面向輿情監測的話題追蹤方法*
2021-09-15 08:34:56陳黎明黃瑞章秦永彬陳艷平劉麗娟
計算機與數字工程 2021年8期
陳黎明 黃瑞章 秦永彬 陳艷平 劉麗娟
(1.貴州大學計算機科學與技術學院 貴陽 550025)(2.貴州省公共大數據重點實驗室 貴陽 550025)(3.貴州師范學院 貴陽 550018)
1 引言
如今各大新聞網站會對各種各樣的事件進行報道,這些大量的新聞報道中既存在著正能量的有利信息,也可能隱藏著負面或者敏感的信息。一條普通新聞一旦被關注可在極短的時間傳播開來,往往會從普通事件演變成爆點事件,繼而引發政府公信力下降等問題。因此,輿情監管部門對新聞報道高度重視,要求加強監測力度,密切關注事態發展。
話題檢測與跟蹤(Topic Detection and Tracking,TDT)[1]是一種面向新聞信息流的處理技術,旨在自動識別新話題和持續跟蹤已知話題,其中話題由一個種子事件以及與其直接相關的事件組成。話題追蹤作為TDT子任務,其目的是依據給定的新聞集合或描述在后續辨認出話題相關報道,能夠用于快速獲取話題信息,協助有關部門進行輿情監測和分析。
輿情監測的對象為熱點或敏感話題,需要人為介入的機制,因此更傾向于使用一組關鍵詞來進行話題追蹤,方便在追蹤過程中進行調整。根據關鍵詞來進行特定話題追蹤,有以下難點:1)輿情新聞數據容易遺漏。使用關鍵詞進行簡單匹配會引入大量無關數據,所以需要衡量詞語在文章中的重要性,常用來衡量詞語重要性的方法難以處理詞語出現頻率較低的情況,這會導致當新聞中與話題相關的信息出現頻率較低時難以追蹤到此類新聞數據。2)用戶給定的關鍵詞可能不全,不足以全面描述話題,造成追蹤結果不理想。3)隨著時間的變化,話題重心也在變化,會產生話題漂移現象,話題關鍵詞也隨之變化,初始給定的關鍵詞需要動態更新。
為了解決上述問題,本文提出了一種面向輿情監測的話題追蹤方法,根據用戶給出的關鍵詞監督信息進行話題追蹤,充分考慮人為介入的應用場景;針對輿情新聞數據容易遺漏的問題,本文通過對話題關鍵詞進行加權的TextRank算法來提取有傾向的關鍵詞作為文本特征表示,進而提升追蹤效果;針對關鍵詞不完全的問題,對輿情數據進行分析,通過點互信息對話題關鍵詞進行補全;針對話題漂移的現象,在話題追蹤過程中根據關鍵詞衰減指數[2]對話題關鍵詞進行動態調整。實驗結果表明,本文方法在面向輿情監測的話題追蹤任務上取得了較好的效果。
2 相關工作
話題追蹤是在后續新聞報道中辨認出已知話題所相關的新聞報道[3],可以為新聞事件的追蹤及判斷決策提供輔助支持[4]。針對話題追蹤的研究集中在分類或聚類算法的選擇與融合、自適應話題追蹤幾個方面。
基于分類的追蹤方法利用訓練好的分類器來進行話題相關性分析。文獻[5]使用SVM算法訓練了一個是否相關的分類器,避免了需要類型標簽的問題。文獻[6]在改進型DF文本特征的基礎上,通過構建樸素貝葉斯模型來實現話題追蹤。文獻[7]提出了一種基于改進KNN的話題跟蹤算法,解決了由于數據不平衡和跟蹤代價較高的問題。雖然分類算法使用廣泛,但需要大量訓練數據。此外隨著時間的發展,話題的重心在動態變化,會產生話題漂移的現象,簡單的分類算法已經不能滿足動態話題追蹤需求。
基于聚類的追蹤方法常見的是SinglePass算法以及K-means算法。文獻[8~10]使用了改進的SinglePass算法來進行話題追蹤,其主要研究在于選取不同的文本特征來提升聚類效果。雖然這類算法效率較高,但容易受輸入順序的影響。文獻[11]提出了一種改進的K-means算法,基于新聞報道相似性選擇初始聚類中心點,保證各新聞話題集群具有很好的區分度。文獻[12]根據K-means聚類結果對子話題向量集進行動態調整,能夠更精確地對話題繼續追蹤。但K-means算法又具有其局限性,如對初始中心點的選擇敏感和用戶必須自定義分組K等。
由于話題漂移現象的存在,自適應話題追蹤得到了進一步發展。此類算法在話題追蹤時將新特征融入至初始模型并對特征項權重進行實時修正,進而改進追蹤效果。文獻[13]提出了一種基于詞匯相關性的自適應追蹤方法。文獻[14]利用最小特征平均可信度閾值更新策略來完善話題模型。文獻[15]基于時間的分布屬性調整特征向量權重分配,實現話題模型的自適應學習更新。文獻[16]根據報道時間特點研究了動態閾值話題追蹤方法。文獻[17]提出一種基于關聯語義網絡的話題追蹤方法,解決了無法詳細描述話題追蹤趨勢的問題。文獻[18]利用了主題新穎性和消退概率來追蹤話題。
相比于上述方法,本文方法基于關鍵詞對特定話題進行追蹤,更適用于輿情監測的應用場景。
3 方法介紹
3.1 方法概述
本文方法流程如圖1所示。待追蹤新聞由新聞標題和正文組成,話題表示為一組關鍵詞,人為給定的關鍵詞監督信息作為其初始值,用戶可以在追蹤的過程中進行介入,修改話題關鍵詞。在每批待追蹤輿情新聞數據到來時,追蹤流程按以下步驟進行處理。首先,通過對話題關鍵詞進行加權的TextRank算法提取新聞關鍵詞。其次,通過點互信息對話題關鍵詞進行補全。最后,計算每篇新聞文本和話題的關鍵詞相似度,相似度大于閾值的新聞文本被判定為與話題相關,并對話題關鍵詞進行反饋更新。接下來,將對這些步驟做詳細介紹。
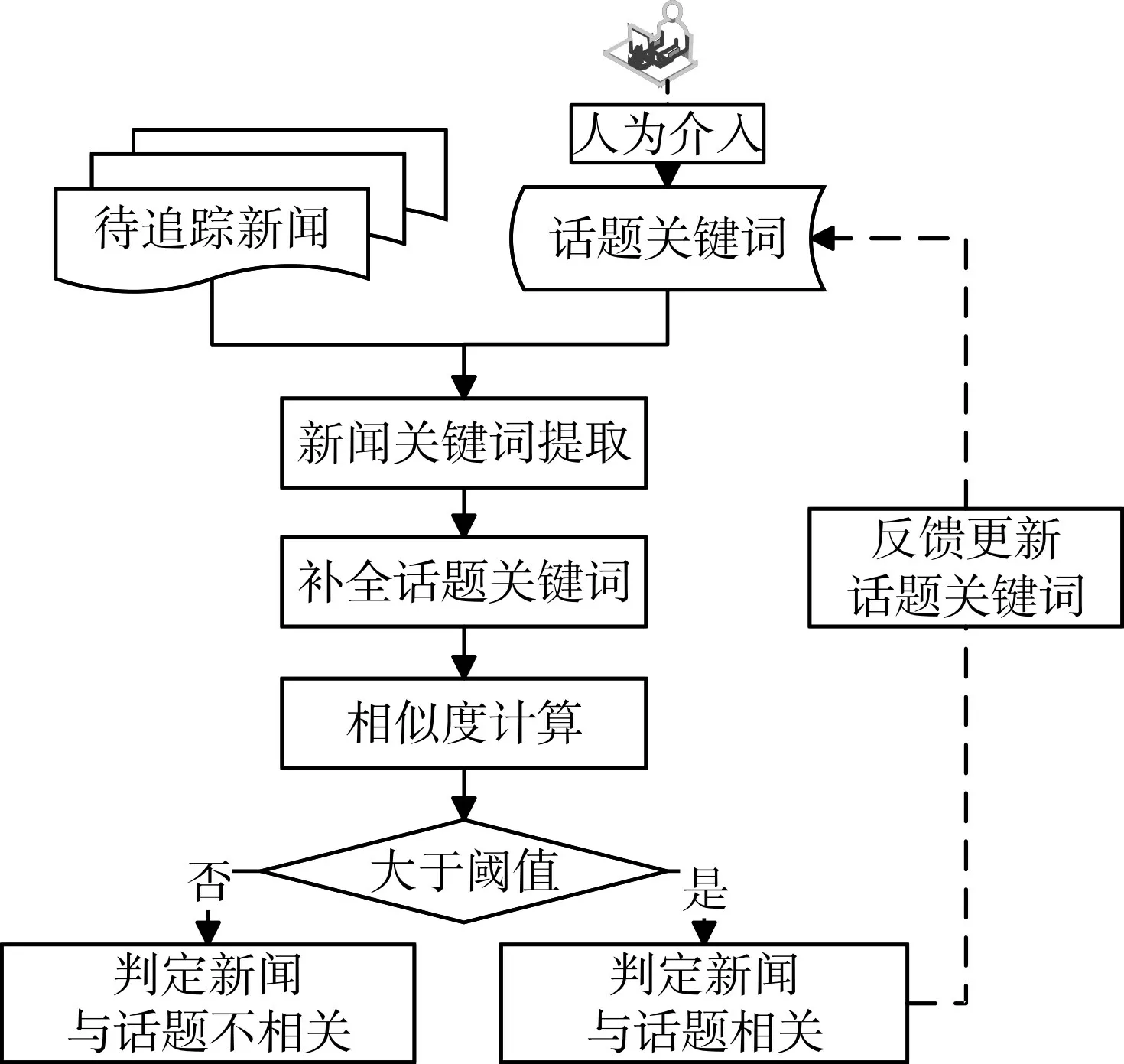
圖1 話題追蹤方法流程
3.2 新聞關鍵詞提取
目前最常見的關鍵詞抽取算法為TextRank[19],它是一種基于詞匯圖模型的算法,把文檔看作是由詞匯構成的圖結構,依靠文檔自身的結構關系,即可實現關鍵詞抽取,簡單有效,但傳統TextRank算法忽略了詞語本身的重要性信息[20]。當在追蹤某個的特定話題時,僅關心特定的一些詞語,這些詞的重要程度比其他詞語高,比如話題關鍵詞。因此,本文對傳統TextRank算法進行了改進,對話題關鍵詞加權,提高話題關鍵詞在新聞中出現時被作為新聞文本關鍵詞提取出來的概率。
設G(V,E)是由給定文本的詞匯構成的一個圖結構,那么對于該文本中任何一個詞語Vi,其基于加權TextRank算法的權值迭代公式為
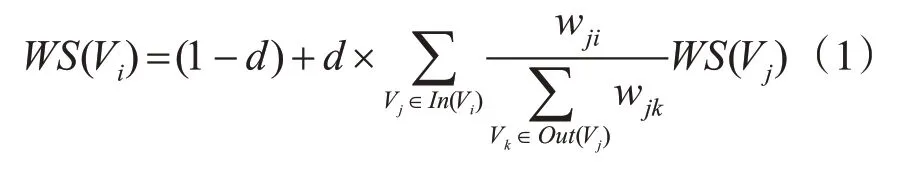
式(1)中d為調節系數,一般取0.85;I n(Vi)表示指向節點Vi的所有節點的集合;Out(Vj)表示節點Vj指向的所有節點的集合。wji為節點Vj的詞語重要性影響力傳遞到節點Vi的權重,其計算公式如下:
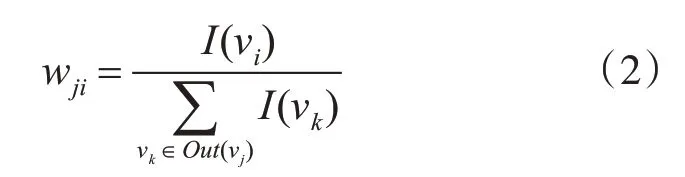
式(2)中I(vi)表示節點Vi的重要性取值,設λ為對詞語進行加權的參數,本文中λ取2,則I(vi)賦值如下:

基于式(1)~(4)進行迭代運算,當式(1)兩次迭代結果之間的差異非常小時停止迭代運算,該值一般取0.0001。然后按照大小對WS(V)進行降序排序,選取前8個候選詞作為新聞文本關鍵詞。
3.3 相似度計算和話題追蹤
Jaccard相似度用來比較樣本集之間的相似性,Jaccard系數值越大,說明相似度越高。設KT為話題關鍵詞集合,K N為新聞文本關鍵詞集合,則Jaccard系數計算如式(5)所示。
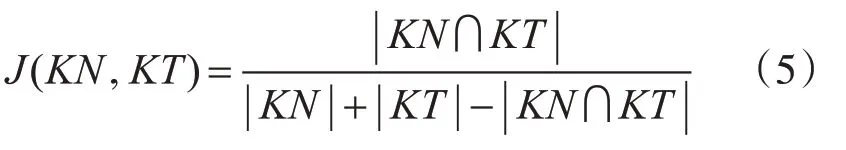
通過式(5)計算追蹤話題和新聞文本之間的相似度,相似度大于閾值α的新聞文本被判定為與話題相關,相似度低于閾值的則判定為與話題不相關。
3.4 話題關鍵詞更新
為了充分補全話題關鍵詞,采用點互信息PMI(Pointwise Mutual Information)來挖掘潛在的關鍵詞。PMI被用來衡量兩個關鍵詞之間的關系,PMI的大小代表了它們關系的強弱。PMI的計算公式如下:

通過式(6)計算出新聞文本關鍵詞對的PMI,挑選出PMI大于閾值μ的關鍵詞對。如果一個關鍵詞和任意兩個話題關鍵詞的PMI大于閾值,則添加該關鍵詞到話題關鍵詞集中,對話題關鍵詞進行補全。
此外,針對話題漂移現象,需要融入新的話題特征,對話題關鍵詞進行更新。當一篇新聞被判定為與話題相關時,采用基于關鍵詞衰減指數的算法來對話題關鍵詞進行動態更新,詳細描述如算法1所示。設話題候選關鍵詞向量為V(K)=(K1:w1,K2:w2,…,Kn:wn),其中K表示話題候選關鍵詞,w表示候選關鍵詞權重。第一次進行更新時,V(K)用話題關鍵詞進行初始化,w的初始值為2。
算法1話題關鍵詞更新算法
輸入:
話題候選關鍵詞向量V(K)
新聞文本關鍵詞集合K N
衰減指數θ
輸出:
更新后的話題關鍵詞集合K Tupdated
更新后的話題候選關鍵詞向量Vupdated(K)
1)for每個關鍵詞Ki∈KNdo
2) ifKi i n V(K)then
3)wi←wi+0.5
4) else在V(K)中添加(Ki,0.5)
5)for每個關鍵詞Kj i n V(K)do
6) ifKj?KNthen
7)wj←wj*θ
8)輸出Vupdated(K)
9)Vupdated(K)按權重w大小進行排序
10)初始化KTupdated為空
11)forKm i n Vupdated(K)do
12) 在KTupdated中添加Km
13) ifKTupdated的關鍵詞個數>8 then
14) break
15)輸出KTupdated
4 實驗及分析
4.1 實驗數據及評價標準
為了驗證所提方法的有效性,本文從新浪、鳳凰、搜狐、網易等新聞網站收集了2018年11月~2019年1月共28125篇新聞作為實驗原始數據。從原始數據中選取五個話題進行追蹤,并對其進行標注,除五個話題外,其它數據均為反例。話題名稱和對應的新聞數量如表1所示。

表1 數據集
實驗使用準確率P、召回率R和兩者綜合性能指標F值三個指標進行量化考察,F值越高,話題追蹤性能越好。設TP為在追蹤結果中被判定屬于某話題且實際也屬于該話題的新聞數量,FP為在追蹤結果中被判定屬于某話題但實際不屬于該話題的新聞數量,FN為在追蹤結果中被判定為其它類別但實際屬于該話題的新聞數量。則準確率P、召回率R和F值的計算公式如下:

4.2 話題追蹤對比實驗
為了驗證本文方法在話題追蹤上的效果,選取基于SinglePass的追蹤方法和文獻[2]方法作為對比方法。實驗設置相似度閾值α為0.1,衰減指數θ為0.8,時間窗口為天,并選取兩篇種子新聞作為對比方法的初始類心,其中基于SinglePass的追蹤方法選取的文本特征表示方法是TF-IDF。實驗結果如表2所示。
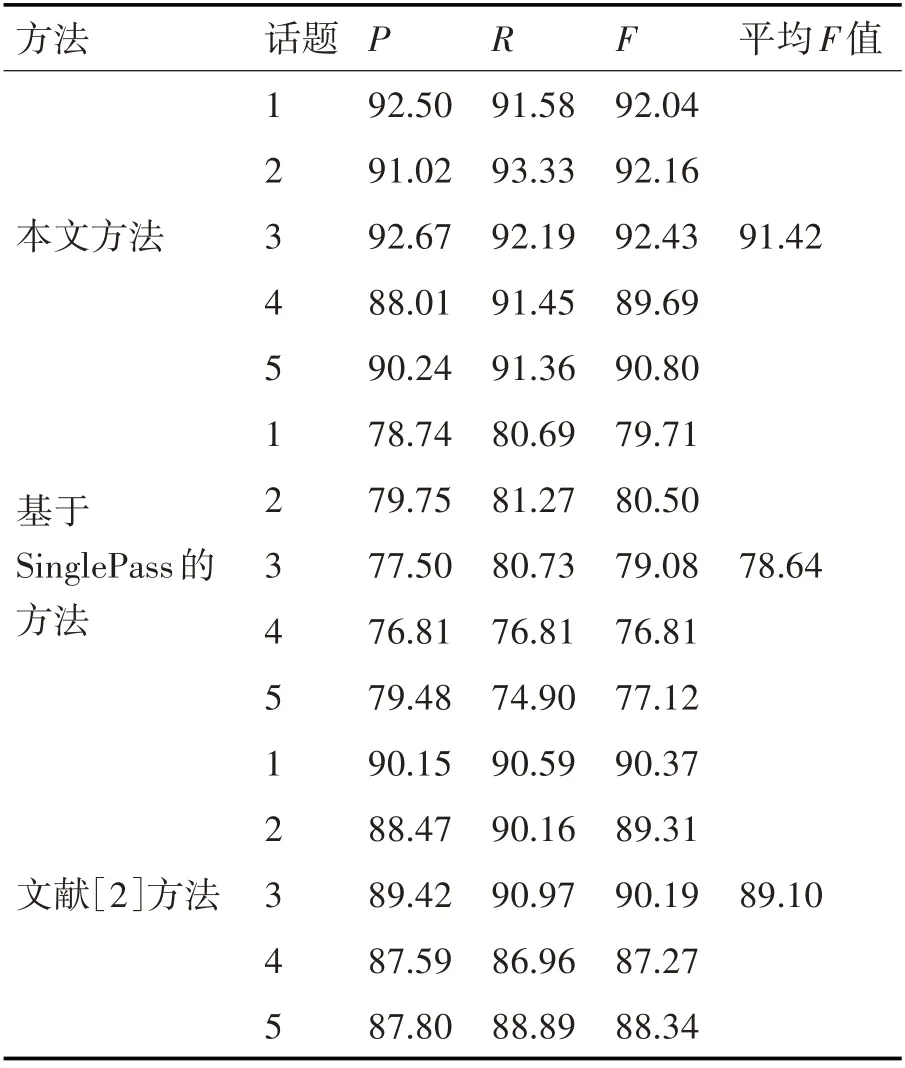
表2 話題追蹤方法實驗結果
從表2可以看出,本文方法優于基于Single-Pass的追蹤方法,原因是選取了有傾向的關鍵詞作為新聞文本特征表示,而基于SinglePass的方法選取的文本特征表示方法是TF-IDF,當新聞中關鍵詞出現頻率比較低時,其所占權重較小,導致聚類效果不理想,而有傾向的關鍵詞加大了重要詞的權重,能夠提取出關鍵詞出現頻率低的新聞。此外,本文方法和文獻[2]方法都有反饋更新話題關鍵詞的機制,然而本文方法在平均F值上比其高出2.32%,主要是因為本文利用PMI對話題關鍵詞進行了補全以及引入了話題關鍵詞候選向量,在反饋更新策略上做了改進,從而取得了較為優越的結果。
4.3 話題關鍵詞分析
本文基于關鍵詞對輿情話題進行動態追蹤,關鍵詞的變化影響著話題自適應追蹤的效果。表3展示了本文方法在追蹤“孟晚舟被捕”話題過程中關鍵詞的變化。從表中可以看出,話題發生了漂移現象,重心從“被捕”發展成為了“保釋”,這表明本文方法能夠有效地應對話題漂移現象,對話題進行自適應追蹤。

表3“孟晚舟被捕”關鍵詞變化
5 結語
本文提出了一種面向輿情監測的話題追蹤方法,根據給出的關鍵詞信息來進行特定的話題追蹤,充分考慮到了輿情監測需要人為介入的應用場景,解決了輿情新聞容易遺漏、關鍵詞不完整、話題漂移的難點,取得了較好的追蹤效果。在未來的工作中,擬研究如何根據追蹤到的新聞數據梳理話題發展脈絡。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
