基于改進D-LinkNet 模型的高分遙感影像道路提取研究
2021-09-15 07:36:46張立恒薛博維何立明
計算機工程 2021年9期
張立恒,王 浩,薛博維,何立明,呂 悅
(1.長安大學(xué) 信息工程學(xué)院,西安 710064;2.西安中科星圖空間數(shù)據(jù)技術(shù)有限公司,西安 710000)
0 概述
高分遙感影像是現(xiàn)代交通體系的重要載體,而路網(wǎng)提取技術(shù)是近些年來逐漸發(fā)展成熟的一門獨立學(xué)科,其在高分遙感影像中的應(yīng)用價值主要體現(xiàn)在車輛導(dǎo)航、智能交通、地圖繪制、城市規(guī)劃等諸多領(lǐng)域。同時也給自然災(zāi)害預(yù)警、災(zāi)后重建、軍事目標打擊等相關(guān)場景提供有效的參考,對經(jīng)濟、政治、地理、軍事等方面具有不可替代的意義[1-2]。
但隨著遙感技術(shù)的不斷革新,測量精度已經(jīng)達到亞米級,分辨率也已經(jīng)突破分米(dm)級別,并且有進一步發(fā)展的趨勢。伴隨而來的是地物背景信息的細節(jié)更加豐富,非道路信息如植被陰影、車輛流動、高樓建筑遮擋、人流流動等作為干擾噪聲十分繁雜,造成目標信息提取難度增加,即道路信息識別難度加大。另外,在路網(wǎng)識別過程中不同質(zhì)地的道路會呈現(xiàn)出不同的光譜特性[3],還可能出現(xiàn)同譜異物或同物異譜的現(xiàn)象;當前道路提取絕大多數(shù)都采用半自動化方式,加上算法自身魯棒性較差、傳統(tǒng)方法識別精度較低、過程繁瑣等一系列問題,都給路網(wǎng)提取帶來較大的挑戰(zhàn)。
目前,以卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)為典型代表的深度學(xué)習(xí)理論,在圖像分類[4-5]及目標檢測[6-7]等領(lǐng)域均表現(xiàn)出巨大的發(fā)展?jié)摿ΑI疃葘W(xué)習(xí)作為近來比較熱門的研究方法,其在高分影像道路智能化提取領(lǐng)域的實際應(yīng)用也取得了長足的發(fā)展。文獻[8]提出CNN 訓(xùn)練大樣本數(shù)據(jù)集的線性整合卷積算法,該算法可以預(yù)測像素區(qū)域為道路的概率,同時為每個像素點分配標記標簽來判斷是否為道路區(qū)域,適用場景為道路邊緣輪廓較粗糙的影像。文獻[9]以地面材質(zhì)不同的分類為依據(jù),提出一種弱監(jiān)督的提取算法,該算法利用Deep Lab 構(gòu)建學(xué)習(xí)網(wǎng)絡(luò),由ResNet 網(wǎng)絡(luò)結(jié)構(gòu)負責測試穩(wěn)定性,最后根據(jù)條件隨機場(Conditional Random Field,CRF)修復(fù)邊界,在滑動窗口利用光譜角度距離連接相鄰路段。文獻[10]提出一種改進型graphcut 道路檢測算法,該算法能夠利用Orchard-Boumand 聚類算法聚類道路和非道路像素點,構(gòu)建Gibbs 能量懲罰函數(shù)中的區(qū)域項,繼而使用maxflow算法對生成的權(quán)重圖進行分割,提取出道路信息。從上述方法的提取效果來看,較之前有大幅度提升,其準確性、魯棒性、適應(yīng)性也較傳統(tǒng)方法有明顯改善。
高分遙感影像道路提取問題的關(guān)鍵在于識別影像中相關(guān)聯(lián)的道路像素特征信息。然而,在一些實際的應(yīng)用場景中,常會因非道路關(guān)聯(lián)像素點的干擾,即受前景道路像素點與背景非道路像素點在量級上存在巨大差距的困擾,這種情況導(dǎo)致很難建立起一種高效的道路分割模型。
D-LinkNet[11]模型架構(gòu)在中心區(qū)域加 入了空洞卷積層[12],這樣能夠最大程度地增大感受野的范圍及促進多尺度特征融合,同時不會造成特征圖分辨率的損失,盡量保留道路的空間細節(jié)信息。本文將D-LinkNet 應(yīng)用于高分遙感影像道路提取研究,并依據(jù)影像中道路的特征對模型做出改進措施,提升該網(wǎng)絡(luò)模型在高分遙感影像中道路的分割精度。
1 高分遙感影像道路提取模型
1.1 D-LinkNet 網(wǎng)絡(luò)模型
D-LinkNet 網(wǎng)絡(luò)模型是北京郵電大學(xué)模式識別實驗室在2018 年的CVPR(Computer Vision and Pattern Recognition)全球衛(wèi)星圖像道路提取競賽(DeepGlobe Road Extraction Challenge)項目中取得最高分數(shù)脫穎而出的模型。本文D-LinkNet 網(wǎng)絡(luò)架構(gòu)是由殘差網(wǎng)絡(luò)構(gòu)建的編碼區(qū)、中心區(qū)域以及解碼區(qū)3 個部分組成。
該模型以LinkNet 作為基本框架,采用一種Encoder-Decoder 的架構(gòu)。該模型的主要思想是:編碼區(qū)將道路信息編碼到特征信息上;解碼區(qū)將編碼的道路特征信息映射到空間中進行分割。由于在中心區(qū)域加入卷積層的基礎(chǔ)上,網(wǎng)絡(luò)本身并未增加學(xué)習(xí)參數(shù),大幅降低了訓(xùn)練的難度。對于道路提取任務(wù),D-LinkNet 增加中心區(qū)域的空洞卷積層能進一步識別道路特征點信息的感受野。空洞卷積層相對于LinkNet 中池化層的優(yōu)勢是在保證特征圖分辨率的同時,不會丟失空間信息。
編碼區(qū)是由1 個尺寸為7×7、stride=2 的初始卷積模塊和4 個殘差模塊組成。殘差模塊使用ResNet34 作為預(yù)訓(xùn)練網(wǎng)絡(luò)結(jié)構(gòu),采用跳躍連接的方式增強區(qū)域塊的泛化表征能力。中心區(qū)域的核心部分是空洞卷積層模塊,該模塊是一種串、并聯(lián)并存的連接方式。另外,本文在原有結(jié)構(gòu)的基礎(chǔ)上嵌入channel-spatial 雙注意力模塊,精準地捕獲道路特征信息。解碼區(qū)采用一種殘差網(wǎng)絡(luò)的瓶頸連接結(jié)構(gòu)[13],該結(jié)構(gòu)利用1×1 的卷積核來提升 網(wǎng)絡(luò)的計算效率,如圖1 所示,最后利用轉(zhuǎn)置卷積上采樣將邊長變?yōu)樵瓉淼?2 倍,還原為原始圖像的尺寸。本文構(gòu)建的改進D-LinkNet 網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。
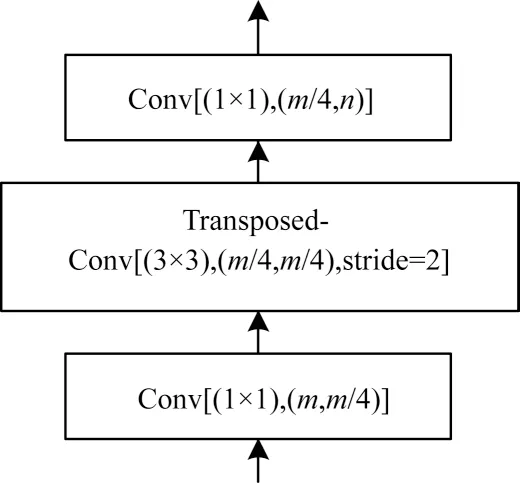
圖1 殘差網(wǎng)絡(luò)瓶頸結(jié)構(gòu)1×1 卷積核Fig.1 Residual network bottleneck structure 1×1 convolution kernel
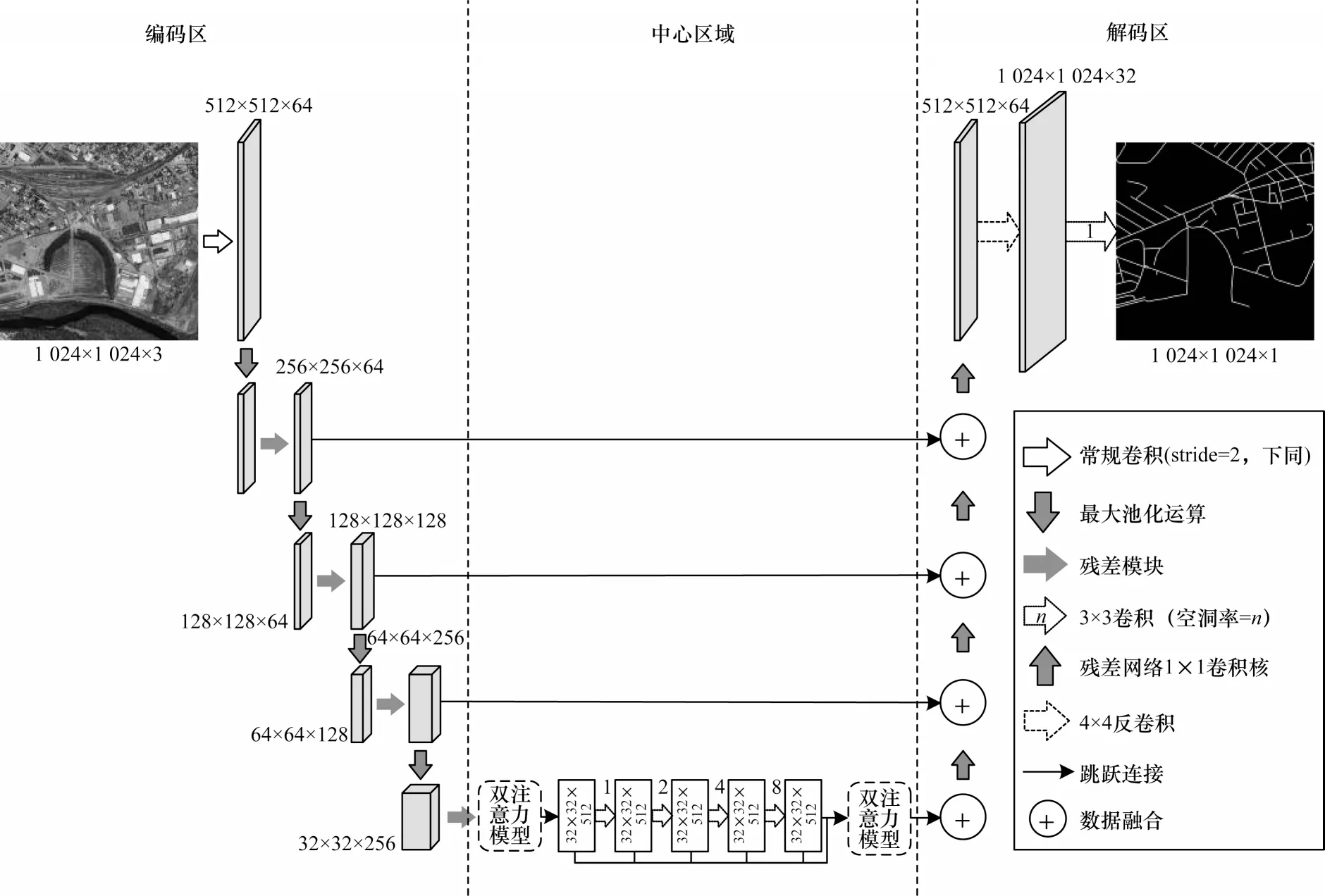
圖2 用于道路提取的改進D-LinkNet 網(wǎng)絡(luò)Fig.2 Improved D-LinkNet network for road extraction
1.2 注意力模塊
在神經(jīng)網(wǎng)絡(luò)中引入注意力機制的目的在于通過對重要的特征進行加權(quán)處理,來增強有效層的特征。對于本文而言,引入注意力機制的作用是從復(fù)雜的背景干擾信息中檢測出條狀道路輪廓。神經(jīng)網(wǎng)絡(luò)主要是通過掩碼這一橋梁搭建注意力機制。掩碼的實現(xiàn)原理是通過一層新的權(quán)重分布層,將圖像中的重要的目標特征信息標注出來,網(wǎng)絡(luò)再通過學(xué)習(xí)及訓(xùn)練獲取標注后的圖片道路區(qū)域,從而形成注意力。注意力機制的優(yōu)勢在于能夠依據(jù)梯度算子的前向傳播及后向反饋能力,通過訓(xùn)練來學(xué)習(xí)圖像中的注意力權(quán)重參數(shù)。本文提出一種綜合注意力通道域[14]、空間域[15]組合形式的新型通道-空間雙注意力域機制,并且對加入的新型注意力模塊展開詳細的說明。
1.2.1 通道域注意力
通道域注意力機制的設(shè)計思路類似于信號與系統(tǒng)分析的傅里葉變換。任意連續(xù)信號均可由正弦波的不同權(quán)重的線性組合表示,而這一時域信號經(jīng)時頻變換可轉(zhuǎn)換成頻域信號的形式。同樣,每張圖像均可由(R,G,B)三通道表示。圖像經(jīng)過n個卷積核的卷積運算,得到n通道的矩陣(H,W,n)。這個過程將圖像的特征信息分配到n個卷積核上,從而生成n通道的特征圖。通過對不同通道賦予不同權(quán)重的大小,體現(xiàn)相應(yīng)相關(guān)度特征信息的通道。
為學(xué)習(xí)每個輸出通道的不同權(quán)重,繼而得出相對應(yīng)相關(guān)度的道路信息,此處使用一種擠壓-激勵模型結(jié)構(gòu)來完成道路通道域信息的提取,圖3 所示為通道域注意力模型。其中X表示輸入圖像的特征信息,經(jīng)過卷積運算Ftr,得到下一層的輸入特征信息U。其核心區(qū)域主要包括擠壓、激勵、尺度變換3 個小模塊。

圖3 通道域注意力模型Fig.3 Channel domain attention model
擠壓過程是一個全局平均池化的運算:

其中:H、W、C分別表示上層張量的高度、寬度以及通道數(shù)。然后對得到的C通道擠壓后的信息引入非線性變換,該過程通過激勵函數(shù)實現(xiàn):
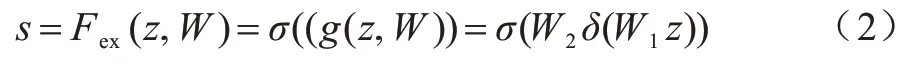
其中:σ表示sigmoid 非 線性激活函數(shù);δ為ReLU 非線性映射激活函數(shù);W1、W2?,通過對權(quán)重參數(shù)zc、s的學(xué)習(xí)訓(xùn)練,獲得一維的激勵權(quán)重參數(shù),用于激活各層通道。最后利用一個尺度函數(shù)Fscale根據(jù)不同通道任務(wù)需求來乘以不同的權(quán)重參數(shù)完成通道道路信息的尺度變換,實現(xiàn)對道路通道信息增強注意力的功能:

其中:uc表示不同的通道;sc表示通過訓(xùn)練學(xué)習(xí)到的權(quán)重參數(shù)。
1.2.2 空間域注意力
空間域注意力機制是通過空間轉(zhuǎn)換器模塊,將原始圖像的空間信息做相應(yīng)的空間信息轉(zhuǎn)換,提取出重要的道路信息。空間域注意力模型如圖4所示。
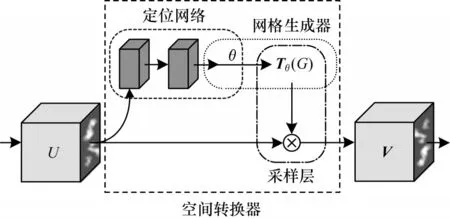
圖4 空間域注意力模型Fig.4 Spatial domain attention model
空間域注意力機制設(shè)計思路是通過學(xué)習(xí)圖像中道路信息,經(jīng)過訓(xùn)練使得空間轉(zhuǎn)換器能夠在復(fù)雜條件下通過旋轉(zhuǎn)、聚焦、縮放的手段將道路信息以框盒的形式提取出來。輸入U會分兩路進入空間轉(zhuǎn)換器模塊:支路1 會直接進入采樣層;支路2 會通過定位網(wǎng)絡(luò)和與其重合的網(wǎng)格生成器部分,這個過程經(jīng)過定位網(wǎng)絡(luò)能夠?qū)W習(xí)一組參數(shù)θ,可作為網(wǎng)格生成器模塊的訓(xùn)練參數(shù),得到的采樣信號本質(zhì)就是一個變換矩陣Tθ(G),再到達網(wǎng)格生成器和采樣層的重合區(qū)域,此時變換矩陣與支路1 的原始圖像卷積得到圖像特征輸出矩陣V,V?,其中H′、W′分別表示輸出網(wǎng)格的高度和寬度。另外,空間轉(zhuǎn)換器中還包含單位矩陣E和采樣矩陣,分別完成原始關(guān)鍵信號提取和旋轉(zhuǎn)縮放功能。采樣矩陣可表示為:
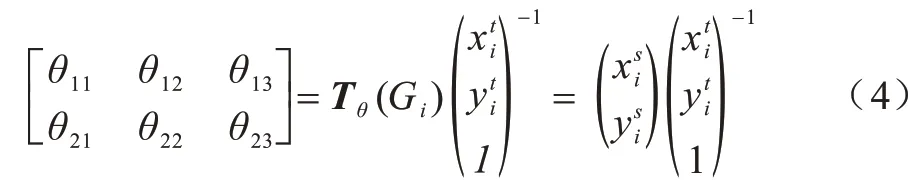
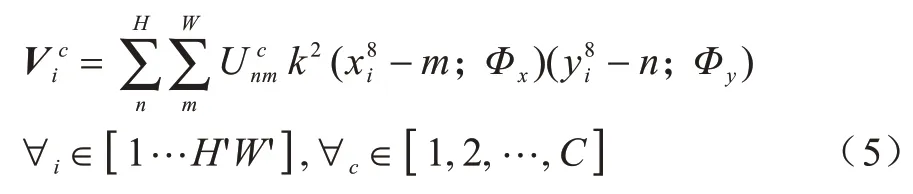
1.2.3 通道-空間注意力
本文提出的空間-通道雙注意力機制集中了以上2 種注意力域的優(yōu)勢,能夠同時實現(xiàn)學(xué)習(xí)道路特征通道權(quán)重參數(shù)對所需道路通道的增強,又能在復(fù)雜環(huán)境下,通過多種手段完成對道路信息的標注提取。
該網(wǎng)絡(luò)的設(shè)計思路是受DANet 雙注意力網(wǎng)絡(luò)結(jié)構(gòu)的啟發(fā)[16],采用級聯(lián)的連接方式,可以依次在空間域和通道域捕獲道路信息的全局特征依賴,利用前者建立通道的相關(guān)性,后者來學(xué)習(xí)空間域特征信息的相關(guān)性,如圖5 所示。
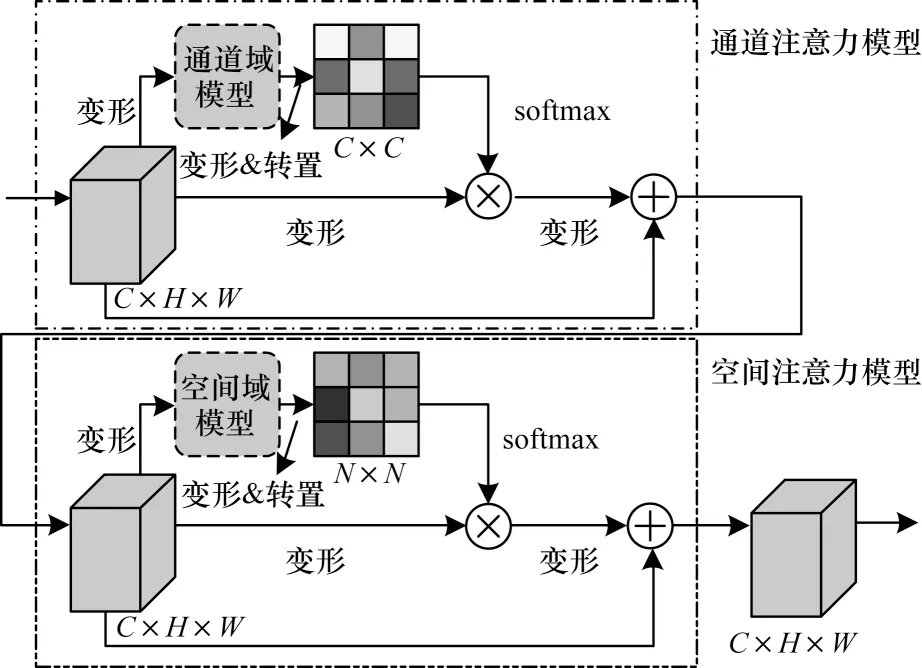
圖5 通道-空間域模型Fig.5 Model of channel-spatial domain
對每張尺寸為C×H×W特征圖分2 條支路操作:支路1 直接對特征圖下采樣運算變形(reshape)得到一個輸出結(jié)果;支路2 是變形后的特征圖,先通過通道域模型,然后經(jīng)過變形與轉(zhuǎn)置再與變形后的特征圖進行乘積運算,得到1 個尺寸為C×C的通道注意力圖,最后通過1 個softmax 層,得到第2 個輸出結(jié)果。2 條支路進行卷積運算,再經(jīng)過上采樣運算變形還原為原始輸入尺寸。與原始輸入圖像融合,得到最終尺寸同樣為C×H×W的輸出,而此輸出作為空間注意力模型的輸入。特征圖矩陣S中的元素為:

其中:xij為通道j對通道i的影響程度;Ai、Aj表示A中的元素,輸出E中的元素為:

其中:β為尺度變換因子。對于空間注意力模塊,與上述通道注意力模塊相似,主要區(qū)別在于將原有的通道域模塊換成空間域模塊,生成尺度為N×N(其中N=H×W)的空間注意力圖。矩陣S′中的元素及輸出為:
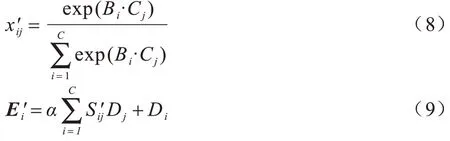
其中:α為尺度變換因子。上述矩陣S可看作一個小型注意力模型,用于計算每行像素的依賴關(guān)系。
1.3 損失函數(shù)的構(gòu)建
在深度學(xué)習(xí)圖像識別領(lǐng)域,構(gòu)建損失函數(shù)最常用的2 種方式是交叉熵損失[17]和折頁損失[18]。交叉熵損失是一種邏輯斯蒂回歸模型,而折頁損失是一種支持向量機(SVM)模型[19-20]。這2 種損失通常被當作是構(gòu)建損失函數(shù)優(yōu)化分割網(wǎng)絡(luò)必不可少的元素。作為網(wǎng)絡(luò)輸出的最后的網(wǎng)絡(luò)層,通常是以交叉熵損失為主。二值交叉熵(Binary Cross Entropy,BCE)損失函數(shù)能夠使輸出預(yù)測最大程度上與真實樣本相符,滿足“最大熵原則”優(yōu)化網(wǎng)絡(luò)輸出;DICE系數(shù)損失(DICE Coefficient Loss,DICE)是一種集合相似度度量的函數(shù),用于衡量2 個樣本間的相似度。2 種損失的梯度不同,DICE 損失的梯度為p-t,DICE損失的梯度為2t2/(p+t)2。其中:p為輸出預(yù)測樣本的概率;t為目標標簽的概率。由數(shù)學(xué)知識可知DICE 的損失大于BCE 的損失。本文在原有基于DICE+BCE 的D-LinkNet 模型損失函數(shù)的基礎(chǔ)上,提出一種新型超參數(shù)損失函數(shù)。對2 項損失做加權(quán)處理,通過調(diào)節(jié)新定義2 項損失的超參數(shù)μ、λ的不同權(quán)重比,來優(yōu)化調(diào)整網(wǎng)絡(luò)模型的分割及預(yù)測性能:
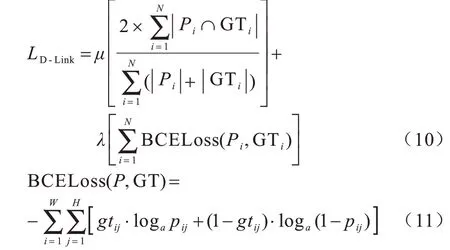
其中:i表示當前迭代樣本的序號;N表示批量大小;P為輸出的預(yù)測概率圖;GT 是真實標簽。在μ>λ的前提條件下,可通過實驗來獲取最佳權(quán)重比例。
1.4 網(wǎng)絡(luò)框架
D-LinkNet 分割網(wǎng)絡(luò)結(jié)構(gòu)是采用backbone-head的骨架結(jié)構(gòu),直接利用線性插值上采樣的操作。它是一種端到端的神經(jīng)網(wǎng)絡(luò)架構(gòu),沒有冗雜的學(xué)習(xí)參數(shù),不需要大量的冗余計算,這樣就可以直接將注意力模塊加入到D-LinkNet 網(wǎng)絡(luò)中。另外,將注意力機制引入到神經(jīng)網(wǎng)絡(luò)中,通常是Encoder-Attention-Decoder 的形式,因此只需對圖2 中心區(qū)域做出改進。但又由于該網(wǎng)絡(luò)中有上采樣層,因此注意力模型的位置需要經(jīng)過實驗對比來獲取最佳的植入位置,如圖6 所示,虛框A、B 部分為注意力模塊。
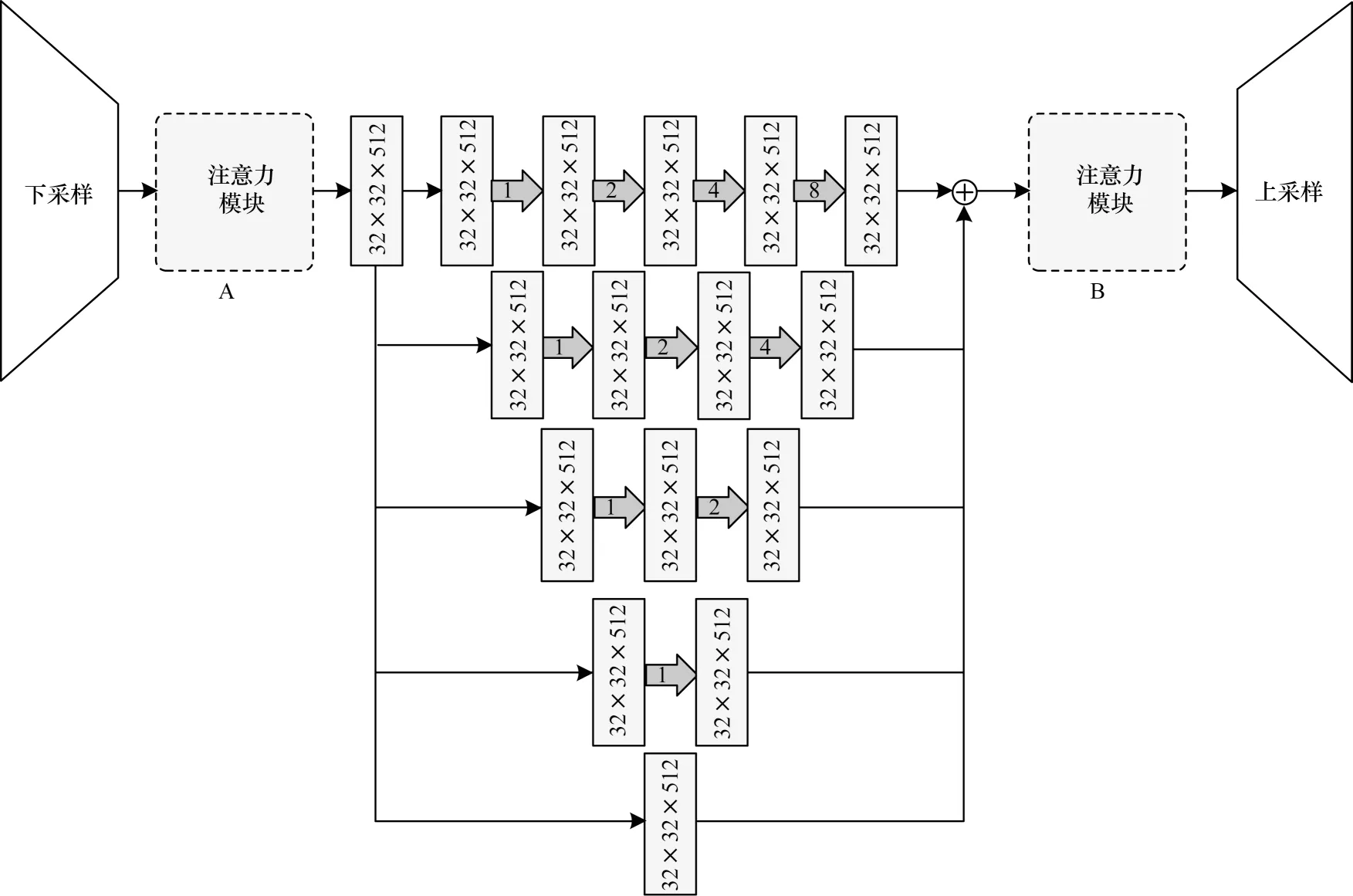
圖6 改進D-LinkNet 結(jié)構(gòu)Fig.6 Structure of improved D-LinkNet
在圖6 所示的改進D-LinkNet 結(jié)構(gòu)框架中,注意力模塊A 左側(cè)連接的是將預(yù)訓(xùn)練好的ResNet34 作為編碼器,充分激活網(wǎng)絡(luò)的表征能力。中心區(qū)域的5 條分支路加入空洞卷積運算模塊。所謂的空洞卷積本質(zhì)就是一種特殊的“池化”運算。相對于普通的池化過程,空洞卷積的優(yōu)點是在不損耗特征信息情況下,能夠增大感受野的范圍,從而輸出更多的信息。圖中灰色箭頭表示神經(jīng)網(wǎng)絡(luò)的深度,5 條支路的深度依次為4、3、2、1、0(0 代表恒等映射),感受野的尺寸依次為15、7、3、1、0。該結(jié)構(gòu)能在不損失分辨率的條件下完成特征多深度、多尺寸的融合,采用特征層“堆疊”的特征融合方式,無后處理運算過程。之后加入1×1 的卷積層進行特征融合。最后通過用于歸一化的Sigmoid 函數(shù)及ReLU 激活函數(shù)獲得與輸入圖像分辨率相同像素級的道路預(yù)測概率圖。根據(jù)設(shè)定的閾值最終得到遙感影像道路分割預(yù)測的二值圖像。
2 實驗結(jié)果與分析
為驗證本文提出的高分遙感影像道路提取方法的準確性與有效性,針對改進D-LinkNet 模型內(nèi)部不同超參數(shù)權(quán)重比比值的設(shè)定,進行一系列的橫向?qū)Ρ葘嶒灐A硗猓瑢τ诟倪M模型外部而言,對當前主流的道路分割方法進行縱向?qū)Ρ葘嶒灒庇^展現(xiàn)本文改進的網(wǎng)絡(luò)與當前主流經(jīng)典網(wǎng)絡(luò)道路預(yù)測效果的對比。
2.1 數(shù)據(jù)集
本文是在開源的數(shù)據(jù)集Massachusetts Road Datasets 上進行實驗。該數(shù)據(jù)集是美國馬薩諸塞州2 600 km×2 600 km 范圍內(nèi)的地面遙感影像數(shù)據(jù),這其中的地物信息主要涵蓋城市、郊區(qū)以及農(nóng)村地區(qū)的道路分布。該數(shù)據(jù)集總共有1 171張尺寸為1 500像素×1 500 像素的遙感圖像,空間分辨率為1 m(1 m/pixel)。其中包含1 108 張訓(xùn)練數(shù)據(jù)集(完整的圖像有706 張,其余402 張均有不同嚴重程度的缺失)、49 張測試集以及14 張驗證集。本文的訓(xùn)練樣本選擇經(jīng)清洗后的訓(xùn)練集及驗證集共720 張遙感圖像作為訓(xùn)練數(shù)據(jù)。
2.2 實驗環(huán)境及方法
為對本文提出改進網(wǎng)絡(luò)模型的道路分割預(yù)測效果做出客觀的評價與對比,所有實驗均在相同軟、硬件環(huán)境下進行。
軟件環(huán)境:操作系統(tǒng)為內(nèi)存為64 GB 的CentOS7.2;深度學(xué)習(xí)框架為Pytorch1.5;編程環(huán)境為Python3.5。
硬件環(huán)境:CPU 型號為Intel?Xeon?E5-2650 v4@
2.2 0 GHz,GPU 為Tesla P100。
參數(shù)設(shè)置:動量參數(shù)為0.9,batchsize 設(shè)定為8,學(xué)習(xí)率調(diào)整3 次,初始值為0.001 的SGD 更新梯度優(yōu)化算法。訓(xùn)練過程總共迭代90 輪,分別于訓(xùn)練的第30、50、70 輪分別對學(xué)習(xí)率更新1 次,學(xué)習(xí)率分別為0.000 1、0.000 01、0.000 001。其中,在初始學(xué)習(xí)率下迭代10 098/8×30=37 868 次,后面3 種學(xué)習(xí)率均迭代10 098/8×20=25 245 次,所以整個訓(xùn)練過程總共迭代37 868+25 245×3=113 603 次。
2.3 圖像預(yù)處理
在數(shù)據(jù)集訓(xùn)練之前,首先需要對圖像進行預(yù)處理。受限于GPU 內(nèi)存的運算能力,對每張1 500 像素×1 500 像素的圖像進行切分。切塊大小為512×512,切塊后的訓(xùn)練集總共包含10 098 幅圖像,驗證集包含441 張圖像。另外,在訓(xùn)練過程中對數(shù)據(jù)進行了簡單的增強,包括隨機翻轉(zhuǎn)和隨機裁剪,隨機裁剪大小為480 像素×480 像素的圖像。本文使用的Massachusetts Road Datasets 道路與背景的像素占比分別為5%和95%。此處采用一種占比倒數(shù)加權(quán)的方法來解決兩類像素點占比不平衡的問題。
2.4 評價指標
實驗采用精確率P(Precision)、召回率R(Recall)、F1-score、平均交并比(Mean Intersection over Union,mIoU)4 項評價指標,作為評價本文道路分割效果的參考依據(jù),分別定義如下:

其中:TP 表示真正列,實際道路像素被預(yù)測為道路像素;FP 表示假正例,非道路像素被預(yù)測為道路像素;FN 表示假反例,非道路信息被預(yù)測成非道路信息;另外2 種評價指標F1與mIoU 是圖像分割中常見的2 項評價指標;k+1 表示類別數(shù)目(k個目標類和1 個背景類);pij表示將類別i誤判為類別j的像素數(shù)量,pji反之;pii表示分類正確像素的數(shù)目。
2.5 改進D-LinkNet 網(wǎng)絡(luò)的訓(xùn)練過程
圖7 和圖8 所示分別為經(jīng)過90 輪迭代,DLinkNet 和本文提出的改進D-LinkNet 各項評價指標隨迭代次數(shù)變化的折線圖。
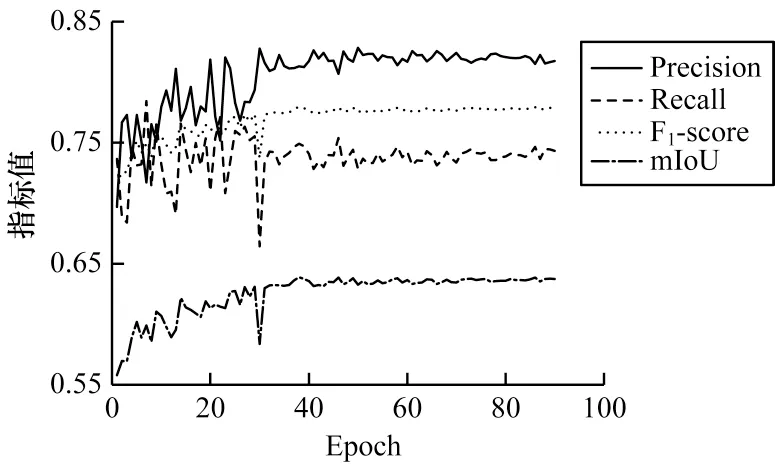
圖7 D-LinkNet 各項評價指標迭代折線圖Fig.7 Iteration line diagram of D-LinkNet each evaluation index
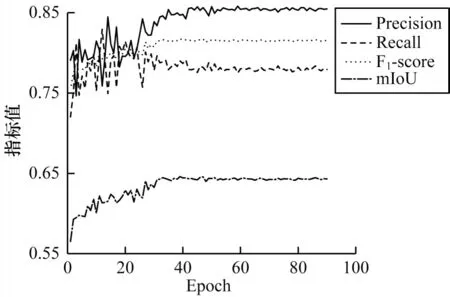
圖8 改進D-LinkNet 各項評價指標迭代折線圖Fig.8 Iterative line diagram of improve D-LinkNet evaluation index
從圖7和圖8可以看出,當各項指標趨于穩(wěn)定之后,本文改進的網(wǎng)絡(luò)均高于原始網(wǎng)路。其中:精確率由原來的0.817 3 增長到0.854 9;召回率由之前的0.743 3 增長到0.779 3;F1-score從0.778 6 增長到0.815 4;mIoU 從0.637 4增長到0.663 1。4項指標分別約增長了3.8、3.6、3.7 和2.6 個百分點。不難得出,改進后網(wǎng)絡(luò)的道路分割性能較之前有顯著改善,預(yù)測效果明顯提升。
2.6 損失函數(shù)超參數(shù)權(quán)重實驗
對于式(10)中DICE+BCE 損失設(shè)定的超參數(shù)權(quán)重比值,固定λ=1 調(diào)整μ的取值,DICE 與BCE 權(quán)重比分別按照1∶1、2∶1、3∶1、4∶1、5∶1 這5 種先驗比例設(shè)定,分別在不同的比例條件下,通過對比分析得出最佳效果的道路分割權(quán)重比。此處以F1-score 作為評價改進網(wǎng)絡(luò)預(yù)測性能的指標。另外,下文實驗在實際訓(xùn)練過程中,均以49 張測試集上的測試結(jié)果作為評測指標。
如圖9 所示,本文設(shè)定的5 種超參數(shù)權(quán)重比的F1-score 會隨著迭代輪次的增加呈現(xiàn)上升的趨勢。通過對比可以發(fā)現(xiàn),當沒有設(shè)定超參數(shù)權(quán)重(即權(quán)重比為1∶1)時,F(xiàn)1-score 的分數(shù)最低,經(jīng)過90 輪迭代的取值僅為0.776 7;而當權(quán)重比為4∶1 時,其F1-score的分數(shù)最高,達到0.815 4。并且,該權(quán)重比下網(wǎng)絡(luò)的預(yù)測性能處于較為穩(wěn)定的狀態(tài)。5 種超參數(shù)權(quán)重比的性能對比如表1 所示。
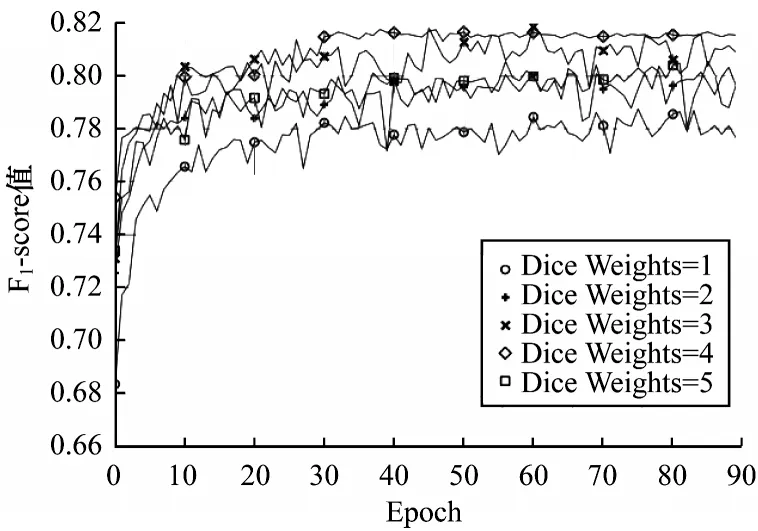
圖9 不同權(quán)重比的F1-socre 迭代折線圖Fig.9 F1-score iteration line graph of different weight ratio

表1 不同超參數(shù)權(quán)重比的性能對比Table 1 Performance comparison of different super parameter weight ratio
2.7 本文網(wǎng)絡(luò)與經(jīng)典網(wǎng)絡(luò)的對比實驗
為進一步驗證本文提出網(wǎng)絡(luò)的準確性與有效性,選取FCN-8s、U-Net[21]、DeepLabv3+[22]、DANet[16]和D-LinkNet5 種用于道路分割的經(jīng)典網(wǎng)絡(luò)與本文提出的網(wǎng)絡(luò)進行實驗對比。
FCN-8s 網(wǎng)絡(luò)模型共包含13 個卷積層、2 個轉(zhuǎn)置卷積層和5 個池化層。在訓(xùn)練過程中為實現(xiàn)模型的穩(wěn)定性及收斂性,適當降低網(wǎng)絡(luò)的振幅及調(diào)整學(xué)習(xí)參數(shù),加快網(wǎng)絡(luò)的收斂速度,以提升網(wǎng)絡(luò)模型的準確性和高效性。U-Net 網(wǎng)絡(luò)模型能夠利用拼接技術(shù)進行道路特征信息的融合,加寬網(wǎng)絡(luò)的深度,強化道路特征信息,其在道路提取任務(wù)中表現(xiàn)得更為出色,準確率也更高。該模型在下采樣過程中,每張圖像后面復(fù)用2 個3×3 的卷積層,每個卷積層后包含1 個非線性ReLU 層,第2 個復(fù)用的卷積層后有1 個尺寸為2×2 的最大池化層。上采樣過程使用1 個反卷積層,后面復(fù)用2 個3×3 的卷積層和非線性層。在網(wǎng)絡(luò)的最后一層添加1 個1×1 的卷積層,將特征向量映射到輸出分割的道路圖像上。DeepLabv3+網(wǎng)絡(luò)模型添加了空洞卷積層,卷積核尺寸為3×3,擴張率為2。另外,卷積層后緊 接著添加1 個ReLU 層、1 個BN 層以及1 個1×1 的卷積層,目的是降低道路提取過程中的運算量,提高模型的效率。DANet 網(wǎng)絡(luò)模型是將含通道的特征圖與其本身轉(zhuǎn)置相乘,利用一個softmax 層做歸一化處理,再與原始特征圖的轉(zhuǎn)置相乘,最終將道路信息映射到原始特征圖上,輸出道路提取后的相關(guān)性信息。表2 所示為不同分割網(wǎng)絡(luò)經(jīng)過90 輪訓(xùn)練迭代的各項評價指標數(shù)據(jù)對比。
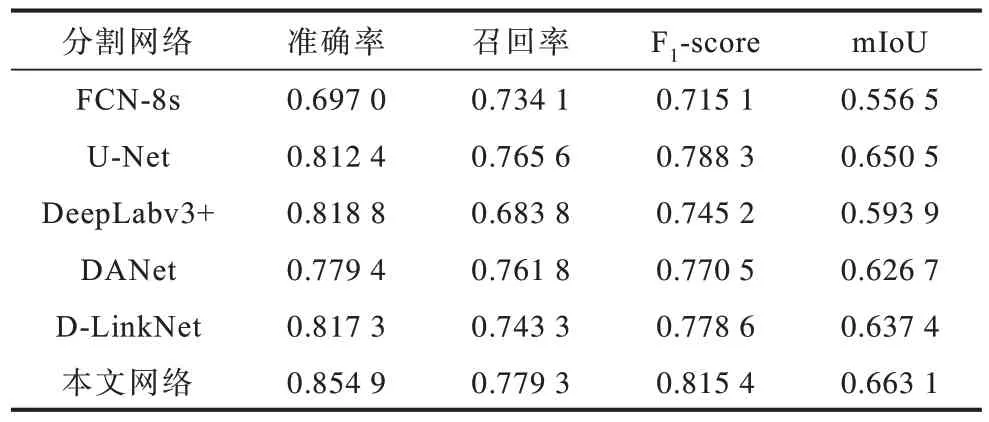
表2 不同道路分割網(wǎng)絡(luò)評價指標對比Table 2 Evaluation indexes comparison of different road segmentation networks
當前幾種熱門的經(jīng)典網(wǎng)絡(luò)與本文提出網(wǎng)絡(luò)的道路預(yù)測圖如圖10 所示。由圖10(c)~到圖10(h)結(jié)合表2 可 知,F(xiàn)CN-8s、DeepLabv3+以 及DANet的道路分割效果及評價指標較差,而U-Net 與D-LinkNet 的分割效果較為理想。本文以D-LinkNet為基礎(chǔ)框架,進行一系列的改進措施,增強了網(wǎng)絡(luò)道路像素點的識別能力。實驗結(jié)果表明,本文提出的改進D-LinkNet 網(wǎng)絡(luò)在高分遙感影像道路提取任務(wù)中的表現(xiàn)相對于分割網(wǎng)絡(luò)更具有優(yōu)勢。

圖10 本文網(wǎng)絡(luò)與經(jīng)典網(wǎng)絡(luò)的道路預(yù)測圖Fig.10 Road prediction diagram of this paper network and classic network
3 結(jié)束語
本文在D-LinkNet 分割網(wǎng)絡(luò)的基礎(chǔ)上,針對高分影像道路提取中出現(xiàn)的“虛檢”“漏檢”“誤檢”問題,提出改進的D-LinkNet 網(wǎng)絡(luò)模型。在原始分割網(wǎng)絡(luò)的基礎(chǔ)上引入channel-spatial 雙注意力機制,同時基于原始的DICE+BCE 損失對其進行改進,構(gòu)建一種超參數(shù)權(quán)重損失,并按照先驗比例設(shè)定超參數(shù)權(quán)重,通過實驗得出最佳的超參數(shù)權(quán)重比。實驗結(jié)果表明,本文提出的改進D-LinkNet 網(wǎng)絡(luò)模型在Massachusetts Road Datasets 上的表現(xiàn)要優(yōu)于原始DLinkNet 分割網(wǎng)絡(luò)。下一步將圍繞模型的優(yōu)化算法對網(wǎng)絡(luò)模型的分割性能進行優(yōu)化,嘗試使用當前較主流Adam 等優(yōu)化算法提升網(wǎng)絡(luò)的運算效率。另外,對于模型主干架構(gòu)的輕量化也是今后的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
