基于改進的Faster R-CNN的通用目標檢測框架
2021-09-18 06:22:32馬佳良孫曉飛
計算機應用 2021年9期
馬佳良,陳 斌,孫曉飛
(1.中國科學院成都計算機應用研究所,成都 610041;2.中國科學院大學計算機科學與技術學院,北京 100049;3.哈爾濱工業大學(深圳)人工智能研究院,廣東深圳 518055)
(*通信作者電子郵箱chenbin2020@hit.edu.cn)
0 引言
近年來,隨著深度卷積神經網絡(Convolutional Neural Network,CNN)的發展,計算機視覺研究人員見證了目標檢測技術的快速進步。基于深度學習的目標檢測器可分為兩類:二階段檢測器[1-5]和一階段檢測器[6-8]。一階段檢測器直接產生目標的類別概率和位置坐標,經過一次檢測即可直接得到最終的檢測結果。二階段檢測器則首先產生候選框,然后再對每個候選框預測類別和位置。二階段檢測器具備錯誤率低和漏報率低的特點,因此無論是在工業應用還是學術研究中,針對二階段檢測器的改進都受到廣泛關注。
二階段檢測器的檢測流程如圖1 所示,首先將一張圖片輸入骨干網絡提取特征,然后在圖片上均勻鋪設矩形錨框,再根據錨框和目標的交并比進行排序篩選,確定訓練樣本,最后在特征圖上裁剪目標特征送至后續的子網絡進行訓練。這個流程簡單有效,幾乎成為了所有二階段檢測器的固定范式。基于該范式,檢測器訓練的成功與否取決于兩個關鍵方面:1)所選區域樣本是否具有代表性;2)輸入任務網絡的視覺特征是否準確。使用物體的最小外接矩形來表示目標的位置雖然很適合卷積運算,但這種形狀無關的設計顯然弱化了目標的表示能力。這給上述兩個方面帶來了顯著的問題,這些問題不僅阻礙了模型功能的充分利用,還限制了模型的檢測性能。
下面詳細描述這兩個問題:
1)無論是在判斷樣本正負還是在應用非極大值抑制(Non-Maximum Suppression,NMS)時,交并比(Intersection over Union,IoU)都是評價包圍框質量的最重要的標準,高IoU往往代表著優質樣本。但實際上,由于物體的形狀各不相同,錨框內的特征除了包含物體內的有效信息,還有物體外的背景信息,非目標的背景區域會誤導模型的判斷。具體來說,如圖1 所示,在右下的目標附近預設了包圍框A 和包圍框B,根據交并比計算公式,包圍框A 與真值(Ground Truth,GT)框的IoU 為0.69,包圍框B 與GT 的IoU 僅為0.64。但通過觀察很容易發現,包圍框A 位于有效目標的外部,而包圍框B 位于目標的內部,顯然包圍框B包含更多的有效信息,應當是更有效的樣本。
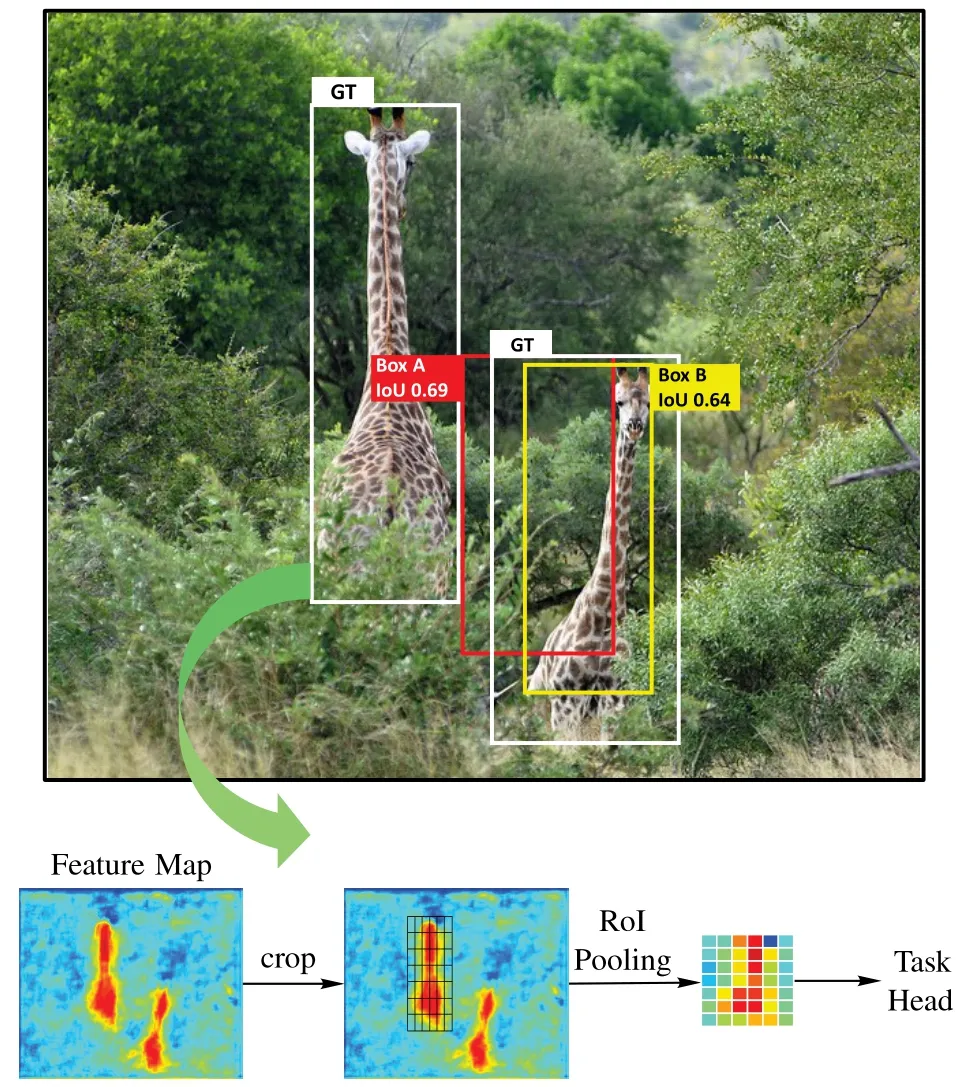
圖1 二階段檢測器檢測過程示意圖Fig.1 Schematic diagram of detection process of two-stage detector
2)為了解決候選區域尺寸各異、數量龐大的問題,Fast R-CNN(Fast Region-based Convolutional Neural Network)[1]首先提出感興趣區域池化(Region of Interest Pooling,RoI Pooling)操作,RoI Pooling 從分辨率不同的輸入特征中獲得固定大小的特征圖來完成后續任務,這一改進極大地提高了二階段檢測器的效率,成為了往后大部分目標檢測器的標配組件。但RoI Pooling 是一種均勻的網格下采樣方法,無論候選區域框是什么形狀,長寬比例多么懸殊,最后都會被采樣成為固定尺寸的、更小的正方形特征圖。在這個過程中,目標的幾何形狀信息會嚴重受損,特征也會發生扭曲變形,這不利于后續子任務的準確完成。
針對上述問題,在傳統Faster R-CNN(Faster Regionbased Convolutional Neural Network)[2]算法基礎上,提出了一個改進的二階段目標檢測框架——Accurate R-CNN。在該框架的實現中,首先提出了有效交并比(Effective IoU,EIoU),它基于越靠近目標中心的包圍框越有效的啟發式認識,以中心度權重衡量有效主要樣本。該判別依據使模型對有效樣本更加敏感。除此之外,本文還提出了一個上下文內容相關的特征重分配模塊(Feature Reassignment Module,FRM)。該組件通過兩種內核編碼水平垂直方向上的孤立遠程關系和全局多尺度上下文,并根據目標的幾何信息對特征進行重編碼,以彌補常規池化方法引起的特征扭曲變形。
本文在微軟多場景通用目標(MS COCO)檢測和實例分割數據集上驗證了模型的性能。在無需額外技巧的情況下,針對目標檢測任務,使用殘差網絡(Residual Network,ResNet)進行驗證,本文實驗采用ResNet50 和ResNet101 作為主干,Accurate R-CNN 相較于Faster R-CNN 的平均精度(Average Precision,AP)提高了1.7 個百分點和1.1 個百分點,顯著地超越了使用同樣骨干網絡的基于掩膜的檢測器。除此之外,在添加掩膜分支后,使用ResNet50 和ResNet101 作為主干,Accurate R-CNN 相較于Mask R-CNN(Mask Regionbased Convolutional Neural Network)的掩膜平均精度(mask Average Precision,mAP)也能提高1.2 個百分點和1.1 個百分點。最后在更小的PASCAL VOC 檢測數據集上進一步驗證了Accurate R-CNN 的檢測效果,Accurate R-CNN 同樣在平均精度上取得了1.4 個百分點的提升,驗證了本文方法的通用性。
1 相關工作
1.1 針對感興趣區域的池化方法
He等[9]通過在卷積層和全連接層之間加入空間金字塔池化結構,對候選框所對應的特征采用金字塔空間池化,提取出固定長度的特征向量,顯著地提高了網絡的訓練速度。RoI Pooling[1]從深度神經網絡提取的特征中獲得的固定大小的特征圖,在顯著地提高了網絡訓練和推理速度的同時,提高了檢測的準確率。RoI Warping Pooling[10]引入了雙線性插值來生成更小的感興趣區域,這使得池化方式對位置信息更加敏感。除此之外,下采樣過程也有了梯度的傳導,采樣結果更加準確。Position-Sensitive RoI Pooling[11]為骨干網絡提取的特征設計了一個位置敏感的分數圖,人工引入位置信息到通道維度,從而有效改善較深的神經網絡對物體位置信息的敏感程度。RoI Align[4]是在Mask R-CNN[4]這篇論文里提出的一種區域特征聚集方式,它很好地解決了ROI 池化操作中兩次量化造成的區域不匹配問題,具體來說,RoI Align取消了原來的量化操作,使用雙線性插值的方法,對坐標為浮點數的像素取周圍的多個近鄰像素計算目標采樣值,從而將整個特征聚集過程轉化為一個連續的操作。Precise RoI Pooling[12]不再有RoI Align中取近鄰像素點數目的參數,也不再涉及量化取整操作,該方法針對整個感興趣區域里的特征圖求積分,采樣點更密集,同時所有的像素值也都有梯度的傳遞。Deformable RoI Pooling[13]首先從感興趣區域中生成池化后的特征圖,然后通過全連接層生成對應感興趣區域采樣點的偏移量,擴大池化范圍。這種可變形池化技術顯著地改善了無人駕駛汽車對魚眼相機中畸變目標的重建模能力[14]。不同于先前的工作,本文關注的不是更密集的采樣點或擴大感興趣區域的池化感受野,而是提出了一個內容相關的特征重分配模塊,它同時考慮目標的孤立區域和全局區域的上下文,對感興趣區域內的特征重新建模,以減少下采樣過程中的目標幾何語義的損失。
1.2 上下文建模方法
上下文建模方法被廣泛地應用于目前最先進的場景分析(或語義分割)方法中。早期用于場景分析的上下文關系建模技術涉及條件隨機場(Conditional Random Field,CRF)[15-16],它們大多是在離散的標簽空間中建模的,而且計算量大。對于連續的特征空間學習,先前的工作使用多尺度特征聚合[17-20]來融合上下文信息,通過多個視野的過濾器或池化操作來融合上下文信息。Chen 等[21-22]通過擴張卷積(Dilated Convolution)融合不同的擴張率特征,以增加網絡的感受野,獲取更多的上下文信息。在后續的改進中[23],作者進一步引入編碼器-解碼器(encoder-decoder)結構,更好地利用骨干網絡提取的低層特征。DenseASPP(Dense Atrous Spatial Pyramid Pooling)[24]使用密集連接的方式將每個擴張卷積的輸出結合到一起,通過一系列的擴張卷積組合級聯,后面的神經元會獲得越來越大的感受野,同時也避免了過大擴張率的卷積導致的卷積退化。除此之外,聚合非局部上下文對模型捕獲長距依賴也很有效,CCNe(tCriss-Cross attention Network)[25]對于每個像素使用一個交叉注意力模塊來獲得其交叉路徑上的上下文信息,并通過一個循環操作,使得每個像素可以捕獲所有像素的長依賴關系。形狀可變上下文算法[26]對于每一個目標像素設置其對應的上下文窗口,利用一個卷積對,計算上下文窗口中所有其他位置的卷積響應與目標像素處的卷積響應之差,根據差的大小確定某位置與目標像素的關聯程度。提高感受野的另一個研究方向是空間金字塔池化[27],通過在每個金字塔級別采用一組具有唯一內核大小的并行池操作,網絡能夠捕獲更大范圍的上下文。在本文的工作中,為了捕獲不同形狀的目標的全局和局部依賴,針對目標的幾何特點設計了對應的內核,最后結合所有幾何特征學習特征圖的變形函數。
1.3 包圍框采樣的改進方法
深度學習中針對包圍框采樣方法的改進主要分兩個方向:第一個方向是從損失函數入手,通過反向傳播間接地突出重要的包圍框。OHEM(Online Hard Example Mining)[28]在訓練的過程中選用損失值最大的前一部分包圍框當作困難樣例,給這些樣例更大的損失權重。聚焦損失函數(Focal Loss)[6]解決了目標檢測中正負樣本比例嚴重失衡的問題,降低了大量簡單負樣本在訓練中所占的權重。第二個方向是在交并比的基礎上,啟發式地選擇合適的預設包圍框。角度加權交并比[29]利用方向信息和包圍框邊的空間位置關系改進訓練集中包圍框的選擇。SCSiamRPN(Strong-Coupled Siamese Region Proposal Network)[30]在原始交并比上添加近似約束,通過在包圍框回歸任務的損失函數中添加以交并比為主變量的加權系數,提高中心樣本的貢獻,進而提升邊框的定位精度。交并比平衡采樣(IoU-balanced sampling)[31]在統計了全部錨框和真值的交并比后,針對負樣本的交并比分布設計了分層抽樣。主要樣本注意力(PrIme Sample Attention,PISA)[32]提出了IoU Hierarchical Local Rank,它既反映了局部的IoU 關系(即每個真值目標周圍的包圍框),又反映了全局的IoU 關系(即覆蓋整個圖像的包圍框)。Dynamic R-CNN(Dynamic Region-based Convolutional Neural Network)[33]根據訓練期間感興趣區域的統計信息自動調整標簽分配標準(IoU閾值),逐步提高正樣本篩選的閾值。Cascade R-CNN(Cascade Regionbased Convolutional Neural Network)[5]級聯不同IOU 閾值來界定正負樣本的輸出,使不同IOU 值檢測與其相對應的IOU 值的目標。不同于之前的工作,本文在IoU 的基礎上提出了一種新的樣本評價標準——有效交并比(EIoU),該標準針對包圍框的幾何特點,根據包圍框的中心度衡量有效主要樣本。
2 本文方法
本文提出的Accurate R-CNN 的整體架構如圖2 所示。本章首先介紹提出的有效交并比,該評價標準應用于錨框初始化和非極大值抑制中,可以使網絡獲得更準確的有效樣本,學習到更準確的目標特征。然后,介紹提出的特征重分配模塊,該模塊在檢測網絡中放置于感興趣區域池化操作之前,可以根據局部和全局上下文學習一種內容相關的特征變形方法,有效地緩解常規池化導致的特征損失。最后,介紹整個網絡的結構和一些實現細節。
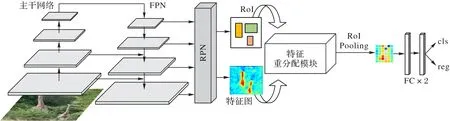
圖2 Accurate R-CNN示意圖Fig.2 Schematic diagram of Accurate R-CNN
2.1 有效交并比(EIoU)
交并比作為相似程度的度量,是判斷包圍框準確與否的關鍵指標,無論是在感興趣區域篩選,還是非極大值抑制中,交并比都是判斷一個包圍框的位置質量的第一標準。由于原始交并比的設計缺陷,一些對檢測很重要的包圍框被視為冗余而被剔除了。針對第1 章提出的假設,即使交并比值相等,在目標內的包圍框應該比在目標外的包圍框更重要。受到FCOS(Fully Convolutional One-Stage object detection)[8]的 啟發,本文使用“中心度”來衡量一個包圍框在目標內的程度,中心度通常用來表示包圍框的中心到目標的真值包圍框的中心的標準化距離。EIoU 啟發式地認為,更靠近真值包圍框中心的錨框,可能包含更多的有效目標,應當被認為更重要。

最后使用中心度權重修正原始交并比值得到EIoU:

其中:IoU為包圍框B和真值框的交并比值。可以在圖3 中看到,使用中心度權重校正包圍框的交并比之后,靠近目標內部的包圍框得分更高。

圖3 EIoU的中心度權重示意圖Fig.3 Schematic diagram of centrality weight of EIoU
2.2 特征重分配模塊(FRM)
針對不同目標,感興趣區域池化操作無差別地將其下采樣成正方形。但由于目標的形狀各不相同,特征圖的長寬比例也沒有固定的關系,在這個過程中,特征可避免地會因為變形而損失一些幾何特點。為了解決這個問題,本文設計了一個可學習的特征重分配模塊,它根據目標的全局上下文和幾何結構特點對像素位置進行重分配,以彌補下采樣過程中的特征損失。
如圖4 所示,提出的特征重分配模塊以特征金字塔網絡(Feature Pyramid Networks,FPN)[3]提取的目標的分層特征為輸入,由分別捕獲不同位置之間短距離和長距離依賴關系的兩種內核組成。對于一個通道數為C、高為H、寬為W的輸入特征圖F,首先使用降維卷積壓縮輸入特征圖的通道數。對于長距離依賴,使用水平和垂直的條帶池化操作來捕獲窄特征,這種條帶池化操作使分散在整個場景中的區域之間的連接成為可能。對于語義區域分布緊密的情況,使用輕量級的金字塔池化模塊[27]來獲取局部上下文信息,并在每個池化層后面接一個3×3的卷積使捕獲到的上下文更加精準。該金字塔池化模塊總共包含兩個后接卷積層的自適應池化層,和一個用于保存原始空間信息的二維卷積層,其中兩個自適應池化層的池化因子設置為2×2 和5×5。最后通過連接操作將所有子路徑合并,得到特征最終的幾何編碼信息稱之為Fc。
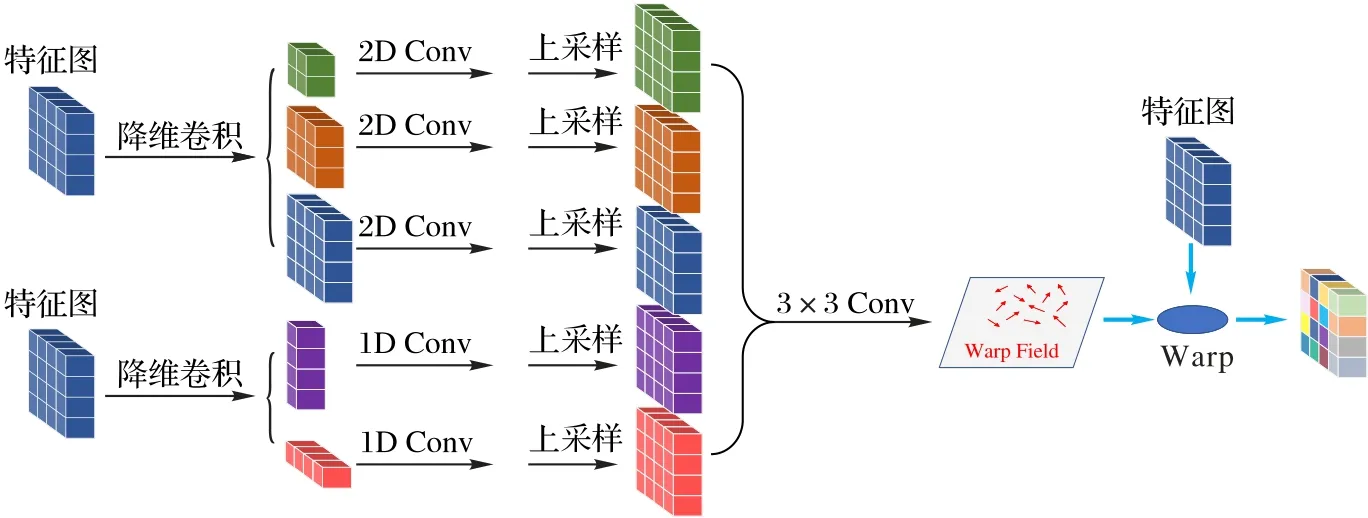
圖4 特征重分配模塊示意圖Fig.4 Schematic diagram of feature reassignment module
接下來根據目標的幾何編碼信息重分配目標特征,以抵消感興趣區域池化操作引起的特征損失和變形。具體來說,對于輸入特征圖F,首先根據其幾何編碼信息Fc來學習特征圖上每一個像素點在水平和垂直方向上的移動量δ∈R2×H×W,這個過程定義如下:

其中:conv1(?)是一個輸出通道為2的3×3卷積。定義特征圖F上的像素的初始位置為p,則該位置的像素值可寫為F(p),將歸一化后的位置移動量δ(p)加到p上,得到該位置元素的新位置p*為:

其中:H和W表示感興趣區域特征圖的高和寬。
為了解決浮點偏移引起的量化問題,采用雙線性機制確定采樣值,該機制以采樣點最近鄰的四個像素的值來近似輸出,該過程有如下定義:

其中:N(p)表示位置p的像素周圍最近的四個像素點;wP表示根據每個鄰近像素和p的距離計算得到雙線性核權重。對所有像素應用上述變形函數得到其對應的重分配位置,并將重分配的特征圖作為后續RoI池化的輸入。
2.3 網絡的整體架構
網絡的整體結構如圖2 所示,把錨框生成階段和RPN(Region Proposal Network)的NMS 階段中的IoU 判別標準替換為EIoU。除此之外,為了降低特征金字塔的相鄰特征層在合并時存在的語義鴻溝,在FPN的每組相鄰特征之間,對上采樣后的較粗糙分辨率的特征圖應用一個3×3的可變形卷積網絡(Deformable Convolution Network,DCN)[13]。
檢測網絡的分類任務損失函數為:

其中:CE(Pi,Gi)表示交叉熵損失函數,即單一樣本分類損失。對于真值標簽為Gi,預測標簽為Pi的候選框i,其交叉熵損失函數計算如下:
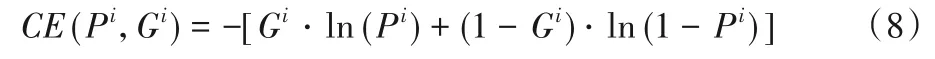
邊框回歸任務的損失函數如下所示:
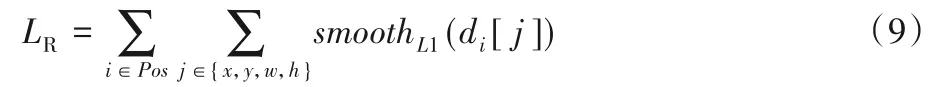
其中:smoothL1(di[j])表示smooth L1 損失函數;di為樣本i對應的某一個邊框的預測值與正則化之后的真值的差(包括邊框的中心橫縱坐標x和y,邊框的寬w和高h);Pos表示正樣本。其中smooth L1損失函數的計算方法如下:
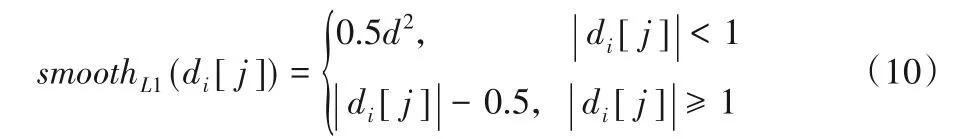
總的損失函數的形式如下:

其中:Gi*在對應錨框為陽性時設置為1,否則設置為0。
3 實驗與結果分析
3.1 數據集和評價指標
本文在兩個公開數據集上進行了實驗:
第一個是包含80 個類別的MS COCO 目標檢測數據集和實例分割數據集。MS COCO 包含118 287 張用于訓練的圖像(train2017),5 000 張用于驗證的圖像(val2017)和20 000 張用于測試的圖像(test-dev)。其中test-dev數據集沒有公開標簽,因此在MS COCO 官方服務器上測評test-dev 并匯報測試集的結果,使用val2017數據集匯報消融實驗的結果。匯報的結果都遵循MS COCO 標準的平均精度(AP)指標,其中AP50表示使用IoU 閾值0.5 來確定預測的包圍框或者掩膜在評估中是否為陽性,AP75同理。APS表示面積小于32×32個像素的目標的平均精度值,APM表示面積在32×32個像素到96×96個像素之間的目標的平均精度值,APL表示面積大于96×96個像素的目標的平均精度值。后面不帶閾值表示的AP,指IoU 以0.50到0.95區間內每隔0.05作為閾值時的平均結果。
第二個數據集是包含20 個類別的PASCAL VOC 目標檢測數據集,其中有用于訓練的12 000 張(VOC2007+VOC2012)圖像和用于驗證的5 000張(VOC2007)圖像,在VOC驗證數據集上報告的結果遵循VOC style的平均精度指標。
3.2 實驗細節
本文中所有實驗都是基于MMDetection[34]實現的。為了公平起見,本文使用該檢測庫重新實現了所有被對比的基線方法,值得注意的是重新實現的基線方法的效果比原始論文提高了超過1 個百分點。本文使用2 個NVIDIA GeForce RTX TITAN GPU 訓練,該顯卡內存為24 GB。對于COCO 數據集,輸入圖像的大小被等比例縮放到短邊為800 像素的尺寸,將每個GPU的批處理大小設置為8;對于VOC數據集,輸入圖像的大小被等比例縮放到短邊為600 像素的尺寸,將每個GPU的批處理大小設置為16。在兩個數據集上初始學習率均設為0.02,總共訓練12 輪,在第8 和第11 輪以0.1 的比率下降學習率。所有實驗使用設置動量的隨機梯度下降(Stochastic Gradient Descent,SGD)優化器訓練,動量設置為0.9。
3.3 主要結果
在COCO test-dev 數據集上評估了本文提出的Accurate R-CNN,并與其他最先進的二級檢測器進行比較。所有結果見表1。
針對目標檢測任務,當使用ResNet50 作為骨干網絡時,提出的Accurate R-CNN 的AP比基于ResNet50 的Faster R-CNN 提高了1.7 個百分點。當使用ResNet101 作為骨干網絡時,提出的Accurate R-CNN 比基于ResNet101 的Faster RCNN 提高了1.1 個百分點。針對實例分割任務,當在Accurate R-CNN 中添加了掩膜分支后,如表1 所示,使用ResNet50 作為骨干網絡時,Accurate R-CNN 的AP相比Mask RCNN(Mask Region-based CNN)在包圍框質量上提高了1.5個百分點,在掩膜質量上提高了1.2 個百分點。當使用ResNet101 作為骨干網絡時,Accurate R-CNN 相比Mask RCNN,包圍框質量提高了1.2個百分點,掩膜質量提高了1.1個百分點。這充分說明了該方法在不同任務上的通用性。

表1 在COCO tes-dev數據集上的檢測結果Tab.1 Detection results on COCO test-dev dataset
本文還在PASCAL VOC 的驗證數據集上測試了Accurate R-CNN 的性能,如表2 所示:當使用ResNet50 作為骨干網絡時,檢測性能提高了1.4 個百分點;當使用ResNet101 作為骨干網絡時,檢測性能提高了1.4個百分點。在圖5中可視化了和基線方法相比每一類上的檢測效果,可以看到Accurate R-CNN幾乎對全部類別的檢測都有提升。
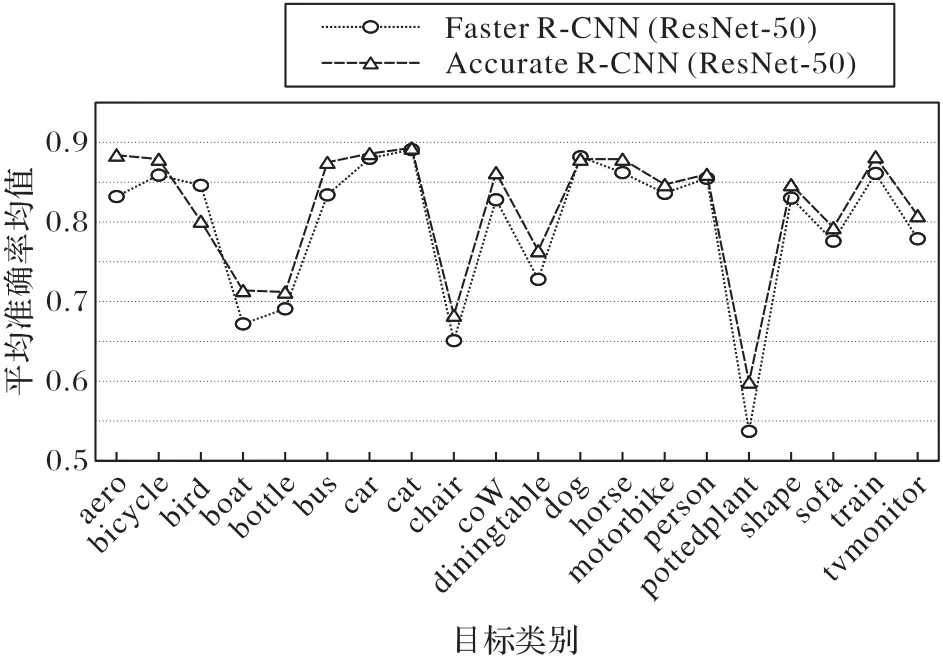
圖5 PASCAL VOC測試集上的檢測表現Fig.5 Detection performance on PASCAL VOC test set
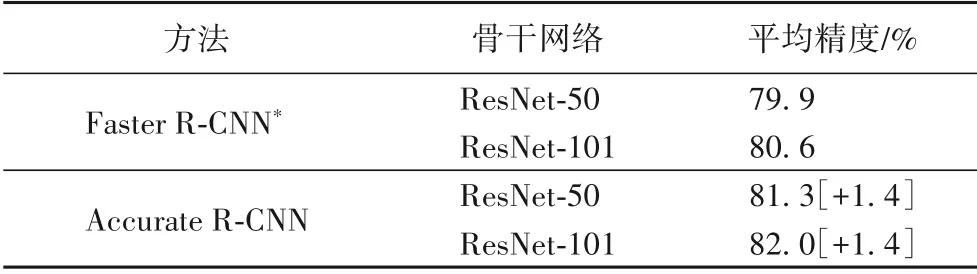
表2 在PASCAL VOC數據集上的檢測結果Tab.2 Detection results on PASCAL VOC dataset
由圖6(a)和圖6(b)可知,在MS COCO 數據集上,針對目標檢測的回歸和分類任務,本文方法可以穩定地降低訓練過程中的損失函數,使檢測目標逐漸精準。除此之外,在圖6(c)和圖6(d)中可以觀察到,和基線方法Faster R-CNN 相比,Accurate R-CNN 可以在相同的迭代次數下更快地提升包圍框的準確性。當添加了掩膜分支后,和基線方法Mask R-CNN相比,Mask Accurate R-CNN具備更快更好的掩膜分割性能。
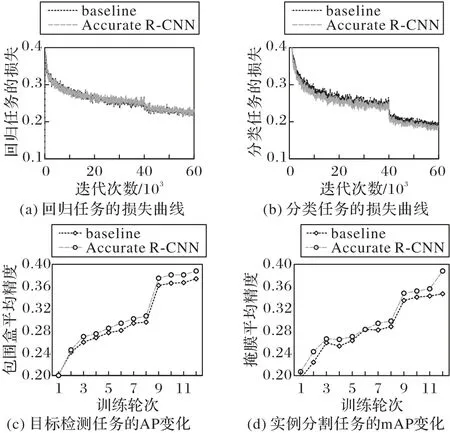
圖6 訓練過程中的損失和精度變化Fig.6 Loss and accuracy change in training process
3.4 消融研究
通過一定的消融實驗來分析本文方法,結果如表3 所示。首先對每個單獨改進的效果進行了實驗驗證,然后對不同組件組合后的改進效果進行分析。
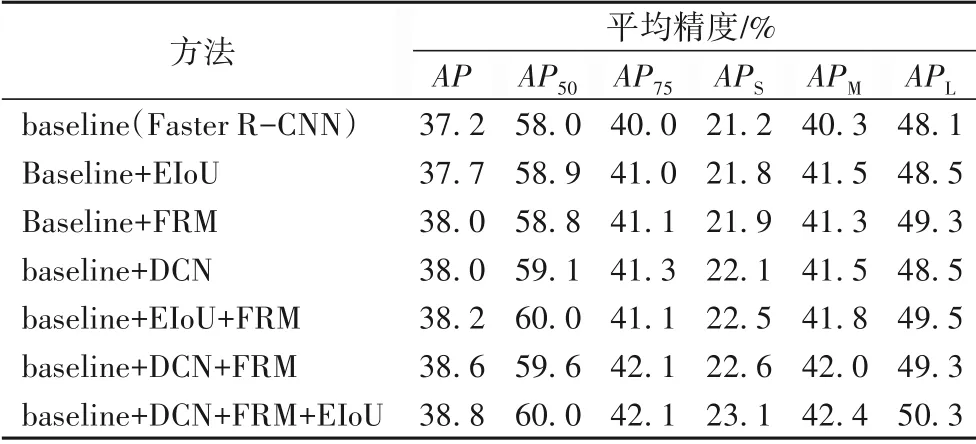
表3 在COCO val數據集上基于ResNet-50骨干網絡的消融研究結果Tab.3 Ablation study results based on ResNet-50 backbone network on COCO val dataset
在使用EIoU 來代替原來的包圍框評價標準IoU 之后,平均精度提高了0.5 個百分點,雖然提升幅度有限,但AP75和APM均提升了超過1個百分點,這說明對于中等大小尺寸的目標,包圍框混淆現象是很容易發生的。由于缺乏完全貼合的預設包圍框,模型會在真值包圍框的附近選擇部分次優包圍框,EIoU有利于過濾掉質量低的次優包圍框。
在將FRM 單獨添加到基線檢測器中時,模型取得了0.8個百分點的提升,其中大部分指標的提升超過1 個百分點,無論是大目標還是小目標,均受益于FRM 優秀的特征建模能力。這說明FRM 有效地避免了不同形狀的目標因為下采樣池化而導致的特征畸變。
在特征金字塔的相鄰特征層之間添加DCN 后,可以看到平均精度提升了0.8個百分點,其中AP50、AP75均取得了超過1個百分點的提升。這說明特征金字塔的相鄰特征層間是存在語義鴻溝的,直接將其放大并相加不夠準確。可變形卷積在卷積核中引入偏移量,有效地緩解了特征合并過程中的語義差異,使特征金字塔構建的分層特征更加準確。
當在基線方法中插入提出的FRM,并將IoU 替換為EIoU時,相較于基線方法取得了1.0 個百分點的提升。當在特征金字塔中添加可變形卷積,并在感興趣區域池化之前插入提出的FRM時,相較于基線方法取得了1.4個百分點的提升,其中AP75取得了超過2 個百分點的提升。當將全部組件添加到基線模型時,可以達到38.8%的平均精度,相較于基線方法取得了1.6個百分點的提升。
3.5 結果可視化
在MS COCO 數據集中隨機選擇了3 000 張圖片用于檢測結果對比,骨干網絡為ResNet50,設置檢出分數閾值為0.5。在全部檢測結果中挑選了10 對有代表性的對比結果進行可視化,基線方法(Faster R-CNN)和本文方法(Accurate R-CNN with ResNet50)的檢測效果如圖7 所示。從圖7 可看出:本文方法Accurate R-CNN針對尺度差異大的目標具有更高的檢出率,針對尺寸較大的目標檢測到的邊框也更加準確。

圖7 包圍框檢測效果對比(ResNet50)Fig.7 Comparison of bounding box detection effect(ResNet50)
本文方法Accurate R-CNN在實例分割任務上同樣表現出了較好的性能。針對添加了掩膜分支的Accurate R-CNN,檢測效果如圖8 所示。從圖8 可看出:對于長寬相差懸殊(如長凳、列車、提包)和由于遮擋而損失特征(如皮椅、紙杯)的兩類目標,帶掩膜分支的本文方法Accurate R-CNN 比基線方法均實現了更高的檢出率和更準確的掩膜分割結果。

圖8 掩膜檢測效果對比Fig.8 Comparison of mask detection effect
4 結語
本文從所選區域樣本是否具有代表性和輸入任務網絡的視覺特征是否準確兩方面分析了基于深度學習的二階段檢測器的設計缺陷。針對該缺陷,在Faster R-CNN 的基礎上作出了幾個改進使檢測效果會更加準確。具體來說,本文提出了名為Accurate R-CNN 的二階段檢測器,通過有效交并比EIoU和特征重分配模塊FRM 兩個簡單的組成部分,Accurate RCNN 可以在MS COCO 和PASCAL VOC 兩個數據集上顯著地改善基線方法。目前,本文提出的特征重分配模塊雖然可以方便地插入到大部分二階段檢測方法中,但對于不使用感興趣區域池化操作的單階段檢測器來說尚不適用,后續研究將考慮把特征重分配的思想應用到單階段檢測器中。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
