輕量級視覺手勢識別系統
2021-09-10 08:36:36朱想先樓逸倫
電子元器件與信息技術 2021年6期
朱想先,樓逸倫
(寧波普瑞均勝汽車電子有限公司,浙江 寧波 315000)
0 引言
手勢識別一直以來都是人機交互領域中重要的研究方向,在虛擬現實、智能座艙、智能家居等方面有廣闊的應用前景。考慮到嵌入式平臺的資源有限性特點,本文提出了輕量級視覺手勢識別交互系統,并設計了一個帶有批歸一化層的輕量級多層神經網絡Light MLNN。本系統采用Zhang等人提出的Mediapipe Hands[1]將攝像頭RGB數據轉化為21個手部關鍵點3維位置坐標,再將坐標處理后送入Light MLNN實現靜態手勢分類。并且引入二元交叉熵損失函數(BCE Loss)作為目標函數,與常用多分類損失函數交叉熵損失函數(CE Loss)相比,以微小準確率損失為代價,能夠抑制非目標手勢被錯分成目標手勢分類。
1 手勢關鍵點提取
本文采用Mediapipe Hands作為手勢關鍵點提取方案。它主要由BlazePalm Detector和Hand Landmark Model兩個神經網絡模型構成。BlazePalm Detector模型的輸出經過非極大值抑制等處理轉化為僅包含手掌的檢測框坐標,并且輸出手掌關鍵點位置。利用模型輸出的手掌檢測框、中指關節和手腕關節,Mediapipe Hand將檢測框旋轉并且放大得到全手檢測框。Hand Landmark Model將裁減后全手檢測框中的圖像轉化為全手21個關鍵點的3維坐標、左右手性和手勢分數。在實時應用中,手掌檢測模型一旦檢測到手勢,后續全手檢測框由手勢關鍵點模型計算產生。當手勢分數低于閾值時,手掌檢測器才會再次激活。對于單手關鍵點提取任務,兩個檢測器交替工作,提高了處理速度。后續對關鍵點的分類則交由Light MLNN實現。
2 Light MLNN 多層神經網絡模型
2.1 Light MLNN 網絡結構
本文采用Pytorch框架訓練Light MLNN模型。模型輸出N×C維向量,C為手勢類別個數,根據不同數據集有不同的取值。模型N×C輸出代表了該N批手勢的C個手勢分類的分數。網絡采用ReLU作為激活函數,并在激活函數后引入了BN層[2]用于加快模型收斂速度。這里以1維向量為例介紹BN層,多維向量BN層的輸出如文中采用的64維是64個1維向量在BN層上獨立運算的結果。在訓練時,BN層的計算過程為yi=BNr,β(xi)

2.2 損失函數的選擇
Light MLNN輸出的分類分數在采用不同損失函數時有不同解釋。對于多分類問題,通常采用的損失函數為CE Loss。采用CE Loss時隱藏了一個假設,即假定輸入的手勢關鍵點數據屬于上述C個分類。而在應用場景下,輸入手勢并不局限于數據集中的C個分類,因此CE Loss并不十分適合實際場景[4-5]。我們在訓練中引入帶sigmoid的BCE Loss,模型的C個分類分數經過sigmoid運算被獨立地視作該分類是否出現的概率。若C個分類出現概率均低于閾值,則模型預測結果為未識別到目標手勢。實驗中我們發現在輸入非目標分類手勢時,利用BCE Loss訓練的模型更不容易將其識別為目標分類手勢[6-7]。
3 實驗結果與分析
3.1 兩個損失函數的比較
我們采用2種損失函數將Light MLNN模型在Hand Gestures Dataset上進行訓練。對于CE Loss訓練的模型,算法的輸出為輸入手勢在10個分類概率分布。我們選取ASL Alphabet數據集中的E、H、V、Y分類作為非法手勢。Hand Gestures Dataset的10個目標手勢和ASL Alphabet的4個非法手勢的關鍵點示意圖如圖1所示。兩種模型的對非目標手勢分類效果和目標手勢驗證準確率如表1。這里將分類E的召回率定義為模型將E識別成非法手勢的個數與E總數的比值,H、V、Y同理。雖然準確率上與CE模型有1%左右的差距,但是BCE訓練的模型將多數非目標手勢識別為非法手勢,閾值0.9時平均召回率達到78.08%,而這指標在CE模型上只有35.97%。
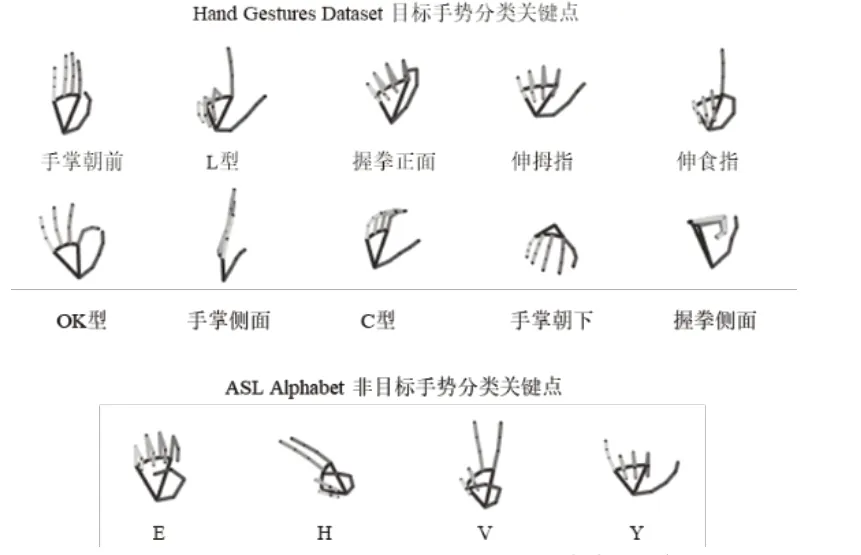
圖1 目標手勢與非目標手勢關鍵點示意圖

表1 CE 與BCE 模型對非目標手勢分類效果和目標手勢驗證準確率
3.2 BN層對訓練速度的影響以及模型準確率表現
這里損失函數采用BCE Loss,我們將帶BN層的模型和不帶BN層的模型在SigNN Character Database的關鍵點數據上進行訓練,訓練損失如圖2所示。在相同全樣本訓練輪數時,采用BN層的模型訓練損失更小,驗證集準確率更高,收斂更快。將閾值設置在0.9時,模型在SigNN Character Database和ASL Alphabet驗證集上的準確率分別為95.73%和94.60%,均取得良好效果。
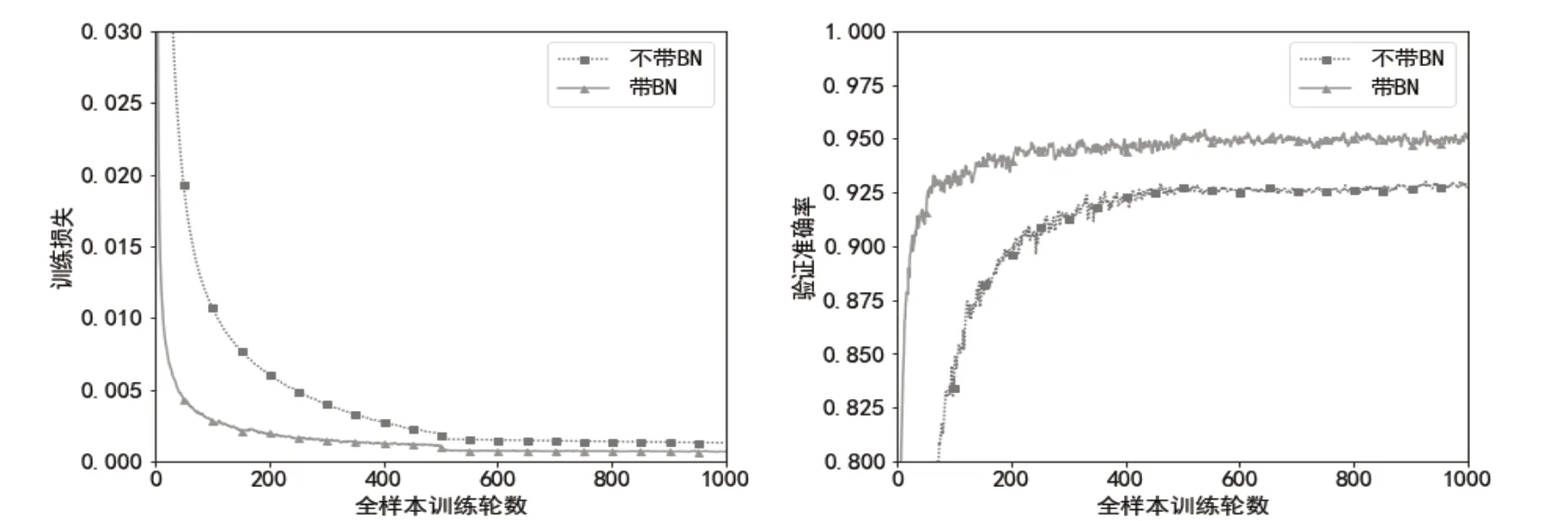
圖2 帶BN 層與不帶BN 層模型在SigNN Character Database 上的訓練損失與驗證準確率
4 結束語
實驗結果表明,本方案能夠以平均12FPS的速度在樹莓派4B上識別靜態手勢,并且具有良好識別準確率。由于選擇BCE Loss進行訓練,手勢識別模型能夠更好地識別出非目標手勢,減少實際應用中對手勢識別的誤報。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
