河北省治超處罰聯網系統的設計與實現
2021-09-13 22:17:10左曉飛高志偉丁曉楠葛紅志陳繼寶
計算機與網絡 2021年14期
左曉飛 高志偉 丁曉楠 葛紅志 陳繼寶

摘要:為了更好地提升治超效果,加強對違規超載運輸車輛、駕駛員和企業的管理,設計了治超處罰聯網系統,通過采集外部系統的處罰數據和車輛、駕駛員、運輸企業等基礎數據,并按照相應規則對數據進行清洗、規范化處理和存儲,從而滿足黑名單的生成。系統實現了治超處罰形勢綜合分析預測、處罰信息管理、黑名單管理和處罰備案等功能,為治超工作提供助力。
關鍵詞:超限超載;黑名單;數據治理;前后端分離
中圖分類號:TP393 文獻標志碼:A 文章編號:1008-1739(2021)14-53-4
0引言
近年來隨著國家對公路貨運車輛超限超載整治和處罰力度的加大,各地治超形勢穩定好轉,道路交通運輸行業健康有序發展。但是,由于利益驅使,部分車輛運營單位一味地追求利潤,存在僥幸心理,在交管部門下班時間或夜間進行超限超載運輸Ⅲ,給公路運輸安全帶來了不小的隱患。超限超載運輸對公路危害極大,嚴重損害公路的使用年限,同時也是引起交通事故的主要原因之一,對人民群眾的生命財產安全帶來極大的安全隱患,此外超限超載也嚴重干擾運輸市場的正常運營,不利于我國市場經濟的健康有序發展。
為了更好地提升治超效果,加強對違規超載企業、貨運車輛和駕駛員管理,將路面及源頭查獲的違規超載企業、貨運車輛和駕駛員處罰信息進行聯網,建立黑名單制度,對黑名單中的企業、車輛、駕駛員和源頭企業進行處罰,從而減少相關人員和單位重復超限超載的次數。
本文設計的治超處罰聯網系統,通過對接已有車輛駕駛員企業基礎信息系統和治超執法系統,實現了全省超載超限信息的聯網處理,并能夠根據黑名單制度自動生成違規超載企業、車輛、駕駛員和源頭企業黑名單。
1系統設計
系統的道路運輸從業企業、貨運車輛和駕駛員等基礎數據依托基礎信息系統,違規超限超載信息來源于治超執法系統,涉及到外部系統的數據融合治理,是本系統的設計難點和重點。
數據治理是將已有系統進行融合實現數據共享,減少信息孤島的必要步驟,通過數據治理可以實現數據的標準化,將原先相互隔離的系統變為互聯互通的整體,真正實現各種數據的融合和共享,推進數據的資產化和價值化。系統數據治理主要流程包括數據采集、數據清洗與規范化、數據存儲。
1.1數據采集
系統需要融合2個不同系統的數據,這2個系統的數據結構、存儲方式和數據提供方式均有較大差別,因此根據各自系統的特點設計了2種數據采集方式。
(1)數據庫同步方式
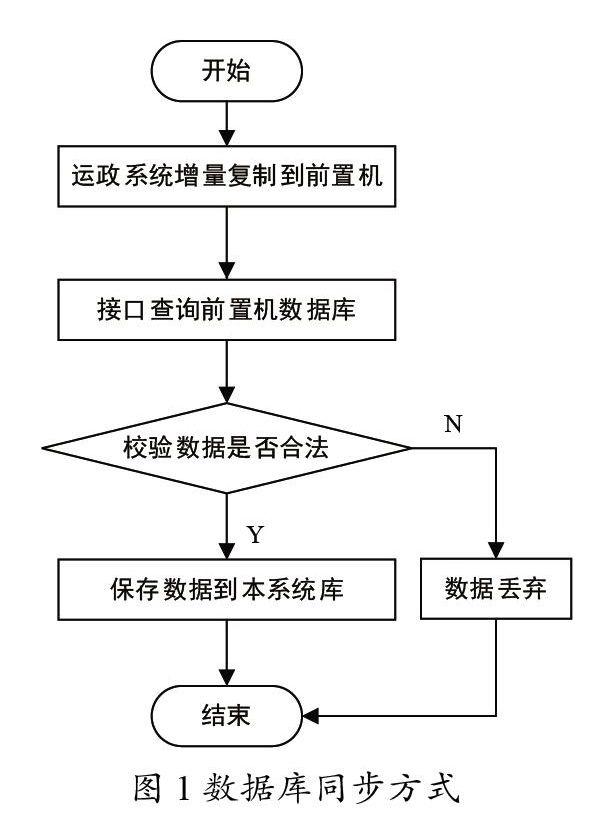
道路運輸從業企業、貨運車輛和駕駛員等基礎數據由于數據量較大,且更新頻率不高,故采用數據庫同步方式進行2個系統的數據同步,具體實現方式如圖1所示。
①運政系統將前一日的新增和修改的基礎數據通過增量復制方式同步到前置初數據庫中;②系統接口查詢前置機數據庫,獲取增量復制同步的基礎數據;③循環判斷數據是否合法;④若數據不合法,則該數據直接丟棄,不予處理;⑤若數據合法,則將該數據保存到本系統數據庫;⑥本次數據同步結束。
(2)接口拉取方式
違規超限超載信息屬于變化較快的動態數據,每日均會有新數據產生,是本系統生成黑名單的原始數據來源,直接關系到本系統的運行成效,因此采用接口拉取方式,每日凌晨2點定時從冶超執法子系統獲取前一日全省違規超載超限信息,具體實現方式如圖2所示。由于接口拉取方式獲取數據需要通過網絡,如只調用一次接口獲取當日所有超限超載信息,則會出現數據傳輸耗時長、接口等待時間超時的問題,因此設計了循環調用、多次獲取的方式。
①本系統開始拉取前一日數據;②從數據庫獲取開始時間;③調用治超執法子系統接口獲取數據;④判斷獲取的數據條目是否達到100條;⑤若不足100條,則更新開始時間;⑥若達到100條,則開始第2次拉取,并取最后一條數據的時間為開始時間;⑦從步驟②開始循環,直到運行到步驟⑤;⑧本次接口拉取數據結束。
1.2數據清洗與規范化
數據采集后就需要進行數據清洗和規范化處理,之所以要進行這一步,主要是因為外部系統的數據規范同本系統采用的標準有差別,或者是由于外部系統所采用的規范標準比較陳舊已不能滿足最新需求,此外對一些明顯錯誤的數據進行了清洗。主要進行如下幾方面的清洗和規范化。
(1)重復數據清洗
由于系統在統計企業黑名單時對該企業車輛數據的準確性要求較高,車輛統計比實際多或者比實際少,都會影響企業違規占比的計算結果,對企業是否進入黑名單有直接關系。因此系統在獲取到車輛數據后,對車牌重復的車輛進行了去重。
(2)錯誤數據清洗
對拉取的企業、車輛和駕駛員中的明顯錯誤數值進行更正,確保數據的正確性。對拉取的違規超載超限數據的車牌號進行規范和解析,部分車牌號前面有車牌顏色文字,因此需要將車牌顏色和車牌號屬性分別解析并提取。此外也有車牌號是車頭牌照加掛車牌照的組合,因此需要將車頭牌照和掛車牌照分別解析并提取。
(3)行政區劃代碼規范
由于運政信息系統所采用的行政區劃代碼同本系統采用的國家民政部行政區劃代碼有差別,因此對不一致的行政區劃代碼的數據進行相應的轉換,以便于在本系統內進行使用。
1.3數據存儲
系統采集的數據經過清洗和規范化后就需要做持久化,根據數據的更新及訪問頻率采取不同的存儲策略,對于行政區劃、車牌顏色、車輛軸數等更新頻率較低、查詢頻率較高的字典類型數據采用內存數據庫建立緩存的方式進行存儲,從而可以滿足數據的查詢和處理效率。對于車輛、駕駛員、企業等更新和查詢頻率均不高,但需要永久保存的數據,則采用關系數據庫進行存儲,由于車輛、駕駛員數據較多,可達百萬級別,在進行模糊查詢時檢索效率較低,因此對部分查詢字段采用全文索引的方式進行檢索,經對比查詢效率能夠滿足使用要求。
2系統實現
系統采用前后端分離的技術進行實現,項目前端采用MVVM的模式開發,通過模塊化、數據綁定和自動路由的能力來簡化開發,后端使用Spring Boot框架進行開發,處理相關業務邏輯,并為前端提供數據服務。傳統的前后端耦合開發的方式,會使得代碼冗雜,可讀性和可重用性下降,前后端分離技術很好地解決了上述問題。
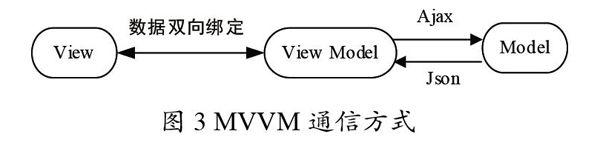
MVVM開發模式由經典的軟件架構MVC模式衍生而來,可以用于在前端領域構建基于事件驅動的UI開發平臺。MVVM的通信方式如圖3所示。
View表示頁面,Model表示數據模型,二者沒有直接聯系,通過ViewModel進行雙向交互。MVVM的控制器不會監聽瀏覽器的事件,而是監聽一個屬性表,由瀏覽器的事件修改屬性,為觸發控制器中的方法,增加了一層控制業務的屬性,即ViewModel,View與Model通過ViewModel實現雙向綁定。View和Model之間的同步工作完全是自動的,ViewModel通過雙向數據綁定把View層和Model層連接起,負責把Model的數據同步到View顯示出來,并把View的修改同步回Model。MVVM的核心思想就是只關注Model的變化,讓框架自動去更新頁面DOM,開發人員不需關注數據狀態的同步問題,從而實現數據和視圖的真正分離。
2.1治超處罰形勢綜合分析預測
系統能夠對冶超處罰數據進行統計和分析,生成治超形勢數據、總體信息概覽等,并以數字、餅狀圖、表格、地圖及折線圖等形式進行展示。不同管理機構的用戶可以查看本地的統計分析數據,能夠直觀了解本地的治超形勢,為決策提供依據,運輸企業、車輛、駕駛員統計結果如圖4所示。
2.2處罰信息管理
可以查看所有車輛超載處罰信息,包括手動錄入和自動同步的數據。支持處罰信息的導入和導出以及每條處罰信息對應的處罰決定書的導入和導出,處罰信息管理頁面如圖5所示。
2.3黑名單管理
可以查看運輸企業、車輛和駕駛員的黑名單數據,支持黑名單的查詢和導出,同時可以導出每一條違規記錄的處罰決定書。可以查看進入黑名單時的違規次數和每次違規的記錄,運輸企業黑名單可以查看違規占比。系統可以設置黑名單閾值,根據閾佰生成黑名單列表。黑名單管理頁面如圖6所示。
2.4處罰備案
可以查看運輸企業、車輛、駕駛員及源頭企業的黑名單,有管轄權限的機構及其上級機構可以對黑名單中的企業、車輛、駕駛員及源頭企業進行處罰,處罰時需選擇處罰方式,點擊礁定即完成處罰操作,此時相應對象將被移除黑名單。此外,車輛發生違規地點的管轄機構可以向管轄對象的機構抄送黑名單處理提醒,起到提醒作用。上級機構可以向下級機構進行抄送,對黑名單的處理工作進行督辦。處罰備案頁面如圖7所示。
2.5基礎數據管理
可以對車輛、駕駛員、運輸企業和源頭企業等基礎數據進行管理,能夠對上述基礎數據進行添加、修改、刪除等操作,并可查看數據詳情。其中車輛和駕駛員數據量較大,為提升檢索速度,數據庫表存儲時對部分檢索字段添加了全文索引,從而極大地提升了模糊查詢的效率。基礎數據管理頁面如圖8所示。
3結束語
河北省冶超處罰聯網系統通過對超載處罰數據的對接和分析,實現了車輛、駕駛員、運輸企業及源頭企業超載運輸黑名單制度的落實,系統運行半年以來成效顯著,為河北省的冶超工作提供了助力。下一步將進一步完善系統對數據的分析能力,構建更優化的模型,提升超載趨勢預測的準確度。
