基于查詢語言轉換的多源數據統一訪問框架①
2021-10-11 06:46:20李躍鵬溫亮明黎建輝
計算機系統應用 2021年9期
李躍鵬,溫亮明,黎建輝
1(中國科學院 計算機網絡信息中心,北京 100190)
2(中國科學院大學,北京 100049)
1 引言
大數據應用系統是由多種數據處理工具構成的集成性系統,其數據結構、數據存儲位置、數據管理與分析工具等均具有多樣化特點[1,2].例如在電商系統中,通過關系數據庫管理用戶交易數據,商品數據存儲于文檔數據庫;為加快系統響應速度,通過Key-Value 數據庫緩存高頻率訪問數據;統計報表使用流處理工具、SQL 查詢引擎等進行歷史數據統計分析.在科學大數據管理領域,科研項目通過領域關系型數據庫管理從傳感器、遙感衛星等科學裝置獲得的實驗數據;使用領域非結構化數據庫進行高能物理對撞機事件數據的存儲與索引;通過圖數據庫管理物種、基因組等知識圖譜數據;借助領域數據分析工具對各類實驗數據進行統計與交叉分析,進而得出實驗結論[3].大數據集成系統使用的數據處理工具分為兩類:數據提供者使用標準查詢語言、WebService 等接口方式提供數據庫、開放平臺等基礎數據管理服務;數據消費者調用多個數據提供者接口獲取數據,并通過標準查詢語言、WebService 等接口對多源異構數據進行查詢、統計、分析、展示等操作,如SQL 查詢引擎、數據倉庫、管理系統等.數據消費者與數據提供者之間的數據訪問方式具有以下特點:
(1)數據訪問接口各異:數據提供者接口需經轉換才能符合數據消費者的接口格式要求.比如報表系統中,數據消費者使用SQL 語言對數據進行統計,然而數據提供者的服務接口為文檔查詢、WebService 以及文件等形式.
(2)數據訪問模式多樣:數據消費者與數據提供者之間是多對多數據訪問方式.例如數據倉庫使用SQL語言對多個異構數據源進行分析;而異構數據源除了為數據倉庫提供服務,還會被多個部門或外部應用系統消費.
(3)松耦合方式集成:數據消費者與數據提供者獨立運行、部署與迭代更新.例如作為數據提供者,存儲用戶、業務與實驗等數據的數據庫會根據技術、場景等因素進行更新,然而數據消費者的訪問接口卻并不改變;相反,數據消費者會根據業務、性能等需要調整數據消費者的數據訪問接口.
基于以上數據訪問特點,要實現數據提供者接口與消費者接口的交互協作,集成系統必須提供一個接口適配器以滿足雙方需要,目前已有研究特定應用場景接口適配器的相關工作.隨著數據提供者與數據消費者工具的更新變化,這種針對特定應用場景的一對一型接口適配器勢必難以適應數據遷移與工具迭代更新需要,因此我們提出了一種基于查詢語言轉換的多源數據統一訪問框架,通過引入中間數據模型和雙端適配器將數據訪問接口API 與實際數據模型相分離,使得集成系統具有更好的靈活性和擴展性.
2 相關工作
接口適配器以數據消費者數據模型或數據提供者數據模型作為中間數據模型.首先將數據提供者或數據消費者的Schema 映射為中間數據模型,然后通過數據轉換或查詢語言轉換方式完成接口適配轉換.數據轉換適配器將數據提供者所持有數據動態或一次性轉換為消費者可識別的數據格式進行存儲或處理;查詢語言轉換適配器將數據消費者端的查詢語言轉換為數據提供者端的查詢語言.
根據數據消費者對數據提供者的訪問方式,數據消費者與數據提供者的接口適配方式分為一對一適配、多對一適配以及多對多適配3 種(如圖1(a)至圖1(c)所示).
(1)一對一適配:采用查詢語言轉換方式將數據消費者接口轉換為數據提供者查詢語言.例如文獻Sql2Saprql (RETRO)[4]、Sparql2Sql (D2RQ)[5]、Cypher2sql (Cytosm)[6]等提出了將不同查詢語言轉換為SQL 查詢語句或將SQL 查詢語句轉換為其它查詢語言的方法.
(2)多對一適配:以消費者數據模型為中間數據模型,數據提供者向統一模型動態提供適配數據.例如SparkSQL[7],Presto[8]、Impala[9]等SQL 查詢引擎適配器將關系數據庫、文檔數據庫、CSV 文件、JSON 文件等數據源動態轉換為臨時關系表來實現SQL 統一查詢.Gradoop 適配器將異構數據動態轉換為屬性圖模型的節點和邊來實現Cypher 語言統一查詢[10].
(3)多對多適配:為數據提供者和數據消費者提供接口適配.例如Polystore[11]要求系統支持多種全局數據模型與本地數據模型之間的轉換,通過數據提供者與數據消費之間的成對查詢語言轉換適配器為上層應用提供多樣化數據查詢接口.
以數據訪問接口適配方法存在的問題是中間數據模型與查詢語言模型綁定,使得接口適配器只在單個數據提供者與數據消費者之間產生效用.對于數據轉換適配器,當多個數據消費者的數據模型不同時,數據提供者必須向數據消費者提供不同的適配數據.對于查詢語言轉換適配器,多對多訪問同樣必須采用case by case 方式實現成對查詢語言轉換.當系統中存在n個異構數據提供者和n個數據消費者時,要支持多對多訪問就必須開發n!個適配器,如果新增一個異構數據提供者則需要實現2n個轉換器,從而影響系統對新數據源的擴展性.因此,本文嘗試探索提出一種雙適配器數據統一訪問框架(如圖1(d)所示),通過數據提供者與數據消費者兩端適配器將查詢語言與數據模型分離,從而對新數據提供者與數據消費者的支持只要按需實現一個適配器即可.
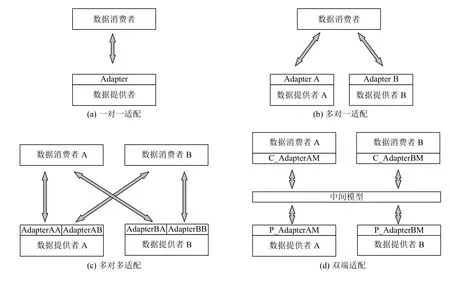
圖1 數據提供者與消費者接口適配方式
3 框架設計
雙Adapter 數據統一訪問框架BAF4DUA 將多個異構數據消費者與數據提供者接口進行適配,為上層應用提供多樣化的數據服務接口.該框架使用中間模型統一表示數據提供者所持有數據,中間查詢計劃統一表示消費者與提供者查詢語言的語義;數據消費者與數據提供者兩端分別與中間模型進行接口適配,將數據訪問接口與數據模型分離,從而支持消費者與提供者多對多數據訪問,提高系統的靈活性與擴展性.
如圖2所示,雙Adapter 數據統一訪問框架由數據消費端Adapter、中間數據模型、中間查詢計劃、數據提供者端Adapter 以及數據映射5 部分構成.
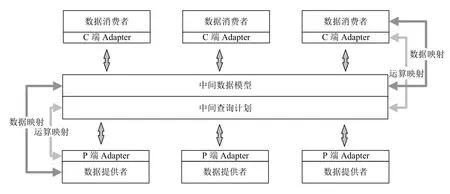
圖2 雙Adapter 數據統一訪問框架
(1)數據消費者端Adapter是系統數據訪問請求的編碼器.它將消費者查詢語句涉及的目標數據與中間數據模型進行映射,同時將查詢語句的語義編碼為中間查詢計劃.根據系統設計需要,數據消費者端Adapter還需對查詢結果進行格式轉換以滿足消費者應用需求.
(2)數據提供者端Adapter是系統數據訪問請求的解碼器,它將中間查詢計劃解碼為數據提供者可識別的查詢語句,實現中間數據模型與數據提供者的數據映射.根據系統設計需要,數據提供者端Adapter 還需要將查詢結果轉換統一數據格式.
(3)中間數據模型為系統多源異構數據提供統一語義視圖,它定義數據的統一表示方式,記錄中間模型的元素構成與數據持有者的映射關系,支持數據的增、刪、改、查、合并等操作.根據系統設計需要,中間數據模型還需定義通用數據格式以供數據消費者與數據提供者之間進行查詢結果轉換.
(4)中間查詢計劃將數據提供者和數據消費者接口對數據的操作進行抽象化處理,定義系統支持的運算類型,實現數據提供者與數據消費者查詢操作與中間查詢計劃運算的相互轉換.由于不同數據提供者和數據消費者對數據運算操作的支持程度不同,根據系統設計需要,還必須對不支持的數據操作進行補償運算.
(5)數據映射將數據提供者所持有數據與中間數據模型進行映射,在映射過程中數據提供者根據中間數據模型的定義,將其所持有的數據按照映射規范向中間數據模型注冊.在此過程中,數據映射規范需要適量增加或減少原有數據的限制以滿足中間數據模型的定義.
4 框架實現
為了驗證BAF4DUA 框架在實際系統中的應用,本文實現了一個多對多數據統一訪問系統,其中數據消費者接口為標準查詢語言,數據提供者接口為常用數據庫.該系統中間數據模型使用實體與關系對數據進行統一表述,數據映射將數據庫、WebService 等查詢接口的數據對象映射為中間數據模型元素.中間查詢計劃選擇四類運算形式化描述查詢語句的語義信息,消費者與提供者Adapter 將各自接口與中間數據模型和中間查詢計劃進行適配.目前系統支持通過SQL、Cypher、MongoDB 等查詢語言接口對不同數據提供者進行數據訪問,在不影響系統其它組成部分的情況下,可實現數據庫遷移、緩存、統一管理等應用需求.
4.1 中間數據模型與數據映射
中間數據模型對集成系統中的異構數據采用統一方式進行語義描述,系統數據用實體(Entity)與關系(Relation)兩個概念對常見數據源進行描述[12].實體為具有相似意義的數據集合,實體元素的具體數據格式不限,既包括結構化形式的表數據,也包括非結構化形式的文檔數據;關系為實體間的語義關聯,可通過多種方式進行表示,關系表示形式包括實體條件表達式或存儲的關系數據.中間數據模型的形式化表示如下:
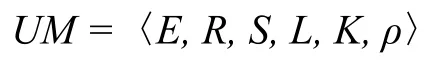
其中,E表示實體集合,R∈(E×E)表示關系集合,S表示數據源集合,L表示用于實體與關系標識的標簽集合,K表示L、S與E、R之間的映射關系,ρ表示S與R之間的數據映射方式.
異構數據源S包括兩種形式:一是以標準查詢語言為訪問接口的數據庫管理工具,如關系數據庫、文檔數據庫以及圖數據庫等;二是其它非標準化數據訪問接口,如WebService、Shell 命令以及文件系統等.S中的每個元素必須包含連接訪問該數據源的所有參數,如連接字符串、URL 以及用戶名密碼等.
映射關系K由兩部分構成:標簽映射Kl:(E∪R)→L表示標簽與ER 元素之間的映射關系,即實體集合與關系由一個標簽唯一標識;數據映射Ks:(E∪R)→(S∪ρ)表示數據源與Entity、Relation 元素之間的映射關系,即Entity 與Relation 由數據源與數據映射方式構成.
針對不同數據源,數據映射方式ρ采用多種方法將異構數據源映射為Entity和Relation 元素.對于提供標準查詢語言接口的數據源,可使用通用的數據映射規范自動將數據源映射到中間數據模型.如表1所示,將關系模型數據中的Table 映射為中間數據模型的Entity 元素,將“外鍵”或屬性相關的邏輯表達式映射為中間數據模型中的Relation 元素;將文檔模型數據源中的Collection 映射為中間數據模型的Entity,將文檔的DBref 或屬性的邏輯表達式映射為中間數據模型的Relation;將屬性圖模型數據源中具有相同Label的節點集合映射為Entity,而將具有同樣Label的邊集合映射為Relation.
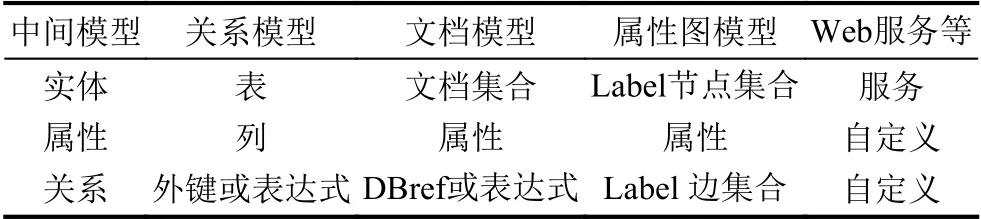
表1 數據映射關系
對于無標準查詢語言接口的數據提供者,需要根據數據提供者的數據訪問接口特點自定義數據源與中間數據模型的映射方式.例如WebService 接口與中間數據模型的映射需要根據服務URL、Token 以及業務參數等與實體、關系進行映射.
4.2 中間查詢計劃
查詢計劃是對查詢語句所表達語義的形式化描述,它是一個節點為數據模型運算的樹形結構.中間查詢計劃p:umsrc→umtarget描述了從數據umsrc向查詢目標數據umtarget轉換的運算過程,它代表了查詢語句的查詢目標,系統支持的運算類型越多,執行計劃能夠支持的查詢功能越豐富.在實現過程中,我們選擇了4 類中間數據模型運算作為中間查詢計劃的基礎組成部分:
(1)scan(umsrc,umtarget,item)運算對參加運算的中間數據模型中實體與關系進行選擇.其中item指umsrc中的實體或關系元素,scan運算將umsrc中的item元素加入umtarget.如果item類型為Relation,scan運算同時將與該Relation 關聯的Entity 添加到umtarget.
(2)filter(umtarget,item,cond,type)運算對umtarget中Entity 或Relation 集合內數據對象進行條件約束.其中item指umtarget中的實體或關系元素,cond為item中數據對象滿足的邏輯表達式條件,type為過濾運算類型.根據不同過濾運算類型,filter運算采用不同形式過濾umtarget中的數據.
(3)link(umsrc,umtarget,item1,item2)運算在Entity 元素item1與item2之間建立一個關系加入umtarget中.建立Relation的方式有兩種:一是通過item1與item2之間的邏輯表達式創建一個臨時Relation;二是從umsrc選擇與item1、item2對應的Relation 加入umtarget.
(4)project(umtarget,cond)運算根據cond條件選擇umtarget中的元素或元素內容保留參與后續運算.cond條件包括兩類:umtarget中Entity 或Relation 元素;Entity或Relation 數據的屬性、列等子元素.
4.3 消費者端Adapter 與數據提供者端Adapter
BAF4DUA 架構中適配器對數據消費者和數據提供者的數據查詢接口進行轉換翻譯:第1 步,數據消費者端Adapter 將數據消費者查詢語句編碼為中間查詢計劃統一表示;第2 步,數據提供者端Adapter 將中間查詢計劃解碼為數據提供者可識別的查詢語句.通過中間查詢計劃對查詢語句的統一形式化表示,BAF4DUA框架將查詢語言接口與數據模型解耦.
查詢語句在數據源執行過程中會解析節點為數據模型運算的邏輯查詢計劃樹,數據源執行引擎遍歷查詢計劃樹依序執行運算節點.數據消費者端Adapter對查詢語句的語義編碼過程需實現中間查詢計劃與邏輯查詢計劃、中間數據模型與數據源的運算映射兩部分內容:
(1)數據映射:主要過程是解析數據消費者請求的查詢語句,獲取查詢語句的目標數據對象,根據數據映射方式ρ獲取目標數據對象與中間數據模型Entity和Relation的對應關系,收集相應的數據作為后續運算參數.
(2)運算映射:主要過程是將數據消費者查詢語句解析為邏輯查詢計劃樹并自底向上遍歷,根據根節點到當前運算節點路徑計算邏輯查詢計劃樹中的每個運算節點所處的狀態并據此確定后續運算映射.邏輯查詢計劃樹的運算節點與中間執行計劃運算節點之間存在一對一、一對多、多對一以及多對多關系,根據運算映射關系生成中間執行計劃的運算節點以及中間執行計劃樹.
與數據消費者端對查詢語句的編碼過程相反,數據提供者端Adapter對中間執行計劃樹解碼操作,生成數據提供者查詢語言接口的邏輯查詢計劃樹.解碼過程根據數據映射方式ρ從中間執行計劃運算節點的參數中抽取出數據源的操作對象,實現中間數據模型與數據源的有效映射.根據中間執行計劃運算節點與邏輯查詢計劃運算節點的對應關系生成邏輯查詢計劃樹,進而生成目標查詢語句提交給數據提供者執行.
5 案例示范
5.1 BAF4DUA 案例工具實現
根據第4 節提出的BAF4DUA 框架實現方案,本文實現了一個支持關系模型、屬性圖模型和文檔模型與中間數據模型的相互映射,以及SQL、Cypher、Mongo 命令3 種查詢語言的相互轉換的案例工具.
如圖3所示,BAF4DUA 案例工具的具體實現主要包括10 個類.UnifiedDataModel 類為Entity 與Relation 組成的圖數據結構,在使用BAF4DUA 案例工具之前需根據數據提供者的數據進行初始化,通過UnifiedDataModel 類,查詢語言轉換過程中可以確定中間查詢計劃、數據提供者查詢對象、數據消費者查詢對象之間的映射關系.接口類Encoder 與Decoder 包含查詢語言與中間查詢計劃UnifiedQueryPlan 進行轉換的encode與decode函數.SqlEncoder、CypherEncoder以及MongoEncoder為Encoder 接口類的具體實現,其中SqlEncoder 首先利用Apache Calcite[13]將SQL 語句解析為SQL 查詢計劃,然后通過遍歷SQL 查詢計劃將SQL 查詢計劃中的JOIN、FILTER 運算以及表達式轉換為UnifiedQueryPlan 中對應運算Operator.類似的,我們使用開源工具Cytosm[14]以及Mongo-Shell-Like-Query[15]分別將Cypher 與Mongo 命令分別解析成相應的查詢計劃,根據4.3 節所述遍歷該查詢計劃生成對應的UnifiedQueryPlan對象.SqlDecoder、Cypher-Decoder 以及MongoDecoder為Decoder 接口類的具體實現.其中SqlDecoder 假設最終生成的SQL 語句模式為:
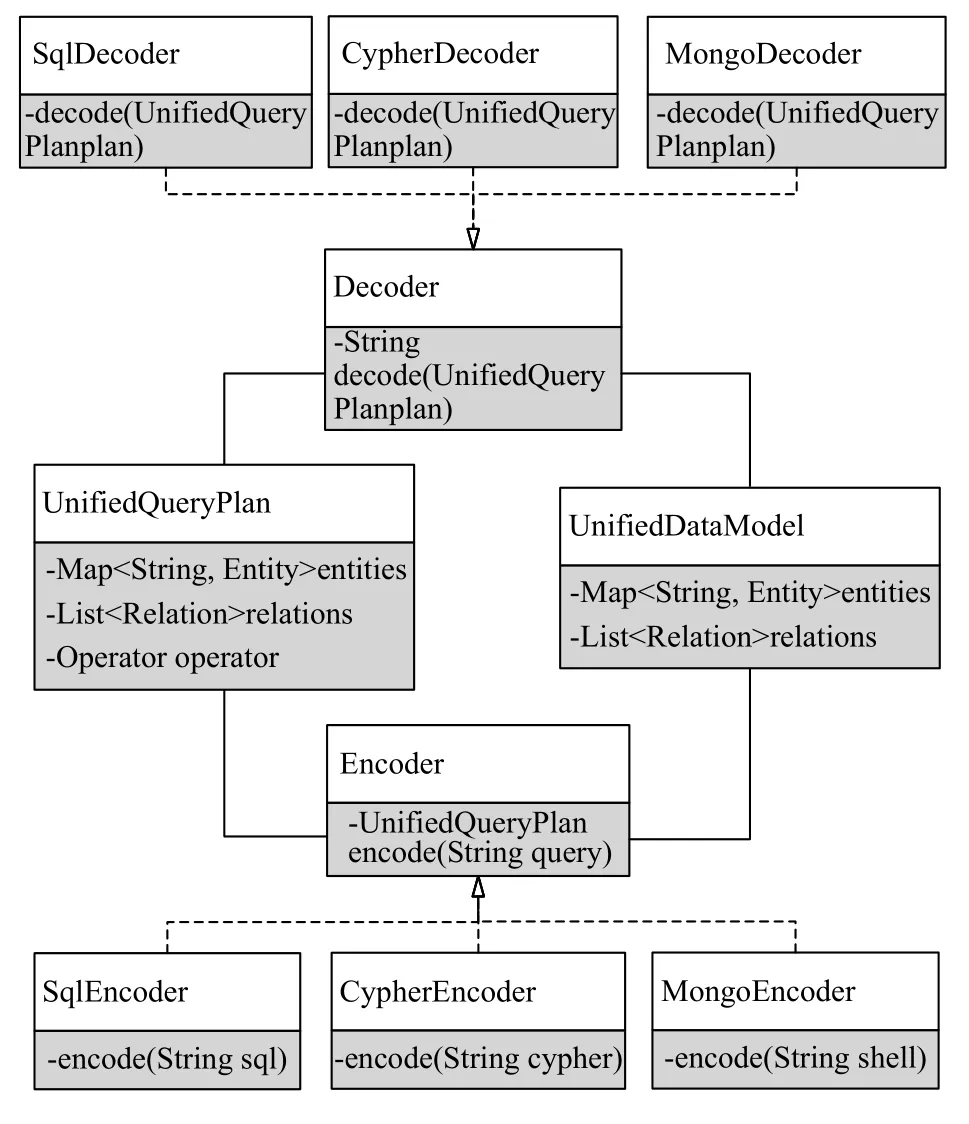
圖3 BAF4DUA 案例工具類
SELECT <RESULT>
FROM <TABLES>
WHERE <CONDITION>
根據UnifiedQueryPlan 類的Entities 與Relations成員生成SQL 語句的SELECT 與FROM 元素;通過解析查詢計劃中的運算Operator 生成SQL 語句的WHERE條件對結果進行過濾;類似的,CypherDecoder 主要針對如下Cypher 句式:
MATCH <ENTITY>
MATCH <RELATION>
WHERE <CONDITION>
RETURN <RESULT>
根據中間查詢計劃UnifiedQueryPlan 生成句式的各部分的內容;MongoDecoder 則將UnifiedQueryPlan中的Operator 運算統一組合成一個Pipeline,將Scan、Filter、Link 以及Project 四類運算轉換為Mongo 命令Pipeline 中的JSON 運算對象,最后將整個Pipeline對象序列化為Mongo Shell 命令語句.
需要指出的是,本文中案例工具的實現方式存在一定的局限性,尤其是Decoder 部分的實現還有很大的提升空間.例如本文使用了固定的查詢語句模式,根據中間查詢計劃分別轉換為固定句式中的組成部分,而不是將中間查詢計劃直接轉換為數據提供者查詢語句對應的查詢計劃.除此之外,本文的案例沒有對聚合查詢、多語句查詢等操作進行處理.
5.2 查詢語言轉換性能
為了驗證查詢語言轉換對查詢性能的影響,我們將生成的1 GB TPCH[16]數據導入關系型數據庫MySQL、圖數據庫Neo4j 以及文檔型數據庫MongoDB 中,對TPCH 基準測試中單表查詢語句Q1 與多表查詢語句Q2的查詢語言轉換與數據查詢時間進行了統計,其中MySQL、Neo4j和MongoDB 數據庫的運行環境如表2所示,查詢時間結果如表3所示.在數據導入過程中,TPCH 數據集的8 個文件分別導出為MongoDB的8 個Collection 以及Neo4j的8 類節點.根據TPCH提供的ER 模型,我們在Neo4j 中創建了節點之間的邊.需要說明的是,TPCH 數據集的不同導入方式以及索引會對后續查詢時間產生一定影響.

表2 數據庫運行環境
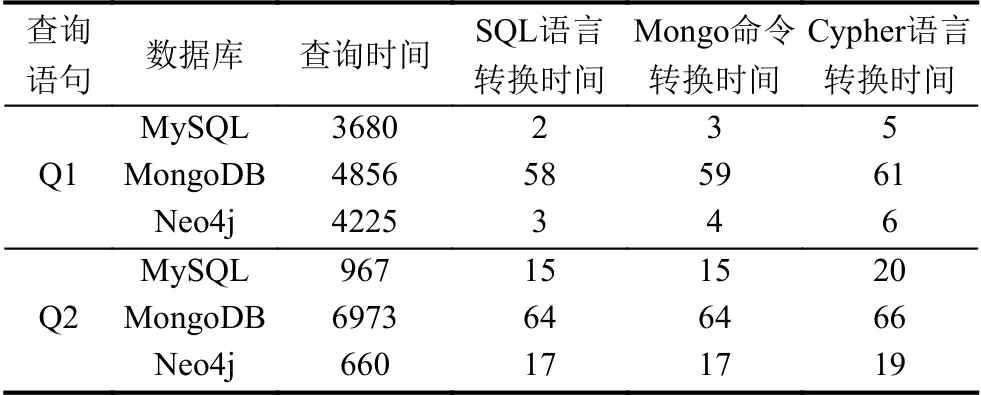
表3 查詢語言轉換與數據查詢時間(ms)
由表3可知,查詢語言轉換時間在70 ms 內,相對于數據查詢時間占比最高不大于1%,并且隨著數據量的增加查詢語言轉換的時間占比會越來越少.由于Mongo 命令的解碼過程使用了第三方的JSON 轉換工具,因此中間查詢計劃解碼為MongoDB 接口的時間要比其它接口的解碼時間更多,故而查詢語言的編碼時間均在10 ms 以下.總體而言,在提高開發效率與系統擴展性、滿足數據統一訪問的前提下,查詢語言轉換帶來的查詢性能損失在可接受范圍之內.
5.3 查詢語言轉換應用案例
案例1.數據庫緩存:為提高系統的響應速度,應用系統通常采用主數據庫與緩存數據庫相結合的方式管理業務數據,例如使用Redis對用戶信息進行緩存.此時系統開發需同時使用SQL 與Redis 語言進行數據查詢,如果能夠將SQL、Mongo 命令以及Cypher 編碼為中間查詢計劃,同時將中間查詢計劃解碼為Redis 查詢語句,那么系統就可以為不同主數據庫增加緩存功能,并且保持系統開發的接口統一性.
為實現以上目標,系統需要一個數據提供者端Adapter 將中間查詢計劃轉換為Redis 查詢語言.其中數據映射將Redis 數據庫中具有一定模式的Key 定義為中間數據模型的Entity;Entity的屬性值與Key 值相對應;Relation 則根據用戶定義表達式進行Entity的關聯.中間查詢計劃與Redis的具體運算映射方式如表4所示.

表4 中間查詢計劃與Redis 運算映射
以客戶Customer 數據為例,假設客戶數據在Redis中Key的存儲模式為<Cust_ID_USERNAME_NATION,customer_object_hash>,那么Customer 實體定義為以字符串“Cust”開頭的Key,實體屬性ID、USERNAME、NATION的值分別對應以“_”進行分割的每個值.如圖4所示,假設系統要查詢“李”姓中國籍客戶,那么使用SQL、Cypher 以及MongoDB 命令進行查詢時會首先編碼為中間查詢計劃,然后再轉換為Redis查詢語句,最后實現Redis對3 類主數據庫的緩存.
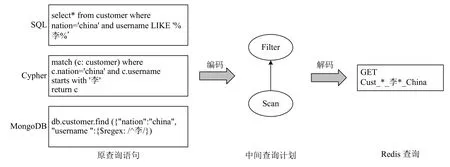
圖4 Redis 查詢語言轉換案例
案例2.數據統一管理:科學數據管理系統通常會查詢多個數據源,甚至會調用不同學科的數據源來驗證假設的真偽.國家重點研發計劃“科學大數據管理系統”項目為用戶提供包括天文、高能物理和微生物3 種異構數據在內的多元異構數據的統一訪問接口.以高能物理數據處理系統EventDB[17]為例,它通過分布式存儲與數據索引,能夠對高能物理實驗中產生的EB級事例進行存儲與查詢.EventDB的接口形式為特定命令,如有以下查詢命令:time=178789800~178807800&detID=1&channel=12&pulse=0~255&eventType=0,其含義為查詢2017年8月31日15:50:00 至2017年8月31日20:50:00 之間5 小時內1 號探測器、12 號通道、0 號事件的脈沖跨度的變化情況.
數據提供者Adapter的數據映射需根據科研用戶的查詢需求和習慣,根據實驗因素與中間模型進行映射.例如相同特征的事例映射與Entity 集合對應;實體屬性為EventDB 中事例的相關數據值;Relation 根據自定義表達式進行Entity 關聯.中間查詢計劃與EventDB命令的映射如表5所示.

表5 中間查詢計劃與EventDB 運算映射
假設用戶習慣按照探測器進行事例查詢,EventDB中的探測器編號為n的事例與Entity 映射,事例的time、detID、channel、pulse 與eventType 等屬性為Entity的屬性值.如圖5所示,如果要查詢3 號探測器在2017年8月31日15:50:00 至2017年8月31日20:50:00 之間內的所有脈沖變化,那么SQL、Cypher、MongoDB的查詢語句可根據以上映射關系首先編碼為中間查詢計劃,然后轉換為EventDB 查詢命令.

圖5 EventDB 查詢語言轉換案例
6 結論與展望
在大數據時代,集成系統使用多樣化工具對內外部數據進行統一管理分析,這增加了系統開發、數據管理工具更新遷移以及數據統一管理等任務的接口適配成本.本文提出了一種基于查詢語言轉換的多源數據統一訪問框架BAF4DUA,該框架特色之處在于采用了雙Adapter 模式:數據消費者Adapter 先將消費者數據訪問接口語言轉換為中間數據模型的查詢計劃,而后通過數據提供者端Adapter 將中間查詢計劃轉換為數據提供者的數據訪問接口.通過BAF4DUA 框架,可實現數據消費者的查詢語言接口與數據源的數據模型相分離,數據消費者和數據提供者可采用即插即用的方式增加或更新相應的Adapter,增加了系統的靈活性與擴展性,更符合集成系統多對多數據訪問的特點.
本文所提BAF4DUA 框架的局限性在于僅考慮了單一使用場景下的數據查詢操作,還需要進一步完善以適應更復雜的數據統一訪問應用場景.后續研究可從以下幾個方面進一步拓展:(1)設計與實現支持具備count、sum 等更豐富功能的查詢運算類型;(2)設計與實現查詢數據位于不同數據庫場景下的數據處理方案;(3)設計與實現智能化數據統一插入存儲方案.
猜你喜歡
人民交通(2019年16期)2019-12-20 07:03:52
消費導刊(2018年22期)2018-12-13 09:19:00
現代營銷(創富信息版)(2018年2期)2018-02-10 05:20:49
瞭望東方周刊(2017年34期)2017-09-13 17:13:26
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年16期)2016-08-21 13:56:16
財經(2016年15期)2016-06-03 07:38:02
發明與創新(2016年21期)2016-05-17 03:57:29
財經(2016年3期)2016-03-07 07:44:46
