基于三次精調的人臉分割方法
2021-09-10 07:22:44黃娜趙志剛于曉康
青島大學學報(自然科學版) 2021年2期
黃娜 趙志剛 于曉康











摘要:針對人臉分割的精度問題,提出了融合網絡深層特征和淺層特征的新結構,三次精調人臉檢測框,提高人臉分割的精確度。新結構結合通道注意力與空間注意力機制,利用深度分離卷積,為每個通道特征提供各自對應的注意力權重,充分利用深層語義信息與淺層定位信息,為精確分割提供特征信息,三次精調為分割提供準確的檢測結果。實驗結果相比Mask R-CNN的mAP提高0.1,相比最新方法mAP提高0.2。
關鍵詞:人臉分割;精調;通道注意力;空間注意力
中圖分類號:TP391
文獻標志碼:A
收稿日期:2020-09-30
通信作者:
于曉康,男,博士,副教授,主要研究方向為計算機幾何,計算機圖形學,計算機視覺等。E-mail: xyu_qdu@163.com
人臉是非常重要的特征,人臉檢測、人臉識別、人臉分割等技術廣泛應用于安全、通信、醫療、社交等領域。Cuevas等[1]提出對光照變化有健壯性的人臉分割方法;Segundo等[2]提出基于人臉關鍵點的人臉分割算法;Subasic等[3]提出適用于電子身份文件識別的人臉分割模型;Khan等[4]以多任務的方式提出頭部姿態估計和人臉分割的模型;Masi等[5]在人臉檢測之后,通過3D投影計算得到完整的人臉形狀,再通過已有的人臉分割網絡得到有誤差的人臉分割,計算兩者之間的差異,構造新的損失函數,為人臉分割提供了新思路;Wang等[6]通過強化學習訓練模型,分割視頻中的人臉。但現實中人臉遮擋的情況復雜多樣,現有模型對于不同場景不同弧度的人臉邊界,還是無法精確分割。實例分割方法也不斷更新,經典方案Mask R-CNN[7]在目標檢測網絡Faster R-CNN[8]的基礎上,加入特征金字塔網絡FPN,提出RoIAlign方法代替RoIPooling,僅添加了一個mask分支做分割,取得不錯的實驗效果。Masklab[9]相比于Mask R-CNN,加入方向預測的分支與mask分支特征結合;MS R-CNN[10]在Mask R-CNN中添加了MaskIoU Head分支完善評分依據。這些提高分割精度的方法多數是通過增加新的任務分支,來提供給mask分支補充信息,輔助分割任務以獲得更好的效果,但沒有關注目標檢測和網絡中間層特征對分割精度的影響。近年來在CNN中應用注意力機制的研究逐漸展開,Hu[11]認為通道注意力SE模塊能夠提高分類任務的準確率;BiSeNet[12]借鑒SE模塊,將注意力機制應用到語義分割任務中;SKNet[13]利用注意力機制融合不同層的特征;Woo[14]提出相加融合通道注意力和空間注意力分支特征。但這些已有的空間注意力對不同通道并沒有區分,使網絡中間層特征沒有得到充分利用,同時檢測結果不準確也造成了人臉分割不精確,本文針對以上問題提出改進方法。
1 方法分析與方案
在分割任務中,檢測階段的結果至關重要,通常將檢測框緊貼實例的邊界定義為好的檢測結果。人類臉型有多種,加上不同發型遮擋,不同姿勢角度的拍攝,使圖像中人臉邊界弧度不同,甚至存在尖角,這給檢測和分割任務增加了困難。二階段檢測通常采用兩次相同的框體調整方法,先對框體的中心位置進行調整,再以中心位置為基準,調整框體四條邊的位置。在調整四條邊的位置時,對上邊界和下邊界使用相同的調整值,對左邊界和右邊界使用相同的調整值。存在的問題是,在中心位置沒有得到準確調整時,后續進行的邊框調整并不準確。針對此問題提出了改進方法,加入第三次調整分支,固定框體的中心位置不動,給出四條邊各自不同的調整值。在測試過程中,串聯在第二次框體調整之后,進行第三次精調。在訓練過程中,訓練目標由初始極值點與真實極值點計算差值得到,損失函數采用smoothL1損失函數。第三次精調分支結構如圖1,對于RoIAlign截取到的7×7×256的人臉特征,分別進行無邊界填充的7×7卷積操作、全局平局池化和全局最大池化操作,拼接兩種池化的結果,輸出特征維度為1×1×512,一層1×1的卷積+relu激活,一層1×1的卷積+sigmoid激活獲得通道感知。得到的通道感知與7×7的卷積結果相乘,作為殘差分支加入7×7的結果分支再做一次relu激活。最后經過一層1×1的卷積+BN操作+relu激活,全連接調整維度,得到4條邊各自的調整值。
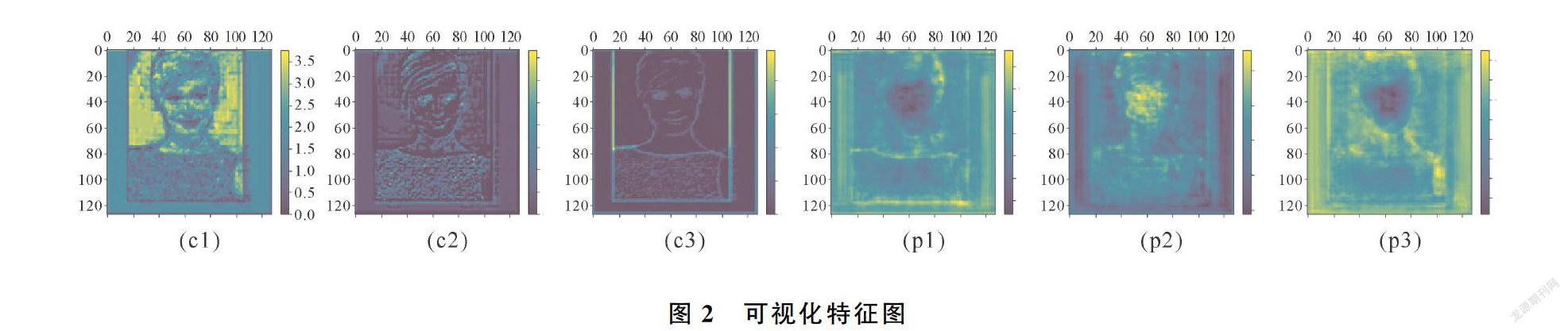
特征金字塔網絡FPN將網絡深層的語義信息傳遞到淺層,淺層特征有了語義信息的補充,但是定位信息有所丟失,影響人臉分割結果,尤其是小面積人臉,因為小面積人臉的特征是在網絡淺層截取的。圖2的(c1)、(c2)、(c3)為主干網絡resnet-101的C3特征,疊加深層特征后為(p1)、(p2)、(p3),疊加后的特征更模糊不清。PANet[15]改進了FPN也只是考慮將淺層定位信息傳遞到網絡深層。針對以上問題,本文結合注意力機制,提出融合深淺特征的新結構,充分利用網絡深層特征和淺層特征。主干網絡resnet-101的C4、C5層的輸出通道數分別是1 024、2 048,通過1×1的卷積降維到256個通道,信息的損失很大,因此對于C4、C5層特征,由模塊attention-A替換普通的1×1的卷積,如圖3。
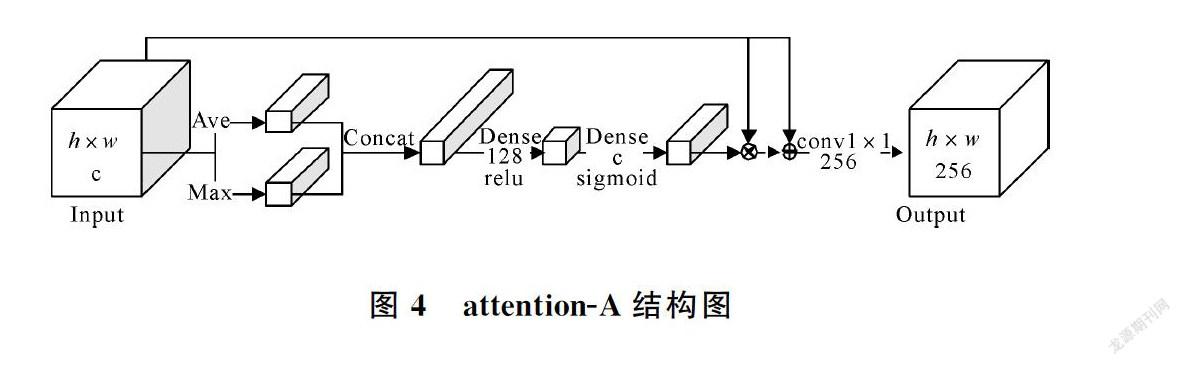
模塊attention-A的結構見圖4,先對輸入特征分別做全局平均池化和全局最大池化,拼接兩種池化的結果,第一次全連接降維到128通道+relu激活,第二次全連接調整維度與輸入特征通道相同+sigmoid激活,得到各通道的權重,與輸入特征對應通道相乘,受resnet的啟發,再與輸入特征相加。經過attention-A,有利的通道特征獲得更大的權重,特征得到了增強。已有的基于空間的注意力是應用于所有通道的,由此提出注意力模塊attention-B,結合通道注意力機制和空間注意力機制,為每個通道特征生成各自不同的注意力,具體結構如圖5所示。對于輸入特征Input,三個并列的分支分別做上采樣操作、全局平均池化操作和全局最大池化操作。對上采樣放大后的特征先進行
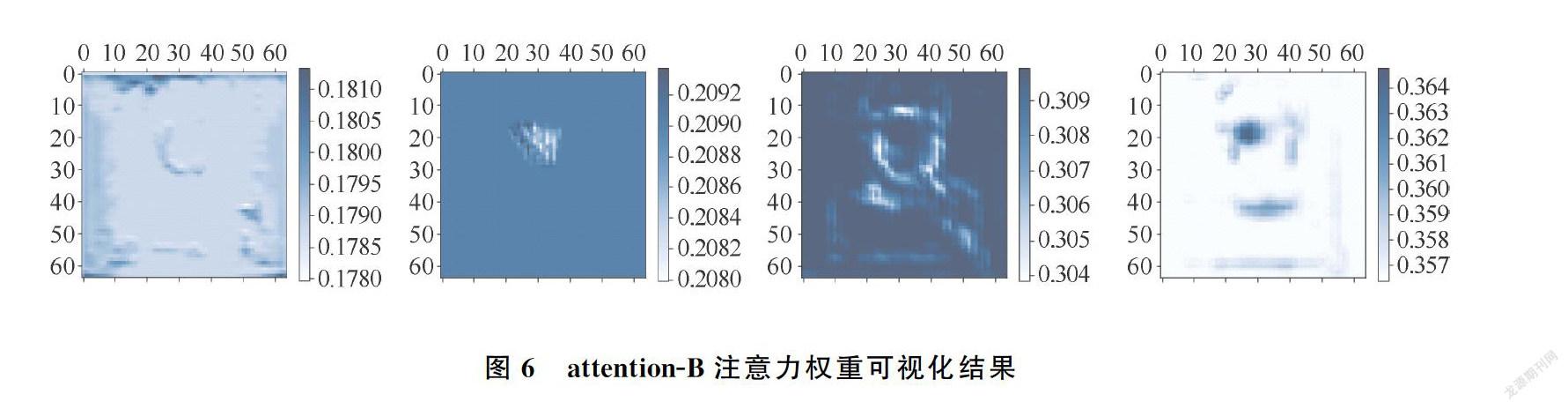
一層3×3Depthwise卷積操作+relu激活,再進行一層3×3 Depthwise卷積操作+sigmoid激活,得到每個通道各自的空間注意力。全局平均池化操作和全局最大池化操作的結果相拼接,一層全連接層降維到128通道+relu激活,一層全連接層恢復維度到256通道+sigmoid激活,得到通道注意力。將兩種注意力相乘,再與放大的特征相乘。受文獻[12]啟發,再將相乘的結果與放大特征相加,得到經注意力機制引導的深層特征,加到淺層特征中。圖6可視化C5到C4層的attention-B生成的權重,證實能夠得到每個通道不同的注意力。
2 實驗
為使模型得到有效訓練,訓練集需要多種面積的人臉圖像,本文實驗組合了300 Face in Wild數據集、Multi-Task Facial Landmark (MTFL)數據集、coco數據集中不同大小的人臉圖像,其中訓練集1 800張,驗證集240張,使用labelme標注工具制作訓練目標,實驗選用resnet-101做主干網絡,為減少GPU內存的使用,設定resnet-101的C1-C4層不參與訓練,使用在coco數據集預訓練的權值。由本文提出的attention-A、attention-B結構融合深淺層特征,第一、二次的框體調整與RPN網絡的調整方法相同,第三次框體調整由本文提出的第三次精調分支調整,調整后截取對應的特征進行分割預測。整體損失函數為
L=Lrpn_class+Lbox1+Lclass+Lbox2+Lbox3+Lmask(1)
其中,Lrpn_class表示RPN網絡的前背景分類損失,Lbox1表示第一次框體調整分支的損失,Lclass表示最終的分類損失,Lbox2表示第二次框體調整分支的損失,Lbox3表示第三次精調分支的損失,Lmask表示人臉分割mask的損失,L計算整體損失和。每次迭代訓練1 800張圖,共迭代200次,初始學習率0.03,學習率衰減0.01,權重衰減為0.000 1,動量為0.9。實驗環境Intel(R) Core(TM) i5-3570K CPU,Nvidia GeForce GTX 1080 GPU,tensorflow-gpu2.0,keras2.3。
2.1 人臉檢測實驗結果
圖7展示了Mask R-CNN和本文方法的人臉檢測結果,實驗過程中主干網絡、參數設置一致。可見本文提出的第三次精調分支是有效的,三次調整后的檢測框能更好的貼合人臉。表1和表2計算了人臉檢測的平均IoU和IoU閾值在0.5~0.95之間的mAP,本文方法的結果更優。其中IoU是預測框pre_box和真實框gt_box的交集和并集的比值
IoU=pre_box∩gt_boxpre_box∪gt_box(2)
評價指標mAP由準確率Precision和召回率Recall計算得到。準確率Precision
Precision=TPTP+FP(3)
召回率Recacll
Recall=TPTP+FN(4)
其中,TP表示被預測為正,實際也為正的樣本數量;FP表示被預測為正,實際為負的樣本數量;FN表示被預測為負,實際為正的樣本數量;TN表示被預測為負,實際為負的樣本數量。大于IoU閾值的記為正樣本,小于IoU閾值的記為負樣本。平均準確率AP的計算取召回率變化的節點劃分區間,取對應區間準確率的最大值與區間長度相乘作為區間AP,最后區間AP相加得到最終的平均準確率AP,mAP是計算多種IoU閾值的AP均值。
2.2 人臉分割實驗結果
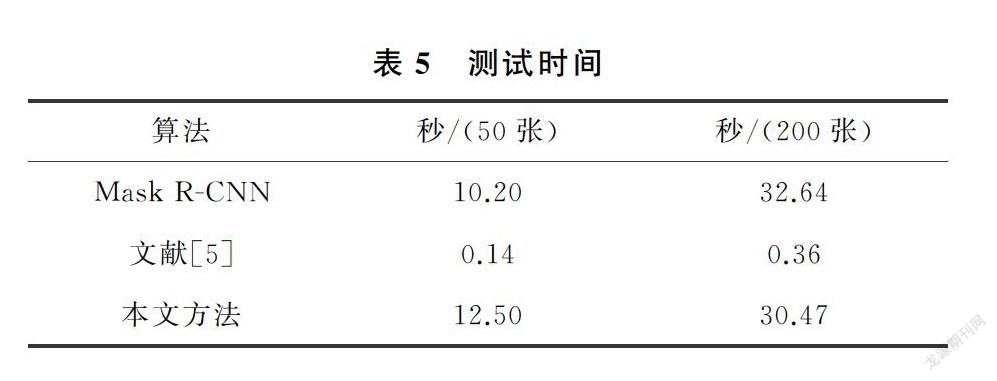
Mask R-CNN、文獻[5]和本文方法的人臉分割結果如圖8,實驗結果證明第三次精調分支能有效提高檢測的準確度,進而提高人臉分割的精確度。本文提出的深淺層特征融合結構能更好的結合網絡深層的語義信息和淺層精確的定位信息,對弧度較大的人臉邊界分割更精確。表3計算了三種方法的AP和mAP,IoU由預測人臉mask和真實人臉mask label計算得到。由表中數據可見本文方法的準確率更高,文獻[5]由于網絡結構較簡單,特征提取不夠充分,準確率略低,但為人臉分割領域提供了新思路。表4使用同樣的驗證集測試,比較了文獻[5]和本文預測mask與真實mask label的IoU,結果表明本文算法的分割精確度更高。由于增加了一次框體調整步驟,融合深淺層特征的結構也比單純卷積操作復雜,本文算法整體復雜度略高。表5計算了Mask R-CNN、文獻[5]和本文方法的測試用時,分別為處理50張圖像和200張圖像的用時。由于文獻[5]的模型網絡結構較為簡單,用時很少,本文方法由于網絡結構較為復雜,用時略長,但精確度更高。
3 結論
本文提出融合深淺層特征的新結構,充分利用網絡深層語義信息和淺層定位信息,三次精調檢測框。通過給出四條邊框各自不同的調整值,提高人臉檢測的準確度,進而提高人臉分割的精確度。但在人臉分割任務中,對于頭發等細致的物體對人臉造成遮擋時,分割的精度還有待提高。現有的人臉分割網絡計算量較大,如何精簡網絡算法,提高計算速度,也是今后繼續深入研究的方向。
參考文獻
[1]CUEVAS E, ZALDIVAR D, PEREZ M, et al. LVQ neural networks applied to face segmentation[J]. Intelligent Automation & Soft Computing, 2009, 15(3):439-450.
[2]SEGONDO M P, SILVA L, BELLON O R P, et al. Automatic face segmentation and facial landmark detection in range images[J]. IEEE Transactions on Systems Man & Cybernetics Part B Cybernetics, 2010, 40(5):1319-1330.
[3]SUBASIC M, LONCARIC S, HEDI A. Segmentation and labeling of face images for electronic documents[J]. Expert Systems with Applications, 2012, 39(5):5134-5143.
[4]KHAN K, AHMAD N, KHAN F, et al. A framework for head pose estimation and face segmentation through conditional random fields[J]. Signal, Image and Video Processing, 2019, 14(1):159-166.
[5]MASI I, MATHAI J, ABDAIMAGEED W. Towards learning structure via consensus for face segmentation and parsing[C]// 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, 2020:5507-5517.
[6]WANG Y J, DONG M Z, SHEN J, et al. Dynamic face video segmentation via reinforcement learning[C]// 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, 2020:6957-6967.
[7]HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]// 16th IEEE International Conference on Computer Vision (ICCV).Venice, 2017:2980-2988.
[8]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 36(6):1137-1149.
[9]CHEN L C, HERMANS A, PAPANDREOU G, et al. MaskLab: Instance segmentation by refining object detection with semantic and direction features[C]// 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018:4013-4022.
[10] HUANG Z J, HUANG L C, GONG Y C, et al. Mask scoring R-CNN[C]// 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, 2019:6402-6411.
[11] HU J, SHEN L, SUN G, Squeeze-and-excitation networks[C]// 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Salt Lake City, 2018:7132-7141
[12] YU C Q, WANG J B, PENG C, et al. BiSeNet: Bilateral segmentation network for real-time semantic segmentation[C]// 15th European Conference on Computer Vision(ECCV). Munich, 2018:334-349.
[13] LI X, WANG W H, HU X L, et al. Selective kernel networks[C]// 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach, 2019:510-519.
[14] WOO S, PARK J, LEE J, et al. CBAM: convolutional block attention module[C]// 15th European Conference on Computer Vision (ECCV). Munich, 2018:3-19.
[15] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018:8759-8768.
[16] WANG F, JIANG M Q, QIAN C, et al. Residual attention network for image classification[C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, 2017:6450-6458.
Face Segmentation Method Based on Three-fold Fine Tuning
HUANG Na, ZHAO Zhi-gang, YU Xiao-kang
(College of Computer Science and Technology, Qingdao University, Qingdao 266071, China)
Abstract:
As regards the precision of face segmentation, a new structure combining the deep and shallow features of the network was proposed, and the face detection frame was fine-tuned three times to improve the accuracy of face segmentation. The new structure combined the mechanisms of channel attention and spatial attention, and utilized depthwise separable convolution to provide corresponding attention weight for each channel feature. And semantic and location information were fully used to provide feature information for precise segmentation, and the third fine-tuning provides accurate detection results for segmentation. Compared with Mask R-CNN, the experimental results of this paper increase mAP by 0.1 and 0.2 compared with the latest method.
Keywords:
face segmentation; fine-tuning; channel attention; spatial attention
