基于不平衡文本分類的改進Stacking模型*
2021-09-15 08:35:48趙禮峰
計算機與數字工程 2021年8期
蔣 瑤 趙禮峰
(南京郵電大學理學院 南京 210023)
1 引言
如今,我們生活在一個信息驅動的時代,人們不僅從社會、生活的環境中獲得信息,更多的信息來自于網絡這片海洋里[1]。隨著互聯網的飛速發展,人們慢慢傾向于在網絡上闡述觀點和表達情感,從網絡上的言論中獲取信息。以臉書(Facebook)、微博、微信等為代表的社交平臺和以亞馬遜、淘寶為代表的電子商務平臺上的評論迅速增多,所蘊含的信息量也非常多。從大量評論中挖掘出其蘊含的態度或情緒信息是迫切需要的,因為從一個商品的評價中,賣家和買家可以做出決策;在各大網站上的評論有助于政府的輿情監控。
文本分類就是從文本中獲取信息,進而對信息進行分析處理,挖掘出更為重要的知識。文本分類分為兩個部分:特征工程和分類器,特征工程是將數據變為信息的過程,是最為耗時耗力的,卻又相當重要的過程[2]。DF(詞頻)、CHI(卡方檢驗)、IG(信息增益)、ECE(期望交叉熵)等常常被用來作為特征選擇的依據[3]。Bao Guo等[4]運用TF-IDF將文本分詞后向量化作為文本的特征進行分類。牛玉霞[5]對特征選擇算法IG進行改進,并與DF進行了結合,提取了更為重要的特征用以文本分類,提高了文本分類的精度。文本分類的另一部分分類器是將信息變為知識,即我們所想得到的結果,前人對文本分類采用的分類器算法不斷更新,使得文本分類的預測效果越來越好。Peixin Liu等[6]將樸素貝葉斯(Na?ve Bayesian)作為分類器對短文本進行分類取得了很好的效果。盧興[7]使用支持向量機對中文短文進行分類,并證明了其有效性。
本文根據網購評論數據預測購物體驗的積極與消極傾向,由于積極評論的數量遠遠多于消極評論,而消極評論對商家的決策過程更為重要,所以識別少樣本(消極傾向)的工作更為重要。為適應此數據高維不平衡特征,采用TF-IDF特征提取方法,在算法上提出融合隨機森林和邏輯回歸的Stacking算法,通過對比,文本分類的效果有所提高。
2 相關技術
2.1 TF-IDF(詞頻-逆文檔頻率)
TF-IDF是一種統計方法,它的計算公式為TF(詞頻)×IDF(逆文檔頻率),它的含義是如果一個詞在某段文本中出現的頻率越多,而在所有的文本中出現的頻率越少,則這個詞的tfidf權值越大,就越能代表這個文本[8]。

1)TF(詞頻)是指某個詞在所有的文本中出現的頻率:2)IDF(逆文檔頻率)即文檔頻率的倒數,表示在每個文本中經常出現的詞對所有文本的影響反而會小[9]:

2.2 隨機森林(Random Forests)
隨機森林是Bagging集成算法的一個擴展,它是以決策樹為基分類器來構建Bagging集成的,并且在集成的過程中引入了隨機屬性選擇,即每個屬性都有被選擇加入訓練過程中,保證了基學習器的多樣性,提高了模型最終的泛化性能[10]。
隨機森林最終的決策結果由所有基分類器決策樹的分類結果的組合得出,如圖1所示。對于分類問題,選用投票法來決定,對每個決策樹的分類結果進行統計投票,少數服從多數;對于回歸問題,則取決策樹分類結果的平均值作為隨機森林的結果[11]。
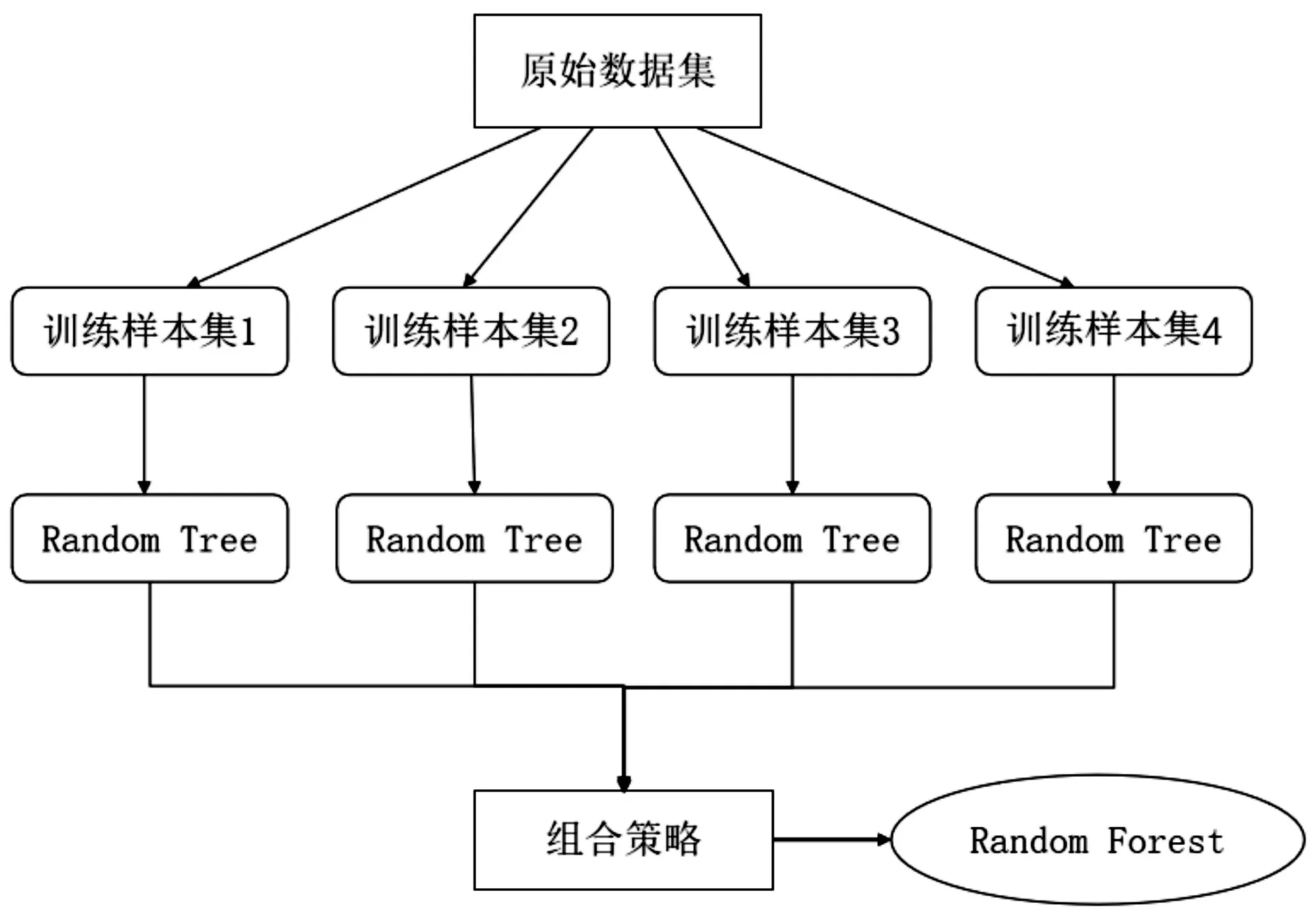
圖1 隨機森林示意圖
隨機森林的優點如下。
1)它能夠處理高維度數據,并且不用進行特征選擇這項耗時耗力的工程;
2)它容易做并行化處理,且速度比較快;
3)最重要的一點,隨機森林在處理不平衡數據集的問題上,可以平衡由數據集帶來的誤差[12]。
2.3 Stacking集成算法
Stacking是將多個不同的機器學習器結合在一起的一種集成算法,與投票法集成不同的是,Stacking將基學習器叫做初級學習器,用于結合的學習器叫做次級學習器[13]。實現Stacking的過程如下。
1)劃分數據集D來訓練初級學習器h1,h2,h3…;
2)用訓練出來的若干個初級學習器對D上的測試集分別進行預測,將所有預測結果結合在一起,作為次級訓練集,訓練次級學習器[14];
3)對最初劃分的需要預測的數據集用每個初級學習器進行預測,然后將預測的所有結果取平均,再用次級訓練器對處理后的預測結果再預測,得到最后的結果[15]。
3 基于不平衡數據的改進Stacking模型
3.1 不平衡數據處理方法
在二分類試驗中,一般把所關注的一類樣本,即少數類樣本視為正類,另一類則認為是負類。當正類的樣本數量遠小于負類的樣本數量時,這種情況下的數據稱為不平衡數據。
不平衡數據通常通過采樣方法來改變數據分布,以減少數據的不平衡度。采樣方法有過采樣和欠采樣,即提升少類樣本數或減少多類樣本數,從而增大正類特征對分類器的影響,但若只是復制樣本的過采樣,易導致模型過擬合;只是對負類樣本進行欠采樣,模型的泛化能力會降低[16]。
故本文不局限于數據采樣方法,而是結合采樣方法,并在算法層面上做出改進。
3.2 融合隨機森林和邏輯回歸的改進Stacking模型
每次從負類樣本中不放回抽取一定比例的樣本,保留所有正類樣本,合并成一個訓練集,依次訓練隨機森林模型。具體步驟:分別從負類中隨機抽取與正類一樣多、數量為正類5倍、10倍、16倍和25倍的數據,與所有正類樣本構成一個訓練集,依次迭代訓練五個隨機森林。
抽樣倍數不同可以得到不同參數的分類器,保證了分類器的多樣性,將得到的五個隨機森林作為初級分類器。考慮TFIDF的高維稀疏性,選擇邏輯回歸分類器作為次級分類器。圖2展示了改進Stacking模型的一部分。
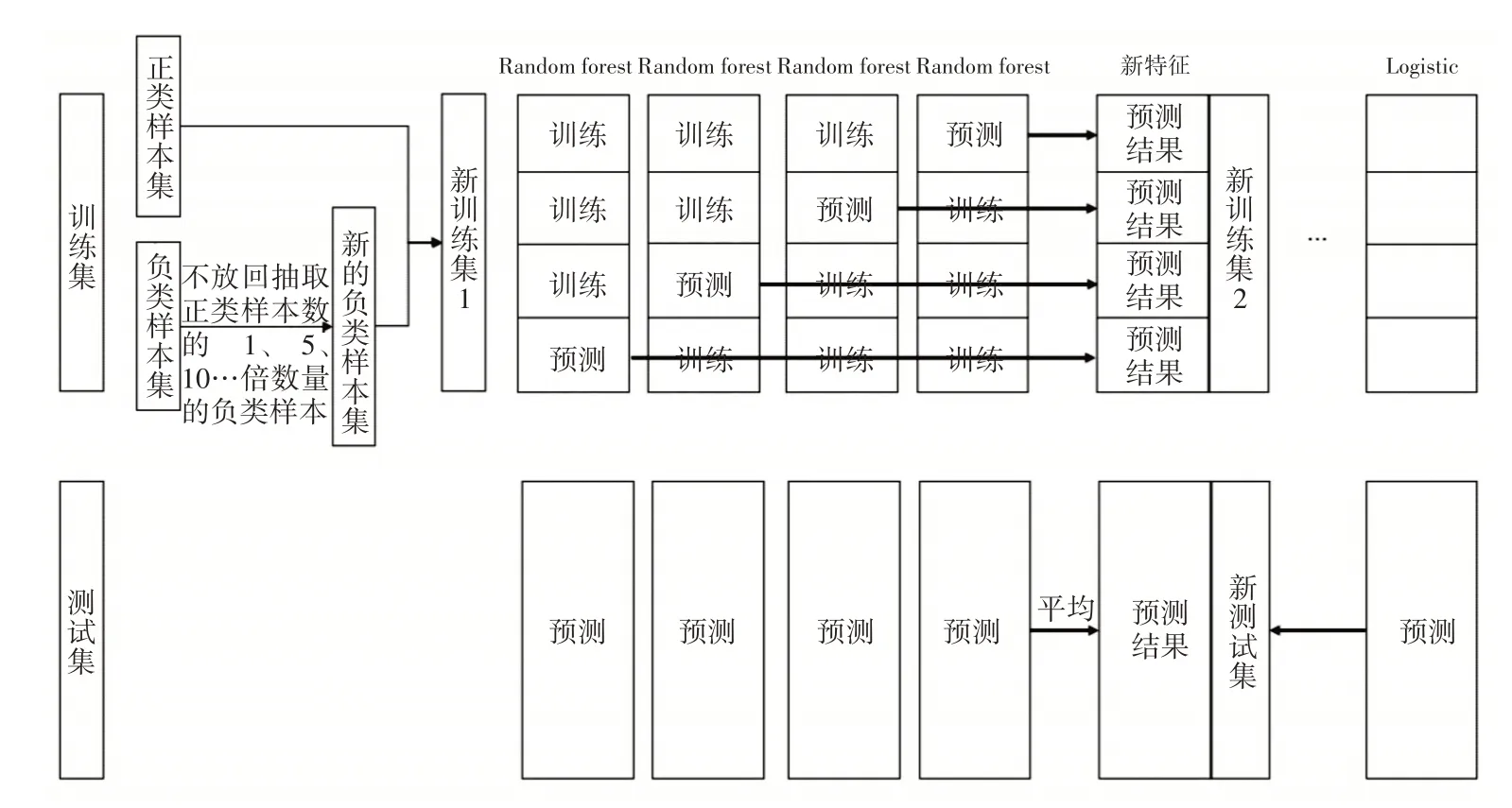
圖2 改進Stacking模型
4 實驗設計與結果分析
本 文 數 據 集 來 自Kaggle(http://www.kaggle.com)上提供的Amazon電子商務平臺的購物評論。該數據集包括67992條評論和評分(1級~5級),筆者將1、2等級視為消極評論,其他視為非消極評論。數據集信息如表1所示。
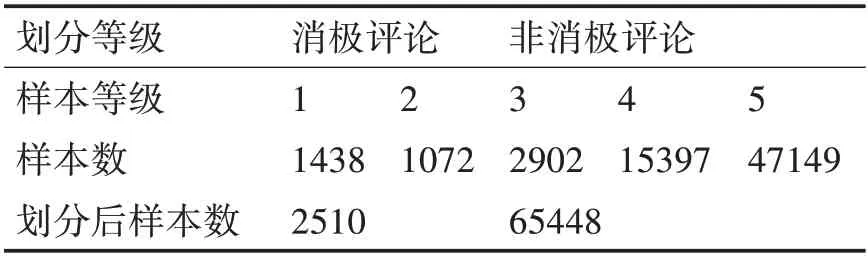
表1 數據集信息
由表1可知,數據存在高度不平衡,將1、2等級的消極評論視為正類,其他等級的視為負類,正類與負類的比值達到1∶26以上。
4.1 數據清洗
本文數據集中的評論為英文評論,對于英文文本的處理包括HTML字符轉換、解碼數據、移除Stop word、移除標點符號、移除表情符、拆分黏在一起的詞、去除URL等[17]。
4.2 特征提取
文本數據屬于非結構化數據,機器往往是不能對這種數據進行運算分析的,一般要轉換成機器能分析的結構化數據,故將文本數據特征進行向量化[18]。在文本分類中,詞向量是一種常用的文本表示方法[19]。詞條權重的計算往往需要考慮:
1)如果一個詞在一篇文檔中出現的頻率越多,則對文本識別的貢獻越大;
2)如果一個詞在所有文檔中出現的次數越少,則它對于不同文檔的區分能力越強[20]。
TFIDF綜合考慮到了這兩點。本文將評論中所有的詞放入tfidf的詞庫中,然后計算tfidf值作為詞條權重,將文本數據轉換為詞向量,從而進行分類器的訓練[21]。
4.3 評價指標
在大多數研究中,通常用混淆矩陣來評價一個模型分類的好壞,筆者根據本文數據集高維不平衡的特征,選擇召回率(Recall)、精確率(Precision)、F1測度值(F1-Measure)和G-mean作為最終結果的評價標準[22],因為這種數據特征的分類準確率一般會很高,而其他指標卻不佳,所以不能選擇準確率作為評價本文數據集的指標。下面基于表2計算召回率、精確率、F1值和G-mean[23]。

表2 混淆矩陣
4)G-mean在不平衡數據分類的評價中使用較廣,它同時考慮了召回率和特異率,綜合評估了算法性能,計算公式如下:
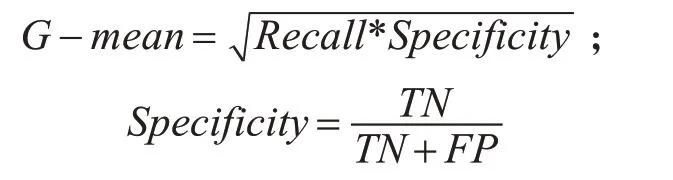
4.4 實驗結果
本文的抽樣比例為8∶2。由于本文主要目標是提高正類樣本的分類效果,且結果表明在正類樣本預測效果提高的同時,負類樣本分類效果依舊表現優異。負類樣本的分類效果對本文研究不具有參考價值,所以表3只給出了單個隨機森林和Stacking模型的對正類預測的評價指標的匯總。
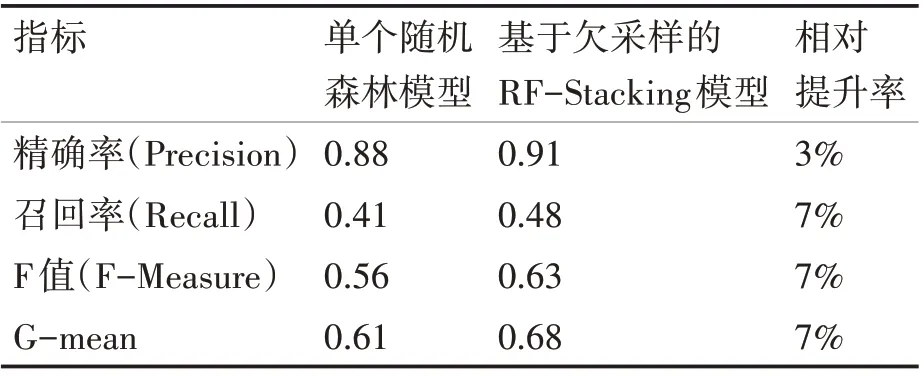
表3 單個隨機森林和Stacking模型結果比較
由表3可以看出,Stacking模型的各項指標都要優于單個隨機森林模型。一般情況下,召回率提高的同時必然會損失一部分精確率,但本文所選擇的模型在召回率提高的同時保證了精確率,說明此模型對高維不平衡數據預測是有效的。
并且筆者將此模型的預測效果與當前文本分類主流算法RNN(循環神經網絡)的預測效果進行了比較,發現其準確率達到了97.88%,而RNN的準確率為97.58%,且此模型比RNN的運行用時更短,這進一步說明了本文提出的改進Stacking模型能夠有效提高不平衡文本分類的分類效率。
5 結語
為提高消極評論的分類效果,本文提出了一種基于欠采樣的隨機森林Stacking模型,該模型充分適應本文數據集高維不平衡特征,構造不同倍數的欠采樣得到多個不同的基分類器,根據Stacking集成隨機森林和邏輯回歸,對測試集進行預測,對單個隨機森林和改進Stacking模型預測分類結果進行了對比,并與深度學習RNN算法的分類結果和分類速度進行了比較。實驗結果表明,本文提出的改進Stacking模型能夠提高高維不平衡評論數據的分類效果,充分驗證了本模型的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
