基于空洞卷積的人體實例分割算法
2021-09-10 07:22:44王沖趙志剛潘振寬于曉康
青島大學學報(自然科學版) 2021年2期
王沖 趙志剛 潘振寬 于曉康





摘要:針對人體實例分割任務中存在著姿態多樣和背景復雜的問題,提出了一種高精度的實例分割算法。利用Mask R-CNN算法特征融合過程中的細節信息,改善人體分割任務中邊緣分割不精確的問題,提高人體分割精度。改進了特征金字塔的特征融合過程,將原有自頂向下的路徑改為自底向上,以保留淺層特征圖中更多的空間位置信息,并且在特征融合過程中加入多尺度空洞卷積,在增大特征圖感受野同時保持分辨率不變,可以避免降采樣過程中特征丟失;使用COCO數據集和網絡平臺,建立新的人體圖像數據集。最后將本算法與Mask R-CNN算法做對比,在IoU分別為0.7、0.8和0.9時,準確率提高了0.26,0.41和0.59。實驗結果表明,算法在新的人體圖像數據集可以得到更精確的結果。
關鍵詞:實例分割;空洞卷積;多尺度特征融合
中圖分類號:TP391
文獻標志碼:A
收稿日期:2020-10-19
通信作者:
于曉康,男,博士,副教授,主要研究方向為計算機幾何,計算機圖形學,計算機視覺等。E-mail: xyu_qdu@163.com
實例分割實際是目標檢測和語義分割的結合。相對于目標檢測,實例分割可精確到物體邊緣;相對于語義分割,實例分割可以分割出每個獨立個體。實例分割算法是從圖像中用目標檢測方法框出不同實例,然后在不同實例區域內進行逐像素預測的分割方法。目前目標檢測領域的深度學習方法主要有兩類:雙階段的目標檢測算法和單階段的目標檢測算法。雙階段的目標檢測算法要先生成一系列的候選框,再進行分類。如RCNN[1]通過選擇性搜索產生候選框,再通過SVM對區域進行分類;Fast R-CNN[2]通過選擇性搜索算法產生候選框,對候選框進行ROI pooling操作統一特征圖大小,最后通過softmax進行分類;Faster R-CNN[3]用區域候選網絡(Region Proposal Network,RPN)代替選擇性搜索算法,在生成候選框時效率更高。單階段的目標檢測算法無需生成候選框,只要一個階段就可以完成檢測。輸入一張圖片,直接輸出目標檢測的結果,如YOLOV1[4],YOLOV2[5]等。隨著深度學習的日趨成,越來越多基于深度學習的語義分割框架被提出。Long等[6]提出了全卷積網絡(FCN)是對圖像進行像素級分割的代表,是神經網絡做語義分割的開山之作。FCN可以接受任意尺寸的輸入圖像,采用反卷積對最后一個卷積層的feature map進行上采樣,使它恢復到輸入圖像相同的尺寸,從而可以對每個像素都產生了一個預測,同時保留了原始輸入圖像中的空間信息,最后在上采樣的特征圖上進行逐像素分類。Chen等[7]提出了DeepLabV2網絡模型,引入了空洞卷積,擴大感受野的同時降低了計算量,通過使用多尺度特征提取,得到全局和局部特征的語義信息。Dai等[8]提出的金字塔場景解析網絡(PSPNet)引入充分的上下文信息和不同感受野下的全局信息,并在ResNet的中間層加入輔助損失,該模型也取得比較理想的結果。基于目標檢測的實例分割,是目標檢測和語義分割的合并。人體實例分割,則是人體目標檢測與人體語義分割的結合。He等[9]提出了Mask R-CNN算法,以ResNet-101[10]為底層網絡,使用金字塔結構融合多尺度特征,構建特征金字塔網絡[11-12](Feature Pyramid Networks,FPN),在Faster R-CNN的基礎上添加了一個掩碼分支,在分割精度上得到了很好的效果。雖然Mask R-CNN在分割精度方面得到很大的提升,但是相對于人體實例分割方面仍然存在著問題,Mask R-CNN中使用的FPN是自頂向下的多特征尺寸融合,即由深層特征到淺層特征的融合,雖然更好地將語義信息融合至淺層網絡,但在人體實例分割中存在著姿態和背景復雜的問題,因此淺層的空間位置信息更為重要。針對上述問題,本文在Mask R-CNN算法的基礎上,用新的人體圖像數據集進行網絡訓練和評估,為了提高檢測準確率,將FPN原有自頂向下路徑改為自底向上,以便更好利用淺層網絡的空間位置信息。在改進后的FPN網絡中加入空洞卷積,擴大感受野,保留大量的語義信息,進一步優化分割結果。
1 方法
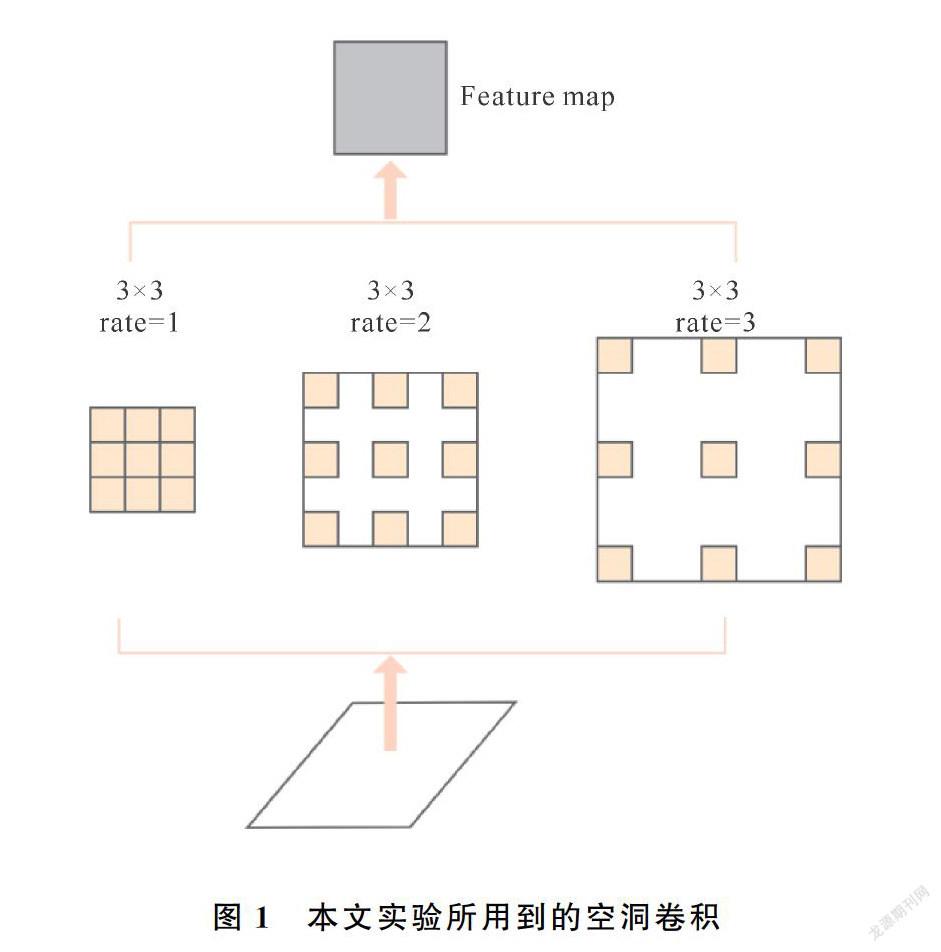
本文基于Mask R-CNN算法,針對其中的特征金字塔結構做出改進,鑒于淺層特征圖具有更多的空間位置和細節信息,將傳統特征金字塔中的自頂向下特征融合結構改為自底向上,將淺層特征圖逐層融入到深層特征圖中,這樣可以將細節信息更好地保存下來。由于ResNet網絡中第一層輸出的特征圖分辨率過大,增加運算成本,本模型從第二層開始構建新的金字塔特征。圖像的實例分割是一種像素級分割,要對圖像中每一個像素點進行類別判斷,因此每個像素的判別與分割結果有很大關系。但是,人體圖象分割時不能只考慮像素本身,還要考慮目標的整體性,所以分割時要結合全局語義信息。因此,本文提出使用空洞卷積:空洞卷積是向普通卷積引入了一個新參數——dilation_rate,即空洞率,用來保證在特征圖尺寸不變的基礎上擴大感受野。空洞率不同時,感受野也會不同,為了得到不同尺度的感受野,實驗設置了三種不同的空洞率,確保獲取多尺度特征信息。本文設置的空洞率參數分別為1,2,3。如圖1所示。
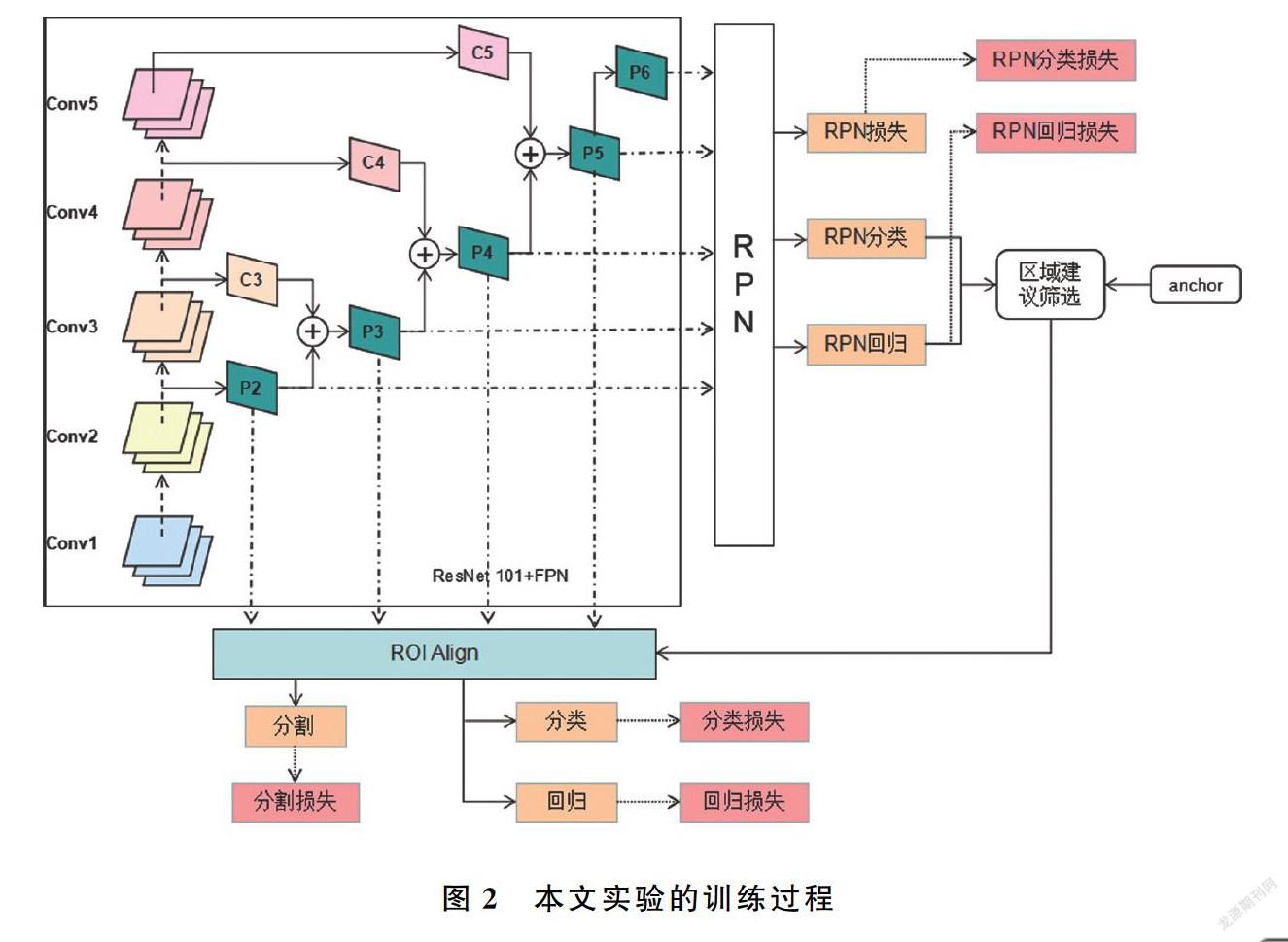
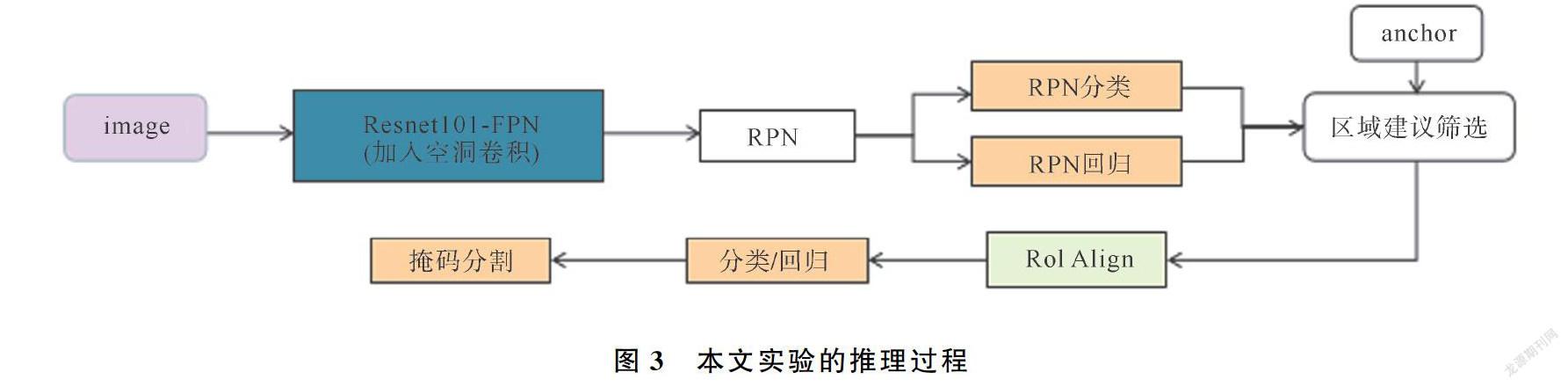
本文提出的網絡結構在訓練過程和推理過程有以下不同:訓練過程要計算RPN損失和網絡損失更新網絡參數,而推理過程不需要計算損失函數;在訓練過程中分類、回歸和掩碼分割是并行計算的,推理過程中,分類/回歸和掩碼分割是串行計算的。圖2和圖3分別為訓練過程和推理過程的網絡結構。
(1)訓練過程。以Resnet101為底層網絡,將原版的FPN網絡中自頂向下路徑改為自底向上,并在FPN的P2~P5層加入空洞卷積構建了高分辨率的特征融合網絡。特征融合后,特征金字塔網絡生成的各層特征進入RPN。另外對RPN生成的每個錨框進行二分類判斷前景和背景,給出該錨框的前景得分并對其進行位置回歸。為了減少計算量以及精確檢測結果需要對錨框進行篩選,選擇適合的錨框進行檢測。隨后對篩選出來的錨框進行RoIAlign,將錨框映射回特征圖,再由映射回特征圖的錨框得到固定大小的特征區域,隨后對每個特征區域進行分類、回歸和掩碼分割,并與真實值作比較,分別計算損失。最后依據整體損失,調整參數,在不斷訓練中最小化損失函數。損失函數為
L=Lcls+Lbox+Lmask(1)
其中,Lcls和Lbox分別表示類別損失函數和邊框回歸函數,其計算方式與Faster R-CNN中的Lcls和Lbox計算方式相同。Lmask是分割分支的損失,mask分支會輸出k×m×m的特征圖,其中k表示輸出的維度,每個維度表示一個類別,m×m表示特征圖大小。Lmask采用平均二值交叉熵函數,只計算對應類別維度的mask損失。
(2)推理過程。推理過程與訓練網絡有所區別,以Resnet-101為主干網絡,將原版FPN中自頂向下路徑改為自底而上,且加入空洞卷積,提出新的特征融合結構。在融合網絡深淺層特征后,RPN網絡對每個生成的錨框進行二分類,判斷其為前景或者背景,以前景得分篩選出合適的錨框,進行RoIAlign操作,再對每個特征區域進行分類、回歸和掩碼分割。
2 實驗
本次實驗數據集為人體圖像數據集,數據集中的圖片在COCO數據集選取或者從網絡下載得到。本次實驗數據集加上背景類共有兩類,其中訓練集圖像2 000張,驗證圖像200張,測試圖像500張。每張圖片中最少有一個人體實例。通過labelme制作相應的掩碼標簽,并標記真實類別。深度卷積網絡需要大量數據進行訓練,為了防止過擬合問題的出現,得到更好性能的網絡模型,在訓練階段使用數據增強技術對數據進行了擴充,對圖片進行隨機旋轉。對原始圖片進行旋轉,圖片對應的掩碼也會做相應的旋轉。圖4所示為旋轉后的圖片及其對應的掩碼。
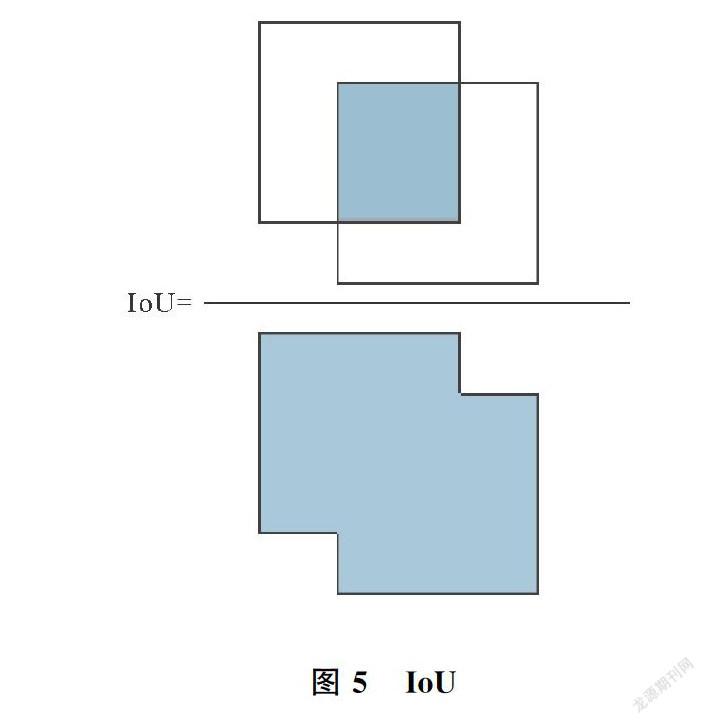
在訓練階段,將原圖、真實框、labelme標記的真實掩碼標簽和真實類別輸入網絡。使用Resnet101作為主干網絡,得到C1到C5不同尺度的特征圖,依次對C2到C5層的特征圖進行降采樣并與其上一層經過降維之后的特征圖進行融合,得到特征圖P2到P5,尺寸大小分別為[256,256,256],[128,128,256],[64,64,256],[32,32,256]。在特征融合過程中使用不同尺度的空洞卷積以得到不同感受野的特征信息,為了消除特征圖相加造成的特征混亂,使用3×3卷積對P2到P5層特征圖進行卷積操作,得到的特征圖作為后續RPN和全連接層的輸入。根據各個特征層的大小得到多個面積和長寬比不同的邊界框,這些邊界框稱為錨框。訓練階段,將每個錨框視為一個訓練樣本,生成的錨框信息包括前/背景得分和偏移量。通過RPN網絡輸出全部錨框的信息,用于訓練RPN損失,訓練時,對前景得分進行排序,保留前景得分最高的6 000個錨框,為了確保不會出現過于重復的推薦區域,修正調整得到候選框,通過非極大值抑制操作保留2 000個候選框。與目標框的交并比(Intersection over Union,IoU)不小于0.5的候選框記為正樣本,否則記為負樣本。從2 000個候選框中選取200個進行后續訓練,其中33%為正樣本。根據正樣本與真實框的重疊率,確定參與訓練的候選框的對應標簽,用于掩碼分支的訓練,在其類別掩碼上計算損失函數。其中IoU的計算如圖5所示。在測試階段,骨干網絡同樣采用Resnet101和改進之后的FPN對圖像進行特征提取和融合,進行RPN操作后,對其輸出的前景得分進行排序,再通過非極大值抑制保留1 000個候選框,對這1 000個候選框進行ROIAlign操作,將其映射成固定大小相應的特征區域,最后對候選框分類,回歸和Mask生成。本次實驗使用的深度學習框架是keras,在圖片輸入的時候將圖片縮放到1 024×1 024大小,為每個GPU 處理1張圖片,錨框的大小設置為(32、64、128、256、512),每個尺寸對應生成寬高比分別為(0.5、1.0、2.0)的錨框,經過130次迭代,學習率為0.02,權重衰減為0.0001,動量為0.9。在Nvidia GeForce GTX 1080ti GPU上進行實驗,圖6是訓練損失函數曲線,曲線總體呈下降趨勢。
為了驗證本文中提出模型的有效性,將本文的模型進行實例分割并與Mask R-CNN算法進行了對比,圖7是Mask R-CNN模型與本文模型得到的實例分割對比圖。圖7(a)、(c)是本文算法的分割效果圖,圖7(b)、(d)是Mask R-CNN算法的分割效果圖,其中第1,4,7列為實驗結果原圖,第2,3,5,6,8列為結果的細節圖。通過圖7的實例分割對比圖來看,本文的模型的分割結果在邊緣上與目標更加貼和,如圖7第5列人體分割圖中,Mask R-CNN算法得到的效果圖有著明顯缺失,本文模型則可以得到更為精準的分割效果。因為在特征融合過程中使用自底向上的結構可以保留更多的空間位置信息,且空洞卷積可以保持特征圖尺寸不變,在一定程度上減少信息損失,提高分割的準確度。
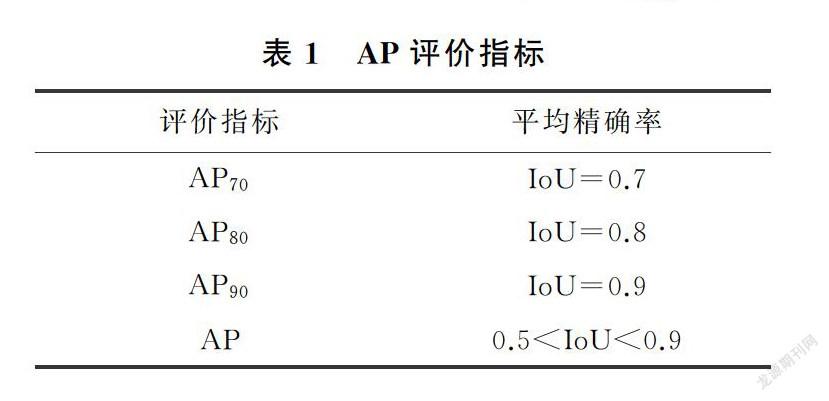
本文以Mask R-CNN算法為比較對象,在不同的IoU閾值下分別計算平均準確率(average precision,AP)來評價本文的性能,AP以召回率為橫坐標,精確率為縱坐標,繪制精確率—召回率曲線,曲線下方的面積為AP
AP=∫10P(R)dR (2)
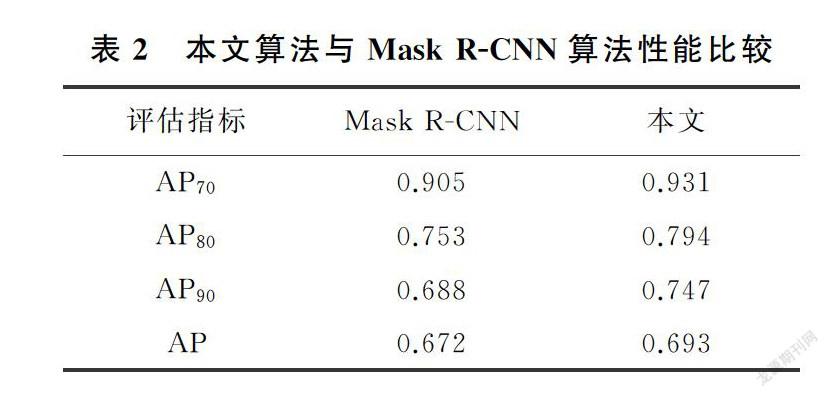
其中,P為精確率,R為召回率,P=TP/(TP+FP)、R=TP/(TP+FN),其中,TP表示被正確預測為正樣本的數量,FP表示負樣本被預測為正樣本的數量,FN表示正樣本被預測為負樣本的數量。AP的評價指標如表1所示,計算結果如表2,可知,與Mask R-CNN算法相比,IoU=0.7,0.8和0.9時本算法準確率分別提高了0.26,0.41和0.59,實驗數據驗證了本文方法的有效性,自底向上的特征融合、多尺度空洞卷積的引入使得本文算法分割精度得到了提升,本文方法有著更高的精度。
3 結論
本文對Mask R-CNN算法進行部分修改做人體實例分割,將原有Mask R-CNN算法的FPN結構,加入空洞卷積進行特征融合。在新的人體數據集上進行對比試驗,并對本文算法的性能加以分析,可知,通過使用自底向上的特征融合路徑和加入空洞卷積,在一定程度上保留了更多的空間位置信息,擴大感受野,保持了全局特征的穩定性。通過對比實驗結果,本文提出的算法改善了Mask R-CNN算法中的邊緣分割失誤的問題提升了平均精度。但本文仍存在著問題,細節分割的邊界不精準,例如人的毛發,這是實例分割中的難點,也是未來研究的重點。
參考文獻
[1]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Columbus, 2014:580-587.
[2]GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV). Santiago, 2015:1440-1448.
[3]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]// 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, 2015: 1137-1149.
[4]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Seattle, 2016:779-788.
[5]REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Honolulu, 2017:6517-6525.
[6]LONG J, SHELLHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Boston, 2015:3431-3440.
[7]CHEN L, PAPANDREOU G, KOKKINOS I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transations on pattern analysis and machine intelligence, 2018,40(4):834-848.
[8]DAI J, HE K, SUN J. Pyramid scene parsing network[C]//30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu, 2017:6230-6239.
[9]HE K, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]//16th IEEE International Conference on Computer Vision(ICCV). Venice, 2017:2980-2988.
[10] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Seattle 2016: 770-778.
[11] LIN T .Y, DOLLAR P, DIRSHICK R, et al. Feature pyramid networks for object detection[C]//30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, 2017:936-944.
[12] 于蘭蘭,張志梅,劉堃,等.侯選框算法在車輛檢測中的應用分析[J].青島大學學報(自然科學版),2018,31(2):67-74.
Person Instance Segmentation Algorithm Based on Dilated Convolution
WANG Chong,ZHAO Zhi-gang,PAN Zhen-kuan,YU Xiao-kang
(College of Computer Science and Technology, Qingdao University, Qingdao 266071, China)
Abstract:
Aiming at the problem of multiple pose and complex background in person instance segmentation, a high-precision instance segmentation algorithm is proposed. By making use of the detailed information in the process of feature fusion of Mask R-CNN, the problem of inaccurat edge segmentation in person instance segmentation is improved, and the accuracy of person instance segmentation is improved. The feature fusion process of feature pyramid is improved. The original top-down path is changed to bottom-up path to retain more spatial details in the shallow feature map, and multi-scale dilated convolution is added in the feature fusion process to increase the receptive field of the feature map while keeping the resolution feature map unchanged, which can avoid information loss caused by down sampled. A new person image dataset is established from COCO dataset and network platform. Finally, compared with the Mask R-CNN, the proposed algorithm improves the accuracy by 0.26, 0.41 and 0.59 when the IOU is 0.7, 0.8 and 0.9 respectively. Experimental results show that algorithm can get more accurate person segmentation effect on the new person image dataset.
Keywords:
instance segmentation; dilated convolution; multi-scale feature fusion
