基于網絡搜索數據的經濟總量預測研究
2021-09-18 04:15:12李宜軒山東工商學院統計學院
環球市場 2021年27期
李宜軒 山東工商學院統計學院
一、緒論
隨著我國網民數量不斷增加,網絡包含的信息也得到倍數的增長,而當前的研究熱點就是如何挖掘出互聯網所蘊含的信息。2019年全球貿易擴張趨弱、中美貿易摩擦不斷升級,以及突如其來的新冠肺炎病毒(Covid-2019)全球大爆發都對2020年中國經濟增長帶來了較大負面沖擊。目前國內外復雜的經濟形勢加大了預測GDP的難度,因此,如何有效地預測GDP是值得研究的重要理論與現實問題。
在利用網絡搜索數據進行經濟研究方面,Ettredge(2005)很早利用網絡搜索數據對美國的失業率進行預測[1]。Thomas B.G?tz,Thomas A.Knetsch(2019)等利用谷歌網絡搜索數據結合偏最小二乘法、LASSO方法等選擇指標加入傳統的橋梁方程模型(Bridge Equation Models)預測德國的GDP[2]。Robin F.Niesert,Jochem A.Oorschot,Christian P.Veldhuisen(2020)利用Google搜索數據來預測美國,英國,加拿大,德國和日本的失業率,CPI和消費者信心指數[3]。劉濤雄,徐曉飛(2015)應用網絡搜索數據使用“兩步法”以及單方程線性模型對GDP進行了預測[4]。在宏觀經濟研究方面,仝冰(2010)利用中國數據,建立了一個中等規模的動態隨機一般均衡(DSGE)模型,主要宏觀經濟變量進行預測[5]。劉漢,劉金全(2011)利用混合數據抽樣模型(MIDAS)對我國季度GDP進行了預報和預測[6]。袁靖(2014)基于VAR模型,在貝葉斯推斷下,深入分析推導了FAVAR、TVP-VAR和TVP-FAVAR模型的狀態空間形式,引入了因子分析思想和時變參數特征,解決了待估參數過多降低模型維度問題,并且預測能力逐步顯著改善[7]。這為本文的研究提供了思路,將在前人研究的基礎上繼續改進和探究。
二、主成分回歸模型的方法步驟
(一)對原始數據進行標準化

(二)計算相關系數矩陣
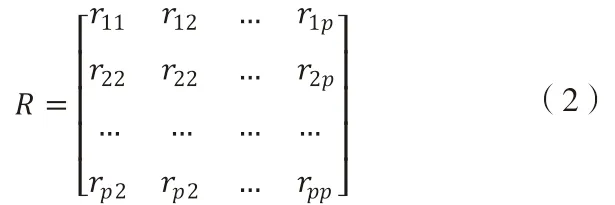
rij(i,j=1,2,…,p)為原變量xi與xj的相關性系數,rij=rji,其計算公式為
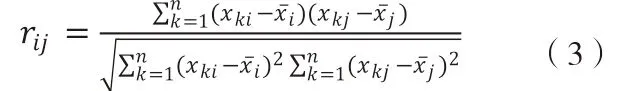
(三)計算特征值與特征向量
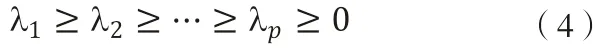
(四)計算主成分貢獻率及累計貢獻率
(1)貢獻率:
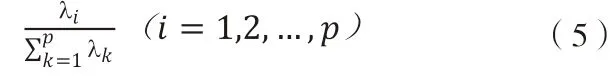
(2)累計貢獻率:
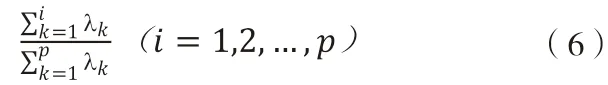
(五)采用普通最小二乘法,對主成分進行回歸
做前m個主成分F1,F2,…,Fp對因變量的多元線性回歸,得到回歸模型
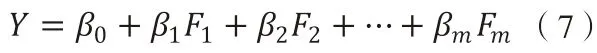
(六)轉化為自變量的線性組合
由于每個主成分F1,F2,…,Fp均是自變量X1,X2,…,Xp的線性組合,因此,經過轉化可得最終線性回歸模型
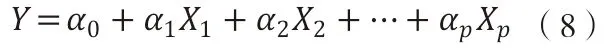
三、指標數據來源及數據處理
本研究的預測變量為GDP,解釋變量分為兩類。一類為政府統計指標,屬于結構化數據。本文的結構化數據選取了12個與宏觀經濟緊密相關的指標,將沿用其所選的指標,數據來源于2011-2019年中華人民共和國統計局網站的政府統計月度數據,包括消費價格指數、社會消費品零售總額等,經過整理、計算成季度數據(樣本的統計特征見表1)。為消除異方差的影響,對出口總值、進口總值、外商直接投資、社會消費品零售總額、國家財政收入、流通中現金、貨幣和準貨幣變量取自然對數。
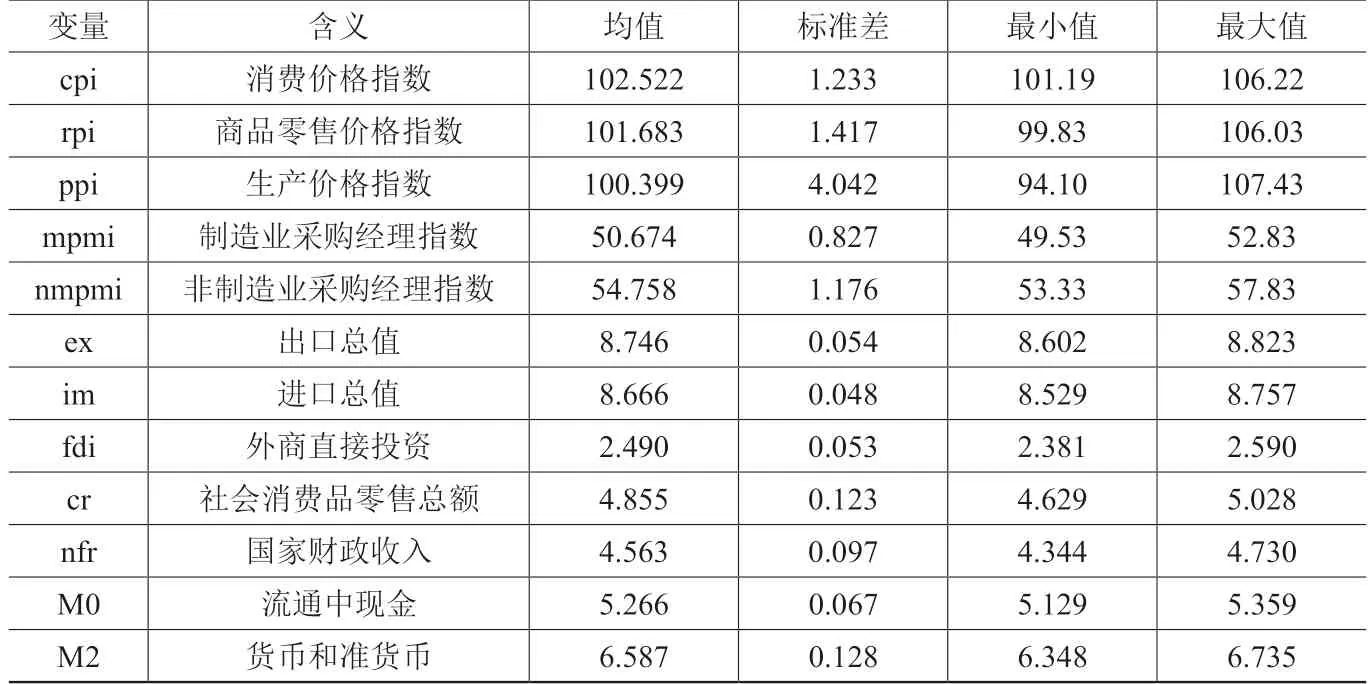
表1 政府統計指標樣本的統計特征
另一類解釋變量來源于互聯網搜索行為,為2015-2019年的百度指數網站的相關關鍵詞的百度指數。經過初步篩選,確定對外貿易、環境等125個關鍵詞。通過進一步將這些關鍵詞的搜索指數與季度GDP數據進行詞向量技術分析,剔除掉一些相關性較小的關鍵詞,并結合經濟邏輯的基礎上最終保留了85個關鍵詞。將此85個百度搜索指數分成五類,根據GDP的構成和宏觀經濟增長的主要決定因素,這五類分別為:消費、投資、進出口、資本和技術創新。除此之外,考慮到宏觀經濟增長也受政策和環境的影響,本文也將經濟政策不確定性指數(EPU)作為一個重要變量。
四、季度GDP的預測及預測結果進行比較
本研究全部數據為2011年第一季度至2020年第四季度共40期,把2011年第一季度至2019年第四季度共36期作為訓練集;預測集分為樣本內預測集和樣本外預測集,共8期。本文分別建立兩個主成分回歸模型,模型一為僅有政府統計數據的回歸模型,模型二是在模型一的基礎上加入了經濟政策不確定性指數和網絡搜索指數的回歸模型,運用模型一和模型二分別對變量做回歸和預測,并計算出兩種模型的相對誤差,結果由圖1展示。
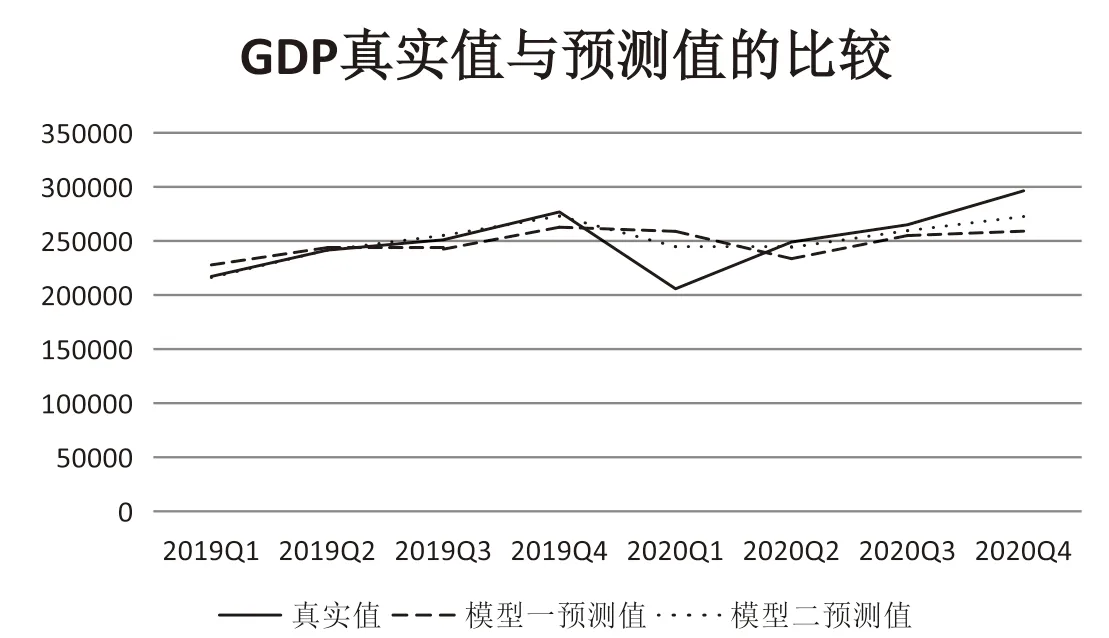
圖1 兩種模型結果與真實值的比較
由表2可知,無論是樣本內預測還是樣本外預測,加入互聯網搜索數據和經濟政策不定性指數后的預測誤差都遠小于用政府數據預測的季度GDP。
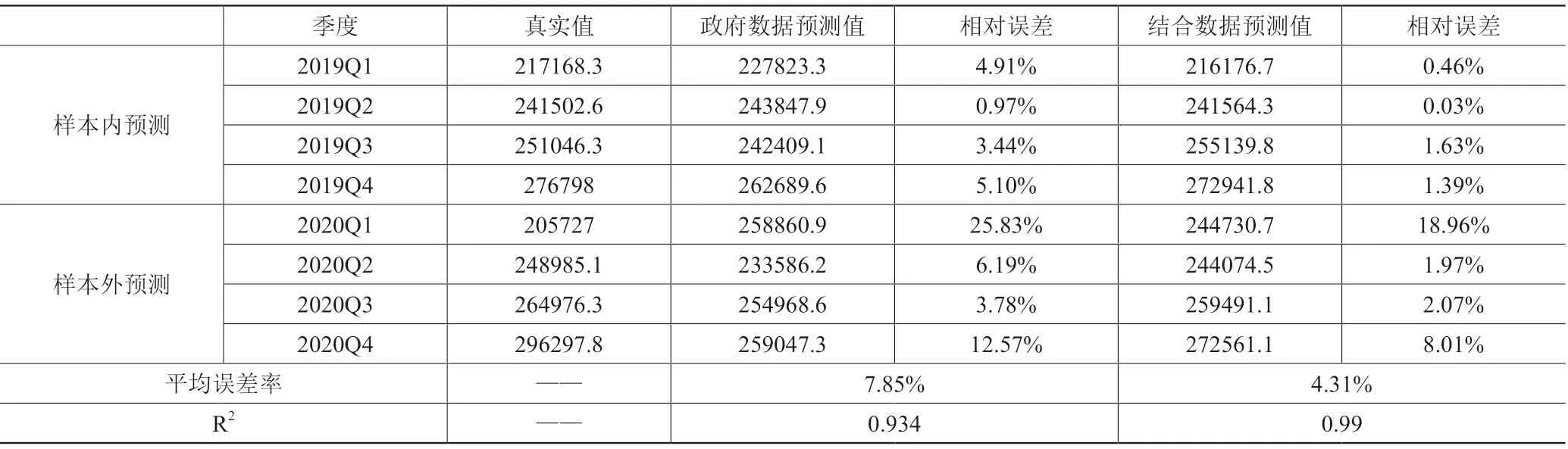
表2 模型擬合結果比較及季度GDP樣本內外預測結果的比較
五、結論與展望
1.加入網絡搜索指數和經濟政策不確定性指數對經濟總量GDP的擬合和預測效果比較好,基本可以實現對我國宏觀經濟進行實時監測,且提高了預測精度。
2.傳統統計方法在預測方面的應用中,主成分回歸對處理高維數據可以表現得非常出色,模型可以達到較好的擬合效果,預測精度也比較高。
3.大數據應用方面而言,要充分利用非結構化數據,挖掘更加有效的在線信息,結合傳統宏觀經濟統計數據,將中長期經濟監測向實時監測轉變。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
