云計算環境下的海量圖像查重算法設計
2021-09-01 14:18:34高興
綏化學院學報 2021年9期
關鍵詞:分類
高 興
(沈陽音樂學院公共基礎部 遼寧沈陽 110818)
云計算技術是借助于大規模低成本的服務器構成的分布式計算系統,將海量的數據通過網絡云進行分解或者分類,將結果傳送或者反饋給用戶。云計算能夠按照用戶需求提供云服務,且具備運行成本低、可靠性高、擴展性好等優勢[1]。云計算包括虛擬化技術、分布式海量數據存儲和分布式計算技術,可以實現龐大、復雜的數據信息等資源處理,使海量的數據信息在較短時間內完成處理,提高數據信息的處理效率[2]。圖像作為當下主要的信息傳播方式,在眾多領域都廣泛應用,如何在海量的圖像中判斷相同的圖像,已然成為當下圖像查重領域的主要研究內容。
一、云計算環境下的海量圖像查重算法
(一)云計算環境下的海量圖像識別技術。海量圖像分類是圖像查重的前提,為了更好地完成海量圖像分類,采用云計算技術完成[3]。在云平臺上利用云計算技術實現圖像分類處理的整體流程。圖像分類需先提取云平臺上圖像數據庫中的圖像特征,并將待分類圖像特征與圖像庫中圖像特征進行匹配,根據匹配結果完成圖像的類別劃分[4]。云計算技術圖像分類原理如圖1所示。其中,圖像預處理主要作用是完成圖像的色彩轉換,并將轉換后的圖像存儲。采用相關特征提取方法完成存儲圖像的數據計算,獲取圖像特征[5]。
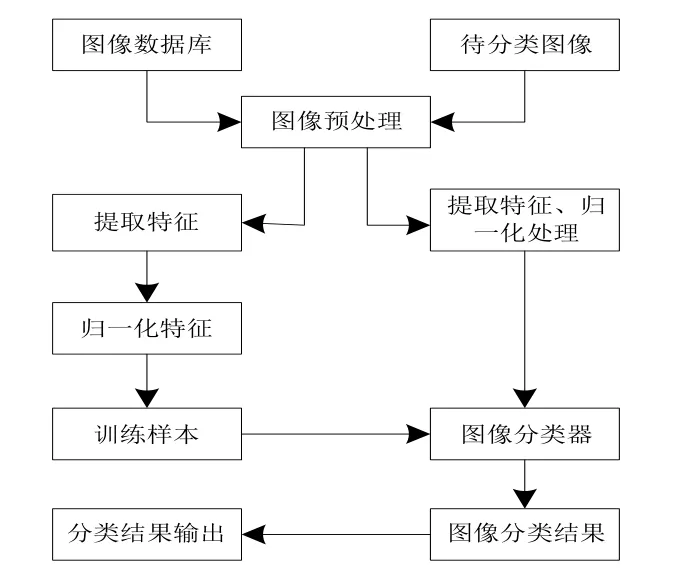
圖1 云計算技術圖像分類原理
利用圖像分類器將圖像特征數據樣本進行訓練,并將訓練后的結果存儲于本地文件中,用于圖像分類。分類器主要運行步驟如下所述:
(1)通過云平臺上傳海量圖像數據信息,上傳完成提交后,從分布式文件系統中獲取數據源,通過數據集群配置劃分數據,并分類處理上傳的Reduce和Map,并輸入Reduce和Map過程中的節點信息。
(2)操作時,讀入儲存在分布式文件系統中圖像樣本的同時,使用遺傳算法優化數據樣本參數類型轉換后的組合參數,完成svm—train函數的調入。為獲取支持向量,需完成樣本數據的訓練,并將處理結果輸入在Reduce中。
(3)實現Reduce的操作過程,采用數據形式key/value完成分類和排序Map函數的轉換,向實現規定的路徑文件中輸入處理后的數據,輸出圖像分類結果。
(二)基于Zernike矩陣的圖像比對。
1.比對算法流程。采用Zernike矩陣完成分類圖像比對,步驟為:
(1)由于圖像旋轉后可能存在偽邊塊,為將其去除,需要先完成兩幅對比圖像(圖像A和B)的偽邊塊檢測,確定兩幅圖像的區域和大小,將偽邊塊去除后,保存圖像區域的有效內容[6],即為A1和B1。
(2)采用插值法對B1實行圖像歸一化處理,使B1和A1的大小相同,得出B2。
(3)將A1旋轉,旋轉次數為s,每次旋轉角度為360/s,計算A1每次旋轉結束后的第T個Zernike矩,并且T≥2,根據計算得出的數值構建S*T矩陣,其為:
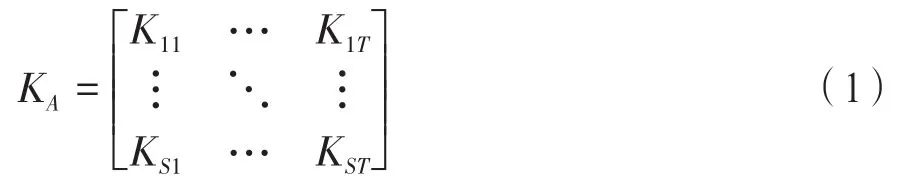
(4)對矩陣KA的每一列進行均值和標準差的計算,獲取均值向量和標準差向量,分別為其中:
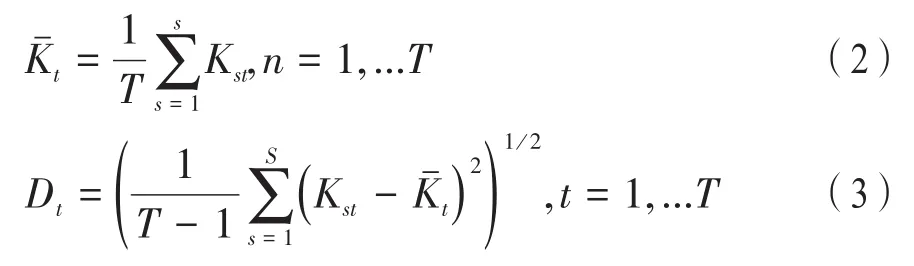
(5)無需對B2進行旋轉,對A1相對應的T個Zernike矩進行計算,得出矩值向量VB。
其具體流程如圖2所示。
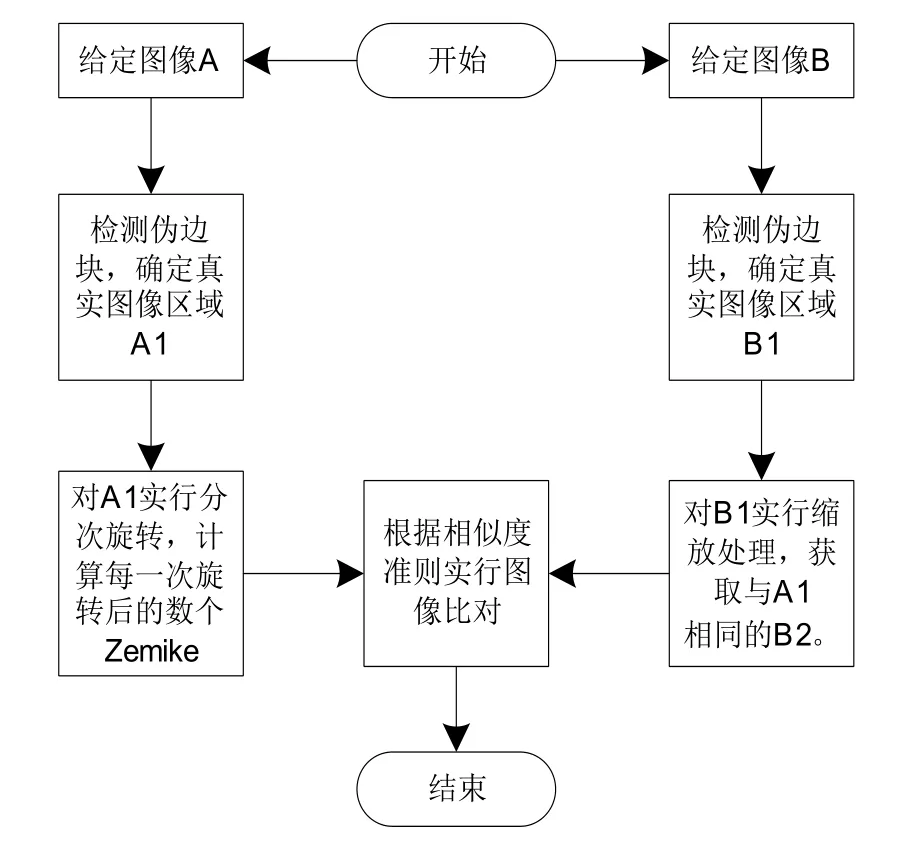
圖2 算法比對流程
2.真實圖像區域大小的確定。由于圖像旋轉后四周會出現偽邊塊,通常情況下偽邊塊的區域呈現黑色、白色或者是其他的單一灰度區域[7]。為了解決偽邊塊對Zernike矩值造成的影響,需對所有偽邊塊實行區分。對圖像靠近四條邊沿位置的像素值進行掃描后,統計像素值的出現概率。如果某個像素值出現比例較大,判斷該像素值在旋轉后形成偽邊塊像素值,將該像素值的臨近四條邊沿的連通圖像區域判斷為偽邊塊。為確定真實圖像的實際大小,從而保障后續的圖像大小歸一化,則處理步驟如下:
(1)為將圖像轉化為黑白圖像,根據圖像像素值采取二值化方式完成圖像處理。偽邊塊區域作為單獨一類,其余區域歸為另一類,均判斷為真實圖像。
(2)對二值化后的黑白圖像實行邊緣檢測以及其中存在的直線進行檢測,將圖像中相交后可構成矩形的四條直線看作真實圖像的邊界。
(3)確定由四條直線相交構成的矩形,將其看作為真實圖像區域,并依據四個直線交點坐標,確定真實圖像大小。
3.歸一化相似度準則。真實圖像之間的相似程度通過相似度準則進行衡量,其取值范圍在[0,1]之間。當Zernike矩的階數較高時,計算結果與較低階的矩值存在很大差別,甚至存在數個數量級的差別。為保證每一個Zernike矩陣作用的統一和均衡,對VB實行歸一化處理,獲取,其中:

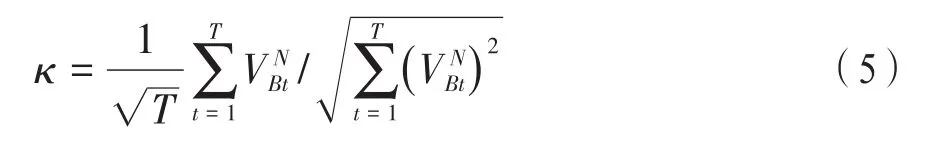
如果獲取的相似度κ值大于設定的閾值,則表示兩幅圖像的內容相同,反之,則不相同。根據相似結果判斷圖像重復情況,完成圖像查重。對和VB的相似度進行計算,如果已經經過歸一化處理,并且成為一個全1向量,則兩幅圖像相似度為:
二、仿真測試結果與分析
選取某圖像庫作為研究對象,展開相關測試分析。該圖像庫共有圖像數量82000張,重復圖像共10087張。其中主要分為風景類圖像14600張,重復圖像4220張;建筑類圖像12800,人物類圖像3020張;文字文本類圖像18400張,重復圖像1120張;動物類圖像11200,重復圖像728張;玩具類圖像25000張,重復圖像999張。
(一)分類性能測試。測試本文算法的圖像分類性能,從節點數量對圖像識別時間的影響和圖像分類精度兩個方面完成測試,測試結果如表1、表2所示。分析表1可知:本文算法進行圖像識別過程中,如果云計算平臺上只有2個節點時,玩具類圖像數據交換所需時間較長,該現象表明針對圖像識別,兩臺計算機所需時間較大程度大于1臺計算機識別所需時間。當節點數量為3個以上時,隨著節點數量的增加,處理相同數量圖像所需的時間逐漸減少。該測試結果表明,節點數量的增加,會增加圖像分類的速度,可根據需要分類的圖像數量,選擇適合的節點數量。

表1 不同節點數量下圖像識別時間/ms
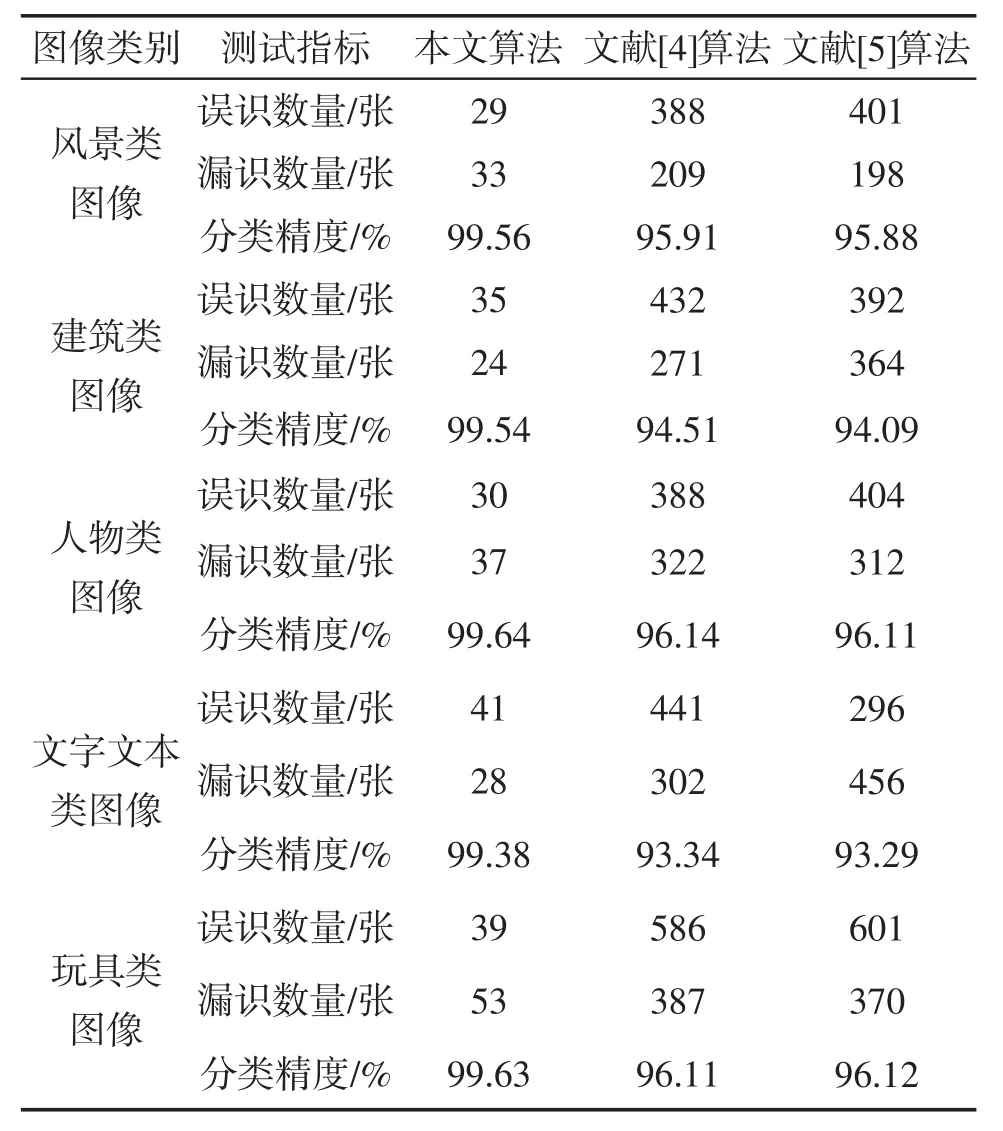
表2 三種算法的分類精度對比
從表2可知:對于五類圖像,本文算法的分類精度最佳,分類精度均在99%以上對比算法的漏識和誤識數量高于本文算法,它的分類精度低,這主要是因為本文算法采用云計算技術從通過分布式文件系統中獲取海量圖像數據源,通過數據集群配置劃分處理數據,保證圖像分類結果的精度。
(二)查重性能測試。為進一步測試本文算法查重性能,隨機抽取人物類圖像的一組圖像,如圖3所示。其中(a)圖為原始給定圖像,經其縮放60%后,進行逆時針旋轉,得出(b)圖,此時兩幅圖像內容相同,但是數據本身存在較大差別。選取4階Zernike矩(共包含9個Zernike矩值),對(a)圖進行旋轉,每次旋轉角度為20°,獲取(a)圖的Zernike矩值、標準差數值和(b)圖的Zernike矩值、歸一化后的數值,分別如表3、表4所示。分析表3可知:表中包含圖3(a)圖均值以及標準差的數值,相比較均值而言,可看出標準差相對很小,說明Zernike矩在進行圖像不同角度旋轉時,大小保持相對穩定,表示本文算法具備較好的旋轉不變性。

圖3 實驗使用的圖像
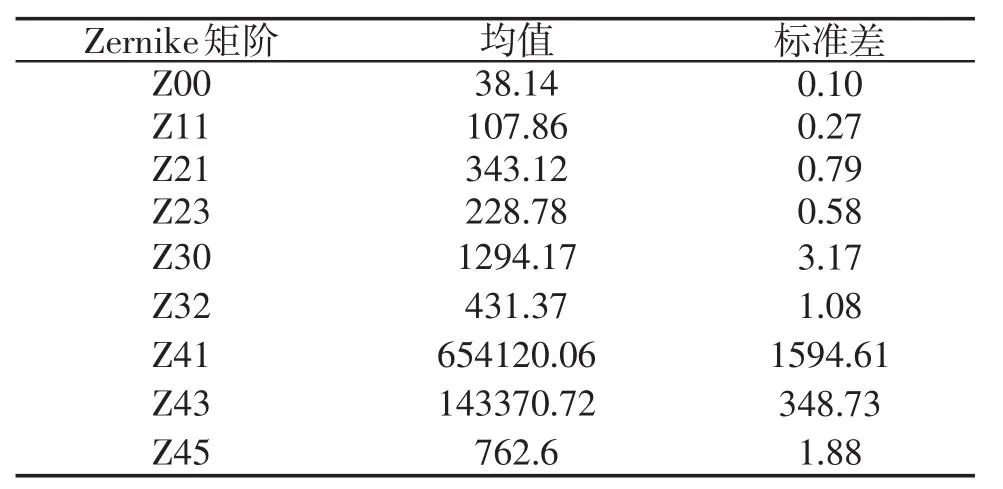
表3 (a)圖的均值和標準
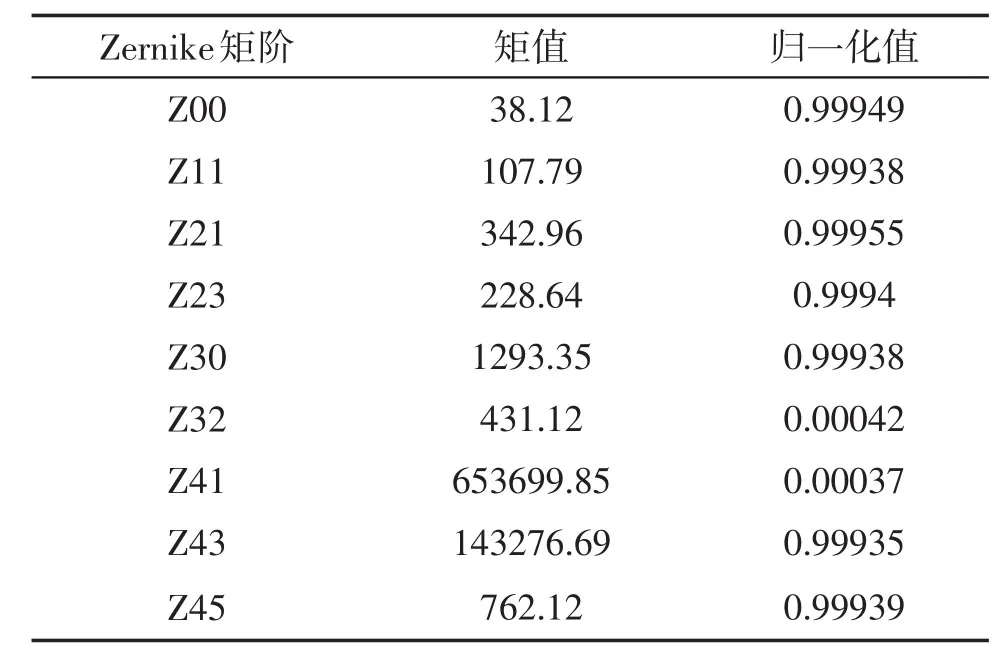
表4 (b)圖的矩值和歸一化值
分析表4可知:將獲取的矩值通過公式(5)進行計算,獲取相似度值。相似度值越高說明兩幅圖像內容相同,表明兩幅圖像重復。說明本文方法具備圖像查重能力,可完成海量圖像的查重。差
圖像查重可理解為將重復圖像聚集到相同的簇,因此,查重效果的衡量公式為:
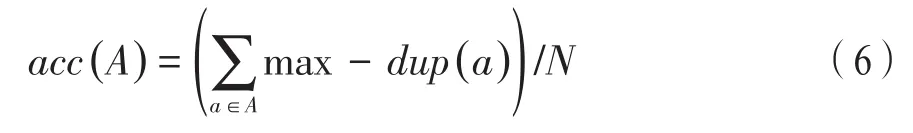
式中:A為圖片重復檢測的結果集合,其元素為檢測到的重復圖像,a中最大的真實重復圖像數量為max-dup函數;如果a=[1,1,2,2,2,3,3],則max-dup(a)=3,表示2的個數為a中出現最多的元素數量,acc表示查重聚類純度。
以人物圖像數據集為例,采用三種算法對其進行相似度查詢,測試三種算法在相似度閾值變化的情況下,acc的變化結果如圖4所示。分析圖4可知:本文算法在相似度閾值變化的情況下,acc值高于兩種對比算法那,明本文算法進行圖像查重的圖像相似度查重效果最佳。兩種對比算法的acc值相對較低,由于閾值的變化導致大量圖像被錯誤地檢測為重復。本文方法具備較好的分類性能,可將相同類別的圖像劃分為一個集合,極大程度降低了圖像相似度檢測的錯誤數量,保證圖像相似度檢測的精度。并且根據圖中曲線變化,結合閾值的固定的范圍可以看出,本文算法在相似度閾值為0.8~0.9范圍內,acc精度最高。
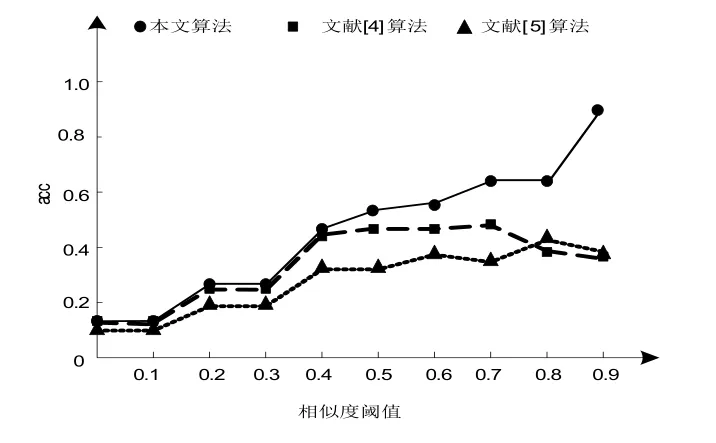
圖4 不同算法acc變化結果
三、結論
為了實現海量圖像內容查重,設計了云計算環境下的海量圖像查重算法,測試結果表明:云計算技術的節點數量對于海量圖像分類存在影響,可根據圖像數量適當選擇合適的節點;針對五種類型圖像,本文算法的分類精度高,為后續圖像高精度查重奠定了可靠基礎;本文算法具備較好的旋轉不變性,可有效完成圖像查重。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
