圖像特征注意力與自適應注意力融合的圖像內容中文描述
2021-09-18 06:21:42孔東一
計算機應用 2021年9期
趙 宏,孔東一
(蘭州理工大學計算機與通信學院,蘭州 730050)
(*通信作者電子郵箱kdongyi@163.com)
0 引言
圖像內容描述主要工作是通過計算機視覺(Computer Vision,CV)識別圖像內的實體、實體屬性及實體間的關系,然后利用自然語言處理(Natural Language Processing,NLP)技術生成一段合理的描述語句。圖像內容描述屬于多模態任務的一種,通過計算機視覺與自然語言處理技術的交叉融合,從而實現圖像到文本描述之間的跨模態轉換[1]。當前國內外的圖像內容描述研究工作,根據技術類型主要分為三類:基于模板的方法、基于檢索的方法和基于深度學習的編解碼方法。
計算機視覺與自然語言處理領域借助于深度學習的快速發展,使得圖像特征提取和語句生成效果大大提升,基于深度學習的編解碼方法進行圖像內容描述,其效果已經遠遠超過前兩種圖像內容描述方法,因此本文使用基于深度學習的編解碼方法進行圖像內容描述研究。
圖像由實體、實體的屬性以及實體間的關系組成,例如圖1 中有一個男人正在騎一匹棕色的馬,“男人”和“馬”是實體,“棕色”是“馬”的屬性,“騎”就是“男人”和“馬”之間的關系,實體間的關系等這類信息隱含在圖像結構中,不易被網絡模型檢測和識別。Jiang等[2]研究表明人類在處理隱含信息時可以吸引并引導注意力。Bahrami 等[3]研究表明人類的注意力可以調節隱含信息所引發的大腦活動。因此,人類在對圖像進行描述時,在重點關注圖像實體對象的同時也會合理地關注實體間的關系等類似的隱含信息。現有文獻中,通過引入注意力機制來將文本描述中的詞語對應到圖像中相應的區域,從而提高文本描述的生成效果,但是存在以下問題:1)人類在描述圖像時,更加關注圖像中的重點內容,同時會合理地關注隱含信息,現有模型如自適應注意力[4],雖然對實體及實體屬性等重點內容進行了重點關注,但該方法是通過忽略或降低了對某些隱含信息的注意力關注換取的,會導致一些內容的關注信息減弱或缺失。2)現有工作中,圖像特征注意力機制[5]雖然可以均等地關注圖像實體、實體屬性及實體間關系等內容,但是并沒有考慮對圖像中重點內容對象進行加強關注。

圖1 圖像的實體、實體的屬性以及實體間關系Fig.1 Entities,properties of entities and relationship between entities in an image
如表1 所示,由于上述問題,現有模型在對圖像進行中文描述時,會出現重點內容如圖中顏色、對象動作等識別錯誤,以及未重點關注到圖像內主體對象如圖中生成的描述未關注到圖中的草莓,而是關注了大棚內后方蔬菜形狀的物體上。

表1 注意力信息缺失或減弱及重點內容未加強關注Tab.1 Attention information weakening or missing and not focusing on key content
針對上述問題,本文首先通過圖像特征注意力來關注圖像中實體、實體屬性及實體間的關系等內容,然后使用自適應注意力機制來對圖像內的重點對象進行加強關注,使得在突出圖像中重點對象的同時合理地關注圖像中的隱含信息,模擬人類在描述圖像時對圖像的關注度,從而更加精準地提取圖像內的主體內容,使描述語句更加合理準確。
1 相關工作
Mao 等[6]提出了一種多模式遞歸神經網絡(multimodal Recurrent Neural Network,m-RNN)模型。該模型首次將卷積神經網絡(Convolutional Neural Network,CNN)與RNN 結合,解決了傳統的基于模板和基于檢索方法對圖像進行描述時,生成的描述語句存在生硬、單一且受限于數據集文本等問題。Vinyals 等[7]提出了NIC(Neural Image Caption)模型,該模型使用長短期記憶(Long Short-Term Memory,LSTM)網絡替換m-RNN 模型中的RNN,增強模型的長期記憶能力,顯著地改善了圖像描述的生成效果。上述工作利用編碼-解碼結構,通過CNN提取圖像語義特征信息,經過RNN解碼后生成圖像描述語句,得益于深度神經網絡的特征提取能力和自然語言生成能力,使得生成的描述語句結構合理、通順自然。
文獻[6]的NIC 模型不同于文獻[7]的m-RNN 模型,m-RNN 模型在RNN 解碼的每個時刻,都將圖像特征信息輸入到模型中,因此容易放大圖像噪聲,引起過擬合問題;NIC 模型在訓練每張圖像時,圖像特征信息只輸入一次,在循環訓練每個詞語時,圖像特征信息完全依靠LSTM 的長期記憶,該模型雖然解決了過擬合問題,但是會由于LSTM 長期記憶的減弱問題,而導致圖像特征信息逐漸減弱。為解決上述圖像內容描述研究中出現的問題,Xu 等[5]借鑒來自于機器翻譯領域的注意力機制,在編碼-解碼結構的圖像描述模型基礎上,加入圖像特征注意力機制對模型進行改進。圖像特征注意力機制將描述文本中的詞匯與圖像中每個特征進行權重計算,生成一個帶有權重信息的圖像特征向量,解碼網絡每一時刻接收不同權重的圖像特征信息,從而解決過擬合及圖像特征信息減弱的問題。
文獻[5]中通過圖像特征注意力機制在圖像特征與詞語之間建立注意力關注機制,但是該模型并未考慮對實體及實體屬性的突出關注。Lu 等[4]建立了自適應注意力機制,通過引入視覺哨兵對文本詞匯在圖像中的重要度進行計算,由視覺哨兵決定最終的預測詞匯是使用語言模型直接生成,還是使用空間注意力對詞向量進行注意力權重計算后生成。Anderson 等[8]使用Faster R-CNN 代替CNN 對圖像進行目標檢測,進而識別出圖像中的實體并進行注意力關注。但是上述兩個模型在注意力關注時,會忽略某些實體、實體屬性及實體間的關系,造成圖像注意力信息的缺失,導致模型不能很好地學習到圖像與詞匯間的映射關系,影響圖像描述生成效果。
2 注意力融合的圖像內容中文描述模型
2.1 圖像內容中文描述模型框架
本文提出的圖像特征注意力與自適應注意力融合的圖像內容中文描述模型框架如圖2 所示。在訓練時,將原始圖像進行圖像預處理后,送入預訓練的CNN 中得到圖像特征向量;圖像文本描述語句使用分詞工具進行分詞,將分詞后的詞語進行匯總統計并去除低頻詞語,為每個詞語進行唯一編號后形成詞典表,然后使用詞典表將所有圖像文本描述語句進行編號形成數字序列;使用Word2Vec工具以詞嵌入的方式對上述數字序列進行文本向量化,形成高維度詞向量矩陣;將上述圖像特征向量與詞向量一起送入圖像特征注意力模塊中,從而計算得到帶有權重信息的圖像特征語義向量,緊接著將其送入LSTM 網絡進行解碼預測得到當前時刻的隱藏狀態,該隱藏狀態中蘊含著詞向量對圖像特征的注意力視覺信息以及語句間的語義信息;然后將生成的隱藏狀態送入自適應注意力模塊,以自適應方式對當前時刻不同區域圖像特征的關注度進行動態調節,從而實現圖像特征重點內容的加強關注;最后模型利用SoftMax 算法來將生成的詞向量概率矩陣還原為文本語句。在測試時,將測試圖片經過預處理后送入模型預測得到描述語句,利用評價算法計算得分。
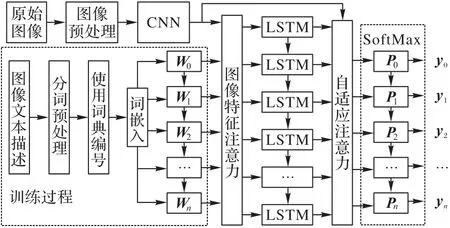
圖2 圖像內容中文描述框架Fig.2 Framework of Chinese image captioning
2.1.1 編碼器網絡
模型中Encoder 部分使用預訓練的ResNet152 作為圖像特征提取網絡,ResNet 網絡作為大規模視覺識別競賽ILSVRC2015的冠軍,在網絡中引入殘差結構解決了梯度消失問題[9],網絡層深度可以達到152 層,在圖像特征提取和識別效果上有著非常高的準確率。本文將ResNet152 網絡的倒數第二層輸出大小為1×1的平均池化層和最后一層全連接層替換成一個輸出大小為14×14 的平均池化層,最終得到圖像特征向量的維度為2048×14×14,這里將得到的圖像特征向量Va用式(1)表示:

其中:vi∈R2048是圖像特征向量中任意位置的圖像特征;k表示圖像特征的個數。
為了使自適應注意力模塊的圖像特征與LSTM 輸出的隱藏狀態ht維度匹配,使用帶有ReLU(Rectified Linear Unit)激活函數的全連接層進行維度調整,通過式(2)~(4)計算輸入到自適應注意力模型的圖像特征向量Vb。
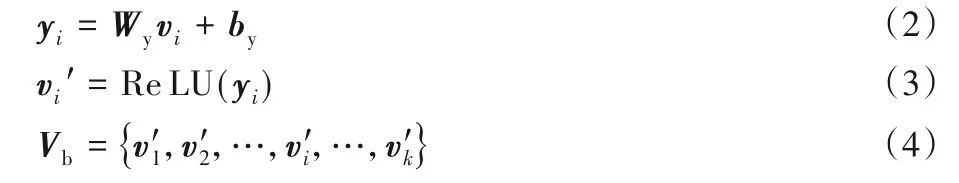
其中:∈Rm,m為LSTM 輸出的詞向量維度大小;Wy為全連接層需要訓練的權重參數;by為全連接層需要訓練的偏置參數。
2.1.2 解碼器網絡
模型中Decoder 部分使用LSTM 對圖像特征進行解碼,LSTM 由經典的RNN 改進而來,解決了RNN 中的梯度消失和長期依賴問題[10],傳統LSTM網絡結構如圖3(a)所示。
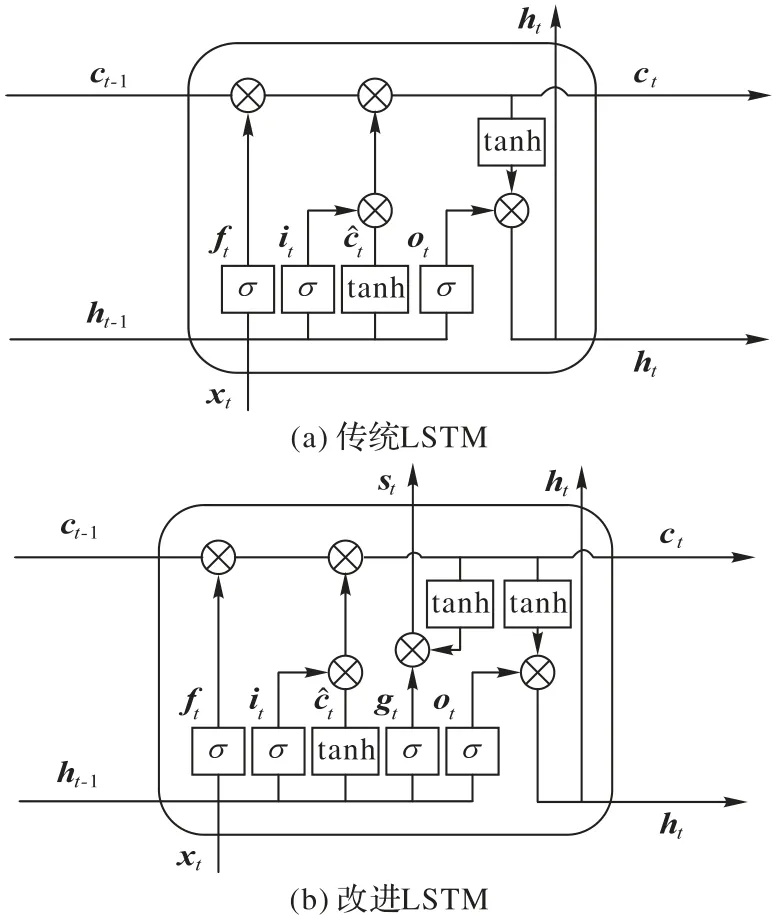
圖3 傳統LSTM與改進LSTM的網絡結構示意圖Fig.3 Schematic diagrams of traditional LSTM and improved LSTM network structures
LSTM通過三個門控單元來對網絡中的信息進行控制,計算過程如下:
首先,利用式(5)的輸入門it來控制網絡需要存儲和處理的信息。

其中:Wi為輸入門的權重參數;bi為輸入門的偏移參數;σ為Sigmoid 激活函數;ht-1為t-1 時刻網絡的短期記憶輸出;xt為t時刻網絡的輸入。
然后,利用式(6)計算長期記憶ct,通過式(7)的遺忘門ft來控制網絡丟棄無用信息,為t時刻網絡的中間量用式(8)表示。
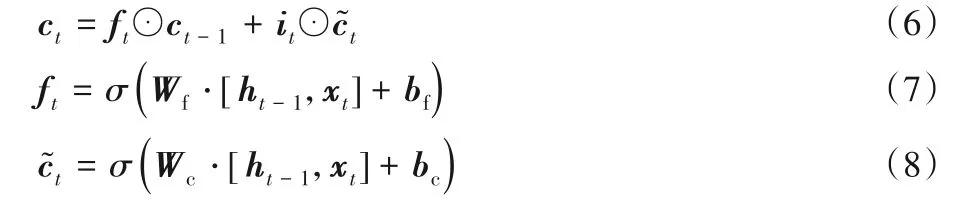
其中:Wf為遺忘門的權重參數;bf為遺忘門的偏移參數;Wc為中間量的權重參數;bc為中間量的偏移參數;⊙表示矩陣元素相乘。
最后,利用式(9)的輸出門ot來控制短期記憶ht的輸出,如式(10)所示。
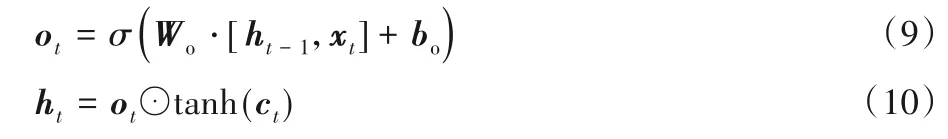
其中:Wo為輸出門的權重參數;bo為輸出門的偏移參數。
圖像特征注意力計算生成的帶有注意力權重信息的圖像特征信息與數據集標簽中的詞向量融合后作為解碼器的輸入信息,因此解碼器的LSTM 中存儲了圖像隱藏信息和語言語義信息,在傳統LSTM 中加入一個新的門控單元gt,用于提取這些信息,如圖3(b)。從而在LSTM 中提取出新的輸出,包含圖像和語義的隱藏信息st,用于自適應注意力模塊的輸入,計算過程如式(11)~(12)所示。LSTM 的隱藏信息ht和st中雖然都包含有圖像特征注意力信息和語言語義信息,但是st會通過訓練過程更加匹配自適應注意力的自適應調節任務,而ht主要用于最后的詞向量的計算輸出。
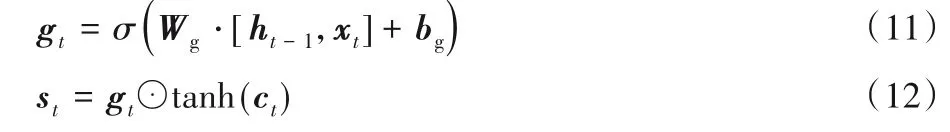
其中:Wg和bg為新增加門控需要學習的權重參數和偏置參數。
在t0時刻,將圖像特征Va進行加權平均并通過單層感知機訓練,作為LSTM 啟動輸入信息c0和h0,計算過程如式(13)~(14)所示。

其中:finit,c和finit,h為單層感知機計算函數;vi為式(1)中的圖像特征;k表示圖像特征的個數。
2.2 圖像特征注意力與自適應注意力融合
2.2.1 圖像特征注意力機制
通過圖像特征注意力將訓練集的文本描述的詞匯信息映射到對應的圖像特征區域,計算過程如下:
首先計算時刻t圖像特征各個區域的注意力權重,通過式(15)的多層感知器(MultiLayer Perceptron,MLP)來耦合圖像特征區域vi和解碼器LSTM 上一時刻輸出的隱藏信息ht-1。將上述計算結果送入式(16)所示的softmax 函數來計算t時刻第i個圖像特征區域的權重值φti,可以得到圖像各個區域的權重分布φt,權重分布的和為1,即=1,這些權重分布代表了t時刻的詞向量信息對圖像各個區域的關注程度。
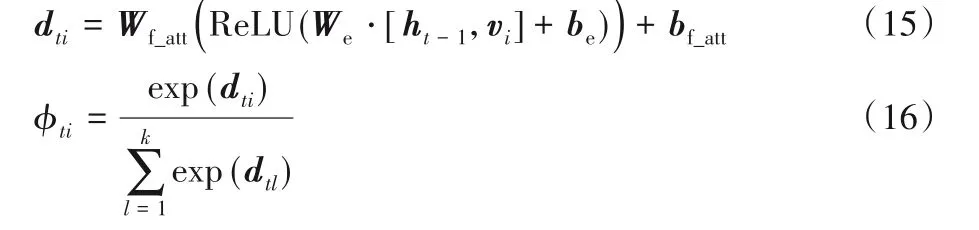
其中:Wf_att、We、bf_att和be為多層感知機需要學習的權重參數和偏置參數;vi為式(1)所表示的圖像特征;k表示圖像特征的個數。
然后通過式(17)將上述計算的權重分布φti施加到對應的圖像區域,其中閾值λt用來讓注意力模型集中關注圖像特征中的目標,如式(18)所示,最后得到t時刻帶有權重信息的圖像特征向量qt。

其中:L為圖像特征區域的個數;Wβ為閾值λt需要學習的權重參數。
2.2.2 自適應注意力機制
利用自適應注意力機制從圖像特征Vb和LSTM 里蘊含有圖像特征注意力的隱藏信息ht中提取出加強注意力信息et;通過自適應的方式來調節圖像和語言語義的隱藏信息st與自適應注意力信息et之間的依賴比例,從而達到對圖像特征中的重點內容再次加強關注的目的。計算過程如下:
首先通過式(19)~(21)計算自適應注意力的加強關注信息et,為自適應注意力提供圖像中的注意力信息。
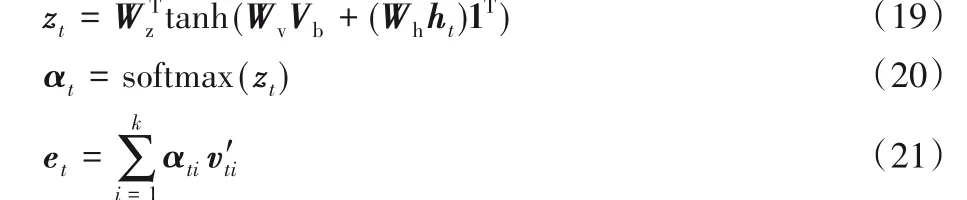
然后利用式(22)中的視覺哨兵模塊βt,來自適應地調節該注意力機制的輸出rt,從而決定rt是更加依賴基于自適應注意力加強關注后的信息et,還是更依賴基于圖像特征注意力提取的隱藏信息st。

其中:st在式(12)求得;視覺哨兵模塊βt計算過程如式(23)~(24)所示。

其中:式(24)表示βt取自向量∈Rk+1的最后一個元素由語義隱藏信息ht和圖像隱藏信息st融合而來。
2.2.3 注意力融合機制
基于人類在圖像描述時的注意力機制,本文將圖像特征注意力和自適應注意力進行深度融合,如圖4所示。
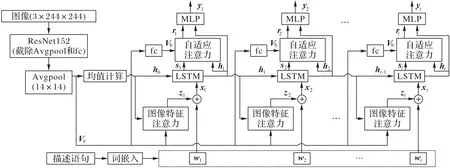
圖4 注意力融合機制示意圖Fig.4 Schematic diagram of attention fusion mechanism
首先將上述圖像特征注意力生成的帶有權重信息的圖像特征向量qt與文本描述詞嵌入后的詞向量wt進行向量拼接,得到LSTM的輸入xt,如式(25)所示。

其中:{;}代表將兩個向量進行拼接。
然后把拼接后的向量xt送入LSTM,預測出當前時刻的LSTM 的圖像及語言語義隱藏狀態ht和st,通過式(26)融合為,用來指導自適應注意力的視覺哨兵模塊,從而自適應地調節對圖像產生注意力的加強程度,決定某個圖像區域中是否更依賴于再次提取的圖像加強關注信息et。如式(22)所示,當某個圖像特征區域中隱藏信息st比重較大時,則該區域的圖像關注信息主要由圖像特征注意力提供;當加強關注信息et比重較大時,則該區域圖像關注信息會在圖像特征注意力基礎上二次加強關注。通過上述過程,實現在圖像內其他內容關注度不減弱或丟失的前提下,對圖像中的主體內容進行再次加強關注。

其中:Wz和Wh與式(19)中的權重參數相同。
最后通過多層感知機MLP 將自適應注意力輸出rt和LSTM 隱藏狀態ht融合,然后利用softmax 函數求得模型最終輸出的詞向量yt,如式(27)~(28)所示。
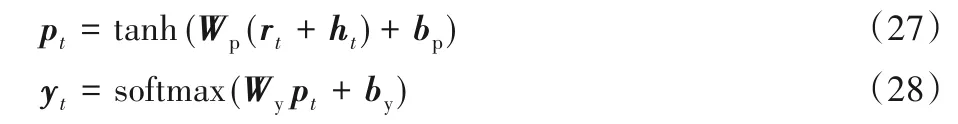
其中:Wp、Wy和bp、by為多層感知機需要學習的權重參數和偏置參數。
不同于文獻[4]中的自適應注意力模型只對圖像特征內的不同內容進行不同程度的關注,這會減弱或丟失對實體間關系等隱含信息的關注度。本模型對圖像特征中重點區域進行注意力加強關注,同時由于前面已經利用圖像特征注意力提取了所有注意力信息,自適應注意力模型是在包含了所有注意力信息的隱藏狀態st和ht的基礎上,有針對性地再次加強關注,因此不會減弱或丟失對圖像中隱含信息的關注,而文獻[4]中LSTM的隱藏狀態中并不包含圖像注意力信息。
2.3 損失函數計算
本文使用交叉熵損失函數來計算模型預測生成的詞向量yt與數據集中語句描述標簽的詞向量的損失值,通過最小化損失函數的值來對模型進行訓練,交叉熵損失函數計算過程如式(29)所示。

其中:C為描述語句的長度;表示t時刻生成的詞向量yt預測為的概率。
為了使圖像特征注意力中的每個圖像特征區域都得到關注,在損失函數中加入正則項,使得模型在解碼階段的所有時刻的任一圖像特征區域權重值之和均相等,即≈1,從而使圖像特征注意力所關注的每個圖像區域參與到文本描述生成過程中。模型的損失函數如式(30)所示。
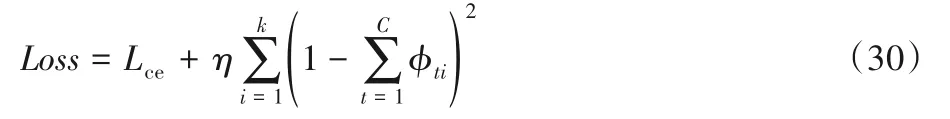
其中:η為正則項的參數,本文取1;k為圖像特征的個數;C為描述語句的長度。
3 實驗與結果分析
3.1 實驗平臺
本文實驗的硬件平臺為Intel Xeon Silver 4116 CPU@2.10 GHz 處理器,運行內存為128 GB,顯卡為NVIDIA Tesla T4 GPU,顯存為16 GB,軟件平臺使用支持GPU 加速運算的PyTorch 深度學習框架,配置NVIDIA CUDA 10.1 及cuDNNV7.6深度學習加速庫。
3.2 數據集及評價指標
為了驗證本文模型的有效性,選取在圖像內容中文描述領域涉及場景最全面、語言描述最豐富、規模最大的ICC 數據集[11]進行實驗。數據集中訓練集、驗證集和測試集分別有210 000 張、30 000 張和30 000 張圖片,每張圖片對應5 句中文語句描述,如圖5所示。

圖5 ICC圖像內容中文描述數據集示例Fig.5 Examples of ICC Chinese image captioning dataset
為客觀評測模型性能,本文使用廣泛用于圖像內容描述領域的BLEU(BiLingual Evaluation Understudy)[12]、METEOR(Metric for Evaluation of Translation with Explicit ORdering)[13]、ROUGEL(Recall-Oriented Understudy for Gisting Evaluation with Longest common subsequence)[14]和CIDEr(Consensusbased Image Description Evaluation)[15]作為評價指標,為本文模型和對比模型計算評價得分,從而客觀評價模型的語句描述生成效果。值得注意的是,CIDEr 評價指標是專門設計用于客觀評價圖像描述任務的指標,本文將在對比其他評價指標得分基礎上,重點分析CIDEr評價指標得分差異。
3.3 實驗參數設置
在圖像預處理時,將數據集原始圖片大小縮放至256×256 像素大小,在模型讀取圖片時,進行15°隨機旋轉,并對圖像進行隨機裁剪,得到224×224 像素大小的圖像。在描述語句預處理時,采用“jieba”分詞工具對數據集中的描述文本進行分詞,對分詞后的描述詞匯進行匯總統計,將大于低頻閾值的詞匯形成詞匯表,本文選取的低頻詞匯閾值為5,最終得到7 768 個詞匯。解碼器中的LSTM 輸入的詞嵌入向量維度、輸出維度、圖像特征注意力和自適應注意力層維度大小均設置為512,在生成詞向量時,使用Dropout 技術[16]防止模型過擬合,Dropout取值為0.5。
模型訓練階段,使用Adam[17]優化算法對模型參數進行優化,批訓練大小為64;初始學習率為0.000 1,每輪次訓練結束后,若模型在驗證集上評價得分連續3 個輪次沒有增長時,將學習率衰減0.1;為防止梯度爆炸,在反向傳播時進行梯度裁剪。在模型訓練起步階段,首先固定編碼器網絡的參數,訓練到模型在驗證集評價得分不再增長時,對編碼器參數進行微調,使編碼器和解碼器進行聯合訓練。
3.4 實驗結果及分析
訓練過程中,每輪次訓練結束后,在驗證集進行推理預測并計算評價指標得分,每輪次得分結果繪制曲線如圖6 所示,保存驗證集上評價得分最高的模型,在訓練結束后在測試集進行測試。在圖6 中第10 輪次得分有明顯的跳躍式增長,因為模型解碼器剛開始的參數是隨機初始化的,并不具備有效的解碼能力,為防止產生的誤差反向傳播到編碼器,剛開始訓練時固定編碼器中預訓練的ResNet 網絡參數。當驗證集評價得分不再上升時,說明解碼器已經具備模型解碼能力,并且達到解碼器參數優化的瓶頸,此時進行ResNet 網絡的參數微調,讓預訓練的編碼器更加適應本模型的任務,因此模型評價得分迅速增加。
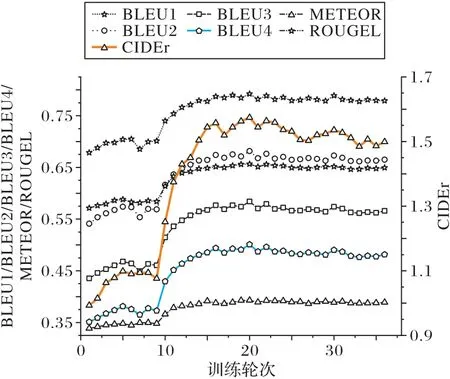
圖6 模型各輪次評價指標得分Fig.6 Evaluation index scores of models in each round
為驗證模型的有效性,本文使用相同的實驗環境,分別搭建基于自適應注意力和基于圖像特征注意力的圖像內容描述模型,在ICC 數據集進行模型對比實驗,實驗評價得分結果如表2 所示。從表2 可可知,在圖像內容中文描述任務上,單一的圖像特征注意力比自適應注意力模型性能要好;相較于單一的基于自適應注意力和基于圖像特征注意力的模型,本文模型進行注意力融合后,模型識別性能大幅提升,尤其是CIDEr 評價指標,分別提升10.1%和7.8%,說明本文模型有效提升了圖像內容描述任務的性能。

表2 不同注意力機制模型下的評價指標得分對比Tab.2 Comparison of evaluation index scores under different attention mechanism models
本文還與圖像描述領域具有權威代表性的研究工作進行了對比,表3為對比結果。

表3 本文模型與其他模型的性能對比Tab.3 Performance comparison of proposed model with other models
表3 中:Baseline-NIC 模型[11]使用NIC 模型對其公開的ICC 數據集進行性能測試的結果。基于自底向上和自頂向下(Bottom-Up and Top-Down,BUTD)注意力的圖像描述模型[8]使用Faster R-CNN 提取圖像內的實體對象,該模型的實驗結果為文獻[18]在ICC 數據集上的復現結果,結果表明在圖像內容中文描述任務上,BUTD 模型在BLEU、METEOR 和ROUGEL 評價指標上優于NIC 模型,但是CIDEr 評價指標遜色于NIC 模型。全局注意力機制模型[18]在BUTD 模型基礎上加入了全局注意力機制,結果表明該模型的CIDEr 評價指標上有優化提升,其他指標與BUTD 模型持平。相較于以上三種模型,本文模型評價指標得分均有大幅提升,分別提升10.9%、12.1%和10.3%。
除此之外,本文還進行了主觀對比實驗。如表4 中第一個實例,自適應注意力模型成功識別出實體對象“草莓”,但是由于對衣服顏色屬性的注意力信息減弱,將白色衣服識別為紅色;圖像特征注意力由于沒有注意力的重點關注機制,將注意力重點關注到了圖像后方蔬菜形狀的物體上,并沒有重點關注實體對象“草莓”;第二個實例,自適應注意力和圖像特征注意力模型在圖像內的行為描述出現錯誤,本文模型成功描述出“下棋”這一行為動作;第三個實例,自適應注意力和圖像特征注意力模型并沒有將注意力聚焦到“喂”這個隱含信息上,因此兩者描述沒有抓住圖像重點,本文模型合理準確地對該圖像進行了描述。由對比效果可知,本文模型相較于單一注意力模型能夠生成更加準確、質量更高的圖像中文描述語句。

表4 各模型描述效果在實例中的主觀對比Tab.4 Subjective comparison of different model description effects for examples
4 結語
本文提出一種圖像特征注意力與自適應注意力融合的圖像內容中文描述模型,通過圖像特征注意力對圖像特征進行全面關注,然后使用自適應注意力對圖像特征重點區域再次加強關注,很好地模擬了人類的注意力過程,提升了模型對圖像的關注和理解能力,使模型對圖像的內容描述性能大幅提高。最后將本文模型與單一注意力模型進行了對比實驗測試,并與其他前沿的圖像描述方法進行對比,實驗結果表明本文模型相較于其他模型性能提升明顯,圖像的內容識別更加準確,描述語句更加合理。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
臺聲(2016年2期)2016-09-16 01:06:53
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
