基于條件變分自編碼網(wǎng)絡的短文本分類
2021-09-16 03:12:48鄭山紅李萬龍
計算機應用與軟件 2021年9期
康 宸 鄭山紅 李萬龍
(長春工業(yè)大學 吉林 長春 130012)
0 引 言
文本分類是基于文本中的詞項等一些內(nèi)置屬性,能夠成功地將每個文檔分類到預先定義好的類別中。在自然語言處理文本挖掘領域,文本分類是一項重要的研究內(nèi)容,被廣泛應用于Web搜索、日志分析、信息過濾和情感分析等領域[1]。隨著互聯(lián)網(wǎng)大數(shù)據(jù)的發(fā)展,短文本數(shù)據(jù)的規(guī)模迅速增長,對短文本進行高效準確的分類顯得非常重要。與長文本分類不同,由于文本主題特征稀疏,短文本中有利于文本分類的主題特征不夠充分,因此導致傳統(tǒng)的文本分類模型處理短文本的分類效果不佳。
文本分類的相關工作可以追溯到20世紀50年代。文本分類包含以下六個主要步驟:準備訓練和測試數(shù)據(jù)、文本規(guī)范化處理、特征抽取、模型訓練、模型預測與評估、應用部署,其中特征抽取以及模型訓練尤為重要。傳統(tǒng)的特征抽取方法有通過計算特征權(quán)重選定閾值過濾特征的統(tǒng)計方式,如互信息(MI)[2]、χ2統(tǒng)計量(CHI)[2]和期望交叉熵[2]等。由于這些方法都是基于統(tǒng)計的方式進行特征抽取,不僅需要繁瑣的特征工程,而且對于字符數(shù)比較少的短文本特征抽取不夠充分,最終的分類效果往往很差。隨著統(tǒng)計機器學習的發(fā)展,特征抽取可以不依靠繁瑣的特征工程,而是由模型自己訓練得到,但是需要額外的表示文本。常見的文本表示包括詞袋模型和向量空間模型(VSM),這些文本表示方式在長文本分類中有很好的效果,但是對于短文本,這些文本表示導致維度高且系數(shù),模型訓練過程參數(shù)眾多且有效特征稀疏,訓練模型很容易發(fā)生過擬合,如基于SVM的統(tǒng)計機器學習文本分類算法[3-4]。隨著深度學習的發(fā)展,文本分類不再需要繁瑣的特征抽取工作,而是由深度學習模型參數(shù)擬合訓練進行抽取,利用LSTM及一維卷積等網(wǎng)絡模型架構(gòu)自動抽取文本分類的主題特征。LSTM網(wǎng)絡擅長處理全部序列信息特征,將整個序列數(shù)據(jù)看成一個數(shù)據(jù)點,序列中的詞項信息狀態(tài)進行保留傳遞,但是在處理短文本分類中,LSTM網(wǎng)絡處理的文本序列稀疏,并且對于文本分類任務,n-gram特征可能對文本分類任務更為有效。因此Kim等[5]提出了一維卷積,不同于LSTM提取文本全部序列信息,一維卷積神經(jīng)網(wǎng)絡能夠根據(jù)filter來學習局部序列信息,因此在對n-gram特征敏感的分類任務上表現(xiàn)尤為突出。但是使用一維卷積對短文本進行特征抽取過程中,短文本字符限制導致提取出來的n-gram語法主題特征不足,導致一維卷積處理短文本時主題特征挖掘不夠充分。
本文將預訓練好的LDA的主題詞項分布拼接成單通道的文本特征表示,然后應用二維卷積進行特征的抽取統(tǒng)計參數(shù),根據(jù)統(tǒng)計參數(shù)生成文本主題的潛在空間,構(gòu)建文本分類模型僅需要將文本映射到主題潛在空間中,由映射后的主題特征作為文本分類的輸入,類別標簽作為輸出,構(gòu)造全連接層的分類器。不僅彌補了短文本分類主題特征不夠充分,同時也利用了二維卷積神經(jīng)網(wǎng)絡層次化結(jié)構(gòu)的優(yōu)點。
1 預訓練LDA主題模型
主題模型是對文字中隱含主題的一種建模方法。主題可以看成是詞項的概率分布,主題模型通過詞項在文檔級的共現(xiàn)信息抽取語義相關的主題集合,并能夠?qū)⒃~項空間中的文檔映射到主題空間,得到文檔在低維空間中的表達[6]。Blei等[7]提出了基于貝葉斯思想的LDA主題模型,主題分布及主題詞項分布是由兩個先驗Dirichlet分布生成,然后不斷迭代求解出最終的主題分布和主題詞項分布。
本文采用Gibbs采樣的方式迭代求解LDA主題模型的參數(shù),在求解過程中每次都對聯(lián)合分布中的某一個分量進行采樣,其他的分量保持不變,最終將所有分量都計算一次。推導后的Gibbs采樣求解LDA主題模型迭代公式如下:
(1)

2 模型設計
由于深度學習能夠通過參數(shù)擬合學習出有益于文本分類的主題特征,并通過分類器進行分類,而抽取有益于文本分類主題特征關系到最終分類效果的好壞。因此,本文利用具有標簽指導的條件變分自編碼網(wǎng)絡生成文本主題的潛在空間,進而通過預訓練的方式將待分類的文本映射到文本主題潛在空間中得到主題特征,使用得到的特征進行文本分類。基于條件變分自編碼網(wǎng)絡進行文本分類分為兩個步驟:(1) 預訓練文本主題的潛在空間模型。通過構(gòu)建條件變分自編碼生成文本主題的潛在空間。(2) 訓練文本分類模型。利用預訓練的文本主題潛在空間映射文本得到主題特征進行短文本分類。
2.1 預訓練文本主題潛在空間模型
變分自編碼網(wǎng)絡最流行的應用是創(chuàng)造性地從圖像的潛在空間中采樣,并創(chuàng)建全新圖像以及編輯現(xiàn)有的圖像。通過訓練數(shù)據(jù)變分自編碼能夠?qū)W習到連續(xù)且具有良好結(jié)構(gòu)的圖像潛在空間,而這種空間同樣適用于文本數(shù)據(jù)。同時為了更好地重構(gòu)原始特征,將文本的類別標簽加入變分自編碼網(wǎng)絡作為條件指導重構(gòu)文本主題特征。預訓練文本主題潛在空間模型分為Encoder與Decoder兩個部分,Encoder部分如圖1所示,Decoder部分如圖2所示。
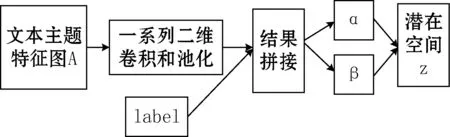
圖1 Encoder
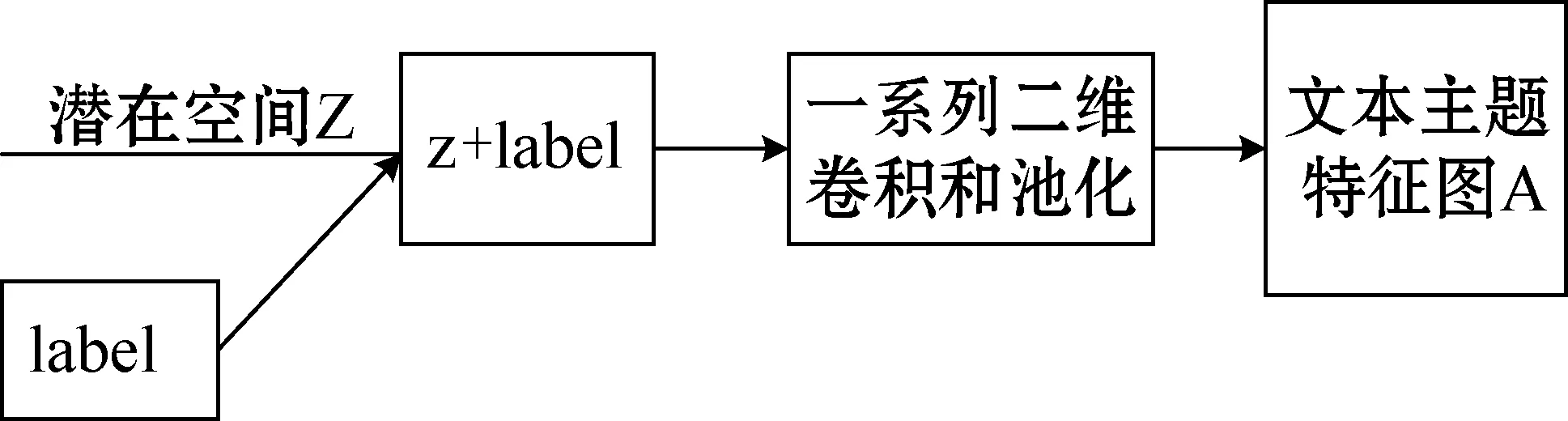
圖2 Decoder
2.1.1文本主題特征圖
不論是傳統(tǒng)的文本分類模型還是應用機器學習模型,都需要將文本字符表示成計算機能夠識別的數(shù)值,這個過程被稱為文本向量化。常見的文本向量化方式有one-hot編碼及詞嵌入。其中one-hot編碼是將每個單詞與一位唯一的整數(shù)索引相關聯(lián),然后將這個整數(shù)索引i轉(zhuǎn)換為長度為N的二進制向量(N是給定詞匯表大小),其中只有第i位置的元素是1,其余的所有元素都是0。這種方式將文本中詞項看成獨立元素,忽略了文本中詞項與詞項之間的關系,并且由于N通常很大,導致文本向量化后的維度稀疏,模型很容易過擬合。詞嵌入方式是根據(jù)詞項共現(xiàn)將文本中的詞項表示為相對低維的密集型向量,向量中包含詞的語義信息,常見的詞嵌入方式有Word2vec和GloVe等[8]。但是對于文本分類任務來說,詞項主題信息比詞項語義信息更有利。對于短文本而言,如何充分挖掘詞項的主題信息至關重要,本文將LDA預訓練的主題詞項分布作為短文本分類的特征,采用拼接的方式,將短文本中每個詞項拼接成文本主題特征圖,然后經(jīng)過二維卷積對拼接后的文本主題特征圖進行特征提取。文本主題特征如圖3所示。

圖3 文本主題特征
將短文本表示為拼接的主題詞項向量特征圖,之后可以通過二維卷積來進行特征提取。對于短文本分類任務而言,將短文本拼接成單通道的特征圖,是將短文本特征類比于圖像特征,當然文本具有不同于圖像的特點,但是對于文本分類任務來說,通道中的每一個維度都可能影響最終的分類結(jié)果。對于擁有j個詞項的短文本來說,其某一個維度可能包含著關于體育主題特征,在應用二維卷積進行抽取特征后,關于這個維度的特征可能尤為的突出。對于文本分類任務來說,完整的詞項序列或者比較長的詞項序列可能幫助不大,但是簡短連續(xù)的詞項對可能會對文本主題有幫助,而在二維卷積處理文本主題特征圖的時候,可以選定一個filter,每一次卷積操作考慮filter width個主題向量維度特征和filter height個連續(xù)詞項對。
2.1.2文本轉(zhuǎn)換為統(tǒng)計分布參數(shù)
變分自編碼網(wǎng)絡生成圖像,假定潛在正態(tài)分布能夠輸入圖像。將所定義的潛在空間分布定義為正態(tài)分布,正態(tài)分布能夠很好地模擬圖像的生成。對于文本主題特征圖而言,需要生成具有連續(xù)且高度結(jié)構(gòu)化的文本主題潛在空間,并且能夠生成輸入的文本主題特征圖。在LDA主題模型中,生成主題分布及主題詞項分布使用的是多維Beta分布的Dirichlet分布,選擇單維度的Beta分布,指定生成參數(shù)的維度可以模擬Dirichlet分布,因此將潛在空間的分布定義為Beta分布。Beta分布的概率密度函數(shù)表達式為:
(2)
式中:α、β是兩個正值參數(shù),稱為形狀參數(shù)。B(α,β)計算如下:
為了能夠應用梯度下降法迭代求解參數(shù)。變分自編碼網(wǎng)絡使用重參數(shù)技巧,雖然已知潛在空間分布為Beta分布,但是生成的統(tǒng)計參數(shù)是通過模型計算出來的,需要靠梯度優(yōu)化算法反過來優(yōu)化這些統(tǒng)計參數(shù),從潛在空間“采樣”操作是不可導的,而“采樣”的結(jié)果是可導的。“采樣”的過程計算式表示為:
Z=zmean+exp(zvariance)×ε
(3)
式中:Zmean和Zvariance分別為Z的均值和方差;ε是一個很小的隨機張量。由于使用Beta分布作為潛在空間的分布,因此具體重參數(shù)技巧公式為:
(4)
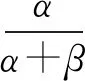
2.1.3條件變分自編碼的損失函數(shù)
條件變分自編碼的參數(shù)是由兩個損失函數(shù)來進行訓練的,分別為輸入文本特征圖A與輸出文本特征圖的重構(gòu)損失,以及能夠幫助生成的主題潛在空間Z學習到良好結(jié)構(gòu)的正則化損失。由于傳統(tǒng)的條件變分自編碼網(wǎng)絡假設正態(tài)分布生成圖像,因此傳統(tǒng)的條件變分自編碼的正則化損失就是計算兩個正態(tài)分布p1和q1的KL散度,具體公式如下:
(5)
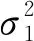
而在前面為了生成更加結(jié)構(gòu)化、對文本分類更加有益的文本主題潛在空間,假定潛在空間分布是由Beta分布構(gòu)成,因此對應的正則化損失函數(shù)是計算兩個Beta分布的KL散度,具體公式如下:
p2~Beta(α,β)
q2~Beta(α′,β′)
(β′-β)ψ(β)+(α′-α+β′-β)ψ(α+β)
(6)
式中:p2服從參數(shù)為α、β的Beta分布;q2服從參數(shù)為α′、β′的Beta分布;ψ為雙伽瑪函數(shù);KL(p2,q2)表示計算兩個Beta分布的KL散度。KL散度計算的是兩個分布之間的距離,但是不滿足對稱性。Beta分布和正態(tài)分布所有點的概率密度都是非負的,不存在某一個區(qū)域的概率值為0,KL散度無窮大的情況。
2.2 訓練文本分類模型
預訓練得到的文本主題潛在空間具有連續(xù)和高度結(jié)構(gòu)化的特點。由于假定文本主題潛在空間的分布為Beta分布,因此潛在空間能夠?qū)⑽谋居成錇橄鄳闹黝}特征編碼。接下來就可以利用這些主題特征編碼來訓練文本分類模型。訓練模型結(jié)構(gòu)如圖4所示。
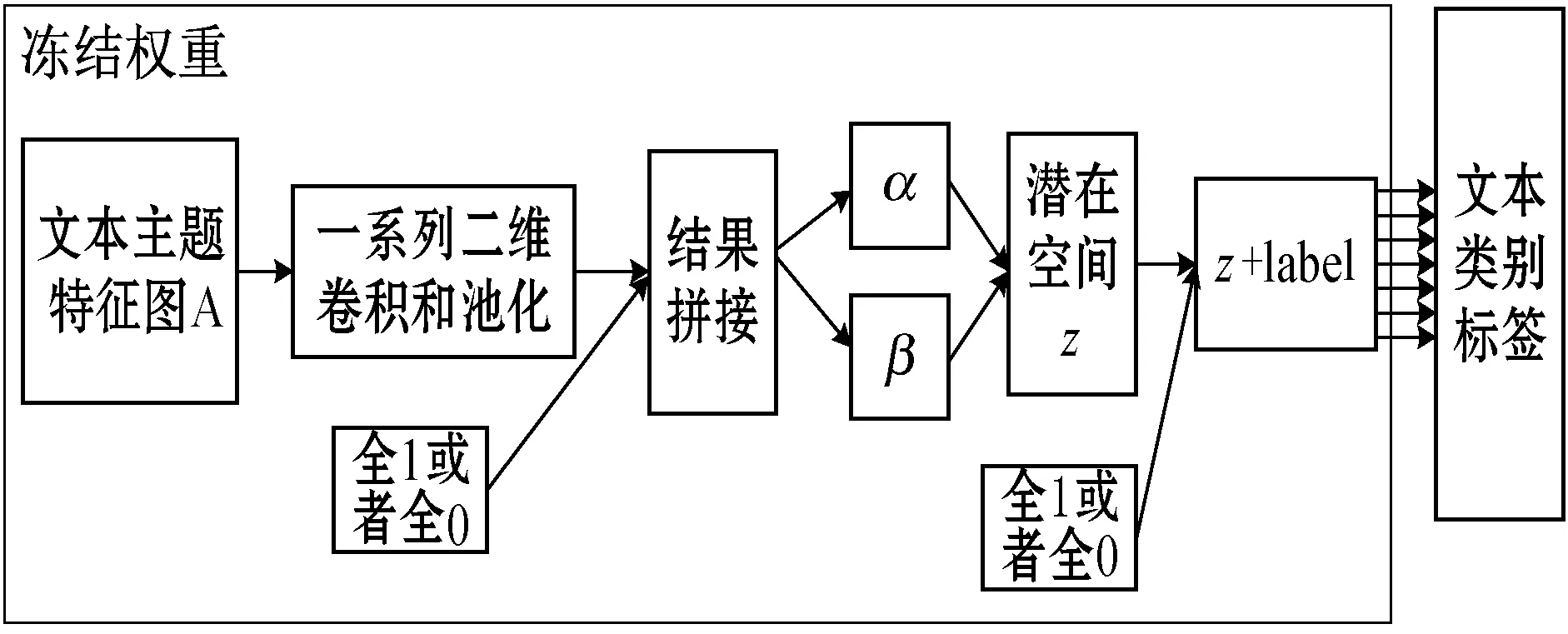
圖4 利用文本主題潛在空間端到端的訓練文本分類
利用文本主題潛在空間進行端到端的文本分類,將預訓練文本主題潛在空間模型的Encoder架構(gòu)保留,并將文本映射到文本主題潛在空間后的文本主題特征作為分類器的特征進行分類。為了避免訓練導致學習好的參數(shù)權(quán)重遭到破壞,在訓練文本分類需要凍結(jié)生成文本主題潛在空間的Encoder部分。
由于預訓練文本主題潛在空間過程中引入了標簽作為指導,有助于更好地重構(gòu)文本主題特征圖。但是在利用生成的文本潛在空間進行文本分類的過程中,沒有重構(gòu)文本主題特征圖的過程,因此不再需要類別標簽作為條件。但是在整個過程中使用的是預訓練好的模型架構(gòu)參數(shù)權(quán)重都是固定不變的,并且測試模型的時候也不能知道文本的已知的類別標簽,因此在利用潛在空間進行端到端的文本分類過程中,將作為條件的類別標簽設置為全0或者全1,忽略此時文本標簽的指導作用。
3 實 驗
3.1 預訓練主題詞項分布
在55 000條搜狗新聞文本數(shù)據(jù)集上預訓練LDA主題模型,共計375 030個詞項,將主題數(shù)設置為4~100(間隔8),困惑度隨主題數(shù)的變化情況如圖5所示。
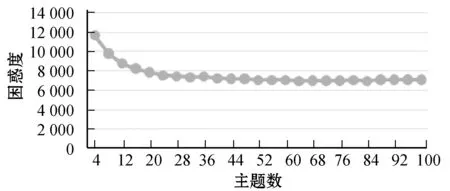
圖5 主題數(shù)與困惑度的折線圖
圖5中主題數(shù)量與困惑度呈現(xiàn)遞減的趨勢,但是當主題數(shù)量為64時,遞減逐漸趨于平緩。因此為了得到更好的主題詞項分布,將主題數(shù)量設置為64,兩個超參數(shù)α和β分別設置為0.78和0.01[7]。
3.2 實驗數(shù)據(jù)
采用搜狗實驗室公開的2012年6月到7月搜狐新聞數(shù)據(jù)集,從中均勻提取10個類別的60 000條新聞數(shù)據(jù)集。將其中的45 000條新聞數(shù)據(jù)作為訓練集,5 000條新聞數(shù)據(jù)集作為驗證集以及10 000條新聞數(shù)據(jù)集作為測試集。提取每條新聞數(shù)據(jù)標題作為短文本數(shù)據(jù)集,同時為了避免構(gòu)造的文本主題特征圖過于稀疏,除了過濾掉短文本中停用詞之外,還需要過濾掉一些主題不夠明顯的詞項。
在計算兩個Beta分布的KL散度時,為了得到更好的文本主題分布,將其中的一個Beta分布參數(shù)都設置為0.01。
3.3 對比算法
本文提出的條件變分自編碼網(wǎng)絡解決文本分類問題,文本的主題信息對文本分類有很大的幫助,因此將在LDA主題模型上預訓練的主題詞項分布作為短文本的詞項向量,通過拼接的方式拼接成擁有單通道的文本主題特征圖,通過二維卷積將文本主題特征體轉(zhuǎn)換為Beta分布的兩個統(tǒng)計參數(shù)α和β,進而生成文本主題的潛在空間。在訓練文本分類的過程中,將文本映射到預訓練的文本主題潛在空間的特征作為輸入,具體的10個類別作為輸出的全連接分類器。為了方便將基于條件變分自編碼的短文本分類算法記為CVAE-TC,進行對比的分類算法有傳統(tǒng)分類模型的SVM、LSTM以及簡單的fastText模型[9],用于分類效果比較好的一維卷積Text-CNN模型[5],還有將圖像注意力機制加入到文本中的HAN模型[10]。
3.4 實驗結(jié)果
實驗對比了CVAE-TC、SVM、LSTM、Bi-LSTM、fastText以及Text-CNN和HAN七種文本分類模型。CVAE-TC模型在文本分類過程中包含兩個步驟,一個是預訓練文本主題潛在空間;另一個過程是利用文本主題潛在空間進行文本分類的過程。僅考慮文本分類過程時間效率與最快的fastText模型相近,為了公平把預訓練文本主題潛在空間的過程算入CVAE-TC模型的訓練時間中。不同模型在精度以及總的訓練時長上的對比如表1所示。
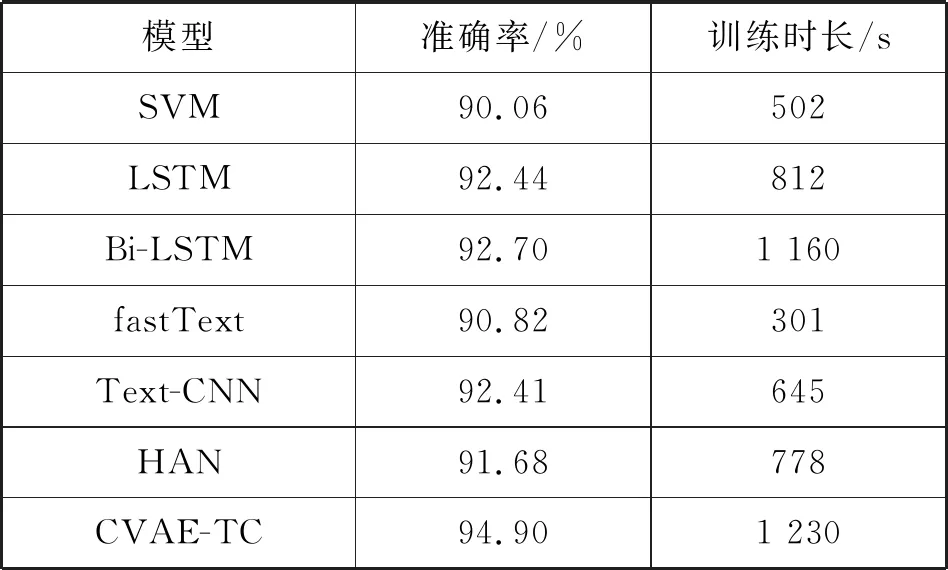
表1 不同模型在短文本分類上的對比(10 epoch)
其中短文本分類算法在精度上對比如圖6所示。
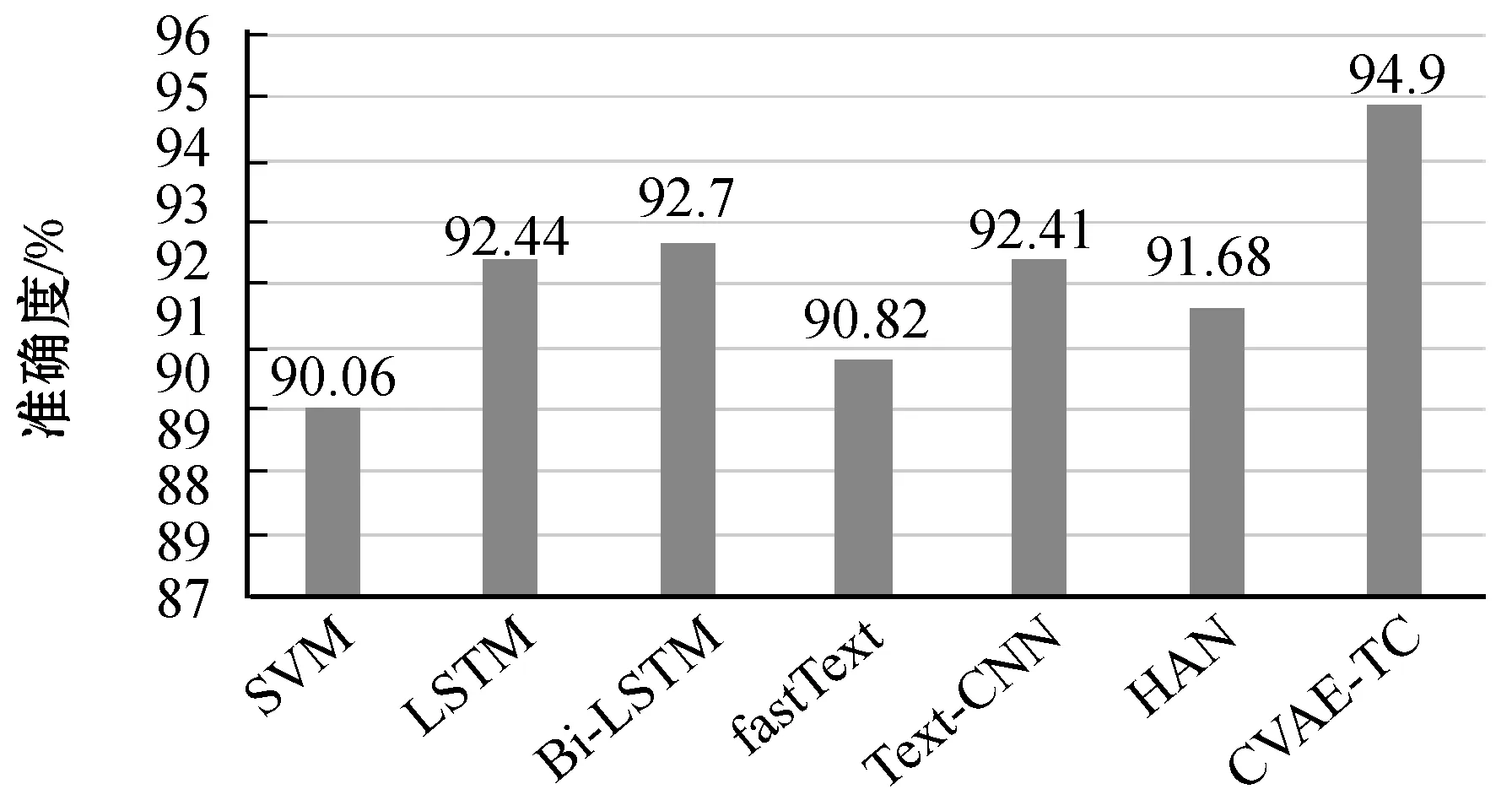
圖6 七種分類算法精度柱狀圖
可以看出,在七種分類算法中CVAE-TC的分類準確度最高達到了94.90%,而對于其他的分類算法在短文本上的分類效果不佳,沒有充分地挖掘短文本中的主題信息。在傳統(tǒng)的文本分類算法中,Text-CNN比LSTM等一些模型分類效果好,這也說明了對于文本分類任務來說,連續(xù)的詞項對比完整的詞項序列更有用。而CVAE-TE將短文本的主題信息直接將引入文本特征中,通過拼接成單通道的文本主題特征圖的形式,應用二維卷積神經(jīng)網(wǎng)絡對連續(xù)個詞項的部分相同維度的主題特征進行提取。從分類精度上可以看出,預訓練的文本主題潛在空間不僅有很強的魯棒性,而且能夠更好地映射出文本的主題信息。
七種分類算法中的訓練時長對比如圖7所示。
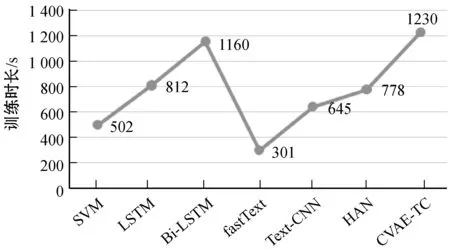
圖7 七種分類算法總的訓練時長
處理短文本特征的時候,相對于長文本特征少,因此使用簡單模型的時候,訓練時長會非常的短,比如fastText。CVAE-TC由于包含預訓練文本主題潛在空間的部分,因此需要的時間是最長的。但是由于將文本轉(zhuǎn)換為單通道的特征圖,可以應用成熟的圖像領域技術進行優(yōu)化。
從多維文本主題潛在空間中采樣一組點,并將其解碼成單通道的文本主題特征圖,通過可視化的方式顯示20×20=400個文本主題特征圖,如圖8所示。
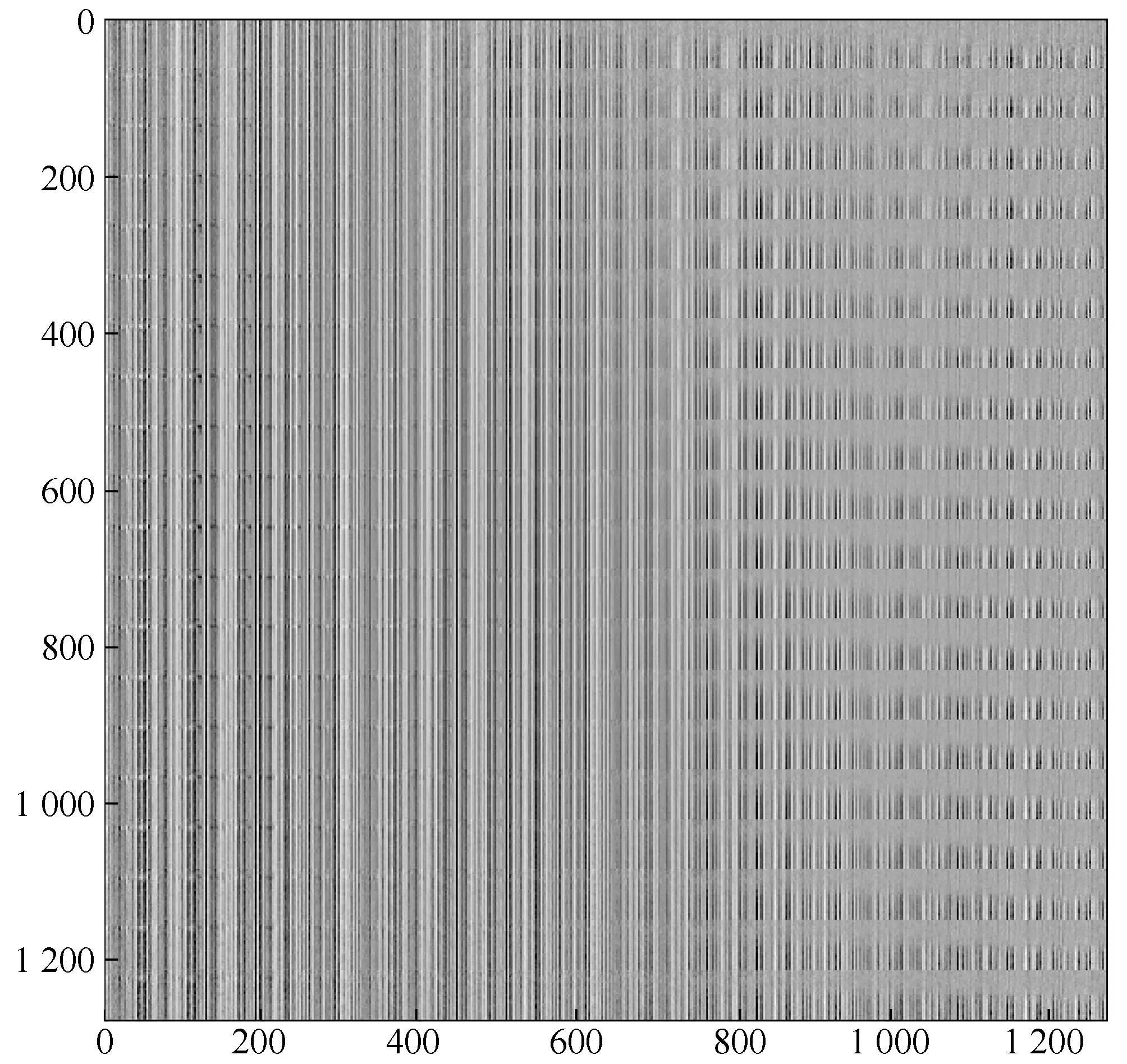
圖8 采樣文本主題潛在空間
雖然采樣文本主題潛在空間可視化不如采樣圖像潛在空間的可視化直觀,但是由于文本主題特征圖任意維度的特征值都在0~1之間,因此可以通過灰度圖像的可視化來可視化主題特征。維度值越接近于0可視化的結(jié)果越黑,表示維度主題不夠明顯,而維度值接近1,可視化的結(jié)果越白,表示當前維度的主題突出。通過圖8采樣后的可視化可以看出,得到的文本主題潛在空間具有很強的連續(xù)性,主題從左到右呈現(xiàn)一種逐漸過渡。
4 結(jié) 語
本文提出了基于變分自編碼的短文本分類模型,通過預訓練的LDA的主題詞項拼接單通道特征圖作為短文本的分類特征。通過二維卷積提取及Beta分布來生成文本主題的潛在空間,之后利用文本主題的潛在空間進行文本分類。短文本分類的效果得到了明顯的提升,但是在構(gòu)造特征圖過程中,雖然過濾掉短文本停用詞及主題特征不明顯的詞項,避免了主題詞項特征稀疏問題,但是由于維度比較大,導致某些維度的特征值比較小,增加了運算難度和時間效率復雜度,并且在重構(gòu)的過程中很難保證這些特征值比較小的維度。未來工作主要是優(yōu)化文本主題特征以提升算法的效率。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
