
基于密度信息熵的K-Means算法在客戶細(xì)分中的應(yīng)用
2021-09-22 03:59:16蒲曉川黃俊麗宋長松
吉林大學(xué)學(xué)報(理學(xué)版) 2021年5期
關(guān)鍵詞:模型
蒲曉川, 黃俊麗, 祁 寧, 宋長松
(1. 遵義師范學(xué)院 信息工程學(xué)院, 貴州 遵義 563006; 2. 國立釜慶大學(xué) 技術(shù)管理學(xué)院, 韓國 釜山 48513;3. 遵義師范學(xué)院 管理學(xué)院, 貴州 遵義 563006; 4. 河西學(xué)院 經(jīng)濟(jì)管理學(xué)院, 甘肅 張掖 734000)
在眾多客戶關(guān)系分析模型中, 最常用的是RFM模型(最近一次消費(fèi)(Recency)、 消費(fèi)頻率(Frequency)和消費(fèi)金額(Monetary)), 從多維度分析客戶的價值. 在此基礎(chǔ)上, 目前已有很多研究擴(kuò)展了該模型的適用范圍, 如文獻(xiàn)[1]提出了一種以傳統(tǒng)RFM模型為基礎(chǔ), 針對客戶潛在價值的RFMP模型; 文獻(xiàn)[2]在RFM模型的基礎(chǔ)上構(gòu)建了融入行業(yè)屬性的RVS模型等. 但這些方法并未考慮客戶的發(fā)展情況這一因素. 由于計算機(jī)數(shù)據(jù)挖掘中的聚類方法在應(yīng)用上與企業(yè)客戶關(guān)系管理相近, 因此可用聚類算法解決企業(yè)客戶的管理問題.K-means聚類在算法時間度量指標(biāo)及適用于大規(guī)模數(shù)據(jù)等方面效果較好, 因此廣泛應(yīng)用于解決客戶細(xì)分問題中.
基于此, 本文提出一種基于客戶發(fā)展的改進(jìn)RFM模型, 并針對K-means聚類算法的初始聚類中心選取問題進(jìn)行優(yōu)化改進(jìn), 采用統(tǒng)計學(xué)方法和聚類效果對實驗結(jié)果進(jìn)行驗證.
1 TFA模型構(gòu)建
客戶關(guān)系管理中的客戶細(xì)分是指選擇一定的細(xì)分變量, 按一定的劃分標(biāo)準(zhǔn)對客戶價值進(jìn)行分類的方法[3]. 客戶關(guān)系管理中最常用的是RFM分析模型, 但該模型存在細(xì)分后得到的客戶群過多、 購買頻率與購買金額之間存在多重共線性缺陷等[4]. 為克服RFM模型的缺點, 本文提出TFA模型, 是以客戶發(fā)展空間T、 購買頻次F和平均購買額A作為客戶貢獻(xiàn)度和發(fā)展空間的客戶分類模型. TFA模型中,T表示客戶發(fā)展空間,T值越大表示客戶返店消費(fèi)意愿越低,T值越小表示客戶返店消費(fèi)意愿越高, 其計算公式為

(1)
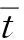
傳統(tǒng)RFM模型未對其指標(biāo)進(jìn)行權(quán)重分析, 導(dǎo)致不能體現(xiàn)各指標(biāo)在實際銷售中的重要程度, 在改進(jìn)模型中引入層次分析法(AHP)使之更精準(zhǔn). AHP是一種常用的權(quán)重分析方法[5], 首先將指標(biāo)屬性拆分為二維對應(yīng)關(guān)系, 然后通過業(yè)內(nèi)專家對屬性進(jìn)行權(quán)重判別. 本文通過填寫專家問卷調(diào)查方法和層次分析法計算指標(biāo)權(quán)重, 計算公式為
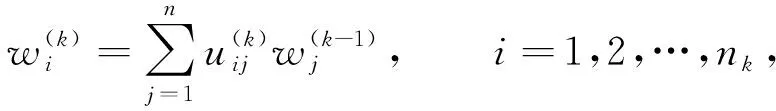
(2)
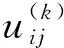
wTFA=0.26×T+0.11×F+0.63×A,
并通過
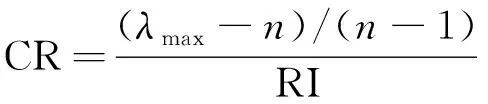
(3)
驗證權(quán)重的一致性, 其中λmax為判斷矩陣的最大特征根, RI為隨機(jī)一致性指標(biāo). 若CR<0.1, 則說明權(quán)重系數(shù)在可接受范圍內(nèi). TFA模型的指標(biāo)含義及權(quán)重列于表1.

表1 TFA模型參數(shù)指標(biāo)含義及權(quán)重
2 K-means聚類算法優(yōu)化改進(jìn)
由于RFM模型劃分為8類, 在實際應(yīng)用中存在劃分過細(xì)的問題, 按照人為規(guī)則劃分, 需要一種不設(shè)前提的細(xì)分方式, 并按照數(shù)據(jù)集規(guī)律進(jìn)行分類, 隨著數(shù)據(jù)挖掘技術(shù)的發(fā)展, 引入無監(jiān)督的計算機(jī)算法已成為必然.
2.1 K-means算法
K-means算法的基本原理是將樣本集中的樣本按歐氏距離判斷其相似度, 并劃分到不同簇中, 使其簇間相異度最大. 算法基本流程如下:
步驟1) 從輸入的數(shù)據(jù)點集合中隨機(jī)選擇K個點作為聚類中心;
步驟2) 對數(shù)據(jù)集中的每個點x, 代入
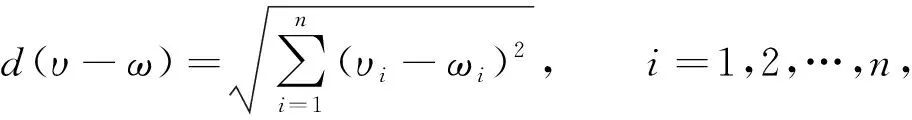
(4)
計算其與最近聚類中心(已選擇的聚類中心)的距離d(x);
步驟3) 將每個點按最近分配給每個聚類中心;
步驟4) 計算每個聚類群均值, 確定新聚類中心;
步驟5) 循環(huán)執(zhí)行步驟2)~4), 如新聚類中心不再移動, 則終止計算; 否則轉(zhuǎn)步驟2).
經(jīng)典的K-means算法具有快速、 簡單的優(yōu)點, 有良好的可伸縮性, 處理大數(shù)據(jù)集效率較高, 其時間復(fù)雜度為O(nTK), 接近于線性, 適合挖掘大規(guī)模數(shù)據(jù).但K值很難估計, 且初始點的選擇會極大影響迭代次數(shù)及最終結(jié)果.
2.2 密度值及信息熵
參考文獻(xiàn)[4]提出的密度計算方法.設(shè)數(shù)據(jù)集有n個樣本數(shù)據(jù)X={x1,x2,…,xn}, 樣本點xi的局部密度為ρi, 計算公式為
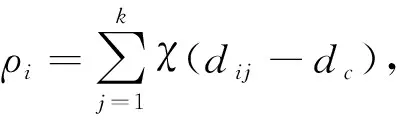
(5)
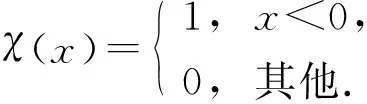
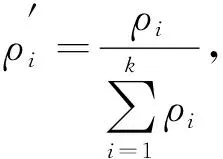
(6)
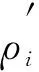
計算所有樣本的密度概率, 并引入信息熵作為目標(biāo)函數(shù), 信息熵是對聚類混亂程度的度量, 如果信息熵較大, 則表明聚類混亂程度較大, 信息熵較小則混亂程度較小.因此, 數(shù)據(jù)集混亂程度表示為

(7)
如果密度dc截距取值過大將導(dǎo)致局部密度概率值ρ′變小, 信息熵值過大, 則數(shù)據(jù)聚類不確定度過大; 如果dc過小將出現(xiàn)無法聚類的情形, 存在極值, 引入梯度下降法對信息熵進(jìn)行求極值, 確定其極值點, 并將極值點所在的dc作為最佳截距.
2.3 改進(jìn)K-means聚類算法
傳統(tǒng)K-means聚類算法選取初始聚類中心時, 由于算法自身的敏感性和隨機(jī)性, 易導(dǎo)致其聚類結(jié)果不穩(wěn)定, 因此目前已提出了許多初始聚類中心選擇改進(jìn)方案: 如文獻(xiàn)[6]提出了一種基于網(wǎng)格聚類與密度峰值的改進(jìn)初始聚類中心選擇算法; 文獻(xiàn)[7]提出了一種基于數(shù)據(jù)空間網(wǎng)格化的簇中心選擇算法. 本文受上述算法啟發(fā), 提出一種基于密度信息熵的初始聚類中心選取的改進(jìn)算法, 算法流程如下.
算法1初始化聚類中心算法.
輸入: 數(shù)據(jù)集陣列X,K值;
輸出:K個初始聚類中心數(shù)據(jù);
步驟1) 輸入樣本集X, 根據(jù)式(5)計算其密度值ρi;
步驟2) 根據(jù)式(6)計算局部密度概率ρ′, 并代入式(7)求出信息熵H的極值, 確定其最佳截距dc;
步驟3) 根據(jù)最佳截距排序并按密度值大小加入集合C中;
步驟4) 計算集合C中密度最大樣本數(shù)據(jù)與集合中其他密度中心的距離, 取最大距離為第二中心點;
步驟5) 再選擇與前兩個點最短距離最大的點作為第三個初始聚類簇的中心點, 以此類推求出K個中心并進(jìn)行聚類, 算法結(jié)束.
3 實驗結(jié)果與分析
選擇機(jī)器學(xué)習(xí)標(biāo)準(zhǔn)數(shù)據(jù)集和真實數(shù)據(jù)集作為實驗對象, 選擇K-means和基于密度的聚類(DBSCAN)算法進(jìn)行對比測試. 采用Python編程環(huán)境, 集成約200個包, 采用Win10系統(tǒng), 硬件環(huán)境為i7處理器, 16 GB內(nèi)存. 真實數(shù)據(jù)來源為UCI機(jī)器學(xué)習(xí)存儲庫中Online Retail Ⅱ數(shù)據(jù)集, 共計約54萬條數(shù)據(jù), 描述某線上銷售企業(yè)1年內(nèi)的銷售記錄. 銷售記錄含訂單號、 客戶號、 商品描述、 訂單金額、 生成訂單日期等數(shù)據(jù). 由于原始數(shù)據(jù)的質(zhì)量會影響TFA模型細(xì)分的結(jié)果, 因此真實數(shù)據(jù)實驗前需對原始數(shù)據(jù)進(jìn)行預(yù)處理, 首先清洗缺失值并利用Pandas聚合函數(shù)及統(tǒng)計中的四分位方法對原始數(shù)據(jù)中的異常值進(jìn)行過濾, 最后得到模型數(shù)據(jù).
3.1 算法實驗驗證
選取UCI中4個較有特色的人工數(shù)據(jù)集(Iris, Wine, Digits, Glass)作為算法驗證數(shù)據(jù)集. 將本文算法(Bwsf)實驗結(jié)果與K-means和DBSCAN算法結(jié)果進(jìn)行對比, 數(shù)據(jù)集屬性列于表2.

表2 人工數(shù)據(jù)集屬性
為有效統(tǒng)計并對比結(jié)果, 所有算法均在同一環(huán)境下運(yùn)行50次, 取相應(yīng)算法的最優(yōu)值和平均值作為分析數(shù)據(jù), 結(jié)果列于表3. 為更清晰地對比不同算法的差異, 圖1和圖2分別給出了不同算法的迭代次數(shù)和準(zhǔn)確率對比. 由圖1和圖2可見, 本文算法在迭代次數(shù)上效果較好, 在聚類準(zhǔn)確率上明顯更穩(wěn)定, 優(yōu)于K-means和DBSCAN算法.

表3 不同算法的測試結(jié)果
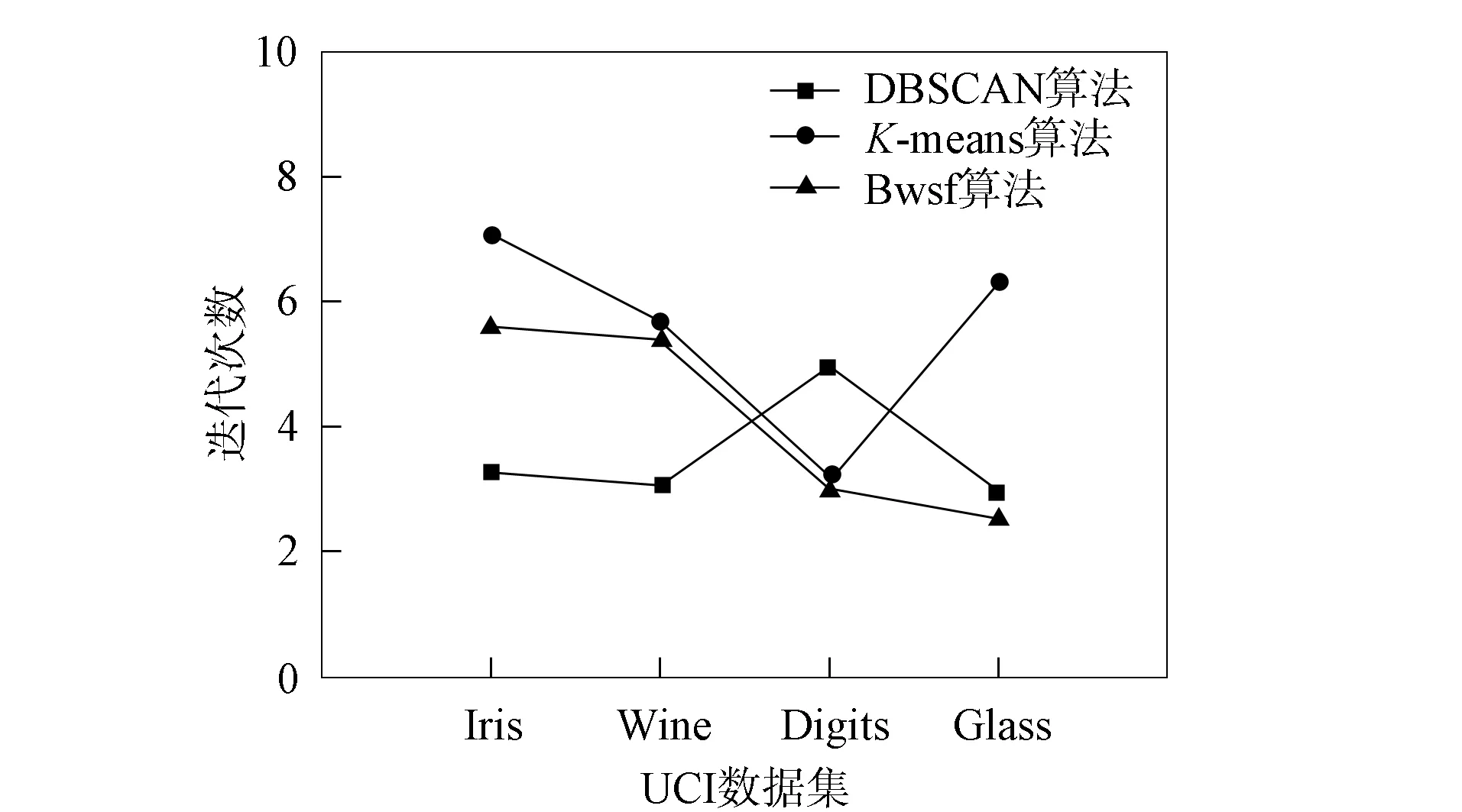
圖1 不同算法的迭代次數(shù)對比Fig.1 Number of iterations comparison of different algorithms
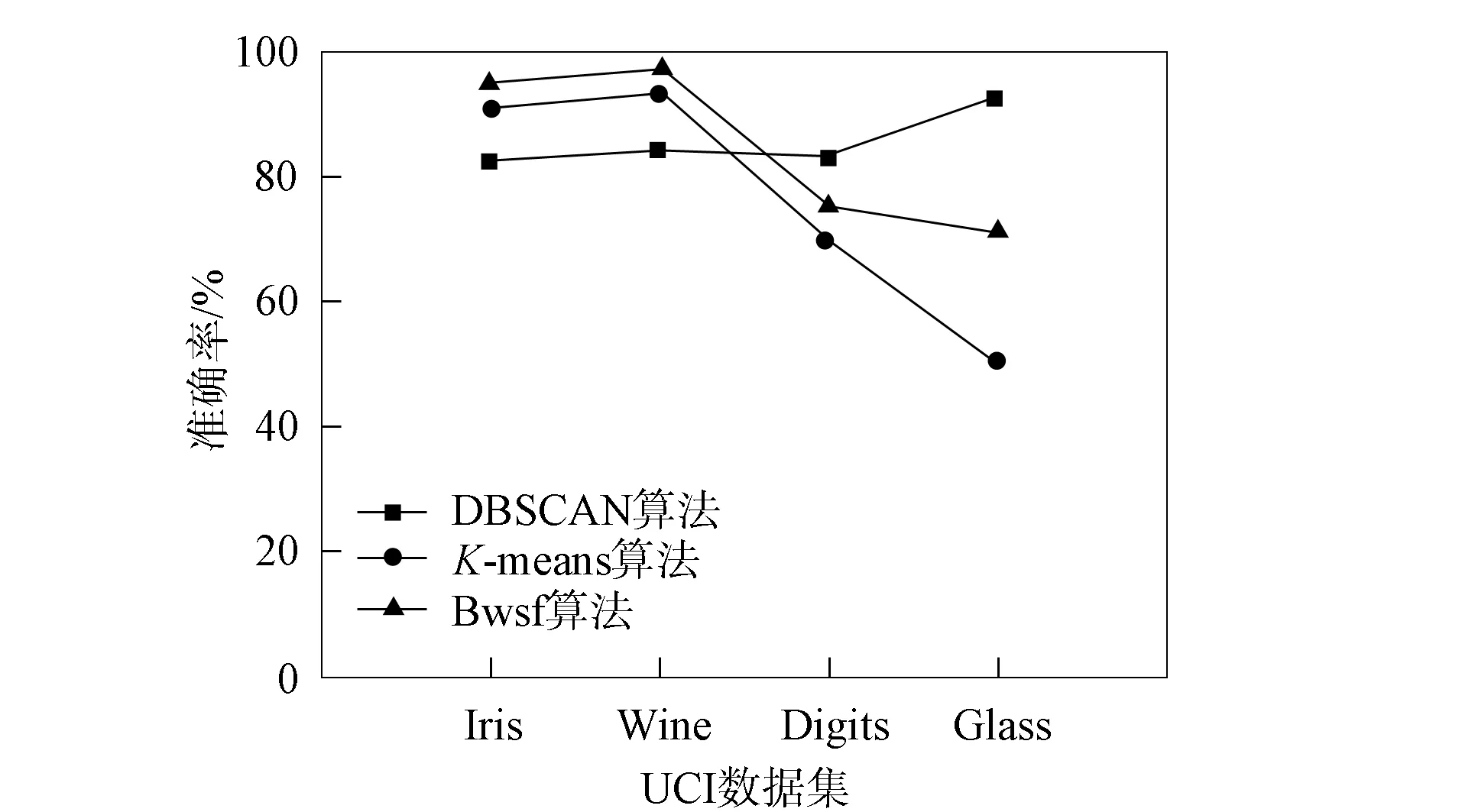
圖2 不同算法的準(zhǔn)確率對比Fig.2 Accuracy comparison of different algorithms
對降維后的人工數(shù)據(jù)集Iris,Wine,Digits及Glass使用本文算法同時進(jìn)行可視化處理, 結(jié)果如圖3所示. 由圖3可見, 聚類結(jié)果基本符合算法測試數(shù)值.

圖3 本文算法對各數(shù)據(jù)集的聚類結(jié)果Fig.3 Clustering results of each data set by proposed algorithm
由上述算法驗證結(jié)果可見, 改進(jìn)K-means算法優(yōu)化了聚類中心的選取, 并通過密度信息熵改善了原始算法易陷入局部最優(yōu)、 對非簇數(shù)據(jù)集聚類效果較差的情形, 對比密度聚類算法沒有數(shù)據(jù)的依賴性, 對于不同數(shù)據(jù)集有較強(qiáng)的兼容性, 并且適用于較大數(shù)據(jù)集的聚類.
3.2 真實數(shù)據(jù)集應(yīng)用
真實數(shù)據(jù)集經(jīng)過缺失值清理、 特征值、 四分位異常值清洗等處理后, 基于TFA模型, 從原始數(shù)據(jù)中生成模型指標(biāo), 需要對生成指標(biāo)進(jìn)行標(biāo)準(zhǔn)化處理. 常用方法有最小-最大標(biāo)準(zhǔn)化、Z-score標(biāo)準(zhǔn)化和均值歸一化等. 本文采用Z-score標(biāo)準(zhǔn)化方法對生成指標(biāo)進(jìn)行處理. 利用Numpy.std函數(shù)將模型指標(biāo)分別代入
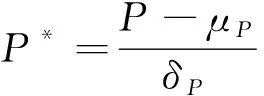
(8)
得到聚類算法的指標(biāo)屬性. 在K-means算法中, 為評估該改進(jìn)聚類算法聚類效果和K值的合適度, 本文選擇輪廓系數(shù)(silhouette coefficient)和Calinski-Harabasz指數(shù)對聚類結(jié)果進(jìn)行評估, 輪廓系數(shù)計算公式為
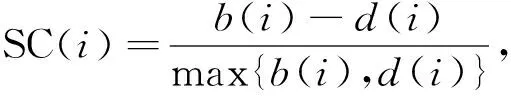
(9)
其中SC(i)∈[-1,1],b(i)表示第i個樣本到同簇所有樣本的平均距離,d(i)表示第i個樣本到其他簇平均距離中的最小平均距離.b(i)也稱為同簇的不相似度,d(i)也稱為簇間的不相似度.SC(i)值越大, 聚類效果越好, 對應(yīng)的K值為最佳聚類數(shù).Calinski-Harabasz指數(shù)的計算公式為
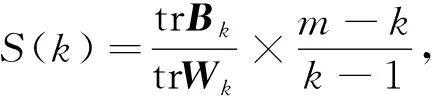
(10)
其中m為訓(xùn)練集樣本數(shù),k為聚類數(shù), tr為矩陣的跡,Bk和Wk分別為簇間協(xié)方差矩陣和同簇內(nèi)協(xié)方差矩陣.S(k)值越大聚類效果越好.
為驗證TFA模型, 本文根據(jù)聚類結(jié)果數(shù)據(jù)計算了輪廓系數(shù)和Calinski-Harabasz指數(shù), 并進(jìn)行數(shù)據(jù)可視化對比, 結(jié)果如圖4和圖5所示. 為驗證TFA模型聚類效果的有效性, 實驗對比了RFM模型聚類與TFA模型聚類輪廓系數(shù)(SC)與Calinski-Harabasz(CH)指數(shù)的結(jié)果, 不同模型的聚類評估對比結(jié)果列于如表4. 由表4可見: 當(dāng)K=6時, TFA模型在評估算法中SC值與CH值均最優(yōu); 而RFM模型在無監(jiān)督聚類算法中, 聚類效果不佳, 如在輪廓系數(shù)中最佳聚類為K=2, 但在CH聚類評估中最佳聚類為K=8.
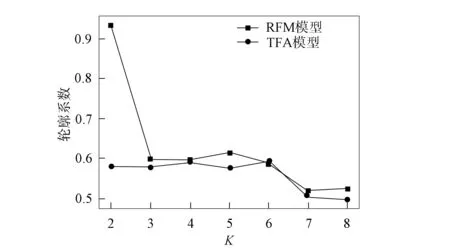
圖4 輪廓系數(shù)對模型的評估結(jié)果Fig.4 Evaluation results of contour coefficients on model
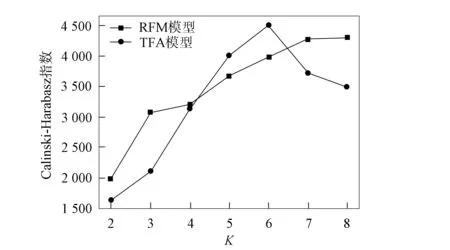
圖5 Calinski-Harabasz指數(shù)對模型的評估結(jié)果Fig.5 Evaluation results of Calinski-Harabasz index on model

表4 驗證算法結(jié)果
3.3 結(jié)果分析
無監(jiān)督聚類結(jié)果一般從模型參數(shù)指標(biāo)和聚類算法兩方面考慮, TFA模型調(diào)整了指標(biāo)參數(shù), 更能有效體現(xiàn)用戶分類的差異[8].
將TFA模型指標(biāo)分別經(jīng)改進(jìn)K-means算法聚類后按聚類中心值匯總, 并將每類中心值按模型權(quán)重計算總價值, 結(jié)果列于表5, 表5中“↑”表示聚類效果提升, “↓”表示聚類效果下降, “_”表示聚類效果不變.
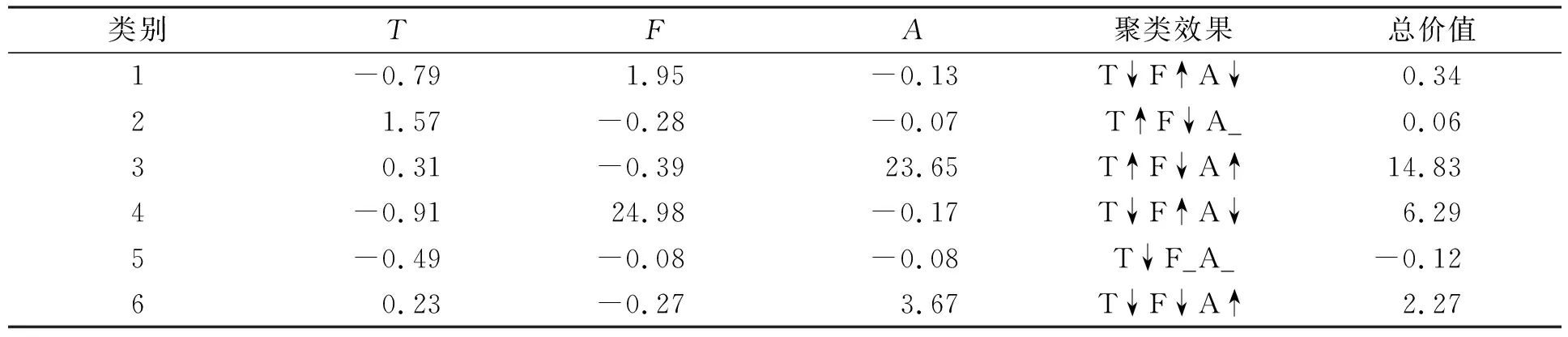
表5 TFA模型聚類分析結(jié)果
表6列出了TFA模型聚類客戶級別對比結(jié)果. 由表6可見, 在該數(shù)據(jù)集中鉆石型客戶只有0.14%, 其在返店指標(biāo)、 貢獻(xiàn)度上均為最高, 但其消費(fèi)頻度為均值左右, 說明該類鉆石型客戶購買的產(chǎn)品均為高價值產(chǎn)品且利潤較高; 高價值發(fā)展型客戶, 在購買頻次上最突出, 雖然其利潤較低, 但其未來發(fā)展有很高的提升空間, 其價值仍然很高; 較高價值發(fā)展型為1.31%, 其表現(xiàn)為返店指標(biāo)、 貢獻(xiàn)度上較高, 消費(fèi)頻度較低, 從指標(biāo)上判別有可能為新客戶中購買能力較強(qiáng)者; 低價值發(fā)展型客戶為5.86%, 其消費(fèi)頻次較高, 但因貢獻(xiàn)度較低, 其價值也較低, 但從發(fā)展的角度需要對其關(guān)注; 高價值維護(hù)型用戶所有指標(biāo)都接近均值, 而且數(shù)量較多, 占比為23.77%, 該類客戶為企業(yè)長期顧客, 相對穩(wěn)定; 低價值易損型客戶, 占比最大為68.83%, 這也是線上交易企業(yè)顧客流失率較高特點的體現(xiàn).
從改進(jìn)聚類算法性能分析, 由于本文算法數(shù)學(xué)模型較簡單, 其復(fù)雜度較低, 因此易理解. 從其聚類評價分析, 如果TFA模型都選K=6的情形, 由表4可見, TFA模型指標(biāo)使用本文算法比RFM模型使用本文算法有更好的聚類效果.

表6 TFA模型聚類客戶級別對比結(jié)果
綜上所述, 本文首先提出了一種基于客戶發(fā)展空間的客戶細(xì)分模型(TFA), 該模型使用客戶發(fā)展空間、 購買頻率、 平均購買額作為客戶分類指標(biāo)屬性, 并加入了基于層次分析法的權(quán)重系數(shù)使其能體現(xiàn)指標(biāo)屬性的重要程度. 其次, 本文提出了改進(jìn)的K-means算法, 通過引入密度信息熵初始中心選擇算法, 有效避免了原始算法在初始中心選擇上的不足. 最后, 通過人工數(shù)據(jù)集聚類準(zhǔn)確率和迭代次數(shù)等指標(biāo)及真實數(shù)據(jù)集聚類可視化分析進(jìn)行實驗, 實驗結(jié)果表明, 該方法的分類結(jié)果有效且運(yùn)行效率有所提升.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
