基于神經網絡方法的經濟困難學生認定研究
2021-10-16 12:45:01余楨偉李媛
現代信息科技 2021年7期
關鍵詞:數據挖掘
余楨偉 李媛
摘要:隨著校園一卡通的應用,學生在校行為數據得以客觀記錄。為了解決高校學生工作中對于經濟困難學生認定存在的主觀性強,認定材料煩瑣等問題,文章采用數據挖掘方法,采集某高校校園一卡通消費數據,應用神經網絡算法構建高校經濟困難學生精準認定模型。該方法有助于實現對學生經濟困難等級的輔助預測,提高高校學生資助工作的科學化水平。
關鍵詞:數據挖掘;人工神經網絡;學生資助
中圖分類號:TP18? ? ? 文獻標識碼:A 文章編號:2096-4706(2021)07-0006-04
Research on Identification of Students with Financial Difficulties Based on
Neural Network Method
YU Zhenwei,LI Yuan
(Suzhou Institute of Technology,Jiangsu University of Science and Technology,Suzhou? 215600,China)
Abstract:With the application of campus all-purpose card,studentsbehavior data in school can be recorded objectively. In order to solve the problem of strong subjectivity and cumbersome identification materials in the work of college students,this paper uses data mining method to collect the consumption data of the campus all-purpose card of a college,and uses neural network algorithm to construct the accurate identification model of college students with financial difficulties. This method is helpful to realize the auxiliary prediction of studentsfinancial difficulty level and improve the scientific level of college studentsfinancial aid work.
Keywords:data mining;artificial neural network;studentsfinancial aid
收稿日期:2021-03-18
課題項目:2019年江蘇高校哲學社會科學研究項目(2019SJB905);2021年江蘇科技大學蘇州理工學院“暖心助困·勵志助學”暨學生工作精品項目(ZZKT202104)
0? 引言
隨著校園一卡通在各個學校流行,學生的日常消費行為被記錄,通過對學生行為數據尤其是消費類數據展開挖掘分析,進而客觀判斷學生經濟困難情況,成為當前各個高校學生資助工作的研究熱點,許多學者對此展開深入探討。在高校學生資助工作研究方面,王煜等學者基于某所高校校園一卡通的數據和獎學金發放情況,通過構建Logistic回歸模型確定影響獲得助學金與否的因素,為其建立數學模型,從而幫助到真正家庭困難的學生[1];柴政等學者在大數據應用的背景下,基于神經網絡的數據挖掘方法,分析“一卡通”消費數據來挖掘經濟困難學生,提高了經濟困難學生評定結果的準確性,但仍然存在著數據特征不夠細化的不足[2]。為了真正使資助工作落到實處,構建嚴格的學生資助評估方案十分必要[3]。
本論文提出的神經網絡模型方法通過對學生“一卡通”消費數據進行提取和訓練,對模型參數進行優化改進,以最后得出的神經網絡模型來預測貧困等級[4],有助于彌補上述方法的不足,挖掘潛在的經濟困難學生,保護學生的隱私,同時緩解了學生的忌貧心理,更具有科學性和準確性,有助于做到精準挖掘貧困人群,以更人性化的方式幫助到真正家庭經濟困難的學生,防止不貧困學生虛假申報或貧困學生不申請行為的產生。
1? 數據準備
本文的消費數據來源于校園一卡通,經濟困難學生名單來源于某高校學生資助中心。校園一卡通中可以通過消費數據來反映學生在學校的日常消費情況,并為貧困等級評價提供數據[5]。
1.1? 數據采集
以某高校2019年的經濟困難學生庫為例,采集他們自2019年3月1日至4月31日共兩個月的一卡通消費數據,涉及743個學生個體(其中734人在3月和4月均有消費記錄),共121 694條消費記錄(3月65 366條,4月56 328條)。除此之外,還需要從學生資助中心部門采集2018年到2019年在經濟困難學生庫中實際發放助學金的經濟困難學生名單數據,包含492名經濟困難學生,一共匹配到72 684條消費記錄(3月39 446條,4月33 238條)。樣表如表1所示。
1.2? 數據預處理
將數據進行分類匯總,根據消費類型可分為“餐費支出”“購熱水支出”“淋浴支出”“商場購物”“用電支出”“用水支出”等,根據每項消費類型把每個學生的消費次數和消費金額表示出來,將這幾類消費類型的消費次數、消費金額、消費總次數、消費總金額作為人工神經網絡模型輸入層的節點,讓模型學習其中的規律從而進行預測。變量描述性統計表如表2所示。
從平均值、標準差、極小值和極大值四個方面對這492名經濟困難學生兩個月的校園一卡通數據進行描述性統計分析,可以看出在餐費、購熱水、淋浴、商場購物支出、用水5種消費類型中,餐費支出金額的平均值最大,由此可見學生的日常消費地點以食堂居多,且標準差數值也最大,這說明每個學生食堂消費金額落差很大,這在很大程度上反映出了學生的個體差異。餐費支出作為必須支出,很大程度上能反映出學生是否貧困,如果某個學生一卡通的消費次數過少,那么屬于非正常現象,如果將他的消費數據放進模型會對模型產生干擾,對于怎樣去界定一個學生消費次數過少的標準,本文經過多次試驗得到一個更加利于提高預測準確性的預處理標準,將兩個月加起來的總消費次數低于15次和餐費次數低于5次的學生個體數據進行了去除處理,去除后最終減少了22個學生個體。
2? 數據分析
2.1? 數據導入
本文將三月和四月的消費數據聚集在一起并進行數據預處理后的數據作為訓練數據集,將訓練集中的一半數據作為測試數據集。圖1為基于RapidMiner軟件神經網絡的程序配置流程圖[6]。
2.2? 參數設置
輸入層由13個屬性項組成,輸出層有3個神經元,分別代表貧困等級“A”“B”“C”。其中“A”等級代表助學金2 000元,“B”等級代表助學金1 500元,“C”等級代表助學金1 000元。為了計算效率的提高,本文只設置一個隱藏層,對于隱藏層節點數的選取,本文選用了眾多公式中相對有效的一種,h=(m+n)1/2+α,其中m為輸入層節點數,n為輸出層節點數,α∈[1,10],在本文中,m為13,n為3,所以h∈[5,14],經過將本文選取的不同模型進行多次試驗后發現h取5、6、7、8時和10、11、12、13、14時預測準確率比h取9時略低,只有h取9時預測準確率最高,訓練結果最佳,因而本文隱藏層節點數取9。本文經過嘗試發現調試最大運行次數(Training cycles)和精確度(epsilon)也能提高模型精確度,經過多次調試,最終設置最大運行次數為500,精確度為10-5,如果訓練誤差低于精確度值,則不再優化。參數設置界面如圖2所示。
2.3? 模型建立
在高校經濟困難學生認定預測模型中,重點在于體現認定模型的精度而不是廣度,入選的變量一定要能夠客觀真實地表現學生的貧困情況。包括學生的基本信息(學號)、一卡通消費信息(消費總支出金額、消費總支出次數、餐費支出金額、餐費支出次數,購熱水支出金額、購熱水支出次數、淋浴支出金額、淋浴支出次數、商場購物金額、商場購物次數、用水支出金額、用水支出次數等)。變量能反映學生的消費水平、貧困等級,在變量的選擇上,任何一項重要指標都不應被遺漏,應做到完整、全面、系統地反映學生的實際貧困情況。本文建立的高校經濟困難學生認定模型,為了實現數據的可獲得性,選擇的變量一定要能夠被簡便獲取,為了提高模型的精確性,互斥變量一定要有相同的權重和測度,以實現橫向比較,選取的指標要直觀反映出學生的消費水平。模型運行配置界面如圖3所示[7]。
2.4? 模型輸出
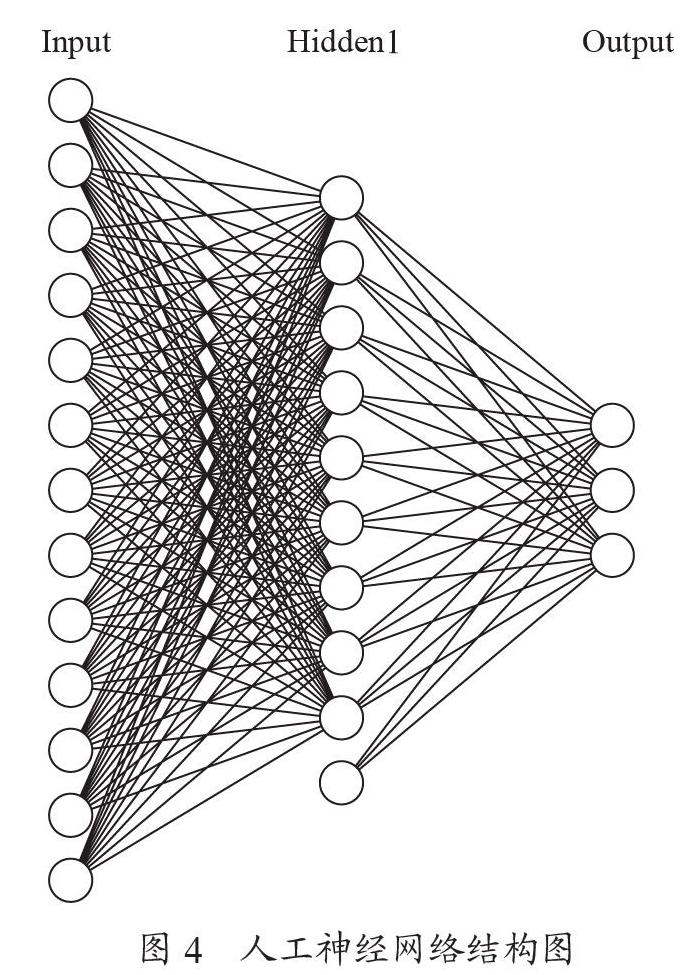
人工神經網絡結構一共有三部分組成,它們分別是輸入層、隱藏層、輸出層[4]。本文的輸入層有13個神經節點,分別代表這兩個月的消費總支出金額、消費總支出次數、餐費支出金額、餐費支出次數,購熱水支出金額、購熱水支出次數、淋浴支出金額、淋浴支出次數、商場購物金額、商場購物次數、用水支出金額、用水支出次數這些消費屬性。神經網絡通過調整這些節點之間相互連接的關系來進行預測貧困等級,隱藏層負責根據接收輸入層數據源并通過計算輸出結果給輸出層,它是連接輸入層和輸出層的橋梁,最后的輸出層節點代表A、B、C三種貧困等級。人工神經網絡結構如圖4所示。
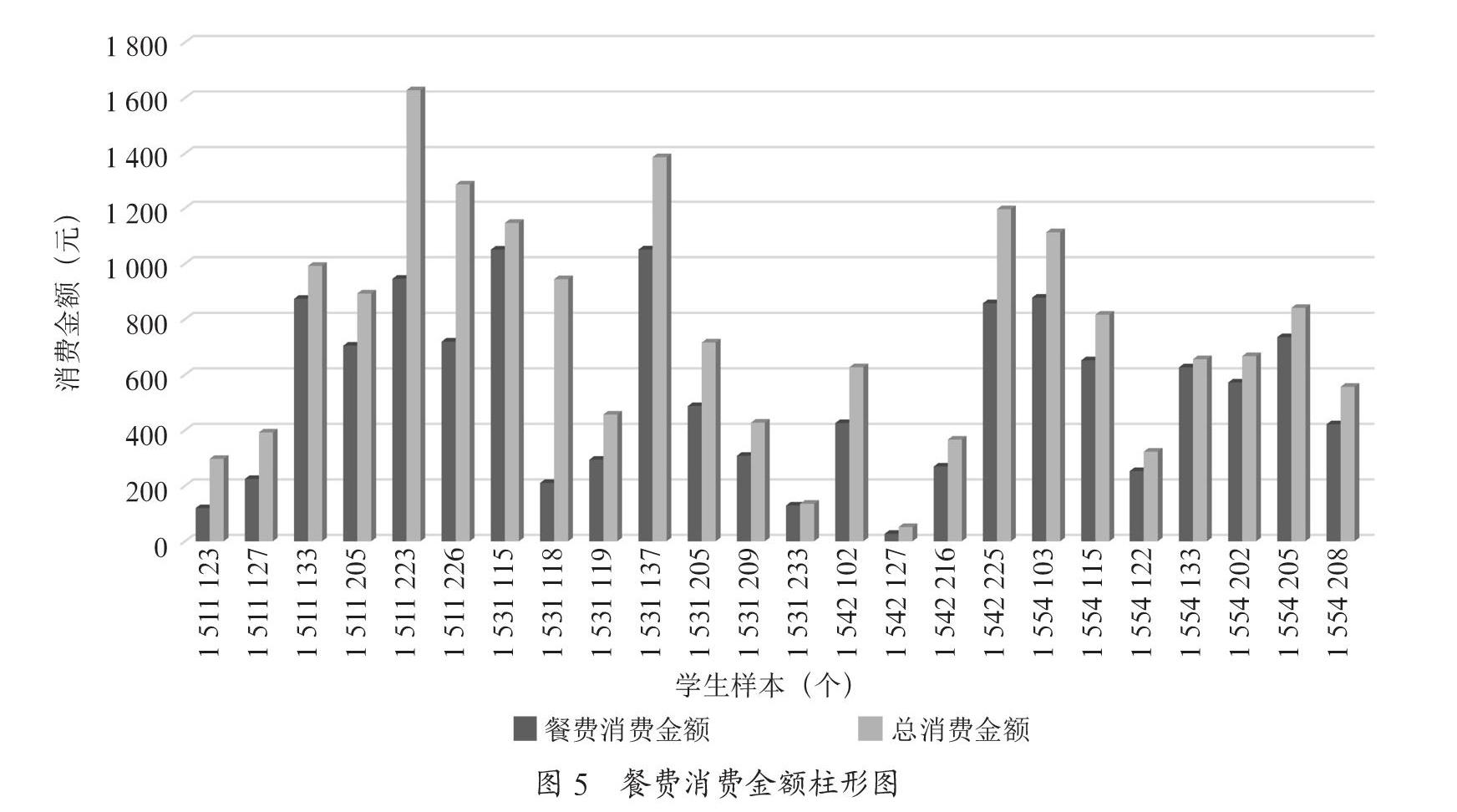
通過圖5可以清楚地看到餐費消費金額與總消費金額的相關性。對于絕大部分經濟困難學生,餐費消費金額占總消費金額比重較大,且明顯可以發現餐費消費的線性變化與總消費金額的線性變化相似,因此為了使預測模型得到更好的優化,對餐費數據一定要做好異常值處理。
2.5? 模型驗證
本文在訓練集為三月和四月按學號匯總后的數據集不變的基礎上,通過對測試數據集的標準優化來提高預測準確率。
第一次本文以訓練集共492條數據(其中A類貧困等級占比為18%,B類貧困等級占比為64.2%,C類貧困等級占比為17.6%),測試集為訓練集近1/2的數據,共250條數據,隱藏層節點數為9,最大運行次數為500,精確度為的預測條件得出預測準確率為75.6%的結果。第二次以與第一次訓練集、測試集相同,并在此基礎上對數據進行預處理得出預測準確率為75.9%的結果。
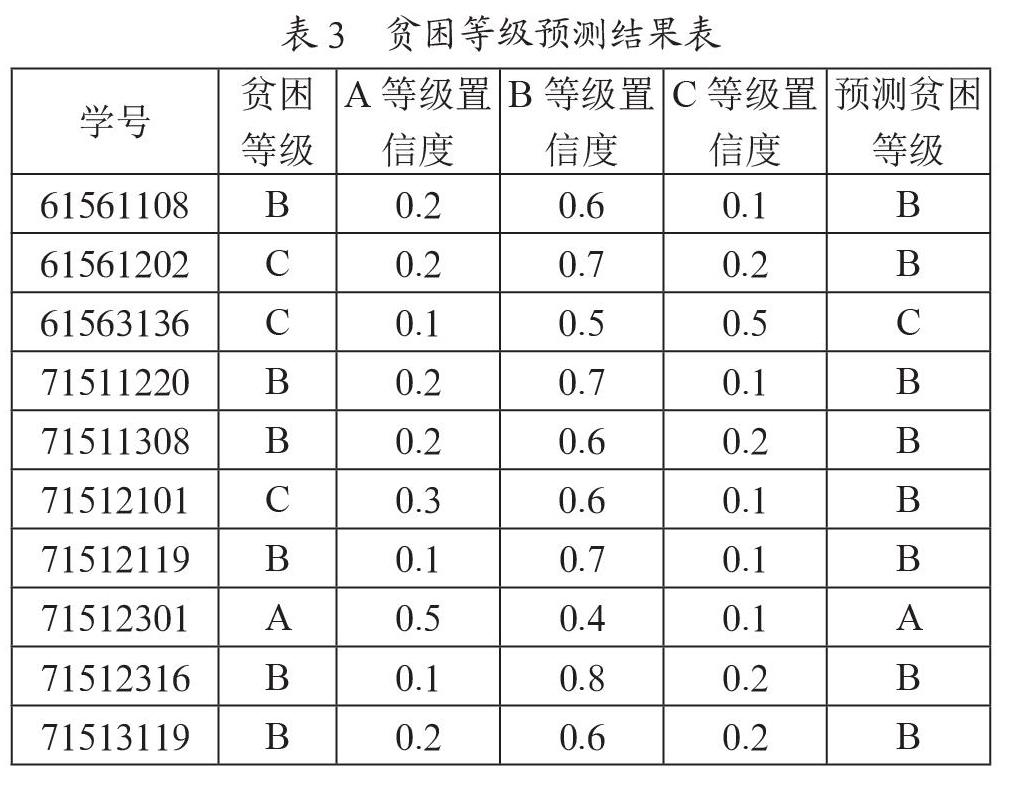
第三次仍然以與第一次訓練集、測試集相同,并在此基礎上刪除兩個月消費總次數小于15次、餐費支出次數小于5次的學生個體數據,得出預測準確率為76.3%的結果。第三次的預測準確率相對具有參考價值且足夠優化,可以作為最優模型。將測試數據集放入已經建好的神經網絡模型中,將本來標注好的貧困等級跟預測得出的貧困等級進行對比,測試數據共233條,其中有178條數據符合標簽數值,預測準確率為76.3%。部分結果如表3所示。
3? 結? 論
從實驗結果來看,本文得出的最終模型還有一定的提高空間,未來若能夠從多維的數據,包括學生成績數據等,對學生進行綜合評價,在經濟困難學生的貧困等級預測上能夠比單一的一卡通消費數據更具有說服力。在移動支付的普及的背景下,目前尚不能采集到使用手機支付的數據,這也會使預測產生偏差,未來在多維數據的補充下,預測的準確率會得到一定的提升。
本文基于神經網絡構建的高校經濟困難學生認定模型,一定程度上彌補了傳統方法主觀性較強的局限性。但當前計算機模型預測無法做到百分百準確,而一旦出現錯誤,會影響到經濟困難學生享受學生資助政策。故本人認為當下經濟困難學生判定工作最終仍要以人工決定為主要依據,同時輔以信息化技術,運用數據分析方法給高校工作人員提供決策依據,進一步提升高校學生資助工作的科學化水平。
參考文獻:
[1] 王煜,劉彤彤,郭磊.基于校園大數據的助學金獲取關鍵因素分析——以某高校一卡通數據為例 [J].中國教育信息化,2018(17):64-66.
[2] 柴政,屈莉莉,彭貴賓.高校貧困生精準資助的神經網絡模型 [J].數學的實踐與認識,2018,48(16):85-91.
[3] HUANG W,LI F,LIAO X,et al. More money,better performerce?The effects of student loans and need-based grants in Chinas higher education [J].China Economic Review,2018(51):208-227.
[4] 王慧健.基于神經網絡方法的時間序列預測方案研究 [D].南京:南京郵電大學,2019.
[5] 金琳.基于數據挖掘的用戶行為分析研究 [J].電子商務,2020(4):41-42.
[6] 李冠利.基于RapidMiner數據挖掘技術的NCRE成績預測分析 [J].南京廣播電視大學學報,2018(4):80-82.
[7] 馮曉媛.大數據挖掘技術應用研究 [J].數學技術與應用,2019,37(1):127-128.
作者簡介:余楨偉(1992.10—),男,漢族,湖北黃梅人,助教,碩士,研究方向:數據挖掘、管理信息系統;李媛(1998.01—),女,漢族,江蘇揚州人,本科,研究方向:信息管理與信息系統。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
