一種基于偏好免疫網絡多特征辨識的油茶果分選識別方法*
2021-09-23 14:07:06李昕陳澤君李立君譚季秋吳發展
中國農機化學報 2021年9期
關鍵詞:特征
李昕,陳澤君,李立君,譚季秋,吳發展
(1. 湖南工程學院機械工程學院,湖南湘潭,411104; 2. 湖南省林業科學院,長沙市,410004;3. 中南林業科技大學機電工程學院,長沙市,410004; 4. 株洲豐科林業裝備科技有限責任公司,湖南株洲,412000)
0 引言
油茶是我國的重要特產木本油料之一,屬常綠灌木或小喬木。全世界的油茶主要分布于我國長江流域及以南地區,是我國重要的經濟作物。近年來,隨著油茶種植面積的增加,茶籽全果資源化利用開始受到關注,同時油茶產業也開始進入產業化與自動化,在其產業化過程中出現的問題主要有機械設備的智能化程度較低、實時作業效率較低等問題。油茶果全果資源化產業鏈主要包括油茶果采摘、油茶果脫殼、油茶果殼籽粒分選以及油茶籽粒后加工等環節,目前針對全果資源化產業鏈已經做出了大量的研究工作,并取得了一定的研究成果,并投入應用之中[1-2]。本研究集中于油茶果采摘脫殼的后期處理工作,即如何使用智能算法對脫殼后的油茶果殼、籽粒進行分選,并使用噴氣嘴吹飛分選后的油茶果殼,最終將目標的果殼與籽粒分離出來的過程。
目前對農林業目標的智能分選識別方法中,主要的分選識別方法有單特征識別與多特征混合識別[3-13],Wang等[14]利用圖像的RGB特征分量進行了櫻桃圖像識別;Pearson等[15]使用了HSV,Lab等多顏色特征分量用于玉米色選識別;趙吉文等[16]使用灰度單特征分量識別了瓜子的特征;王丹丹等[17]使用卷積網絡識別了多特征分量的蘋果目標。從前人的研究中得出,單特征識別時間短但效率較低,而多特征識別雖然識別率較單特征識別高,但受限于算法運算的實時性要求,并不適用于所有目標的特征辨識。
本文基于已有的研究基礎,提出了一種多目標偏好人工免疫網絡算法,并通過對油茶果殼籽粒特征的研究分析,將油茶果殼、籽粒的顏色形態6項特征作為目標參數輸入多特征免疫網絡算法中進行測試。最終使用6種維度數據進行智能辨識,通過智能算法取得有效的分選結果。
1 試驗材料與圖像預處理
1.1 試驗材料
試驗材料選取脫殼后的油茶果殼、籽粒圖片,樣本圖片的采集時間為2019年11月,采集地點為湖南株洲豐科林業裝備有限責任公司,油茶基地采集的油茶樣本脫殼后產生的待分選的油茶果樣本作為試驗樣本,如圖1所示。

圖1 油茶果殼籽粒樣本
1.2 圖像分割
本文提取油茶果殼與籽粒采集圖片作為試驗樣本數據,首先對樣本數據進行圖像分割處理,以確定油茶果實、籽粒在圖片中的目標區域范圍,在區域范圍之內再對油茶果實、籽粒的顏色形態特征進行樣本特征提取,以便后續進行目標的多維度辨識。
基于油茶分選處理系統良好的識別采集環境,為保證整體圖像辨識系統的運算速度,本文選取經典的最大類間分割法(Otsu)圖像分割算法進行分割。雖然模糊聚類、多元統計、深度神經網絡等近期的智能算法在目前已經得到了廣泛應用并取得了較好的效果,但具體在本研究中的油茶果殼籽粒的實時分選線上,速度與效率是著重需要考慮的因素。而Otsu圖像分割算法是一種基于灰度圖像閾值分選判斷的經典算法,Otsu算法的基本思想是根據圖像的灰度直方圖確定閾值K,進而將灰度圖像分割為前景目標A和背景目標B以提取油茶果殼籽粒的前景目標和背景目標。其具體表達式如下
e2(K)=PA(μ-μA)2+PB(μ-μB)2
(1)
式中:μ——圖像的灰度均值;
μA、μB——前景目標A、背景目標B的均值;
PA、PB——前景、背景運算參數;
e(K)——最大閾值參數。
當K的取值到最大時,即是最佳閾值。
Otsu圖像分割法自提出以來,由于其優良的實時辨別性能與效率,目前已廣泛應用于實時性要求較高的圖像分割系統之中,特別在農林業實地生產與試驗中也得到了廣泛的應用。在分割得出目標果殼籽粒目標區域的基礎上,本文在圖像分割油茶果殼籽粒區域目標的基礎上,再對區域內果殼籽粒的顏色形態特征進行提取與辨識,而后使用免疫算法確立分選目標。圖像分割與目標區域如圖2所示。

(a) 原圖 (b) 分割目標 (c) 區域特征
1.3 目標顏色特征
基于農林業目標的顏色特征,傳統的農林業目標自動化分選通常采用顏色特征分選的方法對顏色差異較大的果實目標進行顏色分選識別,如葡萄、西紅柿、茄子等目標。
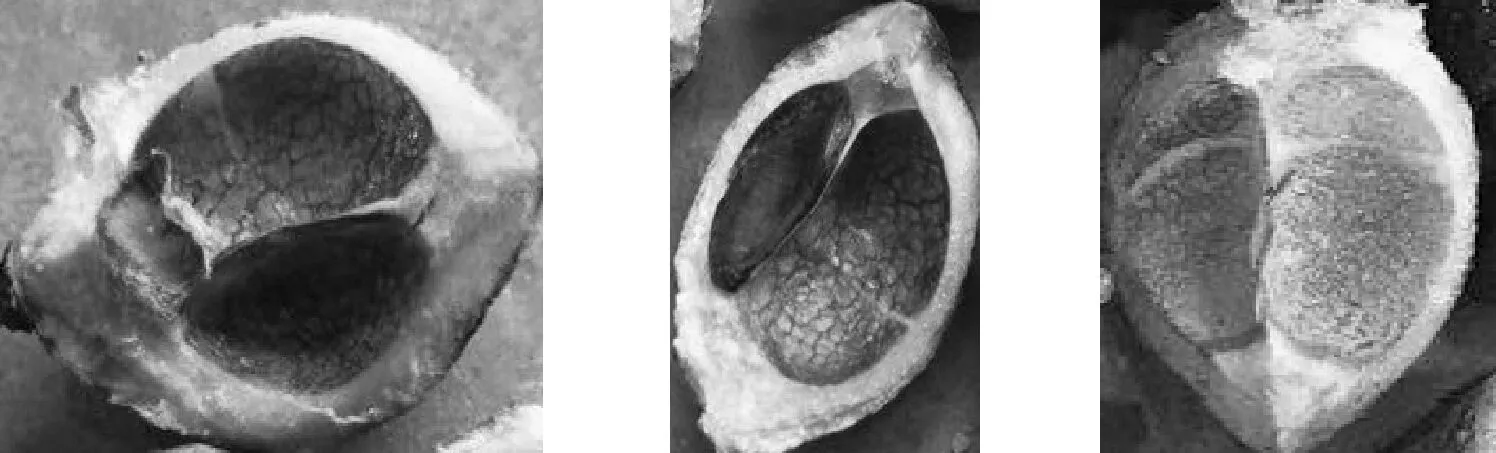
油茶果脫殼后的果殼與籽粒同樣具有顏色特征差別明顯的特點,適合于初步的顏色特征辨識,油茶果殼/籽粒顏色形態如圖3所示。

圖3 油茶果殼/籽粒顏色形態
本研究提取目標果殼籽粒的RGB色差圖的3項分量作為輸入數據,特征參數中,油茶籽粒顏色特征偏暗黑,而果殼顏色特征趨向于白色。
1.4 目標形態特征
如上文所述,油茶果殼籽粒脫殼后雖然顏色目標區分較為明顯,但受到外界環境溫濕度影響較大,在油茶果采摘存放12天以后,其果殼顏色特征漸漸趨向于暗黑色,與籽粒顏色相接近,因此僅靠顏色維度的特征識別將會帶來很大的局限性。而油茶果殼與籽粒的形態特征區分較為明顯,籽粒呈飽滿圓形,果殼相對呈長條形,長寬差距較明顯。因此本研究進一步在提取油茶果殼籽粒伸長度L,寬度W,周長S,面積A,4項數據的基礎上,設定伸長率、圓形度、圓滿度3項參數作為形態學輸入參數,形態學參數公式如式(2)~式(4)所示。
(2)
(3)
(4)
式中:S1——伸長率;
S2——圓形度;
S3——圓滿度。
經采集圖像統計分析,油茶果殼、籽粒的形態、顏色特征參數范圍如表1所示。
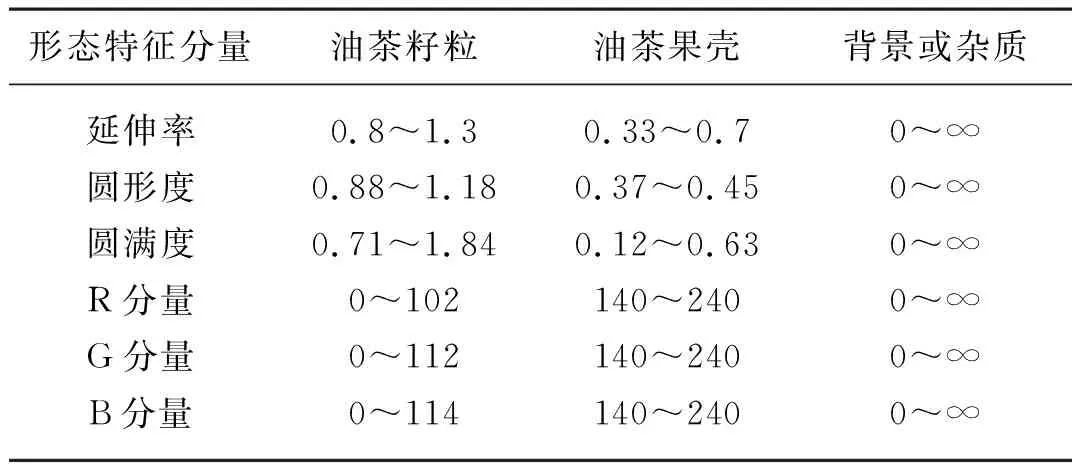
表1 油茶果殼籽粒顏色形態分量范圍Tab. 1 Color and morphological range of Camellia seed/shell
2 基于偏好免疫網絡的油茶果殼目標分選
2.1 人工免疫網絡
本研究采用人工免疫網絡系統作為分選聚類的基礎算法,在此基礎上根據油茶果殼籽粒的多特征進行改進后分選聚類。人工免疫網絡系統是一種模擬生物免疫系統的智能算法,算法中提出的抗體、抗原等生物學概念對應于算法數據中的聚類概念。在圖像處理領域中,將輸入的待識別數據作為抗原數據,將欲識別聚類的典型目標數據庫數據作為抗體數據進行綜合識別分選,最終得到較好的分選聚類效果。
人工免疫網絡算法系統中設置閾值作為聚類分選條件,滿足閾值條件的網絡將得到聚類分選結果,不滿足條件的算法將重新輸入免疫算法網絡繼續進行運算直至得到最終聚類結果為止。
1) 選擇待處理的數據,從數據中選取偏好數據庫中的數據,并定義為免疫學中的抗原細胞,并將這些數據作為初期數據輸入網絡進行運算。
2) 輸入網絡后,對各抗原細胞之間的親和力水平進行運算比較。
3) 按照算法中設定的克隆規則對網絡中的數據細胞進行克隆。
4) 按照式(5)、式(6)的方法對經克隆運算后的細胞進行變異操作,最后保留父代群體于網絡中。
C′=C+αN(0,1)
(5)
α=(1/β)exp(-f)
(6)
式中:C′——細胞C產生變異后形成的新細胞;
N(0,1)——均值為0,偏差為1的高斯隨機變量;
[2]郭惠玲:《基于博弈論視角的電商價格戰分析》,《北京理工大學學報》(社會科學版)2014年第5期。
α——變異參數;
β——調節函數的指數衰減變量;
f——經標準化處理后的細胞適應值。
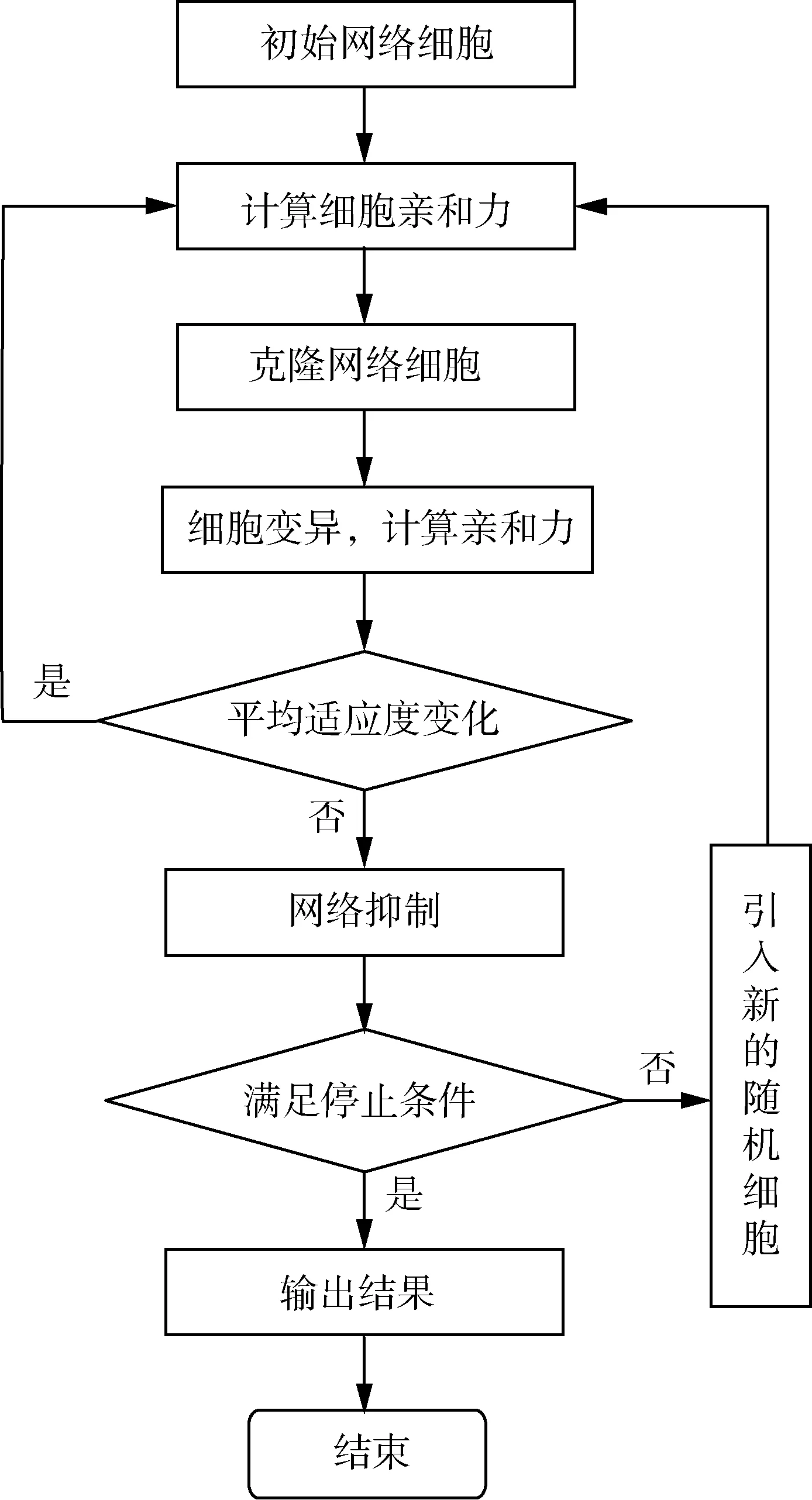
圖4 免疫網絡算法流程
5) 變異后,重新運算免疫網絡細胞親和力。
6) 選擇親和力最高的網絡細胞組成新的網絡,并計算新網絡的細胞親和力。
7) 計算網絡中所有細胞的親和力,如果小于閾值則判定為親和力高的細胞予以保留,其他細胞則予以抑制。
8) 輸入一定比例的隨機網絡細胞數據,返回第二步。
9) 輸出產生的網絡細胞數據。
在人工免疫網絡算法中,抗體數據即為網絡細胞,算法中設置了抑制模塊、親和力模塊、增值模塊等仿生模塊。并使用閾值來決定是否停止運算,滿足條件則停止,不滿足則隨時輸入新的數據校正,以保證網絡的生命力。
2.2 偏好多目標模塊設定
Ishibuchi等[18]提出并驗證了將決策者待決策的信息(即偏好信息)輸入智能算法中可以有效地使算法向偏好區域收斂,通過這種方法可以提高算法效率。這同時也將偏好模塊融入算法體系之中,用算法搜索出滿足一個或數個偏好約束的解。偏好概念提出后,許多學者在各自的領域對偏好概念進行了研究,并將其應用于算法識別之中,同步增強了算法的可用性。
本文針對前人在偏好區域以及與多目標優化結合的算法研究成果的基礎上,提出了將多目標優化、偏好區域與人工免疫網絡算法相結合的算法,以縮減算法的搜索時間,節約算法的計算資源,并對算法的計算模塊優化,提高了算法在圖像分選識別中的效率,并將其應用于油茶果圖像脫殼后分選環節中。
偏好多目標優化在偏好區域基礎上的多目標優化,是多目標優化的一種形式,具體定義如下
miny=F(x)=(f1(x),f2(x),…,fm(x))
(7)
s.t.:gi(x)≤0,i=1,2,3,…,q
hj(x)=0,j=1,2,3,…,p
其中:x=(x1,x2,…,xn)∈X?Rn
y=(y1,y2,…,ym)∈Y?Rm
式中:n——決策向量個數;
m——目標向量個數;
X——由n維決策向量定義的決策空間;
Y——由m維決策向量所構成的目標空間;
F(x)——決策與目標向量之間的映射函數;
g(x)——不等式約束的個數,共有q個;
h(x)——等式約束的個數,共有p個。
本研究的多特征偏好免疫網絡算法中,抗體空間為決策空間X,抗原空間為決策空間Y,單個抗體為決策空間向量,單個抗原為目標空間向量。
2.3 偏好數據庫設定
油茶果殼、籽粒都有其特有的顏色與形態特征,且具備一定的區別。在形態特征上,油茶果殼的形狀偏長,而油茶籽粒的形狀偏圓形,因此兩者在形態學、圓形度、圓滿度上就能有所區分。在顏色特征上,油茶果殼的顏色偏青色,而籽粒的顏色偏暗黑色,則可以從RGB色差分量上有所區分。這6項形態學、顏色特征可以分別作為油茶果殼籽粒區分的基本特征,并將其建立目標特征數據庫。目標數據庫在免疫網絡算法中定義為偏好模塊,在后續的分選過程中,新的特征數據輸入免疫算法中,免疫算法使用偏好模塊對輸入數據進行親和力判定。輸入特征數據符合偏好模塊數據庫中油茶果殼特征的判定為油茶果殼,符合油茶籽粒特征的則判定為籽粒,這樣的方法與傳統的分選算法相比,充分利用了免疫算法的多目標聚類功能與偏好數據庫分選功能,從而具有更高的識別率,有利于下一步的油茶生產線處理。油茶果殼籽粒的形態學、RGB分量特征區分如圖5所示。
(a) 油茶果殼
2.4 多特征免疫網絡算法流程
在前文多特征以及偏好模塊研究基礎上,本文根據油茶果脫殼后圖像與形態的多特征特性,以提升算法的識別率及平衡識別時間為目標,構造一種多特征偏好人工免疫算法,以此算法模型作為油茶果殼、籽粒的分選算法,多特征偏好人工免疫網絡算法模型在油茶果分選識別處理的具體算法流程如下。
1) 從油茶果殼籽粒數據庫中選取一部分形態顏色數據,將其作為免疫網絡的初始數據。
2) 輸入網絡后,對各抗原細胞之間的親和力水平進行運算比較。
3) 以油茶果脫殼后圖像顏色形態特在作為偏好數據形成偏好區域,按照算法中設定的克隆規則對網絡中的數據細胞進行克隆。
4) 按照式(5)、式(6)對克隆后的細胞進行變異,變異概率與父代細胞親和力成反比例,最后保留父代的群體細胞于免疫網絡之內。
5) 計算變異后網絡細胞的親和力。
6) 選擇親和力最高的網絡細胞組成新的網絡,并計算新網絡的細胞親和力。
7) 計算網絡中所有細胞的親和力,小于閾值則且親和力高的細胞予以保留,其他細胞則予以抑制。
8) 采集每個油茶果殼籽粒的樣本形態顏色特征參數作為免疫網絡先驗知識,設定為疫苗,輸入一定比例的疫苗數據及隨機生成的細胞數據進免疫網絡,返回步驟2。
9) 輸出產生的油茶果殼籽粒特征數據的網絡細胞并進行分類。
油茶特征數據輸入輸出的多特征人工免疫網絡模型如圖6所示,油茶的圖像經過顏色形態6特征提取后,輸入網絡進行訓練,再進行綜合判定,最終實現輸出結果。
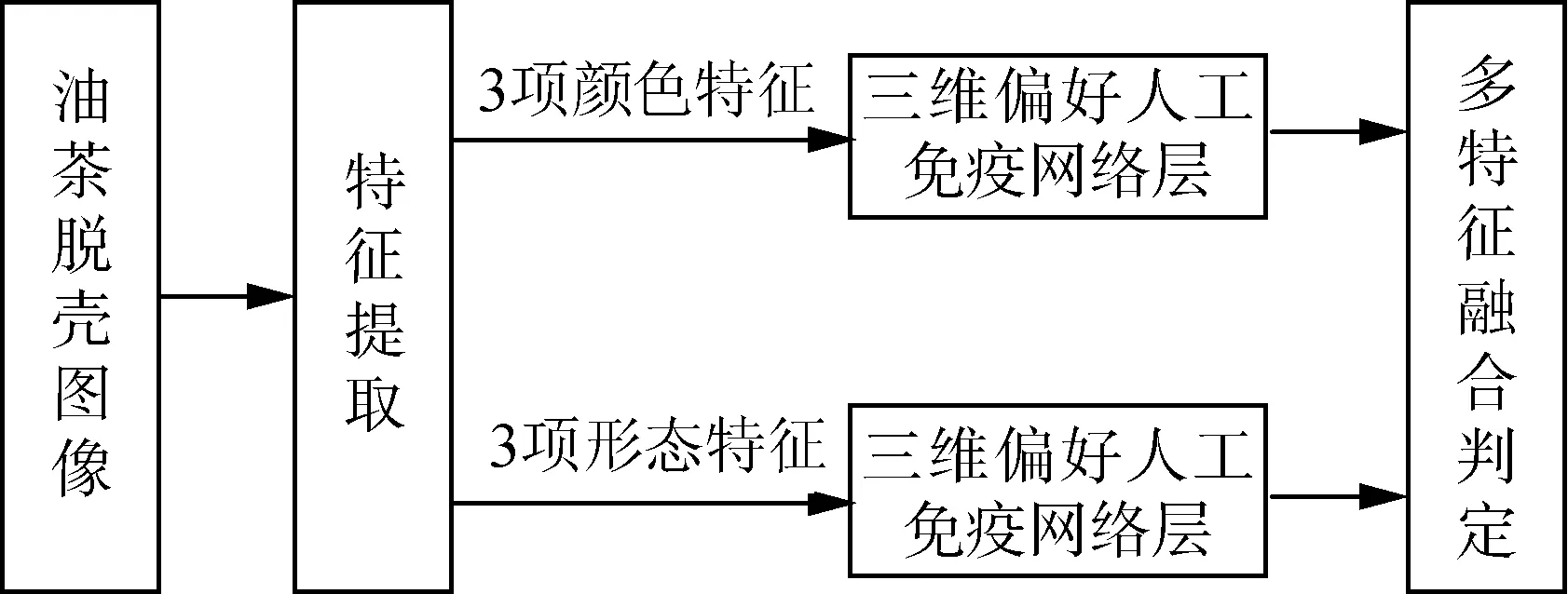
圖6 多特征偏好人工免疫網絡識別模型
由圖6可知,多特征偏好人工免疫網絡算法主要環節有以下幾步:(1)油茶果脫殼后圖像的多特征提取;(2)對各特征進行免疫網絡聚類分選;(3)免疫網絡進行多特征判斷與數據輸出。
3 試驗與結果分析
3.1 算法的效果驗證
由于油茶果殼籽粒在晾曬3天與12天后的顏色差距較大,識別效果會有很大不同,因此試驗中選取不同晾曬天數的圖片進行識別率與識別時間測試,以得到對比結果。由于新采果實顏色特征區分明顯,顏色特征識別率較高,形態特征基本不變,綜合識別率最高,本研究選取涵蓋顏色與形態特征的2特征分量、4特征分量以及6特征分量圖片進行特征訓練與運算識別,2特征分量為R分量與伸長率分量輸入組合;4特征分量為R分量,G分量,伸長率分量,圓形度分量輸入組合;6分量為R分量,G分量,B分量與伸長率分量、圓形度分量、圓滿度分量輸入組合。通過對2特征分量,4特征分量,6特征分量進行運算后,最終得到的不同分量樣本圖片的識別率與識別時間如圖7、圖8所示。
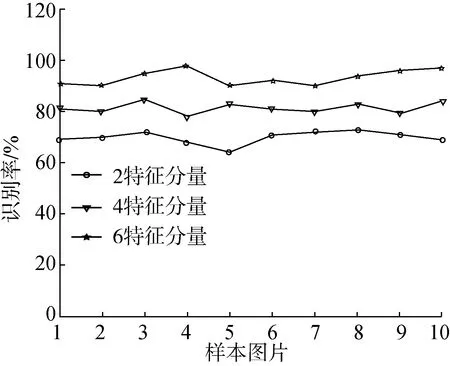
圖7 晾曬3天不同分量特征果殼識別率
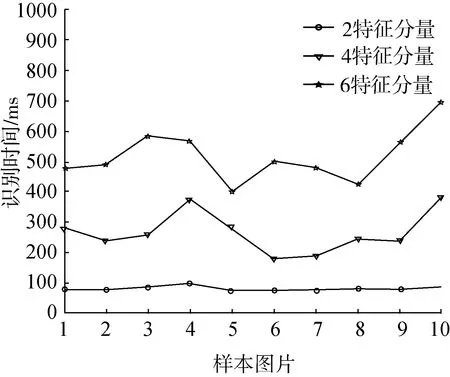
圖8 晾曬3天不同分量特征果殼識別時間
晾曬12天后,油茶果殼與籽粒的顏色變得相近,給顏色識別帶來了很大的困難,顏色識別率相對降低了,形態特征識別率基本不變,因此2分量、4分量、6分量的整體識別率相對降低,而識別時間基本不變,如圖9、圖10所示。
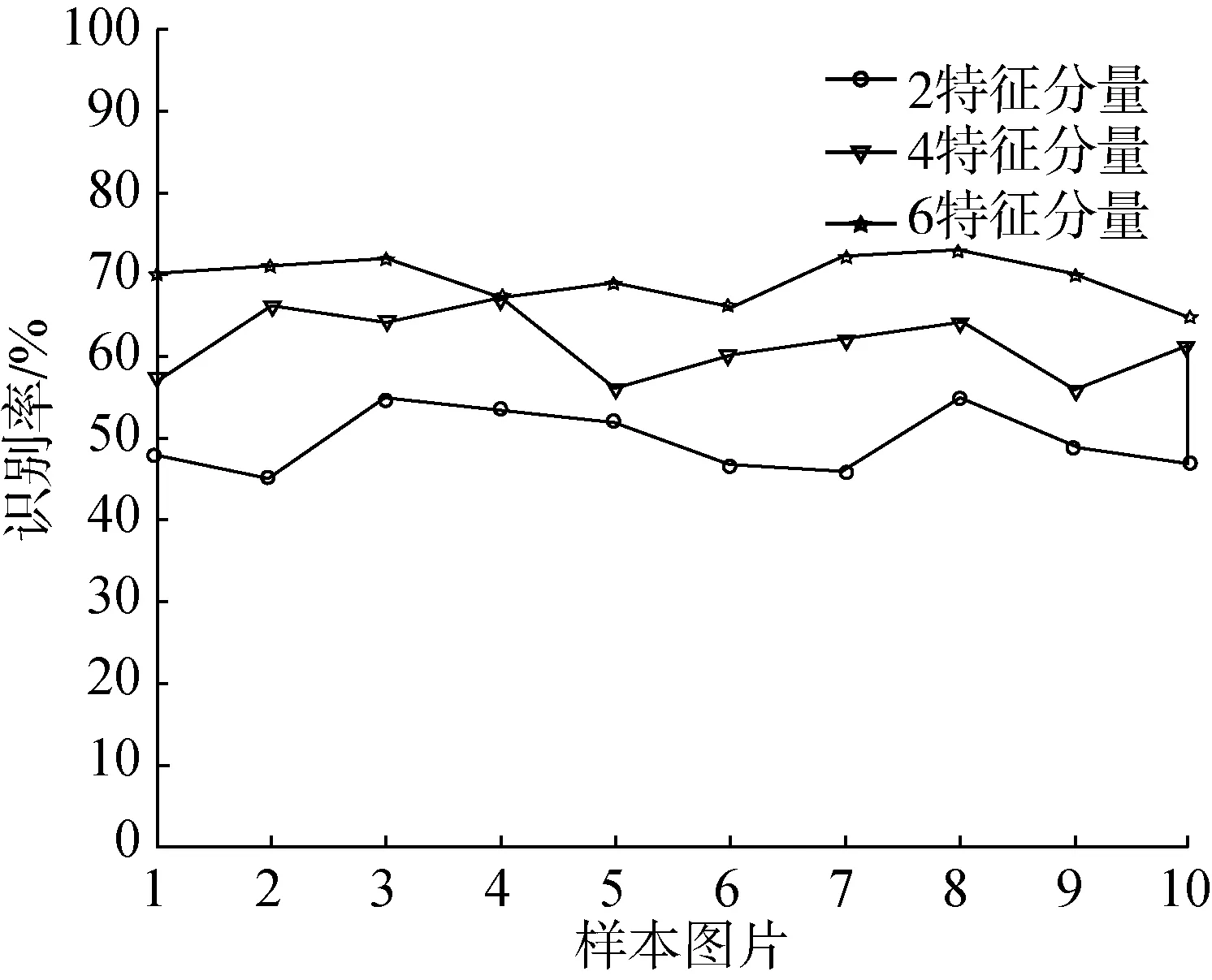
圖9 晾曬12天不同分量特征果殼識別率
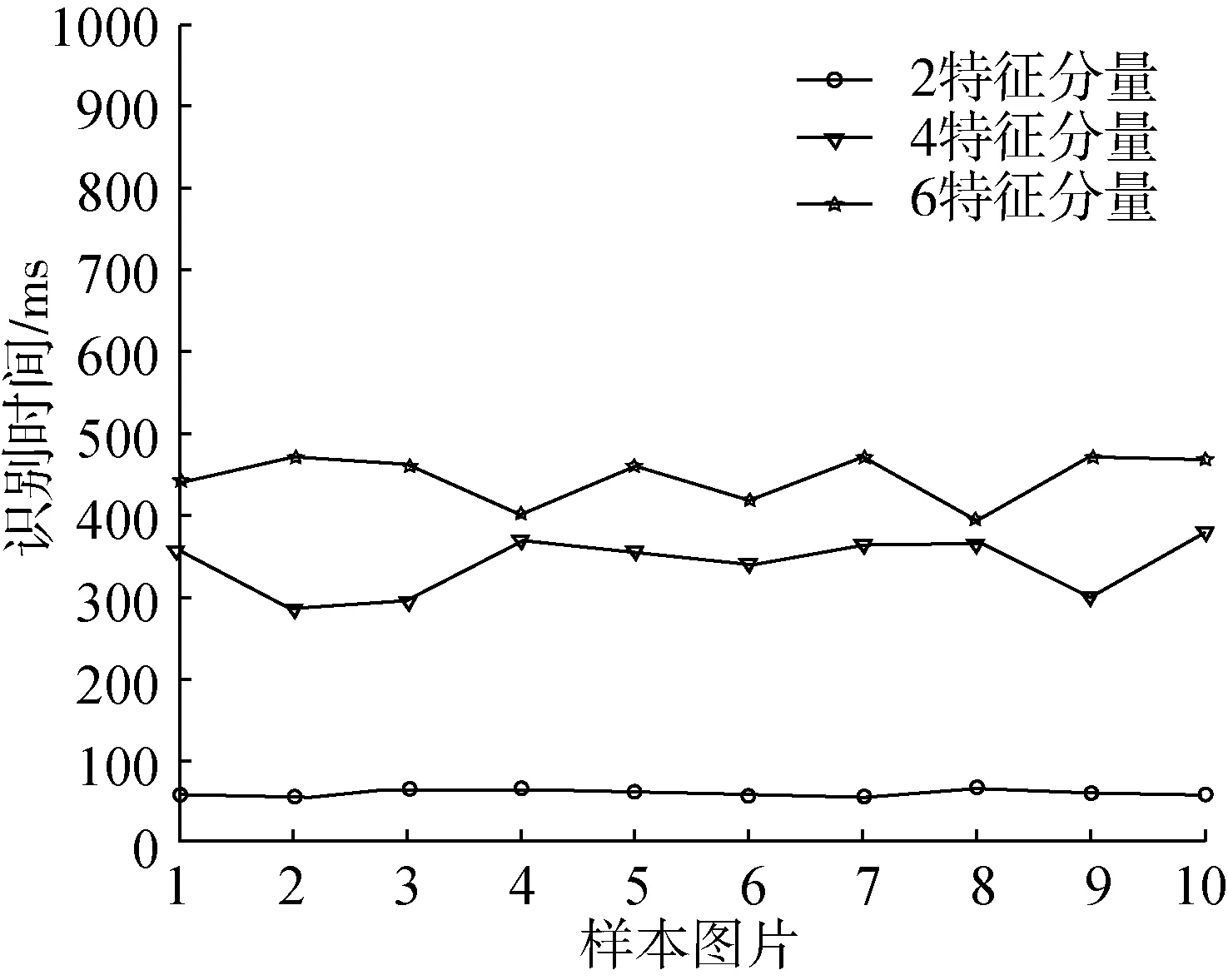
圖10 晾曬12天不同分量特征果殼識別時間
綜上可以得出,在識別特征分量增多的情況下,識別效率是可以增加的,同樣,效率的增加伴隨著識別時間的增加,使多特征識別的實際操作性變差,因此適當的采用合適的特征向量進行訓練與識別是必要的。在3天存放期內,2分量、4分量與6分量樣本的識別率均值分別為70%、80%與90%;晾曬12天時,由于樣本顏色特征的變化,識別率降低到均值為50%,60%和75%,而識別時間均值則分別為60 ms級、350 ms級與450 ms級,在2分量時識別時間最低達到了50 ms,使用MATLAB程序仿真和Visual C++6.0程序運行時,可以滿足現有傳送帶識別實時率要求。
經過多特征免疫算法識別后,油茶果殼籽粒目標得到了較好的區分,目標油茶果殼籽粒的實際分選效果如圖11所示。可見,經過分選辨識后,油茶果殼籽粒目標已經在視覺上進行了標記和分選,有利于下一步在設備上進行分離操作。

圖11 分選標記后的油茶果殼籽粒
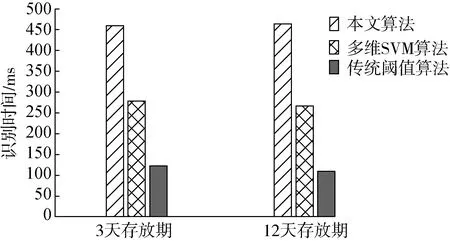
圖12 不同算法分選時間對比
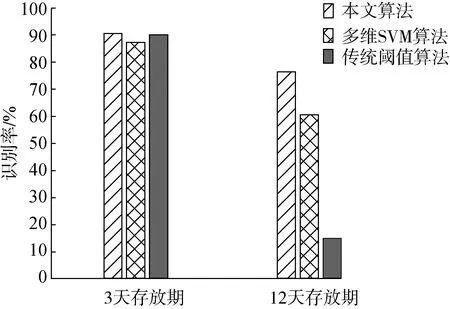
圖13 不同算法識別率對比
3.2 與其他算法的比較
為驗證本文提出算法的有效性,選用了農林業常用的單特征色選閾值分選法和多維支持向量機分選法(SVM)[19]進行比較。隨機選取存放周期為3天與12天的油茶果實、籽粒圖片各10張,比較本文算法、單特征色選閾值、多維支持向量機3種算法,最終得到各算法不同識別時間和識別率如圖12、圖13所示。
從圖12、圖13可以得出,由于算法結構與輸入數據的因素,其中傳統閾值法的分選法耗時最短,在存放期為12天的圖像中達到最低,為110 ms。傳統的閾值色選結構較為簡單,單純以顏色特征作為油茶果殼籽粒的定義標準,因此其算法執行時間較短,但正因為算法結構簡單,因此在復雜的顏色識別環境下不具備多特征自適應性,很多環境不能單純的使用顏色閾值來判定區分目標,當油茶的存放期達到12天,果殼與籽粒的顏色區分已經不明顯時,傳統顏色閾值算法對目標的識別能力下降,分選方法的識別率大幅度下滑,降低到了15.2%,基本不具備可用性,因此傳統顏色閾值算法是一種不具備自適應性的算法,不利應用于油茶果殼籽粒的識別;SVM多特征分選算法是建立在SVM算法的基礎上的,SVM算法的算法結構特征是二分性,而本研究輸入的數據是多特征,因此SVM算法結構不太適用多特征識別。同時SVM算法本身時間復雜度較高,在顏色區分不明顯的情況下會造成識別時間的上升和識別率的下降;而本文采用的多特征偏好免疫網絡算法采用了聚類方法對輸入的多特征進行聚類辨識,而偏好目標數據庫模塊又在此基礎上提高了識別時間,增加了識別效率,相對而言從算法結構和識別結果上更加適合油茶果殼籽粒分選的要求,通過對比試驗證明了本文的算法較其他算法的有效性。
4 結論
1) 由于油茶果殼籽粒的單特征分選存在識別效果不明顯的問題,本文提出了一種融合形態、顏色特征的多特征智能分選免疫算法,對采摘脫殼后的油茶果殼、籽粒圖像進行綜合分選,在實地生產線上進行測試。本文的主要工作集中于目標的多特征提取以及免疫算法的內部改造。
2) 從多特征融合分選角度來說,由于農林業產品的外部特征比較復雜,因此傳統的只靠單一特征分選與單一特征的單一維度分選已經不適合實際生產要求與智能化發展要求。因此應該以多特征數據作為算法的判斷依據符合農林產業實時分選、識別要求。本研究在樣本晾曬3天時,特征2分量、4分量與6分量的識別率均值分別為70%、80%與90%,而晾曬12天時,識別率均值也達到了50%,60%和75%,證明了本文分選方法在效率上的有效性。
3) 從算法優化角度來說,由于油茶果殼籽粒的訓練樣本特征相對固定,因此對訓練樣本的特征進行特征分量精細化與細分可以解決算法復雜性問題。在與單特征色選閾值分選法、多維支持向量機分選法對比試驗中,本文所選的算法識別率最高達到90%以上,證明了算法的有效性。
4) 本研究采用的免疫算法分選方案都是基于油茶果殼籽粒多特征融合的方法,是對目前市面上已有的色選方案的改進,也是針對油茶果殼、籽粒實際情況的升級分選識別方案,目前市面上智能形選、色選方案并不多,因此本文具有一定的應用創新性。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
