基于增強多維多粒度級聯森林的信用評分模型
2021-09-18 06:21:52卞凌志王直杰
計算機應用 2021年9期
卞凌志,王直杰
(東華大學信息科學與技術學院,上海 201620)
(*通信作者電子郵箱wangzj@dhu.edu.cn)
0 引言
隨著金融業的不斷發展,向商業銀行貸款的人數也越來越多,這在增加了銀行可周轉資金的同時也使銀行面臨信用風險的威脅[1]。根據中國銀行業監督管理委員會統計,銀行不良貸款余額近年來呈上升趨勢,因此,構建有效、可靠的信用評分模型對于銀行避免損失和在激烈競爭的市場中生存至關重要[2]。
利用借款人個人信息對違約概率進行預測可以衡量借款人無法償還債務的風險。為了提高信用評分的準確度,要求對借款人的信息進行全面的分析并建立合適的模型。
目前信用評分的模型可分為兩類:一種是基于傳統統計學習的方法,另一種是基于機器學習的方法。傳統基于統計學習的方法利用數據在統計方面的性質和規律進行建模,主要的方法有邏輯回歸(Logistic Regression,LR)與線性判別分析(Linear Discriminant Analysis,LDA)。如Steenackers 等[3]利用LR 的統計學習思想對信用評分進行建模;Baesens 等[4]分別使用LDA與LR方法對信用評分進行建模。LR使用極大似然法的迭代方式,從而找到參數中最接近真實的估計值;LDA通過計算原始分類樣本的均值與方差,并計算新的樣本在投影后得到的特征屬于各分類的概率。這兩種方法可以有效解決各種分類問題,但是統計學習強烈依賴于獨立變量和非獨立變量之間的線性關系,不能有效地利用現有的特征學習的方法,因此預測準確度不高。繼傳統方法后,在分類問題中逐漸開始使用基于集成學習的機器學習方法,集成學習在信用評分模型中的應用分為裝袋法(Bagging)和提升法(Boosting)。Bagging 方法的主要想法是分別訓練幾個模型,并對這些模型進行平均,從而得到較好的模型,如Breiman[5]提出了隨機森林(Random Forest,RF)方法,將每個決策樹得到的結果進行平均,可以有效提高單個決策樹模型的預測結果準確度,并用于解決各類回歸與分類問題。Boosting 方法的主要想法是將弱分類器組裝為強分類器,常用的方法有Freund 等[6]提出的自適應增強(Adaptive Boosting,AdaBoost)和Friedman[7]提出的梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)。近年來,Chen 等[8]提出的極端梯度提升(eXtreme Gradient Boosting,XGBoost)高效地實現了GBDT 算法并在算法上的有許多改進。Ke 等[9]提出的輕量級梯度提升機(Light Gradient Boosting Machine,LightGBM)算法同樣高效地實現了GBDT算法,在原理上與XGBoost 算法相似,但是LightGBM 具有更快的運行速度并且可以直接處理類別數據。XGBoost 與LightGBM 都是競賽中常用的方法,在對提取好的特征進行訓練分類中都能取得不錯的效果。各類集成學習的方法廣泛應用于信用評分模型中,在不同的數據集上表現各不相同,在預測結果上仍然具有改進的余地。
在近三年的信用評分研究中,Arora等[10]提出了基于嵌入式的Lasso 方法的改進版本,即Bolasso 方法分別改進支持向量機(Support Vector Machine,SVM)、樸素貝葉斯(Naive Bayes,NB)、K-近鄰(K-Nearest Neighbors,KNN)與隨機森林算法建立信用評分模型,該方法在訓練數據有輕微變化時,可以選擇不同的特征子集,但在預測準確度上仍有提升的空間。Moscato 等[11]使用常用的機器學習方法與可解釋人工智能工具,在信用評分問題中同時評估分類器的準確性性能及其可解釋性,但僅在一個數據集上進行了研究,模型的泛化能力有待改進。
本文在模型方面選擇Zhou 等[12]提出的多維多粒度級聯森 林(multi-dimensional and multi-grained cascade Forest,gcForest)算法。這是一種基于隨機森林的算法,通過多維多粒度掃描提出數據的特征,利用級聯森林模塊去學習并生成模型,通過引入層的概念很好地解決了RF、XGBoost、LightGBM 等集成樹算法容易過擬合的問題。為了進一步提高特征提取的多樣性,并在增加隨機森林層數后避免梯度爆炸或梯度消失問題,從而能在保持之前的模型效果的基礎上繼續增加學習特征的能力,借鑒深度學習中殘差網絡的結構,在gcForest 的基礎上進行改進,本文提出了多維多粒度級聯殘差森林(multi-dimensional and multi-grained cascade residual Forest,grcForest)模型,并考慮了信用評分建模的整個過程,包括數據預處理、建立模型、調參、算法改進和評估。通過AUC(Area Under Curve)、準確率等評價指標對模型結果進行論證,同時與現有的各種機器學習算法在四個不同的信用評分數據集上進行對比。
1 gcForest算法
1.1 級聯森林結構
gcForest是一種決策樹集成方法,通過級聯的方式堆疊多層隨機森林,以獲得更好的特征表示和學習性能。相較于深度學習,gcForest 只需要很少的訓練數據,就能獲得很好的性能,而且基本不需要調節超參數的設置。gcForest由兩部分組成:級聯森林與多粒度掃描結構。
在級聯森林中,每一層都可以包含多個不同的隨機森林,這樣能夠增強模型的泛化能力。如圖1 所示,在實驗中使用了兩種隨機森林:隨機森林(實線)與極限森林(虛線)。級聯森林的層數可以自己確定,每一層隨機森林學習輸入特征向量的特征信息,經過處理后輸入到下一層,每層結束后都會在驗證集上進行估計,如果預測效果沒有明顯提升,就不再繼續增加深度,訓練過程就會終止。
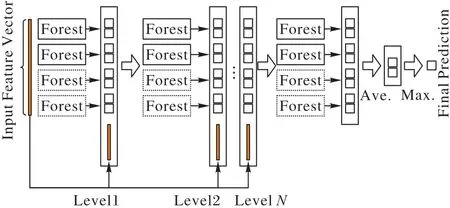
圖1 級聯森林結構Fig.1 Structure of cascade forest
在級聯森林中,隨機森林的每棵決策樹對于輸入特征向量都會產生一個關于每類的預測概率,對所有決策樹產生的概率分布向量進行平均就得到隨機森林輸出的類分布向量。然后將這些類分布向量與原始的特征向量進行拼接,得到下一層的輸入向量,不斷迭代直到收斂為止。
1.2 多粒度掃描結構
受到卷積神經網絡的啟發,對輸入特征使用多粒度掃描的方式產生級聯森林的輸入特征向量。
例如在圖2 中對于400 維的輸入數據,如果采用100 維的滑動窗口對輸入特征進行處理,最終得到301個100維的特征向量。在本實驗中使用多個不同大小的滑動窗口,從而生成不同粒度的特征向量。

圖2 多粒度掃描結構Fig.2 Structure of multi-grained scanning
1.3 總體結構
圖3 是gcForest 模型的總體框架圖,假設輸入特征為400維,多粒度掃描模塊具有3 個滑動窗口,并使用這些數據作為一個隨機森林和一個極限森林的輸入,如果是二分類預測,那么能得到1 204維特征向量,然后輸入到第一級級聯森林中進行訓練。
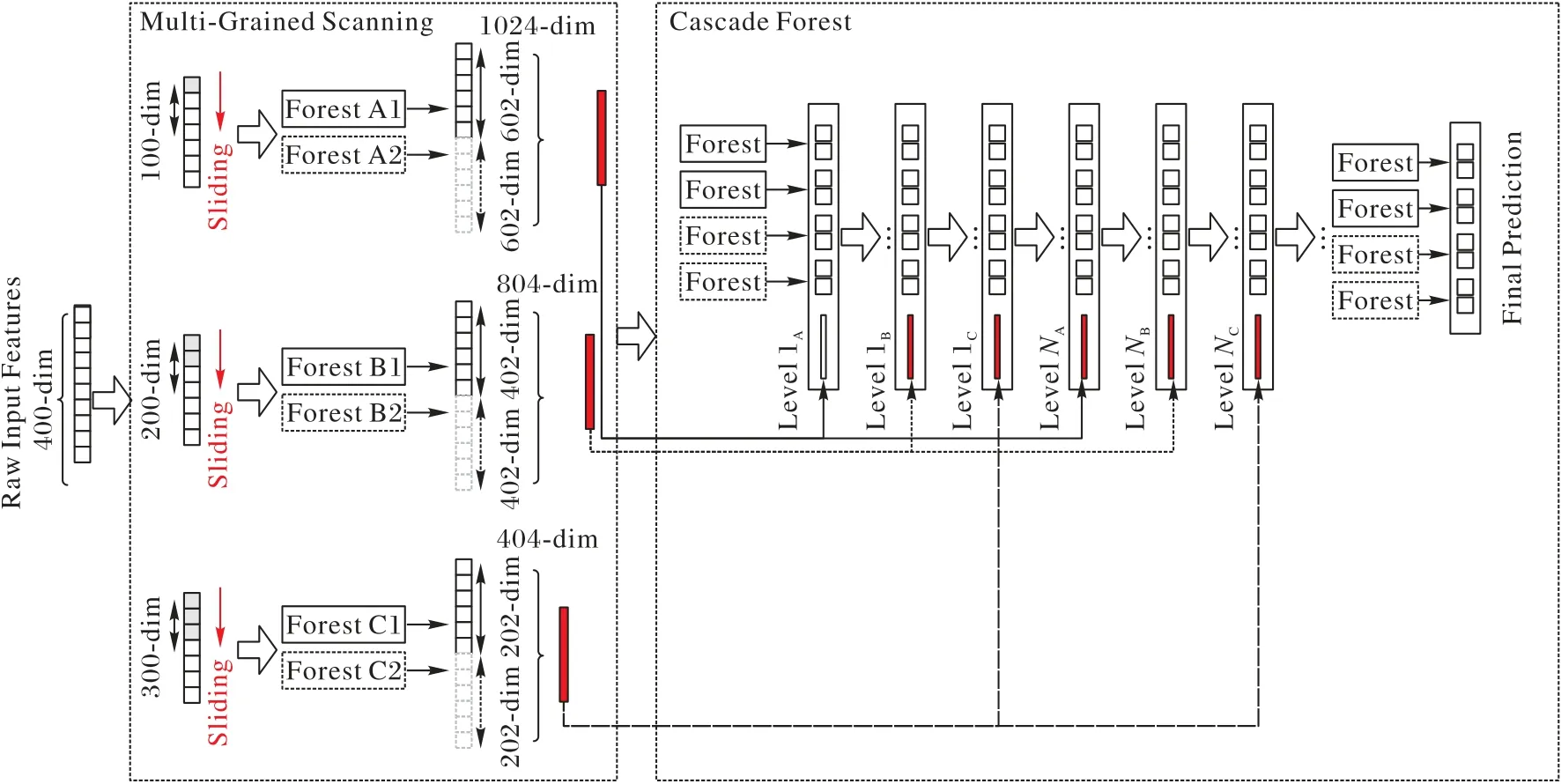
圖3 gcForest模型的總體框架Fig.3 Overall framework of gcForest model
另外兩個窗口掃描后分別得到804維與404維特征向量,將它們用于訓練二級和三級級聯森林,不斷重復這一過程,直到驗證性能收斂為止。
2 算法改進
類似于深度神經網絡(Deep Neural Network,DNN),隨著隨機森林層數的增加,模型能夠獲取的特征與信息也就越多,但也有可能出現梯度消失或梯度爆炸的問題。針對這一問題,在神經網絡中引入了殘差網絡(ResNet),使得在增加網絡層數后能在保持之前的模型效果的基礎上繼續增加學習特征的能力。
為了在gcForest 中增加隨機森林層數時避免梯度爆炸或消失問題,提出了grcForest,即在級聯森林模塊中也采取類似殘差網絡的結構,將第一層隨機森林得到的結果加到后面的隨機森林輸入特征中,從而提高了特征提取的多樣性,并使得在增加隨機森林層數時模型能夠在保留之前效果的基礎上向最優值靠近。
如圖4~5 所示,輸入特征在經過多粒度掃描后的特征值輸入兩類隨機森林中,由于實驗為二分類問題,因此每個隨機森林產生兩個分類結果,將這些結果保存下來并與相應的多粒度掃描得到的特征值一起輸入后面每一層的隨機森林中,不斷重復這一過程,直到驗證性能不再提高為止。

圖4 grcForest流程Fig.4 Flowchart of grcForest

圖5 級聯殘差森林結構Fig.5 Structure of cascade residual forest
3 信用評分實驗
3.1 評價指標
在分類算法中,常見的分類指標有準確率Acc(Accuracy)、精確率Pre(Precision)、召回率Rec(Recall)、真正例率TPR(True Positive Rate)、假正例率FPR(False Positive Rate)、F1-Score、ROC(Receiver Operating Characteristic)曲線[13]、AUC(Area Under Curve)[14]等,這些指標都要通過混淆矩陣(Confuse Matrix)中的真正類TP(True Positive)、假負類FN(False Negative)、假正類FP(False Positive)和真負類TN(True Negative)進行計算。此外,Brier 分數BS(Brier Score)[15]也經常用于分類問題中,它的值越低就代表預測結果越好。
準確率Acc是預測正確的概率:

精確率Pre指正確預測為正樣本(TP)占所有預測為正樣本(TP+FP)的比率:

召回率Rec指正確預測為正樣本(TP)占所有正樣本(TP+FN)的比率:

精確率和召回率是相互影響的,F1-Score值可以同時兼顧兩者:

真正例率與召回率公式相同,都表示正確預測為正樣本占所有預測為正樣本的比率:

假正例率指錯誤預測為正樣本占所有實際為負樣本的比率:

ROC曲線是以FPR作為X軸,TPR作為Y軸的函數。AUC值是ROC 曲線與X軸、Y軸圍成的面積,AUC值越接近1,則預測方法的真實性越高。

其中:n是樣本的數量;r是類別;fti是模型預測第t個樣本的類別為i的概率;oti是第t個樣本的真實值(類別為i則取1,否則取0)。
在本文中,主要使用的評價指標是AUC與Acc,其他一些指標(F1-Score、BS與TPR)也作為參考一同列出。
3.2 數據集預處理
在信用評分模型中,借款人的各種個人信息一般包括如貸款金額、期限、年齡、職業、銀行存款、住房情況、消費記錄、還款記錄等數據。由于數據集中還包含許多類別數據與無用數據,因此在建模前要先對數據進行預處理。在填補缺失數據并將類別數據轉化為數值后對數據進行特征提取,常用的特征提取方法有卡方檢驗[16]、主成分分析(Principal Component Analysis,PCA)、遞歸特征消除(Recursive Feature Elimination,RFE)[17]、線性判別分析[18]等方法。本文中使用RFE方法進行特征提取。
實驗中數據集使用機器學習開放數據集網站UC Irvine Machine Learning Repository 中的德國、澳大利亞信用數據集[19],Kaggle 網站上的公開信用數據集與P2P 平臺Lending Club網站上的貸款數據[20]。
在有些數據集,如Kaggle 與P2P 數據集中存在一些丟失數據,如果丟失數據為數值類型,則用平均值填充;如果為類別類型,則用眾數填充,并用數值對這些類別進行編碼替代。在P2P 數據集中樣本過大,有423 808 組數據。由于邊際效應,過多數據并不會提高模型準確度,反而大幅地降低了模型效率,因此對數據集進行隨機抽樣,對正、負樣本分別抽取5 500組數據組成新的數據集。
表1 所示為數據預處理后的實驗數據集與它們的數據維度、樣本大小與樣本正負比。

表1 實驗中的數據集Tab.1 Datasets used in experiments
此外,在這些數據集中除了建模必要的信息外還有許多冗余的數據,如果直接輸入機器學習模型中可能會降低學習效率,因此先對這些數據集使用RFE方法進行特征提取。
4 實驗與結果分析
為了證實對gcForest 方法改進的有效性,在不同數據集上將grcForest 與未改動的gcForest 方法以及其他當下常用的信用評分方法進行對比實驗,并與近幾年其他文獻在信用評分模型上的表現進行對比。在每個數據集的實驗中使用5 折交叉驗證的方法提高實驗結果的可靠性。
表2~5 是分別使用隨機森林(RF)、邏輯回歸(LR)、XGBoost、LightGBM、gcForest 與改進后的grcForest 對3.2 節中經過預處理的德國、澳大利亞、Kaggle 與P2P 數據集進行分類預測后得到結果的各項指標。可以看到grcForest模型在各數據集上都表現出色。

表2 各模型在德國數據集上的結果Tab.2 Results of different models on German dataset
在德國數據集中,grcForest的AUC值為0.768,排名第一,比排名第二的gcForest 高0.005,比第三的LightGBM 高0.012;而Acc值為最高的0.75,超過排名第二的gcForest 0.011,比LightGBM 高0.035;在其他指標中也都是最好的。因此在德國數據集中,grcForest效果最好。

表3 各模型在澳大利亞數據集上的結果Tab.3 Results of different models on Australian dataset
在澳大利亞數據集中,grcForest 的AUC值是最高的,為0.919,比排名第二的gcForest 高0.010;Acc值與RF 相同,排名第二,都為0.877,比gcForest 高0.054,而最高的XGBoost為0.891;BS值為0.098,僅比最低的LR 高0.002,在其他指標中也都優于gcForest。因此在澳大利亞數據集中,grcForest與XGBoost效果較好。
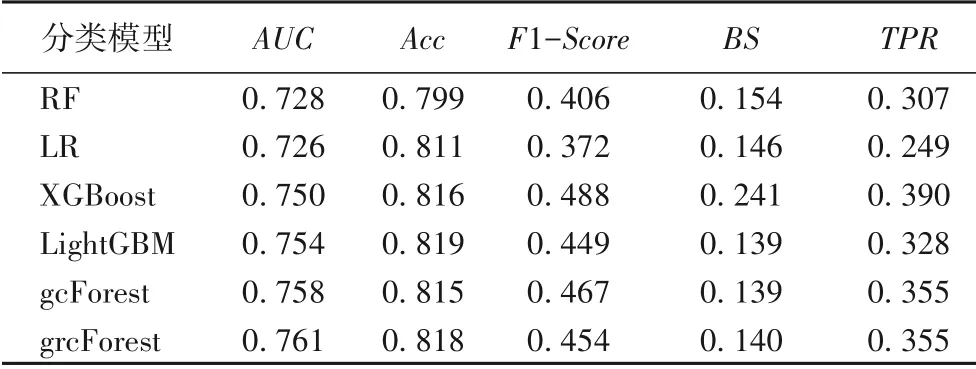
表4 各模型在Kaggle數據集上的結果Tab.4 Results of different models on Kaggle dataset
在Kaggle 數據集中,grcForest 的AUC值為0.761,排名最高,比第二的gcForest 高0.003;Acc值為0.818,排名第二,略低于第一的LightGBM,比gcForest 高0.003;在其他指標上也都表現穩定。grcForest 與LightGBM 在Acc和BS上僅差0.001而在其他指標上都略優于LightGBM;在關鍵的指標AUC與Acc上均略高于gcForest,因此在Kaggle 數據集中,grcForest 效果最好。

表5 各模型在P2P數據集上的結果Tab.5 Results of different models on P2P dataset
在P2P 數據集中,grcForest 的AUC值是最高的,為0.9,比gcForest 高0.003;Acc值為0.824 排名第二,與gcForest 相同,比第一的LightGBM 低0.004,但在其他指標上都優于LightGBM;在指標F1-Score、BS和TPR上均表現最好。因此在P2P數據集中,grcForest效果最好。
在近三年信用評分模型研究中同樣有在現有機器學習模型基礎上進行改進的,在表6 中將grcForest 與文獻[10]中經過Bolasso 方法改進的SVM、NB、KNN 與RF 算法(簡寫為BSSVM、BS-NB、BS-KNN 與BS-RF)使用信用評分模型中最重要的兩個評價指標:AUC與Acc進行對比。由于在該文獻中沒有在澳大利亞與P2P 數據集上進行實驗,因此只在德國與Kaggle數據集上進行對比。

表6 grcForest模型與其他文獻算法效果對比Tab.6 Effect comparison of grcForest model and other models in literatures
從表6 可以看出,grcForest 的AUC值在兩個數據集中都是最高的,Acc值也都表現不錯,明顯優于經過Bolasso 方法改進后的SVM、NB 與KNN 算法;雖然Acc值低于BS-RF 算法,但AUC值均更高。在信用評分模型中,相較于Acc指標,AUC更能對一個模型作出全面的評價,因此grcForest 的表現是最好的。
圖6~9 是各模型在4 個數據集上的ROC 曲線,并在曲線下方列出了各模型對應的AUC值。
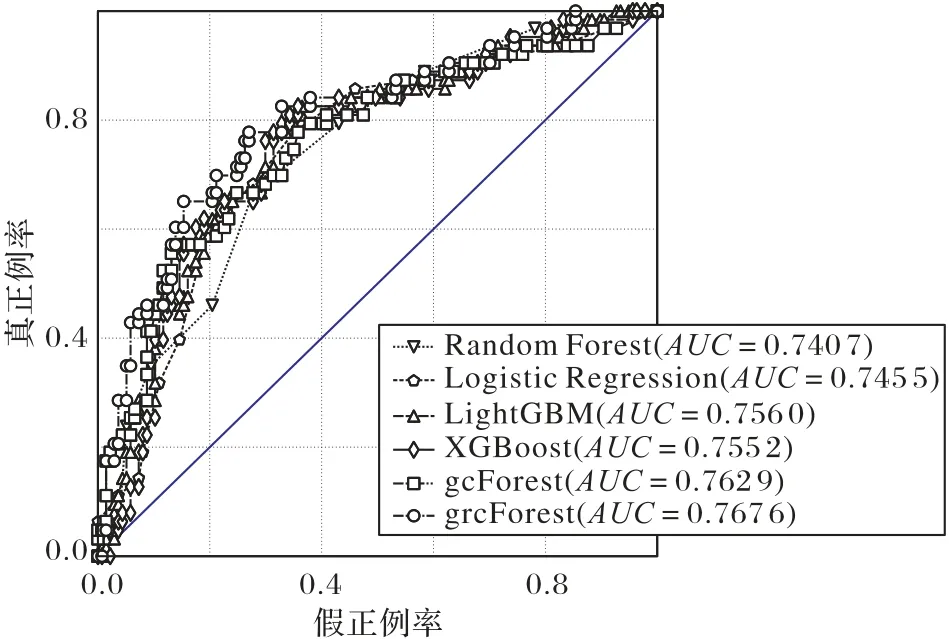
圖6 各模型在德國數據集上的ROC曲線Fig.6 ROC curves of different models on German dataset
結合表2~5中的各項評價指標可以看出如下幾點:
1)在當下常用的信用評分方法中,LightGBM 與XGBoost比其他方法的效果更好。
2)在各數據集上gcForest 與LightGBM、XGBoost 方法效果接近。
3)改進后的grcForest 比gcForest 方法表現更穩定,效果更好,除在澳大利亞數據集中與XGBoost 結果相當,在其他數據集中均表現最好,其AUC值相較于LightGBM 平均高1.13%,相較于XGBoost平均高1.44%。

圖7 各模型在澳大利亞數據集上的ROC曲線Fig.7 ROC curves of different models on Australian dataset

圖8 各模型在Kaggle數據集上的ROC曲線Fig.8 ROC curves of different models on Kaggle dataset

圖9 各模型在P2P數據集上的ROC曲線Fig.9 ROC curves of different models on P2P dataset
5 結語
隨著計算機科學的不斷發展,信用評分模型也得到不斷改進,從而更好地幫助銀行抵御信用風險。本文將一種深度森林的機器學習方法gcForest 應用于信用評分,并在此基礎上對gcForest 進行改進,將級聯森林模塊中第一層隨機森林得到的結果加入后面每一層隨機森林的輸入中,從而提升了在信用評分模型中的效果。
在未來的工作中,信用評分模型仍然有一些可以改進的地方,例如將grcForest與其他機器學習算法進行融合;使用優化算法對grcForest 的超參數進行優化;對多粒度掃描模塊進行優化并使運行速率得到提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
