基于單哈希多維布隆過濾器的DDS自動發(fā)現(xiàn)算法
2021-10-15 12:49:08樊智勇劉哲旭
計算機應(yīng)用與軟件 2021年10期
樊智勇 騰 達 劉哲旭
1(中國民航大學(xué)工程技術(shù)訓(xùn)練中心 天津 300300) 2(中國民航大學(xué)電子信息與自動化學(xué)院 天津 300300)
0 引 言
數(shù)據(jù)分發(fā)服務(wù)DDS是一種高性能的中間件,能夠以較小的開銷實現(xiàn)可預(yù)測的數(shù)據(jù)分發(fā)。對象管理組織(Object Management Group, OMG)先后頒布了Version1.0、Version1.1和Version1.2規(guī)范[1-3]。該規(guī)范定義了一個與用戶具體使用的平臺、語言、所處位置都不相關(guān)且可擴展的基礎(chǔ)服務(wù)模型[4]。DDS采用以數(shù)據(jù)為中心的發(fā)布/訂閱通信模式,使分布式系統(tǒng)能夠?qū)崿F(xiàn)數(shù)據(jù)高效、可靠的發(fā)布與訂閱[5]。目前,DDS已經(jīng)被成功應(yīng)用于海軍作戰(zhàn)管理、空中交通管制和船舶等系統(tǒng)[6]。
針對DDS自動發(fā)現(xiàn)過程,RTI(Real-time Innovations)提出了基于簡單發(fā)現(xiàn)協(xié)議的自動發(fā)現(xiàn)算法SDP_ADA(Simple discovery protocol automatic discovery algorithm)[7]。該算法在中小型實時系統(tǒng)中取得了良好的效果,但當(dāng)系統(tǒng)的規(guī)模增大時,大量的數(shù)據(jù)需要頻繁地交換,會產(chǎn)生網(wǎng)絡(luò)數(shù)據(jù)傳輸量和內(nèi)存消耗較高的問題。文獻[8]將DDS簡單發(fā)現(xiàn)協(xié)議和標準布隆過濾器Bloom結(jié)合,提出了一種自動發(fā)現(xiàn)算法SDPBloom。在自動發(fā)現(xiàn)過程中,SDPBloom通過Bloom存儲端點描述信息,有效地解決了 SDP_ADA中存在的高內(nèi)存消耗和高網(wǎng)絡(luò)數(shù)據(jù)傳輸量等問題,增強了DDS的可拓展性。但是SDPBloom的實現(xiàn)需要大量的哈希函數(shù)運算,導(dǎo)致CPU資源消耗過多,并在分布式系統(tǒng)中產(chǎn)生了一定的延遲。為解決這一問題,本文提出了一種基于單哈希多維布隆過濾器的自動發(fā)現(xiàn)算法。該算法中的OMBF通過一個哈希函數(shù)和取模運算代替SDPBloom中多個哈希函數(shù),降低了參與者端點匹配過程的計算量。
1 DDS簡單發(fā)現(xiàn)協(xié)議
域是一個虛擬網(wǎng)絡(luò)概念,它有助于隔離和優(yōu)化分布式應(yīng)用程序之間的通信。只有同一個域中的域參與者才能相互通信[10]。域參與者由發(fā)布者和訂閱者組成,每個發(fā)布者和訂閱者分別管理一個或多個數(shù)據(jù)寫入者和數(shù)據(jù)讀取者。本文將數(shù)據(jù)寫入者和數(shù)據(jù)讀取者統(tǒng)稱為端點。只有數(shù)據(jù)寫入者和數(shù)據(jù)讀取者具有相同的主題時,域參與者才能建立通信。域參與者之間的數(shù)據(jù)傳輸通過自動發(fā)現(xiàn)協(xié)議完成。
DDS簡單發(fā)現(xiàn)協(xié)議可以分為簡單參與者發(fā)現(xiàn)階段和端點發(fā)現(xiàn)階段[11],兩個階段的發(fā)布/訂閱關(guān)系如圖2所示。

圖2 SDP自動發(fā)現(xiàn)過程
簡單參與者發(fā)現(xiàn)階段:域參與者之間進行相互發(fā)現(xiàn)。本地域參與者通過數(shù)據(jù)寫入者向其他域參與者發(fā)送數(shù)據(jù)包,同時也會通過數(shù)據(jù)讀取者讀取其他域參與者發(fā)送的數(shù)據(jù)包。
簡單端點發(fā)現(xiàn)階段:本地域參與者與其他域參與者進行相互匹配。它們相互交換包含主題名稱、主題類型和服務(wù)質(zhì)量策略等信息的數(shù)據(jù)包。
在DDS簡單發(fā)現(xiàn)協(xié)議中,每個本地域參與者需要將自己所有的端點信息發(fā)送給其他域參與者,同時也會接收其他域參與者發(fā)送的所有的端點信息,這會產(chǎn)生大量的內(nèi)存消耗和網(wǎng)絡(luò)傳輸量。事實上,每個域參與者只關(guān)心與自己訂閱主題相關(guān)的端點信息。因此,本文提出了基于單哈希多維布隆過濾器的自動發(fā)現(xiàn)算法。
2 算法設(shè)計
為降低標準Bloom的哈希計算量,本文提出了一種新型布隆過濾器OMBF。為降低DDS自動發(fā)現(xiàn)過程中的內(nèi)存消耗和數(shù)據(jù)傳輸,本文將OMBF與DDS簡單發(fā)現(xiàn)協(xié)議結(jié)合,提出了自動發(fā)現(xiàn)算法SDP_OMBF。
2015年9月,沙特阿拉伯和巴林簽署價值約3億美元的新輸油管道鋪設(shè)合同。該管道由沙特阿美石油公司和巴林石油公司共同管理,將把原油從沙特阿美公司位于沙特東部的布蓋格煉油廠輸送到巴林石油公司煉油廠。
2.1 OMBF
OMBF是一種高效率的空間隨機數(shù)據(jù)結(jié)構(gòu),它用位數(shù)組簡潔地表示一個集合,并可以判斷一個元素是否屬于這個集合。OMBF是一個多維向量,每一維向量分為k個分區(qū)且初始值為0。向量維數(shù)用t表示,每一維向量分區(qū)i的大小用mi(1≤i≤k)表示。
OMBF的哈希函數(shù)計算過程分為以下三個階段:
(1) 哈希階段:A→B。A是將要存儲或查詢的集合中的元素,B是經(jīng)過哈希函數(shù)映射之后的機器字。
(2) 選維階段:B→C。C是OMBF向量某一維,通過對B取模得到,即|B|(h(x)modt)。每次取模的結(jié)果選中OMBF向量某一維。
(3) 取模階段:B→D。D是OMBF向量某一維中的位置,通過對B取模得到,即|B|(h(x)modmi)。每次取模的結(jié)果使OMBF向量某一分區(qū)中某一位置為1。
如果每維向量中每個分區(qū)大小為互質(zhì),那么OMBF中這種不均勻的分區(qū)方法將會產(chǎn)生相互獨立的取模結(jié)果。更確切地,如果gi(x)=h(x) modmi,每個分區(qū)滿足條件(mi,mj)=1,1≤i≤j≤k,即mi、mj為相對素數(shù),那么g1(x)、g2(x)、…、gk(x)相互獨立。
圖3表示OMBF的結(jié)構(gòu),其中假設(shè)k=3,集合S{x1,x2}中的元素通過一個哈希函數(shù)h(x)和取模運算存儲在OMBF中。
通過實例說明OMBF的工作原理。假設(shè)m1=11、m2=13、m3=19。當(dāng)存儲元素x1時,首先,在哈希階段通過哈希函數(shù)h(x)轉(zhuǎn)換成機器字h(x1),設(shè)h(x1)=9 655;然后,在選維階段d=h(x1) modt,即將元素x1映射到OMBF向量中第d維;最后,在取模階段機器字h(x1)分別對各分區(qū)進行取模。g1(x1)=h(x1) modm1=8,g2(x1)=h(x1) modm2=9,g3(x1)=h(x1) modm3=3,即第d維三個分區(qū)對應(yīng)第8位、第9位、第3位。當(dāng)查詢某一元素是否屬于集合S時,將待查詢元素經(jīng)過3個階段運算之后,檢查相應(yīng)3個位置是否為1,如果是,則判定該元素屬于集合S。
2.2 OMBF性能分析
OMBF和Bloom一樣,在元素查詢過程中也會發(fā)生誤報。OMBF誤報由兩個因素導(dǎo)致:(1) 在哈希階段,由機器字沖突發(fā)生的誤報,用a表示;(2) 在取模階段,在機器字不發(fā)生沖突的情況下,機器字取模余數(shù)發(fā)生沖突導(dǎo)致的誤報,用b表示。OMBF總的誤報率用FOMBF表示,計算如下:
FOMBE=P(f)=P(f|a)P(a)+P(f|b)P(b)=
P(a)+P(f|b)(1-P(a))
(1)
(2)
同理,可以得到機器字取模余數(shù)發(fā)生沖突導(dǎo)致的誤報率為:
(3)
通常機器字的長度遠大于OMBF向量,所以P(a)接近于0。OMBF的誤報率可以簡化為:
(4)
由于SDPBloom中的哈希函數(shù)數(shù)量等于SDP_OMBF中每一維的分區(qū)數(shù),即哈希函數(shù)數(shù)量為k,其誤報率FSBF為[12]:
(5)
(6)
2.3 SDP_OMBF
在OMBF和簡單發(fā)現(xiàn)協(xié)議SDP的基礎(chǔ)上,本文提出了一種新的自動發(fā)現(xiàn)算法SDP_OMBF。SDP和SDP_OMBF的自動發(fā)現(xiàn)執(zhí)行過程如圖4所示。

(a) SDP執(zhí)行過程
圖4用兩個節(jié)點通信的實例說明SDP和SDP_OMBF執(zhí)行過程,實例中本地參與者A向遠程參與者B發(fā)送端點信息。SDP_OMBF的執(zhí)行過程如圖4(b)所示。在參與者發(fā)現(xiàn)階段,將本地參與者端點描述信息生成OMBF向量,然后和本地參與者數(shù)據(jù)包一塊發(fā)送至遠程參與者。參與者端點描述信息使用參與者端點信息唯一標識符,本文使用主題名作為唯一標識符。在端點發(fā)現(xiàn)階段,遠程參與者根據(jù)自身訂閱的主題對OMBF進行查詢。如果存在訂閱主題,則向本地參與者發(fā)送訂閱信息,本地參與者將被訂閱的主題數(shù)據(jù)包及服務(wù)質(zhì)量發(fā)送至遠程參與者進行下一步匹配,如果匹配成功,兩參與者建立通信。而在圖4(a)所示的SDP的執(zhí)行過程中,遠程參與者將會訂閱和接收本地參與者所有的端點信息。本文提出的SDP_OMBF將大量的端點信息減少為一條OMBF向量信息,因此,可以有效地減少自動發(fā)現(xiàn)過程中的內(nèi)存消耗和網(wǎng)絡(luò)傳輸量。
3 實 驗
本節(jié)通過仿真和實驗驗證SDP_OMBF的有效性。本文將SDP_OMBF與使用較廣的DDS改進自動發(fā)現(xiàn)算法SDPBloom進行對比,驗證SDP_OMBF網(wǎng)絡(luò)傳輸量和內(nèi)存消耗、主題查詢時間和誤報率。實驗平臺為Intel(R)CPU Core(TM) i5-3210、12 GB DDR 3(1 600 MHz)存儲器和4核×2線程(2.5 GHz),軟件環(huán)境為DDS分布式互聯(lián)架構(gòu)平臺。
3.1 網(wǎng)絡(luò)傳輸量和內(nèi)存消耗驗證
實驗設(shè)置了1 000個參與者,每個參與者發(fā)布100個主題,每個主題信息是6 800字節(jié),主題關(guān)鍵字為4字節(jié)。在SDPBloom和SDP_OMBF中,存儲主題關(guān)鍵字的向量為72字節(jié)。在端點發(fā)現(xiàn)階段,當(dāng)查詢主題關(guān)鍵字中成員元素的比例從10%到90%變化時,SDP_OMBF和SDPBloom的網(wǎng)絡(luò)傳輸量和內(nèi)存消耗如圖5和圖6所示。
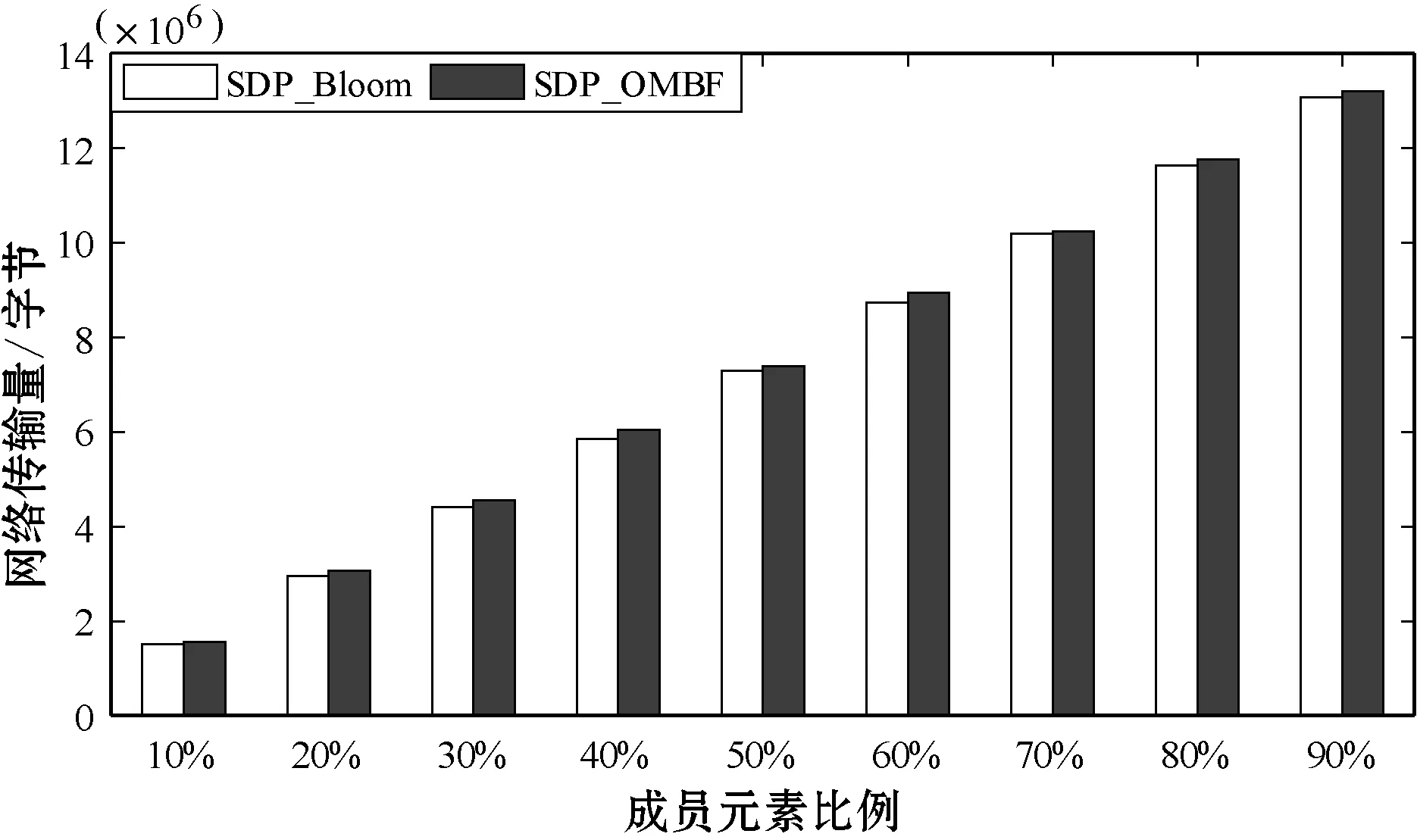
圖5 SDPBloom和SDP_OMBF的網(wǎng)絡(luò)傳輸量

圖6 SDPBloom和SDP_OMBF的內(nèi)存消耗
可以看出,當(dāng)端點匹配逐漸增大時,SDPBloom和SDP_OMBF中的網(wǎng)絡(luò)數(shù)據(jù)傳輸量和內(nèi)存消耗也逐漸增大。無論端點匹配率如何變化,兩者網(wǎng)絡(luò)數(shù)據(jù)傳輸量和內(nèi)存消耗都近似相等。
3.2 主題查詢時間和誤報率驗證
本文實驗中,參與者端點信息的每個主題關(guān)鍵字大小為4字節(jié)。在SDP_OMBF中,本地參與者n個主題關(guān)鍵字映射到OMBF向量中。遠程參與者查詢主題關(guān)鍵字成員元素比例在10%至90%之間變化。令m=150、n=100、k=3、t=3。SDP_OMBF中的哈希函數(shù)為MD5,SDPBloom中的哈希函數(shù)為MD5、MD2和SHA-1。
當(dāng)m變化時,進行了100組實驗,實驗結(jié)果如表1、表2所示。

表1 m=561時,SDPBloom和SDP_OMBF誤報率和計算時間對比
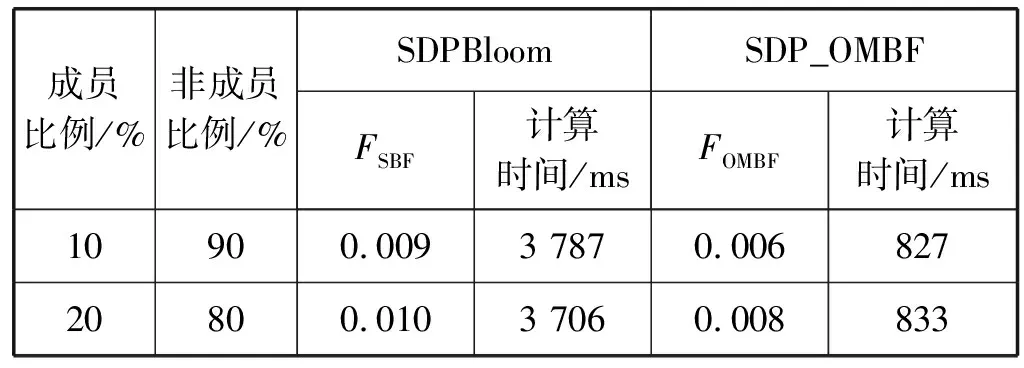
表2 m=1 413時,SDPBloom和SDP_OMBF誤報率和計算時間對比

續(xù)表2
從表1和表2可以看出,當(dāng)m較小時,SDP_OMBF的誤報率略大于SDPBloom;當(dāng)m增大時,兩者誤報率近似相等。然而,SDP_OMBF的運算時間始終低于SDPBloom約3 000 ms。
4 結(jié) 語
本文對 DDS 中SDP_ADA和SDPBloom自動發(fā)現(xiàn)算法進行了深入研究, 在分布式仿真系統(tǒng)規(guī)模較大時,針對數(shù)據(jù)傳輸過程中SDPBloom自動發(fā)現(xiàn)算法存在哈希函數(shù)運算量大的問題,提出一種新型的自動發(fā)現(xiàn)算法SDP_OMBF。通過實驗驗證了該算法的有效性。與SDPBloom算法相比,該算法在保證網(wǎng)絡(luò)數(shù)據(jù)傳輸量和內(nèi)存消耗基本不變的條件下,將哈希函數(shù)運算時間降低約78%,從而降低自動發(fā)現(xiàn)過程中參與者端點之間發(fā)布/訂閱信息的時間,提高了分布式仿真系統(tǒng)的實時性。
