融入時(shí)間的興趣點(diǎn)協(xié)同推薦算法
2021-09-09 08:09:26陳紅梅
計(jì)算機(jī)應(yīng)用 2021年8期
關(guān)鍵詞:用戶
包 玄,陳紅梅,肖 清
(云南大學(xué)信息學(xué)院,昆明 650500)
0 引言
隨著全球定位系統(tǒng)、移動(dòng)互聯(lián)網(wǎng)等信息技術(shù)的發(fā)展以及移動(dòng)設(shè)備的普及,基于位置的社交網(wǎng)絡(luò)(Location-Based Social Network,LBSN)受到越來(lái)越多人的喜愛(ài),人們?cè)诰W(wǎng)絡(luò)平臺(tái)(如Yelp、微博、Twitter等)上分享豐富的位置相關(guān)信息,使得位置數(shù)據(jù)激劇膨脹,導(dǎo)致信息過(guò)載,不論服務(wù)商還是用戶,都難以從海量位置數(shù)據(jù)中獲取感興趣的信息,于是位置推薦應(yīng)運(yùn)而生,其中興趣點(diǎn)(Point-Of-Interest,POI)推薦備受關(guān)注。POI推薦是根據(jù)用戶的POI訪問(wèn)歷史,以及用戶和POI的描述信息,分析用戶興趣偏好,發(fā)現(xiàn)用戶潛在感興趣的POI并推薦給用戶。POI推薦不僅可以幫助用戶快速獲取所需信息,改進(jìn)用戶體驗(yàn),也可以幫助服務(wù)商快速定位目標(biāo)客戶,提高商業(yè)利潤(rùn)。
傳統(tǒng)POI推薦大致可以描述為:首先,將用戶的POI訪問(wèn)歷史建模為一個(gè)二維簽到矩陣User-POI,用以表達(dá)用戶訪問(wèn)POI的情況,例如,如果用戶u訪問(wèn)過(guò)POIl,則簽到矩陣元素(u,l)的值1,否則為0。然后,基于簽到矩陣User-POI,采用協(xié)同過(guò)濾技術(shù),學(xué)習(xí)用戶的POI偏好,估計(jì)用戶沒(méi)訪問(wèn)過(guò)但可能感興趣的POI評(píng)分,即簽到矩陣中為0的元素的可能值。最后,按估計(jì)的評(píng)分高低,將用戶沒(méi)訪問(wèn)過(guò)但可能感興趣的POI推薦給用戶。
為了提升POI推薦效果,研究者在傳統(tǒng)推薦的基礎(chǔ)上,融合上下文信息,如用戶間的社交關(guān)系、POI間的距離關(guān)系等。最近,研究者也開(kāi)始關(guān)注用戶訪問(wèn)POI的時(shí)間信息。文獻(xiàn)[1-2]的研究表明,人們一天的活動(dòng)具有規(guī)律性。例如,中午12點(diǎn)用戶大概率訪問(wèn)餐館,半夜12點(diǎn)訪問(wèn)酒吧等。在POI推薦中,如果不考慮時(shí)間因素,則可能出現(xiàn)中午11點(diǎn)向用戶推薦酒吧,晚上12點(diǎn)向用戶推薦餐館,降低POI推薦效果。因此,在POI推薦中,時(shí)間是一個(gè)重要的影響因素。
基于上述分析,本文研究融入時(shí)間的POI推薦,問(wèn)題描述為:根據(jù)用戶的POI訪問(wèn)歷史(包括用戶、時(shí)間、POI信息),分析用戶的訪問(wèn)時(shí)間及POI偏好,發(fā)現(xiàn)用戶潛在感興趣的POI及訪問(wèn)時(shí)間,按時(shí)間推薦POI給用戶。為解決該問(wèn)題,本文主要做了如下工作:
1)首先,分析用戶的POI訪問(wèn)歷史,探索用戶訪問(wèn)POI的時(shí)間關(guān)系,發(fā)現(xiàn)兩個(gè)關(guān)于不同時(shí)間片間POI訪問(wèn)相似度變化的規(guī)律。
2)然后,基于上述兩個(gè)發(fā)現(xiàn)規(guī)律,提出新的用戶簽到數(shù)據(jù)平滑方法和候選POI評(píng)分計(jì)算方法,進(jìn)而提出一個(gè)融入時(shí)間的POI協(xié)同推薦模型。
3)最后,在兩個(gè)真實(shí)數(shù)據(jù)集Foursquare和Gowalla上進(jìn)行實(shí)驗(yàn),評(píng)估所提出的推薦模型。實(shí)驗(yàn)結(jié)果表明所提推薦算法在精確率、召回率、平均絕對(duì)誤差方面均優(yōu)于對(duì)比算法。
1 相關(guān)工作
推薦系統(tǒng)廣泛采用的技術(shù)是協(xié)同過(guò)濾(Collaborative Filtering,CF),可分為基于記憶的協(xié)同過(guò)濾(Memory-Based CF)和基于模型的協(xié)同過(guò)濾(Model-Based CF)。基于記憶的協(xié)同過(guò)濾又可分為基于用戶的協(xié)同過(guò)濾和基于項(xiàng)目的協(xié)同過(guò)濾。該類方法依據(jù)相似的用戶(項(xiàng)目)具有相似的偏好,主要包括兩個(gè)關(guān)鍵步驟:首先計(jì)算用戶(項(xiàng)目)相似度,然后利用相似用戶(項(xiàng)目)的加權(quán)評(píng)分估計(jì)目標(biāo)用戶對(duì)未評(píng)分項(xiàng)目的評(píng)分,從而根據(jù)評(píng)分形成推薦列表[2]。基于模型的協(xié)同過(guò)濾采用數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí),建立推薦模型,該類方法包括決策樹(shù)模型、貝葉斯方法、矩陣分解方法等[3]。
針對(duì)位置數(shù)據(jù)膨脹及信息過(guò)載,上述推薦技術(shù)被用于POI推薦,在此分兩類進(jìn)行介紹:
1)POI推薦。
為了提升POI推薦效果,研究者在傳統(tǒng)方法上融合上下文信息,如用戶間的社會(huì)關(guān)系、POI間的距離關(guān)系等。文獻(xiàn)[4]采用線性插值將用戶間的社會(huì)關(guān)系以及POI間的距離關(guān)系融入基于用戶的協(xié)同過(guò)濾框架;文獻(xiàn)[5]在基于用戶的協(xié)同過(guò)濾框架中融入用戶間的社會(huì)關(guān)系,并貝葉斯方法對(duì)空間影響進(jìn)行建模;文獻(xiàn)[6]探索用戶的2-度好友的社交影響,采用PageRank算法計(jì)算地點(diǎn)影響力,采用核密度估計(jì)方法發(fā)現(xiàn)用戶的位置偏好,最后將三者融合進(jìn)行POI推薦;文獻(xiàn)[7]將用戶偏好和個(gè)性化的地理社會(huì)影響整合到地理社會(huì)推薦框架中,提出一種潛在的基于地理社會(huì)關(guān)系的POI推薦模型;文獻(xiàn)[8-10]利用社會(huì)友誼提高推薦的效率和性能,計(jì)算所有用戶之間的相似性,并利用用戶相似性作為正則化約束矩陣分解。
2)考慮時(shí)間因素的POI推薦。
由于用戶會(huì)在不同的時(shí)間訪問(wèn)不同類型的POI(如餐館、咖啡店、酒吧),所以時(shí)間是POI推薦中的重要因素。為了進(jìn)一步提升POI推薦效果,增強(qiáng)用戶體驗(yàn),最近,研究者也開(kāi)始關(guān)注融合用戶訪問(wèn)POI的時(shí)間信息,提出了考慮時(shí)間因素的POI推薦。文獻(xiàn)[2]在基于用戶的協(xié)同過(guò)濾框架下建模用戶偏好和時(shí)間影響,采用冪律分布建模地理影響,提出了融合時(shí)間與地理影響的時(shí)間感知POI推薦算法;文獻(xiàn)[11-12]中提出了一種基于張量因子分解的協(xié)同過(guò)濾方法,利用一個(gè)高階張量來(lái)融合用戶簽到的異構(gòu)上下文信息——時(shí)間信息、社交關(guān)系、地理位置;文獻(xiàn)[13]用概率模型將用戶對(duì)地點(diǎn)的興趣度,用戶所處的時(shí)間段和地點(diǎn)自身的流行度融合起來(lái)進(jìn)行POI推薦;文獻(xiàn)[14]在基于用戶協(xié)同過(guò)濾的基礎(chǔ)上,結(jié)合有序圖探索用戶偏好,基于用戶當(dāng)前時(shí)間的位置,為用戶推薦下一個(gè)訪問(wèn)的POI;文獻(xiàn)[15]將用戶簽到的時(shí)間信息以及空間信息融入用戶相似度的計(jì)算中,提出一種改進(jìn)的基于用戶協(xié)同過(guò)濾的算法;文獻(xiàn)[16]用有向圖表示用戶的歷史訪問(wèn)數(shù)據(jù),考慮相似用戶、時(shí)間以及簽到序列,基于圖的性質(zhì)提出一種新穎的基于用戶協(xié)同過(guò)濾模型。
本文受文獻(xiàn)[2]啟發(fā),研究融入時(shí)間的POI推薦,但是與文獻(xiàn)[2]不同,本文深入分析用戶簽到的時(shí)間關(guān)系,基于兩個(gè)關(guān)于不同時(shí)間片間POI訪問(wèn)相似度變化規(guī)律的發(fā)現(xiàn)(將在3.1節(jié)中詳述),提出新的用戶簽到數(shù)據(jù)平滑方法和候選POI評(píng)分計(jì)算方法,進(jìn)而提出一個(gè)融入時(shí)間的POI推薦模型,不僅有效解決了簽到數(shù)據(jù)的稀疏性問(wèn)題,還獲得了相對(duì)較高的推薦質(zhì)量。
2 基于用戶的協(xié)同推薦
本文所用符號(hào)和含義描述如表1所示。

表1 本文所用符號(hào)及其含義描述Tab.1 Symbols used in this paper and their meaning descriptions
基于用戶的協(xié)同過(guò)濾(User-based collaborative filtering,U)算法,主要步驟是:首先,根據(jù)用戶的POI訪問(wèn)歷史度量用戶間的相似性,找到目標(biāo)用戶的一組相似用戶。然后,利用相似用戶的加權(quán)評(píng)分,估計(jì)目標(biāo)用戶對(duì)沒(méi)訪問(wèn)POI的評(píng)分,從而根據(jù)評(píng)分形成POI推薦列表。具體地,根據(jù)用戶的POI訪問(wèn)歷史,建立二維簽到矩陣即User-POI矩陣,對(duì)于其中的每個(gè)元素Cul(u∈U,l∈I),如果用戶u訪問(wèn)過(guò)POIl,則設(shè)置Cul=1,否則設(shè)置Cul=0。給定一個(gè)目標(biāo)用戶u,則用戶u對(duì)沒(méi)訪問(wèn)POIl的評(píng)分估計(jì)計(jì)算如式(1)所示:

其中Wuv表示目標(biāo)用戶u和相似用戶v之間的相似度。兩個(gè)用戶間的相似性度量有多種,本文采用使用最廣泛的余弦相似性度量,計(jì)算方法如下:
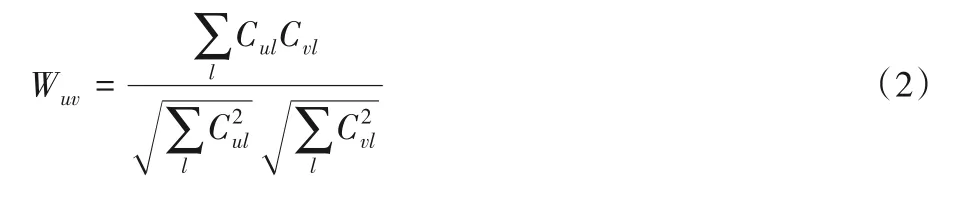
3 融入時(shí)間的POI協(xié)同推薦
3.1 時(shí)間關(guān)系分析
用戶在一天甚至一周內(nèi)的活動(dòng)具有一定的規(guī)律。這個(gè)規(guī)律主要分為用戶訪問(wèn)POI的時(shí)間差異性和連續(xù)性。差異性是指用戶中午去餐館,晚上去酒吧等;工作日在家和單位附近,而周末去離家較遠(yuǎn)的地方游玩等,即用戶訪問(wèn)POI隨時(shí)間的變化而變化。連續(xù)性是指在相鄰時(shí)間段,用戶的活動(dòng)具有相似性[15]。例如,用戶在中午12—13點(diǎn)會(huì)訪問(wèn)餐廳等相似的POI。因此,本文將一天按小時(shí)劃分為24個(gè)時(shí)間片,如24(hh):01(mm):00(ss)為時(shí)間片0,10(hh):15(mm):30(ss)為時(shí)間片10,構(gòu)成時(shí)間片集合T={0,1,…,23}。然后,在兩個(gè)真實(shí)數(shù)據(jù)集Foursquare和Gowalla上,利用常用的相似性度量方法——余弦相似性,度量任意兩個(gè)時(shí)間片間的相似度,分析用戶訪問(wèn)POI的時(shí)間關(guān)系可發(fā)現(xiàn):
1)用戶在不同時(shí)間片訪問(wèn)的POI具有不同程度的相似性。
本文以Foursquare數(shù)據(jù)集上的結(jié)果為例。圖1顯示了該數(shù)據(jù)集上3個(gè)時(shí)間片(7點(diǎn)、12點(diǎn)和18點(diǎn))與其他時(shí)間片的相似度曲線。從圖1中可以看出這3個(gè)時(shí)間片與0—6點(diǎn)的相似度很低,在6點(diǎn)以后逐漸升高,7點(diǎn)以后(8—23點(diǎn))的相似度均比6點(diǎn)以前的高。這和實(shí)際生活中大多數(shù)人上午6—7點(diǎn)出門,凌晨進(jìn)入睡眠相符合。在18點(diǎn)時(shí)間片的曲線上,11點(diǎn)時(shí)相似度有小幅上升,同樣,在7點(diǎn)與12點(diǎn)兩個(gè)時(shí)間片的曲線上,17點(diǎn)和18點(diǎn)時(shí)相似度也有小幅上升,這符合早飯、午飯、晚飯的時(shí)間。綜上,用戶在不同時(shí)間片訪問(wèn)的POI具有不同程度的相似性。
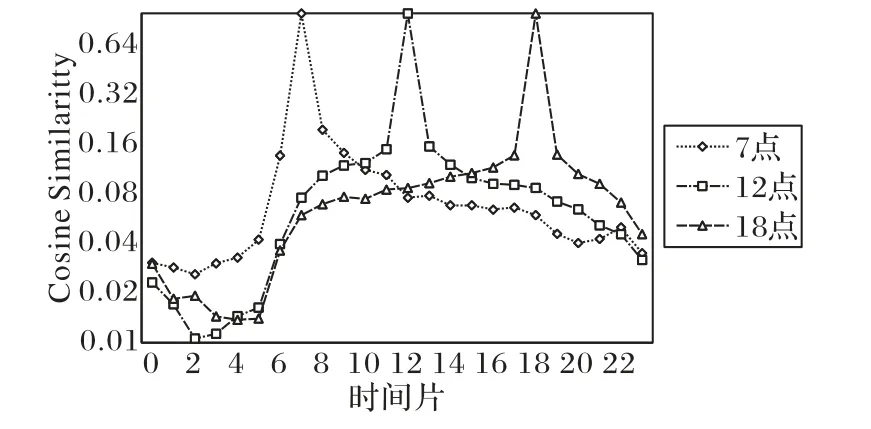
圖1 給定時(shí)間片與任意時(shí)間片之間的相似度Fig.1 Similarities between given time slicesand other time slices
2)用戶訪問(wèn)POI的相似性隨時(shí)間差增加而衰減。
進(jìn)一步,本文分析不同時(shí)間差下,用戶訪問(wèn)POI的相似度,其 中,時(shí) 間 差Δt=|t-t'|(|t-t'|≤12)或Δt=24-|t-t'|(|t-t'|>12),結(jié)果如圖2所示。
本文以Foursquare數(shù)據(jù)集上的結(jié)果為例。由圖2可以看出時(shí)間差越大,時(shí)間片間相似度越低。當(dāng)時(shí)間差為0時(shí),在總相似度中占比為58%,剩余時(shí)間差占比為42%。即,相同時(shí)間片上用戶簽到偏好具有最大的相似性。也就是說(shuō),相同時(shí)間上用戶偏好對(duì)用戶決定是否訪問(wèn)某一POI的影響最大;同時(shí)其余時(shí)間片上的簽到偏好也不能忽視。因此,本文首先利用所有時(shí)間片間的相似度平滑簽到矩陣以緩解數(shù)據(jù)稀疏問(wèn)題,進(jìn)而使用平滑之后獲得的簽到矩陣,發(fā)現(xiàn)用戶偏好。其次,利用相同時(shí)間片的用戶訪問(wèn)偏好最相似這一特點(diǎn),按時(shí)間給用戶推薦POI,從而提高推薦效果。
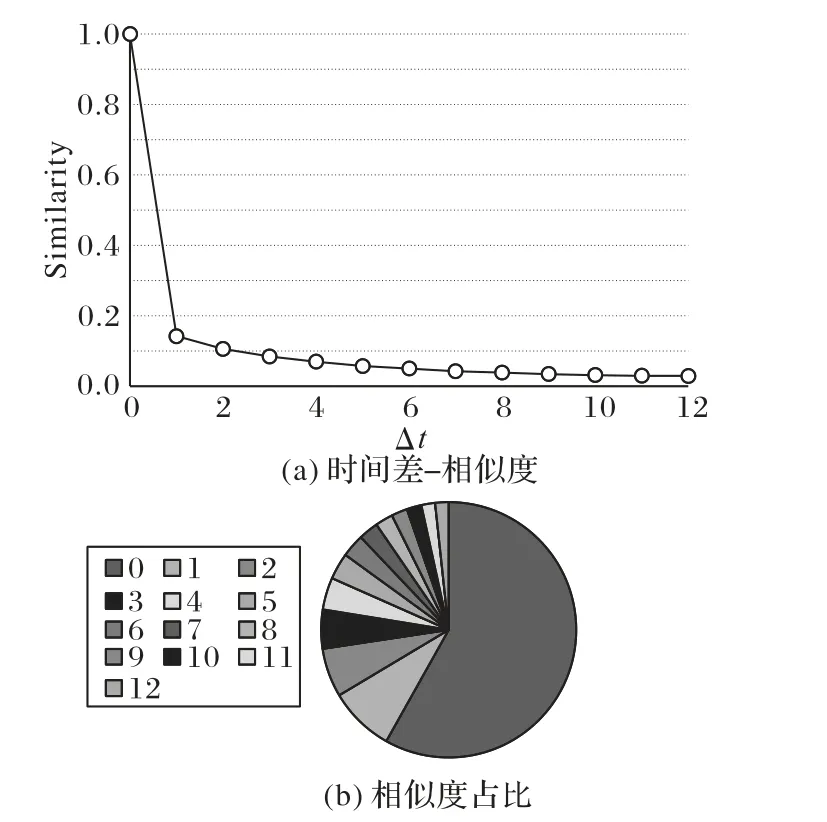
圖2 時(shí)間差與相似度Fig.2 Time differenceand similarity
3.2 融入時(shí)間的POI協(xié)同推薦算法
對(duì)簽到數(shù)據(jù)按小時(shí)劃分之后,原本的二維簽到矩陣User-POI,被建模為一個(gè)三維簽到張量即User-Time-POI。對(duì)于其中每個(gè)元素Cutl(u∈U,t∈T,l∈L),如果用戶u在時(shí)間片t訪問(wèn)POIl,那么設(shè)置Cutl=1,否則設(shè)置Cutl=0。融入時(shí)間的POI協(xié)同推薦算法,首先利用獲取的時(shí)間關(guān)系平滑用戶的簽到矩陣,然后根據(jù)平滑后的簽到矩陣尋找相似用戶,最后利用相似用戶簽到偏好為目標(biāo)用戶u在時(shí)間片t進(jìn)行POI推薦。
3.2.1 時(shí)間片平滑
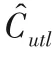

其中Simtt'表示時(shí)間片t與t'的相似度。采用常用的相似性方法——余弦相似性,計(jì)算如下:
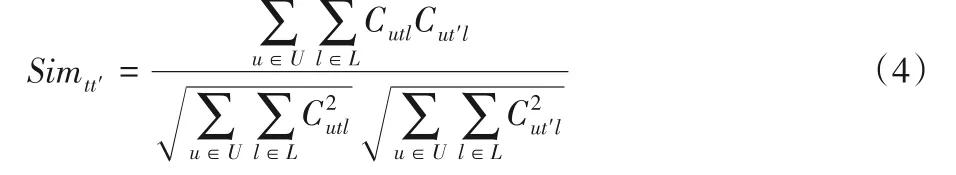
3.2.2 用戶相似度計(jì)算
為解決融入時(shí)間的POI協(xié)同推薦,首先尋找目標(biāo)用戶u的相似用戶。為使搜索到的相似用戶更加準(zhǔn)確,在度量相似用戶時(shí),不僅考慮訪問(wèn)的POI,還加入訪問(wèn)的時(shí)間。例如,用戶u1在時(shí)間t1以及t2訪問(wèn)l1和l2,用戶u2在時(shí)間t1以及t2訪問(wèn)l2和l1,在不考慮時(shí)間的情況下,利用式(1)計(jì)算得到u1、u2的相似度為1,融入時(shí)間之后相似度為0。
在更加稀疏的三維簽到張量中,直接引入時(shí)間計(jì)算兩個(gè)用戶相似度雖然會(huì)提高相似用戶的質(zhì)量,但當(dāng)不同的用戶在不同的時(shí)間片訪問(wèn)同一個(gè)POI時(shí),直接加入時(shí)間片尋找相似用戶忽略了用戶在某一個(gè)時(shí)間片上簽到行為和其他時(shí)間片上的簽到行為具有相似性。例如,用戶u和v分別在時(shí)間t1和t2訪問(wèn)l1,不考慮時(shí)間片相似的情況用戶u和v的相似度為0;考慮時(shí)間片相似的情況,用戶u和v的相似度則大于0。因此,根據(jù)平滑后的簽到矩陣計(jì)算用戶相似度,計(jì)算如式(5)所示:

3.2.3 POI推薦
由3.1節(jié)分析可知,相同時(shí)間片上用戶簽到偏好具有最大的相似性,即相同時(shí)間片上用戶簽到偏好對(duì)用戶決定是否訪問(wèn)某一POI的影響最大。所以,本文利用相似用戶在同一時(shí)間片的訪問(wèn)偏好評(píng)估候選POI。采用基于用戶的協(xié)同過(guò)濾,以及3.2.1節(jié)中平滑后的簽到矩陣、3.2.2節(jié)中的相似用戶及其相似性,估計(jì)目標(biāo)用戶u在時(shí)間片t訪問(wèn)POIl的評(píng)分,計(jì)算方法如式(6)所示:

排序式(6)得到的估計(jì)評(píng)分,即可獲得在時(shí)間片t,向目標(biāo)用戶u推薦的POI列表。融入時(shí)間的POI協(xié)同推薦(Timeincorporated User-based Collaborative Filtering POI recommendation,TUCF)算法描述如下。
輸入:用戶簽到數(shù)據(jù)集,目標(biāo)用戶u,時(shí)間片集合T;
輸出:目標(biāo)用戶u在各個(gè)時(shí)間片上的推薦列表。
1)將用戶簽到數(shù)據(jù)建模為User-Time-POI張量;
2)利用式(4)計(jì)算各個(gè)時(shí)間片間的余弦相似度;
3)根據(jù)式(3)平滑User-Time-POI簽到張量;
4)根據(jù)式(5)計(jì)算用戶間的相似度;
5)獲取候選POI:用戶在時(shí)間片t沒(méi)有訪問(wèn)過(guò)的POI;
6)利用式(6)計(jì)算每個(gè)候選POI的評(píng)分;
7)對(duì)評(píng)估分?jǐn)?shù)排序,取前N個(gè)POI作為推薦列表Rank,并返回Rank。
在TUCF算法中,選出估計(jì)評(píng)分最高的N個(gè)POI作為最終的推薦結(jié)果,根據(jù)實(shí)際推薦的情況N的取值不同。
4 實(shí)驗(yàn)與結(jié)果分析
4.1 實(shí)驗(yàn)設(shè)置
4.1.1 數(shù)據(jù)集
本文使用文獻(xiàn)[2]提供的兩個(gè)真實(shí)數(shù)據(jù)集Foursquare和Gowalla。Foursquare數(shù)據(jù)集為2010年8月—2011年7月的新加坡簽到數(shù)據(jù),包含2 321個(gè)用戶,5 596個(gè)POI,共194 108條簽到。Gowalla數(shù)據(jù)集為2009年8月—2010年9月加州和內(nèi)華達(dá)州的簽到數(shù)據(jù),包含10 162個(gè)用戶,24 250個(gè)POI,共456 988條簽到。兩個(gè)數(shù)據(jù)集中每個(gè)用戶簽到至少5個(gè)POI,每個(gè)POI至少被5個(gè)用戶簽到,每個(gè)數(shù)據(jù)集被劃分為訓(xùn)練集、測(cè)試集和調(diào)參集。本文使用每個(gè)數(shù)據(jù)集中的訓(xùn)練集和測(cè)試集。
4.1.2 對(duì)比算法
為了驗(yàn)證本文所提出的融入時(shí)間的POI協(xié)同推薦(TUCF)算法的性能,選用了以下對(duì)比算法驗(yàn)證該算法的有效性:1)U算法[2];2)具有平滑增強(qiáng)時(shí)間偏好的協(xié)同過(guò)濾(Uwith Temporal preference with smoothing Enhancement,UTE)算法[2]。
4.1.3 評(píng)價(jià)指標(biāo)
本文采用評(píng)價(jià)指標(biāo):精確率Precision、召回率Recall、平均絕對(duì)誤差MAE來(lái)評(píng)估推薦算法的效果。在評(píng)估指標(biāo)中涉及的符號(hào)和描述如表2所示。

表2 評(píng)估指標(biāo)中的符號(hào)描述Tab.2 Description of symbolsused in evaluation indices
1)精確率和召回率。
采用文獻(xiàn)[2]中的方法評(píng)估推薦算法的精確率和召回率。Pre@N(t)和Rec@N(t)分別表示在時(shí)間片t推薦N個(gè)POI的精確率和召回率,計(jì)算如式(7)~(8)所示:

算法推薦N個(gè)POI的精確率Pre@N和召回率Rec@N是所有時(shí)間片的平均精確率和召回率,如式(9)~(10)所示:
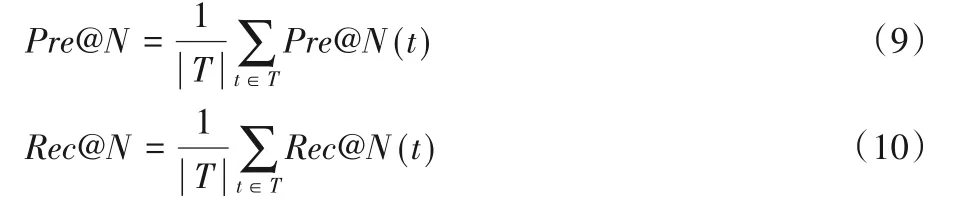
2)平均絕對(duì)誤差。
在簽到張量中,如果用戶u在時(shí)間t對(duì)POIl進(jìn)行了簽到則cutl=1,否則cutl=0,將其作為用戶評(píng)分。首先計(jì)算每個(gè)時(shí)間片上的平均絕對(duì)誤差MAE(t),然后平均所有時(shí)間片上的MAE(t),得到推薦算法的平均絕對(duì)誤差。每個(gè)時(shí)間片上的平均絕對(duì)誤差計(jì)算方法如式(11)所示:
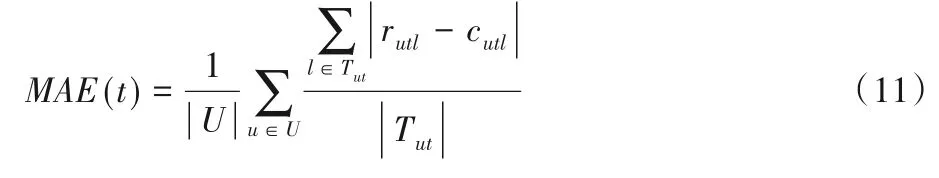
推薦算法的平均絕對(duì)誤差MAE是所有時(shí)間片的平均值,計(jì)算方法如式(12)所示:

4.2 實(shí)驗(yàn)結(jié)果與分析
本文TUCF算法與對(duì)比算法U和UTE的實(shí)驗(yàn)結(jié)果及分析如下。文中的相似用戶數(shù)固定為500,推薦的POI個(gè)數(shù)N分別取5、10、15。
1)推薦算法的精確率和召回率。
TUCF、U和UTE算法在數(shù)據(jù)集Foursquare和Gowalla上的精確率和召回率如圖3所示。
從圖3可以看出:在兩個(gè)數(shù)據(jù)集上,考慮時(shí)間因素的UTE算法、TUCF算法均優(yōu)于未考慮時(shí)間因素的U算法,說(shuō)明考慮時(shí)間因素可以提高POI推薦效果。同時(shí)TUCF算法的精確率和召回率均高于對(duì)比算法U和UTE。尤其是,在POI推薦數(shù)目N=5時(shí),在Foursquare中TUCF算法比U算法在精確率以及召回率上分別提高了63%和69%,TUCF算法比UTE算法的精確率以及召回率分別提高了8%和12%,這表明采用時(shí)間關(guān)系平滑用戶簽到獲取相似用戶,以及利用相似用戶在相同時(shí)間片的訪問(wèn)偏好,可以提高推薦效果。
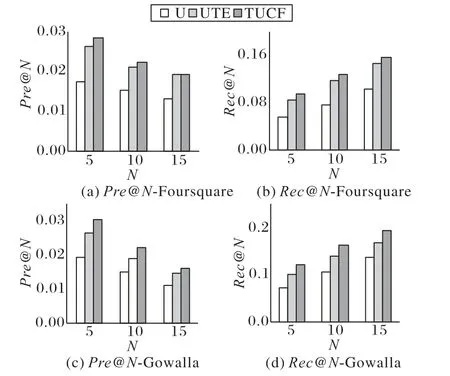
圖3 推薦算法的精確率和召回率比較Fig.3 Comparison of precision and recall of recommendation algorithms
2)各時(shí)間片上的精確率和召回率。
本文以Gowalla數(shù)據(jù)集上的結(jié)果為例,結(jié)果如圖4所示,其中N=5。從圖4中可以看出,精確率和召回率的變化在兩個(gè)方法中相似,且TUCF算法在24個(gè)時(shí)間片上均高于UTE算法。在時(shí)間片11點(diǎn)時(shí),兩個(gè)算法的精確率和召回率達(dá)到最高,在時(shí)間片9點(diǎn)時(shí),精確率和召回率達(dá)到最低。尤其在時(shí)間片7點(diǎn)時(shí),TUCF算法的精確率和召回率相比UTE算法分別改善了67%和50%。這說(shuō)明采用時(shí)間關(guān)系平滑用戶簽到獲取相似用戶,以及利用相似用戶在相同時(shí)間片的訪問(wèn)偏好,可以提高推薦效果。
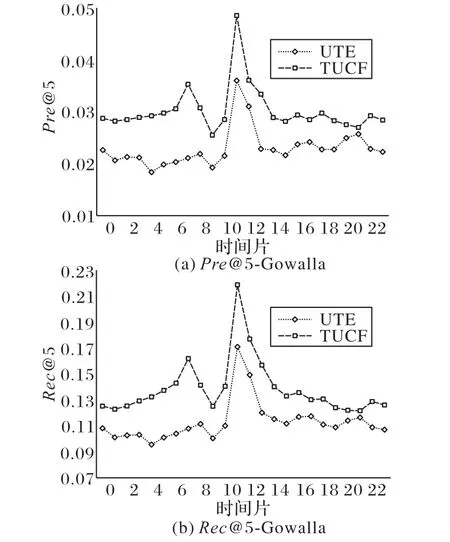
圖4 不同時(shí)間片上的準(zhǔn)確率和召回率比較Fig.4 Comparison of precision and recall on different time slices
3)MAE對(duì)比。
本節(jié)將推薦POI數(shù)量N固定為5,目標(biāo)用戶的相似用戶數(shù)量M從50增長(zhǎng)到2 000,分析相似用戶數(shù)量對(duì)算法的影響,以圖5所示的Foursquare數(shù)據(jù)集上的結(jié)果為例。
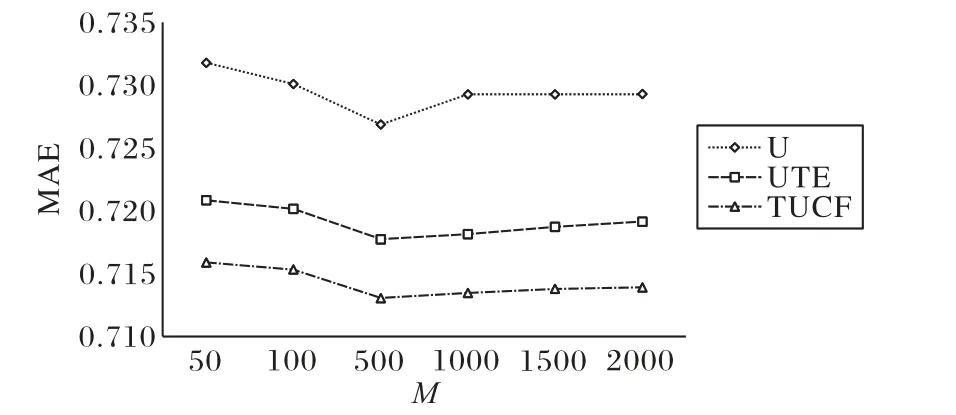
圖5 MAE比較Fig.5 Comparison of MAE
從圖5中可以看出當(dāng)M取500時(shí),取得較好的推薦效果,且對(duì)于不同的M,TUCF的MAE值均低于對(duì)比算法U和UTE。其中考慮時(shí)間因素的TUCF算法、UTE算法,MAE值均比未考慮時(shí)間因素的U算法低,說(shuō)明考慮時(shí)間因素可以提高POI推薦效果。考慮時(shí)間因素的TUCF算法和UTE算法,TUCF算法的MAE值低于UTE算法,表明采用時(shí)間關(guān)系平滑用戶簽到獲取相似用戶,以及利用相似用戶在相同時(shí)間片的訪問(wèn)偏好,可以提高推薦效果。
5 結(jié)語(yǔ)
本文分析基于位置的社交網(wǎng)絡(luò)的用戶簽到數(shù)據(jù),探索用戶簽到的時(shí)間關(guān)系,并利用時(shí)間關(guān)系對(duì)用戶簽到數(shù)據(jù)進(jìn)行平滑處理,然后基于用戶的協(xié)同過(guò)濾算法,提出了融入時(shí)間的協(xié)同過(guò)濾POI推薦算法。在兩個(gè)真實(shí)數(shù)據(jù)集Foursquare和Gowalla上的實(shí)驗(yàn)結(jié)果表明,本文算法不僅可以有效緩解數(shù)據(jù)的稀疏性,還提高了POI推薦的精確率和召回率,減小了平均絕對(duì)誤差。
時(shí)間作為POI推薦的一個(gè)重要因素,除了一天內(nèi)不同時(shí)間對(duì)用戶簽到有影響,用戶的簽到行為還受星期或月份的影響,今后將進(jìn)一步探索其他時(shí)間粒度。此外,POI通常具有類別信息,也將探索類別信息提高POI推薦效果的可能性。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業(yè)黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛(wèi)星與網(wǎng)絡(luò)(2016年12期)2016-02-05 09:23:23
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
