基于改進BP神經網絡的音樂流派分類
2021-09-13 02:27:43樊思含
軟件工程 2021年9期
摘? 要:針對傳統音樂流派分類模型性能不穩定、音樂信號特征單一導致分類準確率低的問題,提出了改進的BP神經網絡(Back Propagation Neural Network)音樂流派分類模型,通過Python的Librosa庫提取了音樂的均方根能量、過零率、頻譜質心、頻譜對比度等多種特征,并使用PCA(Principal Component Analysis)和LDA(Linear Discriminant Analysis)數據降維方法對特征數據進行可視化分析,證明了特征選取的合理性。最后對四類音樂流派進行仿真實驗,并與傳統的分類模型對比。實驗證明,提出的模型10 折交叉驗證的準確率為93.12%,優于KNN(K-Nearest Neighbor)、SVM(Support Vector Machine)等傳統的分類模型。
關鍵詞:機器學習;特征提取;支持向量機;梅爾頻率倒譜系數
中圖分類號:TP39? ? ?文獻標識碼:A
文章編號:2096-1472(2021)-09-17-04
Abstract: Classification models of traditional music genre have problems of unstable performance and low classification accuracy caused by single characteristics of music signals. In view of these problems, this paper proposes an improved BP (Back Propagation) Neural Network music genre classification model. Various features such as root mean square energy, zero crossing rate, spectral centroid, and spectral contrast of music are extracted through the Librosa library of Python. Then, visual analysis of the feature data using PCA (Principal Component Analysis) and LDA (Linear Discriminant Analysis) data dimensionality reduction methods has proved the rationality of feature selection. Finally, simulation experiments are conducted on four types of music genres, and compared with the traditional classification model. The experiment proves that the accuracy of the 10-fold cross-validation of the model proposed in this paper is 93.12%, which is better than traditional classification models such as KNN (K-Nearest Neighbor) and SVM (Support Vector Machine).
Keywords: machine learning; feature extraction; SVM; MFCC
1? ?引言(Introduction)
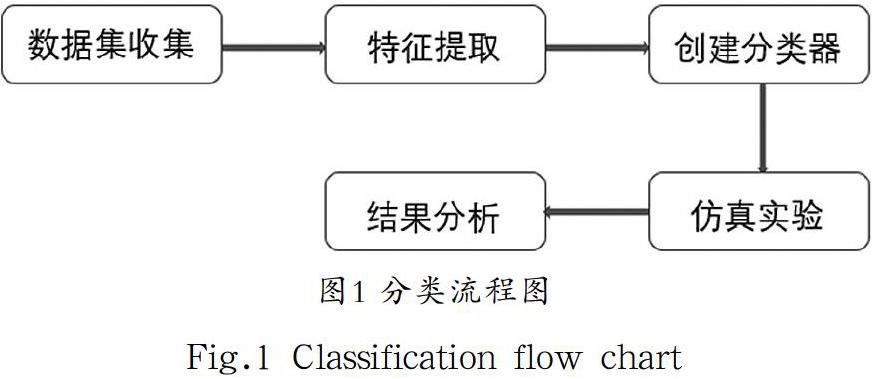
隨著多媒體技術的發展,音樂以各種方式出現在人們身邊,面對網絡上海量的音樂,不同的人喜好差異較大,為方便檢索,對音樂流派進行分類尤為重要。莊嚴[1]等人提出了一種基于譜圖分離的音樂流派分類算法,通過對音樂信號的譜圖濾波,分離出音樂的打擊與和聲部分,對特征進行優化,通過SVM分類器對8 種音樂流派進行仿真實驗,最終達到73%的準確率。陸歡[2]則采用梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficients, MFCC)特征矩陣作為音樂信號的特征,訓練了卷積神經網絡作為分類器,在4 種音樂流派上得到88%的結果。本文借助于Python的Librosa庫,研究了音樂信號的某些時域特征和頻域特征,選取了過零率、均方根能量、頻譜質心、滾降截止頻率、頻譜對比度、梅爾頻率倒譜系數作為音樂數據集的特征,有效解決了單一特征造成的分類準確率低的問題。最后借助機器學習的工具,建立了一個4層的BP神經網絡模型,實現了有效分類。音樂流派分類主要流程如圖1所示。
2? 數據處理和特征提取(Data processing and feature extraction)
2.1? ?數據集
本文中使用的數據集是公開的GTZAN數據集[3],該數據集包含10 種音樂流派,每種流派各有100 段時長為30 秒,采樣頻率為22.05 kHz的16 bit的數字信號。本文選取了布魯斯(bules)、古典(classical)、鄉村(country)、金屬(metal)共4 種音樂流派,共400 個樣本。
2.2? ?特征提取
語音信號具有短時平穩性,即在一個短時間范圍(10 ms—30 ms)內,其特性基本保持不變,因此,對于語音信號的分析都是建立在“短時”的基礎上[4]。在提取語音信號的特征時,首先對信號進行分幀加窗處理,特征提取函數的返回值是每一幀上的結果,選取每個特征在所有幀上的平均值和方差作為該文件的特征,這樣,對于一個音頻文件,提取出來的特征向量的維度是46。特征提取在音樂流派分類中占有非常重要的地位,針對單一特征導致分類準確率低的問題,本文基于Python中的Librosa庫提取了過零率、均方根能量等多種特征[5],特征名稱及其維度如表1所示。
(1)過零率是信號相鄰兩個采樣點取值為異號的次數,它可以對敲打的聲音進行區分[6]。
(2)均方根能量是每一幀內采樣點能量的標準差,可以用來區分有聲和無聲,輕音和濁音[1]。
(3)頻譜質心是用來表征頻譜的度量,表示“質心”的位置,與聲音的亮度有關,值越小,說明越多的能量集中在了低頻的范圍內。圖2(a)和圖2(b)分別展示了blues和metal兩種不同流派的音樂頻譜質心的位置,可以看到,相比于metal,blues的頻譜質心“更低”,且能量主要在低頻范圍。
(4)滾降截止頻率是譜形狀的重要測度,85%的幅度分布低于該頻率[6],表示能量大幅上升(或大幅下降)、失去“阻止”(或失去“通過”)信號效果的位置。
(5)頻譜對比度是信號的幅度譜在每個子波段上峰值與峰谷平均能量的差,高對比度值通常對應于清晰的窄帶信號,而低對比度值對應于寬帶噪聲。
(6)梅爾頻率倒譜系數是語音信號處理中被廣泛使用的
特征,由于人耳聽到聲音的高低與聲音的頻率之間的關系并不是線性關系,頻率尺度更符合人耳的聽覺特性[4],頻率與實際頻率之間的關系可以表示為:它的計算方式在文獻[4]中都有詳細描述,這里不再贅述。
2.3? ?特征數據的降維分析
數據降維方法有多種,線性降維算法因其實現簡單快速的特點應用廣泛,主成分分析(PCA)和線性判別分析(LDA)是線性降維中兩種經典的算法。實驗中,分別使用PCA和LDA對提取的46維特征數據進行降維分析,并將其可視化,圖3為PCA降維的結果,圖4為LDA降維的結果。
從圖3中可以看到,通過PCA算法將46 維特征降為2 維后,classical和metal可以被很好的分開。與PCA不同的是,LDA在計算類內散度和類間散度時應用了數據的標簽[7],因此LDA是一種有監督的降維方法。從圖4中可以看到,經過LDA降維,特征數據被分成了較為明顯的四類,其中,classical、country和metal分類效果較好,從而反映出本文特征選取的合理性。
3? 基于正則化的BP神經網絡(BP neural network based on? regularization)
3.1? ?神經網絡基礎
BP(Back Propagation)神經網絡是1986 年由Rumelhart和McClelland為首的科學家提出的,它是基礎的也是目前應用最廣泛的神經網絡之一。圖5展示了具有兩個隱藏層的神經網絡結構圖。
信號通過輸入層、隱藏層、輸出層前向傳播得到預測值,利用損失函數衡量預測值與真實值之間的誤差,從最后一層反向傳播誤差[8],通過適當的優化器,比如梯度下降,隨機梯度下降等更新權重參數和偏置參參數,最小化誤差,從而使預測值與真實值更接近。神經網絡中前向傳播和反向傳播的偽代碼如表2和表3所示。
其中,是由樣本數據為行向量組成的輸入矩陣,代表神經網絡的層數,表示第層神經網絡的輸出,是激活函數,是層到層的權重矩陣,,表示樣本的真實標簽組成的向量,表示梯度下降的學習率,表示哈達瑪積(Hadamard Product),即對于向量,
3.2? ?網絡結構
本文設計的神經網絡包含3 個隱藏層,神經元的個數分別為128、64、32。ReLU激活函數又稱為修正線性單元,表達式為,由于其具有單側抑制,稀疏激活等優點,故選其作為隱藏層的激活函數。選擇多分類對數損失作為損失函數,如果目標值為時預測結果為,分類的交叉熵為:。優化器則選擇隨機梯度下降,這是因為相比于普通的梯度下降算法,隨機梯度下降的收斂速度更快。本文研究的是四分類問題,所以輸出層的神經元個數為4,輸出層的激活函數為Softmax函數。由于本文的數據量較少,并且樣本的特征差異不大,為了防止過擬合,在設計神經網絡結構時加入正則項,因此優化模型可以表示為:
其中,是損失函數,是權重矩陣的列向量,為正則項,為正則化系數。經過多次調試,最終確定正則化系數為0.004。圖6展示了增加正則項與未增加正則項時模型在訓練集和測試集上準確率和損失值隨著每期訓練的變化曲線(圖6(a)和圖6(c)為增加正則項后曲線圖,圖6(b)和圖6(d)為未增加正則項曲線圖)。從圖6(a)和圖6(b)中可以看出,模型在訓練集上表現較好,準確率達到1,而增加正則項后,無論是測試集上的準確率還是損失值變化曲線都更貼近訓練集,且經過300 期訓練后準確率略微有些提高。
4? 實驗結果與分析(Experimental results and analysis)
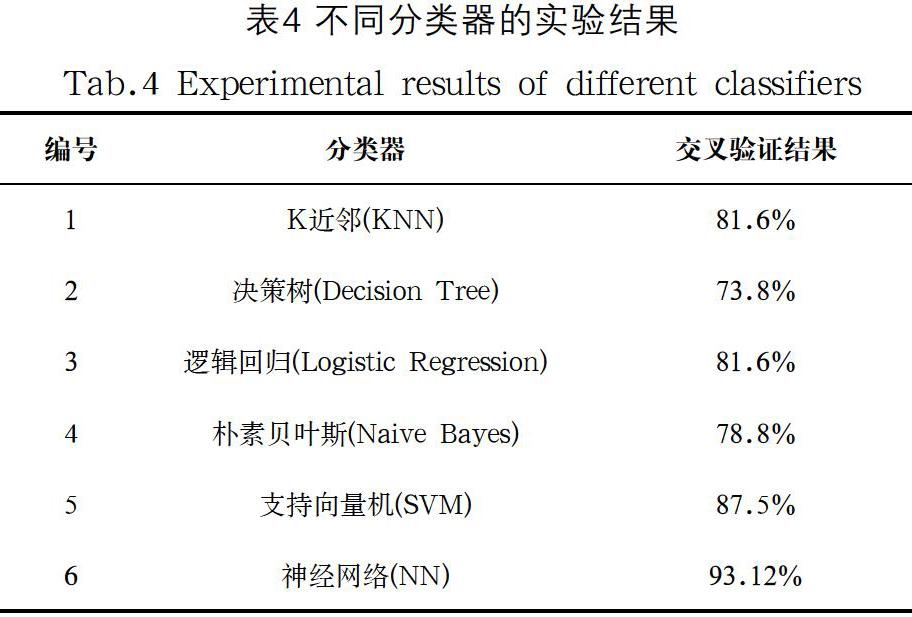
本文按照4∶1的比例劃分訓練集和測試集,從總樣本中選取80 個樣本組成測試集,其中每種音樂流派各20 個。剩余320 個樣本作為訓練集,在訓練集上進行10 折交叉驗證,即將訓練集分成10 個非重疊的部分,每次選其中一部分作為驗證集,其余9 部分作為訓練集。共進行10 次訓練,選取模型在驗證集上10 次準確率的平均值為模型最終得分。具體分類結果如表4所示,可以看到,除決策樹外,其他模型的準確率均在80%左右,本文建立的神經網絡模型(NN)得到的準確率最高,達到93.12%。
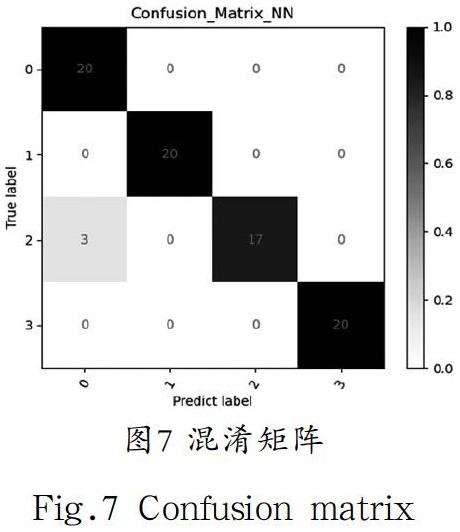
接下來分析模型對每種音樂流派具體的分類結果,我們繪制出模型在測試集上的混淆矩陣如圖7所示,其中0代表blues,1代表classical,2代表country,3代表metal。橫坐標軸表示的是預測類別的標簽,縱坐標軸代表的是真實類別的標簽。該模型對blues、classical和metal三種流派能做到精準分類,對于country的區分效果相對較差,誤將3 個country類別的文件識別成了blues,我們猜想原因與所提取的特征不能有效將這兩種音樂類別區分有關,圖3和圖4可視化的結果也驗證了這一點。
5? ?結論(Conclusion)
音樂流派分類作為音樂信息檢索領域比較熱門的方向,涉及信號處理、模式識別、計算機、數學等多門學科,引起眾多學者的研究,無論是在特征提取還是分類器的選擇上都提出了許多新方法。本文選取的音樂特征雖能夠對不同流派的音樂進行區分,但也存在一定的不足,需要尋求更多特征以保證分類的準確率。其次,本文建立的神經網絡分類模型在四分類上有不錯的表現,但是當音樂種類增多時,分類效果會有一定程度的下降,需要在模型上做進一步的優化。
參考文獻(References)
[1] 莊嚴,于鳳芹.基于節奏和韻律調制譜特征的音樂流派分類[J].計算機工程,2015,41(1):186-189.
[2] 陸歡.基于卷積神經網絡的音樂流派分類[J].電子測量技術,2019,42(21):149-152.
[3] TZANETAKIS G, COOK P. Musical genre classification of audio signals[J]. IEEE Transactions on Speech and Audio Processing, 2002, 10(5):293-302.
[4] 趙力.語音信號處理[M].北京:機械工業出版社,2016:6-84.
[5] 張俊生,郭彩萍,樓國紅,等.Python在數字信號處理中的應用[J].電氣電子教學學報,2015,37(04):115-117.
[6] 黃琦星.基于卷積神經網絡的音樂流派分類模型研究[D].長春:吉林大學,2019.
[7] 趙玉娟.數據降維的常用方法分析[J].科技創新導報,2019,32(16):118-119.
[8] NIELSEN M. Neural networks and deep learning[M]. San Francisco: Determination Press,2015:34-109.
作者簡介:
樊思含(1995-),女,碩士生.研究領域:機器學習,計算數學.
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年11期)2017-04-04 02:52:58
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科學與財富(2016年28期)2016-10-14 21:19:17
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
