一種增量式MinMax k-Means聚類算法
2021-09-22 04:10:36胡雅婷陳營華寶音巴特曲福恒李卓識
吉林大學學報(理學版) 2021年5期
胡雅婷, 陳營華, 寶音巴特, 曲福恒, 李卓識
(1. 吉林農業大學 信息技術學院, 長春 130118; 2. 吉林省科學技術工作者服務中心, 長春 130021;3. 長春理工大學 計算機科學技術學院, 長春 130022)
聚類分析[1-4]是數據分析的一種基本方法, 既可作為一種無監督機器學習方法獨立發現未標簽數據結構, 完成數據分類、 壓縮等工作, 也可與其他方法相結合以提高其性能.k-means算法是一種經典的劃分聚類算法, 通過最小化類內方差之和獲得硬聚類劃分, 因其計算簡單、 聚類效率高等優點廣泛應用于模式識別、 機器學習、 圖像處理及故障診斷等領域[5-8]. 但k-means聚類結果對初始聚類中心依賴較大, 導致算法易陷入局部極小值[9]. 為改善該問題, 可通過改進中心初始化方法降低初始化對算法的影響, 以獲得目標函數的更優解[10-12].k-means++算法[13]通過隨機選擇程序實現初始化中心對整個數據空間的全覆蓋, 在理論上保證了獲得聚類劃分可達到近似最優. 該類算法計算效率相對較高, 但對目標函數解的改善程度有待提高. 全局k-means聚類算法[14-17]作為一種增量式k-means聚類算法, 以每次迭代增加一個聚類中心的方式完成聚類數目的遞增, 通過在數據中選擇使目標函數值減少最多的數據點作為新增的聚類中心. 該算法明顯提升了目標函數解的質量, 但計算效率較低.
針對上述改進算法存在的問題, Tzortzis等[18]提出了MinMaxk-means聚類算法. MinMaxk-means 算法以最小化最大的方差為聚類準則確定目標函數, 該準則能改善k-means算法迭代中產生過大方差類的問題, 從而得到目標函數更優的解. 由于直接優化最小化最大的方差準則函數對應一個非連續可微的優化問題, 因此MinMax算法通過優化加權k-means目標函數得到該問題的近似解. 與k-means及其初始化中心改進算法相比, MinMaxk-means算法能顯著改善k-means算法目標函數解的質量, 計算效率比全局k-means及其改進算法更高. 但為了避免產生空類或單點類, MinMaxk-means算法采用自適應機制動態地調整參數p, 而參數p的合理取值區間為[0,1), 自適應調整不能保證其取值始終位于該區間內, 使算法存在產生空解的可能性.而且實驗結果表明, 初始化中心對MinMaxk-means聚類結果影響較大, 初始化不當可導致迭代次數多、 迭代時間長、 目標函數解的質量差等問題. 為進一步改進MinMaxk-means算法性能, 受全局k-means增量式算法啟發, 本文通過引入增量式聚類思想改進MinMaxk-means算法存在的上述問題. 對于給定的聚類數目k, 首先以較小的kmin值作為起始聚類數目, 通過對一個或多個聚類劃分進行分裂, 以增加聚類數目直至達到指定的k值.與現有的增量式全局k-means算法每次迭代都需從數據集中篩選出新增的聚類中心不同, 本文算法通過分裂已有聚類劃分完成增量式聚類, 并引入均衡化準則確定分裂對象, 其增量式過程計算效率更高, 同時能明顯改善MinMaxk-means算法目標函數解的質量.
1 MinMax k-means聚類算法
MinMaxk-means聚類[18]是k-means聚類的一種改進算法, 通過改進k-means算法的目標函數改善其在迭代過程中易陷入局部最小值問題, MinMaxk-means的目標函數建立在最小化最大的類內方差準則上. 假設X是給定的數據集合,k是聚類數目, 則其目標函數為
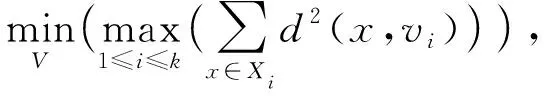
(1)
其中V={v1,v2,…,vk}為聚類中心集合,Xi(1≤i≤k)為第i個聚類劃分, 存儲數據X中所有距離中心vi最近的數據點.目標函數等于X中所有距離中心vi最近的數據點與中心vi之間距離的平方和.
由于直接優化目標函數(1)對應一個非連續可微的優化問題, 無法直接利用迭代算法進行求解, 因此, Tzortzis等[18]對目標函數(1)進行了近似處理, 改寫后的近似目標函數為
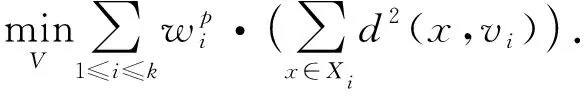
(2)
為了抑制某類方差之和的值過大, 式(2)將參數p的取值范圍限定為區間[0,1).在迭代過程中, 為避免空類問題, 采用自適應策略更新迭代過程中的參數p, 設參數p的最大取值pmax并更新步長pstep, 參數p更新過程為
p=pmax-pstep.
(3)
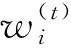
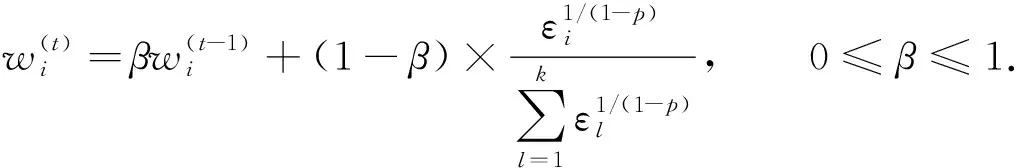
(4)
MinMaxk-means聚類算法流程如下:
步驟1) 初始化參數pstep,pmax,β及聚類數目k、 迭代最大次數tmax和收斂精度δ;
步驟2) 初始化聚類中心V(0);
步驟3) 利用V(0)與給定的參數, 優化目標函數(2)得到聚類中心V′[18];
步驟4) 以V′作為k-means聚類的初始化中心, 運行k-means聚類算法直至收斂, 得到聚類中心V.
由于k-means與MinMaxk-means聚類算法的目標函數不同, 因此算法流程中前三步得到的聚類中心是最優化MinMaxk-means目標函數的結果. 而MinMaxk-means聚類的最終目標是優化k-means的目標函數, 因而在其最后一步需要運行k-means算法以獲得優化k-means目標函數對應的最終聚類結果. 本文將完整的4個步驟稱為“MinMaxk-means”聚類或者簡稱為“MinMax”聚類, 而文獻[18]將前三步稱為“MinMax”聚類, 將完整的四步稱為“MinMax+k-means”聚類, 本質相同.
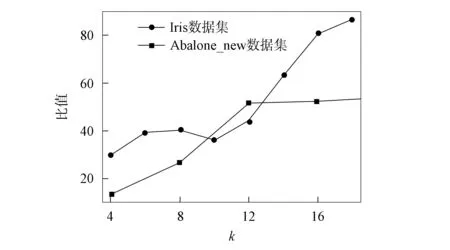
在MinMaxk-means算法的迭代過程中, 通過動態調整參數p處理空類與單點類問題. 但參數p的合理取值區間為[0,1), 自適應地調整不能保證其取值始終位于該區間內, 使得算法可能產生空解. 且通過實驗發現, 初始化中心對MinMaxk-means聚類結果與效率均有較大影響, 初始化不當可導致迭代次數多、 迭代時間長的問題, 空解的產生也與算法初始化聚類中心的選擇有關. 在UCI機器學習典型數據集Iris上分別運行MinMaxk-means和k-means算法. 圖1為MinMaxk-means算法在不同聚類數目下的運行結果(算法參數設置與文獻[18]一致, 運行50次取平均值). 由圖1可見, MinMaxk-means算法存在如下問題: 1) 算法有空解產生, 且隨著聚類數目的增加, 空解產生比例呈逐漸增大的趨勢; 2) 算法并不能保證在給定的迭代次數內收斂. 圖2為不同聚類數目下MinMaxk-means與k-means算法聚類迭代次數與運行時間的比值. 由圖2可見, MinMaxk-means算法平均迭代次數明顯高于k-means算法, 從而導致MinMaxk-means算法計算效率較低, 運行時間明顯比k-means算法長.
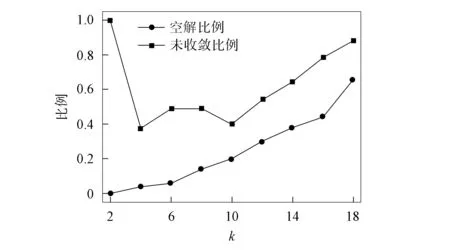
圖1 MinMax k-means算法在不同 聚類數目下的運行結果Fig.1 Running results of MinMax k-means algorithms for different clustering numbers
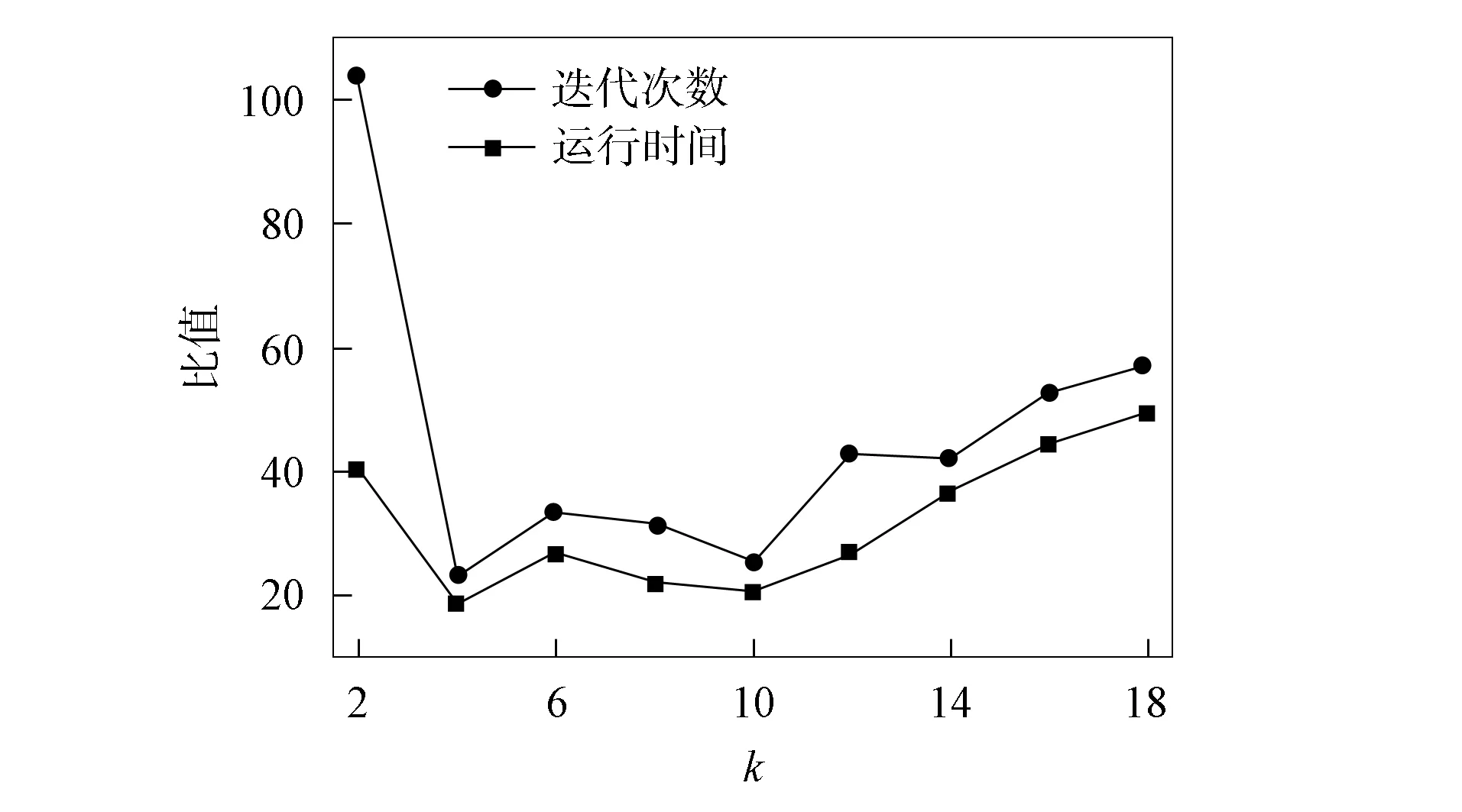
圖2 不同聚類數目下MinMax k-means 與k-means算法的比值Fig.2 Ratios of MinMax k-means and k-means algorithms for different clustering numbers
2 增量式MinMax k-means聚類算法設計
2.1 全局k-means算法
為避免k-means算法對初始化中心敏感的問題, Likas等[17]提出了一種全局k-means聚類算法, 該算法通過增量式增加聚類中心獲取更優的目標函數解, 降低了k-means算法對初始化的依賴程度. 全局k-means算法流程如下:
步驟1) 初始化聚類數目k*=1, 初始化中心V為所有數據的均值;
步驟3) 以V′作為初始化中心, 運行k-means算法至收斂, 收斂后中心賦值給V;
步驟4) 如果k*=k, 則算法停止; 否則, 轉步驟2).
全局k-means聚類算法降低了k-means算法對初始化的依賴程度, 但計算效率較低, 原因如下:
1) 在步驟2)中, 遞增式增加一個中心, 全局k-means算法需要遍歷所有數據點, 并選擇其中對應的目標函數值最小的數據點作為下一個中心, 這一原則基于k-means算法的目標函數最小化; 增量式選擇聚類中心時需計算各數據點之間的距離, 其計算量是O(N2s), 其中N為數據個數,s為數據維數, 而k-means每次迭代的計算量為O(Nsk).一般情況下k?N, 使得全局k-means算法中心選擇的計算量過大.
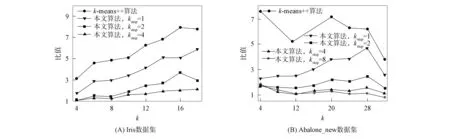
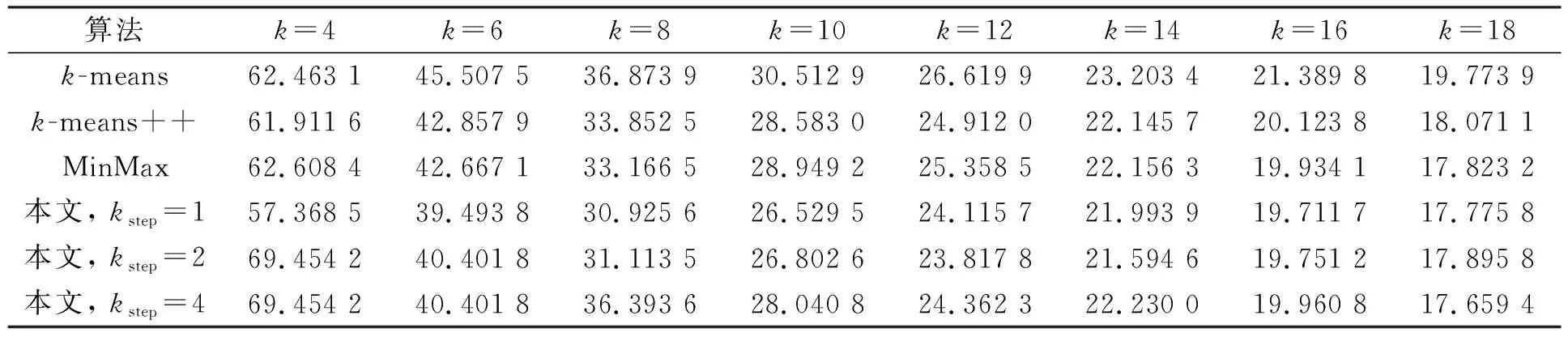
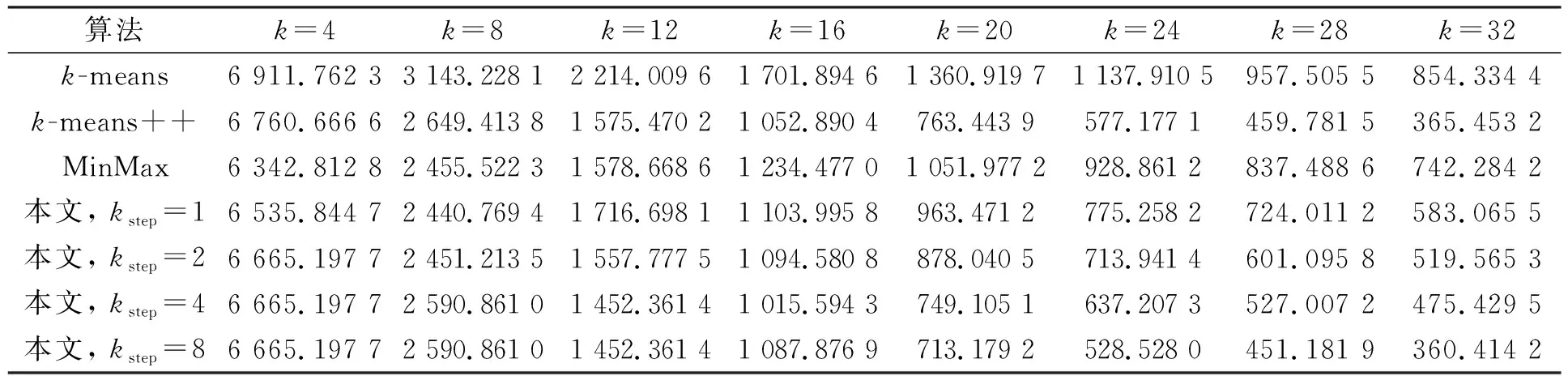
2) 在步驟3)中, 對每個單獨的聚類數目k*(1 本文采用全局k-means算法的增量式聚類思想降低MinMaxk-means算法對初始化敏感的問題. 盡管全局k-means算法的增量式聚類改善了聚類結果對初始化的敏感性, 但與原始k-means算法相比, 其增加了計算量, 計算效率非常低. 因此, 不能直接套用全局k-means算法的增量模式. 本文采用完全不同的增量式過程完成聚類數目的遞增, 從而提升其計算效率. 針對全局k-means算法選擇增量中心的過程計算量過大問題, 本文進行如下改進以提升其計算效率: 1) 針對已有的聚類劃分進行操作, 并非針對數據點進行操作, 由于聚類劃分數目遠小于數據點的個數, 因此從遍歷選擇的角度具有優勢; 2) 對每個劃分采用分裂方式完成聚類數目的增加, 分裂可保證目標函數值是下降的, 這與優化k-means算法目標函數一致; 3) 借鑒MinMaxk-means算法的目標函數原則, 并在其基礎上進行改進, 以快速確定被分裂的聚類劃分. MinMaxk-means聚類準則是最小化最大的類內方差, 以盡量保證各類內的方差均衡. 但對于不同聚類中數據數目不一致、 具有嚴重差異的問題, MinMaxk-means聚類準則并未考慮. 此時, 對數據數目過大的劃分進行分裂可得到更均衡的類內方差結果. 本文采用各類數據均衡的思想確定被分裂的聚類劃分, 避免不同聚類劃分之間數據不平衡導致的類內方差差異過大問題, 從而降低算法整體目標函數值. 同時, 由此產生的計算量極低, 幾乎可以忽略不計, 只需要記錄各聚類劃分的數據數目即可. 針對全局k-means算法時間復雜度較高的問題, 本文進行如下改進: 軍功爵制是對五等爵制分封體制的一種繼承,然而它卻與五等爵制有著明顯的差異和不同。五等爵制規定,天子、諸侯、大夫、士農工的世襲而定,“天子一位,公一位,侯一位,伯一位,子,男一位,凡五等也”[13]P782統治者內部等級和被統治著的身份地位也是受到五爵制的限定。“天子者,爵稱也,爵所以稱天下者何?王者父天母地,為天之子也。所以名之為公候者何?公者,通也,公正無私意也。侯者,候也,候逆順也。伯者,白也。子者,孳也,孳孳無己也,男者,任也。”[14]P2而軍功爵制則是春秋時期,諸侯根據當時的政治形勢和社會環境對庶民做出的一種妥協。 1) 同時分裂多個劃分, 一次性遞增多個聚類中心以快速增加聚類數目, 從而不必對所有的聚類數目k*(1 2) 對每個增量過程中限制算法迭代次數不超過某個給定的較小值, 以降低計算量. 由實驗結果可知, 降低迭代次數并不會影響該算法獲取解的質量. 這是因為本文算法在迭代過程中采用了優化能力更強的MinMaxk-means迭代算法, 其優化能力優于全局k-means所采用的原始k-means聚類算法. 對于一個給定的數據集合X及給定的聚類個數k, 本文算法流程如下: 步驟1) 參數設定.設置最小聚類數目kmin、 聚類數目遞增量kstep和最大迭代次數tmax; 步驟2) 計算初始聚類劃分.令k*=kmin, 在保證迭代次數不超過tmax的前提下運行MinMaxk-means算法對數據集X進行聚類, 記錄聚類結果中各聚類劃分內部數據數目; 步驟3) 分裂聚類劃分. ① 計算分裂聚類數目ksplit: 若kstep>k*, 則ksplit=k*, 否則,ksplit=kstep; 若k*+ksplit>k, 則令ksplit=k-k*; ② 確定被分裂的聚類劃分: 對已有聚類劃分按數據數目從大到小排序, 選取前ksplit個劃分標記為待分裂劃分, 其余聚類劃分標記為穩定劃分; ③ 確定新的初始化聚類中心Vinit: 令Vinit=?, 對每個待分裂劃分, 從其數據集合中隨機選取兩個數據并入到Vinit; 對每個穩定劃分直接選取其數據中心加入到Vinit; ④ 計算新聚類數目k*=k*+ksplit; ⑤ 根據初始中心Vinit、 聚類數目k*和最大迭代次數tmax, 運行MinMaxk-means算法得到新的聚類劃分, 記錄各聚類劃分中的數據點個數; ⑥ 若k* 步驟4) 以上述步驟獲取的k個聚類中心作為初始化中心, 運行k-means算法直至收斂, 得到最終的聚類結果, 算法結束. 為驗證本文算法的有效性, 將其與k-means聚類及其改進算法進行比較, 對比算法包括原始k-means聚類算法、 MinMaxk-means聚類算法[18]和目前常用的中心初始化改進算法k-means++算法[13]. 實驗數據集為UCI機器學習數據庫中的典型數據集Iris(N=150,s=4)和Abalone_new(N=4 177,s=48), 其中N為數據個數,s為數據維數; 所有算法的最大迭代次數為1 000; MinMaxk-means算法中參數采用文獻[18]中的推薦設置, 其中pmax=0.5,pstep=0.01,ε= 10-6,β=0.3.本文算法的參數設置為kmin=2, 增量聚類的最大迭代次數tmax=5.本文同時對比了kstep在不同取值下的聚類結果.實驗結果取每種算法運行50次的平均值.實驗代碼以MATLAB編寫, 硬件配置為CPU: Intel Core i3, 3.40 GHz; 內存12 GB. 3.2.1 與不同算法的對比結果 圖3 不同數據集上MinMax k-means與 k-means算法運行時間的比值Fig.3 Ratios of running time of MinMax k-means and k-means algorithms on different data sets 圖3為不同數據集上MinMaxk-means與k-means算法運行時間的比值. 由圖3可見, 在不同數據集上MinMaxk-means和k-means算法的運行時間比值在10~90內變動. 圖4為本文算法kstep取不同值時與k-means算法運行時間的比值. 由圖4可見, 本文算法在參數kstep的不同取值下, 與k-means++算法運行時間的比值均小于7, 有些結果甚至快于k-means++算法. 因此, 本文算法的計算效率顯著優于MinMaxk-means算法. Iris和Abalone_new數據集上各對比算法的目標函數值分別列于表1和表2. 由表1和表2可見, 不同數據集、 不同聚類數目共計16組對比實驗結果中, 其中15組實驗結果本文算法優于MinMaxk-means算法, 占比達93.75%, 表明本文算法對MinMax的求解精度有明顯優化效果. 以Abalone_new數據集在參數設為kstep=1的情況為例, 其函數值的6次優化結果百分數為0.6%~21%, 其他數據集與參數設置下的優化幅度也接近或高于該百分數. 在次于MinMaxk-means算法的一組實驗數據上, 本文算法得到的仍是所有對比算法中的次優結果. 這里未列出空解產生的比例以及算法未收斂的比例. 對于所有實驗數據集, 本文算法都能正常收斂, 并無空解產生, 表明本文算法可避免MinMaxk-means收斂速度慢、 易產生空解的問題. 對比實驗結果表明, 無論在算法的運行時間上, 還是在目標函數值優化上, 本文算法均明顯改善了MinMaxk-means算法存在的問題. 在時間效率上, 如圖3和圖4所示, 在k-means算法的不同改進算法中, 本文算法的計算效率最高, 其次是k-means++算法, MinMaxk-means算法的計算效率最低. 在聚類算法目標函數值上, 如表1和表2所示, 不同數據集、 不同聚類數目共計16組對比實驗結果中, 本文算法15次取得了最優值, 12次取得了次優值, 明顯優于其他3種對比算法. 圖4 本文算法kstep取不同值時與k-means++算法運行時間的比值Fig.4 Ratios of running time of proposed algorithm and k-means++ algorithm when kstep takes different values 表1 Iris數據集上各對比算法的目標函數值 表2 Abalone_new數據集上各對比算法的目標函數值 3.2.2 參數kstep對本文算法的影響 kstep的取值對本文算法的尋優能力有一定影響.由表1和表2可見, 當k值較小(k<12),kstep取值為1,2時算法性能更好; 當k值較大(k≥16),kstep取值為4,8時算法性能更好.由圖3和圖4可見,kstep值越大, 本文算法的計算效率越高.這是因為隨著kstep值的增加, 算法跳過的k值增多, 從而減少了迭代的總次數. 綜上可見, 本文算法改善了MinMaxk-means算法易產生空解、 收斂速度慢和計算效率較低的問題, 并進一步提升了MinMaxk-means算法目標函數解的質量. 對比實驗結果表明, 本文算法具有較高的計算效率, 得到的目標函數值明顯優于其他對比算法.2.2 改進算法
3 實 驗
3.1 實驗環境與參數設置
3.2 實驗結果與分析