基于二維Winograd算法的深流水線5×5卷積方法
2021-09-09 08:09:20黃程程董霄霄
計算機應用 2021年8期
黃程程,董霄霄,李 釗
(山東理工大學計算機科學與技術學院,山東淄博255049)
0 引言
卷積神經網絡在圖像分類、語音識別、目標檢測等應用中取得了重大進展[1-3]。其中5×5卷積相較3×3卷積有更大的感受野,可以提取更多的邊緣特征,在醫學影像處理等領域效果顯著,且廣泛應用于AlexNet、ZFNet和GoogLeNet等經典模型[1]。近期的許多研究就使用包含5×5卷積的架構取得了較3×3卷積更高的預測準確率[4-6]。
卷積神經網絡模型規模龐大,計算復雜度高,需要占用大量硬件資源,因此硬件加速器逐漸被用于加速神經網絡的預測階段。常用的神經網絡加速器包括圖形處理器(Graphic Processing Units,GPU)、專用集成電路(Application Specific Integrated Circuit,ASIC)和現場可編程邏輯門陣列(Field Programmable Gate Array,FPGA)。得益于高并行度、低能耗和可重構等優點,FPGA成為了目前主流的卷積神經網絡硬件加速平臺[7-16]。
目前在FPGA上加速卷積神經網絡面臨的問題有:1)卷積神經網絡的大規模密集型計算受到FPGA計算能力(片上數字信號處理器(Digital Signal Processor,DSP)數目)的限制,如何優化算法以降低乘法運算量是提升加速器系統性能的主要問題。2)各類快速算法在降低卷積神經網絡乘法運算量的同時通常以提升內存資源占用和存儲器帶寬占用為代價,FPGA片上硬件資源量的限制將影響加速器系統性能。3)卷積神經網絡計算量龐大,高效的數據重用能夠降低能耗開銷并減小設計面積。
在5×5卷積的乘法運算量方面,文獻[7]使用8 bit定點數據量化模型,在2個8 bit權重中插入1個8位的全0數據,組成一個低8位和高8位分別為權重數據、中8位為全0字段的24位新數據,使用1個DSP得出2次乘法運算結果,將傳統卷積算法的乘法運算量降低至50.0%。文獻[8]利用卷積的元素代數性質,應用Winograd快速卷積算法,將使用小尺寸卷積的VGGNet(Visual Geometry Group Network)等模型的乘法運算量降低至45.0%,有效提高了硬件加速器的效率。文獻[9]基于二維快速傅里葉變換(Fast Fourier Transform,FFT)算法提出了一種靈活的自動化設計高通量模型加速器,將乘法運算量降低至約31.0%。文獻[10]采用n=6的二維Winograd算法,級聯3×3卷積構建5×5卷積,將乘法運算量降低至約19.4%。然而二維Winograd算法不同于傳統卷積算法,使用級聯3×3卷積的方法構建5×5卷積將增加乘法運算量、系統的存儲器帶寬需求,級聯的卷積層間也存在計算延遲,同時也會增加設計空間探索周期。在硬件資源占用方面,文獻[11]和文獻[10]分別提出了基于列或行的二維Winograd卷積算法雙緩沖區數據布局方案,降低了存儲器帶寬需求。然而文獻[10]的研究結果表明,他們所設計的加速器存儲器帶寬占用比例略高于片上DSP占用比例,這意味著受制于有限的FPGA硬件資源,部分情況下其設計無法達到理論的最高性能。在數據重用方面,文獻[12]提出了一種基于深流水線體系架構的二維/三維Winograd卷積算法加速器設計,通過層融合和層聚類等方法,顯著提高了數據重用性。文獻[11]和文獻[10]通過雙緩沖區數據布局方案重用了二維W inograd算法鄰域間的重疊數據。但二維Winograd算法轉換過程大量的加法運算中存在可復用的中間結果,這些可復用結果的加法運算屬于無效運算,僅會增加加速器系統的能耗開銷和設計面積,上述文獻并未就此問題進行研究和優化。
針對上述方法中計算復雜度高、存儲器帶寬需求高、級聯的卷積層間存在計算延遲、設計空間探索周期漫長和加法計算量大等問題,提出了一種基于二維Winograd算法的雙緩沖區5×5卷積6級流水線方法。首先選用適宜尺寸的二維Winograd卷積算法降低計算復雜度和存儲器帶寬需求,然后通過雙緩沖區最小塊單元的設定指導并加快設計空間探索,增強可移植性,平衡FPGA硬件資源的使用,使設計不受任何硬件資源限制。最后通過深化二維Winograd卷積算法流水線,復用加法運算過程中的中間計算結果,來降低加法運算量,減小加速器系統的能耗開銷和設計面積。
1 Winograd算法介紹
1.1 符號說明
表1對文章中使用的重要符號進行說明。
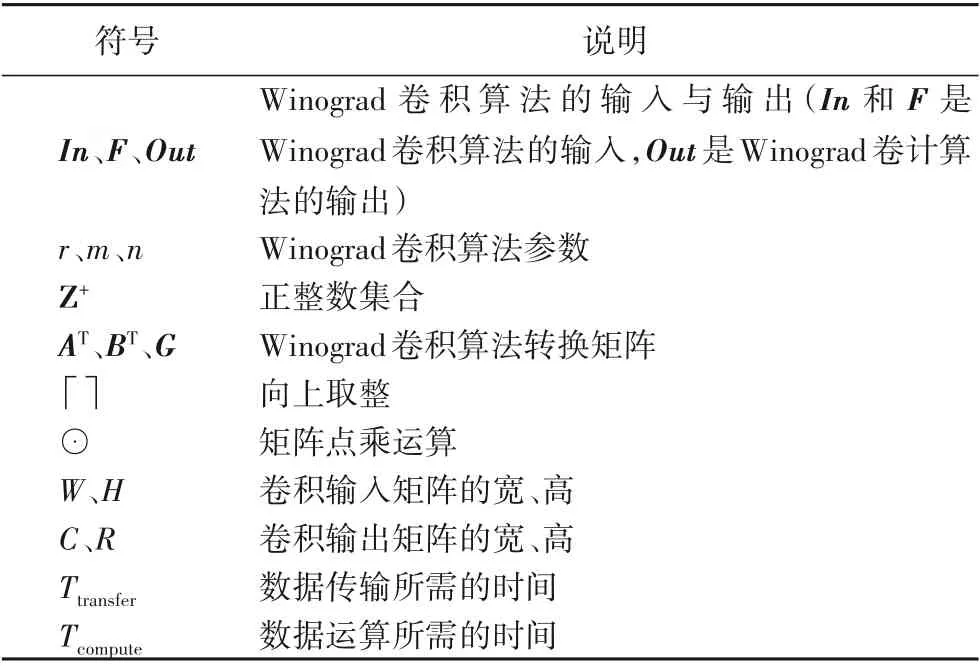
表1 符號說明Tab.1 Explanation of symbols
1.2 一維Winograd算法
Winograd算法于1980年由數學家Winograd提出[17]。以一維Winograd算法為例,記尺寸為r的卷積核輸出m個計算結果為F(m,r)。
傳統卷積算法計算F(2,3)需要2×3=6次乘法。Winograd算法計算F(2,3)僅需要4次乘法,輸入輸出如下:

具體過程如下:
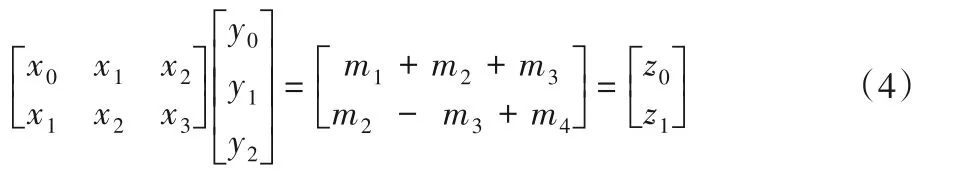
其中m1、m2、m3、m4為:
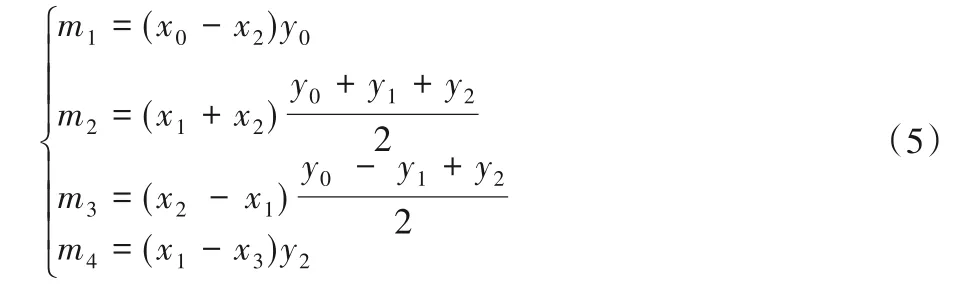
Winograd算法中的常數乘法可以通過移位操作(如2-1、2-2和2)或由2n或2-n(n∈Z+)的組合后再移位(如5=20+22,1/6≈2-3+2-5+2-6)近似得到,因而計算m1、m2、m3、m4只需要4次乘法運算。
上述乘法過程可表示為矩陣相乘形式:

其中Winograd算法F(22,32)的轉換矩陣AT、BT和G表示如下:
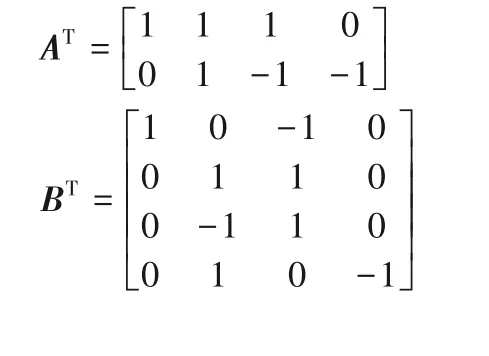

1.3 二維Winograd算法
F(m2,r2)的二維Winograd算法可以通過嵌套迭代一維Winograd算法得到:
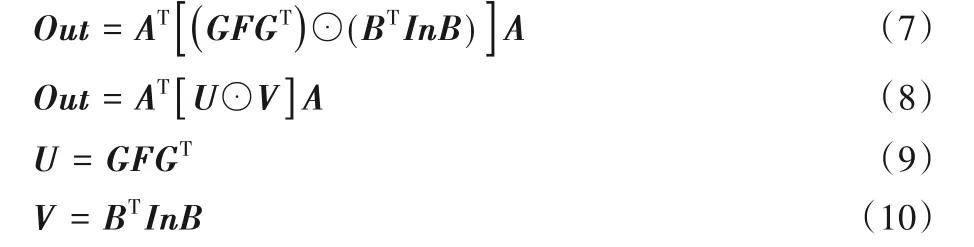
具體運算步驟如下:

記U⊙V結果為out:

隨著壓縮模型理論的提出和應用,現階段的研究大多使用16位定點數據代替浮點數據,以減小計算資源和存儲資源的開銷。文獻[10]研究結果表明,由于轉換矩陣中的常數值范圍會隨參數n的增大而增大,使用16位定點數據時,卷積核的精度不能低于2-10,Winograd算法中參數n(n=m+r-1)不得大于8,否則將影響卷積神經網絡的預測準確率。本文中分別使用多項式插值點(0,1,-1)、(0,1,-1,2,-2)及(0,1,-1,2,-2,1/2,-1/2)計算F(n=3,n=4)、F(n=5,n=6)及F(n=7,n=8)的轉換矩陣AT、BT和G。常數乘法如上所述,通過移位操作或由2n或2-n的組合后再移位實現,使這部分運算不占用DSP資源。
相較于傳統卷積算法,二維Winograd卷積算法的輸出結果不再是輸出特征圖上的單個點,而是多個點組成的輸出特征圖子塊。對一個大小為m2的輸出特征圖子塊,二維Winograd卷積算法需要n2次乘法,而傳統算法需要m2r2次乘法。
2 計算復雜度及帶寬需求的定量分析
2.1 計算復雜度定量分析
由于二維Winograd卷積算法與傳統卷積算法計算原理有差異,這一部分對二維Winograd卷積算法下應用5×5卷積和級聯3×3卷積的計算復雜度進行了定量分析。
在此項工作的定量分析中默認步長為1,當通過卷積后輸出特征圖大小為C×C時,二維Winograd卷積算法乘法運算量為:(■C/■m×n)2。
由于m,n,r均為已知常數,設定C滿足C/m為正整數,不考慮填充問題,可定量分析n≤8時二維Winograd算法下級聯與非級聯方法的計算復雜度。本文采用參數相同的常用F(m2,r2)實現級聯。
使用兩個F(22,32)級聯時乘法運算次數為:
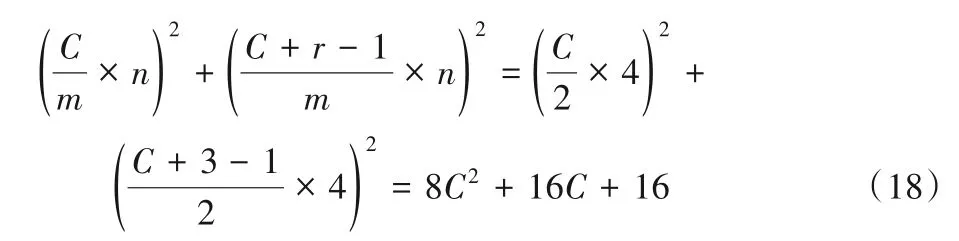
使用兩個F(42,32)級聯時乘法運算次數為:
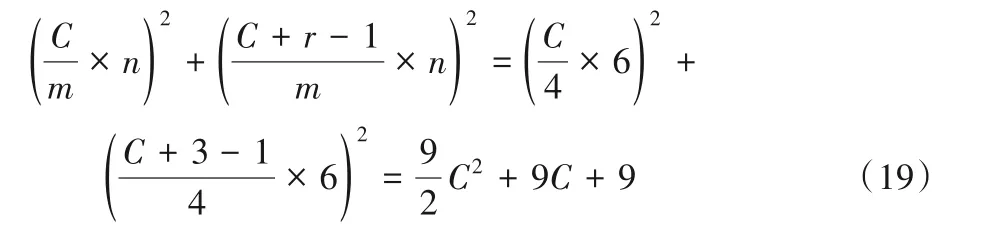
使用兩個F(62,32)級聯時乘法運算次數為:
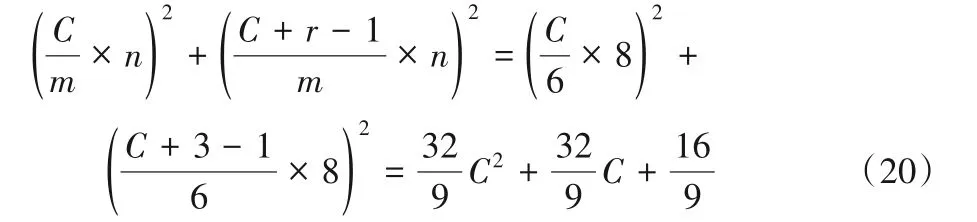
F(22,52)的乘法運算次數為:
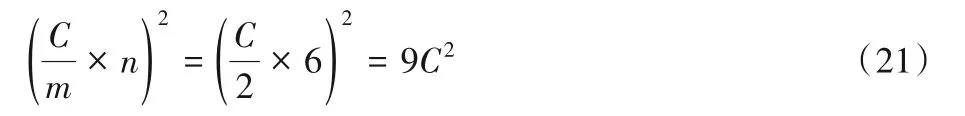
F(42,52)的乘法運算次數為:
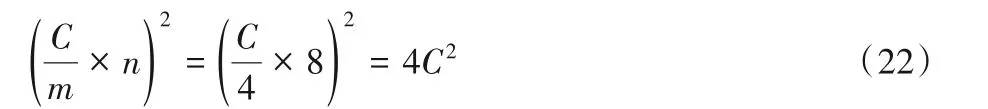
其中應用級聯F(22,32)替代F(22,52)的過程如圖1所示。
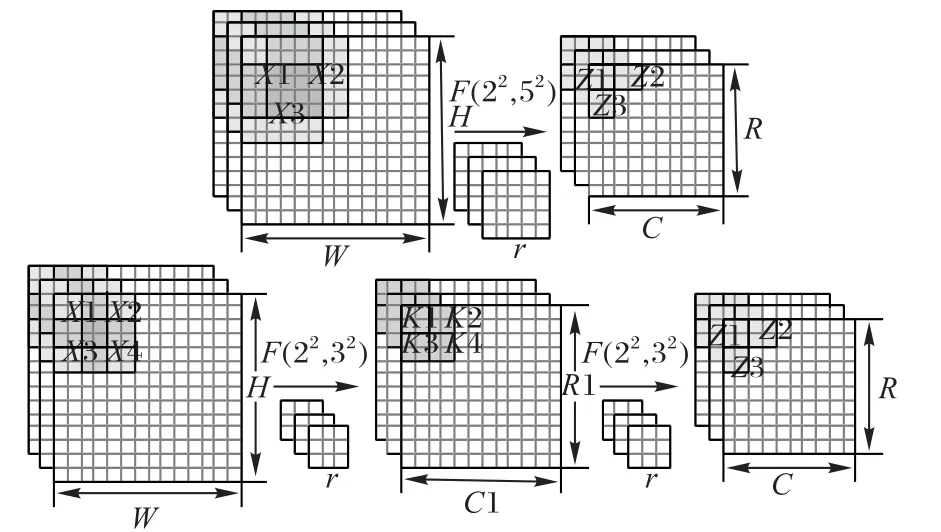
圖1 級聯F(22,32)替代F(22,52)示意圖Fig.1 Schematic diagram of cascading F(22,32)to replace F(22,52)
通過對式(18)~(22)進行對比可以得出:F(42,52)的乘法運算次數是兩個級聯F(22,32)的約49.0%,兩個級聯F(42,32)的約87.1%,兩個級聯F(62,32)的約111.3%。此外,是傳統卷積算法的約17%。
2.2 存儲器帶寬需求分析
為高效地利用硬件資源,數據傳輸速度必須大于或等于計算速度。存儲器帶寬需求越低,數據傳輸速度越快,為系統的準確性和穩定性提供保障。文獻[11]采用基于列的雙緩沖區數據布局完成設計,并未進行設計空間探索。文獻[10]采用基于行的雙緩沖區數據布局完成設計,使用參數組{n,Pm,Pn}指導設計空間探索。其中,n表示F(m2,r2)的尺寸,Pm表示并行運算的輸入圖像的通道數,Pn表示并行運算的卷積核的數目。本文設定參數對{Pc,Px}指導設計空間探索,其中與文獻[10]相較,n=8,Pc=2Pm,Px=Pn。
對存儲器帶寬需求進行建模和定量分析。計算輸入的n列數據所需時間為:

其中:C為輸入圖像通道數,N為卷積核中濾波器數目,Freq為工作頻率。
m列數據并行傳輸所需的時間為:
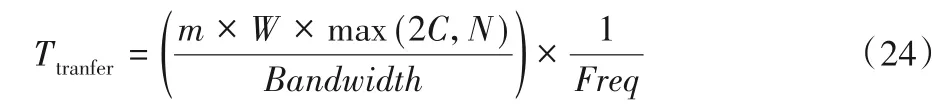
其中Bandwidth為存儲器帶寬。
由于要滿足Ttransfer≤Tcompute,即傳輸時間小于等于計算時間。因此可得存儲器帶寬需求為:
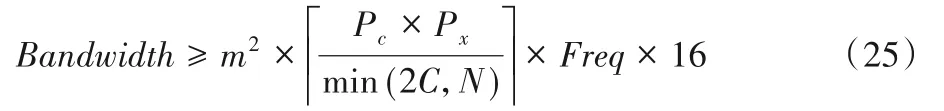
當不采用雙緩沖區設計機制時,n列數據并行傳輸所需的時間為:
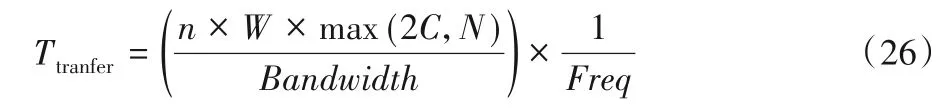
此時的存儲器帶寬需求為:
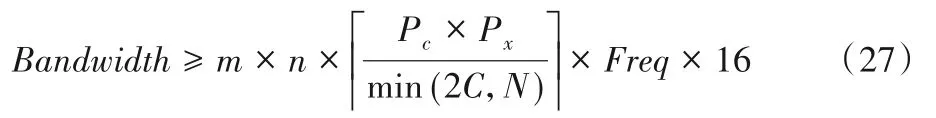
通過對比式(25)和式(27)可得,在理想狀況下,雙緩沖區設計方法可以縮減(1-m/n)倍的存儲器帶寬需求。這意味參數m相同時,卷積核尺寸越大存儲器帶寬需求越低。以F(42,52)、F(42,32)和F(62,32)為 例,三 者 分 別 能 夠 縮 減50.0%(1-4/8)、33.3%(1-4/6)和25.0%(1-6/8)的存儲器帶寬需求。因此F(42,32)和F(62,32)的存儲器帶寬需求約為F(42,52)的1.32倍和1.50倍。本文的設計方法較基于F(42,32)的方法降低了約24.2%的存儲器帶寬需求。而F(62,32)的存儲器帶寬需求最高,無法完成高性能的卷積神經網絡加速器設計。此外存儲器帶寬需求越高,數據重用能力就越差,存儲器訪問也越高,會大幅增加整個硬件加速器系統的能耗。
結合計算復雜度分析進行綜合評定,基于F(42,52)的二維Winograd算法5×5卷積存儲器帶寬需求最低,計算復雜度也低于傳統卷積算法和基于F(22,32)和F(42,32)的設計,且不存在級聯卷積層間的計算延遲。
3 最小塊單元雙緩沖區數據布局方案
由于卷積神經網絡規模龐大,計算過程復雜,且需要保證塊隨機存儲器(Block Random Access Memory,BRAM)使用率和存儲器帶寬使用率均低于或趨近于DSP使用率,使得基于參數組{n,Pm,Pn}的設計空間探索求性能最優解的過程較為漫長。本文的設計將n確定為8,Pc=2Pm,極大地減少了可能的參數組合方式,大幅提高了設計空間探索速度。由于采用了存儲器帶寬需求最低的設計方法,因而僅需在探索過程中求解以BRAM資源為約束條件的性能最優解。
為快速高效完成設計空間探索工作,本文提出了一種雙緩沖區最小塊單元數據布局設計方案,計算和傳輸采用雙緩沖設計并行完成。最初將輸入特征圖和卷積核等輸入數據存儲在外部存儲器中,運算過程中的輸入特征圖和輸出特征圖通過FIFO傳至FPGA平臺。由于片上存儲資源的限制,外部存儲器中存儲的數據將根據運算階段分批次加載到片上存儲器中。之后建立性能評估模型指導設計空間探索求解,對多種參數組合方式進行實驗和數據對比,最終提出本文的設計方案。雙緩沖區最小塊單元設計如圖2所示。首先存儲三個緊鄰的8×4×2(8行、4列、通道數為2)的圖像塊,如圖2中A、B、C所示。其中選擇通道維度的深度為2,既降低了設計空間探索復雜度,也不會對最終性能水平產生影響。每次取相鄰的兩個圖像塊參與二維Winograd算法5×5卷積運算,如AB和BC,每個最小塊單元單個運算周期內執行128次乘法運算。當對AB進行運算后,A中的數據被覆蓋,而后重用B中存儲的數據,對BC進行運算。當完成最初前8行的運算后將自動翻轉至下部分計算的最左端,以此類推向后循環,直至全部運算結束。
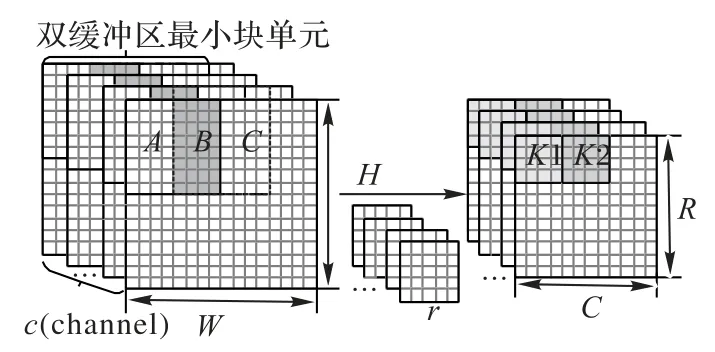
圖2 雙緩沖區最小塊單元設計示意圖Fig.2 Schematic diagram ofdouble-buffer minimum block unit design
通過性能評估模型數據評估得出的雙緩沖區最小塊單元設計,極大地降低了設計空間探索周期,也增強了可移植性。
4 6級流水線設計實現
如式(7)中所示,二維Winograd卷積算法F(42,52)計算需要逐步完成,首先完成U和V的加法計算,而后進行U⊙V的矩陣點乘運算,最后通過加法計算Out輸出結果。根據二維Winograd卷積算法計算過程的這一特性,使用多級流水線設計可以有效降低各計算階段間的延遲。
之前的二維Winograd卷積算法卷積采用4級流水線結構實現[10]。第1階段并行執行U、V的運算,第2階段執行U⊙V的運算,第3階段執行Out的運算,第4階段將各通道計算結果進行累加。這種設計方法在1級流水中完成U、V或Out的計算。在第1階段V的運算過程中,V=BTInB的運算需要等待BTIn全部運算完畢后才能繼續執行下一步與B的運算,使得加法計算過程的延遲可能會大于乘法計算的延遲,導致加速器性能下降。
另一種方法是將In中的元素設為未知參數,離線執行V=BTInB的運算,運算結果中V的元素全部轉換為與In中元素相關的鏈式加法(如F(22,32)中V的首個元素為(x0-x2-x8+x10)),通過這種方式在1級流水中實現V的計算。但由于矩陣乘法的代數性質,該方法需要完成更多次的加法運算。以F(42,52)為例,此方法的加法運算量是逐步運算的近3倍,且部分常數乘法無法再由2n或2-n的組合進行近似。這些加法運算在FPGA中體現為大量觸發器(Flip Flop,FF)和查找表(Look-Up-Table,LUT)的使用。
因此本文啟用深流水線設計,采用逐步運算的6級流水線結構,合理分配硬件資源并減小處理轉換矩陣中常數乘法所帶來的誤差。6級流水線設計結構如圖3所示。對于V,在流水線的第1階段,執行V1=BTIn的運算和存儲,計算過程參考式(13),流水線的第2階段,執行V=V1B的運算和存儲,計算過程參考式(14)。對于U,有兩種實現方式:第一種與V相同,流水線的第1階段,執行U1=GF的運算和存儲,計算過程參考式(11),流水線的第2階段,執行U=U1GT的運算和存儲,計算過程參考式(12)。由于U的運算量始終小于V,這種設計方法不會對流水線的延遲產生影響。第二種是直接離線完成U的運算并加載到FPGA的存儲器中。由于卷積神經網絡預測過程中卷積核權重不發生變化,U可以直接在FPGA外部完成計算。當參數n≤8時,V計算過程中的常數始終可以通過2n或2-n的組合進行精確表示,而U計算過程中會出現諸如1/6等需要進行近似處理的常數,因此這種方法可以在更高的卷積核精度下進行工作。相應地,離線完成U的運算代價是耗費更多的BRAM資源。為保障系統性能,本文選用第一種方法以節省片上BRAM資源。在流水線的第3階段,執行U⊙V的運算并進行存儲。流水線的第4階段,執行Out1=ATout的運算并進行存儲。流水線的第5階段,執行Out=Out1A的運算并進行存儲。流水線的第6階段,將各通道的運算結果進行累加和存儲。
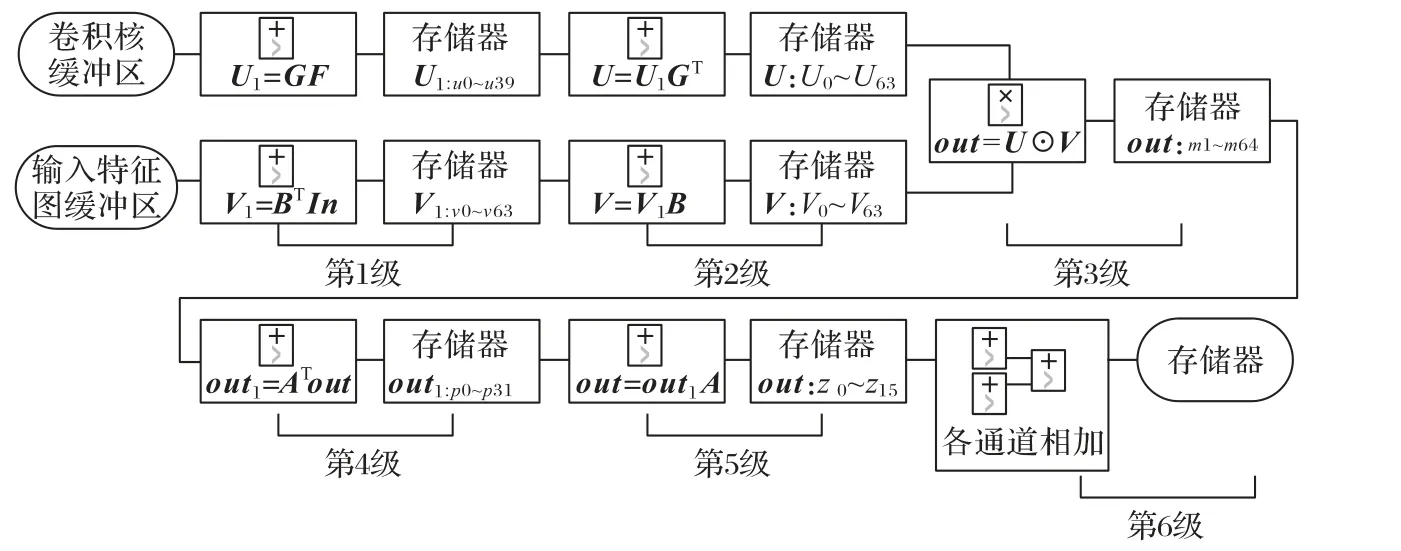
圖3 六級流水線設計結構示意圖Fig.3 Schematic diagram of 6-stage pipeline design structure
5 實驗與結果分析
為驗證針對5×5卷積所提出的雙緩沖區二維Winograd算法6級流水線方法的綜合性能,與現有文獻[7,9-10]的針對5×5卷積的加速器設計方法就硬件資源使用率(設計方法所用的各類硬件資源占片上總資源量的比率)、計算性能和DSP效率等方面進行對比。實驗選用AlexNet的第二個卷積層完成算法設計。為便于比較,采用高速集成電路硬件描述語言(Verilog integrated circuit Hardware Description Language,Verilog HDL)在Xilinx XC7A200T平臺上完成雙緩沖結構設計、加法器和乘法器的流水線設計等。利用Vivado simulator仿真工具建立寄存器轉換級(Register Transfer Level,RTL)仿真模型,時鐘頻率與之前的多項研究工作保持一致,設為200 MHz。卷積神經網絡模型預測過程的剩余部分在FPGA外部完成,確保所設計的算法不影響模型的預測準確率。
5.1 精度損失分析
采用ILSVRC2012數據集對本文所架構的AlexNet進行精度損失分析。訓練數據集中有1 000個不同的類,每個類包含大約1 300個不同的圖像,驗證數據集中有5 000個與訓練數據集不同的樣本。本文采用16 bit定點數據完成量化,采用二維Winograd算法構建AlexNet,并與使用32 bit浮點數的全精度初始模型進行算法精度對比。
如表2所示,本文AlexNet模型的Top-1精度損失不超過0.5%,Top-5精度損失不超過1%,與文獻[7]方法、文獻[9]方法和文獻[10]方法大致相同。其中文獻[9]方法和文獻[10]方法精度損失均<1%,文獻[7]方法由于使用8 bit數據量化因而精度損失略高,約為<3%。

表2 精度損失分析 單位:%Tab.2 Accuracy lossanalysis unit:%
5.2 計算性能分析
乘法運算量是影響卷積神經網絡FPGA加速器實際計算時間的主要因素。本文統計傳統卷積方法、文獻[7]方法、文獻[9]方法、文獻[10]方法和本文方法的AlexNet第二卷積層乘法運算量,并與傳統卷積方法進行加速倍率比較。
由表3可以看出,本文算法5×5卷積的乘法運算量最低,加速倍率最高,為5.82,是其他方法的1.13~2.91倍。
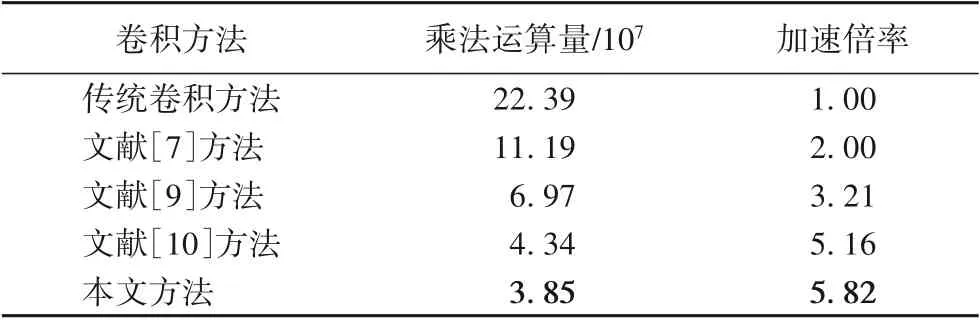
表3 乘法運算量對比Tab.3 Comparison of multiplication computational cost
在各類卷積神經網絡FPGA加速器中,實際運算時間直觀地反映了架構方案的加速水平,是評估加速器性能的重要指標。本文對比并分析了文獻[7]方法、文獻[9]方法、文獻[10]方法和本文方法的AlexNet第二卷積層運算時間,并以文獻[7]方法的計算速度為基線比較了各類方法的加速效果。
由表4可知,得益于最低的乘法運算量、深流水線架構和不存在級聯卷積的層間計算延遲等優勢,本文的方法運算時間最短,對5×5卷積的加速效果最佳。
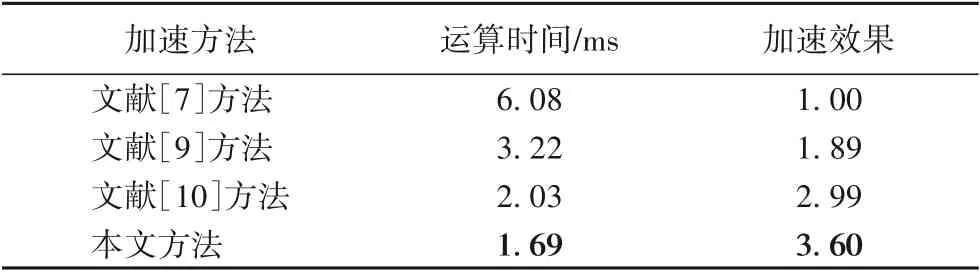
表4 運算時間對比Tab.4 Comparison of computing time
5.3 硬件資源使用率分析
根據文獻[7,9-10]的設計思想,使用本文的FPGA平臺實現其相應算法對AlexNet第二個卷積層的設計,就DSP、LUT和BRAM的資源使用率進行比較。硬件資源使用率對比如圖4所示。
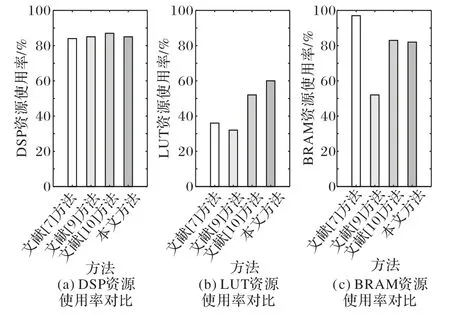
圖4 硬件資源使用率對比Fig.4 Hardware resource utilization comparison
如圖4(a)所示,本文的DSP資源使用率與文獻[7]方法、文獻[9]方法和文獻[10]方法相近,均在80%以上,均能保證卷積神經網絡硬件加速器擁有較高的工作效率。
如圖4(b)所示,本文的LUT資源使用率比文獻[7]方法高24%,比文獻[9]方法高28%,比文獻[10]方法高8%,但遠低于DSP資源使用率。由于二維Winograd卷積算法通過完成大量加法運算來降低乘法運算量,因此采用Winograd算法的本文和文獻[10]需要更多的LUT資源完成加法運算。
此外在Winograd算法U、V及Out的加法計算過程中,存在一些可復用的中間計算結果,例如F(22,32)算法運算過程中式(12)運算結果U的第2、3個元素中均有(u0/2+u2/2)的運算,其中u0、u2為式(11)運算結果U1的第1、3個元素。為降低部分LUT開銷,本文通過字符串精確匹配搜索U、V及Out加法運算中可復用的中間計算結果來指導設計,在二維Winograd卷積算法的加法設計中探索并實現最優的數據重用方式,降低了約8%的加法計算量,以降低LUT資源使用率。這種加法運算中間結果重用方法避免了部分無效計算,減小了設計面積且降低了系統能耗。
如圖4(c)所示,本文的BRAM資源使用率比文獻[7]方法低15%,比文獻[9]方法高30%,比文獻[10]方法低1%。與文獻[7]和文獻[9]的方法相較,本文和文獻[10]的方法相對乘法運算量更低,這意味著在使用相同數目的DSP時,二維W inograd卷積算法可對更多的輸入數據完成卷積運算,因此采用此類方法的本文和文獻[10]在實現過程中需要占用更多的BRAM資源。本文通過設計快速設計空間探索性能分析模型來保證BRAM資源使用率低于DSP使用率,以確保加速器性能不受硬件資源數量限制。
綜合整體硬件資源進行分析,本文的設計與之前研究工作相較各項硬件資源使用率相近,通過數據重用、優化架構和優化加速算法等方式取得了更高的計算性能,提高了硬件加速器的加速效率。
5.4 DSP效率分析
由于卷積神經網絡FPGA加速器的吞吐量、功率和能量效率等性能指標均會受FPGA平臺影響,同一設計方法在不同平臺上會有不同的性能表現。因此本文將DSP效率,即吞吐量/片上DSP數量作為主要指標以客觀分析加速器性能水平。由于本文在同一FPGA平臺上實現相關設計因此各加速方法具有相同的工作頻率和可用DSP總量。
由表5可知,本文的設計在5×5卷積的相關層達到了較高的DSP效率,DSP效率為0.529,高于文獻[7]方法和文獻[9]方法,由于復用了部分加法運算結果降低了吞吐量而略低于文獻[10]方法的0.557。但因本文架構方法有著更低的乘法運算量和存儲器帶寬需求,因此相較文獻[10]方法,本文的加速器系統架構方法速度更快、能耗更低、性能更優。
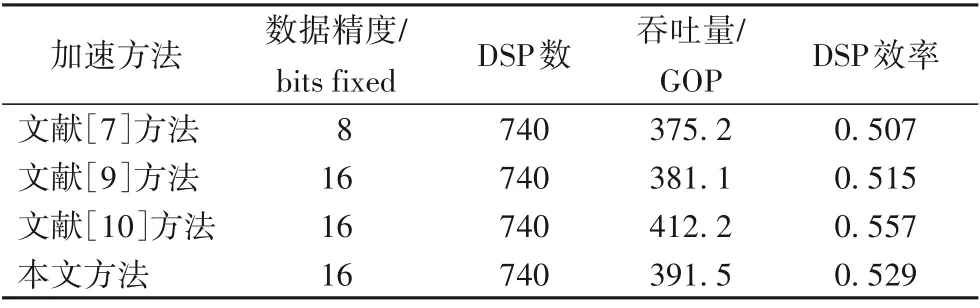
表5 DSP效率對比Tab.5 Comparison of DSPefficiency
6 結語
本文對基于二維Winograd算法5×5卷積的架構問題進行了研究,深化二維Winograd卷積算法流水線并利用雙緩沖區和復用中間運算結果實現數據重用,提出了一種針對二維Winograd算法5×5卷積的雙緩沖區最小塊單元6級流水線方法,并與現有構建5×5卷積的方法進行實驗對比。實驗結果表明,本文提出的深流水線方法在基本不影響神經網絡預測準確率的前提下,具有更低的計算復雜度和存儲器帶寬需求,縮短了計算時間,降低了能耗,為FPGA上5×5快速卷積的架構提供了解決方案,有效地提高了二維W inograd算法5×5卷積在FPGA平臺上的計算效率。
猜你喜歡
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
兒童故事畫報(2019年5期)2019-05-26 14:26:14
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
