
NLP在文獻知識檢索與處理中的應用*
2021-09-24 10:17:00李一琳
科技創新與應用 2021年26期
李一琳,徐 瑞
(1.南京森林警察學院 刑事科學技術學院,江蘇 南京 210023;2.南京大學 信息管理學院,江蘇 南京 210023)
自然語言處理(Natural Language Processing,NLP)又稱自然語言理解,發源于美國IBM沃森研究中心,是一種對自然語言信息進行處理的技術,包括自然語言理解(Natural Language Understanding,NLU)和自然語言生成(Natural Language Generation,NLG)兩部分[1]。它是計算機語言技術的一個分支,通常是指利用計算機對人類的自然語言進行有意義的分析與操作,作為人工智能的一部分,是目前信息技術最重要的研究方向之一。
為了從整體上把握該領域的研究現狀與發展趨勢,本文通過梳理相關文獻,對自然語言與文獻知識處理的發展關系以及在信息檢索、文本處理等方面的研究進展進行歸納總結,探究未來發展趨勢,以期能對自然語言處理的發展應用提供一定的參考。
1 自然語言的發展歷程
1854年,美國波士頓梅堪特圖書館編印的字典式目錄和1876年美國克特發表的《字典式目錄條例》,把主題標識、著者標識、書名標識三者的字順結合起來,應視為人工語言與自然語言兼容化的初步嘗試。
國外學者于20世紀40年代末至50年代初開始涉及該領域,我國在20世紀50年代末和60年代初,開始自然語言檢索的研究工作。從20世紀60年代以關鍵詞匹配為主流,到70年代以句法-語義分析為主導,再到80年代開始實用化和工程化[2],自然語言檢索已經成為國內外情報檢索和自然語言處理領域的共同研究熱點。到20世紀90年代,隨著機器學習算法的引入,研究者開始注重語料庫的建設,目前自然語言處理已經拓展到語音識別、句法分析、機器翻譯、機器學習和信息檢索等多個方面[3]。
隨著微型機網絡和光盤等硬設備的產生,迫切需要產生一種新的檢索方式,自然語言檢索應運而生,給情報檢索領域的應用帶來了巨大變革。在全文數據庫出現后,進一步加速了對自然語言檢索的發展與研究。自然語言在幾十年的發展中已形成有效的理論和實用技術,其中在語音識別算法中引入隱馬爾可夫模型和噪聲信道與解碼模型取得顯著的成績。
從科技、軍事、政務領域的文獻中檢索關鍵信息進行知識組織和分析,是獲取情報的重要手段,以美國為首的西方發達國家十分重視自然語言處理領域的研究,尤其是在軍事領域的應用。
同期,情報檢索的研究也經歷了大致5個階段,由20世紀60年代開始機械情報檢索,到70年代嘗試計算機情報檢索;80年代我國建立了聯系國內外的數據庫聯機檢索系統[4];90年代,美國率先把自然語言處理技術應用到情報檢索中,嘗試建立高級情報檢索系統[5],真正實現了非布爾邏輯中的自然語言檢索[2];近些年則致力于發展情報檢索系統的智能化。
為全面了解自然語言的發展狀況,以中文檢索式:主題=“自然語言處理”“自然語言”在中國知網檢索;英文檢索式:主題=“Natural Language Processing”或“NLP”在Web of Science(WoS)中檢索,檢索文獻的年限為1980年-2020年,共獲取中英文獻41062篇。
根據所獲文獻總量統計,涉及自然語言的論文在2004年開始迅速增長,預計2021年將超過4000篇,可見自然語言在國內相關領域已經進入白熱化的發展態勢。主要關注的研究領域有計算機軟件及計算機應用、自動化技術、中國語言文字、外國語言文字、圖書情報與數字圖書館,這5個領域均有超過1800篇的文獻,其中計算機類文獻高達21818篇。涉及的主題除了自然語言和自然語言處理,還集中在深度學習、人工智能、機器學習、問答系統、機器翻譯等方面。給予此類研究資助最多的是國家自然科學基金、國家社會科學基金和國家高技術研究發展計劃的研究類項目,已發表超過5000篇研究性論文(圖1)。
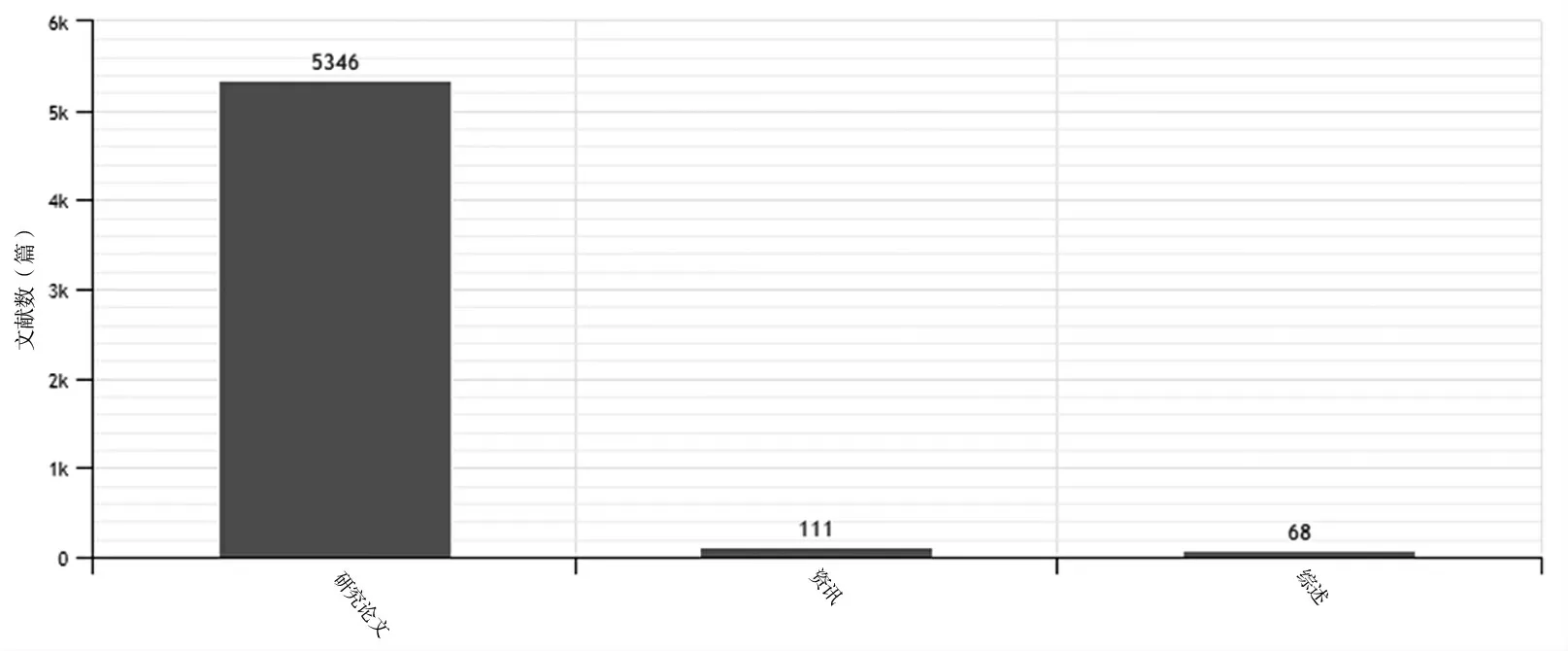
圖1 1980年-2020年間涉及自然語言的文獻類型
2 自然語言在文獻檢索中的應用
自然語言能夠直觀展現文本的名稱、內容和特定的詞匯,對一些沒有規律性的數據進行處理和分析,其檢索方法沒有特定的規范方式,約束較少,能給用戶提供較大的發展空間。用戶在使用時不需要考慮是否存在相關的檢索規則和檢索程序,可直接使用自己的語言和系統進行溝通,最大程度減少人機對話障礙。
隨著信息技術的發展,歐美等西方國家越來越關注自然語言處理在情報獲取中的應用,尤其重視在軍事領域的應用。自然語言處理技術在能夠通過通信、信息捕捉和信息控制等方面為軍事行動提供交流渠道,保障信息及時傳送,提升軍事行動的準確性。
2.1 數據的獲取
數據獲取是所有數據挖掘與分析的開始,文本挖掘則是數據挖掘在文本領域的擴展,自然語言是當前文本挖掘的重要技術,以發現知識為目的[6]。自然語言處理常用的方法有關鍵詞提取、信息收集和信息分類等,根據預設程序劃轉為相應信息等級,并作出提示,該技術能夠主動完成情報自動收集、梳理和分析工作。
在情報機構處理的各類情報素材中,公開來源的文本素材是情報的重要組成部分。在大數據時代,電子郵件、電子文檔、電子數據庫等信息基于新媒體平臺快速傳播,海量的信息為搜集情報提供了重要渠道,同時互聯網信息也具有一定真偽性,對信息的甄別和分析也是一項重要的工作。以美國情報機構為例,通過新媒體平臺獲取信息是目前最為容易且普遍的獲取方式,通過與主要信息來源企業合作,秘密對主要信息來源渠道進行監控。通過預定程序可以實現不間斷、定時且全面的網絡信息平臺情報掃描,對涉及相關情報的信息進行搜索和下載,及時獲取必要的信息。
2.2 情報檢索
在知識是生產力的知識經濟時代,社會的發展越來越依賴于知識的獲取和利用。數據倉庫儲存的知識包括空間位置數據、多媒體數據、文本數據等[6],圖書館是數據倉庫的載體,已經成為信息傳播和交換的中轉站[7]。要在浩瀚的知識庫中快捷地找到關鍵信息并進行高效處理,需依賴于圖書館強大的自然語言檢索功能。
情報檢索語言是基于情報搜索的需求而研發設定的模擬人工語言邏輯和人工語音思維的受控語言,用來標引和檢索文獻,通過深入探索文獻中潛在的規律和內容,挖掘其信息價值。通過梳理1750篇涉及情報檢索的文獻信息,發現國內關于自然語言與情報檢索的研究始于1981年。在對近3年的文獻進行關鍵詞共現網絡分析發現自然語言處理是情報檢索的研究基礎(圖2)。
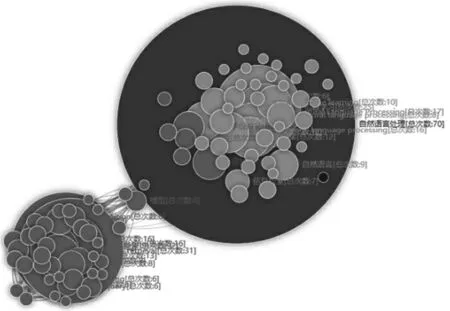
圖2 2018年-2020年間基于情報檢索的關鍵詞共現網絡分析
黃祥喜等[5]指出在情報檢索中對數據事實檢索將超過純書目檢索,這必然依賴自然語言處理,而人工智能和知識庫的發展將促成自然語言處理的實用化。日本九州大學嘗試利用自然語言處理,自動創建詞庫,建立高級情報檢索系統[8]。2000年后發展出虛擬信息顧問系統,具有強大的開放性和擴展性,可根據用戶輸入的問題,從知識庫中搜索并返回一個經過分析處理的答案,實現了自然語言處理在情報檢索中的智能化應用[2]。
情報檢索語言要求用戶具備一定的專業檢索知識,普通用戶很難接受。而情報檢索中的自然語言取自文獻原有的題名、章節名、摘要和正文。因此,掌握自然語言檢索方法更易被普通用戶所接受,各學科的用戶在檢索時也會感到使用本學科領域的自然語言比受控詞表方便得多[7]。
3 自然語言在文獻知識處理中的應用
隨著各類電子數據庫、電子圖書館收錄的數據呈幾何數上升,準確、高效地獲取和處理所需信息需要依賴自然語言處理的人工智能和信息處理技術,現已成為幫助用戶快速獲取價值信息的有效方法。
3.1 文獻信息處理
使用自然語言處理文獻信息有許多細節方法,其中使用計算機來執行自動摘要的重要性在網絡信息飛速增長的時代尤為重要。從文檔中抽取關鍵句、關鍵段落進行組合,增強文摘關聯性,用于自然語言識別是當前自動文摘研究的主要方法,包括:自動摘錄、信息抽取、基于理解的自動文摘、基于結構的自動文摘[7]。
由于使用文本提取技術獲得的數據來源不同,即使同一實體所含有的信息也因各網站、平臺設置的不同而存在差異,比如數據的格式、屬性等。在批量處理數據之前,必須對收集的數據進行清洗,按照屬性、字段、發布時間、主題、業務類型等進行歸類和結構化處理[9],成熟的自然語言處理技術可實現對信息的批量清洗、特征提取和結構化處理。
3.2 知識文庫
雖然利用自然語言技術可以解決文獻信息提取、情報檢索之類的問題,但因自然語言本身的弊端,給信息檢索工作帶來諸多困難。相對于英語的結構簡單化,漢語的多義性、同義性結合人們的生活、思維和表達的復雜化,使漢語言廣泛存在各種歧義。在自然語言處理中,對漢語的語法分析和語義理解至關重要,消歧是梳理語言和文本清洗的預處理工作,需要工作人員具備豐富的知識背景和高儲存量的知識文庫。而依賴于計算機學習、機器翻譯的文本識別更加需要詞匯庫、知識庫、語料庫等詞匯儲備,因此詞匯知識庫的建設已經成為當前自然語言發展的關鍵問題。
近20年涉及知識庫的文獻有1633篇,通過分析近3年的200篇文獻,發現各專業各單位在開展知識庫的研究與建設方面互相之間的關注度很高,主要集中在長短句記憶、統計學習方法、知識圖譜構建、命名實體等方面(圖3)。
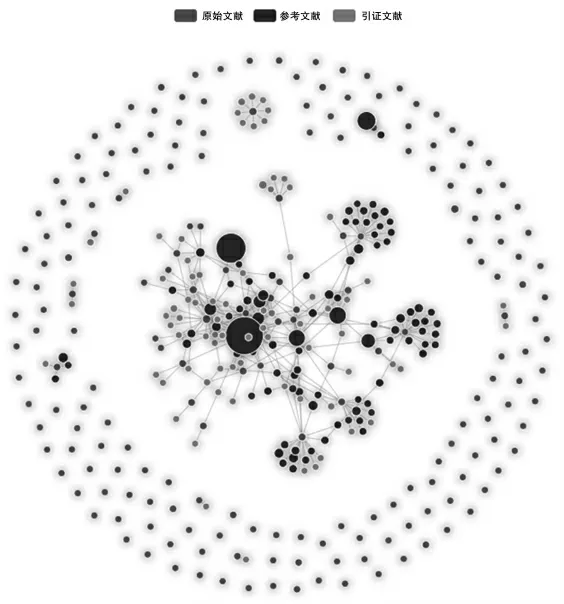
圖3 基于知識庫的文獻互引關系圖
建立詞匯知識庫不但要考慮使用者的便利,還要根據不同的專業類型建立專用詞庫,如:判決文書詞庫、信息知識文庫、媒體專用詞庫、自然資源詞庫、化工材料詞庫等。加強和豐富基礎詞庫建設,將是影響和限制自然語言發展的關鍵環節。
4 結束語
自然語言在文獻知識處理中的應用主要集中在情報檢索、文本挖掘、文本分類、檢索匹配等方面,主要目的是獲取知識。自然語言處理技術在文獻檢索系統中的應用已有諸多成果,但由于自然語言(尤其是漢語)本身的復雜性和多義性增加了檢索和識別的難度,尤其是在知識組織方面很薄弱。鑒于自然語言自身的特點,建議加強基礎數據庫、語料庫、詞匯知識庫的建設,提升計算機處理自然語言的能力。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
