了巨大進步。隨后,Girshick[2]和Ren等[3]在2015年進一步提出了Fast RCNN和Faster R-CNN算法,在提高檢測率的同時也提高了檢測速度,同時Faster R-CNN的提出算是真正實現(xiàn)了網(wǎng)絡(luò)的端到端訓(xùn)練。Redmon J等[4]在2015年提出了YOLO v1算法,進一步提高了目標(biāo)檢測的速度,并且能夠?qū)σ曨l進行目標(biāo)檢測。W Liu等[5]在2016年提出了SSD(Single Shot MultiBox Detector)算法,SSD相較于YOLO v1來說有著更好的表現(xiàn),在保持較快運行速度的同時,在檢測精度方面能夠達到兩階段目標(biāo)檢測算法的水平。同年,Redmon相繼提出了YOLO v2[6]和YOLO v3[7]檢測算法,顯然YOLO v3對目標(biāo)檢測的效果更佳,根據(jù)作者所述,YOLO v3在COCO數(shù)據(jù)集上的實驗表現(xiàn)為51 ms時間內(nèi)mAP達到57.9%,與RetinaNet在198 ms時間內(nèi)mAP達到57.5%相當(dāng),在速度提高了近3.8倍的基礎(chǔ)上還保持了相似的精度,由此顯示了YOLO v3在深度學(xué)習(xí)目標(biāo)檢測算法中,具有較好的檢測速率和檢測準(zhǔn)確率。
而針對安全帽佩戴這一目標(biāo)檢測問題,國內(nèi)也有越來越多的學(xué)者進行深入研究。劉曉慧等[8]在2014年運用膚色檢測和Hu矩的方法進行安全帽佩戴識別。施輝等[9]在2019年以YOLO v3算法為基礎(chǔ),結(jié)合圖像金字塔的多尺度特征獲取,進而構(gòu)建了一種改進YOLO v3算法的安全帽佩戴檢測方法。徐先峰等[10]在2020年利用MobileNet網(wǎng)絡(luò)結(jié)構(gòu)代替SSD算法中的VGG網(wǎng)絡(luò)結(jié)構(gòu),形成一種改進SSD算法的安全帽佩戴檢測方法。近兩年,國內(nèi)逐漸開始有學(xué)者利用深度學(xué)習(xí)的方法進行安全帽佩戴檢測研究,但是很少有針對煤礦員工安全帽佩戴檢測的研究。主要是因為煤礦井下作業(yè)的環(huán)境較為復(fù)雜,井下監(jiān)控視頻數(shù)據(jù)質(zhì)量不高。
本文主要以煤礦井下監(jiān)控視頻數(shù)據(jù)為基礎(chǔ),對視頻數(shù)據(jù)進行相應(yīng)地預(yù)處理,制作形成訓(xùn)練數(shù)據(jù)集;使用YOLO v3算法進行數(shù)據(jù)集的訓(xùn)練,以獲取能夠滿足煤礦井下環(huán)境需求的安全帽檢測模型;通過實驗結(jié)果表明,本文所使用的算法能夠在實驗精度以及實驗速率上滿足現(xiàn)實需求。
一、YOLO v3算法原理
(一)算法網(wǎng)絡(luò)結(jié)構(gòu)。YOLO v3算法是一種單階段目標(biāo)檢測算法,它的網(wǎng)絡(luò)結(jié)構(gòu)如下圖1所示。YOLO v3算法融合了FPN(特征圖金字塔網(wǎng)絡(luò))網(wǎng)絡(luò)結(jié)構(gòu)、殘差網(wǎng)絡(luò)等創(chuàng)新思想,使得整個網(wǎng)絡(luò)具有較好的識別速度和準(zhǔn)確度。YOLO v3算法使用DarkNet-53網(wǎng)絡(luò)實現(xiàn)對目標(biāo)的特征提取,該網(wǎng)絡(luò)由53個卷積層構(gòu)成,包含一系列的3×3和1×1的卷積層,并借鑒了ResNet網(wǎng)絡(luò)中的殘差思想。DarkNet-53網(wǎng)絡(luò)中的殘差組件如下圖2所示,每個殘差組件有兩個卷積層和一個快捷鏈路;先通過步長為2的3×3卷積,獲得特征層x,隨后通過一次1×1的卷積使得通道數(shù)縮減為原先的一半,之后再經(jīng)過3×3的卷積加強目標(biāo)特征的提取并使得通道數(shù)重新擴充,獲得Fx,最后利用殘差組件將Fx和x進行堆疊,DarkNet-53網(wǎng)絡(luò)使用殘差的跳層連接,有效的降低了池化帶來的梯度負面效果。
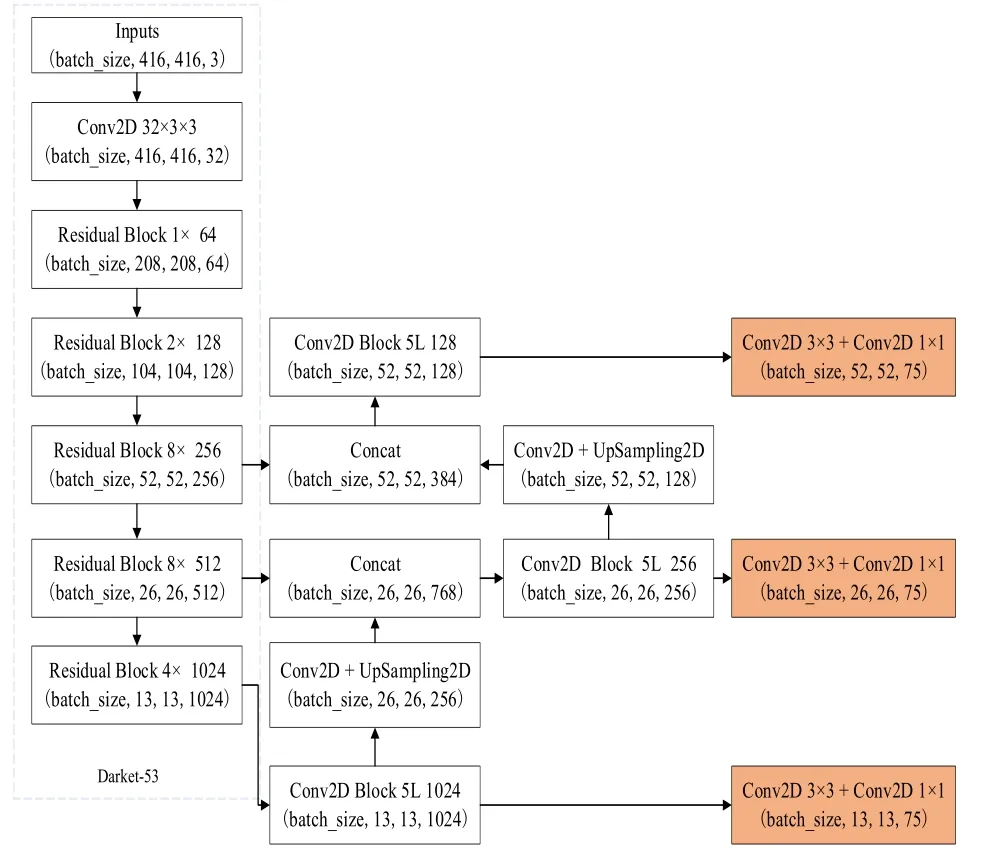
圖1 YOLO v3網(wǎng)絡(luò)結(jié)構(gòu)
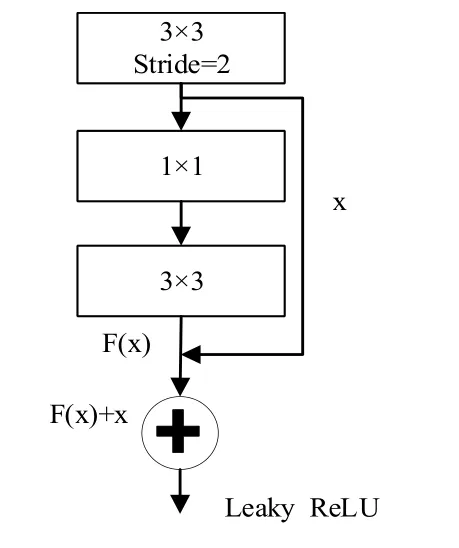
圖2 Darket-53網(wǎng)絡(luò)中的殘差單元
(二)邊框預(yù)測及選擇。
1.邊框預(yù)測。對于檢測目標(biāo)的邊界框預(yù)測,YOLO v3算法沿用了之前YOLO算法中所采用的維度聚類的方式固定錨框(anchor box)來選定邊界框;通過K-means聚類獲得3種不同尺度的先驗框,對于每個預(yù)測邊框會通過算法中的神經(jīng)網(wǎng)絡(luò)預(yù)測出邊框的坐標(biāo)信息,預(yù)測邊界框的坐標(biāo)計算方式如下:
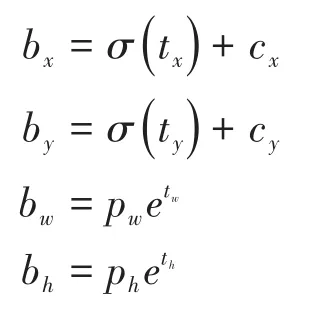
式中bx、by為預(yù)測邊界框的中心點坐標(biāo),bw、bh為預(yù)測邊界框的寬度和高度;cx、cy為網(wǎng)格距離圖像左上角的邊距;tx、ty、tw、th為算法學(xué)習(xí)的目標(biāo);pw、ph為預(yù)先設(shè)定的錨框維度。
對于預(yù)測邊界框中的類預(yù)測,YOLO v3算法每個框使用多標(biāo)簽分類來預(yù)測邊界框可能包含的類,并且不再使用Softmax的方式進行分類,而是使用獨立的邏輯分類器;在算法訓(xùn)練過程中,通過二元交叉熵損失的方式進行類別預(yù)測,通過多標(biāo)簽的方法可以更好地模擬數(shù)據(jù)。
2.IoU及NMS(非極大值抑制)。IoU即預(yù)測框與真實框的交并比,用來反應(yīng)預(yù)測框與真實框的重合度,即:
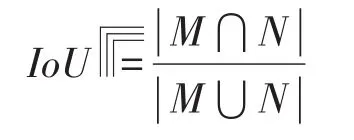
IoU值越大說明預(yù)測框與真實框的重合度越高,則預(yù)測框就能更好地反應(yīng)出真實框內(nèi)的信息,對目標(biāo)檢測的準(zhǔn)確度就會越高。在邊界框之后,每個預(yù)測邊界框會產(chǎn)生一個置信度(Confidence值),這個值反應(yīng)了預(yù)測的邊框內(nèi)含有檢測目標(biāo)的置信度,置信度的表達式如下:
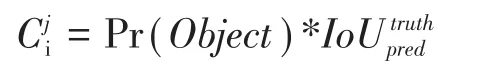
式中Pr(object)是判斷是否有檢測目標(biāo)包含在網(wǎng)格內(nèi),表示預(yù)測框與真實框的交并比值,其中值越高則表明所預(yù)測的邊界框內(nèi)含有檢測目標(biāo)且位置準(zhǔn)確。
在YOLO v3算法中,在預(yù)處理及訓(xùn)練過程中會產(chǎn)生多個預(yù)測框,因此算法會根據(jù)每個預(yù)測框與真實框的IoU值的大小,通過NMS算法來最終確定一個與真實框重合度最高的預(yù)測邊界框。首先針對所有預(yù)測邊框,將置信度低于設(shè)定閾值的預(yù)測框剔除掉,針對同類檢測目標(biāo)每次選取置信度最大的Bounding Box,然后從剩下的BBox中與選取的BBox重合度較高(即IoU值較高)的預(yù)測框,這些與選取的邊界框有著較高重合度的預(yù)測框?qū)灰种疲刺蕹Mㄟ^這種方式選取出來的BBox會被保留下來,并且不會在下一次的選取中出現(xiàn);接著開始下一輪,重復(fù)上述過程;選取置信度最大BBox,抑制高重合度的BBox。采用這種方式,最終對于同一個檢測目標(biāo),最終只會保留一個置信度最高的邊框,不會出現(xiàn)同一目標(biāo)進行多次檢測的重復(fù)行為,從而提高檢測速率。
(三)損失函數(shù)。YOLO v3算法的損失函數(shù)一共包含四個方面,分別是中心坐標(biāo)誤差、寬高坐標(biāo)誤差、預(yù)測邊界框的置信度誤差和分類誤差,損失函數(shù)計算方式如下:
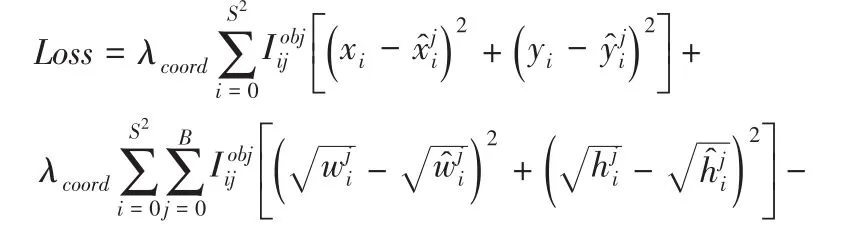
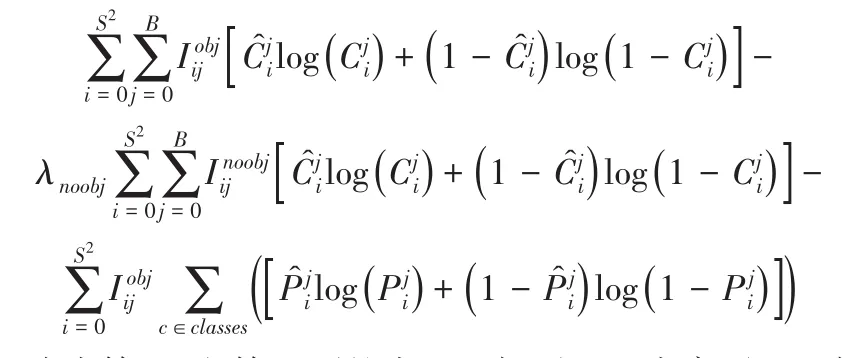
式中第一項、第二項的中心坐標(biāo)誤差和寬高誤差坐標(biāo)反應(yīng)了預(yù)測邊界框的坐標(biāo)誤差情況;第三項、第四項表示預(yù)測邊界框的置信度,反映了預(yù)測邊框內(nèi)含有檢測目標(biāo)的情況;第五項反映了對檢測目標(biāo)的分類情況。
二、實驗流程及結(jié)果分析
本文在Linux系統(tǒng)上搭建實驗平臺,使用NVIDIA GeForce GTX 1660Ti用于GPU加速,實驗環(huán)境為CUDA10.1+CUDNN7.6,本實驗在PyTorch1.6.0深度學(xué)習(xí)框架下對模型進行訓(xùn)練及測試。
(一)數(shù)據(jù)集制作。本文主要是針對煤礦員工安全帽的佩戴檢測,故采用煤礦井下作業(yè)現(xiàn)場監(jiān)控視頻作為數(shù)據(jù)來源;利用OpenCV4.4.0版本開發(fā)庫將所采集的視頻數(shù)據(jù)轉(zhuǎn)換為圖片格式的數(shù)據(jù),再經(jīng)過進一步的圖片篩選共獲得了6892張有效圖片數(shù)據(jù),數(shù)據(jù)集包括佩戴安全帽的作業(yè)人員和未佩戴安全帽的作業(yè)人員兩類,自建數(shù)據(jù)集能夠較好地反映出煤礦井下作業(yè)的真實環(huán)境。
1.數(shù)據(jù)集標(biāo)記。本文根據(jù)的實驗需要,在制作數(shù)據(jù)集過程中使用LabelImg標(biāo)注工具,進行數(shù)據(jù)集的標(biāo)注工作,所標(biāo)注的數(shù)據(jù)集類別分為戴安全帽和未戴安全帽兩類;在進行數(shù)據(jù)集標(biāo)注時,根據(jù)實驗需求對數(shù)據(jù)集中的對象進行有效標(biāo)注,標(biāo)注工具自動生成相應(yīng)的配置文件,以數(shù)據(jù)集中的一張圖片標(biāo)注為例,展示如下圖3所示。

圖3 數(shù)據(jù)集標(biāo)注圖例
2.數(shù)據(jù)集劃分及數(shù)據(jù)預(yù)處理。為了確保訓(xùn)練模型的合理性,本文按照9:1的比例,將數(shù)據(jù)集劃分為訓(xùn)練集和測試集兩部分。為了將自建數(shù)據(jù)集轉(zhuǎn)化為適用于YOLO v3識別的數(shù)據(jù)格式,需要對自建數(shù)據(jù)集進行格式轉(zhuǎn)換;同時,為了提升模型的收斂速度和模型的精度,對數(shù)據(jù)集進行歸一化操作。
(二)模型訓(xùn)練及測試。由于所使用的數(shù)據(jù)集與YOLO v3原始數(shù)據(jù)集不同,因此,需配置實驗所需的yolov3-helmet.cfg文件;更改學(xué)習(xí)率、批次大小等配置參數(shù),使得YOLO v3網(wǎng)絡(luò)能夠有效的對模型進行訓(xùn)練。本文使用PyTorch版本的YOLO v3權(quán)重文件進行模型參數(shù)的訓(xùn)練。其中部分重要參數(shù)設(shè)定如下表1所示。

表1 模型訓(xùn)練部分參數(shù)設(shè)定
按照上表所示的參數(shù)設(shè)置,對模型進行訓(xùn)練,經(jīng)過100次迭代后,獲得相應(yīng)的模型評價指標(biāo),以及一個最優(yōu)模型權(quán)重,并進行模型測試。
(三)實驗結(jié)果及分析。
1.實驗結(jié)果分析。通過上述的實驗過程,可以得到本文所使用的YOLO v3算法對自建的安全帽數(shù)據(jù)集的檢測能夠獲得一個比較好的結(jié)果,具體的識別效果圖見下圖4所示:
根據(jù)圖4-1可見本實驗對于單目標(biāo)簡單環(huán)境下具有更好的識別效果,在多目標(biāo)以及較復(fù)雜環(huán)境下精度稍低,但識別精度也處于較高的水平。

圖4-1 單目標(biāo)及多目標(biāo)識別結(jié)果
根據(jù)圖4-2能夠反映出本文實驗所獲取的檢測模型對于不佩戴安全帽的情形,也能夠有著較好的檢測效果。

圖4-2 未佩戴安全帽檢測結(jié)果
根據(jù)圖4-3可見,本文實驗所獲的檢測模型對存在一定干擾項的情況下(比如佩戴帽子等類似安全帽的情形),也能夠獲得較好的識別精度。由上示圖例可以清晰的看出,本文所研究的安全帽佩戴檢測方法,能夠很好的滿足實際的檢測需求,在多目標(biāo)以及存在干擾項等等情形下,都能夠進行有效識別。

圖4-3 存在干擾項的安全帽佩戴檢測識別
2.與其它算法對比實驗。為了更好的體現(xiàn)本文所使用的YOLO v3算法在安全帽識別上的表現(xiàn),使用其它單階段檢測算法進行對比試驗,具體的實驗對比見下表2所示。
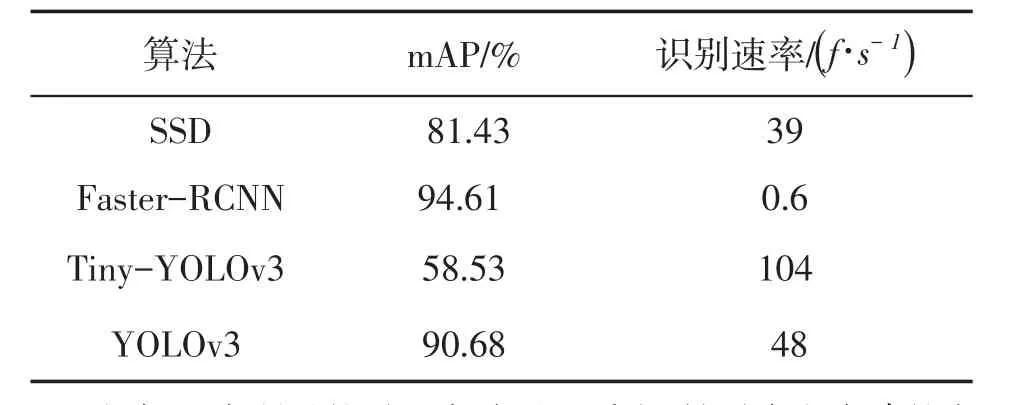
表2 不同算法實驗結(jié)果對比表
根據(jù)上表所示的對比實驗可以看出,針對本文自建的安全帽佩戴檢測數(shù)據(jù)集的檢測來說,本文所使用的YOLO v3算法,相較于其他目標(biāo)檢測算法來說,具有更加優(yōu)越的檢測性能,雖然在檢測精度上低于Faster-RCNN,但是在檢測速率方面本文算法更能滿足對實時視頻流的檢測需求,更加適合實際環(huán)境中的檢測任務(wù)。
三、結(jié)語
本文使用YOLO v3算法作為安全帽檢測的基礎(chǔ),通過對煤礦井下數(shù)據(jù)的訓(xùn)練,獲得一個較穩(wěn)定的模型,能夠?qū)碌淖鳂I(yè)人員的安全帽佩戴情況進行有效檢測,實驗所取得的檢測精度以及算法的檢測速率均能滿足實際的需求,能夠?qū)崟r的視頻流進行有效檢測;但是,算法還存在一定的不足之處,對于較小目標(biāo)的檢測還存在一定的問題,因此下一步需要在現(xiàn)在的基礎(chǔ)上對算法進行有效改進,完善算法對較小目標(biāo)的檢測功能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
