基于詞聚類CNN和Bi-LSTM的漢語復句關系識別方法*
2021-09-15 08:35:48孫凱麗鄧沌華
計算機與數(shù)字工程 2021年8期
孫凱麗 李 源 鄧沌華 李 妙 李 洋
(1.華中師范大學計算機學院 武漢 430079)(2.華中師范大學語言與語言教育研究中心 武漢 430079)
1 引言
漢語復句是銜接小句與篇章的重要單位,在漢語句法中占有重要地位。漢語言研究中,若要取得“句處理”的重大進展,則漢語復句的句法語義自動判定問題便成為了主要的研究內容[1]。復句是由兩個或以上的分句構成,漢語言中近2/3的句子是復句。因此,對漢語句子的研究實則是對復句的研究。復句的關系識別是漢語言應用中語義自動分析的關鍵,是自然語言理解的基礎研究問題。復句關系識別的主要任務是研究復句句間的邏輯語義關系,正確的判斷邏輯關系意味著能夠有效地理解復句。因此,該課題的研究有利于提升篇章分析[2]、自動問答[3]、信息抽取[4]等系統(tǒng)的性能,并推動多種自然語言處理任務的發(fā)展。
復句根據(jù)關系標記標示能力的強弱分為充盈態(tài)有標復句和非充盈態(tài)有標復句。如例1所示,復句中存在關系標記“除了…還…”,由該關系標記可以明確地標示例1屬于并列關系復句,因此,像這樣的復句稱為充盈態(tài)有標復句。例2復句中由于關系標記的缺失,此時若判定復句語義關系,就不能僅僅通過關系標記來進行標示,而需結合句子具體的語義來分析,這樣的復句稱為非充盈態(tài)有標復句。如在例2中,a)、b)兩復句雖含有相同的關系標記“萬一”,但通過具體的語義分析后判定a)為因果關系復句,b)為轉折關系復句。所以,在非充盈態(tài)有標復句中若要正確地識別語義關系,需要充分考慮復句的語義、語境、句法等特征信息,而不是僅僅單純地依靠關系標記來確定。
例1除了在第二師范教國文,還在育德中學講國故。(梁斌《紅旗譜》)
例2a)萬一造成全廠斷水,會帶來不敢想象的災難!(蔣杏《寫在雪地上的悼詞》)
b)聽從郭芙的注意,萬一事發(fā),師母須怪不到他。(金庸《神雕俠侶》)
本文所研究的內容主要是針對非充盈態(tài)二句式復句進行關系識別,使用的語料為邢福義等[5]在2005年發(fā)布的漢語復句語料庫(the Corpus of Chinese Compound Sentence,CCCS)[23]和 周 強 等[6]在2004年發(fā)布的清華漢語樹庫(Tsinghua Chinese Treebank,TCT)。其中CCCS語料庫共收錄658447條有標復句,語料來源以《人民日報》和《長江日報》為主。TCT語料庫則是從大規(guī)模經(jīng)過基本信息標注的漢語平衡語料庫中抽取而來,具有100萬漢字規(guī)模的語料文本,句子總量達到44136條,復句數(shù)量為24444條。
基于CCCS和TCT語料庫,本文提出了一種基于詞聚類算法的卷積神經(jīng)網(wǎng)絡(CNN)與雙向長短時記憶(Bi-LSTM)網(wǎng)絡相結合的聯(lián)合模型架構,并引入融合詞向量的方法解決非充盈態(tài)二句式復句關系識別的任務。本文所提出的聯(lián)合模型架構能夠充分利用CNN與Bi-LSTM網(wǎng)絡結構的優(yōu)勢,在提取文本局部語義特征的同時又獲得了文本整體的語義信息以及長距離的語義依賴特征。其中,本文模型中是對原始的CNN進行改進,將池化層替換為Bi-LSTM網(wǎng)絡層,目的是在提取文本內局部語義特征的基礎上,減少池化操作所帶來的語義信息的丟失。另外,本文在最初階段使用基于K-means的詞聚類算法,實現(xiàn)對復句詞向量的聚類建模,充分挖掘復句中單詞間的語義相似特征信息,增強網(wǎng)絡結構的學習能力。整體而言,本文采用局部語義特征與全局語義特征相互結合相互補充的思想,對復句向量矩陣聯(lián)合建模,最終實現(xiàn)復句關系類別的正確判定。經(jīng)過驗證,本文所提模型取得了較好的識別性能,對比楊進才[11]等的最好識別方法有著明顯的性能提升,準確率提升約3.4%。
2 相關工作
漢語復句的關系識別主要通過分析復句語義、語境,即上文文本信息來判斷復句所表述的語義關系傾向。自2001年由邢福義[7]提出的復句三分系統(tǒng),根據(jù)分句間的邏輯語義關系將復句分為因果、并列、轉折三大類。在這之后,許多專家學者展開了對復句關系自動判別的研究,并取得了一些顯著的成果。復句關系識別技術大致可以分為基于規(guī)則的方法和基于統(tǒng)計模型的方法,又或是兩者的結合。周文翠等[8]選取復句主語、謂語等相關語法特征,并根據(jù)《知網(wǎng)》將特征進行量化,最后使用支持向量機(SVM)訓練模型,實現(xiàn)并列復句的自動判別。Huang等[9]利用決策樹算法提取句子的詞性、長度、關系標記等特征,從而識別漢語句子的因果、并列關系。李艷翠等[10]基于已標注的清華漢語樹庫,結合規(guī)則與句法樹的相關特征采用最大熵、決策樹和貝葉斯的方法進行關系詞與關系類別的判別研究。楊進才等[11]將非充盈態(tài)二句式復句作為研究對象,結合關系標記搭配理論以及句間的語義信息,提出了一種基于語義相關度算法的關系類別自動判別方法。目前,越來越多基于深度學習的方法被廣泛地應用到自然語言處理任務中。該方法相較于傳統(tǒng)模型能夠大幅度地減少特征工程的工作量,并在節(jié)省人工的同時,提升模型的效果。具體主要表現(xiàn)在語言建模中,如Kim[12]首次將CNN運用到句子分類任務中取得了較好的效果,同時給出了模型的幾種變體。Zeng等[13]提出了一種基于CNN的模型方法,同時加入單詞位置特征、名詞詞匯特征等實現(xiàn)關系分類。Cai等[14]將CNN與LSTM進行結合形成一種新的模型架構BRCNN,以此獲取雙向文本語義信息,解決了句子級別的關系分類問題。然而,在漢語復句相關研究中,深度學習方法還尚未有實現(xiàn)的先例,本文將結合深度學習方法與復句句法特征展開對關系類別的自動標識研究。
3 基于詞聚類的CNN和Bi-LSTM結合的模型方法
為了實現(xiàn)復句關系類別自動判定的任務,本文提出了基于詞聚類的卷積神經(jīng)網(wǎng)絡和雙向長短時記憶相結合的網(wǎng)絡架構,模型結構如圖1所示。該模型主要由兩部分組成,底層是傳統(tǒng)的K-means聚類模型結構,上層是經(jīng)改進的卷積神經(jīng)網(wǎng)絡結構。本模型的整體流程:首先使用詞嵌入模型對輸入的文本句子進行編碼,轉換為由詞向量組成的句子表示。之后,經(jīng)過K-means聚類算法對句子單詞進行建模,獲得單詞間的詞義相似特征。然后,將句子表示與詞義相似特征進行拼接輸入經(jīng)改進的CNN模型中,提取句子的局部語義特征,同時通過Bi-LSTM網(wǎng)絡層又獲得雙向語義依賴特征。最終,通過全連接分類層完成復句關系類別的標識。
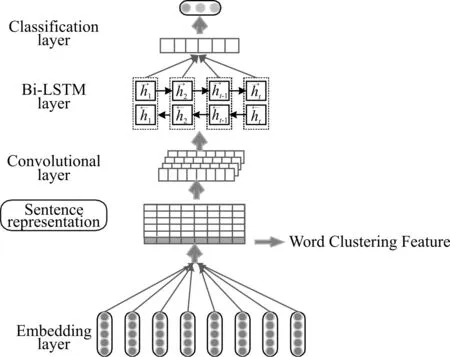
圖1 基于詞聚類CNN與Bi-LSTM結合的模型結構
3.1 輸入和編碼層
模型最初階段,首先要做的是將復句中單詞轉換為機器可識別的實數(shù)向量。本文采用的是由Word2Vec詞嵌入模型訓練得到的詞向量表示。另外,本文使用語言技術云平臺LTP[24]對漢語復句進行分詞,得到詞序列[x1,x2,…,xn],其中n為句子長度。單詞向量xi∈R1×d,d表示詞向量的維度,由單詞向量組成的句子表示為x1:n∈Rn×d,如式(1)所示,其中⊕為連接操作。
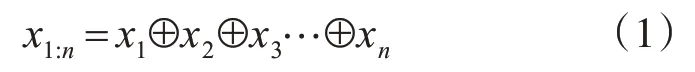
3.2 K-means詞聚類層
給定文本句子數(shù)據(jù)集為D,含有文本S{s1,s2,…,sm},其中每個文本句子si中由n個單詞組成,如式(1)中的x1:n。數(shù)據(jù)集D中文本S所包含句子的單詞總量記為N,K-means算法實現(xiàn)將N個單詞對象自動歸聚到K個簇C1,…,CK中,其中Ci?D且Ci∩Cj=?。該算法實現(xiàn)了簇內對象高相似性和簇間對象的低相似性[15]目的。
K-means算法過程如下。
1)簇的個數(shù)K值初始化為K=N*1%;
2)從D中隨機選擇K個對象作為初始簇的質心點ci,i∈[1,k];
3)計算D中單詞對象x與每個質心點ci之間的歐氏距離d ist(x,ci),將x分配到歐氏距離最近的簇ci中,即最相似的簇;
4)更新簇質心點,即重新計算每個簇中對象的均值點;
5)Repeat,untilD中簇的質心ci不再改變。
詞向量本身蘊含豐富的語義信息以及上下文信息,本文利用K-means算法獨有的簇內高相似性特點對單詞向量進行建模,深層次的挖掘單詞間的語義相似特征。同時,采用簇內替換的方法對該特征進行表示,即文本句子si中的單詞替換為各單詞所在簇的質心向量,重組句子形成句內單詞相似特征表示s′i,以此來增強神經(jīng)網(wǎng)絡的學習能力。
3.3 卷積層
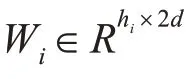


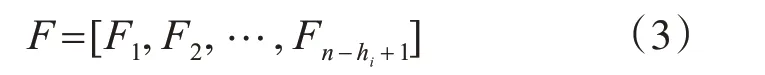
3.4 Bi-LSTM網(wǎng)絡層
循環(huán)神經(jīng)網(wǎng)絡(RNN)是對前饋神經(jīng)網(wǎng)絡的改進,是一種能夠較好地處理序列數(shù)據(jù)的鏈式網(wǎng)絡結構,但是RNN在訓練過程中隨著文本序列長度的增加會帶來梯度爆炸和梯度消失的問題[16~17]。為了解決該問題,Hochreiter等[18]提出了長短時記憶(LSTM)網(wǎng)絡,它的特點在于引入了記憶單元(memory cell)來控制整個數(shù)據(jù)流的傳輸。在每個t時刻,其輸入向量不僅有當前時刻單詞xt∈Rd,還有前一時刻隱藏層狀態(tài)ht-1。具體計算如下:
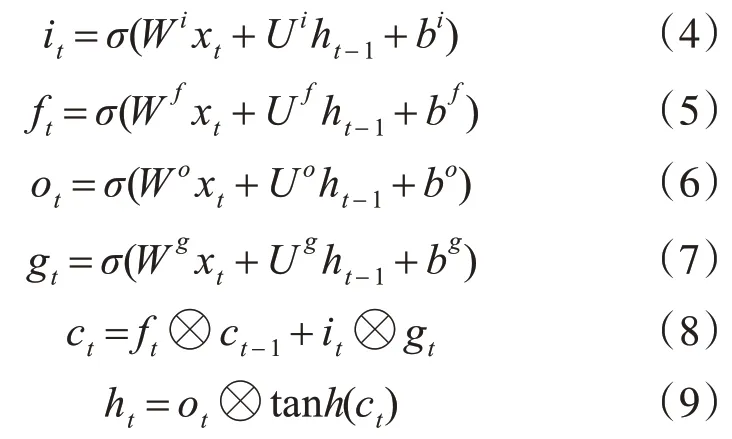
其中,σ是一個sigmoid函數(shù),?表示元素相乘操作。tanh是一個非線性激活函數(shù)。it、ft、ot在這里分別是指輸入門,遺忘門和輸出門。在最初時刻t=1時,ho和c0被初始化為零向量,ht是t時刻以及之前時刻所存儲的所有有用信息的隱狀態(tài)向量表示。
LSTM網(wǎng)絡的優(yōu)點是能夠獲得當前時刻和之前時刻所有單元的信息,其缺點是無法獲得當前時刻之后的所有單元信息,因此雙向長短時記憶(Bi-LSTM)網(wǎng)絡便應運而生,它是對LSTM的進一步改進,即分別用前向和后向的LSTM來獲取過去和將來所包含的隱藏信息,由這兩部分信息組成最終的輸出信息,如式(10):

通過該Bi-LSTM層實現(xiàn)了捕獲語義的長期依賴關系特征,以此提高模型的性能。
3.5 語義關系識別層
該層為最后的語義關系識別層,實則是帶有Softmax函數(shù)的全連接層,根據(jù)以上卷積層與Bi-LSTM網(wǎng)絡層獲得的復句特征表示,作為全連接層的輸入,這里記作Xf。具體計算如下所示:
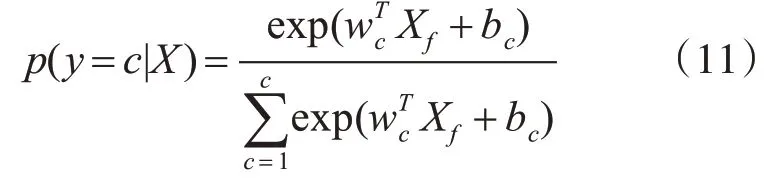
式中:假設關系類別有c類。wc,和bc分別是權重矩陣和偏置項,是隨機生成的可訓練參數(shù)。
4 實驗結果與分析
4.1 實驗數(shù)據(jù)集
本文實驗采用的數(shù)據(jù)集為漢語復句語料庫和清華漢語樹庫。漢語復句語料庫CCCS是一個針對漢語復句研究的專用語料庫,它主要由華中師范大學語言與語言教育研究中心開發(fā)。該語料庫共包含有標復句658447條,收錄的語句主要來源于《人民日報》和《長江日報》。清華漢語樹庫TCT是從大規(guī)模的經(jīng)過基本信息標注的漢語平衡語料庫中抽取而來,是一個具有100萬漢字規(guī)模的語料文本。其中,句子總量達到44136條,復句數(shù)量為24444條。該樹庫中,不同文體語料分布情況為文學37.25%,學術4.64%,新聞25.83%,應用32.28%。
實驗中數(shù)據(jù)樣本將復句的關系類別分為因果關系類別,并列關系類別和轉折關系類別。CCCS語料庫中,我們在本實驗中共選取13215條非充盈態(tài)二句式復句做為實驗樣本集,其中有3224條因果關系復句,7960條并列關系復句,2031條轉折關系復句。在TCT語料庫中由于語料文本有限,我們共使用8577條非充盈態(tài)復句樣本,其中包含2112條因果關系復句,5309條并列關系復句,1156條轉折關系復句。表1展示了實驗中數(shù)據(jù)集的劃分。
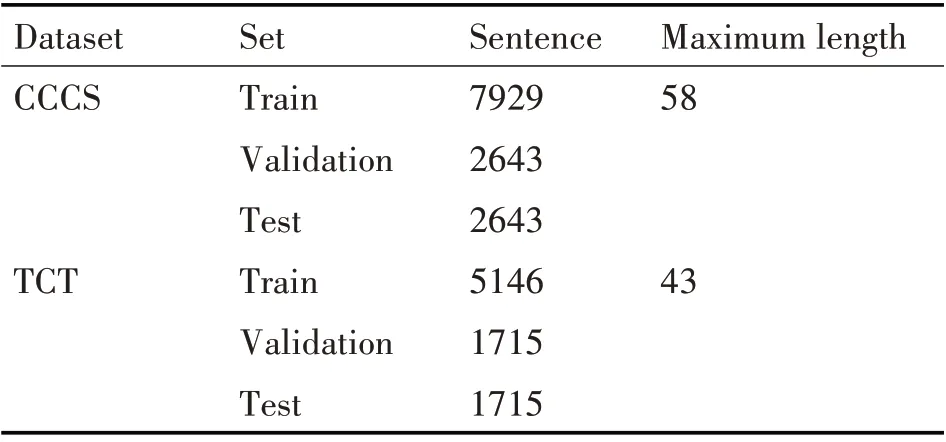
表1 實驗數(shù)據(jù)統(tǒng)計
4.2 實驗模型參數(shù)設置
本文使用Word2Vec[19]預訓練的詞向量,維度設置為300。另外,由于卷積神經(jīng)網(wǎng)絡需要固定長度的句子作為輸入,因此分別統(tǒng)計兩個數(shù)據(jù)集中最長復句所含的單詞數(shù)作為固定輸入長度,句子長度不足的采用隨機均勻分布函數(shù)填充為[-0.25,0.25]的隨機向量值。實驗中采用dropout策略防止過擬合現(xiàn)象發(fā)生,設置值為0.5。同時實驗的目標函數(shù)中又加入L2正則化項來提高模型的性能,并采用反向傳播算法(Back Propagation)[20]以及隨機梯度下降(SGD)優(yōu)化算法[21]對目標函數(shù)進行優(yōu)化。Bi-LSTM網(wǎng)絡層的隱含層維度設置為256維。實驗過程中使用網(wǎng)格搜索的方法調整模型最佳的參數(shù)值,并且通過每1000個epoch驗證一次模型的表現(xiàn)力,主要參數(shù)值具體如表2所示。
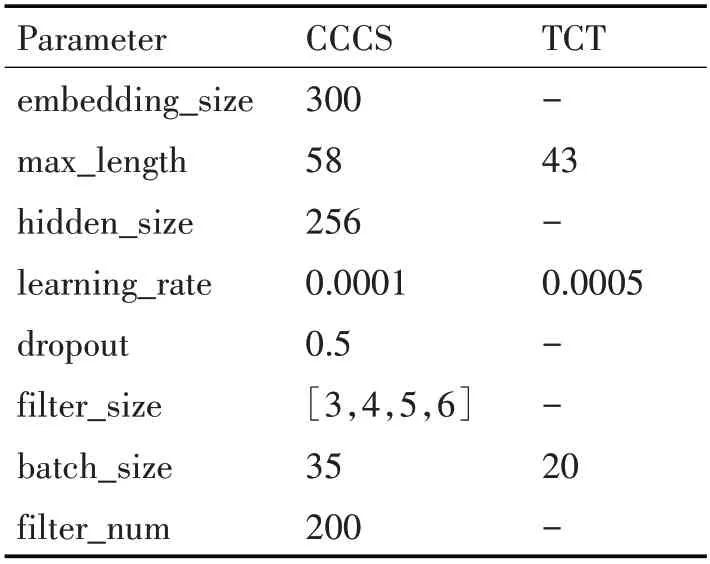
表2 模型超參數(shù)設定
4.3 實驗對比分析
本文采用正確率作為模型的評價指標。它是廣泛應用于信息檢索和統(tǒng)計分類領域的度量值,用來評估模型結果的質量。同時,為了檢驗本文所提模型BCCNN的性能,實驗中設置了兩個基準系統(tǒng):1)機器學習模型方法SVM[8],該模型使用復句主語、謂語再加上時間副詞、方位詞等相關特征,借助《知網(wǎng)》將特征量化,最終實現(xiàn)復句關系分類。2)最大熵模型[22],該方法根據(jù)依存句法樹中句子的成分特征以及依賴關系特征,并且加入單詞對特征進行建模實現(xiàn)句間關系的識別。3)統(tǒng)計學習方法語義相關度算法[11],該方法利用復句核心詞跨度、詞頻以及關系詞搭配距離進行計算復句語義相關度,判別復句的關系類別。表3展示了使用深度學習方法的本文所提模型與以上基準模型性能的比較。為了驗證所提方法的可行性,同時在TCT數(shù)據(jù)集中進行相同的實驗。
經(jīng)實驗驗證,本文所提出的方法在非充盈態(tài)二句式復句上的關系類別自動標識正確率達到了92.4%和90.7。實驗結果對比分析如表3所示。
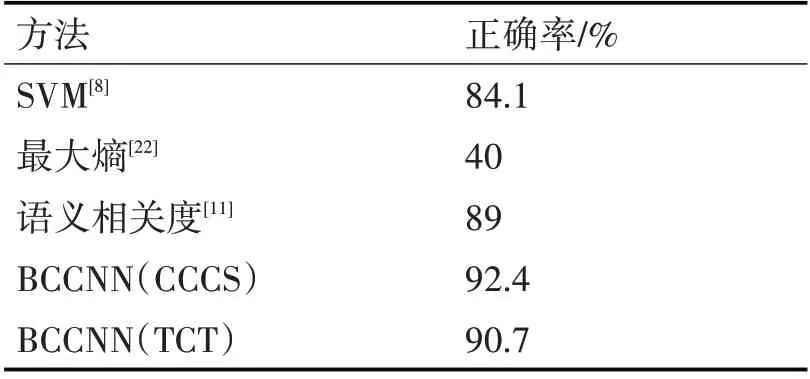
表3 實驗對比結果
其中,傳統(tǒng)機器學習模型SVM識別方法僅能識別并列與非并列復句的關系類別。而基于最大熵的句間關系識別方法的正確率較低,不能滿足實際應用中的需求。
本文所提模型BCCNN與目前效果最好的基于語義相關度識別方法相比,其正確率提高了1.7%~3.4%,并且模型的可拓展性也有所提升,它可以引入不同復雜度的神經(jīng)網(wǎng)絡結構,較語義相關度識別方法更加適應當下自然語言中高維度、大數(shù)據(jù)等特點的計算環(huán)境。
5 結語
本文在復句語義關系識別任務上采用局部語義特征與全局語義特征相互結合相互補充的方法,提出了一種針對二句式非充盈態(tài)有標復句的基于詞聚類的CNN與Bi-LSTM相結合的識別方法。該方法同時考慮了句間自身所蘊含的語義信息、上下文信息和單詞間的語義相似信息以及局部特征信息,而且還考慮了復句內部的長距離語義依賴特征信息,這些特征信息促進了復句關系類別的識別。在復句關系識別任務中,復句的句間語義、語境以及句法等特征信息對于該任務是尤為重要的。在本文所提模型中僅考慮了詞語間的相似性特征,對于句間的語義相似性,結構特性等未考慮,同時也只是針對二句式非充盈態(tài)有標復句展開研究。對于無關系標記的復句關系類別的識別,以及進一步對神經(jīng)網(wǎng)絡模型的再次改進,提高識別正確率是本文下一步的研究工作。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
