基于圖卷積神經網絡的專利語義模型構建研究*
2021-10-12 12:27:54余軍合鄧慧君施培妤胡國建
機械制造 2021年9期
□ 沙 鶴 □ 余軍合 □ 鄧慧君 □ 施培妤 □ 胡國建
寧波大學 機械工程與力學學院 浙江寧波 315211
1 研究背景
當前,專利數據量龐大,簡單的關鍵詞檢索已經無法滿足設計人員在短時間內匹配關聯度較高的專利的需求。專利智能檢索能夠極大地縮短設計人員的查閱時間,提高工作效率。
隨著大數據技術與信息科學處理技術的出現和發展,如何將數據處理技術與方法應用于專利語義網絡,引起了學者的廣泛關注,同時為專利智能檢索提供了技術支持。
基于專利語義模型進行專利檢索時,可以通過輸入一個詞、一句話或一段文字進行查詢,而不必考慮文本中是否包含有關鍵詞。構建高準確性的語義模型,是提高專利檢索準確度的重要方式。語義模型的發展由基于詞袋模型向基于向量模型跨越。楊宏章等[1]基于專利文本結構構建專利語義模型,提高了檢索效率。Zhang Longhui等[2]提出一種基于領域內高平均值頻率術語的專利語義模型,用于目標主題專利的查詢。姜春濤[3]提出基于關鍵詞和依存關系樹的圖模型,為專利智能分析提供語義支撐。王秀紅等[4]針對領域專利知識庫構建,提出由專利文本向量表示專利語義信息的方法。曹洋[5]基于文本排序算法提取文本中語義信息,構建拓撲圖,提升了文本主題的語義準確性。劉斌等[6]采用神經網絡提取專利和論文的特征,實現論文與專利之間的聯系,并提出基于深度學習的專利語義模型。Wu Hengqin等[7]針對技術專利中領域專業技術難以識別的問題,提出應用深度學習的方法來自動識別目標專利。吳素雪[8]提出一種基于卷積神經網絡的專利語義模型,提高了檢索準確度。隨著機器學習算法的發展,在向量模型下構建專利語義已成為研究的熱點,不僅僅局限于關鍵詞的檢索是這一方法的重要應用特點。
深度學習在自然語言處理方面,Srivastava等[9]采用受限玻爾茲曼機對文檔進行主題建模,Hill等[10]使用多層感知機卷積神經網絡、循環神經網絡等對文檔進行建模。前者只考慮詞語間的主題關系,不考慮文檔內的語序問題,后者則主要以滑動窗口對文本建模。在文本分類中,郭利敏等[11]通過卷積神經網絡對小批量文字生成批量文本,將古籍漢字的識別問題轉換為卷積神經網絡的分類問題。最近,圖網絡模型的新發展引起了研究人員的廣泛關注,越來越多的圖網絡模型被人們所熟知[12]。Yao Liang等[13]采用圖卷積神經網絡(GCN)進行文本分類,提出基于文本的圖卷積神經網絡模型。Liu Xi’en等[14]對圖卷積神經網絡進行深一步研究,構建張量圖卷積神經網絡,用于整合各種圖形的異構信息。
圖網絡可以依靠節點之間的信息傳遞來捕捉圖中的依賴關系,圖卷積神經網絡依托于可以建立不規則數據結構的圖網絡,這給筆者基于圖卷積神經網絡構建專利語義模型提供了理論基礎。
2 專利語義模型構建方法
構建基于圖卷積神經網絡的專利語義模型,主要思路是通過確定網絡節點和節點間的連邊關系,構建合適的網絡模型,能夠基于節點特性和整個網絡結構性質,結合神經網絡算法來提取專利語義信息。
在基于圖卷積神經網絡的專利分類模型部分,筆者通過構建專利文本中專利與摘要、摘要中字與字的連邊關系進行圖網絡的構建。
為了探究字與字構建模型的語義和詞與詞構建模型的語義的差異性,基于詞頻-逆向文檔頻率(IF-IDF)算法對摘要進行主題詞提取,通過摘要主題詞與關鍵詞間的節點關系對摘要中字與字構圖方式進行了研究分析。
在基于余弦相似度的圖卷積神經網絡模型分析部分,筆者對兩種不同構圖方式構建的圖卷積神經網絡模型進行分類,并基于分類效果圖分析模型的可靠性。結合相似專利與基準專利,在基于兩種構圖的圖卷積神經網絡模型下進行余弦相似度計算,通過相似度對比分析兩個模型的效果。
筆者基于設計方法學中的三種設計人員常規檢索專利方式,以功能、功能-原理、功能-原理-結構三種檢索式為研究對象,將針對三種檢索式的設計需求作為檢索語句嵌入圖網絡,進行相似專利的匹配。基于返回用戶檢索的結果,采用專利檢索評估方法來評估不同檢索式的優劣。
基于圖卷積神經網絡的專利語義模型構建方法具體流程如圖1所示。
3 圖卷積神經網絡構建方法
3.1 圖卷積神經網絡
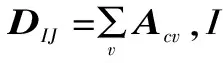
(1)
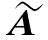
通過疊加多個圖卷積神經網絡層來合并高階鄰域信息:
(2)
式中:H(k)為第k層輸入的特征矩陣;H(k+1)為第k+1層輸入的特征矩陣;Wk為經過k層訓練得出的權重參數。
兩層圖卷積神經網絡可以允許在兩個最大距離的節點間進行消息傳遞,因此,盡管圖中沒有直接構建的專利與摘要的邊,但是兩層圖卷積神經網絡允許在文檔之間交換信息。筆者在初步試驗鄰接矩陣時發現兩層圖卷積神經網絡的性能優于一層圖卷積神經網絡,但更多的層數并不能提高性能。
3.2 異構網絡圖
筆者在專利與摘要主題詞的連邊上應用詞頻-逆向文檔頻率權重。在構建摘要主題詞與摘要主題詞間的連邊時,為了應用全局詞共現信息,在專利庫中所有摘要主題詞上使用一個固定大小的滑動窗口來收集共現信息。通過應用點互信息算法來計算兩個摘要主題詞節點之間的權重。點互信息算法是一種常用的詞關聯度量方法,應用點互信息算法相比應用單詞共現計數,可以獲得更好的結果。
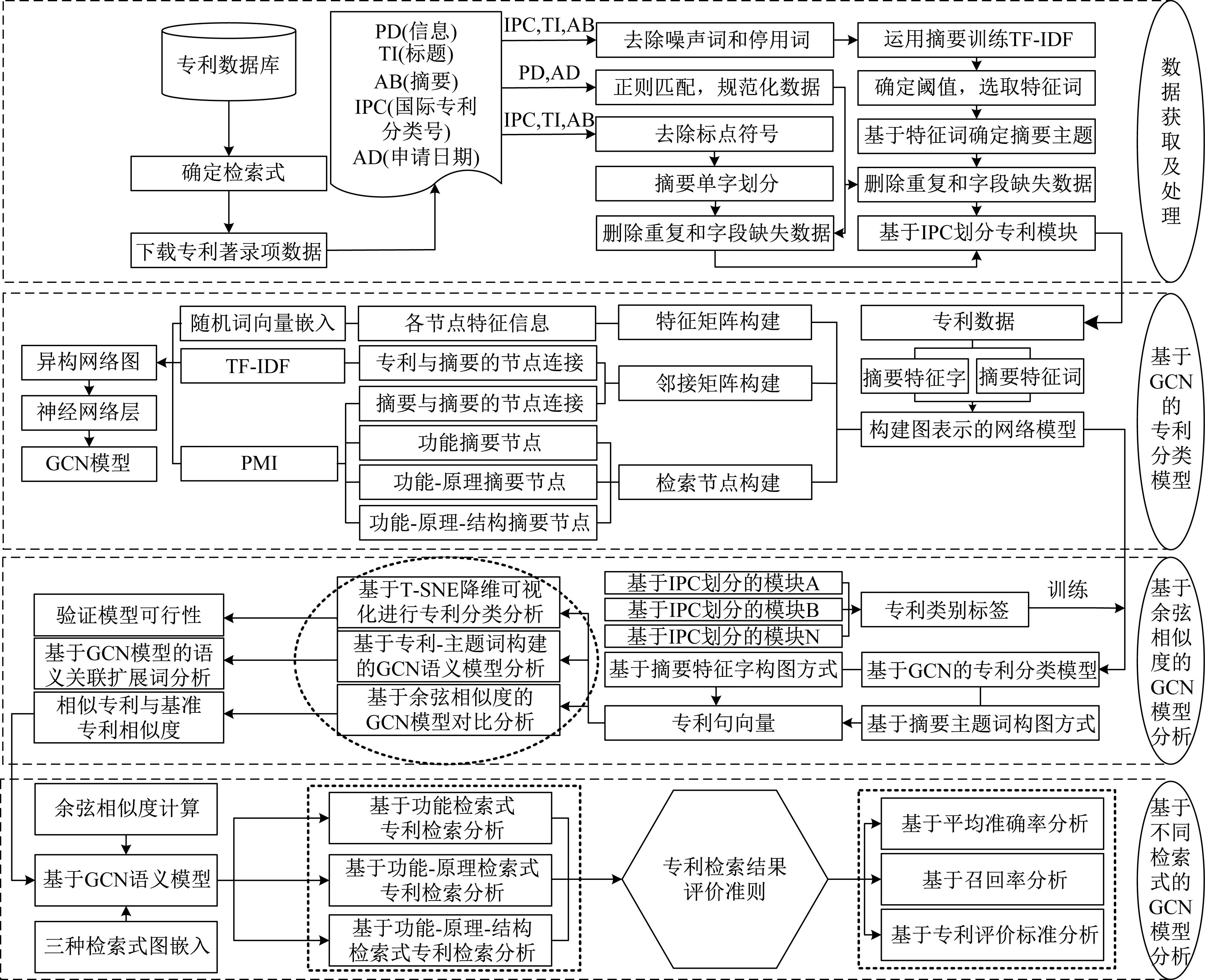
▲圖1 基于圖卷積神經網絡的專利語義模型構建方法流程
鄰接矩陣Acv為:
(3)
式中:S(e,j)為兩個主題詞間的點互信息值數據集;M(i,j)為專利與摘要主題詞的詞頻-逆向文檔頻率權重數據集。
S(e,j)為:
(4)
p(e)=W(e)/W
(5)
p(j)=W(j)/W
(6)
p(e,j)=W(e,j)/W
(7)
式中:W為滑動窗口總數;W(e)為在一個專利庫中包含鄰接矩陣中行摘要主題詞的滑動窗口數;W(j)為在一個專利庫中包含鄰接矩陣中列摘要主題詞的滑動窗口數;W(e,j)為在一個專利庫中同時包含行摘要主題詞和列摘要主題詞的滑動窗口數;p(e)為行摘要主題詞在整個訓練專利文本中出現的概率;p(j)為列摘要主題詞在整個訓練專利文本中出現的概率;p(e,j)為行和列摘要主題詞在整個訓練專利文本中同時出現的概率。
點互信息值為正,表示主題詞與主題詞間的相關性較大。點互信息為負,表示主題詞與主題詞間的相關性較小或不存在。所以,僅給點互信息值為正的兩個摘要主題詞節點連邊。
逆向文檔頻率關系式為:
Q(tl)=log(N/b+0.01)
(8)
式中:Q(tl)為摘要主題詞tl的逆向文檔頻率數據集;N為專利庫中專利的總數;b為包含摘要主題詞tl的專利數。
詞頻-逆向文檔頻率權重M為:
M=PQ(tl)
(9)
式中:P為鄰接矩陣行中摘要主題詞tl在鄰接矩陣列所有專利中出現的次數。
筆者基于字與詞的語義差異性,構建基于專利-單字符和專利-主題詞兩種異構圖的圖卷積神經網絡模型,進行語義模型的研究。構圖中,需要分別對數據進行字符級別的分詞與主題詞提取處理。單字符提取主要通過單字劃分實現。主題詞提取時,先對專利摘要進行數據預處理,再應用詞頻-逆向文檔頻率算法選出專利主題詞。兩種構圖方式舉例見表1。
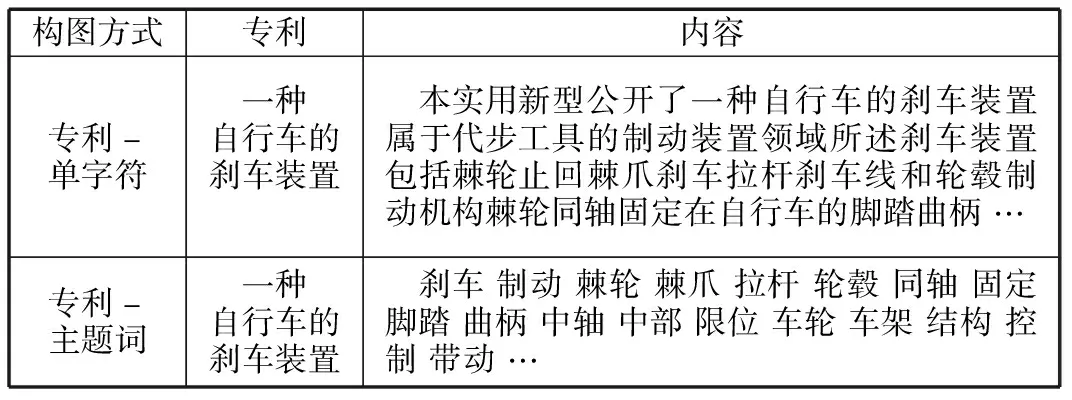
表1 構圖方式舉例
兩種構圖方式的圖卷積神經網絡結構如圖2所示。圖2中,數據集的全部文檔可以表示為D= {d1,d2,d3,…,dn},n為數據集中專利文檔總數。數據集中基于專利-主題詞構建異構文本圖時,全部主題詞可以表示為W={w1,w2,w3,…,wm},m為數據集中專利摘要文本主題詞的總數。數據集中基于專利-單字符構建異構文本圖時,全部單字符可以表示為C={c1,c2,c3,…,cx},x為數據集中專利摘要文本字符的總數。

▲圖2 兩種構圖方式圖卷積神經網絡結構
4 試驗數據集
筆者基于incoPat專利數據庫檢索所需專利數據,采用自行車基本設計結構25個不同配件的關鍵詞,分別搭配自行車主題用于檢索專利數據,共計檢索專利32 684條。由于外觀設計型專利技術特征基于設計圖來展示,與摘要關聯較小,因此筆者選取實用新型和發明專利作為分析數據,篩選出專利共計27 406條。
試驗數據中,自行車的國際專利分類號繁多,共計484種。將國際專利分類號作為訓練標簽類別分類特征不明顯,因此筆者的試驗基于模塊化設計思想,結合國際專利分類號查詢,將國際專利分類號映射至設計模塊。自行車按模塊設計可劃分為車架系統設計模塊、車輪系統設計模塊、車座系統設計模塊、導向系統設計模塊、傳動系統設計模塊、制動系統設計模塊。基于這六個模塊,結合國際專利分類表,進行專利類別標簽劃分。專利類別標簽劃分見表2。

表2 專利類別標簽劃分
5 試驗結果分析
5.1 分類效果
筆者基于Python編程軟件和張量框架構建圖卷積神經網絡模型,在圖卷積神經網絡結構中,卷積層第一層和第二層的嵌入維度設置為200。隨機選擇訓練集的20%作為驗證集,為防止過擬合,設置拋出隱藏節點率為 0.5,學習率為0.01。設置200個訓練周期,若連續10個周期的驗證損失率沒有降低,則停止訓練。模型采用準確率、召回率、綜合評價分數,進行性能評價。
將處理后的數據輸入所構建的圖卷積神經網絡模型,為體現方法的適用性,選擇專利-單字符構圖方式和專利-主題詞構圖方式進行對比試驗。采用專利-單字符構圖方式,輸入節點數為30 258。采用專利-主題詞構圖方式,輸入節點數為66 032。試驗結果表明,基于專利-單字符構圖方式的圖卷積神經網絡模型,分類整體的平均準確率為0.810 3,基于專利-主題詞構圖方式的圖卷積神經網絡模型,分類整體的平均準確率為0.793 7。兩種構圖方式的分類效果對比見表3。
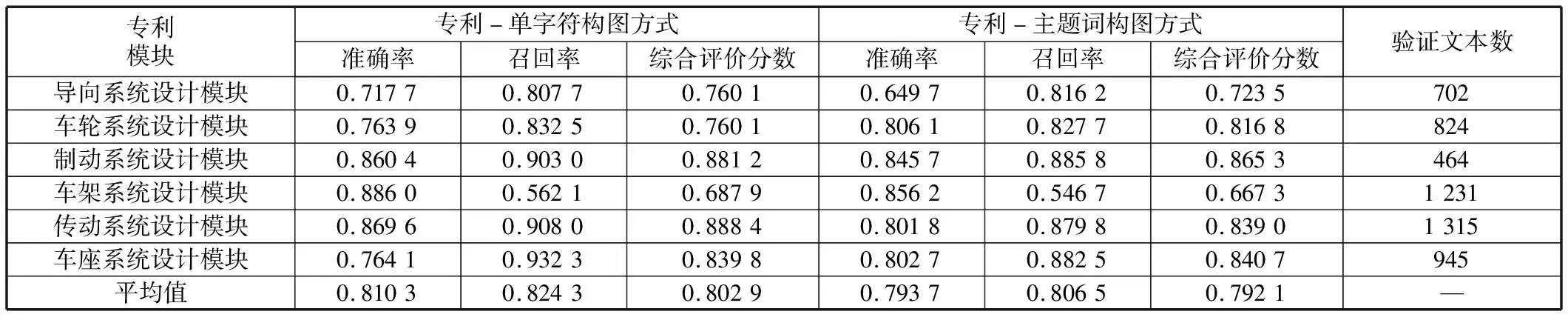
表3 兩種構圖方式分類效果對比
5.2 專利分類可視化
使用t分布隨機鄰居嵌入算法進行高維向量降維可視化,對學習到的文檔嵌入可視化。兩種構圖方式的專利分類可視化如圖3所示。圖3中,+表示傳動系統設計模塊相關專利,▲表示導向系統設計模塊相關專利,■表示車座系統設計模塊相關專利,▼表示車架系統設計模塊相關專利,●表示車輪系統設計模塊相關專利,★表示制動系統設計模塊相關專利。
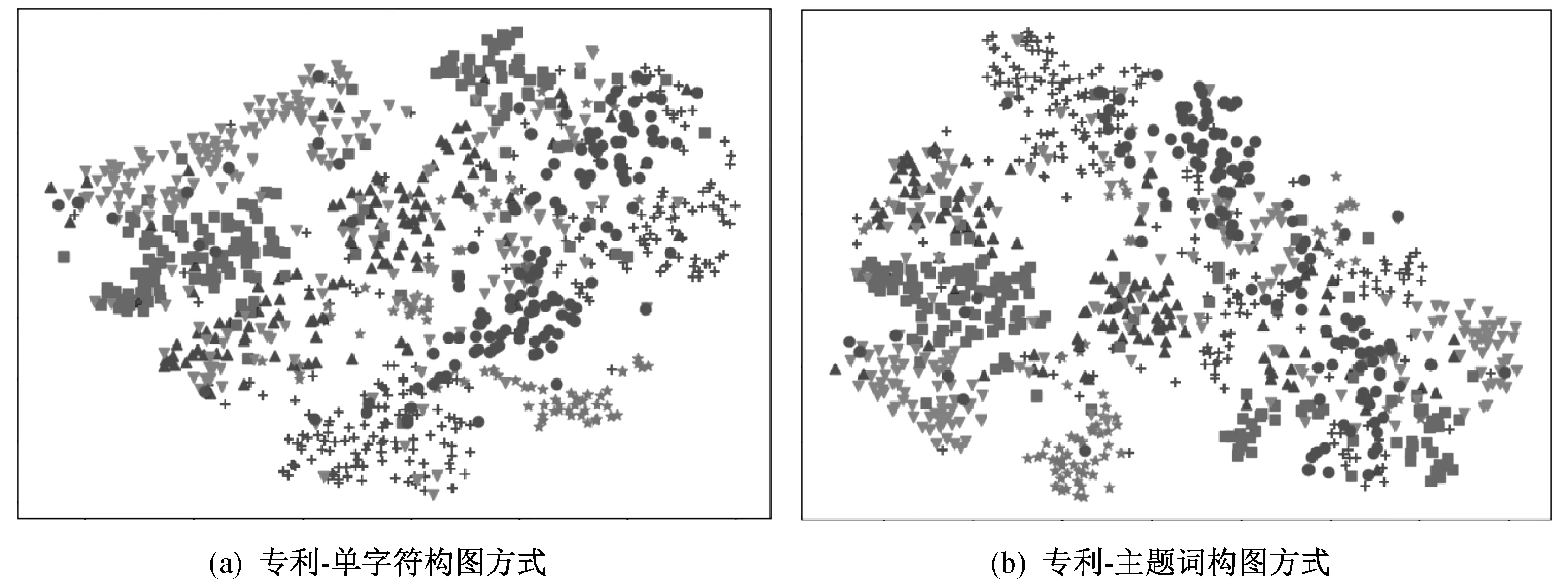
▲圖3 兩種構圖方式專利分類可視化
由圖3可以看出,帶有相同標簽的專利彼此接近,在向量空間中可以區分出六種類型。六種類型各自聚集在一起,這意味著大多數摘要主題詞與對應的設計模塊密切相關。由圖3還可以看出,車架系統設計模塊專利分類效果差于其它類別,這是由于車架系統設計模塊相關專利中的摘要會涉及許多其它模塊相關專利的主題詞,車架系統設計模塊相關專利和其它模塊相關專利的耦合性較強。
5.3 專利語義模型效果
為了進一步對不同構圖方式的專利語義模型效果進行分析,將六類基準專利作為基準向量,對各類相似專利與對應的基準向量進行余弦相似度計算,得到專利語義模型的準確性。筆者所選用的測試專利與基準專利見表4。

表4 測試專利與基準專利
兩種構圖方式的專利語義模型余弦相似度如圖4所示。由圖4可知,六大類共18項專利中,16項專利在基于專利-單字符構圖方式圖卷積神經網絡的專利語義模型中與基準專利的余弦相似度大于基于專利-主題詞構圖方式圖卷積神經網絡的專利語義模型。因此,在向量空間中,基于專利-單字符構圖方式圖卷積神經網絡的專利語義模型的基準專利與測試專利之間的向量更為接近,模型呈現的語義關系更加準確。這說明了基于專利-單字符構圖方式圖卷積神經網絡的專利語義模型的效果優于基于專利-主題詞構圖方式圖卷積神經網絡的專利語義模型。
6 檢索分析
6.1 專利查詢評價標準
專利查詢結果往往通過召回率與準確率來衡量,召回率計算時并沒有考慮用戶因素和相關文檔的排名。目前也有一些算法,如綜合評價分數,對召回率進行改進,但是對于專利集合未知的檢索需求還存在一定問題。鑒于此,Magdy等[15]提出一個結合結果中相關文檔排名情況的專利檢索評價標準,計算式為:
(10)
(11)
式中:H為專利檢索評價標準值;Zmax為返回給用戶的最大檢索專利數;rq為第q個相關文檔的排名;a為相關文檔數;R為Zmax中的相關文檔數。
對于專利檢索,最基本的衡量在于召回率,這個結果關注檢索算法的查全率。
平均準確率對于單個主題而言,指每條相關專利被檢索后的平均準確率。平均準確率是反映系統相關專利排名的一個指標,檢索結果中相關專利排名越靠前,平均準確率就越高。如對于一個檢索句,返回結果相關專利有五個,排名為1、4、7、9、13,則平均準確率計算結果為:
(1/1+2/4+3/7+4/9+5/13)/5=0.552
專利檢索評價標準不僅考慮檢索結果中相關專利的排名情況,而且兼顧召回率。專利檢索評價標準值越大,說明檢索算法的召回率越高,相關專利的排名越靠前。
6.2 不同檢索式對比
在較好的專利-單字符構圖方式圖卷積神經網絡的專利語義模型的基礎上,基于設計方法學對設計人員常規使用的檢索方式進行研究,對專利描述文本按功能-原理-結構、功能-原理、功能三種不同檢索式進行對比試驗。采用三種句式進行語義檢索,分別為:① 為了達到防止剎車鎖死的目的,主要通過剎車器的彈性件與移動座之間的動作關系來實現,剎車器的構成部分有夾臂、滑槽、制動組件、軸部、彈性件;② 為了達到防止剎車鎖死的目的,主要通過剎車器的彈性件與移動座之間的動作關系來實現;③ 為了達到防止剎車鎖死的目的。檢索出相似專利文本,按照相關程度從高到低排序,選取前幾項專利。三種檢索式余弦相似度分析見表5。

▲圖4 兩種構圖方式專利語義模型余弦相似度

表5 三種檢索式余弦相似度分析
由表5可以看出,余弦相似度排名前幾位的專利雖然應用功能不完全相同,但是專利的摘要內容與檢索文本內容有所關聯,這符合檢索文本的目標主題。由余弦相似度可知,檢索文本內容越豐富,最為相關的專利的余弦相似度就越小。這是因為在空間語義模型中,句子越長的文本,所包含的語義越豐富,語義吻合度極高的文本相對就越少。
6.3 檢索結果分析
在基于專利-主題詞構圖方式圖卷積神經網絡的專利語義模型中,對于專利描述文本“為了達到防止剎車鎖死的目的,主要通過剎車器的彈性件與移動座之間的動作關系來實現,剎車器的構成部分有夾臂、滑槽、制動組件、軸部、彈性件”,文本主題詞為“剎車”“鎖死”“夾臂”“滑槽”。筆者為提高專利文本語義分析的準確性,提取主題詞的相關擴展詞進行協同驗證,將訓練后的基于專利-主題詞構圖方式圖卷積神經網絡的專利語義模型輸出的38 531個主題詞詞向量與目標主題詞進行余弦相似度計算,進行相似詞擴展。將余弦相似度閾值設定為0.7,選取語義近似的五個詞,語義關聯詞擴展結果如圖5所示。
專利檢索評價數據選用專利語義模型輸出的余弦相似度排名靠前的300條專利數據,作為文檔庫專利。此外,將其中的前30條作為返回給用戶的檢索最大結果數。通過主題詞及其語義關聯詞的包含與否作為評價專利是否相關的依據,統計結果見表6。
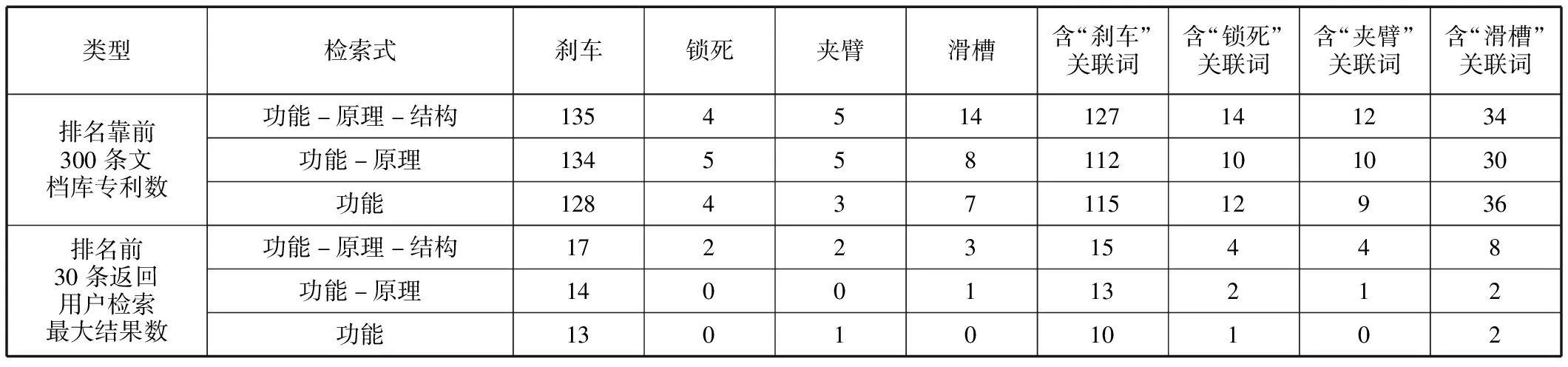
表6 主題詞及語義關聯詞相關專利統計結果
選用的評價標準主要有平均準確率、召回率、專利檢索評價標準,專利檢索評價結果如圖6所示。
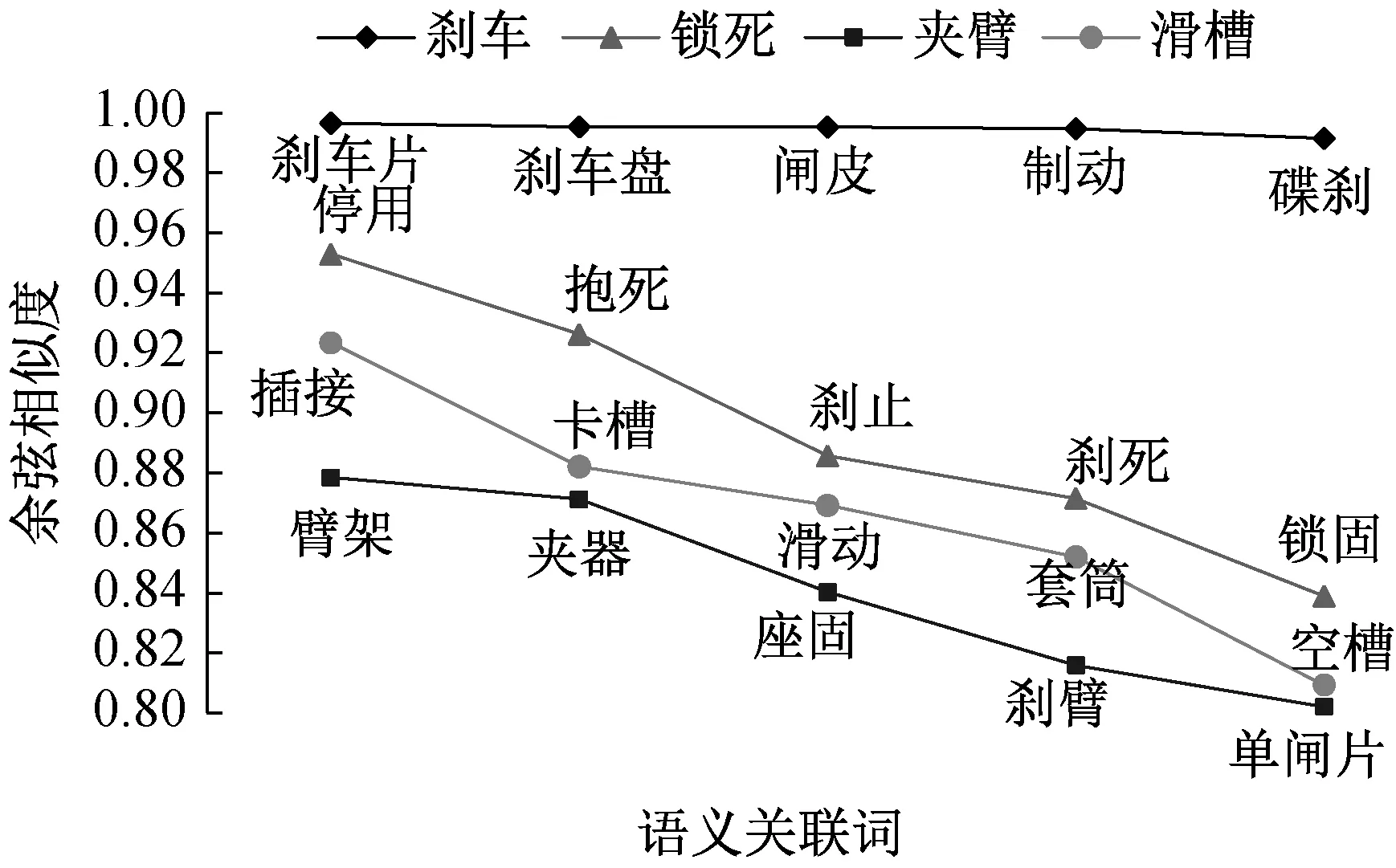
▲圖5 語義關聯詞擴展結果
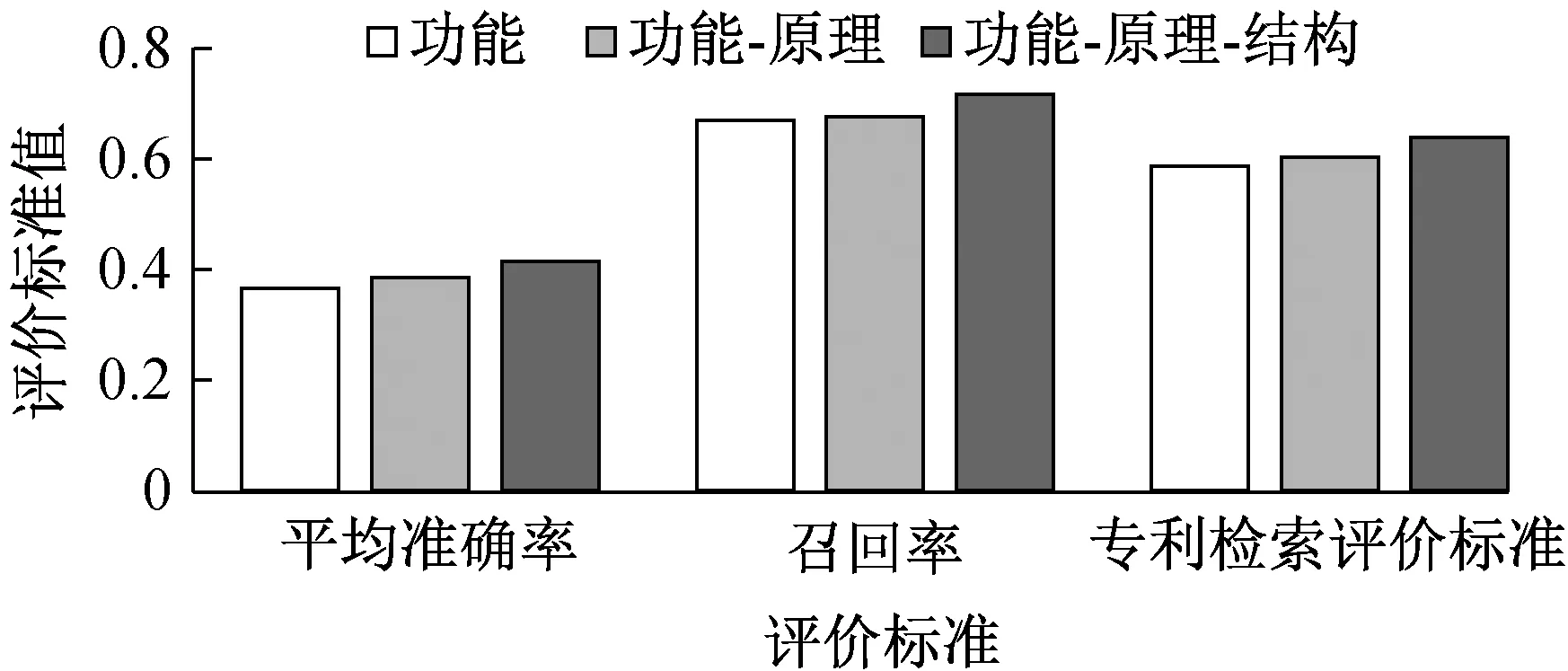
▲圖6 專利檢索評價結果
由圖6可知,功能-原理-結構檢索式效果相比功能-原理、功能檢索式更好,因此,基于專利-單字符構圖方式圖卷積神經網絡的專利語義模型在功能-原理-結構檢索式中檢索效果更佳。
7 結束語
專利由于專業性和專利詞匯的相似性,不能簡單將普通文本直接應用于專利檢索。筆者通過構建基于圖卷積神經網絡的專利語義模型來對專利領域進行檢索,通過不同構圖方式和不同檢索式來對模型進行評估,通過數據分析和對比可知,采用基于專利-單字符構圖方式圖卷積神經網絡的專利語義模型,結合功能-原理-結構檢索式,在檢索效果方面更佳。筆者基于圖卷積神經網絡構建的專利語義模型在一定程度上使檢索變得更加智能,可以為設計人員獲取設計創新知識提供更佳有效的專利檢索方式。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
