基于膠囊網絡的跨域行人再識別*
2021-09-23 01:21:22楊曉峰張來福王志鵬薩旦姆鄧紅霞李海芳
計算機工程與科學 2021年9期
楊曉峰,張來福,王志鵬,薩旦姆,鄧紅霞,李海芳
(1.太原理工大學信息與計算機學院,山西 晉中 030600;2.山西工程科技職業大學計算機工程學院,山西 晉中 030600; 3.國網山西省電力公司電力科學研究院,山西 太原 030001)
1 引言
行人再識別是在行人檢測的基礎上,對不同場景中的目標行人進行再次檢索。近幾年來,行人再識別受到國內外學者的廣泛關注,并取得了很大進步,但在跨域(數據集)測試中效果并不理想,在最新的跨域行人再識別研究中,R1平均準確率mR1(Mean Rank-1)最高只有43.6%。行人圖像特征表示能力不強是跨域行人再識別準確率不高的主要原因。
目前,基于圖像的行人再識別研究可以分為單一域行人再識別和跨域行人再識別。單一域行人再識別,按照分割圖像提取特征的方法可以細分為3類:僅使用行人整體信息進行特征提取的方法[1 - 5]、僅使用行人局部信息進行特征提取的方法[6,7],以及使用行人整體信息和局部信息結合進行特征提取的方法[8 - 10]。鄭鑫等[3]將行人圖像的多種屬性與注意力機制相結合提高行人再識別準確率;Zhao等[7]利用行人肢體分割網絡將行人圖像進行分割;Zhao等[10]采用將人體骨架分割的思想,將人體分割成14個連接點后再組合成6個區域,用于提取局部特征。跨域行人再識別方法可以細分為5類:基于風格遷移的方法[11 - 14]、基于圖卷積神經網絡的方法[15]、基于字典學習的方法[16]、基于特征對齊的方法[17]和基于多屬性學習的方法[18,19]。Deng等[11 - 14]通過對抗生成網絡實現測試域樣本的風格遷移,目的是使模型可以學習到測試域的風格信息。潘少明等[15]利用圖卷積神經網絡建立了訓練域和測試域近鄰樣本的跨域相似度聯系方法,該方法在訓練時需要聯合訓練域和測試域。Peng等[16]提出在訓練域和測試域上同時進行字典學習,獲取不同域之間的共有特征,用于跨域行人再識別。Lin等[17]在跨域行人再識別任務中采用了中間層特征對齊方法。Su等[18,19]分別通過采集行人的多種屬性來提高跨域行人再識別的準確率。
這些跨域行人再識別方法存在一個共同點,它們都采用了基于CNN(Convolutional Neural Networks)的特征提取方法。但是,基于CNN的特征提取方法依然存在問題:由于頻繁使用池化層,CNN各層之間傳遞信息損失大量存在[20];CNN模型過度依賴樣本的數量; CNN特征不能很好地反映特征與整體之間的空間關系[21]。由于上述這些問題,基于CNN提取的特征,其表示能力受到了限制。
為了彌補CNN的不足之處,Sabour等[21]提出了膠囊網絡。膠囊網絡具有良好的特征表示能力[20,22];在數據樣本較少和類不平衡的情況下,膠囊網絡也能保持良好的性能[20,21];膠囊網絡使用了新的動態路由算法,性能優于反向傳播算法[20,21]。通過對比CNN網絡和膠囊網絡,本文選用膠囊網絡為基礎網路并對其進行改進。膠囊網絡存在的不足之處主要有2點:由于膠囊網絡屬于淺層網絡,當輸入空間維度較大時,膠囊網絡無法有效降低中間層特征維度,會消耗大量計算資源,導致算法運行緩慢;膠囊網絡中耦合系數有極小化趨勢[23],不利于梯度反向傳播。
針對膠囊網絡存在的問題和跨域行人再識別任務的要求,模型改進所面臨的最大挑戰是:既要增加網絡深度,降低特征空間維度,又要求模型具備淺層網絡的泛化性能。本文提出了深度膠囊網絡,并且利用深度膠囊網絡實現了一種基于無監督學習的跨域行人再識別方法。通過視角分類訓練任務,本文模型可以獲取圖像中更有鑒別性的特征,這些特征可以直接遷移到跨域行人再識別任務中。特征提取過程沒有利用測試域的任何信息,這是區別于目前所有跨域行人再識別方法的一個重要特點。在實驗中,為了降低難度,本文設計的視角分類訓練任務只設置了3種視角:正面、側面和背面。實驗結果表明,本文方法優于目前所有的無監督學習行人再識別方法,具有良好泛化能力。
本文的主要貢獻是:
(1)采用乘法短連接結合改進的動態路由算法,緩解了深度膠囊網絡梯度消失的問題;
(2)重新設計了特征提取層,充分利用乘法短連接的特性,提升了膠囊網絡的高維信息處理能力,并具有良好的泛化能力。
2 相關工作
2.1 膠囊網絡
2017年,Sabour等[21]提出了膠囊網絡,采用動態路由機制,在多個數據集上取得了最優的分類性能。膠囊的概念在2011年由Hinton提出,膠囊是一組神經元,可以表示特定類型的對象或對象部分的實例化參數[21],實例化參數包括位置、紋理、形狀和顏色等特征。目前,改進膠囊網絡有很多方法,Fang等[24]設計了雙輸入端的Inception特征提取層,2種輸入包括HHBlits蛋白譜和形狀預測串;Chen等[25]將膠囊網絡應用于原始震動信號的故障檢測;Yang等[26]研究了自然語言處理中膠囊網絡效率問題,提出了3種改進策略;Zhang等[22]結合膠囊網絡設計了文檔語法規則網絡。
2.1.1 算法描述
膠囊網絡由3部分組成:
第1部分是特征提取層。特征提取層由一層卷積和ReLU 激活函數組成,卷積核尺寸是9×9,輸入通道數為3,輸出通道數為256。
第2部分是初級膠囊層,如式(1)所示。初級膠囊層由8組卷積和Squash激活函數組成,卷積核尺寸是9×9,輸入通道數為256,卷積輸出張量為z(6×6×32)。初級膠囊層輸出矩陣u(1152×8),其包含1 152(6×6×32)個膠囊,每個膠囊由包含8個特征維度的向量表示,如式(1)所示:
(1)
其中,ζ表示Squash激活函數,如式(2)所示;zP表示第p組卷積輸出的張量,P表示膠囊中特征的維度,p∈{1,…,P},P=8[21]。
(2)
其中,o表示輸入向量(膠囊)。
第3部分是數字膠囊層(Digit Capsule Layer)。數字膠囊層由動態路由算法構成,如算法1所示,其中輸入膠囊由ui表示,ui∈u,u表示所有輸入層的膠囊;輸出膠囊由vj表示,每個輸出膠囊表示一種分類。輸入膠囊和輸出膠囊關聯方式類似于全連接方式。bij表示第i個輸入膠囊對第j個輸出膠囊的關聯強度,bij∈bi,bi表示所有與輸入膠囊ui相關的關聯強度。關聯強度bij經過Softmax函數運算生成耦合系數cij,cij∈ci,ci表示所有與輸入膠囊ui相關的耦合系數。wij表示對輸入膠囊(ui)進行仿射變換。
算法1動態路由算法
輸入:輸入膠囊向量ui。
輸出:輸出膠囊向量vj。
初始化:bij←0。
步驟1ci←Softmax(bi);/*i為輸入膠囊編號*/
步驟2sj←∑icijwijui;/*j為輸出膠囊編號*/
步驟3vj←Squash(sj);//定義如式(2)所示
步驟4bij←bij+wijuivj;
步驟5迭代r次執行步驟1~步驟4;
步驟6迭代結束,輸出預測膠囊向量vj。
2.1.2 膠囊網絡缺陷
膠囊網絡模型主要有2個缺點:
(1)由于膠囊網絡屬于淺層網絡,當輸入空間維度較大時,膠囊網絡將占用大量的計算資源和存儲空間;
(2)由于膠囊網絡中數字膠囊層的部分耦合系數(ci)有極小化的趨勢[23],導致梯度損失,網絡的中間層無法得到重分訓練。
2.2 短連接
科研人員對短連接的研究已經有很長的時間[27 - 29]。早期的短連接是將線性單元應用于多層感知機網絡[28,29],連接網絡的輸入端和輸出端。Szegedy等[30,31]使用短連接將中間層與輔助分類器相連,解決了梯度消失和梯度爆炸的問題。文獻[30]中,Inception模塊也包含短連接,增強了特征的表示能力。He等[32 - 34]對短連接進行了深入研究,通過短連接成功解決了深度神經網絡梯度消失和梯度爆炸的問題。不同的是,He等[32]使用了加法短連接,而Srivastava等[33,34]使用了乘法短連接,乘法短連接也稱為門控機制或空間注意力機制。Wang等[35]將2種短連接方式融合,提出了殘差注意力學習。Yang等[36]在注意力行人再識別網絡中使用了短連接。
以二維輸入信息為例,乘法短連接的數學表示如式(3)所示,加法短連接的數學表示如式(4)所示:
Og(X)=X?G(X)
(3)
Or(X)=X+R(X)
(4)
其中,X表示二維輸入信息,Og(X)∈Rm×n表示乘法短連接的輸出信息,G(X)∈Rm×n表示X的門控信息,R(X)∈Rm×n表示殘差運算單元,?表示矩陣對應元素乘法,+表示矩陣加法。
3 問題定義
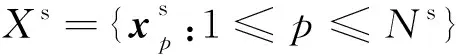
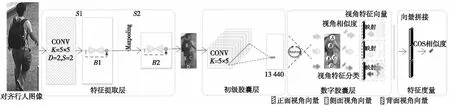
Figure 1 Deep capsule network and feature metric圖1 深度膠囊網絡以及特征度量
4 深度膠囊網絡
針對2.1.2節中提到膠囊網絡的2個缺點,本文通過重新設計特征提取層和改進數字膠囊層動態路由算法,提出了深度膠囊網絡DCapNet(Deep Capsule Network)。
4.1 加深特征提取層
將膠囊網絡應用于復雜任務時,由于其屬于淺層網絡,無法對高維輸入空間進行有效的降維,會導致初級膠囊層輸出過多的膠囊,進而會導致數字膠囊層的運算量成倍增加,膠囊網絡運行效率十分低下。解決這個問題最直接的方法就是加深膠囊網絡的特征提取層,控制初級膠囊層輸入空間的維度。
本文設計的特征提取層結構有6層(不包括ReLU層),結構如圖1所示,關鍵參數如表1所示。其中包括:空洞卷積層、最大池化層,模塊1(B1)和模塊2(B2)。空洞卷積層用于初次特征提取以及特征降維,空洞卷積核K=5×5,空洞系數D=2,跨步S=2。最大池化層用于特征降維,為了減少池化操作帶來的特征損失,設計中限制了池化層的數量。為了避免加深特征提取層帶來的梯度問題,本文將ResNet[32]中的殘差塊結構作為B1和B2的基本結構,如圖2a所示。另外,鑒于Bottleneck[32]設計可以減少計算量,在殘差塊的基礎上,將B1和B2中卷積層(conv1.1和conv2.1)的輸出通道分別減少一半,卷積層(conv1.2和conv2.2)的輸入通道數減半,結構參數如圖2b和表1所示,B1和B2整體計算量減少了一半。最后,考慮到跨域識別的應用背景對模型的泛化能力要求較高,并且受到文獻[33,37]的啟發,將B1和B2中的加法短連接替換為乘法短連接,B1和B2的最終設計如圖2c所示。下文從理論和實驗兩個方面對比2種短連接方法,以證明乘法短連接更適用于解決跨域問題。
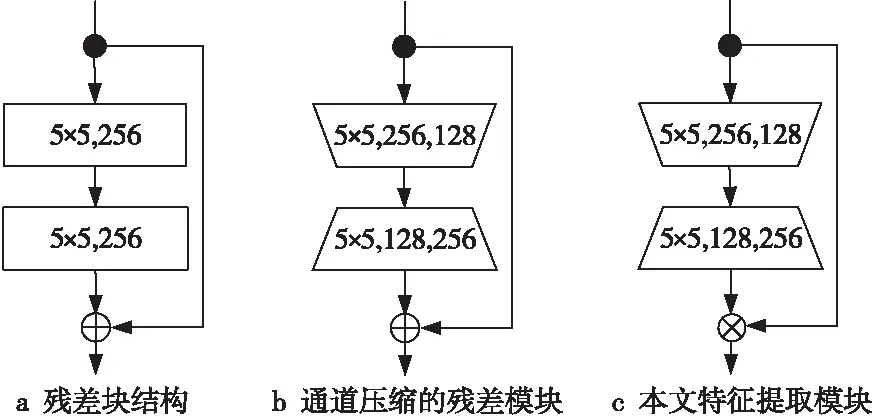
Figure 2 Basic block in feature extraction layer圖2 設計特征提取層基礎模塊
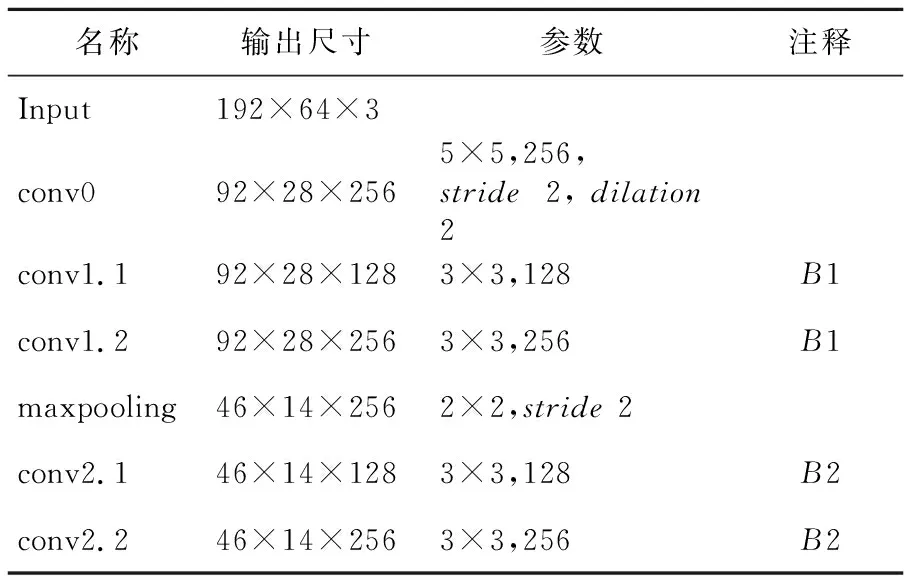
Table 1 Parameters of feature extraction layer
乘法短連接被Dauphin等[37]用于門控線性單元,有效緩解了梯度消失問題,模型收斂速度更快。乘法短連接如式(3)所示,對式(3)求導得到式(5):
(5)
加法短連接是目前解決梯度消失最常用的方法。對式(4)求導得到式(6):
(6)
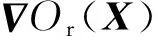
通過理論對比,本文選擇了乘法短連接,不僅可以緩解梯度消失問題,還可以增強特征表達能力,增強模型泛化性能。本文實驗中也對比了2種連接方式,以證實乘法短連接的泛化性能優于加法短連接。
4.2 改進數字膠囊層
文獻[23]研究表明,數字膠囊層動態路由算法的耦合系數的極小化趨勢,會引起梯度消失問題。本文通過修改耦合系數生成函數,緩解了耦合系數的極小化趨勢。
耦合系數由Softmax函數生成[21],Softmax函數定義如式(7)所示:
(7)
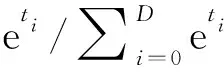
為了緩解極小化趨勢,本文為Softmax函數增加了線性修正項m(T),如式(8)所示:
(8)
本文定義的耦合系數函數如式(9)所示:
α> 0,β> 0
(9)
其中α和β為比例系數,實驗中分別選取9和1。
Softmax函數、m函數以及msoftmax函數的對比如圖3所示。從圖3中可以看出,輸入向量中較小元素對應的輸出得到了一定提升,由圓圈標出。
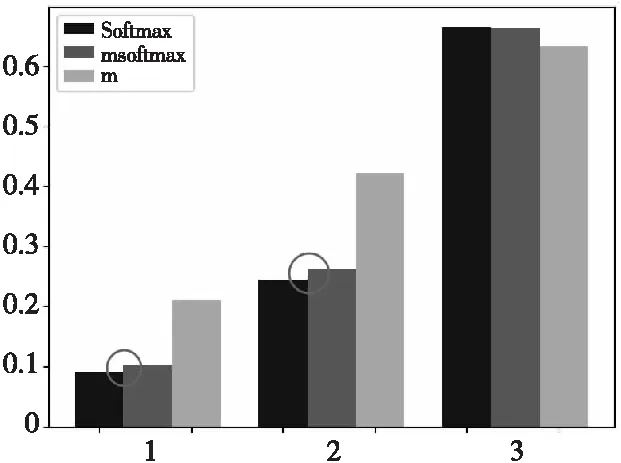
Figure 3 Comparition of softmax,m and msoftmax when input vector is (1,2,3)T圖3 輸入向量為(1,2,3)T 的Softmax函數、 m函數和msoftmax函數輸出對比圖
改進的數字膠囊層動態路由算法如算法2所示。
算法2改進的動態路由算法
輸入:輸入膠囊向量ui。
輸出:輸出膠囊向量vj。
初始化:bij←0。
步驟1ci←msoftmax(bi);/*定義如(9)式,i為輸入膠囊編號*/
步驟2sj←∑icijwijui;/*j為輸出膠囊編號*/
步驟3vj←Squash(sj);//定義如式(2)所示
步驟4bij←bij+wijuivj;
步驟5迭代r次執行步驟1~步驟4;
步驟6迭代結束,輸出預測膠囊向量vj。
4.3 損失函數
本文模型的損失函數由2部分組成:一是行人圖像視角分類損失函數,二是行人分類損失函數,如式(10)所示:
L=LMargin+ηLQuadCosine
(10)
其中,LMargin表示行人圖像視角分類損失函數;LQuadCosine表示行人分類損失函數;η為比例系數,用于調節LMargin和LQuadCosine的權重比。
行人圖像視角分類損失函數LMargin具體表示如(11)式所示:
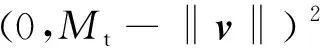
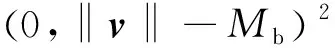
(11)
其中,V表示行人圖像特征向量集合;Tc表示是否為同一視角,如果V屬于該視角則Tc=1,否則Tc=0;Mt為正樣本分類值最大下界;Mb為負樣本分類值最小上界;λ為正負樣本分類損失權重。LMagin的值反映了行人圖像視角分類的可信度,其中特征向量vi的模長表示與某個視角的相似性。
行人分類損失函數LQuadCosine具體表示如式(12)所示:
β1(max(0,cos(vi,vk)-margin1)+
max(0,cos(vi,vl)-margin1))+
β2max(0,cos(vl,vk)-margin2)),
si=sj,si≠sl,si≠sk,
vi∈V,vj∈V,vk∈V,vl∈V
(12)
其中,si,sj,sk,sl分別表示vi,vj,vk,vl的行人ID,margin1表示正負樣本對特征最小距離,margin2表示負負樣本對特征最小距離,β1表示正負樣本對損失函數系數,β2表示負負樣本對損失函數系數。LQuadCosine用于懲罰類內距離大而類間距離小的情況。
本文通過實驗確定了超參數Mt,Mb,λ,β1,β2,margin1和margin2的值,分別為:Mt=0.9,Mb=0.1,λ=0.5,β1=1,β2=1,α=0.2,margin1=0.5,margin2=0.5。
5 實驗與結果分析
5.1 模型訓練測試以及評價標準
本文在CUHK03數據集上進行有監督訓練生成模型,測試分別在Market1501、VIPeR和PRID450S數據集上單獨進行。CUHK03數據集由香港中文大學采集,數據集中包含1 467個行人的28 194幅圖像。Market1501數據集由清華大學采集,數據集中包含1 501個行人的32 668 幅圖像。VIPeR數據集由加州大學圣克魯斯分校采集,數據集中包含632個行人的1 264幅圖像。PRID450S數據集由奧地利科技學院協助采集,數據集中包含450個行人的900幅圖像。CUHK03、Market1501、VIPeR和PRID450S這4個數據集在4種不同的環境中采集,分別屬于4個不同的域,模型的訓練和測試分別在不同的域中進行,所以稱之為“跨域”行人再識別。訓練模型時,學習率LR設為0.000 01,批大小BS設置為4,動態路由算法迭代次數為1,輸入圖像尺寸為192×64。
本文選用的模型評價指標為R1和mR1。R1表示在某個數據集上搜索結果中第1幅行人圖像即是正確結果的概率。mR1表示多數據集R1準確率的平均值,綜合反映算法泛化能力。R1和mR1的計算方法分別如式(13)和式(14)所示:
R1=N1/N
(13)
(14)
其中,N1表示檢索結果中首位命中的數量,N表示被檢索的行人數量,M表示測試域的數量,R1i表示第i個域的R1準確率。
5.2 對比其他跨域行人再識別方法
表2為本文所提方法在VIPeR、PRID450S和Market1501數據集上與目前基于深度學習的最優跨域學習行人再識別方法比較結果。
表2結果表明:在VIPeR數據集上,R1值從39.1%提高到50.2%,提高了11.1個百分點。在PRID450S數據集上,R1值從35.1%提高到58.6%,提高了23.5個百分點。在Market1501數據集上,雖然本文算法的R1值沒有超過PAN算法的,但只落后8.4個百分點。計算3個數據集上的R1平均準確率mR1,本文方法的mR1為54.7%,比第2名MMFA的高出11.1個百分點。通過上述分析可得,本文提出的方法是目前最佳跨域行人再識別方法。
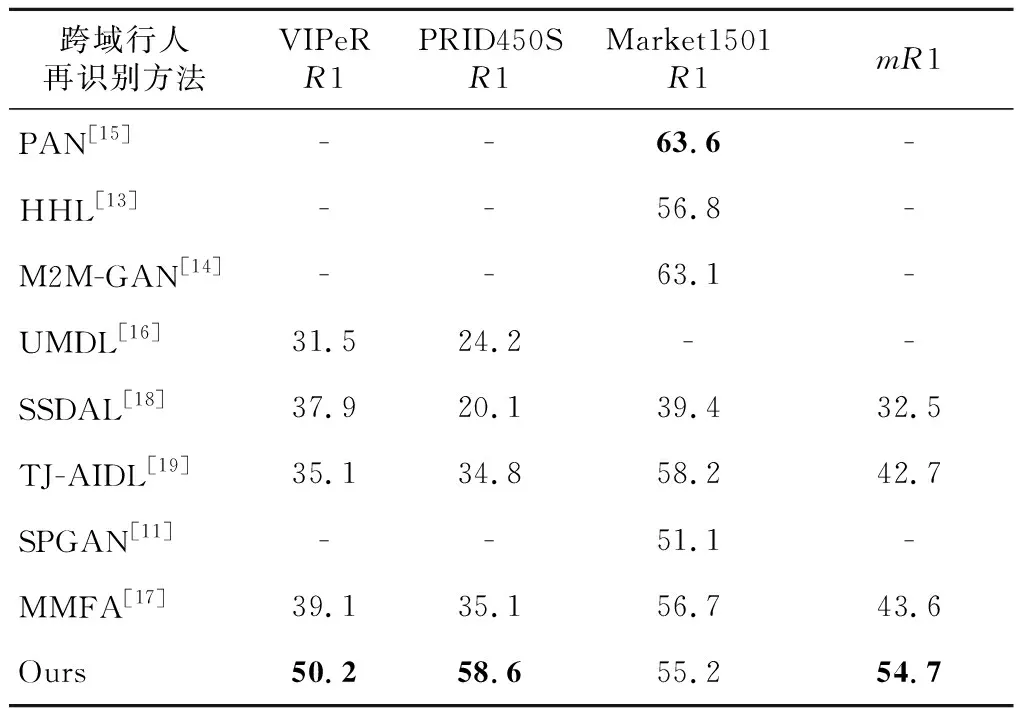
Table 2 Comparison of different unsupervised methods 表2 與跨域行人再識別方法對比 %
5.3 對比2種短連接對模型泛化能力的影響
本節在Market1501數據集上測試加法短連接和乘法短連接對本文模型泛化能力的影響。將圖1中B1和B2中的乘法短連接改為加法短連接,測試結果如表3所示。

Table 3 Comparison of addition shortcut and multiplication shortcut表3 加法短連接和乘法短連接的泛化能力對比
從對比結果可以看出,采用加法短連接的R1準確率(Market1501)為51.5%,而采用乘法短連接的R1準確率(Market1501)為55.2%,高出3.7個百分點。對比說明,采用乘法短連接更有助于提高模型的泛化能力。
5.4 對比不同參數耦合系數函數對模型的影響
本文定義的msoftmax耦合系數函數(式(9))中包含2個超參數α和β。本節在Market1501數據集上,對于不同α和β數值組合進行了對比實驗,結果如表4所示。超參數(α,β)選取3種不同組合:(1,0),(9,1),(8,2)。從對比結果可以看出,(9,1)組合測試結果最好,高出第2名(1,0)組合0.3個百分點,說明改進的耦合系數函數緩解了膠囊網絡的梯度問題。

Table 4 Comparison of different coupling coefficients表4 耦合系數函數不同參數組合對比
5.5 對比不同特征提取方法對模型的影響
本文設計的特征提取過程分為2個階段S1和S2,如圖1所示。S1包括空洞卷積層和B1,S2包括池化層和B2,S2在S1的基礎上進一步降維,確保特征提取層輸出特征的維度降到合理范圍。此外,還有另一種更為簡單的降維方法:只使用S1(空洞卷積層和B1)并且在圖像預處理時直接縮小圖像尺寸。這2種方法都可以有效降低特征提取層輸出維度,區別在于第2種方法使用預處理降維代替了S2降維。
第1種方法的輸入圖像尺寸為192×64,用DCapNet(B1+B2)表示。第2種方法的輸入圖像尺寸為120×40,用DCapNet(B1)表示。本節對比了這2種特征提取層方法對模型準確率的影響,對比結果如表5所示。本文選用的結構DCapNet(B1+B2)的準確率高出DCapNet(B1)的0.8個百分點。對比說明,設計S2階段是非常有必要的,比直接減小輸入空間維度(圖像尺寸)效果好。
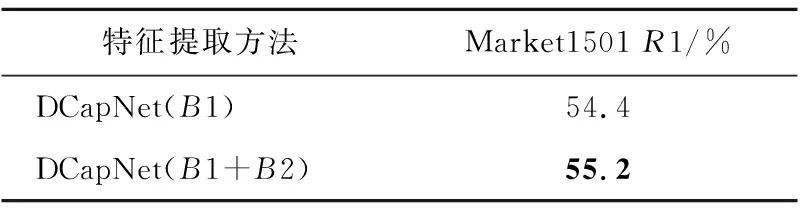
Table 5 Comparison of different feature extraction methods表5 不同的特征提取方法對比
5.6 實驗結果
圖4所示為本文方法在Martket1501數據集上的測試結果,從測試結果中可以看出:給定行人正面圖像可以正確找到側面和背面圖像,如圖4a所示;給定行人側面圖像可以正確找到正面和背面圖像,如圖4b所示;給定行人背面圖像可以正確找到側面和正面圖像,如圖4c所示。上述分析表明,本文方法可以通過正面、側面和背面行人圖像查找到其他角度的行人圖像,證明本方法有效。

Figure 4 Results on Martket1501圖4 在Martet1501數據集上的測試結果
6 結束語
本文提出了基于無監督跨域行人再識別方法,通過視角分類任務訓練,模型獲取的行人特征可以直接遷移到行人再識別任務中。本文方法基于改進的膠囊網絡模型DCapNet實現。通過改進膠囊網絡的特征提取層和動態路由算法,DCapNet提升了處理大維度輸入空間的能力,緩解了梯度消失問題。通過實驗可知,本文提出的方法優于其他無監督行人再識別方法。后續工作將進一步研究特征表示方法,提高跨域行人再識別準確率。
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年11期)2017-04-04 02:52:58
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
