基于不完整乳腺癌數據的模型預測研究
2021-10-16 12:45:01鄧鈺芳
現代信息科技 2021年7期
關鍵詞:乳腺癌


摘要:針對不完整乳腺癌數據問題,該研究提出kmeans-KNN方法處理缺失值。首先對訓練集進行聚類并采用KNN進行缺失值填充,基于完整訓練集訓練線性回歸模型填充測試集的缺失值,然后使用機器學習算法XGBoost、RF、KNN、SVM對完整訓練集進行訓練建模,利用建立好的模型對完整測試集進行測試。結果證明kmeans-KNN在缺失值預處理上優于EM、MICE等常用的缺失值填補方法,在準確度和AUC上,kmeans-KNN+SVM取得最優。
關鍵詞:不完整數據;乳腺癌;診斷預測
中圖分類號:R737.9? ? ? 文獻標識碼:A 文章編號:2096-4706(2021)07-0050-04
Model Prediction Research Based on Incomplete Breast Cancer Data
DENG Yufang
(School of Computer,Electronics and Information,Guangxi University,Nanning? 530004,China)
Abstract:Aiming at the problem of incomplete breast cancer data,the study proposed the kmeans-KNN method to deal with missing values. First,cluster the training set and use KNN to fill in missing values,and train a linear regression model based on the complete training set to fill in missing values in the test set. Then,machine learning algorithms XGBoost,RF,KNN,and SVM are used to train and model the complete training set and complete test is used to test. The results show that kmeans-KNN is better than EM,MICE and other common missing value filling methods in missing value preprocessing,and kmeans-KNN+SVM is the best in accuracy and AUC.
Keywords:incomplete data;breast cancer;diagnosis prediction
收稿日期:2021-03-09
0? 引? 言
據國際癌癥研究機構(IARC)發布的最新數據顯示[1],截至2020年乳腺癌已成為全球女性發病率最高的癌癥。在大數據時代,使用機器學習方法建立乳腺癌診斷模型進行診斷預測為醫生的臨床決策提供科學參考是非常有意義的。然而機器學習方法的應用是基于完整可分類的數據。如果不對缺失數據進行處理則很難通過機器學習方法建立有效的生存預測模型,缺失數據的存在給乳腺癌生存預測帶來了很大的難度,甚至有可能會使整個數據失去價值。因此針對缺失數據進行合理處理是非常有必要的。
針對不完整數據的處理,國內外已有大量的相關研究。如Hadi等人采用不處理、均值、EM和K-近鄰(KNN)四種缺失值處理方法進行比較研究,并使用KNN、決策樹、邏輯回歸和支持向量機(SVM)四種機器學習算法構建乳腺癌生存模型,結果顯示KNN+KNN建立的模型最佳,而均值填充法的效果遠差于EM和KNN填充法[2]。但是大多數研究是先刪除缺失數據然后基于隨機缺失假定來采用缺失值填充法進行缺失值處理,并用均方根誤差和錯誤率評價填充效果[3,4]。而實際應用過程中往往無法驗證隨機缺失的假定是否正確[5],且刪除數據容易導致構造模型時出現偏倚。正如文獻[3]所說的要根據數據集缺失情況和所要研究內容來決定缺失值處理方法,因此為建立有效的乳腺癌診斷模型,本文提出kmeans-KNN進行缺失值預處理,然后采用XGBoost、隨機森林(RF)、KNN、SVM四種機器學習算法進行建模。
1? 不完整乳腺癌數據的預處理方法
數據缺失問題一直是數據預處理的挑戰之一。目前對缺失數據的處理的常見方法有(1)刪除(2)不處理(3)填充[3]。刪除往往是對含有缺失值的樣本進行刪除,不處理則是對含有缺失值的樣本不進行任何處理,然而在基于以機器學習為基礎的數據挖掘中,除了采用XGBoost、決策樹C4.5樹形模型進行數據建模外,其他的機器學習方法都難以處理含有缺失值的數據。填充法是對存在缺失值的樣本進行填充。因此為提高乳腺癌診斷模型的精度,kmeans-KNN的缺失值處理方法步驟為:
(1)劃分數據集D,訓練集:測試集=70%:30%,將訓練集完整的樣本記為Dc,含有缺失值的樣本記為Df。
(2)使用kmeans對Dc聚類。采用曼哈頓距離如式(1)計算數據集Df和Dc聚類之間的相似性。假設有樣本X1(X11,X12,…,X1n)和X2(X21,X22,…,X2n),曼哈頓距離公式dist為:
dist=|X1k-X2k|? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(1)
并將Df數據劃入到相應的Dc聚類,即對數據集D進行聚類。
(3)在聚類內采用KNN填充缺失值,然后合并聚類樣本得到完整的訓練集。
(4)基于訓練集訓練線性回歸模型對測試集中的缺失值進行填充,最后利用機器學習算法建立乳腺癌的診斷模型。
2? 機器學習算法
隨著人工智能的成熟應用,機器學習算法已被廣泛應用于醫療領域研究,如疾病的診斷預測和藥物療效預測等[6,7]。
2.1? XGBoost算法
XGBoost是陳天奇等人于2016年開發的機器學習算法[8],該算法是boosting算法中的一種,它是集成許多決策樹模型的強分類器。其算法思想就是不斷地添加樹,即不斷地進行特征分裂來生長一棵樹,而每次添加一棵樹,其實質是學習一個新函數,去擬合上次預測的殘差。對訓練集,當我們訓練完成得到k棵樹,則樣本分數是根據這個樣本的特征落到每棵樹中對應的葉子節點的對應分數,最后將每棵樹對應的分數加起來就是該樣本的預測值。本文利用XGBoost分類算法對已做缺失值預處理的完整的乳腺癌訓練集進行建模,首先根據基尼系數選出最優的特征,如密度,并把該特征作為樹節點進行分裂。每棵樹的深度為1,然后利用已建立好的模型對完整的測試集進行測試。
2.2? 隨機森林算法
隨機森林算法(RF)是一個集成了多個決策樹的集成分類器。給定訓練集之后,(1)從訓練集中采取有放回隨機抽取n個樣本作為決策樹的訓練集;(2)在訓練決策樹模型的節點的時候,在節點上所有的樣本特征中選擇一部分樣本特征,并在這些隨機選擇的部分樣本特征中選擇一個最優的特征來做決策樹的左右子樹劃分以增強模型的泛化能力。重復(1)(2)兩步,建立m棵決策樹,在分類任務中,m棵決策樹投出最多票數的類別為最終類別。本實驗采用sklearn包中的隨機森林分類器對完整乳腺癌訓練集進行分類建模,該模型集成100棵決策樹,每棵樹采用基尼系數選出最優樹節點進行分裂,每棵樹的深度為1。
2.3? K-最近鄰算法
K-近鄰(KNN)算法是一種基本分類和回歸的算法。對于給定的訓練集,對新的輸入樣本,采用距離度量,如歐式距離、馬氏距離等相似距離方法,在訓練集中找到與該樣本最鄰近的K個樣本,這K個樣本的多數屬于某個類,就把該樣本分類到這個類中。且K的取值往往依賴于數據的分布特點。本文采用sklearn包中的KNN分類算法對完整的乳腺癌訓練集進行分類建模,K的取值為3,即對每個樣本尋找距離最近的3個樣本來確定樣本的類別。
2.4? 支持向量機
SVM是按監督學習方式對數據進行二元分類的廣義線性分類器,其基本模型是在特征空間上找到最佳的分離超平面使得訓練集上二分類樣本間隔最大。給定訓練集D={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,yi∈{+1,-1},i=1,2,…,n。wx+b=0為分離超平面,其中w,b分別為超平面的法向量和截距。則線性SVM學習算法步驟為:
(1)選擇懲罰參數C>0,構造并求解凸二次規劃問題求最優解α=(α1,α2,…,αn)T。
min aiajyiyj(xi ,xj)-ai,s.t. aiyi=0,
0≤αi≤C,i=1,2,…,n
(2)計算w=aiyixi,選擇滿足0≤α≤C的α,計算b=yj-aiyi(xi,xj)。
(3)求解超平面wx+b=0,則分類決策函數為f(x)= sign(wx+b)。
本文采用sklearn包中的SVM分類算法對完整的乳腺癌訓練集進行分類建模,該算法的核函數為線性核函數,即在完整訓練集中找到一條直線使得患良性和惡性腫瘤的患者能較好地區分開來。
3? 數據集與缺失數據處理方法的效果評價
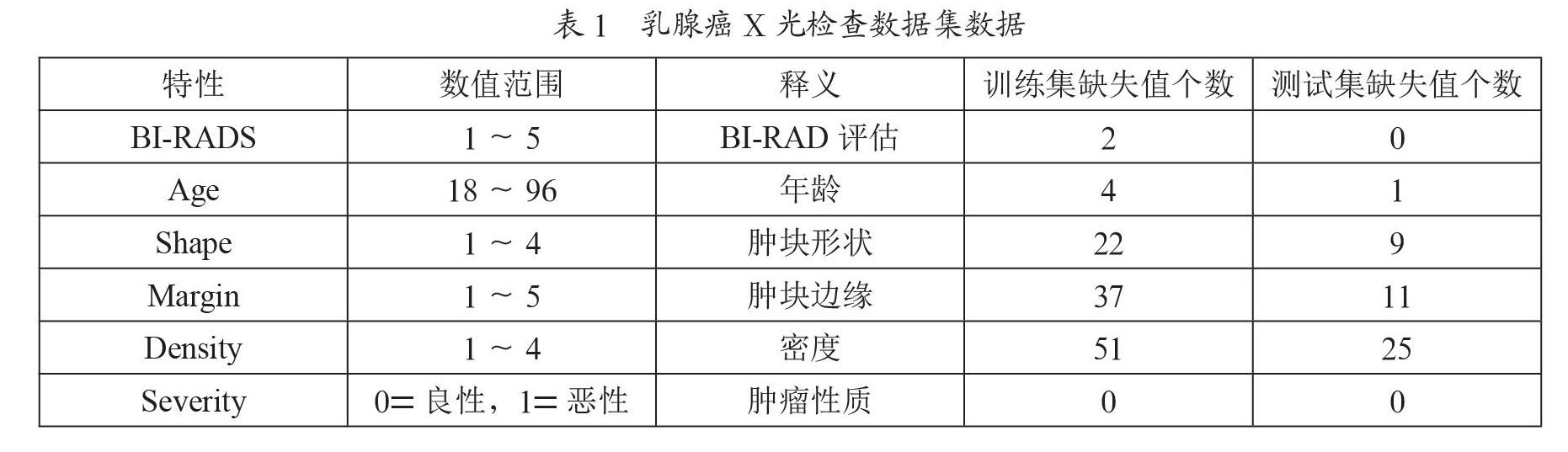
本實驗數據來源于UCI數據集(http://archive.ics.uci.edu/ml/datasets.php)中的乳腺X光檢查數據集,共961例包含6個屬性其中最后一行為標簽,如表1所示。
數據缺失類型分為三種:完全隨機性缺失、隨機缺失、非隨機缺失[3]。完全隨機缺失是缺失值與數據集中已知或者未知的特征是完全無關的。如該數據集中年齡字段是否缺失是完全隨機的,它只取決于患者本身與患者的其他特征信息無關。隨機缺失是指該類數據的缺失依賴于其他完全變量。如該數據集中缺失的腫塊形狀信息往往依賴于腫塊大小。非隨機缺失指的是數據的缺失依賴于不完全變量自身。如良性腫瘤患者的腫塊大小信息缺失。
針對不完整乳腺癌數據建立乳腺癌診斷模型,模型評價指標是依據混淆矩陣的準確度、精確度、特異度、召回率和AUC面積。
4? 仿真實驗與結果
本文基于乳腺X光檢查數據集進行實驗,首先對該數據集隨機地劃分70%訓練集和30%測試集,訓練集和測試集中缺失值情況如表1所示。針對訓練集的缺失數據,該實驗先將訓練集劃分為無缺失值的完整樣本和含有缺失值的不完整樣本,對完整樣本采用kmeans聚成三類,依據曼哈頓相似距離計算不完整樣本和三個聚類中心的距離并將該樣本劃入最相似的聚類內,即對訓練集聚為三類。在類內采用KNN填充法填充缺失值,使缺失值樣本盡可能地符合實際值。為了驗證kmeans-KNN方法的有效性,該實驗還與EM、MICE等七種常用的缺失值處理方法進行比較研究。對于測試集中的缺失值則采用線性回歸法訓練訓練集并填充相應的缺失值。數據缺失值預處理完成后,分別采用XGBoost、RF、KNN、SVM四種機器學習算法對訓練集進行訓練建模,這四種分類算法基于sklearn包實現,參數設置中XGBoost、RF的最大深度為1,SVM的核心函數為“linear”,其他的參數為sklearn包的默認設置。最后用訓練好的模型對測試集進行測試,用準確度、精確度、特異度、召回率和AUC五個評價指標對模型效果進行評價。
實驗結果如圖1和圖2所示,對于未處理數據,由于RF、KNN、SVM無法提供缺失值的自動處理而無法有效建模,而XGBoost可將缺失值作為稀疏矩陣自動處理從而建立有效的模型且模型的準確度和AUC分別為78.2%和78.9%。該實驗將kmeans-KNN與EM等七種缺失值填充法進行比較研究,結果表明kmeans-KNN建立的模型準確度和AUC普遍優于其他結合方法。除了均值填充法外,經缺失值處理后XGBoost模型準確度、精確度、特異度、召回率、AUC普遍高于數據未處理建立的XGBoost模型效果。而在所有的方法結合中,kmeans-KNN+SVM建立的模型準確度和AUC最優,且對于在同一缺失值處理下,SVM建立的模型準確度優于XGBoost、RF、KNN模型的準確度,對于XGBoost、RF、KNN建立的模型效果比較則難分優劣。
5? 結? 論
本文提出的kmeans-KNN方法可以有效解決缺失數據問題,且SVM在分類性能上表現最優。通過該研究可知即使可以采用類似XGBoost方法在建模過程中自動處理缺失值,但先做預處理再建模的效果往往會更好。
參考文獻:
[1] 世界衛生組織國際癌癥研究機構(IARC).Estimated age-standardized incidence rates(World)in 2020 [EB/OL].(2021-03-02).https://gco.iarc.fr/today/online-analysis-multi-bars.
[2] DHAHRI H,MAGHAYREH E A,MAHMOOD A,et al. Automated Breast Cancer Diagnosis Based on Machine Learning Algorithms [J/OL].Journal of healthcare engineering,2019:4253641[2021-03-29].https://www.hindawi.com/journals/jhe/2019/4253641/.
[3] 劉星毅,農國才.幾種不同缺失值填充方法的比較 [J].南寧師范高等專科學校學報,2007,24(3):148-150
[4] 李琳,楊紅梅,楊日東,等.基于臨床數據集的缺失值處理方法比較 [J].中國數字醫學,2018,13(4):8-10+80.
[5] 閆世艷,郭中寧,何麗云,等.臨床研究缺失數據多重填補敏感性分析方法 [J].世界科學技術-中醫藥現代化,2020,22(3):823-828.
[6] 彭佳麗,劉春容,李旭,等.采用XGBoost和隨機森林探索中國西部女性乳腺癌危險因素 [J].現代預防醫學,2020,47(1):1-4.
[7] 吳興惠,周玉萍,邢海花,等.機器學習分類算法在糖尿病診斷中的應用研究 [J].電腦知識與技術,2018,14(35):177-178+195.
[8] CHEN T Q,GUESTRIN C. XGBoost:A Scalable Tree Boosting System [C]//KDD16:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York City:Association for Computing Machinery,2016:785-794.
作者簡介:鄧鈺芳(1996.10—),女,漢族,廣西南寧人,碩士研究生在讀,研究方向:機器學習數據挖掘。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
現代臨床醫學(2022年1期)2022-02-12 02:04:58
甘肅科技(2020年20期)2020-04-13 00:30:42
中國生殖健康(2019年2期)2019-08-23 08:11:42
中國生殖健康(2019年6期)2019-01-06 09:20:12
中國生殖健康(2019年5期)2019-01-06 09:16:40
幸福家庭(2019年14期)2019-01-06 09:15:38
祝您健康(2018年5期)2018-05-16 17:10:16
癌癥進展(2016年9期)2016-08-22 11:33:20
中國組織化學與細胞化學雜志(2016年4期)2016-02-27 11:16:08
