一種面向蔬菜中文知識圖譜表示學習的改進方法*
2021-09-23 14:19:20杜亞茹黃媛高欣娜武猛李海杰楊英茹
中國農機化學報 2021年9期
關鍵詞:模型
杜亞茹,黃媛,高欣娜,武猛,李海杰,楊英茹
(1. 石家莊市農林科學研究院,石家莊市,050041; 2. 石家莊市農業信息化工程技術創新中心,石家莊市,050041;3. 河北省都市農業技術創新中心,石家莊市,050041)
0 引言
隨著信息社會的發展,海量的開放鏈接數據和用戶生成的內容在互聯網上發布和共享[1],人們迫切地需要建立標準化的知識模型以解決知識的共享問題。由Google公司提出的知識圖譜,以知識單元為基礎,快速把握學科前沿領域[2]。知識圖譜作為增強搜索功能的知識庫,近幾年得到迅速的發展。
人們通常采用語義網絡圖的形式來組織知識圖譜中的知識條目,圖中的節點表示實體,邊表示關系。近年來,隨著深度學習技術的發展,表示學習技術以分布式表示為理論基礎,旨在將知識圖譜中的實體和關系用一組低維實值的向量進行表示,很大程度上解決了網絡形式的表示方法在計算過程中面臨的計算效率和數據稀疏問題。知識表示學習模型,最初是建立在知識圖譜的基礎上,但是它貫穿在整個知識圖譜的構建過程中,不僅可用于信息抽取[3],還可以應用在知識融合[4]和知識推理等方面[5-6]。隨著Mikolov等在2013提出word2vec[7],知識的表示學習技術越來越受到重視。Word2vec是一款將詞表征為實數值向量的工具包,該工具包主要利用深度學習的思想,通過訓練可以將文本內容轉化為向量來完成信息處理,并通過計算向量間的差值來衡量對應文本內容的語義相似度。在此基礎上,Bordes等提出表示學習的翻譯模型TransE,TransE模型是一種簡單有效的表示學習方案,其主要思想是將知識圖譜中的關系看作頭實體到尾實體的一種翻譯操作。近幾年來,許多研究者對TransE進行擴展,先后提出了TransH,TransAH[8],TransR,TransD,PTransE,STransE[9]等模型對復雜關系進行建模,但是不同的模型有不同的局限性,還需根據領域和數據集的特點進行針對性的拓展。由于大多數的表示學習技術針對大規模的英文全局知識圖譜,如趙明等[10]利用本體費分類關系的提取方法構建基于植物領域知識圖譜,但基于中文蔬菜領域知識圖譜的表示學習技術的研究卻鮮見報道,隨著農業大數據時代的到來[11],這方面的研究和應用越來越重要。因此,本文在蔬菜信息領域,研究基于多種數據源構建蔬菜知識圖譜的方法,在知識圖譜的構建、命名實體識別和基于知識圖譜的語義檢索等方面展開工作,并在TransE翻譯模型基礎上進行改進,對該領域一對多、多對一和多對多的復雜屬性關系進行表示學習。
1 研究方法
1.1 TransE模型改進
蔬菜領域的概念體系結構較復雜,實體的屬性關系也復雜多樣,比如蔬菜領域涉及蔬菜生長發育規律及其與外界環境條件的關系、病蟲害防治、土壤與營養、栽培技術、輪作套種和遺傳育種等方面,其中,一個屬性關系往往包含兩個或兩個以上的屬性值,這給表示學習造成了極大的困難,使得蔬菜乃至整個農業領域中,基于知識圖譜的表示學習技術研究相對薄弱。
TransE模型雖然在知識表示學習的過程中發揮了令人滿意的效果,但該模型在處理不同類別關系的時候學習的效果不同。由TransE模型的原理可知,對于一個三元組(h,r,t)(h表示頭實體,r表示關系,t表示尾實體),學習目標是h+r≈t,對于同一個頭實體和關系來說,不同的尾實體在向量空間中趨于同一點。例如:(西紅柿,病害是,條腐病)和(西紅柿,病害是,細菌性葉斑病),將這兩個三元組映射到同一個低維的向量中,條腐病和細菌性葉斑病趨于重合。條腐病和細菌性葉斑病對于都屬于西紅柿的病害這一點雖然相似,但從二者的癥狀來看,發病原因和防治辦法等均不同。所以,TransE忽略了同類別向量的語義差別,在表示1-1關系的時候學習效果較好,但是在處理1-N,N-1,N-N等復雜的關系這些相似的情況時學習效果較差,從方法本身對于不同類別關系的表示就存在一定的局限性。
本文針對蔬菜領域知識圖譜的實體和關系特點,提出PTA(Path-based TransE for Attribute)模型,在TransE模型的基礎上進行改進,借助路徑表示學習模型解決該領域復雜屬性關系(一對多、多對一和多對多)表示學習問題[12]。
從蔬菜領域知識圖譜的構建過程中可以看出,除了上下位關系,蔬菜領域包括大量的非分類關系,其中實體間的非分類關系(諸如輪作關系、間作關系等)只占小部分,絕大部分是屬性關系。屬性關系具體包括:病害有、蟲害有、營養價值、藥用價值、生長環境等,而且該領域中,屬性關系一般包含兩個或兩個以上的屬性值。例如,(h張三,r1出生城市,e1石家莊),(e1石家莊,r2是省會城市,e2河北省),(e2河北省,r3隸屬國家,t中國)。從以上三個三元組中可以得出,h實體張三和t實體中國之間可以通過r1出生城市,r2是省會城市,r3隸屬國家三個關系共同構成,如此推理可得到一個新的三元組(h張三,r出省國家,t中國)。當然,這屬于典型三階關系推理,在蔬菜領域,由于含有的實體數量較少,關系路徑沒有如此復雜,而且關系主要集中在屬性關系,因此,受到路徑推理的啟發,PTA模型的目的在于借助路徑推理的思想來表示蔬菜領域知識圖譜中復雜的屬性關系,并將路徑也一起映射到低維的實值向量空間中。
1.2 PTA原理

但是針對蔬菜領域屬性關系的復雜性,本文做出兩個基本假設:第一,蔬菜領域三元組種所包含的蔬菜實體名稱和屬性值均歸為實體范疇;第二,為屬性關系涉及到的上下位關系ISA增加方向關系FISA,例如,三元組(青稞病,ISA,病害名稱)和(病害名稱,FISA,青稞病)表示的語義關系均為“青稞病是一種病害名稱”,知識由于頭實體和尾實體互換了位置,導致上下位關系的名稱發生了變化。
與人物關系圖譜,歌曲圖譜或中醫藥知識圖譜不同,蔬菜領域所包含的實體間關系較少,主要的關系為輪作,間作等關系,除此之外,均可以歸為屬性關系。屬性關系又根據其復雜度進行歸類,主要包含以下4個類別。
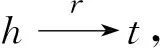
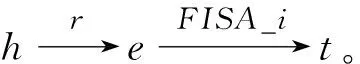
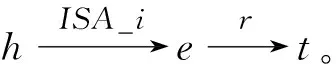
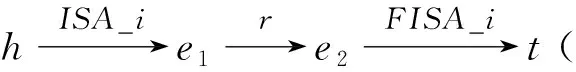
圖1的四幅圖分別表示了以上四種屬性關系的路徑規劃示意圖,實心的圓圈表示蔬菜領域知識圖譜中已有的實體,空心的圓圈表示增加的屬性模糊實體。該屬性模糊實體的增加主要體現在三元組的數據集中,如圖1(b)所示,三元組(西紅柿,別名是,番茄)和(西紅柿,別名是,蕃柿)轉化為三元組(西紅柿,別名是,別名屬性),(別名屬性,FISA,番茄),(別名屬性,FISA,蕃柿),其中,“別名屬性”作為屬性模糊實體來處理。

(a) 1-1關系 (b) 1-N關系
PTA對于每一個三元組(h,r,t)也定義了相應的能量函數
G(h,r,t)=E(h,r,t)+E(h,p,t)
(1)
式中:E(h,r,t)——三元組實體間存在直接關系的相關性;
E(h,p,t)——三元組(h,p,t)的能量函數,涉及到關系路徑p的向量化表示。
1.3 關系路徑的向量化表示
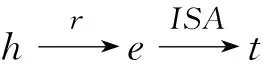
(2)
關系路徑向量p=(r1,r2)可以由三種不同的運算方式得到,其中r1和r2分別表示兩種關系。
1) 相加(ADD)。加法運算即將關系路徑所包含的所有關系向量進行相加操作。
p=r1+r2
(3)
2) 相乘(MUL)。乘法運算即將關系路徑所包含的所有關系向量進行相乘操作,在語義網中,相加和相乘算法已被廣泛應用于相關短語和句子的合成任務中。
p=r1·r2
(4)
3) 循環神經網絡(RNN)。循環神經網絡在語義組成上也被廣泛應用。
ci=f([ci-1;ri])
(5)
式中:f——一個非線性的函數;
[ci-1;ri]——兩個向量的聯結。
通過設置c1=r1來對關系路徑進行基于循環神經網絡的迭代,最后得到p=cn。對于一個屬性關系路徑三元組(h,p,t),本文定義的能量函數為E(h,p,t)=‖h+p-t‖,但是,由于上述工作已經對直接關系三元組(h,r,t)求出了E(h,r,t)=‖h+r-t‖的最小值來保證r≈t-h,在此可直接獲得屬性關系路徑的能量函數,當屬性關系路徑p與直接關系r一致的時候,可同時獲取其最小值。
E(h,p,t)=‖p-(t-h)‖=‖p-r‖
=E(p,r)
(6)
2 試驗結果與分析
2.1 數據采集和預處理
首先需要從百度百科和互動百科中下載蔬菜詞條作為構建蔬菜領域知識圖譜的語料。由于百科詞條中均缺乏準確詳細的分類標簽,因此需要先構建蔬菜詞表,根據已有的蔬菜領域本體結構框架得到蔬菜實體的詞表,包括14個分類,共213種。本文利用蔬菜詞表及其分類情況,采用Python編寫的數據采集工具提取蔬菜百科中的相關文本,包括蔬菜簡介、結構化表格以及目錄中的相關信息,按照文本文檔的形式進行存儲。然后進行數據清洗,刪除噪音和空行,如圖2所示。

圖2 網頁解析結果文檔
在語料采集結束后,利用Jieba分詞系統對其進行全模式分詞,分詞后為后續的模式識別和基于文本的Word Embedding做準備,分詞結果如圖3所示。

圖3 文檔分詞結果
2.2 蔬菜三元組獲取
知識的表示學習在知識圖譜初步構建的前提下進行,除了要獲得蔬菜領域實體及其別名信息,還要獲取關系(包含分類關系和非分類關系)。由于蔬菜的絕大部分非分類關系均為屬性關系,因此,本文更加注重蔬菜屬性關系的表示學習。
圖4表示的是蔬菜領域知識圖譜的三元組示例。

圖4 蔬菜領域知識圖譜三元組示例
其中包含上下位關系,和諸如拉丁學名、別名信息、分布地區、播種方法、栽培技術、病蟲害、營養價值、食用價值和藥用價值等屬性關系。分析圖4可知,蔬菜領域的屬性關系的復雜性,大多數屬性關系都有可能對應有兩個以上的頭實體或屬性值,因此,在對這些三元組進行表示學習時,要特別注意這類復雜關系的建模和相關問題的處理。
2.3 模型訓練
利用表示學習的TransE模型,將知識圖譜中的實體和關系映射在一個低維稠密的實值向量空間中。本文選取根菜類,薯芋類等12個類別的蔬菜三元組作為訓練數據,食用菌(共37種蔬菜)三元組作為測試數據,芽苗菜(共25種蔬菜)三元組作為校驗數據,如表1所示。

表1 知識表示學習TransE模型數據集Tab. 1 Knowledge representation learning TransE model data set
在PTA模型中,除了對實體進行映射之外,還需要對關系路徑進行映射,這里的關系路徑主要由屬性關系和上下位關系構成,一對多和多對一關系為二階路徑翻譯模型,多對多關系為三階路徑翻譯模型。其中,別名信息,病蟲害關系,營養價值,藥用價值等屬性關系均存在以上的情況,因此,需要為圖譜添加屬性模糊實體和關系路徑如表2所示,數據統計情況如表3所示,其中訓練數據,校驗數據和測試數據按照20∶1∶1的概率隨機劃分。
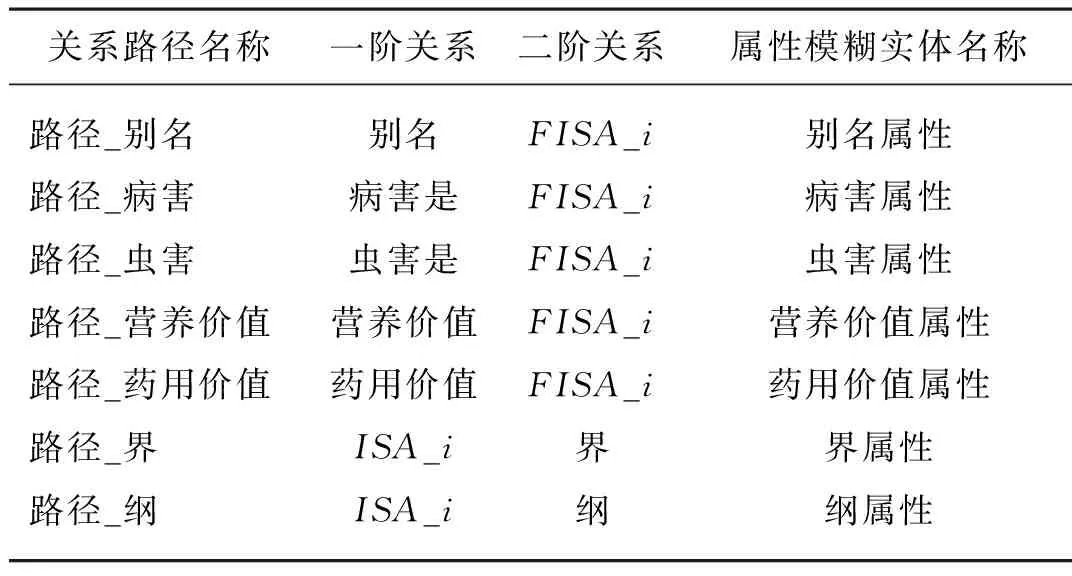
表2 部分二階路徑關系規劃表Tab. 2 Part of the second-order path relation programming table

表3 知識表示學習PTA模型數據集Tab. 3 Knowledge representation learning PTA model data set
對比表1和表3可見,實體數目增加了210個,三元組總條目增加了704條。這些增加的實體數目和三元組條目即為PTA模型中增加的屬性模糊實體和拓展的相關的三元組。
PTA模型的訓練得到的實體向量、關系向量和關系路徑向量。其中,關系路徑向量維度為100,且訓練模型最佳參數配置與TransE模型相同。
2.4 評測任務
由于本文涉及到的蔬菜領域知識圖譜三元組大多經過人工提取,雖然準確率較高,但是有太多因素會導致圖譜的知識覆蓋率較低,因此,后續工作亟待解決的一個問題,就是知識圖譜的動態更新,對于每一個有所缺失的三元組,均利用知識表示學習模型進行補全。知識圖譜的補全選用鏈接預測(Link Prediction)作為一個評價指標用來衡量表示學習模型的效果,本文主要從實體預測方面分別對TransE模型和PTA模型在以蔬菜領域知識圖譜中進行對比。
其中,對于每一個缺失頭實體或確實尾實體的三元組,本文采用隨機梯度下降算法計算打分函數,然后對所有的候選實體進行降序排列,并且選取兩個評估參數來計算:MeanRank和Hits@10。其中,MeanRank的值很大程度上表示了實體預測的情況,該指標越小表示預測效果越好;Hits@10表示,針對一個頭實體或尾實體,預測結果中正確實體排在前10的個數占全體實體數目的比例,該指標越大表示預測準確率越高。因此,MeanRank和Hits@10兩個評測指標分別是從宏觀和微觀的角度上對表示學習模型進行的評價,前者主要測試全部的預測實體效果,從整體上對表示學習模型做出把控,后者主要測試評測結果的優秀率,二者各有側重,從兩個不同的層面反應了表示學習模型的效果。
該評估方法在鏈接預測上有較好的效果,但在某些方面也有缺陷。如果測試數據中的三元組(西紅柿,病害有,筋腐病)的尾實體“筋腐病”缺失,“細菌性斑點病”將被預測出來,但是該實體已經存在于蔬菜領域知識圖譜中,在對錯誤三元組實體預測時,(西紅柿,病害有,細菌性葉斑病)將被視為新的三元組。因此,在對測試三元組進行實體預測評估過程中,可以在鏈接預測排序之前,從知識圖譜的訓練語料,校驗語料和測試語料中過濾出所有此類的三元組,因此,將過濾前的正確三元組數量稱為Raw,過濾后的正確三元組數量稱為Filter。left指的是在知識表示學習的模型訓練過程中進行頭實體預測,即按照實體列表中的實體依次替換三元組的頭實體從而構成錯誤三元組集合,并進行語義相似度的計算;right指的是在知識表示學習的模型訓練過程中進行尾實體預測,即按照實體列表中的實體依次替換三元組的尾實體從而構成錯誤三元組,并進行語義相似度的計算。
2.4.1 不考慮關系分類的鏈接預測
表4所列舉的是使用TransE模型對蔬菜領域數據集表示學習的鏈接預測效果,表5所列舉的是針對PTA模型的三種不同的路徑規劃算法,在蔬菜領域數據集上的鏈接預測效果。
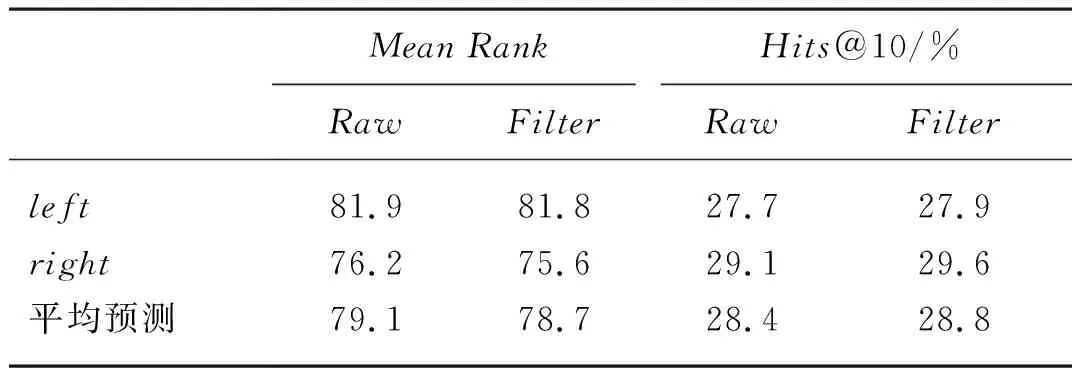
表4 TransE模型在蔬菜領域知識圖譜中的鏈接預測效果Tab. 4 Link prediction effect of TransE model in vegetable domain knowledge map
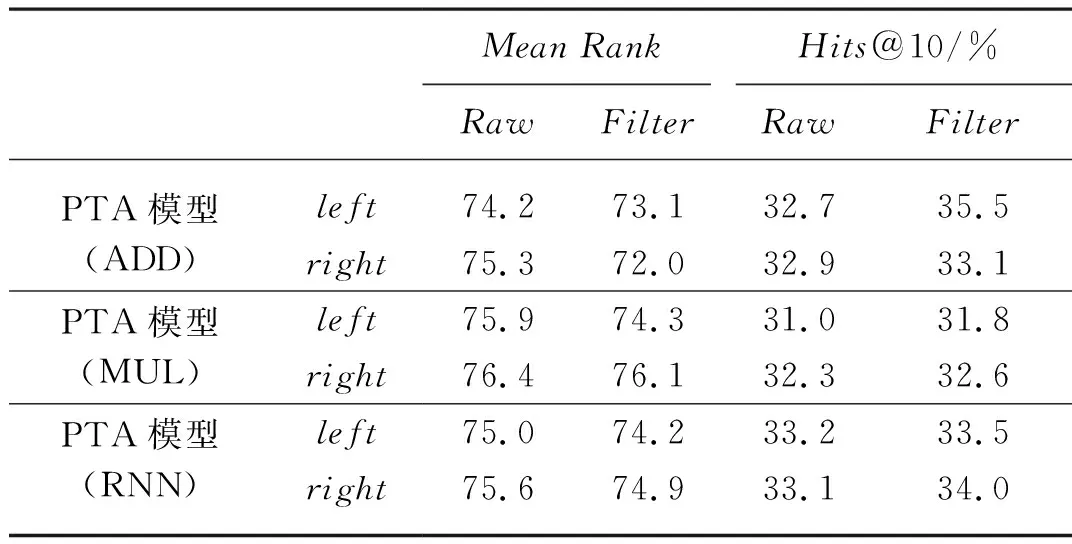
表5 PTA模型在蔬菜領域知識圖譜中的鏈接預測效果Tab. 5 Effect of PTA model on the linkage prediction of vegetable domain knowledge map
從表5可以看出,在PTA模型的三種路徑規劃算法中,較之乘法運算模型MUL和循環神經網絡模型RNN,加法運算模型ADD在MeanRank和Hits@10兩個方面的預測效果都是最佳。其原因在于,加法運算同時符合TransE模型和PTA模型的學習目標。因此,在后續的模型對比實驗中,主要采取PTA模型的加法運算進行屬性關系的路徑計算。
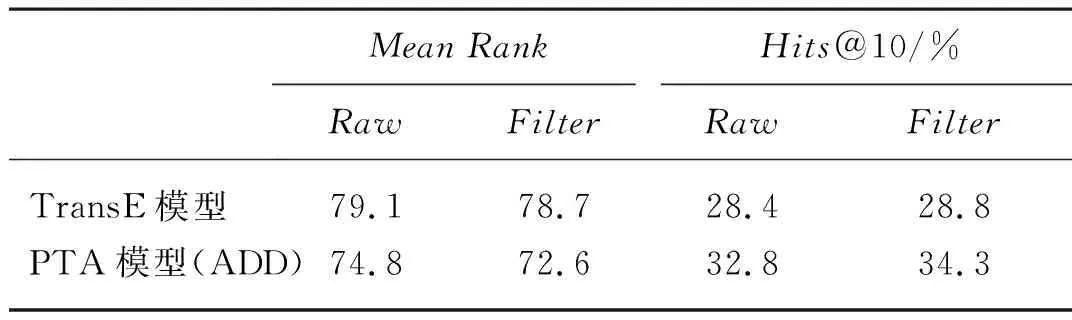
表6 TransE模型和PTA模型在不區分關系類別前提下的鏈接預測效果對比Tab. 6 Comparison of link prediction effects between TransE model and PTA model without distinguishing relationship categories
從表6可以看出,PTA模型預測效果顯著優于TransE模型,平均秩序MeanRank的Filter值下降到72.6,提前了大約6個次序,Hits@10的Filter值達到34.3%,提高了5%。這表明基于路徑的屬性關系表示學習模型為知識圖譜的表示學習提供了一個很好的補充。
2.4.2 考慮關系分類的鏈接預測
本文主要針對蔬菜領域屬性關系的復雜性進行模型的改進。利用屬性關系和ISA關系的結合構成關系路徑來解決1-N,N-1,N-N的復雜關系的表示學習問題。TransE模型和PTA模型在4種關系上的Hits@10值對比結果,如表7所示。
由于對蔬菜領域數據集進行了分類,1-1,1-N,N-1和N-N所對應的單元組條目互不相同,因此,無法比較MeanRank的值。表7所示的復雜關系鏈接預測效果,為TransE模型和PTA模型在不同關系類型數據集上的Hits@10值。結果表明,路徑和預測的方向兩個因素很大程度上決定著預測效果的好壞。

表7 不同表示學習模型在不同類別關系下的鏈接預測效果Tab. 7 Different represents the link prediction effect of learning model under different category relations
首先,從橫向進行比較。分析不同的關系類別和預測方向的關系,表7的鏈接預測結果可被分為四個范疇,其中,由于1-1和N-N關系具有對稱性,兩個模型對于頭實體預測和尾實體預測效果均無較大差別。但兩個模型對于1-N和N-1的關系的鏈接預測效果卻出現了相反的效果。例如,PTA模型在1-N關系的頭實體預測和N-1關系的尾實體預測效果分別為36.1%和38.3%,二者預測結果相當且在四類屬性關系的表示學習中效果最好,而N-1關系的頭實體預測和1-N關系的尾實體預測效果分別為26.5%和27.0%,二者預測結果相當但是在四類屬性關系的表示學習中效果最差。本文以頭實體為例,分析其原因,在1-N關系的頭實體預測任務中,關系路徑的展開方向與預測方向相反,即對于蔬菜領域三元組來說,多個屬性值對應同一個蔬菜實體名稱,當頭實體缺失時,得相似蔬菜名稱的概率由多個屬性值確定,因此頭實體的預測的準確率較高。而在N-1關系的頭實體預測任務中,多個蔬菜實體名稱對應同一個屬性值,當頭實體缺失時,預測出某一個蔬菜名稱的概率較低,因此預測效果較差。
其次,從縱向進行比較。分析不同模型在同一類別關系下的預測結果。
PTA模型與TransE模型相比,在傳統的翻譯模型中,增加關系路徑的向量化表示,旨在將屬性關系與上下位關系進行融合解決復雜關系的表示學習問題。如表7所示,PTA模型的最終Hits@10值比TransE模型提高了6.6%,且在關系分類表示中,尾實體預測N-1關系結果最優,比TransE模型提高了13%。
綜上所述,PTA模型對蔬菜領域知識圖譜的復雜屬性關系有較好的表示效果,在小領域中文知識圖譜的表示學習上發揮了較重要的作用。
3 結論
1) 本研究主要在蔬菜領域三元組數據集上進行基于TransE模型的知識表示學習,將8 780個實體和187個屬性關系映射到同一個低維連續的實值向量空間,通過計算向量的距離來衡量實體和關系之間語義關系,最終MeanRank降低到78.7,Hits@10的值高達28.8%。
2) 針對蔬菜領域特有的屬性關系,以及涉及到的實體數量來對數據集進行分類,提出基于屬性的路徑翻譯模型PTA,分別對1-1,1-N,N-1和N-N四種復雜關系進行表示學習。結果表明,PTA模型較TransE模型有較好的表示學習效果:在不考慮關系分類時,PTA模型預測效果顯著優于TransE模型,平均秩序MeanRank的Filter值下降到72.6,提前了大約6個次序,Hits@10的Filter值達到34.3%,提高了5%;考慮關系分類時,PTA模型的最終Hits@10值比TransE模型提高了6.6%,且在關系分類表示中,尾實體預測N-1關系結果最優,比TransE模型提高了13%。
3) 在實驗過程中,三元組數據集的質量也是影響鏈接預測的關鍵,尤其是針對PTA模型,模糊節點的設置使得實體數目和三元組數目有所增加,正確添加相關的三元組后鏈接預測的實驗結果(Hits@10)較沒有添加三元組的鏈接預測效果有所增加。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
