改進U-Net的新冠肺炎圖像分割方法
2021-10-14 06:34:38宋瑤,劉俊
計算機工程與應用 2021年19期
宋 瑤,劉 俊
1.智能信息處理與實時工業系統湖北省重點實驗室(武漢科技大學),武漢 430065
2.武漢科技大學 計算機科學與技術學院,武漢 430065
2019年12月,新型冠狀病毒肺炎(簡稱“新冠肺炎”)疫情出現,隨后新冠肺炎在局部地區擴散并迅速蔓延至全世界,引起了全球的密切關注[1]。世衛組織將此新疾病命名為“2019年冠狀病毒病”,簡稱:COVID-19。被病毒感染的人數正在全球急劇增加,截至2020 年10 月11日,美國約翰·霍普金斯大學實時統計數據顯示,全球報告的新型冠狀病毒病例已超過3 800 萬例,死亡病例超過100萬例。世界衛生組織(World Health Organization,WHO)宣布疫情為國際關注的突發公共衛生事件,于2020年3月11日確認為大流行病,這在國際社會引起了極大的公共衛生關注[2]。因此,快速檢測和隔離感染者對于限制病毒的傳播至關重要。
逆轉錄聚合酶鏈反應(RT-PCR)被確立為COVID-19篩選的金標準[3]。RT-PCR能夠檢測通過鼻咽拭子、口咽拭子,支氣管肺泡灌洗液或氣管抽吸物獲得的標本中的病毒RNA。但是,最近的各種研究表明,RT-PCR 檢測的靈敏度較低,約為71%,因此需要重復檢測才能準確診斷。此外,由于缺少所需的材料,RT-PCR篩查非常耗時又增加了可用性限制[4]。
用于COVID-19篩查的RT-PCR的替代解決方案是醫學成像,例如X 射線或計算機斷層掃描(Computed Tomography,CT)。近年來,醫學成像技術取得了長足的進步,現已成為診斷和多種疾病定量評估的常用方法。特別是,胸部CT 篩查已成為肺炎的常規診斷工具。此外,CT成像在COVID-19定量評估以及疾病監測中也起著重要作用。在CT圖像上,感染初期COVID-19感染區域可通過肺部玻璃結節(Ground Glass Opacity,GGO)區分,感染后期可通過肺實變來區分[5]。與RT-PCR相比,多項研究表明,CT 對COVID-19 篩查更為敏感和有效,即使沒有臨床癥狀,胸部CT成像對COVID-19檢測也更加敏感。一般情況下,醫生通過觀看患者的CT影像圖,診斷患者肺部是否已感染新冠肺炎。
但感染初期的肺部玻璃結節在CT影像圖中特征不明顯,需要經驗豐富的醫生才能準確識別并標定出感染區域。如果醫生經驗不足或者診斷不夠認真仔細都可能導致對COVID-19的誤診。因此,自動分割技術可以輔助醫生診斷,降低醫生的勞動強度,提高COVID-19診斷準確率,為患者治療爭取寶貴時間。
1 相關工作
近年來,隨著人工智能技術的發展,圖像分割越來越多地采用深度學習技術,取得了優于傳統分割技術的分割效果。特別是卷積神經網絡(Convolutional Neural Network,CNN)[6]的出現,為圖像特征提取帶來全新的解決方法。2015年,Long等[7]在CNN的基礎上,創造性地提出了一種全卷積神經網絡(Fully Convolutional Network,FCN)。他們將傳統CNN 中的全連接層轉化成一個個的卷積層,對圖像進行像素級的分類,從而解決了語義級別的圖像分割問題。Ronneberger 等[8]提出的U-Net網絡模型采用編碼器-解碼器結構,編碼器部分通過卷積和逐級下采樣提取圖像層級的特征對輸入圖像進行編碼;解碼器通過卷積和逐級上采樣將編碼信號映射成相應的二值分割掩模,得到較好的分割結果。與FCN相比,U-Net能夠在較少樣本量的情況下完成模型訓練并實現圖像分割。受U-Net模型啟發,許多研究者對U-Net 網絡進行了改進。文獻[9]中提出了U-Net++模型,通過增加編碼器和解碼器之間的細粒度信息來重新設計跳躍連接;文獻[10]中提出的3D-UNet 把U-Net中所有的2D卷積替換成3D卷積塊,還用了Batch Normalization 防止梯度爆炸;文獻[11]中以U-net 為基礎提出Attention-Unet,在解碼器部分使用了注意力機制,可以將注意力集中在感興趣區域;文獻[12]中提出R2U-Net,將循環卷積神經網絡和循環殘差卷積神經網絡結合,使網絡提取到更好的特征;文獻[13]中將DAC模塊和RMP模塊與編碼器-解碼器結構相結合以捕獲更高級的抽象特征和保留更多的空間信息。這些基于U-Net 模型的改進,都在一定程度上提升了對特定圖像的分割性能。
最近有一些針對肺部的CT 圖像分割的方法。文獻[14]中提出Inf-Net 從肺部CT 圖片中自動分割感染區域。利用并行部分解碼器(Parallel Partial Decoder,PPD)用于聚合高級特征(結合上下文信息)并生成全局圖。然后,利用隱式逆向注意力(Reverse Attention,RA)和顯示邊緣注意力對邊界進行建模和增強表征。此外,為了緩解標記數據不足的問題,提出了一種基于隨機選擇傳播策略的半監督分割框架。在文獻[15]中,準備了包含20 個案例的3D CT 數據的新數據集,其中包含1 800+個帶注釋的切片,并提供了一些預先訓練的base模型,可以作為現成的3D分割方法。文獻[16]中提出了一種編/解碼模式的肺分割算法,向網絡模型中輸入多尺度圖像,使用殘差網絡結構作為編碼模塊,在編碼和解碼之間利用空洞空間金字塔池化(ASPP)充分提取上文多尺度信息;最后利用級聯操作,將捕捉到的信息與編碼層信息級聯,結合注意力機制從而提高分割精度。文獻[17]中提出了一種基于改進的U-Net網絡的肺結節分割方法。該方法通過引入密集連接,加強網絡對特征的傳遞與利用,同時采用改進的混合損失函數以緩解類不平衡問題。
盡管已經有一些深度學習方法為診斷肺炎和肺部分割提供幫助,但是在新冠肺炎CT 切片中與感染分割相關的工作仍然很少。因為存在以下幾個問題:新冠肺炎CT 切片中感染病灶的大小和位置時刻變化,目標病灶區域小,邊界模糊,磨玻璃區域邊界通常對比度低且外觀模糊,難以識別。而且由于在短時間內很難獲取CT切片中肺部感染的高質量像素級分割注釋,所以很難收集足夠的數據集來訓練深度模型。大部分COVID-19 公開數據集中在診斷上,只有極少數據集提供了分割標簽[14]。
僅僅使用原始U-Net 對其訓練,存在梯度消失、特征利用率低等問題,最終導致模型的分割準確率難以提高。為了解決上述問題,本文提出了一種改進的U-Net網絡的新冠肺炎病灶區域分割算法。
本文根據基本的編碼器-解碼器結構并結合EfficientNet[18]模型設計了一種改進的深度卷積神經網絡模型模型,其網絡結構如圖1 所示,由編碼器、解碼器和跳躍連接(Skip Connection)組成。編碼器部分使用了EfficientNet-B0 作為特征提取器,EfficientNet 網絡通過優化網絡寬度、網絡深度和增大分辨率來達到提升指標的優點,大幅度地減少模型參數量和計算量,提高了模型的泛化能力。使用DUsampling結構代替解碼層路徑中的傳統上采樣方法,利用了分割標簽空間中的冗余優勢恢復編碼路徑中丟失的細粒度信息,加快網絡收斂速度,增大特征圖的分辨率。傳統的分割網絡僅僅在最后的Softmax層計算預測結果GroundTruth之間的損失,再通過反向傳播更新優化網絡。但DUpsampling 結構在上采樣部分就提前計算特征圖與GroundTruth之間的損失,再通過反向傳播使解碼層中的低分辨率特征圖融入高層次語義特征,通過跳躍鏈接融合更好的中級和高級語義特征,更好地恢復細節。
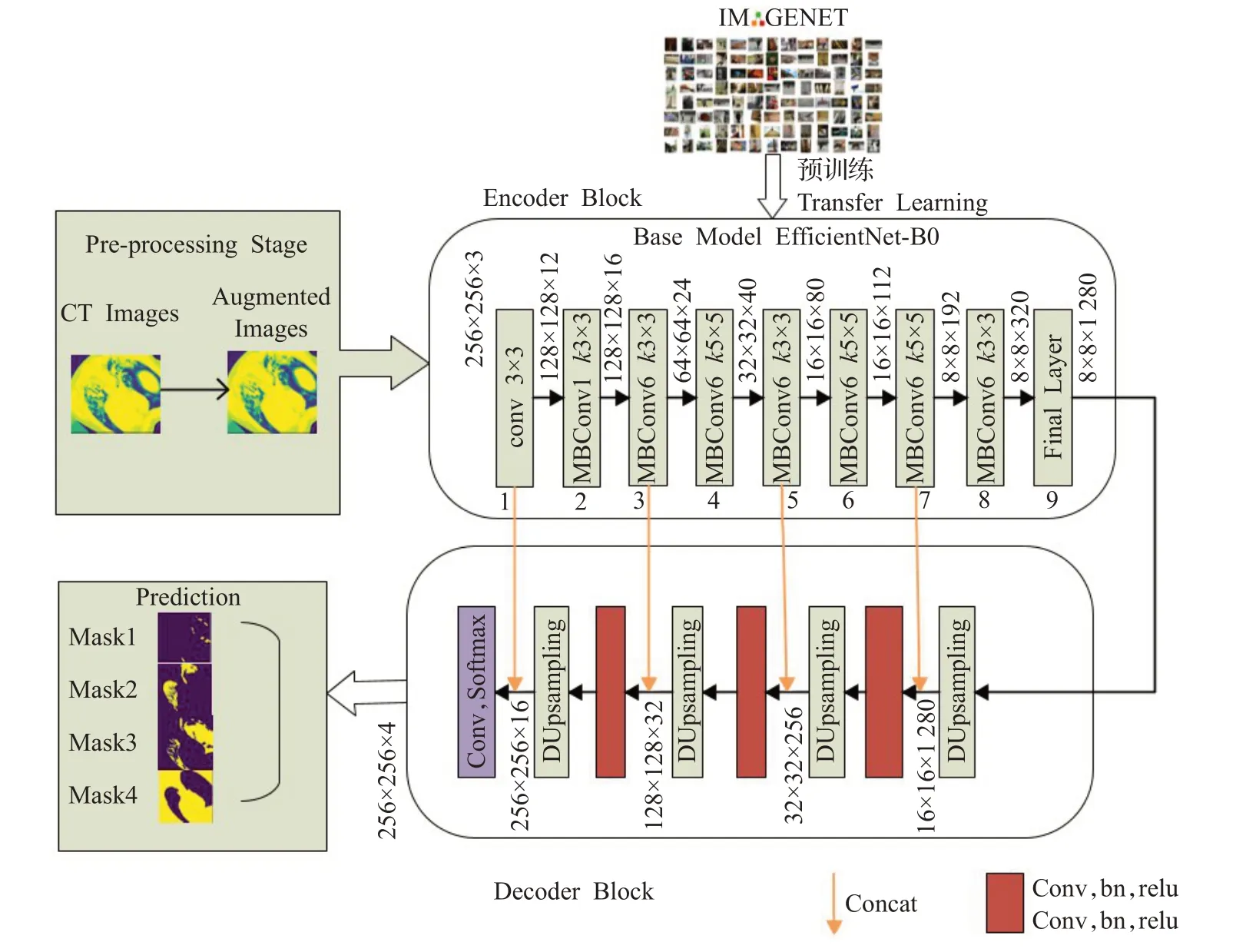
圖1 Efficient-Unet網絡結構Fig.1 Efficient-Unet network structure
該算法加強了網絡對特征的傳遞與利用,能夠有效緩解新冠肺炎病灶中感染區域小,磨玻璃邊界模糊,難以識別和漏檢等問題。本文利用COVID-19 公開數據集對改進網絡的有效性進行驗證,結果表明該網絡能夠顯著提高CT圖像下新冠肺炎肺部病灶分割的準確率。
2 本文方法
2.1 編碼器-解碼器結構
編碼-解碼器結構是語義分割領域最流行的框架之一,其能夠端到端地分割整幅圖片。編碼器-解碼器體系結構將主干CNN 視為編碼器,負責將原始輸入圖像編碼為較低分辨率的特征圖,之后,使用解碼器從較低分辨率的特征圖中恢復逐像素預測。
2.1.1 編碼模塊
EfficientNets是一系列模型(即EfficientNet-B0到B7),它們是通過按比例放大的基礎網絡(通常稱為EfficientNet-B0)得到的,即在網絡的所有維度,即寬度(Width)、深度(Depth)和分辨率(Resolution)中采用復合縮放方法。EfficientNets由于其在性能上的優勢而備受關注。該系列模型在效率和準確性上超越了之前所有的卷積神經網絡模型。寬度是指任何一層中的通道數,深度是指CNN 中的層數,而分辨率與圖像的大小相關。使用復合縮放的直覺是縮放網絡的任何尺寸(例如寬度、深度或圖像分辨率)都可以提高精度,但是對于較大的模型,精度增益將降低。為了系統地擴展網絡的規模,復合縮放使用復合系數,該系數控制有多少資源可用于模型縮放,并且通過復合系數按以下方式縮放維度:

其中φ是復合系數,而α、β和γ是可以通過網格搜索固定的每個維度的縮放系數。確定縮放系數后,將這些系數應用于基準網絡(EfficientNet-B0),以進行縮放以獲得所需的目標模型大小。例如,在EfficientNet-B0 的情況下,設置φ=1 時,在α·β2·γ2的約束下,用網格搜索得出最優值,即α=1.2,β=1.1和γ=1.15。通過更改公式(1)中的φ值,可以放大EfficientNet-B0以獲得EfficientNet-B1 至B7。EfficientNet-B0 基線體系結構的特征提取由幾個移動翻轉瓶頸卷積(MBConv)塊,內置的壓縮和激發(SE),批處理歸一化和Swish激活組成,表1為EfficientNet-B0模型中各層的參數設置。
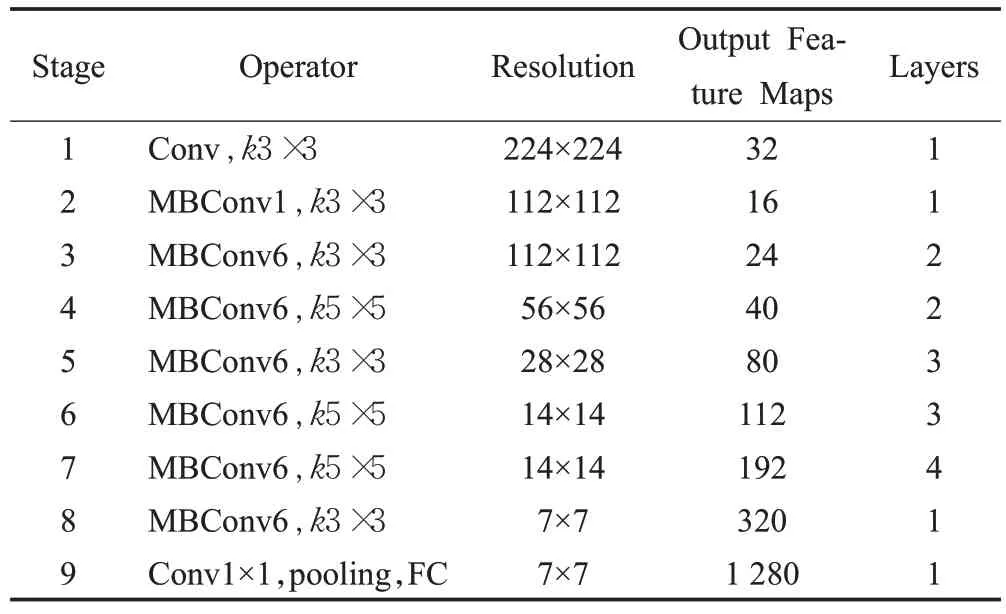
表1 EfficientNet-B0網絡層Table 1 EfficientNet-B0 network layers
MBConv是通過神經網絡架構搜索得到的,如圖2所示,該模塊結構與深度分離卷積(Depth Wise Separable Convolution)[19]相似,由深度可分離卷積和SENet構成。
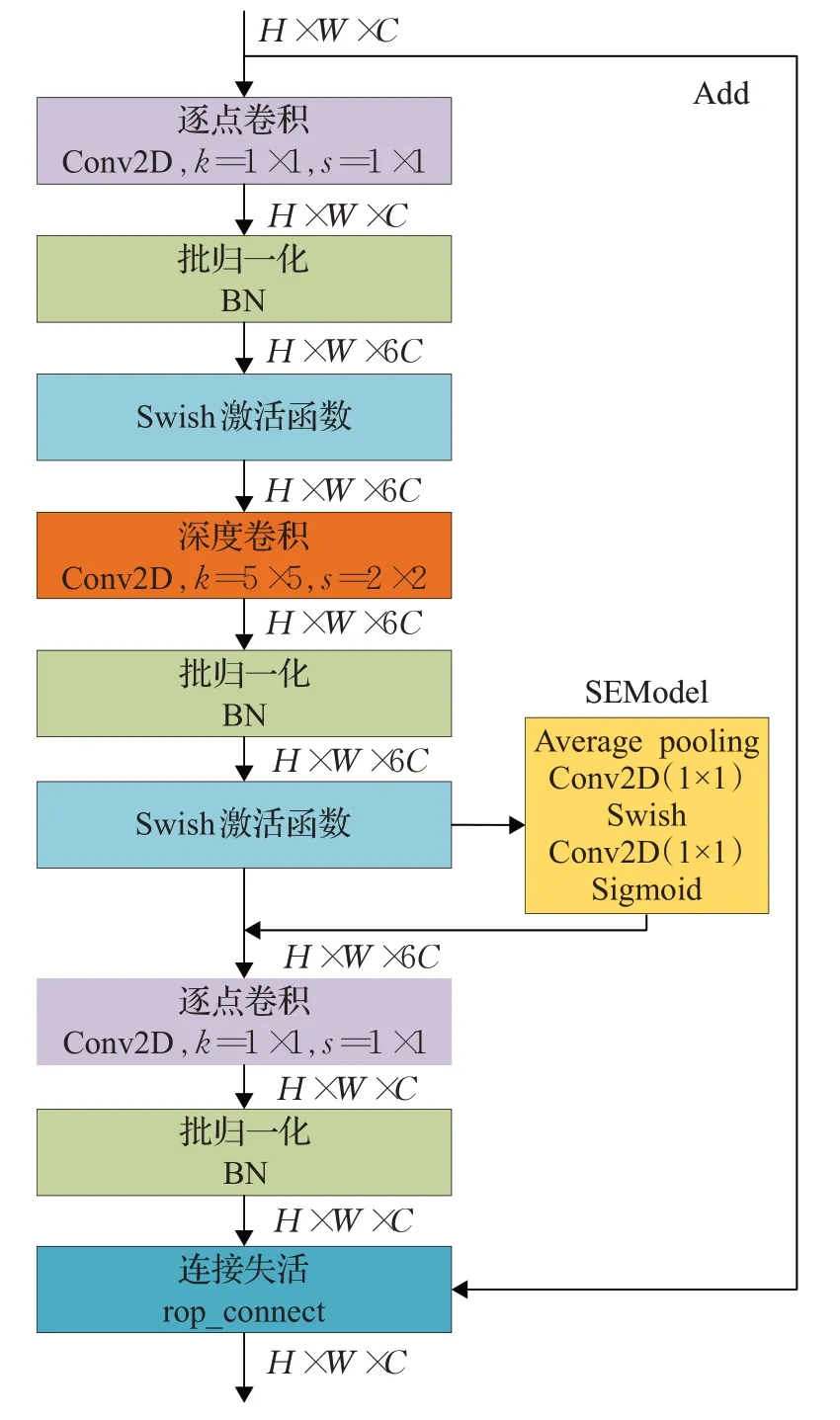
圖2 MBConv結構Fig.2 MBConv structure
MBConv 中的壓縮和激勵操作(稱為SE 模塊[20])是基于注意力的特征圖操作。如圖3所示,SE模塊首先對特征圖執行壓縮操作,然后在通道維度方向上執行全局平均池化操作(Global Average Pooling),獲取特征圖通道維度方向的全局特征。然后對全局特征執行激發操作,使用激活比率(R)乘以全局特征維度(C)個1×1的卷積使其卷積,學習各個通道間的關系,然后通過Sigmoid激活函數獲得不同通道的權重,最后將其乘以原始特征圖得到最終特征。本質上,SE 模塊是在通道維度上做注意力操作或者門操作,這種注意力機制使得模型可以更多的關注更多信息的信息通道特征,同時抑制那些不重要的通道特征。
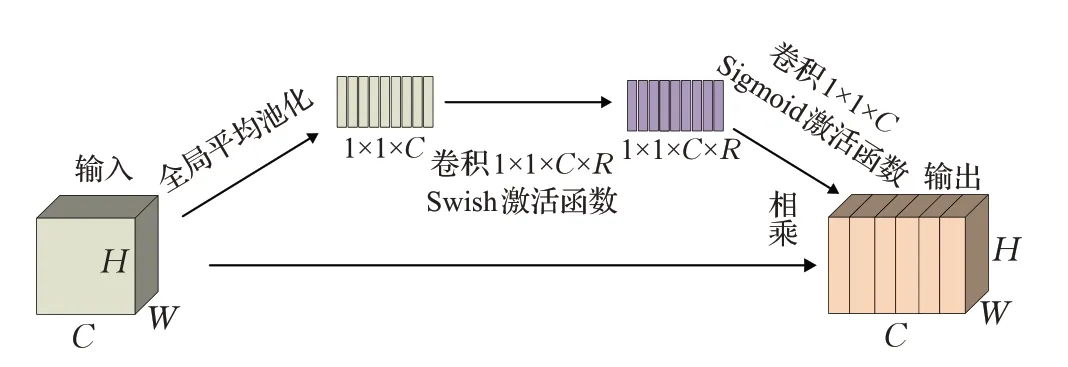
圖3 SE結構Fig.3 SE sturcture
對肺炎圖像進行預處理后,利用卷積神經網絡對預處理圖像進行訓練。增大網絡深度是訓練許多神經網絡經常使用的方法,這樣能捕捉更豐富、更復雜的特征并且適應新任務來進行學習。然而,增加網絡的深度會帶來梯度消失的問題。增加網絡寬度,即特征圖通道數增多,更多的卷積核可以得到更多豐富的特征,增強了網絡的表征能力,更寬的網絡往往能夠學習到更加豐富的特征,并且很容易訓練。但是對于網絡結構過寬且深度較淺的網絡,在特征提取過程中很難學習到更高層次的特征。卷積神經網絡對于具有高分辨率的輸入圖像也可以捕捉細粒度特征,這樣能豐富網絡的感受野來提升網絡。上述網絡的寬度、深度及圖像的分辨率3個指標都可以提高精度,但對于較大的模型,精確度會降低,所以需要協調和平衡不同維度之間的關系,而不是常規的單維度縮放。EfficientNet成功地將網絡寬度、深度及提高圖像的分辨率通過縮放系數對分類模型進行3 個維度的縮放,自適應地優化網絡結構。EfficientNet模型包含從B0 到B7 的8 個模型,每個后續模型編號均指代具有更多參數和更高準確性的變量。EfficientNet 體系結構使用遷移學習來節省時間和計算能力,因此,它提供了比已知模型更高的精度值。這是由于在深度、寬度和分辨率上使用了巧妙的縮放比例。本文使用了B0模型,因為它包含5.3 m參數,使用B1之后的模型,模型的參數會增加,但已經飽和,效率不高。
本文并未網絡權重上進行隨機初始化,而是在EfficientNet 模型中實例化了ImageNet[21]的預訓練權重,從而加快了訓練過程。ImageNet 的預訓練權重在圖像分析領域表現出了非凡的成就,因為它包含超過1 400 萬幅涵蓋折衷類的圖像。優化過程將在新的訓練階段微調初始訓練前權重,以便可以將訓練前的模型擬合到特定的感興趣區域。
2.1.2 解碼模塊
在解碼器還原圖像尺寸的過程中,將傳統的上采樣操作換成DUpsampling 結構[22],一種基于數據依賴的新型上采樣結構。如圖4所示,上采樣結構通常存在于分割網絡的解碼層中,其功能是將特征圖恢復至原始圖像的尺寸。盡管雙線性插值和最近鄰插值的上采樣操作可以在一定程度上捕獲和恢復卷積層提取的特征,缺點是其在準確恢復逐像素預測中的能力有限。雙線性上采樣不考慮每個像素的預測之間的相關性,因為它與數據無關,這種弱數據的卷積解碼器無法生成相對高質量的特征圖。DUpsampling 利用了分割標簽空間中的冗余優勢,能夠從相對粗糙的CNN 輸出中準確地恢復逐像素預測,從而減輕了卷積解碼器對精確響應的需求。更重要的是,它使融合特征的分辨率與最終預測的分辨率解耦。這種解耦使解碼器可以利用任意特征聚合,因此可以利用更好的特征聚合,從而盡可能提高分割性能。
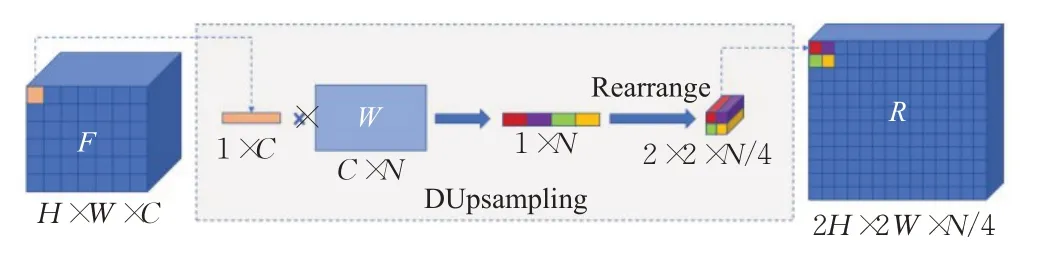
圖4 DUpsampling結構Fig.4 DUpsampling structure
這種新穎上采樣方法可以生成逐像素預測,消除了來自底層CNN 的計算效率低下的高分辨率特征圖,這使得編碼模塊無需減少其步長從而使得計算時間和內存占用大幅度改善。同時由于DUpsampling的高效,使得解碼器能夠將融合的特征下采樣至較小的分辨率,這不但減小了解碼器的內存占用而且將待融合的特征與最終預測解耦,這種解耦使得解碼器能夠利用任意的特征聚合從而獲得最優結果。
3 實驗與分析
本文的模型在TensorFlow 和Keras 框架下實現,硬件環境:CPU 為I7 8700K 處理器,GPU 為NVIDIAGet-Force 1080Ti。首先通過對比實驗選擇最適合的損失函數、訓練模型,利用快照集成得到不同的模型,將模型集成。最后,將本文的網絡和其他網絡結構進行性能對比測試。
3.1 數據集介紹
上采樣的具體操作如下:將H×W×C的圖像上采成2H×2W×N/4 的圖像,圖2 中,RH×W×C表示CT 圖像經過編碼輸出的特征圖,H、W、C分別表示特征圖的高度、寬度、以及通道數。1×C代表針對特征圖F中的每個像素維度,將其乘上一個待訓練矩陣W,其維度為C×N,最終會得到一個1×N的特征表示,再將向量Rearrange為2×2×N/4 的表示,也就完成了上采樣的過程,R表示經DUpsampling結構2倍上采樣后得到的特征圖,經過重排后就相當于對原始的每個像素進行2倍的上采樣。上面的W是根據已知的訓練標簽得到的。在訓練集中真正的分割表示是已知,對每個分割圖進行一個矩陣轉換,將其轉化稱為與Encoder 模塊得到的特征圖相同的維度上。其過程表達式如下:
本文采用COVID-19CT分割數據集[23],其中包含兩個版本。此數據集的第一個版本包含40 例COVID-19患者的100幅軸向CT圖像,所有圖像均標記為COVID-19 類。該數據集具有四種類型的真實分割蒙版,稱為“磨玻璃結節”(掩膜值=1),“肺實變”(掩膜值=2),“胸膜積液”(掩膜值=3)和“背景”(掩膜值=4)。原始的CT圖像和所有地面真相蒙版的尺寸為512×512。數據集的第二個版本已擴展到829 張圖像(來自9 位患者),其中373 張被標記為COVID-19,其余圖像被標記為正常。此數據集的第二個版本中圖像和掩膜的尺寸大小為630×630。將這兩個版本合并在一起,總共包含49 個人,一共929張樣本。
如圖5 中顯示了來自此數據集的兩個樣本圖像。第一列的圖像表示原始圖像,后四列分別代表及對應的4種類型的COVID-19蒙版。圖(a)和圖(b)的圖像表示一個COVID-19 患者樣本圖像和一個正常人的樣本圖像。真實分割掩膜中的磨玻璃混濁和肺實變為黃色,而黑色像素表示健康區域(請注意,如果磨玻璃混濁和肺實變掩膜是完全黑色的,則表示給定的CT 圖像屬于健

圖5 數據集樣本Fig.5 Dataset sample

矩陣P是矩陣W的反變換,其中v表示的是真正的分割結果中的區域表示,是重新構建的v,神經網絡以標準隨機梯度下降(SGD)迭代地優化其目標,矩陣P和W可以通過最小化v和之間的誤差得到,形式化定義如公式(3):康人)。繪制紅色和黑色邊界輪廓是為了更好地顯示包含COVID-19中的磨玻璃混濁和肺實變的部分,而不是原始圖像的一部分。
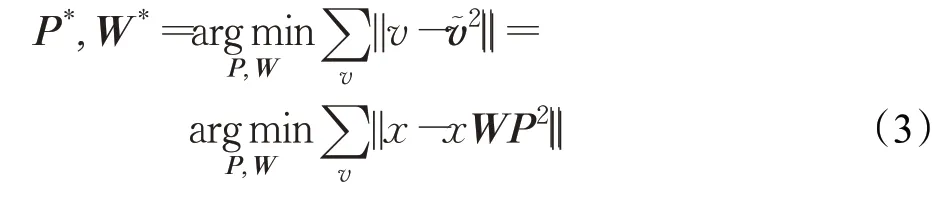
在對上述幾種類型的掩膜進行了仔細檢查和分析之后,本文決定只專注于真實磨玻璃掩膜,因為:一方面,后面兩種掩膜對疾病的診斷和病灶分割來說并沒有太大作用,肺實變掩膜有大量缺失;另一方面,僅僅通過磨玻璃區域也是可以作為輔助診斷COVID-19。
3.1.1 預處理
預處理包括:調窗處理和灰度值標準化。調窗處理是針對不同的器官選擇合適的CT 窗口,本文中將所有大于窗口CT 值修改為窗口最大值,所有小于窗口最小值的CT值修改為窗口最小值。本文針對肺炎病灶分割選擇CT 值范圍為[-1 500,500]。灰度值標準化是將灰度值減去灰度值的均值,再除以標準差,這樣可以方便處理數據和加快模型收斂。灰度值和標準差均通過統計訓練數據計算得到。如圖6 中顯示了預處理前后數據集一(藍色)和數據集二(黃色)的CT值分布直方圖。
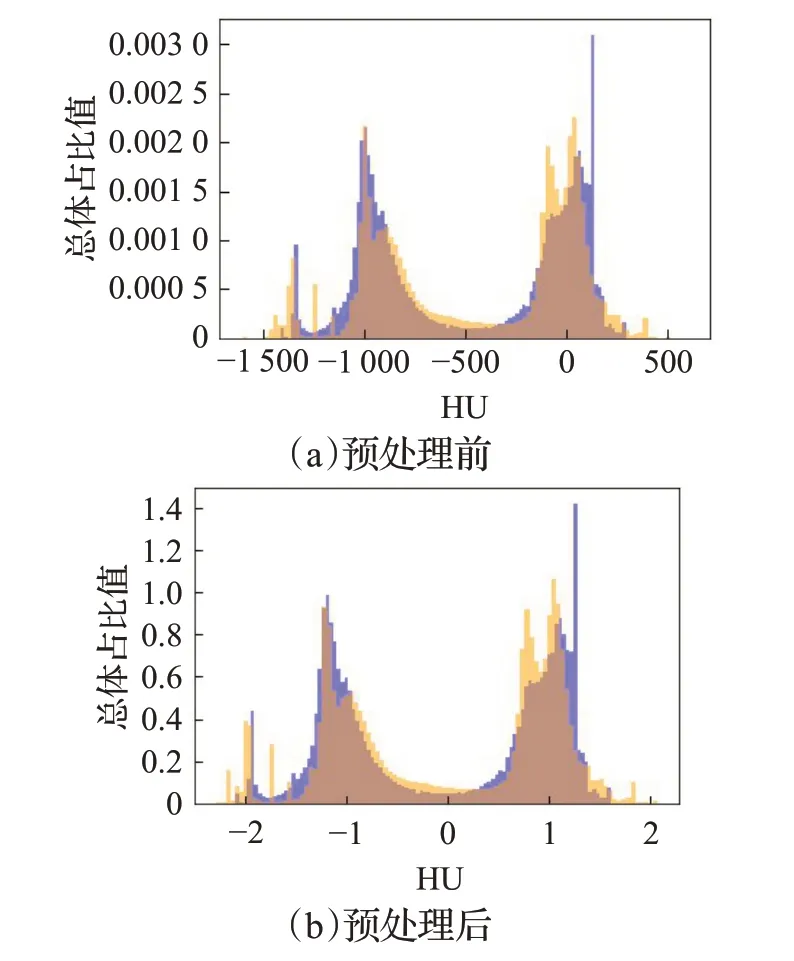
圖6 預處理前后對比Fig.6 Comparison of before and after pretreatment
3.1.2 數據增強
當只有少量訓練樣本可用時,數據增強對于訓練網絡所需的不變性和魯棒性至關重要。本文應用隨機旋轉、隨機剪裁、隨機水平翻移動等圖像增強方法來處理訓練集中的圖像和掩膜。訓練集包含1 810張圖和分割掩膜;驗證集包含150 張圖像和分割掩膜,測試集包含10 張圖像,所有訓練集和測試圖像大小統一為256×256,并進行歸一化處理。
3.2 評價指標
為了多角度充分說明本文算法的性能,本文采用了3種用于評估醫療影像分割效果的評估指標來衡量細分模型的性能,包括準確率、召回率、Dice 系數,這些度量標準也廣泛用于醫學領域。定義如下:

其中,TP(True Positives)表示被正確檢測為正樣本的像素數量;FP(False Positives)表示被錯誤檢測為正樣本的像素數量;FN(False Negatives)表示被錯誤檢測為負樣本的像素數量;TN(True Negatives)表示被正確檢測為為負樣本的像素數量。A是分割結果像素構成的集合,B是實際數據集標簽像素構成的集合。將Dice 系數(DSC)作為主要評價指,Dice系數的取值范圍是[0,1],Dice其值越大,兩幅圖像越相似,分割效果越準確。
3.3 參數設置及訓練
采用Adam優化器進行優化,除學習速率外其余參數采用默認配置。其中,batch-size設置為12;初始學習率設置為0.001;動量參數設置為0.9。如圖7 展示了在訓練過程中本文算法在訓練集和驗證集上的損失值與訓練迭代次數的關系。從圖中可以看出,網絡的損失值隨著訓練迭代次數的增加而降低,當訓練迭代次數超過30時,驗證集的損失值趨于穩定。因此,本文實驗中的訓練迭代次數設置為30。
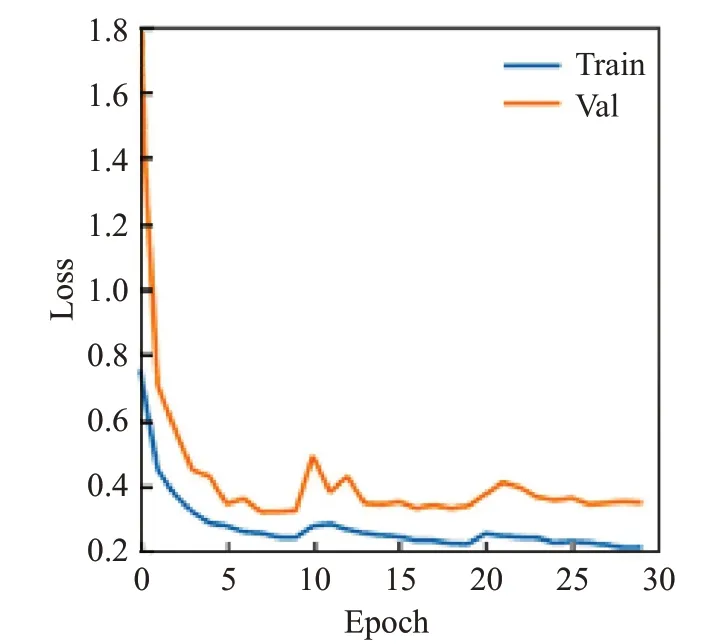
圖7 損失值與迭代次數變化Fig.7 Change in loss value and number of iterations
3.3.1 不同損失函數的對比分析
實驗發現本文模型的分割性能和損失函數的選擇有關,因此為了獲得最合適的損失函數,得到最好的分割性能,本文針對二值交叉熵損失函數、Dice 相似系數損失函數和組合損失函數進行了對比實驗。表2 列出了在3 種不同損失函數下的分割效果,實驗發現,當采用組合損失函數均可以達到最優的分割結果,其原因在于肺部磨玻璃區域在圖像上的占比面積較小,使用單一的損失函數進行優化時,磨玻璃區域所對應的梯度變化容易受到其他背景區域梯度的影響,導致網絡訓練困難,而組合損失函數綜合了兩種損失函數的特點,在網絡反向傳播過程中能夠對難以學習的樣本進行穩定且有針對的優化,從而能夠緩解類別不平衡的問題,提升模型的分割性能。
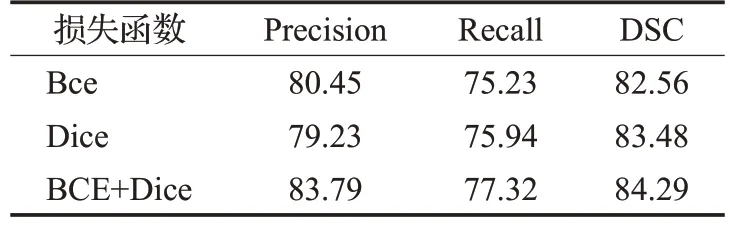
表2 損失函數對比Table 2 Loss function comparison %
3.3.2 模型快照集成
眾所周知,神經網絡的集成比單個網絡更健壯和準確。但是,訓練多個深度網絡進行模型平均在計算上很費時費力。快照集成(Snapshot Ensembling)[24]這是一種無需任何額外培訓成本即可獲得神經網絡集成的簡單方法。它的主要概念是訓練一個模型,不斷降低學習率,利用SGD收斂到局部最小值,并保存當前模型權重的快照。然后,迅速提高學習率,逃離當前的最優點。此過程重復進行直到完成循環。余弦退火學習率是一種在訓練過程中,如圖8所示,調整學習率的方法,隨著epoch 的增加,learning rate 先急速下降,再陡然提升。為CNN創建模型快照的主要方法之一是在單次循環余弦退火訓練中收集多個模型。每個時期的循環余弦退火的學習率定義為:
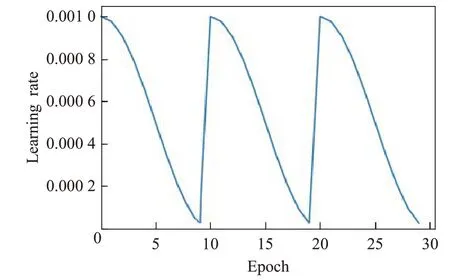
圖8 學習率變化Fig.8 Learning rate change
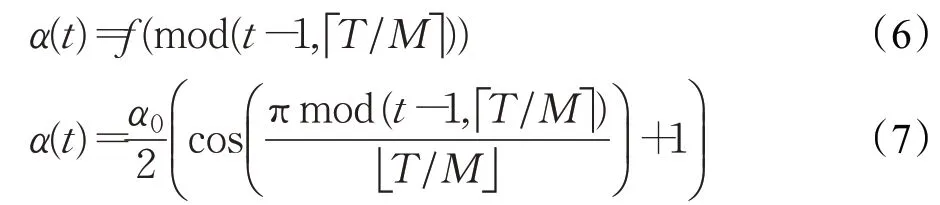
其中α(t)是在時期t的學習率,t是迭代次數,α0 是初始學習率,T是訓練迭代的總數,M是循環周期。訓練M個訓練周期后,我們得到M個模型快照f1,f1,…,fM,每個快照都將用于集合預測中。
3.4 實驗結果及分析
3.4.1 快照集成的對比分析
由于模型的分割性能和學習率的選擇有關,而隨著學習率的循環變化,模型的效果也是循環變化。每個集成包括一次訓練中生成的總共M個模型快照,因此為了尋找最合適的模型集成循環周期M,得到最好的分割性能,本文對比實驗了3種模型組成。
由表3 可見,M=3 的情況下比其他基本模型產生了更好的結果。可以看出單獨模型的準確率是83.79%,召回率是77.32%,Dice值是84.29%;M=3 時準確率是84.38%,召回率是78.64%,Dice 值是85.87%;M=4 時準確率是84.24%,召回率是80.43%,Dice 值是85.12%。每個集成都包含來自以后周期的快照,因為這些快照受到了最多的訓練,因此可能會收斂到更好的最小值。但是并不是集合更多的模型都可以提供更好的性能,當第4個模型添加到集合中時,觀察到各指標均有下降。因此,本文實驗中的M選擇為3。
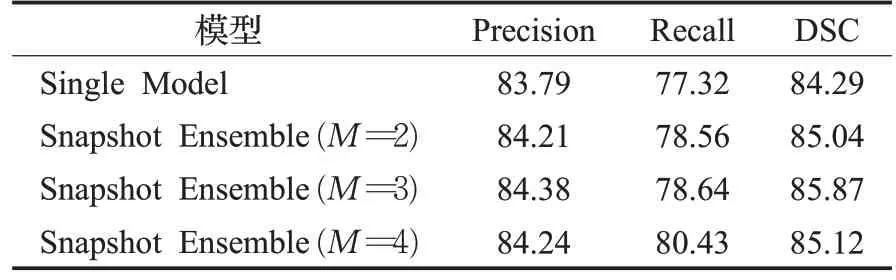
表3 模型集成周期對比Table 3 Model ensembles cycle comparison %
3.4.2 改進上采樣前后對比分析
如表4 所示,用DUpsampling 替換傳統上采樣方法前后相比,在衡量模型分割能力的指標準確率上,DUpsampling比傳統方法提高了1.04 個百分點,在召回率這一指標上,DUpsampling比傳統方法提高了2.09 個百分點,在DSC 這一指標上,DUpsampling 比傳統方法提高了2.39 個百分點,解碼器計算量也減少了50%左右,說明了DUsampling在恢復特征圖尺寸的同時,提升了分割精度,降低了計算復雜度和計算量。

表4 傳統上采樣方法改進前后對比Table 4 Comparison of traditional sampling method before and after improvements
3.4.3 不同分割方法的分析
為了驗證改進的Efficient-UNet 模型的分割性能,將本文與FCN、U-Net、SegNet[25]和CE-Net[26]4 種分割網絡進行對比。根據相同的網絡參數設置,分別對以上5種網絡進行訓練,并利用測試集對訓練好的模型性能進行測試。實驗結果如表5所示。
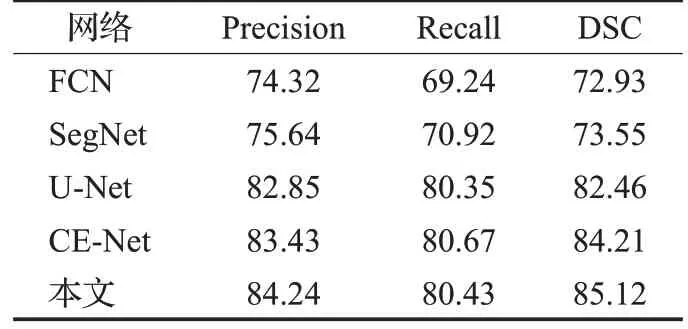
表5 Efficient-UNet與其他網絡對比Table 5 Efficient-UNet compared with other networks %
本文所提方法在Precision、Recall 和DSC 上均有提升。相比于基礎網絡FCN,所提方法在Precision、Recall和DSC 上分別提升了9.92 個百分點、11.19 個百分點和12.19 個百分點。與網絡SegNet 相比,在Precision、Recall和DSC上也分別提升了8.6個百分點、9.51個百分點和12.19 個百分點。這是由于FCN 和SegNet 沒有考慮全局的上下文信息和像素與像素之間的關系,沒有充分利用各層網絡所提取的圖像特征,網絡對于編碼器部分所提取到的特征,只是單純地進行了上采樣操作將其恢復到輸入圖像大小,忽略了空間一致性,會導致邊緣模糊以及空間丟失,因此模型的分割結果比較粗糙。與網絡U-Net相比,Precision提升了1.39個百分點,Recall提升了0.08個百分點,DSC提升了2.66個百分點。與FCN和SegNet 相比,U-Net 中引入了跳躍連接,網絡得以將淺層的簡單特征和高層的抽象特征結合起來,這有助于補充空間的細節。但是由于肺炎圖像數量少,且磨玻璃區域具有邊緣模糊,目標小等特點,對其提取特征較為困難,僅使用原始U-Net訓練,存在梯度消失,特征利用率低等問題。CE-Net可以看出經過算法改進很大程度上改善了以上缺點,使分割精細程度大大提升。
由于本文算法在U-Net 上進行改進,故本文選取U-Net模型作為對比,在訓練過程中,比較兩者對于系統資源的占用情況,如表6 所示。可以看出,與U-Net 相比,改進后的模型無論在顯存占用、GPU使用率還是訓練時間上都更加具有優勢。

表6 Efficient-UNet與U-Net系統資源占用情況對比Table 6 Occupation of system resources of U-Net and Efficient-UNet
如圖9 選擇6 個不同的CT 圖像分割結果的可視化。可以看出,幾種方法對于磨玻璃的細節均有漏分和過多分割的現象,圖(a)是輸入模型的肺部圖像,圖(b)是醫生標注的肺部磨玻璃輪廓金標準,圖(c)是使用本文算法對肺部磨玻璃分割的結果。與網絡CENet相比,所提方法在Precision提升0.81個百分點,DSC提升了0.91 個百分點。說明本文所提方法在新冠肺炎病灶分割上確實更精確。對比觀察圖中,磨玻璃在圖像中所占比例較小,且其像素值與背景區域中的肺部積液和血管等組織相近,未改進的網絡容易受到與病灶相似的干擾區域的影響,錯誤地將背景區域預測為病灶區域。相比之下,本文提出的改進后的網絡能夠有效地區分磨玻璃區域與其他肺部組織,對磨玻璃輪廓的分割更為精確。

圖9 不同模型的磨玻璃分割結果Fig.9 Segmentation results of ground-glass in different models
4 結束語
磨玻璃是新冠肺炎早期階段的特征,從CT 圖像中準確地檢測磨玻璃對新冠肺炎預防和治療具有重要的作用。為了有效檢測CT 圖像中的病灶信息,本文以EfficientNet-B0 為backbone,結合編碼器-解碼器結構,提出了一種改進的深度卷積神經網絡模型。該模型通過使用深度可分離卷積、壓縮和激勵操作操作和DUpsampling上采樣操作改進傳統編碼-解碼模型,對各種復雜細小的肺炎磨玻璃圖像具有更強的特征提取能力,同時降低了模型的計算量。在對比實驗中,本文模型在訓練集和測試集上均表現出比其他已有模型更好的分割效果和泛化能力,能夠有效提取CT 圖像中的新冠肺炎病灶區域。下一步,將考慮到醫療圖像的特殊性,在數據規模擴充、總體網絡結構以及參數的優化等多個方面對模型進一步優化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
