基于DCDAE-BiLSTM 模型的轉轍機故障診斷方法研究
2021-09-18 00:46:56劉可興黃海于
鐵道通信信號 2021年8期
劉可興,黃海于
在地鐵運營信號系統中,當列車遇到分叉路口時,需通過扳動道岔來選擇不同路線,因此轉轍機的控制和維護極其重要,其動作的正常與否直接影響地鐵行車安全。由于轉轍機機械結構復雜,且處于室外,容易受外界環境的影響,據統計在信號設備發生的故障中,轉轍機故障約占信號故障總數的30%[1],故障率較高。
近年來,國內外學者對道岔轉轍機的故障診斷做了許多研究,如:劉新發等[2]以道岔轉轍機的功率數據作為輸入,提取不同故障模式下的特征矩陣,采用模糊聚類算法,從上述特征矩陣中求解模糊等價矩陣,并將其轉變為布爾矩陣,得到動態聚類圖后完成故障診斷;LEE 等[3]利用所采集的轉轍機音頻數據作為提取特征,采用聲學分析法對轉轍機進行故障診斷,試驗證明該方法具有較高的準確率;黃世澤等[4]總結不同轉轍機故障的功率曲線特點,采用基于弗雷歇距離定義的相似函數完成故障診斷。上述方法主要是依靠人工提取故障信號特征,但道岔轉轍機結構復雜,影響因素繁多,導致相同故障模式下信號有不同的表現形式,所以很難提取到有效特征,造成這些算法在實際情況下泛化能力不強。
隨著深度學習的發展,非線性函數自動映射能力已廣泛應用于故障診斷領域,如:唐維華等[5]構建了LSTM 網絡形成道岔故障,但需要大量有標簽數據集進行訓練;陳欣昌等[6]構建了深度自編碼器模型,實現機械故障診斷,通過試驗驗證方法有效;薛嫣等[7]通過對故障信號提取時頻域以及熵特征,構建堆疊稀疏自編碼網絡模型進行訓練,來提高故障診斷準確率,但自編碼網絡在特征提取階段,僅僅是無監督地對原始輸入數據進行重構,無法保證所提取的抽象特征與所識別的故障類型的關聯性;習晨博等[8]采用堆疊去噪自動編碼器與BP 神經網絡相結合的方法,試驗證明準確率更高;徐子弘等[9]采用自編碼器提取不同故障信號的高階抽象特征,并將該特征作為其他分類器的輸入,完成了早期的故障診斷。
基于以上研究,本文以S700K 型道岔轉轍機作為研究對象,應用深度學習技術,對信號集中監測系統中所收集的功率數據進行分析,利用深度卷積降噪自編碼器與循環神經網絡相結合的方法,完成轉轍機故障診斷。此外,由于自編碼器中的隱藏層采用全連接神經神經網絡,訓練時間復雜度偏高,而卷積神經網絡因其權值共享等特點,訓練時間復雜度較低,因此將自編碼器改進為一維卷積神經網絡,經試驗證明該方法可以進一步提高準確率。
1 道岔轉轍機工作原理及故障類型
S700K型道岔轉轍機三相交流電動機的工作拉力為
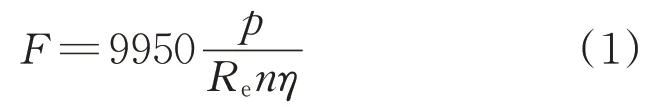
式中:η為電動機效率;Re為轉轍機傳動系統等效力臂;p為輸出功率;n為電動機轉速。
由式(1)可得,S700K 轉轍機的動力與其功率呈線性關系,功率值的改變反映了工作拉力的變化,所以轉轍機的運行情況可以通過其輸出工作拉力的變化表示[10]。據此,本文選取功率數據作為研究對象,通過研究轉轍機正常功率數據和不同故障模式下的功率數據,完成S700K 型道岔轉轍機的故障診斷。
2 故障診斷方法設計
通過對SDAE-BiLSTM 算法的堆疊式降噪自編碼網絡結構進行改進,提出了深度卷積降噪自編碼器——雙向長短期記憶網絡DCDAE-BiLSTM(Deep Convolutional denoised autoencoder and Bidirectional Long Short-Term Memory)算法,用于對轉轍機的故障診斷,具體流程見圖1。該方法主要包含:①數據預處理,由于一次道岔動作在不同的階段,其功率數據值差異較大,因此需先對功率數據進行歸一化,便于不同量級的功率能夠進行計算;②DCDAE 網絡預訓練,對大量數據進行自監督學習,復用編碼層參數后,進入下一階段的分類任務;③BiLSTM 網絡微調,當上述自編碼器訓練完成后,將BiLSTM 網絡接入到卷積自編碼器編碼層,開始訓練帶有標簽的數據集,最終完成故障診斷。
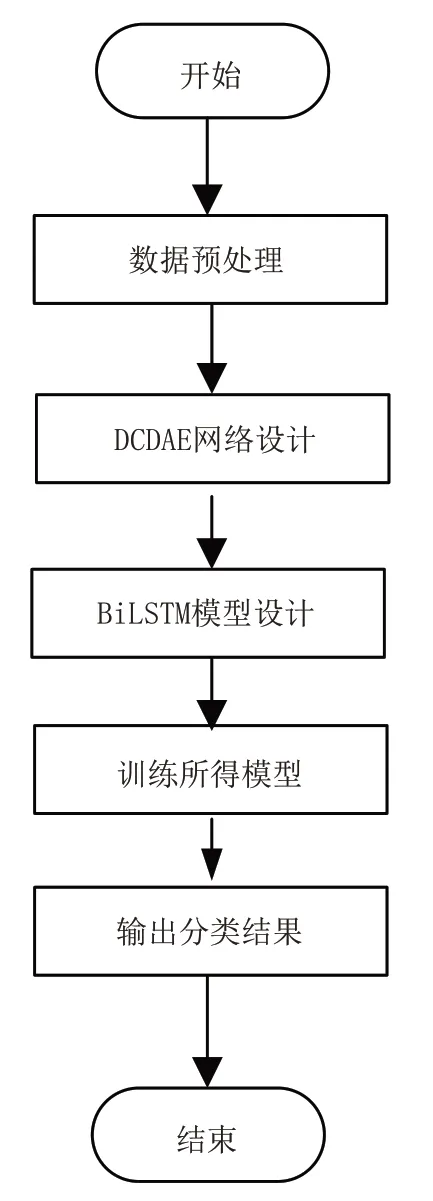
圖1 診斷流程圖
2.1 數據預處理
數據歸一化方法主要分為線性函數歸一化(Min-Max Scaling) 和零均值歸一化 (Z-score standardization),本文采用線性函數歸一化方法,具體計算公式為
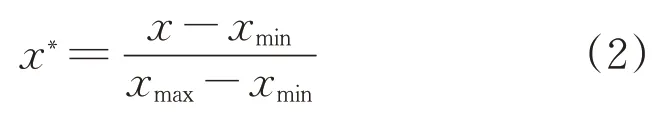
式(2) 將訓練數據和測試數據歸一化到[0,1]區間內,然后把歸一化后的數據作為自編碼器模型的輸入,先進行無監督深層特征提取,再開始微調整個網絡。
2.2 DCDAE深度卷積降噪自編碼器網絡設計
傳統深度降噪自編碼器見圖2,包括編碼層和解碼層[11]。其中降噪主要是對輸入數據加入噪聲,模擬數據被損壞的情況,從損壞的數據中重構出原始數據,提高模型的魯棒性。
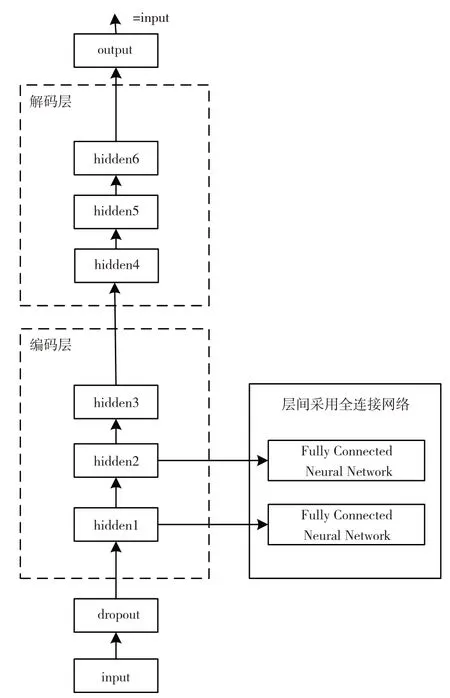
圖2 深度降噪自編碼結構示意圖
傳統自編碼器的隱藏層采用全連接神經網絡,雖然有一定的特征提取能力,但因參數較多,訓練復雜;而卷積神經網絡具有局部鏈接、權值共享等優點,減少了訓練參數,因此本文將傳統自編碼器中的隱藏層改為一維卷積神經網絡,見圖3。卷積自編碼器編碼網絡與解碼網絡具體參數見表1。將上述編碼網絡的最后一層(max_pool 層),通過ReShape 操作改變其維度為(1,396)后,作為BiLSTM網絡的輸入。
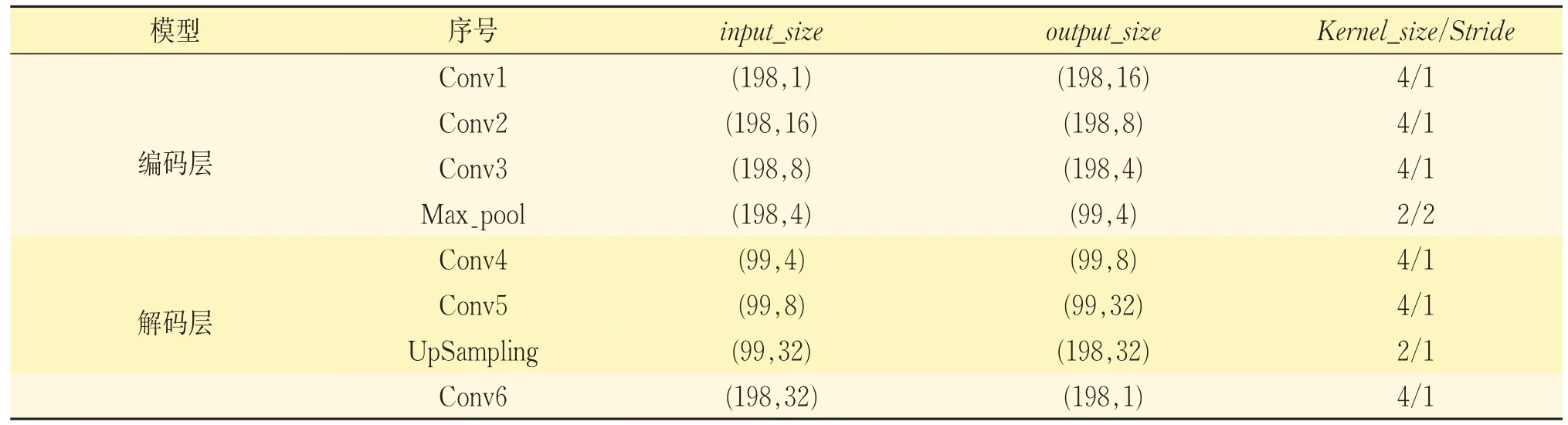
表1 卷積自編碼器網絡模型結構參數
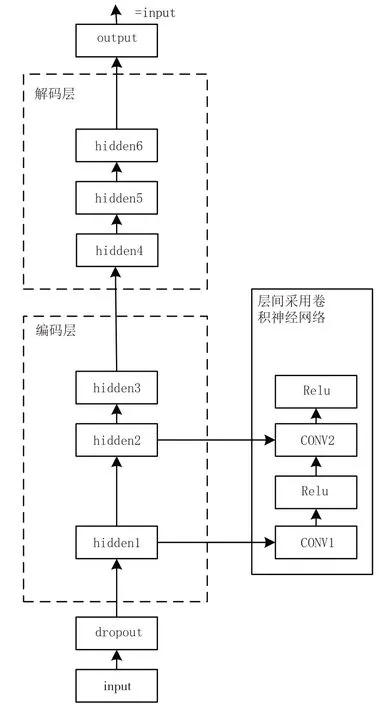
圖3 深度卷積降噪自編碼結構示意圖
2.3 循環神經網絡設計
LSTM 神經網絡核心單元見圖4。其中,xt表示t時刻的輸入序列,Ct表示第t時刻的記憶單元,ht表示t時刻LSTM 神經網絡細胞的輸出值,ft、it、Ot分別表示遺忘門、輸入門以及輸出門的值,具體計算方式如下。
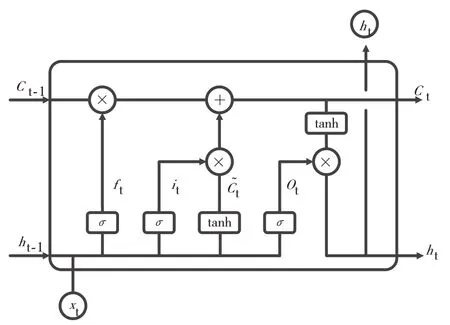
圖4 LSTM 核心單元結構
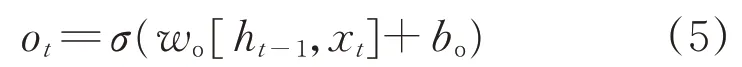
式中wf、wi以及wo表示遺傳門、輸入門、輸出門的權重,bf、bi、bo分別表示各個門的偏置。
由于反映轉轍機工作狀態的功率曲線下一階段的動作緊挨著上一階段,具有時序性,因此將上述自編碼器所提取的特征作為循環神經網絡的輸入,最終完成故障診斷,具體的網絡結構設計見表2。

表2 Bi LSTM 網絡模型結構
3 試驗分析
3.1 試驗數據集及評價指標
真實數據及模擬數據共同組成模型訓練測試數據,其中訓練集數量總共為3 600 個,每種類型各600 個;測試數量總共為1 200 個,每種類型各200個。
為了評估本文所提算法的性能,采用準確率、精確率、誤報率、漏報率以及ROC 曲線等指標進行驗證,其中各指標計算公式如下:
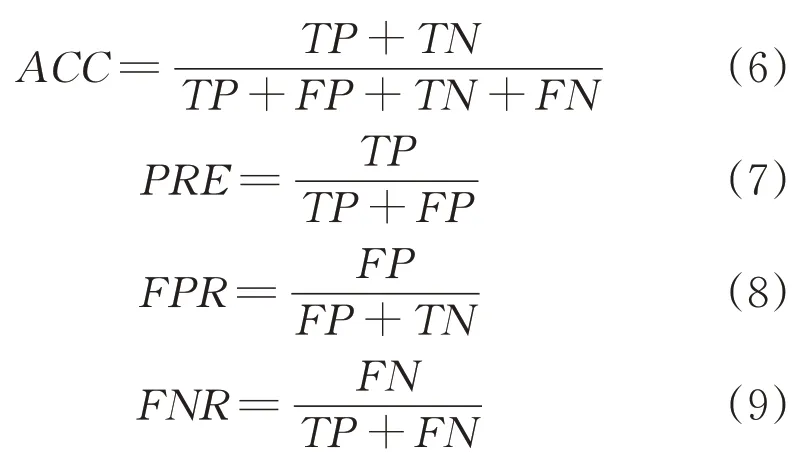
式中:ACC為測試準確率;TP表示實際為正類別,預測為正類別;FN表示實際為正類別,預測為負類別;TN表示實際為負類別,預測為負類別;FP表示實際為負類別,預測為正類別。ROC曲線為接受者操作特性曲線(Receiver Operating Characteristic Curve ROC),ROC 曲線的橫坐標是FPR,縱坐標是TPR,表示將正樣本預測為正的比例,ROC 曲線與橫縱坐標封閉的區域面積稱為AUC(Area under roc Curve),面積越大,表示模型越好。
3.2 試驗環境及參數設置
在確定網絡結構基礎上,為了使試驗結果的差異來自不同的神經網絡模型,設置了同樣的超參數,包括優化器使用Ndam 算法,訓練批次大小32,學習率設置為0.001,epoch設置為200時。對輸入采用dropout 降噪方式,本文比例設置為0.1,最后在Win10 64 位環境下試驗,并采用keras 3.6版本的深度學習框架。
3.3 試驗結果
1)基于DCDAE_BiLSTM 模型的故障診斷試驗結果。本課題采用預訓練階段和微調階段訓練策略,即先將預訓練的深度卷積降噪自編碼器模型,作為微調階段編碼網絡的初始化參數;然后加入雙向循環神經網絡,開始微調整個分類網絡,圖5 表示訓練準確率ACC曲線。其中ACC表示樣本被正確分類的個數占總樣本個數的比例,可以看到本文最終準確率達到了98.82%,為了更加細致地觀察試驗結果,畫出如圖6 所示的ROC 曲線,該曲線中有每一類別的AUC值,即為圖中area 值所示,而表3為每類的精確率等指標。
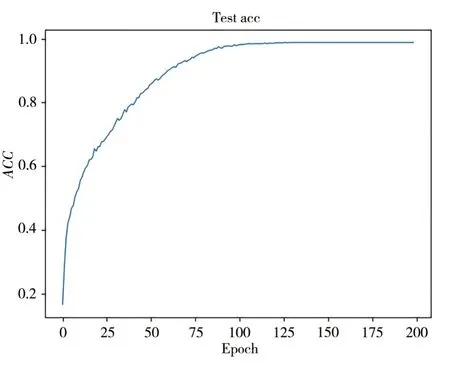
圖5 測試準確率
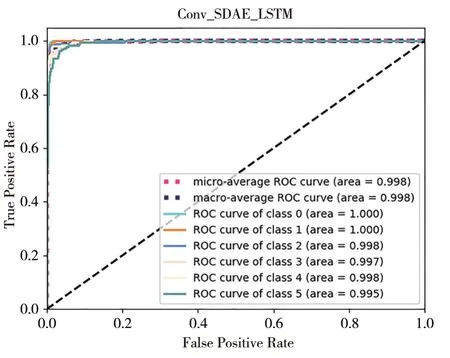
圖6 ROC曲線
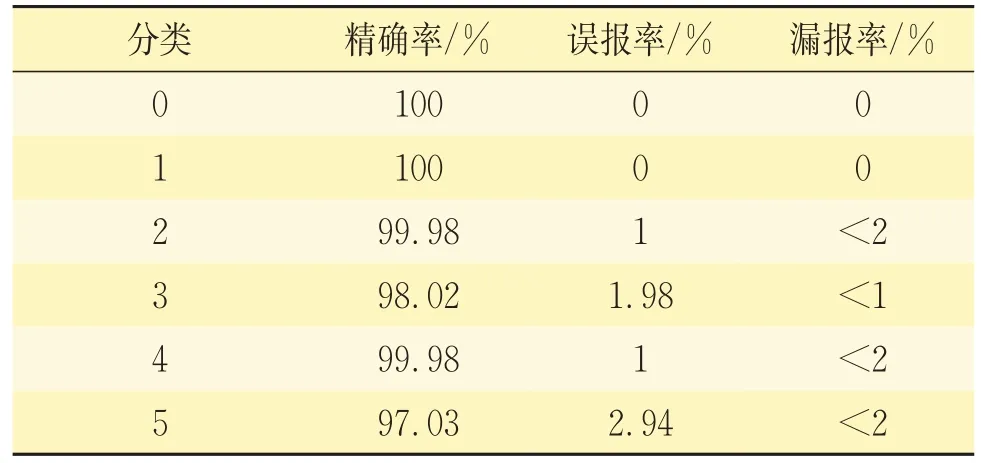
表3 分類試驗結果
2)與其他算法的對比。隨著對道岔轉轍機故障診斷的大量研究,已出現了許多不錯的研究成果,如文獻[13]中構建了多層CNN 模型來完成轉轍機故障診斷,文獻[14]采用CNN-GRU 聯合神經網絡的方法來完成故障診斷等。此外,為了驗證本文所提算法的有效性,還搭建了SDAEBiLSTM模型來作為對比。
幾種算法進行比較的試驗結果見表4。采用多層CNN 模型時,其準確率95.14%,誤報率4.26%,漏報率4.83%;采用CNN-GRU 模型時,其故障診斷的準確率為95.85%,誤報率為3.06%,漏報率為3.17%;而采用SDAE-BiLSTM 模型,其故障診斷的正確率為97.16%,誤報率為1.87%,漏報率為2.99%。相比于上述算法,本文所提的模型故障診斷正確率更高。
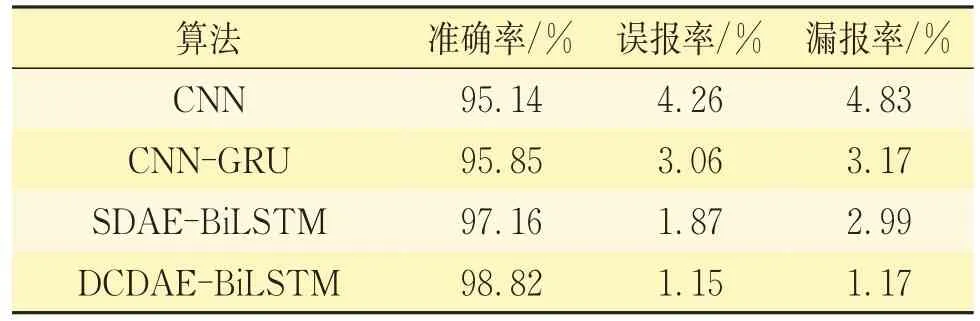
表4 算法對比結果
4 結語
通過分析S700K 型道岔轉轍機故障功率數據,總結歸納出需要診斷的故障類型,在此基礎上,提出深度卷積降噪自編碼器與雙向長短期記憶網絡相結合(DCDAE-BiLSTM)的方法,完成轉轍機故障診斷,試驗結果表明該算法的準確率可達到98.82%。相比于其他算法,該算法具有更高的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
