設備協同管控及安全生產智能調度系統的研究
2021-10-14 06:43:18張偉
山東煤炭科技 2021年9期
張 偉
(晉能控股煤業集團,山西 大同 037000)
1 項目概況
晉能控股煤業集團塔山礦位于山西省大同煤田東翼中東部邊緣地帶,距大同市約30 km。井田東西走向長度17.22~20.84 km,平均24.3 km,南北傾斜寬度9.36~12.56 km,平均11.7 km,井田面積為168.88 km2。塔山礦為同煤集團第一個開采石炭系特厚煤層的千萬噸級礦井,礦井設計產能15 Mt/a,服務年限140 a。
塔山礦結合礦山生產設備管理以及安全生產的具體需求,圍繞礦山設備協同管控、在線診斷及安全生產智能調度的理論、技術和方法,研究基于云平臺的礦山設備協同管控、在線診斷及安全生產智能調度的系統架構與集成開發技術;按照礦山“人、機、環”的異構資源與各類服務的統一描述方法和安全判識準則,建立基于云交互平臺的設備協同管控、在線診斷與智能調度的服務系統,為該煤礦生產系統提供遠程在線診斷與智能調度綜合服務[1-2]。
2 設備協同管控及安全生產智能調度系統的建設
塔山礦設備協同管控及安全生產智能調度系統的建設主要是從設備協調管控系統、安全生產智能調度、煤流運輸設備在線診斷、大型機電設備故障診斷系統、應用系統集成展示五個方面進行建設。
2.1 設備協同管控系統
設備協同管控系統主要包含四部分,主煤流實時監測、協同管控模型、模型訓練、歷史記錄四個部分。
協同管控模型:將底層復雜的多源異構數據以網絡服務形式統一封裝成上層抽象資源;將設備管理與生產管理相結合;將每一個設備管理層次視作一個設備智能協同管控模塊;將物聯網環境中礦山生產設備的各種時間和空間功能服務與信息服務,按照業務應用需求進行流程組合與任務編排,從而建立礦山物聯網生產設備多級協同管控模型。
模型訓練:利用煤流運輸系統設備運行信息、設備故障信息、環境安全信息等各方面的歷史數據,通過多智能體學習訓練,生成設備協同管控模型;將設備實時運行數據經過預處理后輸入到訓練好的設備協同管控模型,實現在線智能決策,進而實現協同管控任務調度,如圖1。
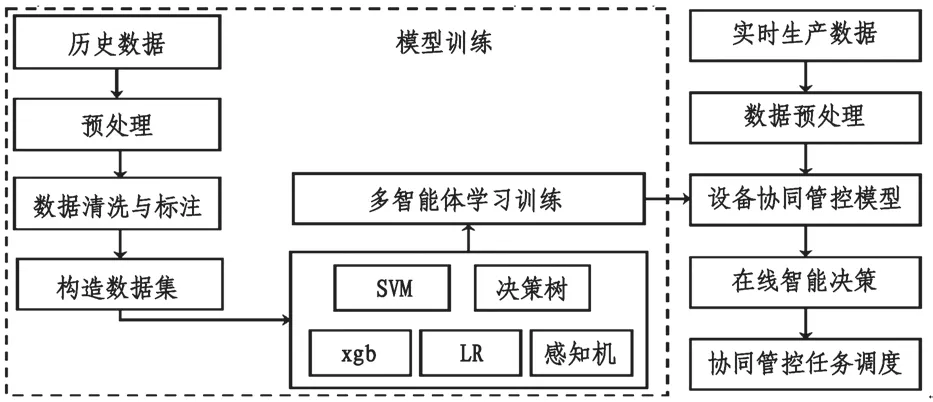
圖1 協同管控模型訓練示意圖
2.2 安全生產智能調度系統
面向多生產場景的礦山安全生產智能調度系統的目標是在生產資源模型和生產業務流程模型的基礎上,構建智能調度算法,為塔山礦井下安全生產任務調度輔助決策提供參考。
2.3 煤流運輸設備在線診斷系統
塔山礦煤流運輸設備在線診斷系統主要包括一部皮帶系統和二部皮帶系統。分析界面主要包含核心傳感器實時數據、系統實時的健康狀態、實時的能量轉換效率,并統計了一段時間內的健康狀態。皮帶檢測算法模型如圖2。
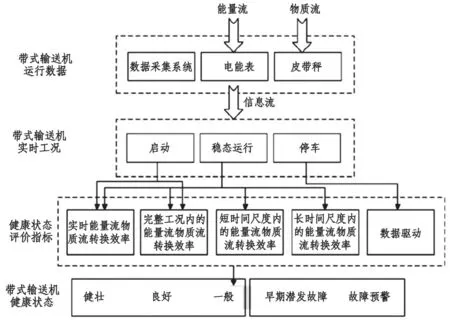
圖2 皮帶檢測算法模型示意圖
2.4 大型機電設備故障診斷系統
2.4.1 通風機
塔山礦主通風系統分析界面分為兩部分:實時監測和風機狀態分析。其中實時監測界面,用戶通過左側模型樹定位具體的部件模型,并同時顯示該部件傳感器的實時數據。風機狀態分析界面,主要通過圖表的分析展示了風機的核心傳感器的實時數據和實時數據曲線。系統10 s計算一次風機運行情況,并實時更新知識界面。塔山礦主通風電機故障診斷模型如圖3。

圖3 主通風電機故障診斷模型示意圖
2.4.2 提升機
提升機的界面主要包含了基本的傳感器數據以及實施的穩態工況,直觀地表達出當前提升機的健康狀態以及能量轉換效率。提升機系統關聯故障分析診斷模型如圖4。
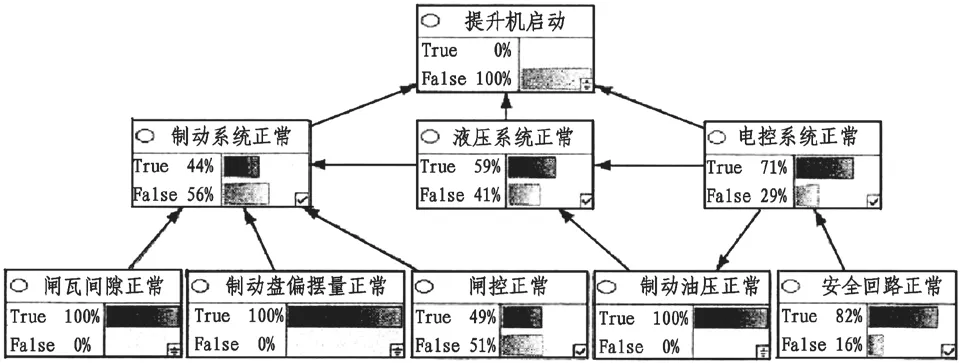
圖4 提升機故障分析診斷模型
2.5 應用系統集成展示
應用系統集成展示主要包括以下幾方面:(1)定時任務管理:定時任務實現業務、數據處理的定時執行;(2)緩存管理:緩存管理將系統經常使用的核心基礎數據存放到內存中,便于前端展示界面實時調用;(3)數據采集管理:數據采集管理實現自動化數據的實時采集;(4)數據標準化管理:數據標準化管理將系統接入的自動化實時數據進行標準化,進行單位、設備、傳感器編碼統一,便于算法及實時展示界面調用;(5)門戶管理:用戶點擊左側系統管理功能菜單,進入系統管理,系統管理主要維護系統的用戶、權限、sql監控、用戶操作日志、菜單管理等基礎功能。
3 系統技術分析
3.1 系統架構
3.1.1 總體架構
系統按照統一的數據采集管理、統一的算法集成、統一身份服務實現權限管理和信息綜合展現。系統由采集層、存儲計算層、服務層、應用層四個層面組成。
系統向下采集數據,向上為算法提供支撐,最終通過三維可視化進行效果展示。通過采集層實現從自動化集成監控系統進行數據采集;在存儲計算層中的數據存儲、備份、清洗進行數據的統一存儲;通過服務層各類服務組件,實現業務底層業務的統一處理;最終應用層通過統一應用門戶集成設備在線診斷、協同管控與系統智能調度的綜合服務三維可視化的統一對外發布。
3.1.2 技術架構
系統技術架構如圖5。
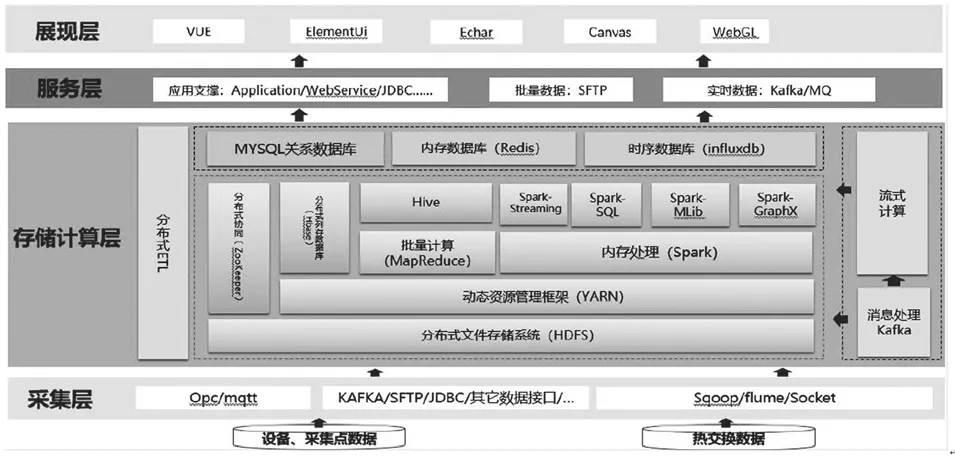
圖5 系統技術架構示意圖
在技術架構上,平臺需要具備采集設備、傳感器實時數據的能力,需要具備支撐非結構化數據以及海量結構化數據的存儲、計算和處理能力,滿足不同類型數據分析應用的并發訪問和響應時間的要求,滿足煤礦企業靜態基礎數據以及各類在線監測監控類數據進行煤礦大數據分析。
因此平臺具備以下能力:(1)數據采集:對于實時傳輸型的數據,基于OPC、SOCKET等技術開發前端數據接收模塊,將采集數據生成統一格式的中間結果文件后,通過MATT協議傳輸給平臺采集層;(2)數據存儲:結構化數據采用hive、spark、storm等方式存儲,非結構化數據采用hbase、文件服務器等方式進行存儲;(3)批量計算:大規模并行批處理作業的分布式計算,主要是1}iIR和Spark等計算框架;(4)實時/準實時計算:平臺具備針對海量數據毫秒級/秒級處理能力,主要采用funk和SparkStreaming等計算框架;(5)查詢技術:平臺可通過Kafka,SQL客戶端、文件等方式提供數據查詢能力;(6)擴展性設計:通過X86服務器構建規模化集群以實現架構的可擴展設計,以便今后面臨業務發展和應用拓展帶來的數據增長時,可以方便地進行硬件擴容,保障存儲和處理性能線性提升。
3.1.3 數據流向
系統數據流向如圖6。
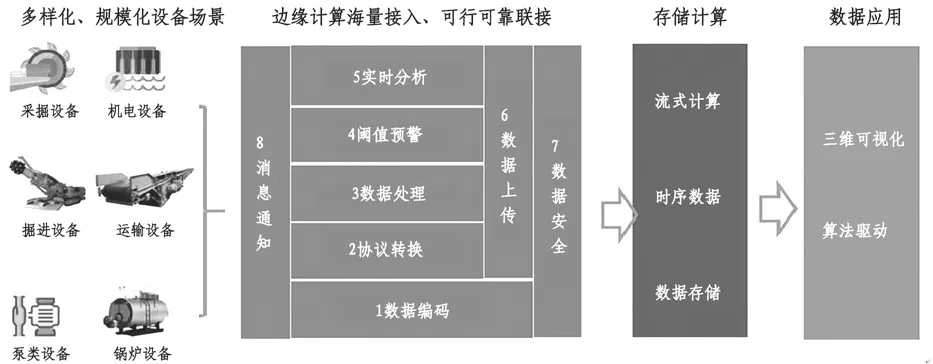
圖6 系統數據流向示意圖
系統首先從自動化集成監控平臺采集算法需要的自動化實時數據,統一進入邊緣計算數據采集端,數據采集端進行數據的統一標準化處理,然后將標準化的數據統一存儲計算,最后將實時數據或計算后結果提供各類應用。
3.1.4 前端開發
系統前端展示,結合扁平化和三維的理念,通過vue和canvas技術,實現系統的三維展示效果。系統前端采用Web SCADA圖形組態可視化編輯器平臺,實現Web化的2D和3D工業監控可視化維護系統平臺。用戶在云端直接進行矢量行業圖標編輯、三維模型擺放、場景構建及量測數據綁定配置,一鍵式無縫發布到桌面和移動終端,實現純HTMLS一體化的開發流程平臺,具有輕量、高效、易用和跨平臺等特性。
Canvas技術不約束用戶后臺框架,不限制通訊方式和傳輸格式,加上基于純HTMLS的跨平臺特性,能靈活適應各行業架構需求,作為輕巧的圖形組件可集成到任何行業應用系統。
系統前端提供了通用組件、圖表組件、拓撲組件到三維組件,組件間可無縫融合嵌套,所有組件內置都已支持、自動適配桌面和移動觸屏交互體驗。
系統前端所有組件采用局部刷新、批量聚合、圖像緩存、極少化DOM元素等,圖形優化(內存//CPU/GPU)等技術,使組件皆可承受上萬甚至幾十萬以上圖元量,上萬的表格數據、網絡拓撲圖元和儀表圖表承載力,更好地適應了物聯網大數據時代需求。
系統前端組件可與多種第三方GIS地理信息平臺無縫融合,實現宏觀場景和局部設備相配合的2D/3D可視化。
3.2 現場部署情況
系統現場部署情況:服務器地址128.127.30.73,系統各部分程度運行路徑見表1。
4 結論
設備協同管控及安全生產智能調度系統已在塔山礦建設完成,系統運行情況總體良好,功能技術指標達到設計要求。系統實施后,該煤礦可以對設備實現協同管控、在線診斷與智能調度服務,有效提高了設備運行系統的安全性和可靠性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
電子制作(2018年11期)2018-08-04 03:26:08
光學精密工程(2016年6期)2016-11-07 09:07:19
