基于支持向量機的磨削表面燒傷識別研究*
2021-09-15 08:35:14孫為釗程廬山
計算機與數字工程 2021年8期
孫為釗 程廬山 周 俊
(上海工程技術大學機械與汽車工程學院 上海 201620)
1 引言
近年來,隨著產業改革的深入進行,以往追求數量的運營方式已經無法適應現代需求,企業紛紛從追求數量模式轉變到追求數量和質量并重的模式。為了提高零件的產量以及質量需要精確掌握磨削時的溫度,在溫度過高時及時采取措施,減少損失。
磨削加工是現代機械制造業實現精密加工和超精密加工的基本工藝技術。由于磨削過程持續的時間較短且加工的金屬層較薄,磨削過程中產生的熱量大部分會集中在磨削區內,在工件表面形成局部高溫,當溫度超過臨界值,就會引起表面熱損傷。在加工時燒傷的零件,內部的金相組織發生氧化,還會產生裂紋,表面材料脫離機體的現象[1],表層硬度下降,影響零件性能。
針對金屬磨削燒傷問題,國內外的研究者做了大量的研究。劉曉初[2]等對GCr15軸承鋼進行了不同砂輪速度、工件速度下的磨削試驗,研究結果表明:燒傷會增加工件表面粗糙度,并分析了合適的加工參數,為避免發生磨削表面燒傷提供了參考依據。黃新春[3]等針對高強度鋼AerMet100的磨削燒傷問題,在大量實驗的基礎上建立了磨削力和磨削溫度關于磨削參數的回歸經驗模型,為Aer-Met100的磨削燒傷測試和控制提供了理論指導。易茜[4]通過對彩色CCD圖像的研究將顏色特征用于燒傷等級的判斷,取得了比較滿意的結果。王延忠[5]等進行了18CrNi4A材料齒輪磨削加工試驗,驗證了有限元仿真分析的可信性。Lin[6]等對鋼軌鋼U71Mn進行磨削試驗研究,發現鋼軌磨削燒傷的實質是磨削溫度的升高引起表面氧化的加劇和有色金屬氧化物的積累。A.O.Odior[7]提出了一種利用神經網絡和模糊技術進行磨削過程的控制系統,使用神經模糊模型來控制磨削過程,使磨削過程在可接受的溫度下獲得最大的輸出功率,最大金屬去除率,不會導致工件燒傷。
支持向量機(Support Vector Machine,SVM)是一種經典的機器學習模型,以其處理小樣本以及強大的分類能力在人像識別、文本分類、筆跡識別等領域取得了突破性進展,但目前在機械加工方面的應用研究仍然不多。本文提出基于SVM的磨削燒傷識別模型,希望能夠準確識別不同的燒傷類型,對SVM識別模型應用到實際生產加工中有一定的理論指導作用。
2 磨削燒傷理論以及判別方法
磨削加工主要有三個階段:滑擦、耕犁和形成切屑。磨削產生的熱量是在這三個階段由能量轉變而成。大多數磨粒以負前角進行切削,因此在非常高的磨速下,磨削區內產生的瞬時高溫改變了金相組織,使某些部分出現變色現象,這就是磨削燒傷[8]。燒傷可以根據不同的參照分為很多類型,根據外觀不同,可分為斑狀燒傷、條狀燒傷、全面燒傷;根據表層顯微組織的變化可分為回火燒傷、退火燒傷、淬火燒傷[9]。
判別燒傷的方式主要有目測法、酸洗法、顯微硬度法等。其中,目測法依據燒傷工件表面所呈現出的顏色深淺來鑒別燒傷程度。酸洗法使用酸性溶液清洗燒傷表面,然后依據顯示出的顏色鑒別燒傷程度。顯微硬度法根據燒傷后的工件表面顯微硬度的變化來評價燒傷程度,燒傷越嚴重,顯微硬度下降越多。
3 磨削燒傷圖像特征提取
磨削燒傷后的工件表面除了會顯示出不一樣的顏色特征還會顯示出紋理特征,通過提取這些特征表示不同類型的燒傷,使用支持向量機對提取的特征進行訓練進而能夠判斷出是某種類型的燒傷。
3.1 顏色特征的提取
在圖像顏色特征提取的眾多方法中,由于顏色矩特征具有維數低和圖像顏色信息主要存在于低階矩中的特點,本文故采用三階顏色矩法提取燒傷圖像顏色特征。其三階矩公式定義如下[10]:
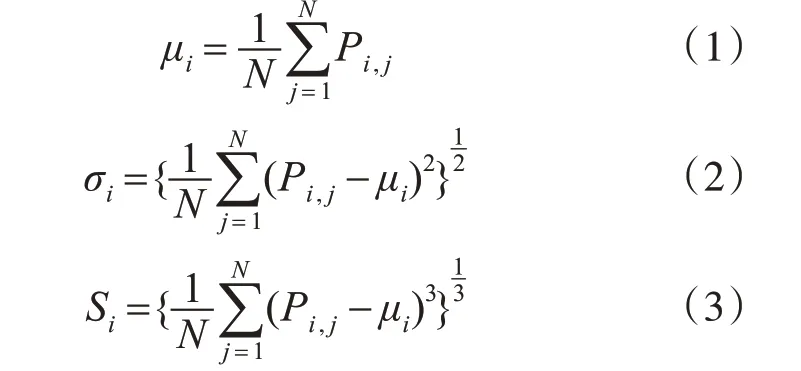
其中,i為彩色圖像顏色通道,共有三個通道,即紅綠藍(RGB)三通道;j為圖像的灰度值;μi值為彩色圖像i通道下的一階顏色矩,σi為二階顏色矩,Si為三階顏色矩,P為彩色圖像第i個顏色通道分量中灰度為j的像素出現的概率,N為圖像像素總和值。
3.2 紋理特征的提取
圖像中紋理特征實質是反映圖像中輪廓線條的粗細、方向、間距等數學統計量,由于灰度共生矩陣計算較簡便,并且它可以較完整的保存圖像局部紋理特征,故本文將灰度共生矩陣作為紋理特征的特征量。下面是四個有效且最常用的公式來表示灰度共生矩陣[11]。
1)能量:
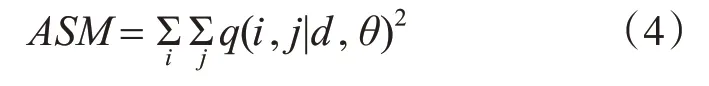
其中,i與j為圖像像素矩陣位置,d為像素的灰度空間距離,θ為圖像紋理生成的方向,q為圖像上位置關系為d的灰度分別為i,j的兩個像素出現的次數。能量代表了圖像紋理的粗細程度,圖像紋理越粗,ASM較大;反之,ASM較小。
2)熵:

熵代表了圖像信息含量的多少,圖像中紋理越模糊,則熵值越小;反之,圖像含有越多清晰的紋理,則熵值越大。
3)對比度:

對比度代表圖像紋理清晰的程度。圖像中紋理的溝紋越深,則對比度值CON越大,圖像紋理是越清晰。反之,對比度CON越小,圖像紋理越模糊。
4)相關性:
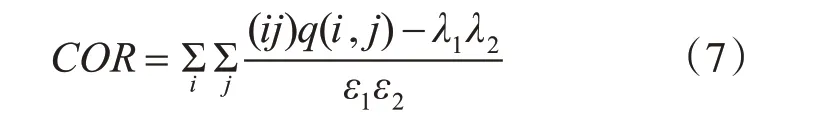
將能量、熵、對比度以及相關性作為磨削燒傷的圖片紋理特征描述,磨削燒傷圖像紋理特征量確定為以下表示:

3.3 全局紋理特征的提取
為增加圖像一個全局特征維度,使提取特征能夠更準確表達圖像紋理特征。將顏色矩提取的三個特征數值與灰度共生矩陣提取的四個特征數值累加,得到一個新的紋理全局描述特征,表達式如下表示:

4 支持向量機理論及模型
磨削加工過程是復雜的非線性過程,充滿了變化。簡單的線性方法很難判斷是否發生燒傷。支持向量機的預測模型具有解決有限樣本、非線性及高維識別問題的優勢[12],在機械加工方面使用仍然較少。本文探討支持向量機理論在磨削燒傷方面的應用。
4.1 支持向量機模型
支持向量機是一種廣義的線性模型分類器,其主要功能是對數據進行二元線性分類,因其出色的分類能力而被應用于各個領域。SVM模具有較高的分類精度以及很好的泛化性[13]。
4.2 SVM的分類算法步驟
對于分類問題,支持向量機具體的學習算法步驟如圖1所示[14]。
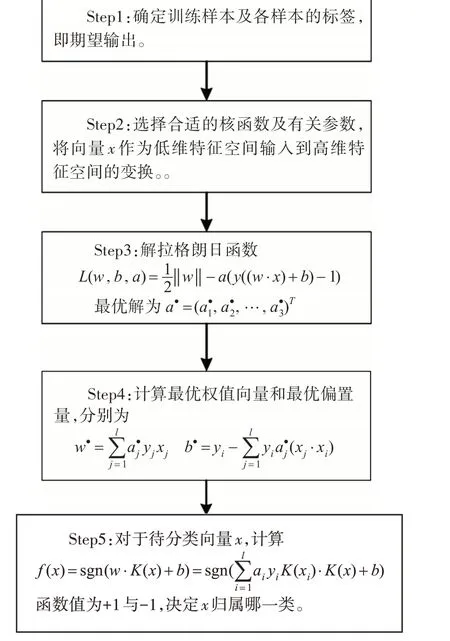
圖1 SVM算法步驟
4.3 圖像數據庫的建立
為保證高質量的訓練樣本庫,采用單純磨削燒傷圖像作為樣本,即包含未燒傷、斑狀燒傷、線條燒傷、全面燒傷四種類型的圖像。為此,選取符合條件的圖像作為磨削燒傷圖像樣本建立磨削燒傷圖像樣本庫。
圖像樣本庫包括上述四類樣本各1000幅圖像,共計5000幅樣本。部分圖像樣本展示如表1所示。展示樣本對應特征值如表2所示。

表1 燒傷圖像樣本庫示意圖
如表2所示,黃色標記的特征值是未燒傷圖的全局紋理特征SUM值,是四類磨削燒傷圖SUM值中最大的數值,所以可以通過全局紋理特征SUM將未燒傷圖從圖像數據庫中分類提取出來;綠色標記的特征值是全面燒傷的一階顏色矩,是四類磨削燒傷圖值中最小的數值,所以可以通過一階顏色矩值將全面燒傷圖從圖像數據庫中分類提取出來;此時還剩下斑狀燒傷圖和線條燒傷圖兩類需要進行區分,可根據三階顏色矩S特征值與對比度CON特征值將剩下的這兩類進行區分識別。較好的特征量選取是圖像識別準確率的保障,根據表2中的特征數據值可以主觀地進行磨削燒傷圖像的分類識別,這也進一步證明本文所提取圖像紋理特征的有效性。
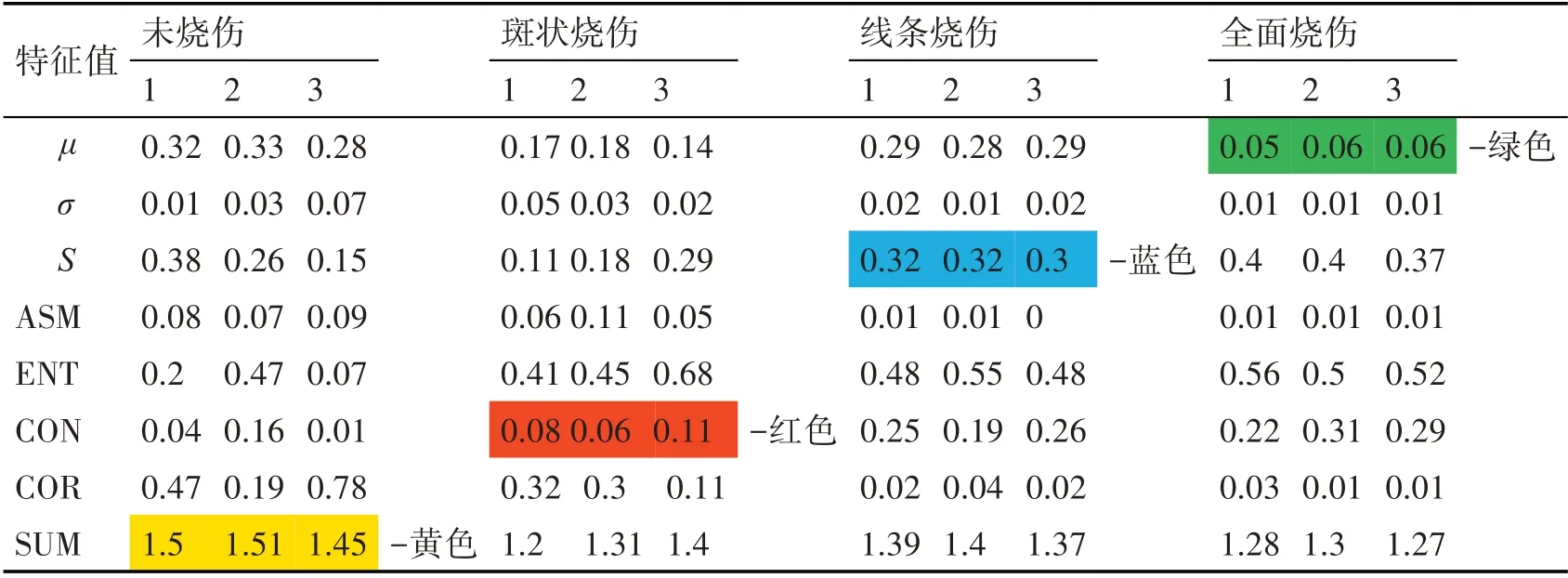
表2 展示樣本對應特征值
5 磨削燒傷圖像分類模型建立與分析
在SVM模型中,高斯核函數的作用是將原始數據空間映射到無限維空間,高斯核函數因子g取值越小,模型分類就越細致,但會出現過擬合問題。懲罰因子c的作用是權衡訓練風險與模型結構風險,懲罰因子c越大,則訓練風險越小,模型結構風險越大,會存在過擬合問題;反之,則存在欠擬合問題[15]。綜上所述的模型參數取值問題,采用網格搜索尋優算法尋找最佳的懲罰因子c,高斯核函數因子g。
考慮到模型訓練耗時問題,采取隨機抽樣的方法來尋取最優的參數,即在建立好的磨削燒傷圖像庫中的四類燒傷圖片分別隨機抽取100張圖像共計400張作為尋優的圖像集。網格搜索尋優結果如表3所示。從表3中可以看出,當懲罰因子c=16,高斯核函數因子g=0.6時,模型訓練準確率為最高的92.76%。
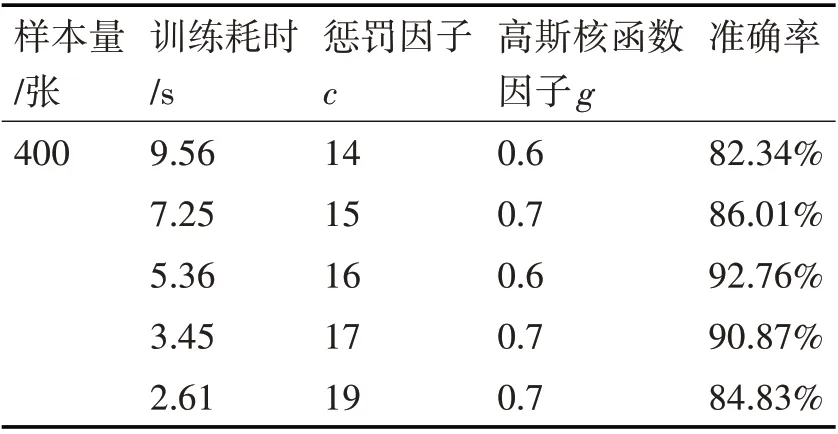
表3 SVM模型參數網格尋優
其次,基于最佳的懲罰因子c和高斯核函數因子g,在不同數量的樣本圖片下進行SVM模型訓練,可得到多個分類模型,并對這些模型進行訓練準確率的測試,分析SVM模型的準確率隨著樣本量的不同而發生的變化的情況;最后,選擇最高訓練準確率的模型作為磨削燒傷圖識別模型,用于對未訓練的燒傷樣本的識別分類。具體過程如下:
1)對不同類型的磨削燒傷圖像進行標記:未燒傷為1,斑狀燒傷為2,線條燒傷為3,全面燒傷為4。將磨削燒傷圖像的的不同類別的特征值提取出來形成特征數據值庫;
2)利用尋找的最佳懲罰因子c和高斯核函數因子g作為初始訓練參數對數目不同的樣本燒傷圖片進行訓練,并建立分類模型。將訓練樣本分別從四類燒傷圖像中隨機抽取相同的數目,各訓練模型樣本量設置為200張、500張、1000張、1500張和2000張燒傷圖像五組;
3)五組SVM燒傷圖像的SVM模型建立完成后,對其進行訓練并測試,得到訓練精度。得到的結果如表4所示。

表4 燒傷圖像分類模型性能
由表4可知,在2000到500幅時,隨著樣本數量的減少,識別的準確率卻呈上升的趨勢。在樣本量為2000時總體的識別率最低,而當樣本量為500時總體的識別率最高。這是因為當樣本量為2000時數據量較大時,訓練計算量太大,有較多支持向量,導致數據偏斜,模型決策函數得到的超平面過擬合,影響準確率。而當樣本量為500時數據量既不大也不小,計算量也不會太大,不會出現數據偏斜的情況,所以準確率最高。當樣本量為200幅時,數據量太小,樣本包含的信息過少,模型泛化性較低,在訓練時能很好地分類,但在測試時準確率卻比較低,因此選擇合適的樣本量能夠提高模型識別準確率。
6 結語
本文提出了基于支持向量機的磨削燒傷圖像分類模型,通過不同樣本量對模型進行訓練及測試。結果表明:
1)建立燒傷類型豐富的圖像庫是圖像精確識別的基礎,提取不同類型燒傷的特征構建燒傷圖像特征庫,可以保證樣本庫的質量和純度。
2)四種燒傷圖像的紋理特征量值之間有所重疊,經過計算,只需8個特征量可以保證模型識別準確度。
3)利用網格搜索算法得到最佳的初始參數后建立的燒傷圖像分類模型性能優越,燒傷圖像識準確率有很大的改善。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
