基于改進tiny-YOLOv3的車輛檢測方法*
2021-09-15 08:35:30王孝蘭王巖松馬明輝竇雪婷
計算機與數字工程 2021年8期
王 碩 王孝蘭 王巖松 馬明輝 竇雪婷
(上海工程技術大學機械與汽車工程學院 上海 201620)
1 引言
隨著人工智能的發展,自動駕駛引起了研究者的廣泛關注[1],智能車輛是汽車行業未來發展的必然趨勢。前方道路環境的感知作為自動駕駛車輛路徑規劃、決策控制的基礎,成為智能車領域的研究重點。其中,車輛作為主要交通參與者,對其準確、實時的檢測在環境感知中至關重要[2]。
車輛檢測的方法主要分為基于傳統算法和深度學習兩種。傳統的前方車輛檢測算法可以分選取感興趣區域[3]、從候選區域提取特征和建立分類器三個步驟。常用的特征有HOG[4]、haar-like[5]和LBP[6]等手工特征,并根據SVM[7]、Adaboost[8]等方法進行分類,完成車輛檢測。但由于目標遮擋、光照變化以及背景干擾等因素影響,人為設計的圖像特征魯棒性差,難以表達所有情況下的目標特征,影響分類器的性能,傳統算法無法滿足日益復雜的交通環境。
隨著深度學習技術的發展,基于深度卷積神經網絡的車輛檢測方法成為一個新的研究方向。該檢測方法主要可分為兩類,一類是基于區域推薦的兩步方法,文獻[9]提出的R-CNN方法首先使用區域推薦產生候選區域,針對每一個候選區域通過CNN提取特征,將特征送入SVM分類器來判斷目標類別,最后利用線性脊回歸器對候選區域的位置進行調整。隨后,在此基礎上何凱明等不斷做出改進,提出SPP-net[10]、Fast R-CNN[11]、Faster R-CNN[12]與Mask R-CNN[13]等目標檢測方法,在目標檢測方面取得很好的檢測效果。但由于兩步法網絡結構復雜,實時性難以保證而較難實現應用。另一類是基于回歸方法的一步方法,代表有YOLO[14]、SSD[15]等。2016年Redom J提出了YOLO(You Only Look Once)檢測算法,將檢測問題作為回歸問題處理,通過分割圖像為若干個單元格,每個單元格直接負責預測目標位置信息與類別信息,更加準確地獲取了圖像局部信息,大大降低了背景的誤檢率,提升了檢測速度。但是存在檢測精度與召回率不高的問題,Redom等通過正則化、維度聚類等方法對YOLO進行改進,提出了YOLOv2[16],在VOC2007數據集上,測試速度為67幀/s時,mAP(mean Average Precision)為76.8%,效果顯著。2018年4月,YOLO發布第三個版本YOLOv3[17],在COCO數據集上的mAP由YOLOv2的44.0%提高到57.9%,但是由于網絡的加深,計算量增多,算法的實時性較差。而SqueezeNet[18]、MobileNet[19]、tiny-YOLO[20]等方法網絡結構簡化,擁有更少的卷積層,降低了計算量,可以有效地提高檢測速度,但犧牲了檢測精度。
為實現復雜環境下的前方車輛準確實時檢測,本文提出了基于改進tiny-YOLOv3的車輛檢測算法。以tiny-YOLOv3網絡為基礎,將前方道路圖像中的車輛作為目標,改進網絡結構,在保證原檢測速度的同時提升檢測精度降低模型大小,使其滿足車輛檢測的實際需求。通過對比試驗,驗證本文提出方法的有效性和準確性。
2 前方車輛檢測模型
2.1 tiny-YOLOv3原理
YOLO算法將檢測問題作為回歸問題處理,在保證檢測精度的同時提升檢測速度。對YOLO網絡進行簡化,得到主干網絡為7個卷積層與6個池化層的tiny-YOLO網絡,在犧牲檢測精度的同時,極大的提高檢測速度。隨后YOLO通過不斷改進,已經發展到第三代YOLOv3,相應地也提出tiny-YOLOv3。
Tiny-YOLOv3采用13層的特征提取網絡,在目標檢測階段原始圖像經過縮放后劃分為S×S的等大單元格,每個單元格負責預測中心落入其中的目標物體的位置信息與類別信息,具體包括B個候選框及其置信度分數,以及C種類別的條件概率。每個候選框預測5維信息,即坐標(x,y)、目標的寬w和高h與置信度,分別記為tx,ty,tw,th,obj_conf。置信度公式為
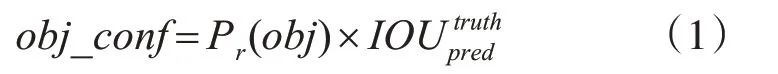

當多個候選框檢測到相同目標時,tiny-YOLOv3使用非極大值抑制方法過濾閾值較低的候選框,得到最佳的目標候選框。
2.2 Inception模型結構
在傳統的卷積神經網絡中,大尺寸的卷積核的計算量很大,Google Inception Net提出的Inception結構通過多層小尺寸的卷積核來代替大尺寸卷積核,減少計算量與參數量達到簡化模型和節省硬件資源的目的,其一種Inception v2模塊結構如圖1所示。一共包含四個通道,第一個通道通過1×1的卷積核提取特征,提高網絡的表達能力;第二個通道先通過池化提取特征信息,再通過1×1的卷積核控制輸出的升維和降維;第三個通道先使用1×1的卷積核減少參數,再使用3×3尺寸的卷積核提取特征;第四個通道與第三個通道類似,通過多加一個3×3尺寸的卷積核得到不同尺度的特征;最后將四個通道的輸出通過聚合操作進行合并。Inception v2模塊通過兩個3×3尺寸的卷積核代替v1中5×5尺寸的卷積核,減少網絡模型參數并加強非線性的表達能力,通過四個不同尺寸的特征提取操作增加網絡對于不同尺度的適應性。
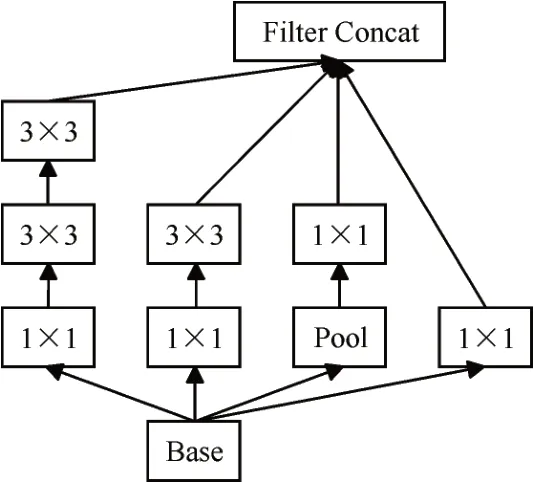
圖1 Inception模塊結構
3 算法改進
3.1 改進的tiny-YOLOv3網絡
由于前方道路圖像中的車輛尺寸與比例不固定,當目標較遠時或車輛互相遮擋重疊時,極易漏檢或將車輛判斷為其他類的目標物體。tiny-YOLOv3網絡作為針對多類別目標檢測的一種簡化網絡,在檢測前方道路車輛已經取得了較好的實時性,但網絡的層數較少,很難對車輛目標特征有較好的提取效果,因此存在對小目標定位精度差、車輛目標識別率低、誤檢或重復檢測等問題。為進一步加強對目標的檢測能力,本文借鑒Inception模塊對tiny-YOLOv3網絡進行改進,用Inception v2模塊替換tiny-YOLOv3的特征提取網絡,并結合上下文相同尺度的特征圖增加檢測尺寸,提升網絡特征提取能力的同時,降低模塊參數,具體網絡結構如圖2所示。

圖2 INt-YOLOv3網絡結構
網絡的具體實現過程如下:當輸入圖片尺寸為416×416時,通過兩組卷積層和步長為2的池化層后得到104×104×32的特征圖。采用三個相同的Inception模塊替代原網絡中的卷積層和池化層,降低特征圖尺寸和增加特征圖通道數,分別得到52×52×128、26×26×256、13×13×512三個不同尺度的特征圖;改變Inception模塊中卷積層的步長為1得到13×13×1024的特征圖;在原有的tiny-YOLOv3網絡檢測部分對13×13×128、26×26×128尺寸的特征圖進行2倍上采樣得到26×26×128和52×52×128的特征圖,幫助網絡學習細粒度特征,并結合上下文信息分別與特征提取部分26×26×256和52×52×128的特征圖融合,得到26×26×384和52×52×256的特征圖。獲取13×13×512,26×26×256,52×52×128三組尺度的特征圖,組成最終的特征表達。對三組尺度的特征圖分別通過三個相同通道數的卷積層進行預測輸出,卷積層的通道數為(5 +4)×3=27。本文稱該網絡結構為INt-YOLOv3。
3.2 網絡訓練
YOLO系列算法采用候選框的思想,通過在數據集上進行聚類確定候選框,提升檢測精度。以矩形框的平均交并比IOU作為相似度對前方車輛目標訓練集的所有目標標注使用K-means聚類方法獲得候選框的尺寸。使用遞增的方法選擇k值,得到IOU與k的關系如圖3所示。考慮到網絡的計算量,且改進的tiny-YOLOv3網絡中使用在三種尺度上進行預測的方法,最終采用k=9的聚類結果,9個候選框尺寸分別為(20,25),(35,39),(66,46),(50,71),(92,81),(141,116),(99,173),(199,183),(228,325)。在每個尺度上的每一個單元格借助三個候選框預測三個邊界框。
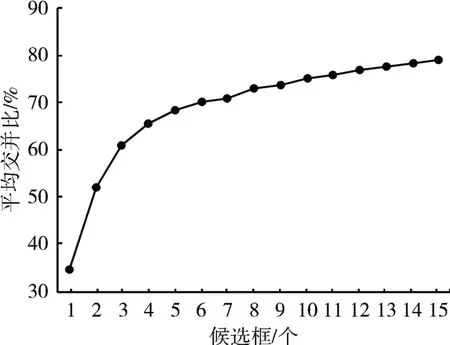
圖3 K-means聚類
以開源的深度學習框架Darknet為基礎,改進的tiny-YOLOv3網絡結構為模型,結合聚類分析和多尺度訓練的方法,訓練車輛檢測器。訓練時模型的初始學習率設為0.001,在25000和35000次迭代后,學習率乘以0.1,動量系數為0.9,權值衰減系數為0.0010,最大迭代次數為50000次。每訓練10批次隨機選取新的圖片尺寸進行訓練,使模型對于不同尺寸的圖像具有更好的檢測效果。采用圖像隨機調整曝光、飽和度、色調等方法對數據進行擴充。
4 實驗結果與分析
4.1 實驗平臺與數據集
實驗平臺配置為Windows 10操作系統,Inter Core i5-8400處理器和16GB內存,搭載NVIDIA GeForce GTX1070Ti顯卡,配置英偉達CUDA9.0和GPU加速庫CUDNN7.0,配置OpenCV 3擴展庫,深度學習框架為Darknet。
本文采用的車輛檢測數據集為KITTI數據集。KITTI數據集包含市區、鄉村和高速公路等場景采集的真實圖像數據,每張圖像中包含車輛和行人等各種目標,還包括光照變化、背景斑雜和樹木房屋等對目標各種程度的遮擋與截斷等情況。根據實際應用場景,本文對KITTI數據集原有的8類標簽信息進行處理,保留實驗需要的4個類別標簽,即:Van,Car,Truck和Tram,同時選取該數據集中7481張圖像作為實驗數據,根據實驗需求將其標注為PASCAL VOC2007數據集格式,其中80%作為訓練集,20%作為驗證集。
4.2 實驗結果與分析
本文采用均值平均精度(mAP)、交并比IOU、模型大小和檢測幀率四個評價指標。部分衡量指標計算公式如下:
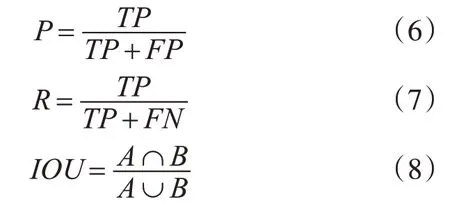
以本文所研究的前方車輛目標類別為例,式中TP表示正確預測車輛目標類別的數量,FP表示將負樣本預測為正樣本的數量,FN表示將正樣本預測為負樣本的數量,P表示準確率,R表示召回率,準確率與召回率越高則算法越具有優越性,A表示預測的目標尺寸,B表示目標的真實值,IOU越高則算法定位越精確。
表1顯示了YOLOv2、tiny-YOLOv2、tiny-YOLOv3與本文提出的INt-YOLOv3方法的實驗結果。這些方法均使用本文選取的KITTI數據集進行訓練與測試。從表中可以看出,本文提出的INt-YOLOv3獲得了89.66%的mAP,相對于tiny-YOLOv3網絡準確度提升了5.75%。對比tiny-YOLOv2、tiny-YOLOv3卷積網絡層數相對較少,車輛特征提取不足,而INt-YOLOv3網絡通過增加網絡寬度與檢測解決了這個問題,因此對車輛特征的表達能力優秀。
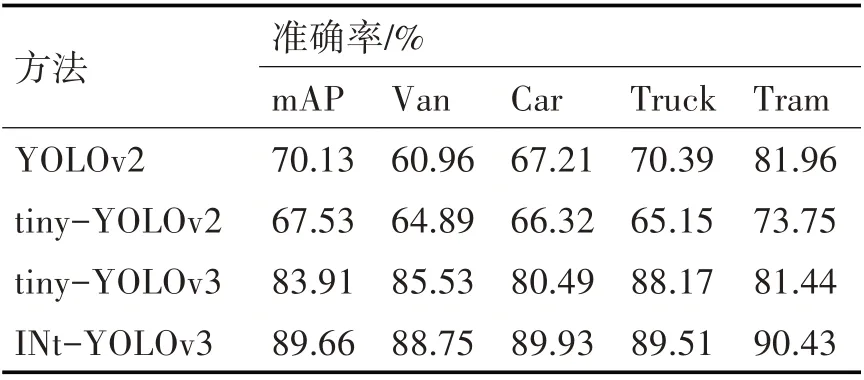
表1 不同方法在KITTI測試集上的測試結果
為了驗證文中設計的INt-YOLOv3網絡的定位準確性,利用平均交并比作為指標進行評測。本文在數據集上分別訓練了YOLOv3網絡和tiny-YOLOv3網絡作為INt-YOLOv3網絡的對照,并使用數據集中測試集測試平均交并比。對比結果如表2所示。
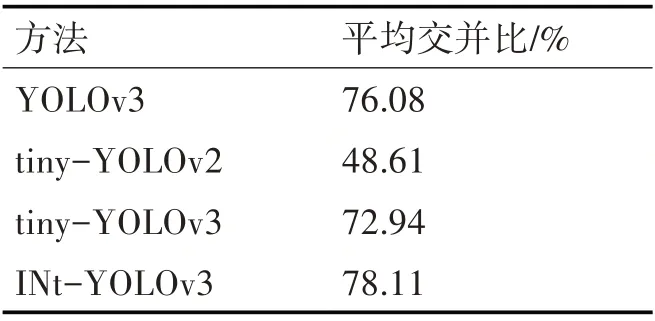
表2 平均交并比測試結果
結果表明,相比較于YOLOv3網絡,INt-YOLOv3網絡平均交并比提高了5.24%;相比較于tiny-YOLOv3網絡,INt-YOLOv3網絡平均交并比提高了8.38%。這說明,在測試集上INt-YOLOv3產生的候選框與原標記框的交疊率更高,對車輛定位的精度更好。原因在于,通過對數據集的K-means聚類分析選擇合適尺寸的候選框以及網格尺寸的改進,可以更好地提升模型的定位精度。
使用預設網絡參數在訓練階段得到網絡模型的權重,在輸入為416×416時比較YOLOv2、YOLOv3、tiny-YOLOv2、tiny-YOLOv3與本文提出的INt-YOLOv3方法的模型大小和檢測幀率。
其結果如表3所示,通過對比發現,本文提出的方法檢測幀率遠超實時性要求,僅比原方法降低了5 f·s-1,但模型大小減少了11MB,反映了本文提出的方法復雜度更低,網絡模型參數更少,對硬件要求低,更便于部署使用到實際場景當中。

表3 不同方法模型大小與檢測幀率
為了更加直觀地檢驗INt-YOLOv3網絡的有效性,本文選取測試集中圖像以及道路采集圖像進行了檢測效果測試,選取KITTI中3張圖片的檢測結果進行對比,圖4(a)、(c)和(e)為tiny-YOLOv3的檢測結果,圖4(b)、(d)和(f)為INt-YOLOv3的檢測結果。對比圖(a)、(b)和(c)、(d),tiny-YOLOv3和INt-YOLOv3能夠很好地檢測出大目標,但INt-YOLOv3檢測出遠距離的車輛,具有更好的小目標檢測能力;對比圖(e)和(f),tiny-YOLOv3對被遮擋的車輛錯誤檢測,并漏檢左側背景顏色相同的Van,而INt-YOLOv3全部正確檢測。圖5為道路采集的兩張圖片檢測結果對比,對比tiny-YOLOv3的檢測結果圖(a)、(c)和INt-YOLOv3的檢測結果圖(b)、(d),INt-YOLOv3比tiny-YOLOv3能更好地檢測出小目標與被遮擋目標。綜合以上檢測結果,對于圖像中較大尺度的無遮擋車輛,兩種網絡具有相近的檢測能力,對于較小尺寸的車輛與被遮擋車輛,tiny-YOLOv3會出現漏檢、錯檢和重復檢測。但本文提出的INt-YOLOv3能夠很好地解決問題,正確地檢測出車輛。因此,INt-YOLOv3具有更好的檢測性能。

圖4 tiny-YOLOv3和INt-YOLOv3在KITTI數據集上的對比結果

圖5 tiny-YOLOv3和INt-YOLOv3在采集圖像上的對比結果
通過以上實驗可以看到,改進后的算法在精度、交并比、模型大小和檢測幀數四項指標上具有更好的表現,尤其在mAP上具有明顯優勢,相比原tiny-YOLOv3在本數據集上提高了5.75%;檢測速度僅下降了5 f·s-1,并且模型大小僅有22MB,相對tiny-YOLOv3減少三分之一。這是因為本文增加了網絡寬度和檢測尺度,提升了網絡的特征提取能力,同時減少參數,網絡模型更小,更便于部署。
5 結語
本文提出了基于改進tiny-YOLOv3的前方車輛檢測方法:INt-YOLOv3。該方法使用Inception模塊替代原卷積層提取特征,并控制卷積層步長替代原池化層完成降維,通過增加網絡寬度,提升網絡特征提取能力,并減少網絡參數;將上下文特征融合,增加檢測尺度,同時利用K-means聚類方法自動生成候選框,增強特征圖的表征能力,提高了模型的定位精度和tiny-YOLOv3網絡在前方車輛檢測的準確率,并且在檢測速度幾乎不變的情況下減少模型大小,更便于模型在移動端的部署。但是,INt-YOLOv3仍存在某些復雜環境下精確識別困難的問題,下一步的重點應放在增強模型的魯棒性和識別效果上。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
