一種改進型TF-IDF文本聚類方法
2021-09-22 04:10:36張蕾,姜宇,孫莉
吉林大學學報(理學版) 2021年5期
張 蕾, 姜 宇, 孫 莉
(1. 吉林大學 發展規劃處, 長春 130012; 2. 吉林大學 計算機科學與技術學院, 長春 130012)
隨著互聯網技術的快速發展, 各種數據呈爆發性增長, 產生了大量文本信息, 因此采用文本分類技術對海量數據進行科學地組織和管理尤為重要. 機器學習技術對文本分類不需要人為干預, 因此被廣泛應用[1-3]. 詞頻-逆文檔頻率(term frequency-inverse document frequency, TF-IDF)算法具有簡單、 可靠性高等特征, 可用于對文本分類, 但也存在不足, 尤其是處理一些特定的分類問題(如學科交叉等問題)時, 存在對與文章內容關系不密切的生僻詞給予過高權重的問題[4-5], 且TF-IDF算法未考慮詞語在不同分類分布時對其權重的影響, 同一詞語在不同論文分類中表示的意義和重要程度不同. 雖然LDA主題模型、 word2vec/doc2vec分布式模型和深度學習模型等經典方法在處理文本分類時都有其各自優勢[6-7], 但在處理一些數據量較小無法滿足深度學習算法, 也不能滿足LDA主題模型、word2vec/doc2vec分布式模型時, TF-IDF算法可以解決這類問題. 因此, 本文采用TF-IDF向量空間模型作為詞頻向量轉化模型. 傳統TF-IDF算法在實際應用中當詞項存在不同語義時在準確分析上還存在差距, 目前已有一些解決方法[8-9], 其中基于詞頻差異的特征選取方法被證明有效[10]. 本文提出一種基于改進TF-IDF文本聚類的分類方法, 以提高算法的準確性. 首先采用改進TF-IDF文本聚類方法進行詞頻向量提取; 然后利用K-mean++算法對TF-IDF算法生成的詞頻向量結果進行聚類分析; 最后利用詞云方法和隨機森林方法驗證本文方法的有效性.
1 改進TF-IDF詞頻向量轉化算法
1.1 TF-IDF算法
在文本分類中常用TF-IDF算法進行特征提取, TF-IDF算法是一種根據單詞在語料庫中出現頻次判斷其重要程度的統計方法, 主要思想是先對詞頻(term frequency, TF)進行統計, 認為詞語出現次數越多, 則文檔可能與該詞語有越多的正向關聯性, 再通過逆文檔頻率(inverse document frequency, IDF)減少常見詞的權重, 計算公式為
TFIDFi,j=TFi,j×IDFi,j,
(1)
其中TFIDF表示詞頻TF和逆文檔頻率IDF的乘積, TFIDF值越大對當前文本的重要性越大.
本文使用的數據為離散化的關鍵詞詞條, 聚類算法無法直接計算關鍵詞. 因此本文采用TF-IDF方法將關鍵詞轉化為詞頻向量, 聚類算法通過計算詞頻之間的距離計算樣本之間的相似度.
1.2 改進TF-IDF算法
TF-IDF算法在本文應用場景中利用了特征詞與其出現的文本數之間的關系, 而忽略了特征詞在不同類別間的分布差異情形, 不利于提高分類的準確性. TF-IDF算法目前已有多種改進方法[11], 本文針對特征詞在不同學科文獻中出現的頻率不同, 在不同學科中含義也不同的問題, 提出一種改進的TF-IDF算法, 利用現有學科分類作為參考, 區分特征詞在不同學科中的含義, 以提高TF-IDF算法結果的置信度, 計算公式為
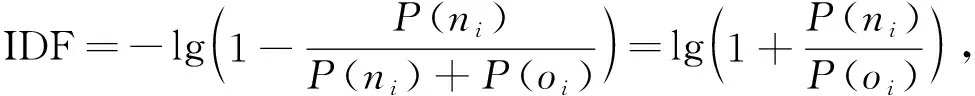
(2)
其中P(ni)表示特征詞i在類n中出現的概率,P(oi)表示特征詞i在文檔中其他分類(文檔中刪除類n后所得分類)中出現的概率.在傳統TF-IDF算法中, 兩個特征詞在文檔中出現的次數相同, 但由于不同特征詞的不同分布,P(ni)和P(oi)不同, IDF值也不同, 因此改進的TF-IDF算法可以更好區分不同特征詞的分布情況.
算法流程如下, 其中算法的輸入為論文文本集D, 輸出為詞頻向量矩陣m.
算法1改進TF-IDF算法.
輸入: 論文集D;
輸出: 矩陣m;
初始化TF-IDF矩陣m;
在定義任務相關數據時,用戶說明包含被挖掘數據的數據庫和表(或者數據倉庫和數據立方體)、選擇數據和分組的條件、挖掘時要考慮的屬性(或維)。這實際就是對多邊矩陣本身框架的識別和認識,選取合適的框架定義多邊矩陣的形式結構。
對論文j中的每個單詞i, 循環執行以下過程:
計算單詞i在該學科分類的頻率P(ni);
計算單詞i在其他學科分類的頻率P(oi);
計算單詞i在所有文獻中的頻率P(TF);
按
更新矩陣m中的每個值;
結束循環.
2 基于改進TF-IDF文本聚類的交叉學科分類方法
2.1 算法流程
本文實驗方法及流程如圖1所示. 首先利用WOS(Web of Science)數據平臺進行論文索引, 選用數據庫中索引的2015—2019年吉林省內各高校、 科研院所發表的所有論文信息, 利用改進TF-IDF算法對論文關鍵詞進行詞頻向量轉化處理, 形成文獻的詞向量矩陣; 然后利用K-means++算法對TF-IDF矩陣進行聚類分析; 最后采用隨機森林算法[12]分別評估改進TF-IDF算法和傳統TF-IDF算法的準確性.
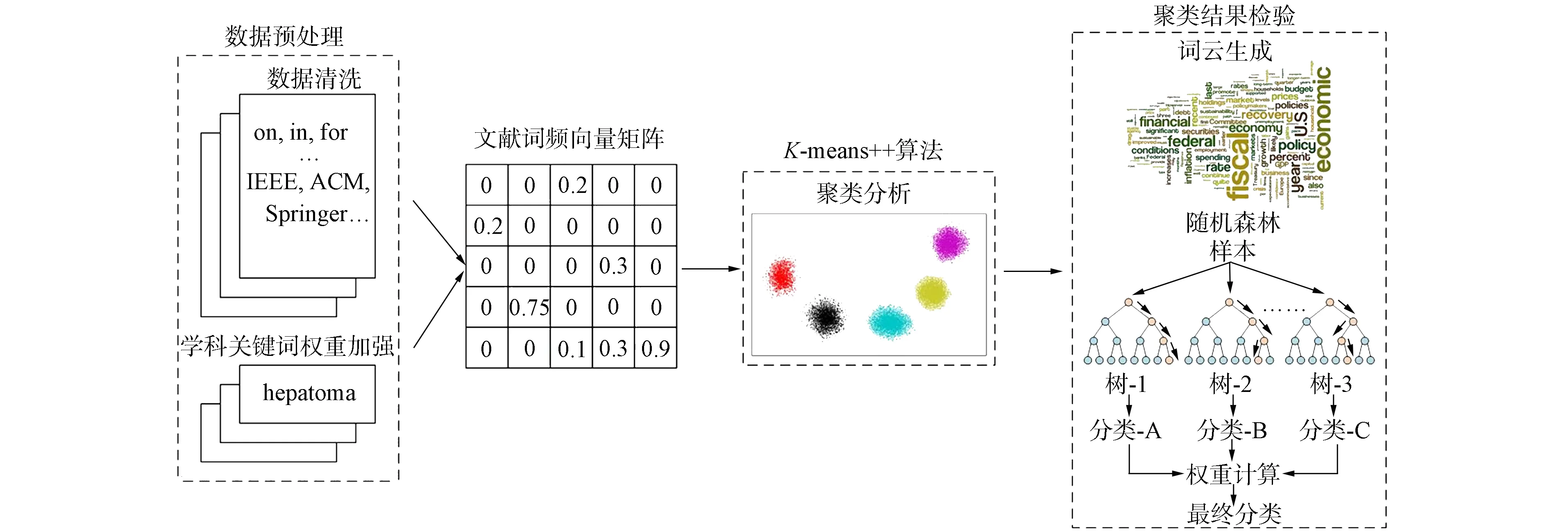
圖1 實驗方法及流程Fig.1 Experimental method and process
2.2 K-means++算法
本文采用K-means++算法對TF-IDF算法生成的詞頻向量結果進行聚類分析.K-means算法是經典的聚類算法之一[13], 假設K-means算法的輸入樣本集為D={x1,x2,…,xm}, 聚類的簇數為k, 經過N次迭代后算法停止,K-means算法的運行步驟如下.
1) 從數據集D中隨機選擇k個樣本作為初始的k個質心向量{c1,c2,…,ck};
2) 對于n=1,2,…,N, 進行如下操作:
① 將簇劃分C初始化為Ct={ct}(t=1,2,…,k);
② 對于i=1,2…,m, 分別計算樣本xi和各質心向量cj(j=1,2,…,k)的距離di,j=‖xi-cj‖, 將最小的xi標記為dij所對應的類別j, 然后更新Cj=Cj∪{xi};
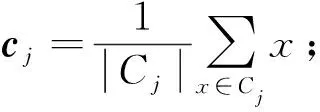
④ 如果k個質心的位置都未發生變化, 則結束算法, 轉步驟3);
3) 輸出結果簇劃分C={C1,C2,…,Ck}.
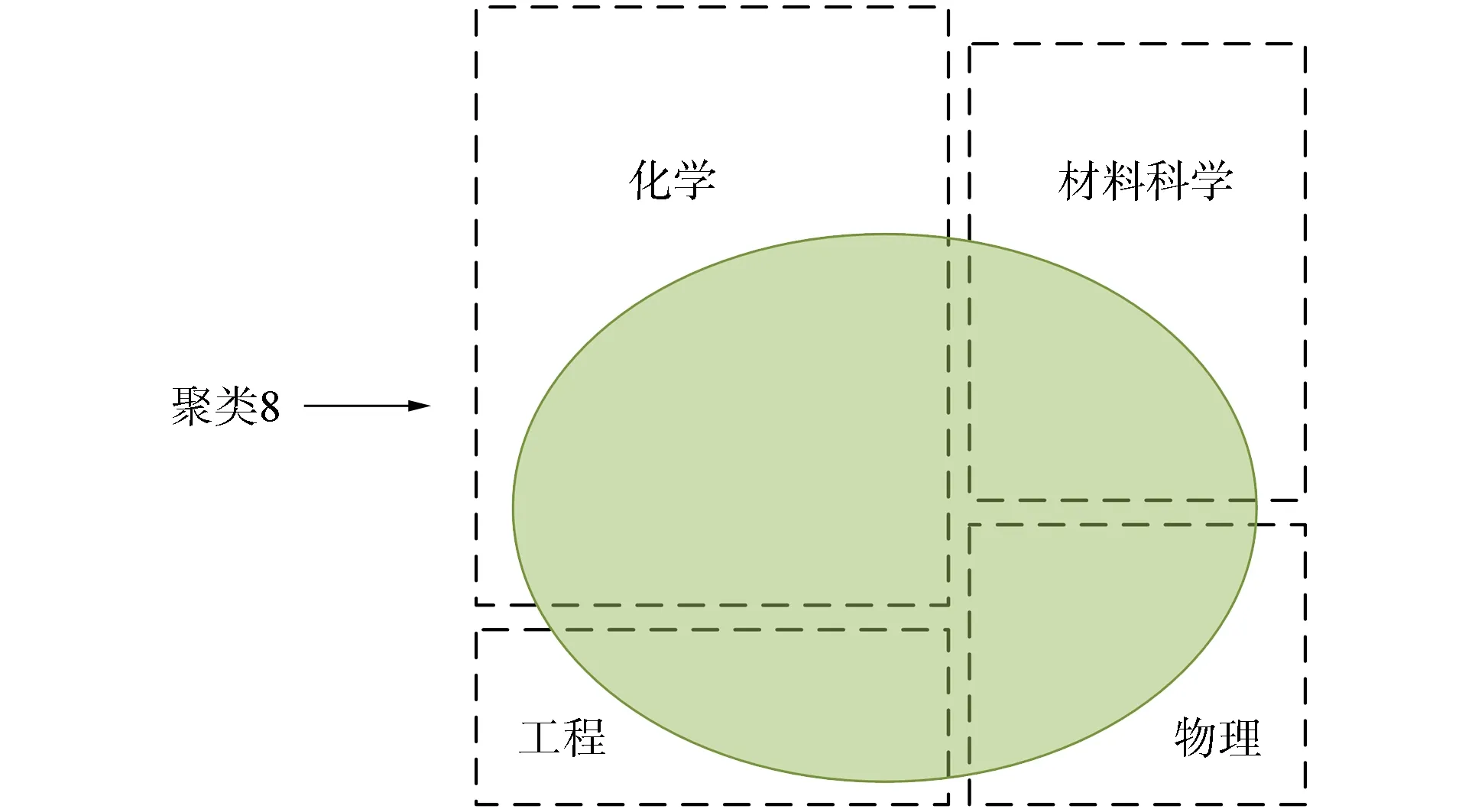
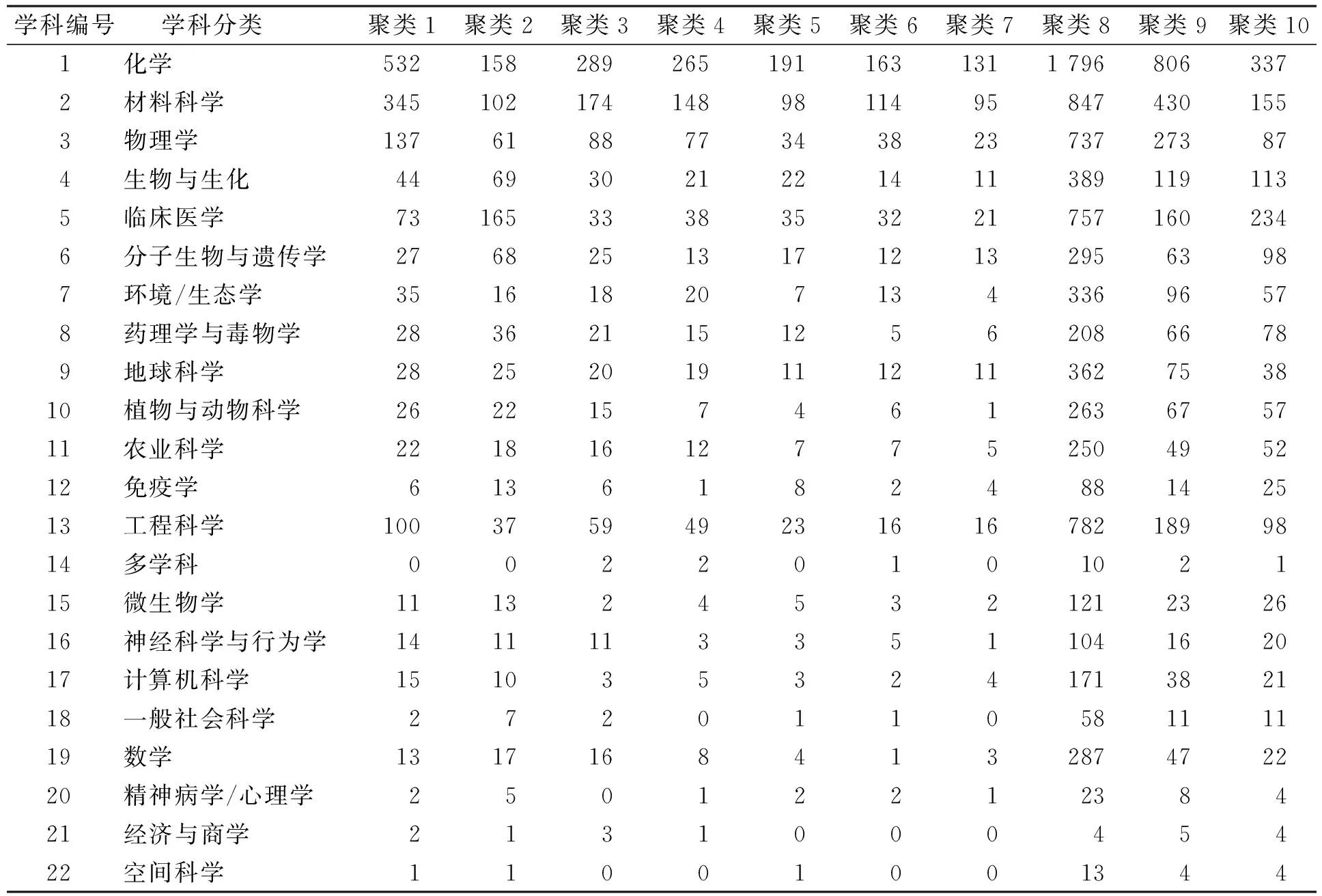
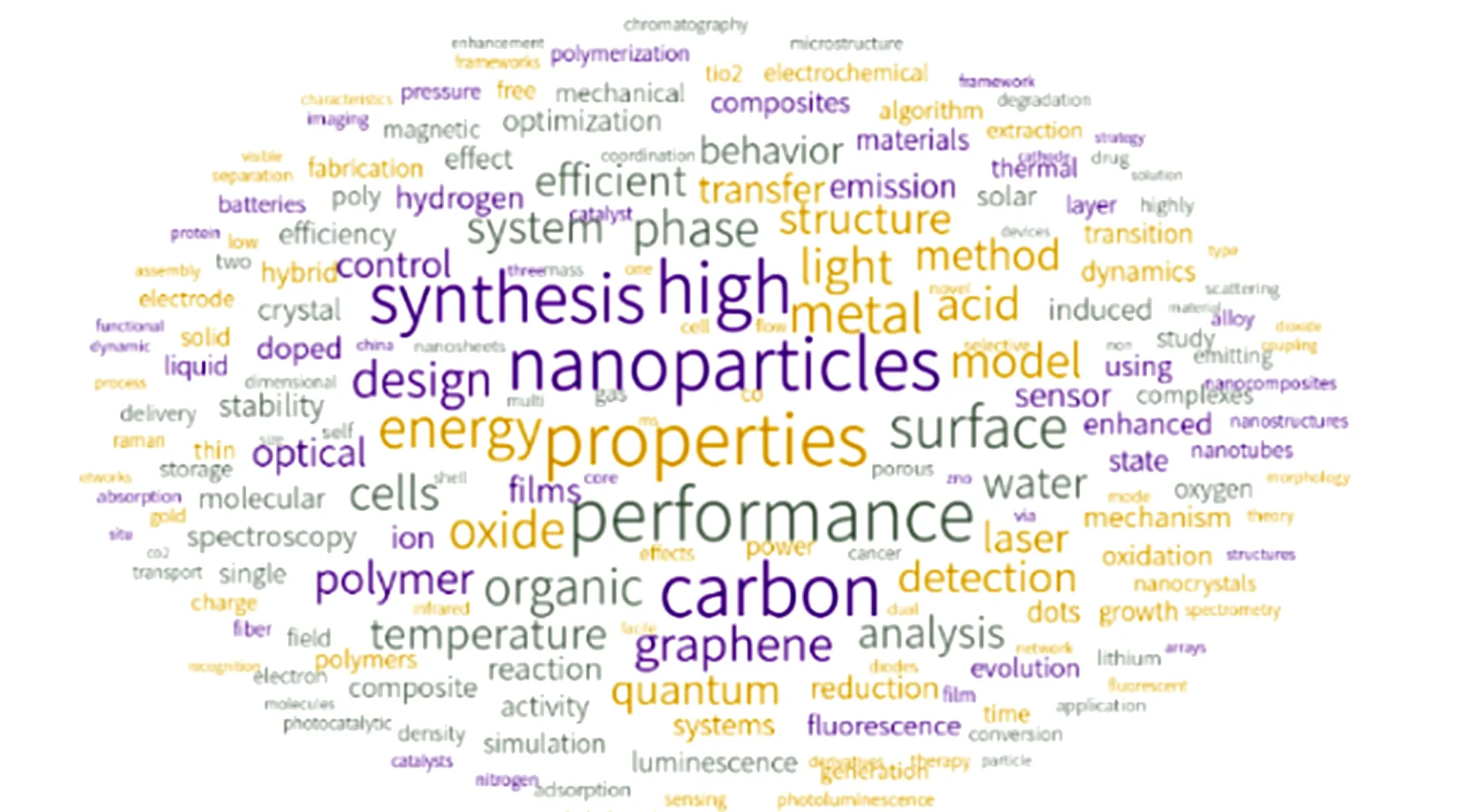
在K-means算法中, 質心位置的選擇對最后的聚類結果和運行時間都有較大影響, 因此需選擇合適的質心.K-means算法默認采用隨機選擇質心, 有可能導致算法收斂較慢, 時間開銷較大[14].K-means++算法對K-means算法隨機初始化質心的方法進行了優化.K-means++算法假設已經選取了n個初始聚類中心(0 本文實驗的數據采用WOS數據庫中的論文進行數據檢索, 并按照ESI學科分類進行整理, 形成實驗數據集. 實驗數據集包含了2015—2019年吉林省全部科研機構發表以及合作發表論文的數據信息, 共篩選出53 346篇論文, 論文信息包含領域、 出版年、 被引頻次、 學科領域百分位、 期刊影響因子、 關鍵詞等, 并按基本科學指標數據庫(essential science indicators, ESI)的22個學科領域進行分類, 包括計算機科學、 工程科學、 材料科學、 生物與生化、 環境/生態學、 微生物學、 分子生物與遺傳學、 一般社會科學、 經濟與商學、 化學、 地球科學、 數學、 物理學、 空間科學、 農業科學、 植物與動物科學、 臨床醫學、 免疫學、 神經科學與行為學、 藥理學與毒物學、 精神病學/心理學、 多學科. 圖2 聚類8交叉學科詞頻分布Fig.2 Term frequency distribution of interdisciplinary in cluster 8 先分別利用傳統TF-IDF算法和改進TF-IDF算法將論文關鍵詞轉換為詞頻向量矩陣; 然后用K-means++算法利用每篇論文關鍵詞的詞頻向量進行聚類, 確定每篇論文所屬的學科分類; 最后按ESI論文庫標準的22種分類(ESI按論文所在出版刊物的所屬學科進行劃分), 與本文采用的單篇論文關鍵詞聚類產生的結果進行學科交叉分析, 分析結果表明, 交叉學科對學科發展具有重要的指導作用[15-16]. 按輪廓系數標準確定K值, 當K=10時, 樣本到同簇其他樣本的平均距離最小, 聚類結果最好, 共產生10個聚類結果, 見表1. 本文以聚類詞匯數量最集中的聚類8為例進行交叉學科群分析, 如圖2所示. 表1 K-means++算法聚類結果 由表1可見: 聚類8形成的交叉學科群中化學學科類的關鍵詞出現詞頻1 796次, 占化學學科關鍵詞總詞頻的38.5%; 材料科學學科類的關鍵詞出現詞頻847次, 占材料科學學科關鍵詞總詞頻的33.8%; 物理學科類的關鍵詞出現詞頻737次, 占物理學科關鍵詞總詞頻的47.4%; 工程學科類的關鍵詞出現詞頻782次, 占工程學科關鍵詞總詞頻的57.1%. 聚類8中包括主要學科分類為化學、 材料科學、 物理學、 工程學交叉學科群, 該結果符合查詢到的學科交叉規律[17]. 圖3 聚類交叉學科關鍵詞分布Fig.3 Distribution of clustering interdisciplinary keywords 圖3為聚類交叉學科關鍵詞分布. 由圖3可見, 聚類8中高頻詞匯也多為化學學科、 材料科學學科、 物理學科、 工程學科相關詞匯, 如納米顆粒(nanoparticles)、 合成(synthesis)、 碳(carbon)、 石墨烯(graphene)等, 說明在論文中出現的高頻詞匯也是學科交叉相對集中的科研熱點. 隨機森林算法是一種有效的分類預測方法, 分類精度較高[18], 本文用隨機森林算法評估聚類結果的準確性. 隨機森林算法包含16個隨機樹、 16個子集, 選取論文的學科分類、 發表年、 當前應用數量、 期刊名稱、 影響因子、 學科百分數作為訓練特征參數, 交叉學科分類作為目標參數. 用隨機森林算法分別對傳統TD-IDF算法與改進TD-IDF算法進行評估, 其精確率、 召回率、F1值和詞頻向量轉化時間結果列于表2. 表2 傳統TD-IDF算法與改進TD-IDF算法的評估結果 由表2可見, 改進TD-IDF算法能區分不同特征詞在全部文檔的分布情況, 提高了算法的精確率,F1值是綜合評價精確率和召回率的指標, 雖然改進TD-IDF算法的召回率略有降低, 但改進TD-IDF算法的F1值更高, 表明改進TD-IDF算法在解決交叉學科聚類問題時具有的更高的置信度. 同時, 改進TD-IDF算法的詞頻向量轉化時間略高于原始TD-IDF算法, 表明其在提高聚類置信度的同時, 并不會增加太多的時間開銷. 綜上所述, 本文提出了一種混合聚類的方法對WOS數據庫中的論文信息進行分類, 分析了各學科間交叉研究的熱點和發展趨勢. 首先使用改進TF-IDF算法統計論文中的關鍵詞詞頻, 然后采用K-means++算法進行聚類, 并對聚類結果進行詞云分析, 最后通過隨機森林算法評估改進TF-IDF算法和TF-IDF算法的準確性, 實驗結果表明, 改進TF-IDF算法能更有效地解決交叉學科的分類任務, 從而為吉林大學雙一流學科建設可持續發展提供決策依據.3 實 驗
3.1 數據集
3.2 實驗結果

猜你喜歡
寧波大學學報(理工版)(2022年4期)2022-07-08 05:12:02
華北理工大學學報(自然科學版)(2021年3期)2021-07-03 09:06:34
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
軍事文摘·科學少年(2017年4期)2017-06-20 23:29:09
中央社會主義學院學報(2016年2期)2016-05-04 04:18:29
