基于Jupyter的數(shù)據(jù)挖掘課程建設(shè)與研究
2021-10-15 01:13:14王茂發(fā)王子民汪華登劉振丙
電腦與電信 2021年7期
王茂發(fā) 王子民 汪華登 劉振丙
(桂林電子科技大學(xué)計(jì)算機(jī)與信息安全學(xué)院,廣西 桂林 541004)
1 引言
Jupyter Notebook是一個(gè)開源的Web應(yīng)用程序,可用于創(chuàng)建和共享包含實(shí)代碼、公式、可視化和敘述文本的文檔。其用途包括:數(shù)據(jù)清洗和轉(zhuǎn)換、數(shù)值模擬、統(tǒng)計(jì)建模、數(shù)據(jù)可視化、機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、元學(xué)習(xí)等。當(dāng)前,在Jupyter平臺(tái)下最為流行的應(yīng)用方式之一,即為采用Python語(yǔ)言結(jié)合各種機(jī)器學(xué)習(xí)工具包進(jìn)行數(shù)據(jù)挖掘開發(fā)和教學(xué)。
選擇Jupyter為數(shù)據(jù)挖掘課程的教學(xué)和實(shí)踐平臺(tái)有以下5個(gè)優(yōu)點(diǎn):(1)代碼與結(jié)果展示一體融合,教與學(xué)的結(jié)果即時(shí)呈現(xiàn);(2)支持當(dāng)下最為流行的Python語(yǔ)言及其各種數(shù)值分析、數(shù)據(jù)處理和機(jī)器學(xué)習(xí)、深度學(xué)習(xí)開發(fā)包[1,2],如:Numpy、Pandas、Scikit-learn、Tensorflow、Pytorch、Keras等;(3)支持以網(wǎng)頁(yè)的形式分享,并對(duì)多種格式無(wú)縫兼容,如:HTML、Markdown、PDF、Python源碼等;(4)分布式運(yùn)行,在數(shù)據(jù)挖掘教學(xué)過(guò)程中,可以利用本地資源、遠(yuǎn)程資源、共享資源同時(shí)進(jìn)行代碼運(yùn)行和展示,進(jìn)而屏蔽課堂對(duì)于各種復(fù)雜運(yùn)行環(huán)境配置和安裝的要求,進(jìn)而實(shí)現(xiàn)一處安裝到處輕松講課和完美展示的效果;(5)交互式展現(xiàn),不僅可以輸出圖片、視頻、數(shù)學(xué)公式,還可以通過(guò)交互式插件呈現(xiàn)可互動(dòng)的可視化內(nèi)容,比如可縮放的地圖和可旋轉(zhuǎn)的三維模型,進(jìn)而實(shí)現(xiàn)理論與實(shí)踐同步,便于全過(guò)程開展沉浸式數(shù)據(jù)挖掘教學(xué),甚至完全代替?zhèn)鹘y(tǒng)的PPT教學(xué)。
2 教學(xué)大綱設(shè)置
數(shù)據(jù)挖掘是計(jì)算機(jī)等專業(yè)必選課之一[3,4]。數(shù)據(jù)挖掘又稱知識(shí)發(fā)現(xiàn),是一個(gè)從海量數(shù)據(jù)中根據(jù)某種法則抽取的,有價(jià)值或知識(shí)的數(shù)據(jù)的過(guò)程。它包括數(shù)據(jù)清洗、數(shù)據(jù)集成、數(shù)據(jù)轉(zhuǎn)換、數(shù)據(jù)挖掘、模式評(píng)估和知識(shí)表示等部分。數(shù)據(jù)挖掘涉及數(shù)據(jù)庫(kù)技術(shù)、機(jī)器學(xué)習(xí)、人工神經(jīng)網(wǎng)絡(luò)、統(tǒng)計(jì)學(xué)、模式識(shí)別、運(yùn)籌與優(yōu)化、面向?qū)ο缶幊痰榷鄠€(gè)學(xué)科中的知識(shí)。它的挖掘?qū)ο罂梢允菆D像、文本、影音、數(shù)據(jù)庫(kù)、數(shù)據(jù)倉(cāng)庫(kù)、Web數(shù)據(jù)庫(kù)等。就功能而言,數(shù)據(jù)挖掘主要是對(duì)所挖掘?qū)ο笾械臄?shù)據(jù)進(jìn)行概念描述、關(guān)聯(lián)規(guī)則的獲取、分類與預(yù)測(cè)、聚類分析、孤立點(diǎn)的發(fā)現(xiàn)、模式評(píng)估等。
通過(guò)本課程的學(xué)習(xí)可使學(xué)生獲得數(shù)據(jù)挖掘的基本理論、基本知識(shí)和基本技能、樹立理論聯(lián)系實(shí)際的工程觀點(diǎn),培養(yǎng)學(xué)生用人工智能的方法和觀點(diǎn)分析和解決數(shù)據(jù)領(lǐng)域問(wèn)題的能力,同時(shí)為學(xué)生后續(xù)學(xué)習(xí)深度學(xué)習(xí)、機(jī)器學(xué)習(xí)等專業(yè)課程提供必要的基礎(chǔ)知識(shí)、理論背景和平臺(tái)經(jīng)驗(yàn)[5,6]。
基于Jupyter開展數(shù)據(jù)挖掘教學(xué)實(shí)踐,有異于傳統(tǒng)的教學(xué)方法,如:(1)可以少用或不用PPT展示;(2)算法講解和代碼演示可以同時(shí)進(jìn)行,理論教學(xué)和實(shí)踐教學(xué)須合二為一;(3)近年來(lái),基于Jupyter平臺(tái)的開發(fā)各種數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)算法和模型工具包層出不窮、日新月異,如XGBoost、LightGBM等模型在Kaggle等數(shù)據(jù)競(jìng)賽平臺(tái)上被廣泛應(yīng)用,最新的數(shù)據(jù)挖掘教學(xué)內(nèi)容必須予以動(dòng)態(tài)體現(xiàn)這些最新的變化[7,8]。
在Jupyter環(huán)境,教學(xué)大綱和教學(xué)安排須進(jìn)一步體現(xiàn)以下兩點(diǎn)要求:(1)理論和實(shí)踐無(wú)縫鏈接,緊密結(jié)合,同步進(jìn)行,有條件布置好遠(yuǎn)程服務(wù)器教與學(xué)可同時(shí)在終端上進(jìn)行,教的內(nèi)容即時(shí)呈現(xiàn),學(xué)的東西即時(shí)實(shí)踐;(2)為了體現(xiàn)平臺(tái)優(yōu)勢(shì),需要在基礎(chǔ)教學(xué)內(nèi)容中安排若干課時(shí),講授Python基礎(chǔ)、數(shù)值處理工具Numpy、數(shù)據(jù)處理工具Pandas和Scikit-learn下的基本數(shù)據(jù)挖掘工具包。進(jìn)而將基于Jupyter環(huán)境下的數(shù)據(jù)挖掘教學(xué)大綱分為基礎(chǔ)和提升兩部分,其中基礎(chǔ)教學(xué)內(nèi)容主要培養(yǎng)學(xué)生基本的數(shù)據(jù)收集、數(shù)據(jù)分析、數(shù)據(jù)處理、數(shù)據(jù)清洗、數(shù)據(jù)可視化能力,主要的講授內(nèi)容有:數(shù)據(jù)挖掘概論、Python基礎(chǔ)、Numpy與Pandas、爬蟲技術(shù)基礎(chǔ)、數(shù)據(jù)清洗、數(shù)據(jù)可視化。提升教學(xué)內(nèi)容主要培養(yǎng)學(xué)生針對(duì)具體任務(wù)的數(shù)據(jù)挖掘能力,主要講授內(nèi)容有:分類、聚類、回歸、關(guān)聯(lián)規(guī)則、深度學(xué)習(xí)、元學(xué)習(xí)初步。一般來(lái)說(shuō),針對(duì)本科生開設(shè)的數(shù)據(jù)挖掘課程總學(xué)時(shí)控制在32~40學(xué)時(shí)之間為宜[9,10],表1給出了建議的教學(xué)大綱。
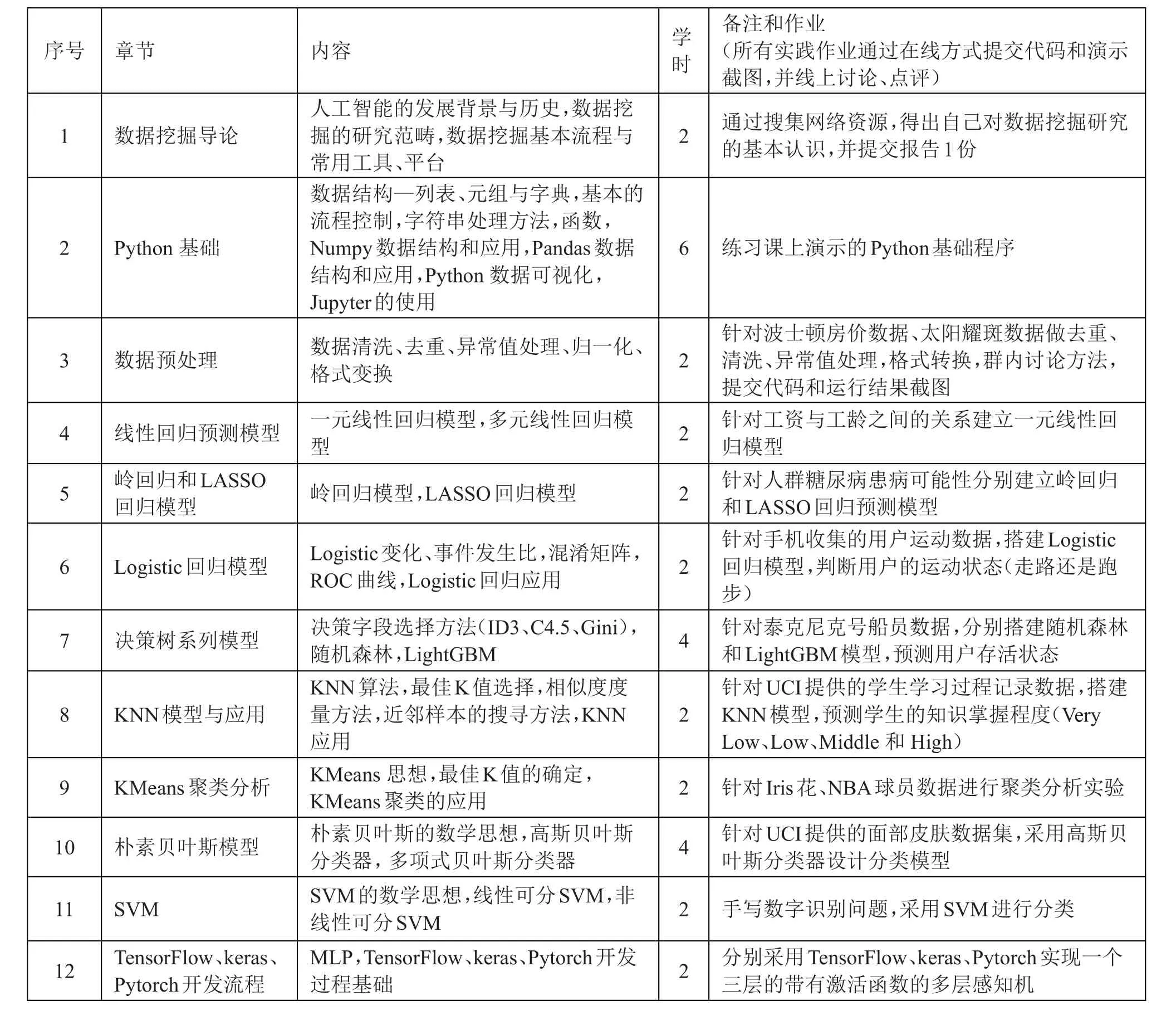
表1 教學(xué)大綱
3 課堂組織
下面以數(shù)據(jù)挖掘中常用的K近鄰(KNN)模型為例,詳細(xì)闡述如何利用Jupyter為載體開展數(shù)據(jù)挖掘課堂教學(xué)。
(1)基礎(chǔ)概念
KNN模型是一種有監(jiān)督的學(xué)習(xí)算法,中文名稱為K最近鄰算法。它屬于“惰性”學(xué)習(xí)算法,即不會(huì)預(yù)先生成一個(gè)分類或預(yù)測(cè)模型,用于新樣本的預(yù)測(cè),而是將模型的構(gòu)建與未知數(shù)據(jù)的預(yù)測(cè)同時(shí)進(jìn)行。該算法既可以針對(duì)離散因變量做分類,又可以對(duì)連續(xù)因變量做預(yù)測(cè),其核心思想就是比較已知y值的樣本與未知y值樣本的相似度,然后尋找最相似的k個(gè)樣本,用作未知樣本的y值預(yù)測(cè)。
首先,介紹一下KNN的算法原理和流程步驟。如圖1所示,模型的本質(zhì)就是尋找k個(gè)最近樣本,然后基于最近樣本做“預(yù)測(cè)”。對(duì)于離散型的因變量來(lái)說(shuō),從k個(gè)最近的已知類別樣本中挑選出頻率最高的類別用于未知樣本的判斷;對(duì)于連續(xù)型的因變量來(lái)說(shuō),則是將k個(gè)最近的已知樣本均值用作未知樣本的預(yù)測(cè)。以分類問(wèn)題為例,具體算法步驟如下:
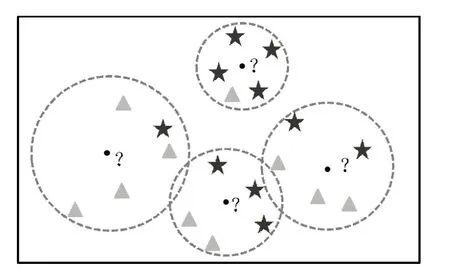
圖1 KNN算法示意圖
1)確定未知樣本近鄰的個(gè)數(shù)k值;
2)根據(jù)某種度量樣本間相似度的指標(biāo)(如歐氏距離)將每一個(gè)未知類別樣本的最近k個(gè)已知樣本搜尋出來(lái),形成一個(gè)個(gè)簇;
3)對(duì)搜尋出來(lái)的已知樣本進(jìn)行投票,將各簇下類別最多的分類用作未知樣本點(diǎn)的預(yù)測(cè)。
接下來(lái),可以向?qū)W生具體講授K值的選擇方法,及具體度量算法(如歐式距離、曼哈頓距離、余弦相似度、卡德相似系數(shù)等),這里不再做具體展開,我們重點(diǎn)介紹下如何使用Jupyter進(jìn)行算法的演示教學(xué)。
(2)基于Jupyter教學(xué)
這里通過(guò)針對(duì)UCI提供的學(xué)生學(xué)習(xí)過(guò)程記錄數(shù)據(jù),搭建KNN模型,預(yù)測(cè)學(xué)生的知識(shí)掌握程度(Very Low、Low、Middle和High)來(lái)演示基于Jupyter的教學(xué)過(guò)程。首先,使用markdown語(yǔ)言列出可能用到的基礎(chǔ)模塊包,并對(duì)每個(gè)模塊包進(jìn)行詳細(xì)介紹,如圖2所示,為后續(xù)模型代碼的開發(fā)打下堅(jiān)實(shí)的基礎(chǔ)。

圖2 可能用到的基礎(chǔ)包說(shuō)明和加載
接著,導(dǎo)入數(shù)據(jù),并預(yù)覽一下該數(shù)據(jù)集的前幾行,使得學(xué)生對(duì)數(shù)據(jù)集有一個(gè)更為清晰和直觀的認(rèn)識(shí),代碼及運(yùn)行結(jié)果如圖3所示,通過(guò)這種方式可以讓學(xué)生清晰地看到數(shù)據(jù)的基本結(jié)構(gòu)。數(shù)據(jù)集一共包含403個(gè)觀測(cè)對(duì)象和6個(gè)變量,首先前5列分別為學(xué)員在目標(biāo)學(xué)科上的學(xué)習(xí)時(shí)長(zhǎng)(STG)、重復(fù)次數(shù)(SCG)、學(xué)習(xí)時(shí)長(zhǎng)(STR)、兩個(gè)相關(guān)科目的考試成績(jī)(LPR和PEG);最后1列是學(xué)員對(duì)知識(shí)掌握程度(UNS),一共含有四種不同的值,分別為Very Low、Low、Middle和High。

圖3 數(shù)據(jù)導(dǎo)入和展示
繼續(xù)將導(dǎo)入的樣本按照3:1拆分成訓(xùn)練集和測(cè)試集,如圖4所示。這里要注意講解函數(shù)model_selection.train_test_split的幾個(gè)參數(shù)的意義:第1個(gè)參數(shù)是自變量,第2個(gè)參數(shù)是因變量,test_size表示測(cè)試樣本所占的百分比,最后一個(gè)參數(shù)random_state表示隨機(jī)數(shù)發(fā)生器的種子。

圖4 數(shù)據(jù)拆分
接著進(jìn)行K值選擇,具體代碼如圖5所示。采用10重交叉驗(yàn)證,測(cè)試不同的K值對(duì)應(yīng)的KNN模型的平均準(zhǔn)確率。這里要給學(xué)生講清楚K取值上限的計(jì)算方法:用樣本總量求以2為底的對(duì)數(shù)。最終通過(guò)圖示法給出最佳的K值,這里取5,如圖6所示。

圖5 交叉驗(yàn)證法確定KNN模型最終的K值
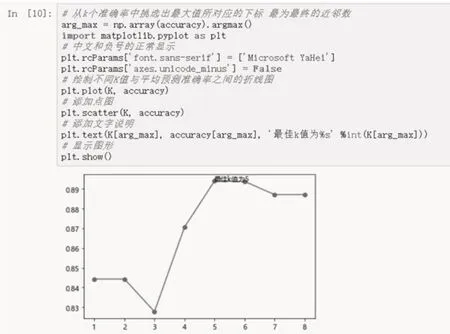
圖6 不同K值對(duì)應(yīng)的KNN模型的效果分析
再接下來(lái),構(gòu)造混淆矩陣,并可視化,如圖7所示。混淆矩陣的對(duì)角線數(shù)值是各個(gè)分類預(yù)測(cè)準(zhǔn)確的樣本量。利用混淆矩陣的可視化結(jié)果,讓學(xué)生理解每個(gè)分類的召回率、準(zhǔn)確率的概念和相互區(qū)別。
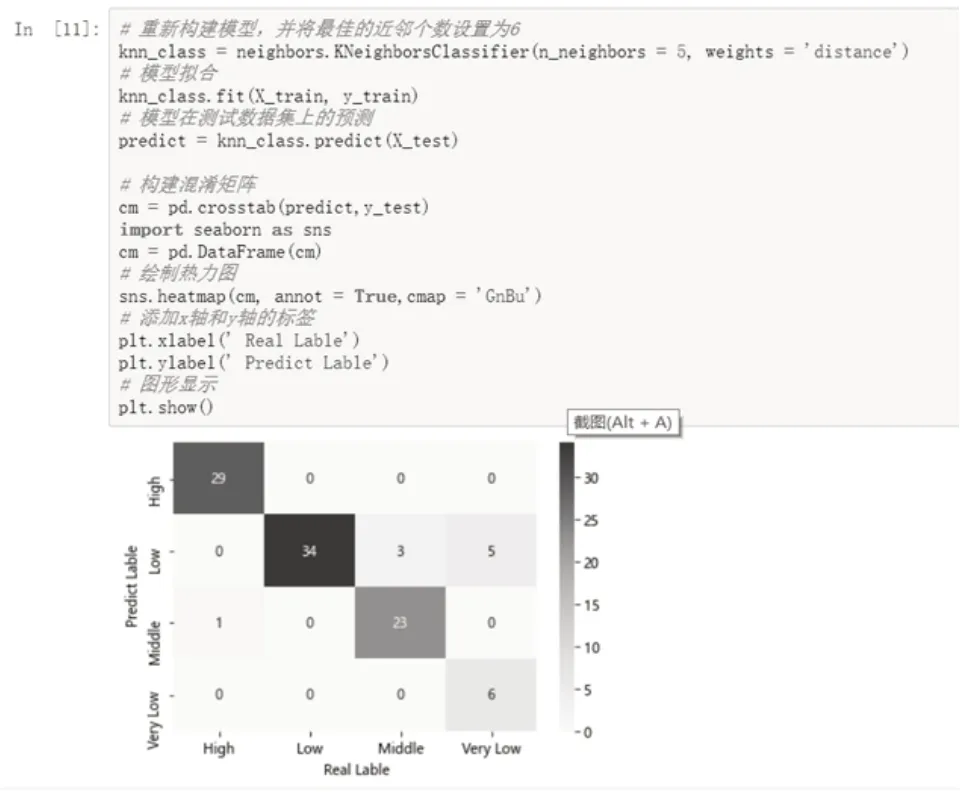
圖7 構(gòu)造最佳KNN模型的預(yù)測(cè)結(jié)果的混淆矩陣
最后通過(guò)Jupyter給出最終模型的準(zhǔn)確率和模型效能的評(píng)估,并講述每個(gè)指標(biāo)的具體含義,如圖8所示。
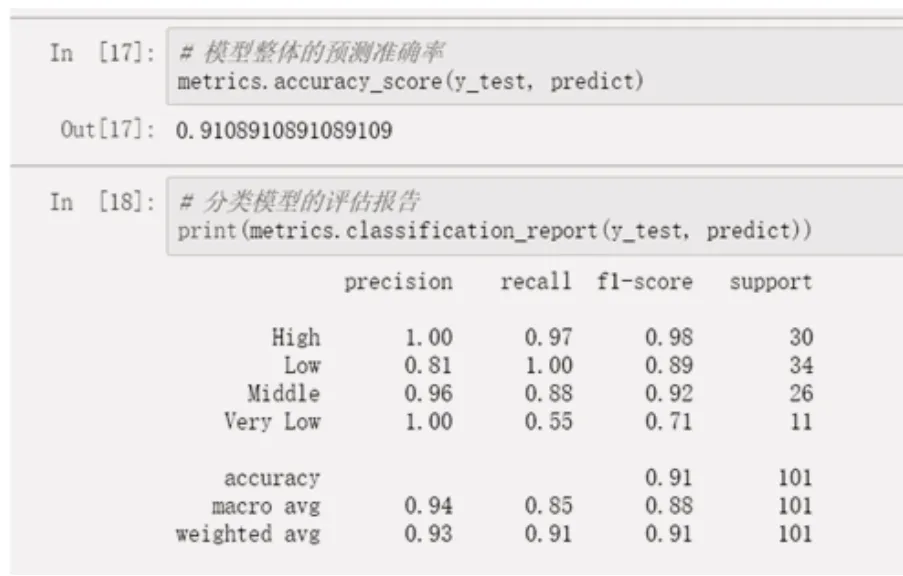
圖8 模型結(jié)果分析
通過(guò)以上基于Jupyter的代碼和結(jié)果講述過(guò)程,可以讓學(xué)生對(duì)KNN模型的建模、實(shí)驗(yàn)、結(jié)果分析有一個(gè)非常直觀的認(rèn)識(shí),從而建立起EDA分析、數(shù)據(jù)建模到結(jié)論分析一整套標(biāo)準(zhǔn)建模思想。
4 考核手段
基于Jupyter,既可以開展理論與實(shí)踐過(guò)程的教學(xué),也可以開展課后作業(yè)及期末考核工作。
在課后作業(yè)的布置環(huán)節(jié),可將作業(yè)以數(shù)據(jù)+任務(wù)的形式進(jìn)行線下部署,要求學(xué)生以Juypter形式進(jìn)行EDA分析、模型建模和結(jié)果展示及分析,最終以Juypter網(wǎng)頁(yè)形式進(jìn)行統(tǒng)一發(fā)布或截屏上傳,這種方式非常有利于學(xué)生數(shù)據(jù)建模連續(xù)思維的培養(yǎng),也有利于教師進(jìn)行線上作業(yè)檢查,全面評(píng)估學(xué)生的實(shí)操能力。
在期末考核環(huán)節(jié),可以將典型的數(shù)據(jù)分析和建模案例以Jupyter形式發(fā)布,具體可以填空、判斷、結(jié)論預(yù)測(cè)與分析等方式出題,全面考察學(xué)生數(shù)據(jù)挖掘過(guò)程中對(duì)各個(gè)具體知識(shí)節(jié)點(diǎn)的掌握程度。
5 結(jié)語(yǔ)
數(shù)據(jù)挖掘是計(jì)算機(jī)大類學(xué)科,尤其是人工智能方向必修課之一,也是學(xué)生走入機(jī)器學(xué)習(xí)的入門課,課程的內(nèi)涵和實(shí)用價(jià)值都非常大。如何在實(shí)戰(zhàn)環(huán)境下方便自如地開展理論與實(shí)踐教學(xué)一直是一個(gè)痛點(diǎn)問(wèn)題。本文首先介紹了Jupyter平臺(tái),然后針對(duì)數(shù)據(jù)挖掘課程教與學(xué)過(guò)程中普遍存在的問(wèn)題,進(jìn)行了系統(tǒng)分析和方案研究。主要從教學(xué)大綱、課堂組織、考核手段等環(huán)節(jié)進(jìn)行闡述,啟發(fā)教師的備課思路和方法,目的提升學(xué)生的數(shù)據(jù)挖掘課程的學(xué)習(xí)興趣,拓展數(shù)據(jù)挖掘課程教學(xué)研究的廣度和深度。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
傳媒評(píng)論(2019年4期)2019-07-13 05:49:14
電力與能源(2017年6期)2017-05-14 06:19:37
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
