基于改進的BERT-CNN模型的新聞文本分類研究
2021-09-08 10:10:32張小為邵劍飛
電視技術 2021年7期
張小為,邵劍飛
(昆明理工大學 信息工程與自動化學院,云南 昆明 650031)
0 引 言
互聯網上的數字文本日益增多,從應用程序到擁有數百萬數據的網站,都存在大量計算機難以甄別的文本數據。由于數據量大且文本語義錯綜復雜,導致文本分類成為一項難題。因此,如何使計算機對大量文本數據進行分類,正成為研究者感興趣的話題。一般來說,文本分類任務只有很少的類。當分類任務有大量的類時,傳統的循環神經網絡(Rerrent Neural Network,RNN)[1](如 LSTM 和GRU)算法準確率表現不佳,因此本文引用谷歌大腦發布的基于transformer的來自變換器的雙向編碼器表征量(Bidirectional Encoder Representations from Transformers,BERT)[2]模型來對中文新聞文本進行分類,數據集采用新浪新聞RSS訂閱頻道2005年至2011年間的歷史數據篩選過濾生成的THUCNews中文文本分類數據集,共有金融、房產、股票、教育、科技、社會、時政、體育、游戲及娛樂10個類別。
1 相關研究
深度神經網絡由于其強大的表達能力和較少的實用技術要求,正成為文本分類的常用任務。盡管神經文本識別模型很有吸引力,但在許多應用中,神經文本識別模型缺乏訓練數據。近年來,人們提出了多種中文文本分類方法。由于中文文本本身的特點,與英語等其他語言相比,中文文本分類比較困難。為了提高中文文本分類的質量,Liu等人[3]提出了一種分層模型結構,可以從中文文本中按順序提取上下文和信息,這種方法是LSTM和時間卷積網絡的組合。而LSTM用于提取文檔的上下文和序列特征。Shao等人[4]提出了一種大規模多標簽文本分類的新方法。首先將文本轉換為圖形結構,然后使用注意機制來表示文本的全部功能。他們還使用卷積神經網絡進行特征提取。與最新的方法相比,該方法顯示了良好的結果,并且使用了4個數據集進行實驗。在CRTEXT數據集上進行的結果表明,與其他數據集相比,他們的模型取得了最好的結果。本文利用BERT自注意力的優點,將BERT當做embedding[5]層接入到其他主流模型,并在同一個新聞數據集進行訓練和驗證。最后將各個模型與BERT拼接的模型進行比較。
2 研究方法
2.1 BERT
2.1.1 BERT的基礎架構
BERT使用的是transformer的encoder的部分,是由多個encoder堆疊在一起的。6個encoder組成編碼端,6個decoder組成解碼端。一個encoder具有輸入、注意力機制以及前饋神經網絡3個部分。BERT的基礎結構如圖1所示。
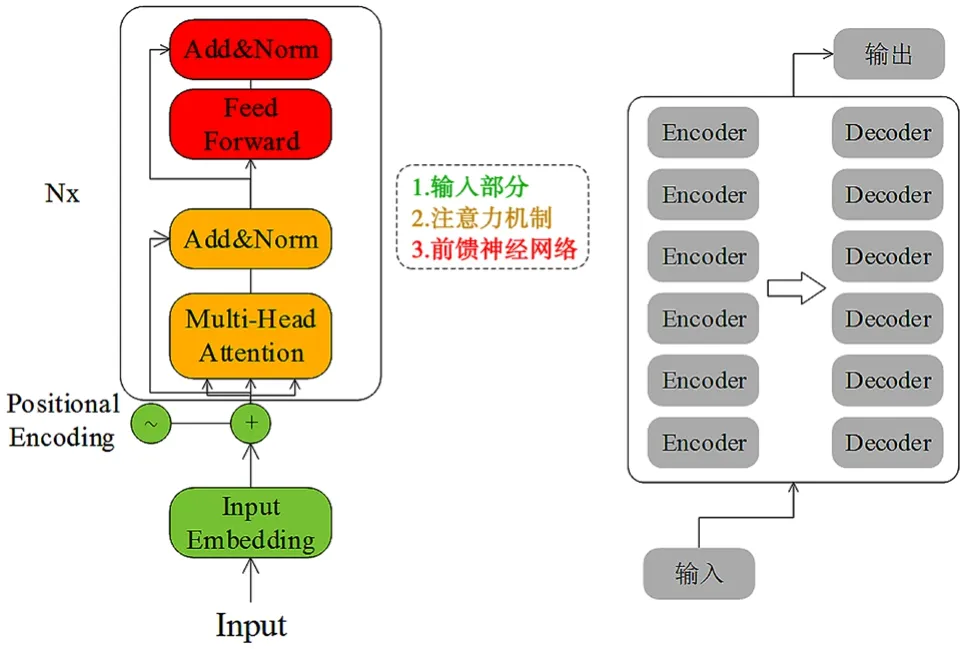
圖1 BERT的基礎結構
BERT編碼器需要一個token序列。處理和轉換token的過程如圖2所示。[CLS]是插入在第一句開頭的特殊標記。[SEP]插入在每個句子的末尾。通過添加“A”或“B”區分句子來創建embedding。另一方面,還在序列中添加每個標記的位置來進行位置嵌入。
圖2中,3個embedding的總和就是BERT編碼器的最終輸入。當一個輸入序列輸入到BERT時,它會一直向上移動堆棧。在每一個塊中,它會首先通過一個自我注意層再到一個前饋神經網絡之后再被傳遞到下一個編碼器。最后,每個位置將輸出一個大小為hidden_size(BERT_Base=768)的向量。
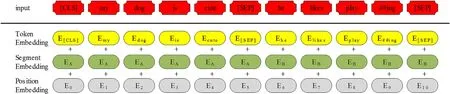
圖2 token轉換過程
2.1.2 掩碼語言模型(Masked Language Model,MLM)
在新聞文本序列中,通過標記[MASK]來替換它們隨機屏蔽一定百分比的單詞。在本文中屏蔽了15%的輸入詞,然后訓練剩下的輸入詞,最后讓解碼器來預測被屏蔽的輸入詞。例如:
調查顯示:29.5%的人不滿意當年所選高考專業
調查顯示:29.5%的人不滿意當年所選[MASK]專業
這里的一個問題是預訓練模型將會有15%的掩碼標記,但是當微調預訓練模型并傳遞輸入時,不會傳遞掩碼標記。為了解決這個問題,將用于屏蔽的15%的token中的80%替換為token[MASK],然后將10%的時間token替換為隨機token,其余的保持不變。
由于BERT在預訓練的時候使用的是大量無標注的語料,因此要使用無監督(無標簽)的方法,本文采用的無監督目標函數是AE自編碼模型。它可以從損壞的輸入數據進行預測并重建原始數據,也就是利用上下文信息的特點來進行重組。另外一種無監督目標函數是AR自回歸模型。下面從一個句子(我喜歡小狗)來比較兩種無監督模型。
AR:

由式(1)可知,AR自回歸模型只用到了文本的單側信息,且依賴于兩個相鄰詞的依賴關系。
AE:

由式(2)可知,AE用mask掩蓋掉某些詞,優化目標是:在“我mask小狗”的條件下出現“我喜歡小狗”的概率,而這個概率等于在“我小狗”的條件下,mask=“喜歡”的概率,據此預測出mask的詞。對比AR自回歸模型,AE自編碼模型的優點很明顯:充分利用了上下文詞與詞的關系而不依賴于相鄰的兩個詞的關系。因此本文BERT采用AE自編碼模型。
2.1.3 NSP(下一個句子預測)
在BERT訓練過程中,模型接收成對的句子作為輸入,并學習預測成對中的第二個句子是否是原始文檔中的后續句子。在訓練期間,50%的輸入是一對,其中第二個句子是原始文檔中的后續句子,而另外50%的輸入是從語料庫中隨機選擇的一個句子作為第二個句子。為了幫助模型區分訓練中的兩個句子(正樣本和負樣本),輸入在進入模型之前先按以下方式處理。
(1)在第一個句子的開頭插入一個[CLS]標記,在每個句子的末尾插入一個[SEP]標記。
(2)將表示句子A或句子B的sentenceembedding添加到每個token中。
(3)將Positional embedding[6]添加到每個embedding以表示其在序列中的位置。
為了預測第二個句子是否確實與第一個句子相關聯,按照以下步驟進行預測。
(1)整個輸入序列經過Transformer模型。
(2)[CLS]標記的輸出使用簡單的分類層(權重和偏差的學習矩陣)轉換為2×1形狀的向量。
(3)用softmax[7]計算IsNextSequence的概率。
在訓練BERT模型時,MLM和NSP是一起訓練的,目標是最小化兩種策略的組合損失函數。
2.2 TextCNN
CNN首次被提出是被用在圖像處理上的,而后YoonKim提出的用于句子分類的卷積神經網絡使得其對于句子分類更加有效。TextCNN[8]模型主要使用一維的卷積核以及時序最大池化層。如果輸入的新聞文本序列由k個詞組成,而每個詞的詞向量為n維,那么輸入的樣本寬度等于輸入的句子序列詞個數k,高為1,輸入的通道數等于每個詞的詞向量n。以下是TextCNN的主要計算步驟。
(1)先定義多個一維的卷積核,再通過這些卷積核對輸入分別進行卷積計算。不同寬度的卷積核會得到個數不同的相鄰詞之間的相關性[9]。
(2)對所有輸出部分的通道一一進行時序最大池化操作,再將池化后的結果連接為向量。
(3)使用全連接層將第2步連接好的向量變換為有關各個標簽(本文使用的數據集標簽一共有10個)的輸出。為了防止出現過擬合,本文還在這一步驟使用了丟棄層[10]。
下面用一個例子解釋TextCNN的原理。采用本文所用的數據集中的一個樣本:“某公司收費遭投訴引關注,用戶抱怨賬單不明”,分詞結果為“某公司收費遭投訴引關注用戶抱怨賬單不明”,詞數為11,每個詞的詞向量設置為6。因此輸入的序列寬度為11,輸出的通道數為6。然后設置2個一維的卷積核,卷積核尺寸為2*4,設置輸出通道分別為5和4。因此,經過一維卷積核計算后,5個輸出通道的寬為11-4+1=8,4個輸出通道的寬為11-2+1=10。接著對各個通道進行時序最大池化操作,并將9個池化后的輸出連接成一個9維的向量。最后,通過全連接層將9維向量轉化為10維輸出,也就是新聞文本類別的標簽個數。具體過程如圖3所示。
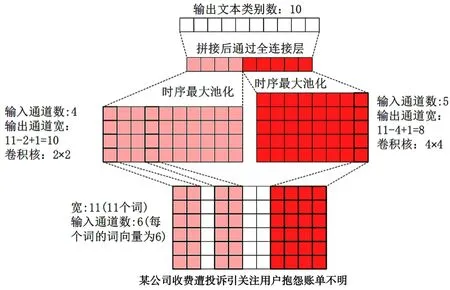
圖3 TextCNN原理
3 實驗與結果
3.1 實驗數據集
在監督學習中,模型的性能主要依賴于數據集。神經網絡的學習也依賴于數據集,如果數據集的數量較少,學習就會不足。為了為模型訓練和模型結果評估提供合適的數據集,本文使用一個名為THUCNews的大型新聞語料庫。這個數據集主要爬取2005-2011年間新浪新聞的RSS訂閱頻道新聞標題,一共有74萬篇新聞文檔(2.19 GB),均為UTF-8純文本格式。該語料庫已在Github上公開。本文主要抽取其中的20萬條新聞標題,一共有10個類別:金融、房產、股票、教育、科技、社會、時政、體育、游戲及娛樂。每個類別有2萬條,平均文本字符長度為20~30。采用其中的18萬條作為訓練集,1萬條用來做驗證集,剩下的1萬條做測試集。
3.2 實驗環境設置
本實驗采用的計算機處理器為AMD R5 3600六核十二線程CPU,顯卡為NVIDIA GTX 1060(6 GB),基于python3.8,深度學習框架主要用的是pytorch1.9.0+cu102 GPU版本,運行內存16 GB。由于顯存容量限制,batch_size設置為16,Epoch設置為3。編程軟件使用的是pycharm社區版。
本次實驗采用的是BERT在Github的公開開源版本,并通過新聞數據集的特點微調BERT,以提升BERT的下游任務的效果。然后將BERT作為embedding輸入到CNN、RNN模型,最后進行BERT、BERT-CNN、BERT-RNN的效果對比。
3.3 評價指標
為了評估各個模型的性能,本實驗使用“提前停止(earlystopping)”技術(一旦訓練效果停止改善,立即自動停止訓練過程),這可以更好地避免過擬合問題。主要采用3種常用的評估指標:Precision精準率、Recall召回率以及F1。最后使用測試準確率Test_accuracy進行比較。3種指標的計算方法為:

式中:TP表示預測10個標簽(0~9)當中的指定標簽被正確預測的個數;FP表示預測為指定標簽但實際上是其他標簽的個數;FN表示預測為其他標簽但實際上是指定標簽的個數。
3.4 實驗結果與分析
3.4.1 實驗結果
BERT、BERT-CNN、BERT-RNN的試驗結果分別如表1、表2及表3所示。平均Test_accuracy實驗結果如表4所示。3個模型在1萬條測試數據中的表現如圖4所示。
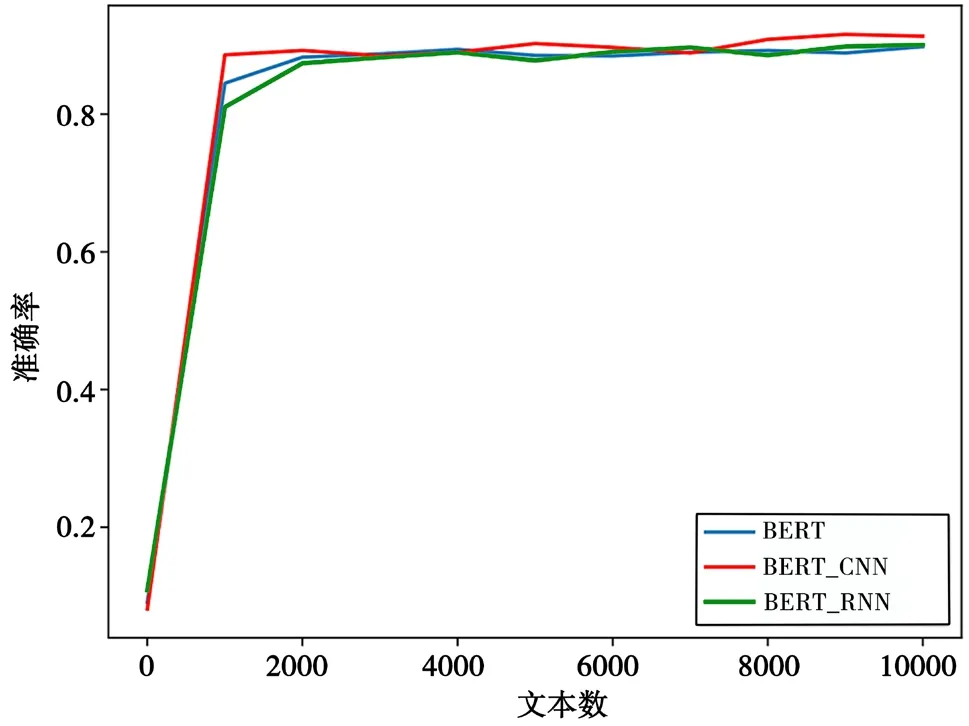
圖4 3個模型在1萬條測試數據中的表現
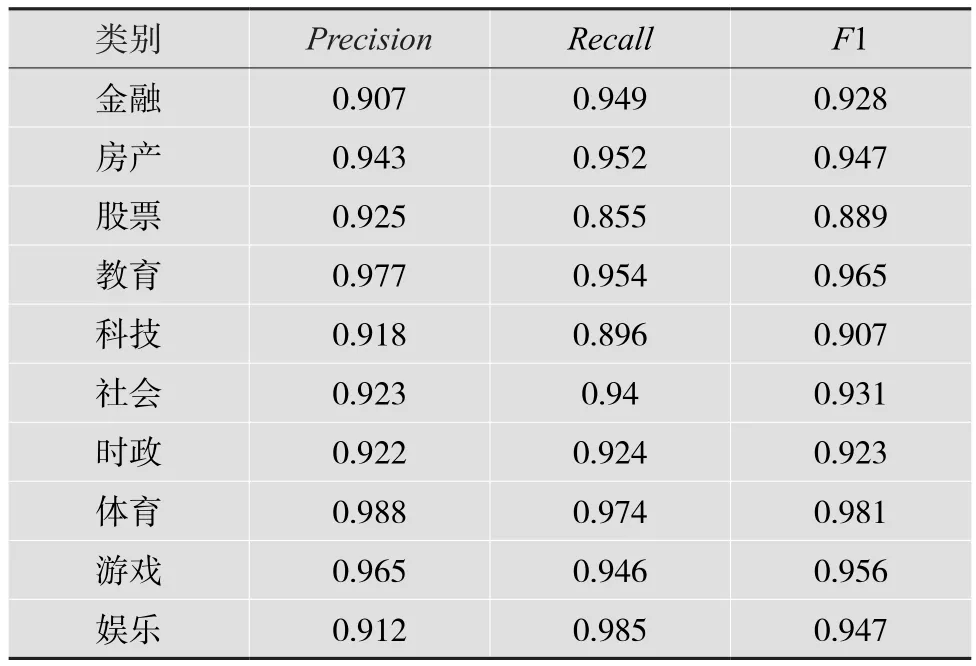
表1 BERT實驗結果
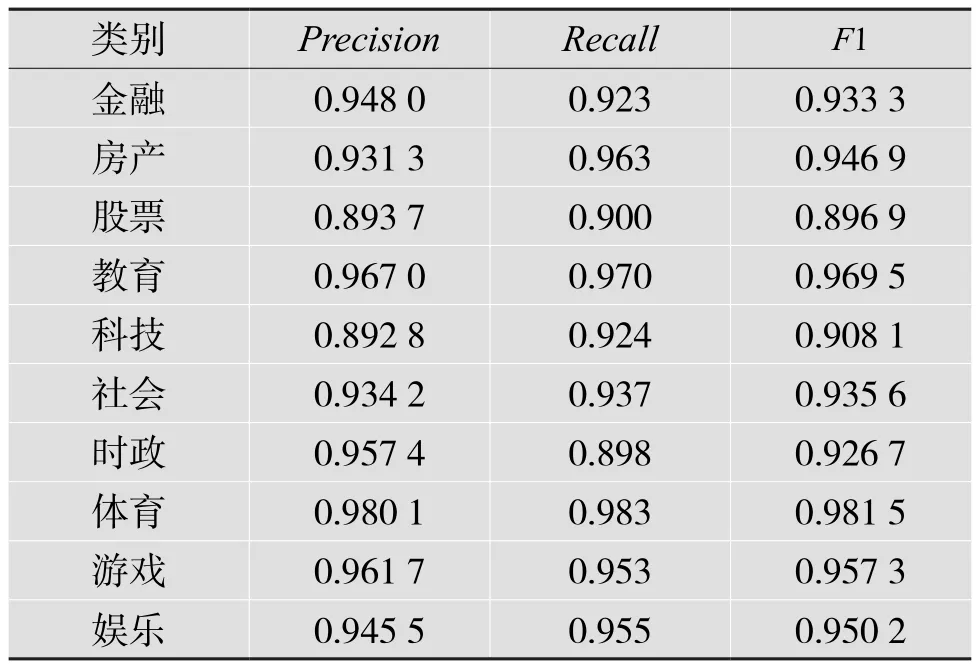
表2 BERT-CNN實驗結果

表3 BERT-RNN實驗結果
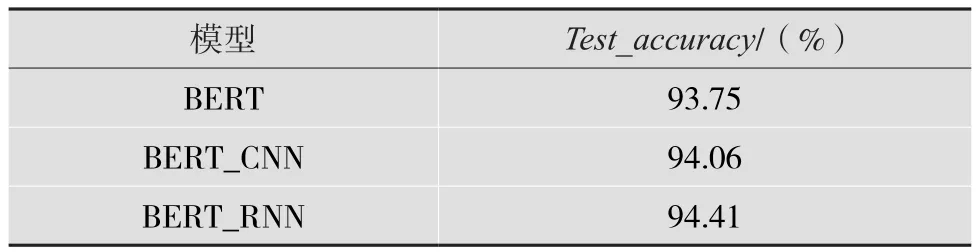
表4 平均Test_accuracy實驗結果
3.4.2 結果分析
從表1、2、3可以得出:識別的標簽不同,各個模型的評價體系得分也不同。10個標簽共30個評分項,BERT-CNN一共有17個得分最高項,BERT有8個得分最高項,BERT-RNN有5個得分最高項。其中,BERT-CNN所有標簽平均得分為0.941,BERT所有標簽平均得分為0.938,BERT-RNN所有標簽平均得分為0.936。可見BERT-CNN表現最佳。
從表4和圖4可以看出,BERT-CNN無論是在平均測試準確率還是測試準確率的表現都要優于BERT和BERT-RNN。
實驗結果證明,本文提出的基于改進的BERTCNN模型在新聞文本測試的表現,測試精度94.06%比原來的BERT模型高出了0.31%,且更為穩定。
4 結 語
本文的模型主要運用于文本的多分類場景中,未來可以嘗試在電影影評進行分類(二分類,積極或消極),各個模型的表現可能會不盡相同,且在相同條件下可以考慮運行時間的長短,將其添加進模型的評級體系。
目前在文本分類問題中,通過各大閱讀理解競賽榜單可以看到,深度學習的成績已經超過人類閱讀理解的能力,但是各個模型量都過于龐大,訓練周期時間長,且對硬件的限制較大。希望未來研究者能夠提出一種輕量級的、能夠運用于各個文本分類器的語言模型。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
