基于貝葉斯糾錯的礦山地質勘測數據糾錯方法
2021-10-16 16:01:54陳弓
現代信息科技 2021年7期


摘要:為解決傳統糾錯方法無法完全校正錯誤數據組的問題,設計了一種基于貝葉斯糾錯的礦山地質勘測數據糾錯方法,使用貝葉斯字典設計統計勘測數據流程,通過使用貝葉斯糾錯器生成候選數據集合,并在此基礎上按照層次的隸屬關系,設定礦山地質勘測錯誤數據編碼規則,對數據組進行逐層編碼排序。為進一步實現對錯誤數據序列的校正,引進了k-spectrum算法,重組錯誤數據序列,以此實現對勘測錯誤數據的有效糾錯。
關鍵詞:貝葉斯糾錯;礦山;地質;勘測數據;糾錯方法
中圖分類號:TP311? ? ? ?文獻標識碼:A 文章編號:2096-4706(2021)07-0085-04
Error Correction Method of Mine Geological Survey Data Based on
Bayesian Error Correction
CHEN Gong
(Geological Information Center,East China Geological Exploration Bureau,Nonferrous Metals,Jiangsu province,
Nanjing? 210000,China)
Abstract:In order to solve the problem that the traditional error correction methods can not completely correct the wrong data group,a mine geological survey data error correction method based on Bayesian error correction is designed. The Bayesian dictionary is used to design the process for counting survey data,and the candidate data set is generated by using the Bayesian error corrector,and on this basis,according to the hierarchical membership relationship,set the coding rules of mine geological survey error data,and code and sort the data groups layer by layer. In order to further achieve the correction of the error data sequence,the k-spectrum algorithm is introduced to reorganize the wrong data sequence,so as to realize the effective error correction of the survey error data.
Keywords:Bayesian error correction;mine;geology;survey data;error correction method
收稿日期:2021-03-12
0? 引? 言
礦山地質勘測是開采礦產資源前期的重要工作之一,只有獲取大量的礦山地質勘測數據,才能確保礦產資源開采工作的安全實施。由于礦山地質結構復雜,并且不同區域的地質環境是隨著地殼變遷而相應變化的,因此,地質勘測單位對礦山地質勘測工作的實施,在精準度方面提出了要求[1]。為了滿足此方面的需求,相關地質勘測單位設計一種針對勘測數據的糾錯方法,此方法以增強現實技術作為支撐,將所獲取的勘測數據進行集成與融合,并呈現在終端計算機顯示屏幕中,將從多個渠道獲取的相同位置信息進行疊加,以更為真實地將礦山地質環境表現出來。在對勘測數據進行顯式處理的過程中,一旦所勘測的數據存在偏差或失真問題,在終端的成像中便會清晰地顯示出來。相比人工糾錯數據的方式,此方式具有更高的糾錯效率,并極大地簡化了記憶數據處理的復雜程度。但此種糾錯方法在實際應用中,需要以智能化設備作為輔助,并在生成礦山地質圖像時,要求以高清的計算機顯示屏幕作為支撐,否則將影響到成像的分辨率與清晰度,從而干預到地質勘測錯誤數據的判斷。因此,在本文的研究中,引進了貝葉斯糾錯器,結合貝葉斯概率計算,得到字符串最大候選結果,并通過對數據的推導,達到對勘測數據糾錯的目的。
1? 基于貝葉斯糾錯的礦山地質勘測數據糾錯方法
1.1? 基于貝葉斯糾錯生成候選數據集合
為了實現對礦山地質勘測數據的準確糾錯,本文引進貝葉斯糾錯器,生成礦山地質勘測候選數據集合[2]。在此過程中,需要獲取礦山地質勘查中不同維度的數據,并將勘測的數據從計算機終端導入貝葉斯糾錯器,結合貝葉斯概率計算公式,對勘測數據集合中的最高正確率進行預測,計算公式為:
(1)
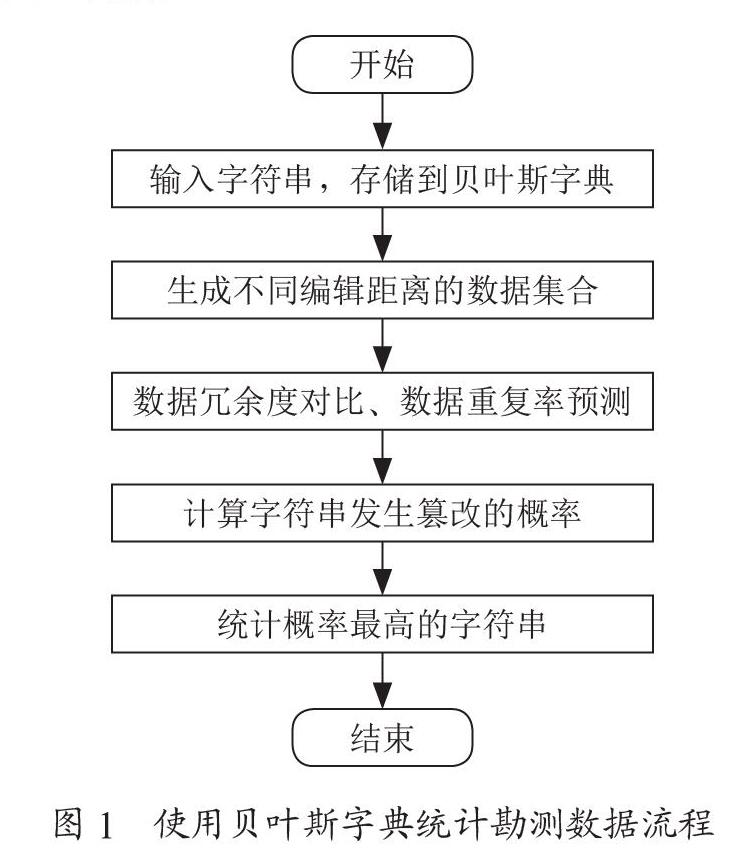
其中,P(wc|wi)表示所獲取的礦山地質勘測數據集合中,數據最高正確率,wc為糾正數據,wi為前端輸入的勘測數據。考慮到在前端輸入的勘測數據中,可能含有大量的重復數據或冗余數據,此種數據會影響計算結果,因此需要通過貝葉斯字典對數據集合進行統計。統計過程如圖1所示。
按照如圖1所示的流程,對勘測數據進行初步統計,但在統計過程中,涉及對數據編輯距離的設計。因此,可將此作為數據糾錯的依據,采用狀態隨機轉變的方式,生成一個隨機字符串[3]。在此過程中,對勘測的礦山地質數據進行一次編輯,可以實現字符的替換、刪除、增加等操作,在編輯中每一個經過處理后的字符均可以作為候選集合中的新字符。在完成對字符串的初步處理后,打亂字符串,對其進行隨機匹配,并使用貝葉斯糾錯器輸出最佳匹配項,將此數據項表示為argmaxlgP(wc|wi),此時最佳匹配字符串在統計集合中出現的概率,可以作為候選集合生成時貝葉斯糾錯器的迭代處理次數。
在完成了對候選數據集合生成前提條件的準備之后,以不同類型的勘測數據字符串長度作為先檢驗概率,使用常規的噪聲通道進行混淆字符串數量的統計[4]。例如,在糾錯器前端輸入d1→f1,后端便可能將“d1”識別為“f1”,或是將“d1→f1”識別為“f1→d1”,按照此種方式,可以得到一個編碼混亂的候選數據集合。為了確保將打亂格式的勘測數據全部導入貝葉斯糾錯器中,需要提前掌握勘測數據的字符串總數,并按照如圖1所示的流程,在將勘測數據完全導入后,進行導入字符串的統計,對比導入后字符串總數與統計的字符串總數是否存在差異。假定前者與后者一致,此時可直接從貝葉斯終端輸出混淆的數組集合。數組集合表達式為:
(2)
其中,len表示礦山地質勘測數據的字符串可編輯長度,i為數據編碼;j為字符串首列字母。按照上述方式,生成候選數據集合。反之,當導入字符串總數與統計字符串總數存在差異時,需要再次對矩陣進行混淆處理,在不改變勘測數據中核心數據與權重數據的前提下,進行數組的二次處理,直到數組滿足計算需求,便可按照標準輸出候選數據,以此完成候選集合的生成。
1.2? 設定礦山地質勘測錯誤數據編碼規則
在完成候選數據集合的生成后,需要對勘測的數據進行編碼,結合編碼次序,掌握勘測數據的規范性。為滿足這種需求,需要設定一個符合礦山地質勘測錯誤數據的編碼規則[5]。在編碼過程中,應當對候選集合中每個數據組的類目進行外延,細分知識層次,并嚴格遵循各類目對數據分的要求,將字符串進行平鋪,此過程中,可允許字符串存在突出或合并的列類,并按照層次的隸屬關系,進行逐層編碼排序。同時,應當明確編碼規則是由字符串識別編號、標識號與序列編號構成,每個不同的編號在規則中所代表的含義是不同的。例如,“W6300”表示字符串識別編號,其中“W”表示對礦山地質的勘測行為;“2020R”表示標識號,其中“2020”表示地質勘測工作實施的年限,“R”表示勘測過程中對不同區域的劃分依據;“18,15,180BL”表示序列編號,其中“BL”表示對指定地質勘測區域內地質類型的劃分,其中“18,15,180”可用來表示勘測點在空間中的坐標。通過上述方式,在完成對數據的編碼后,可基本掌握數據集合的輸出標準及規則。
在掌握礦山地質勘測錯誤數據輸出標準后,應當明確礦山地質勘測過程中,不同文件格式信息的表達是使用字母進行描述的。因此,在設定字符串編碼規則后,需要對常見的字母或符號編碼規則進行編輯,具體內容如表1所示。
綜合表1中提出的內容,對礦山地質勘測錯誤數據進行編碼,此過程可參照如圖2所示的流程進行。
按照表1中提出的編碼規則,輸出圖2終端導出的字符串序列碼,以此作為礦山地質勘測數據結果。
1.3? 基于k-spectrum算法重組錯誤數據序列
通過前期的相關研究,已完成了對礦山地質勘測數據的基本處理,為校正數據序列,利用k-spectrum算法對數據進行重組。在此過程中,考慮到原始數據集合與生成的候選數組集合,其中含有質量參差不齊的reads,因此,需要在糾錯前,對數據進行前端預處理,即過濾數據并調整其格式,使數據在終端的輸出更加規范化。在預處理過程中,應明確k-spectrum算法中k表示為可信度系數,是指數據集合中不同數據集的規范化操作可能性。在此基礎上,在計算機終端導入礦山地質圖示,將前端的數組按照編碼順序,依次輸入計算機中,根據處理的圖像,對勘測區域進行切割[6]。切割過程中,按照堿基序列,將其劃分為多個k-mers,其中mers的字符串長度決定了重組序列的長度,k值的大小表示數組的復雜度。而重組錯誤數據序列的過程,便是求取一個針對k-mers中k的最優值。為了區分冗余數據類型,可設定一個基因值G,G也可以表示勘測數據中的核心值,即數組中不發生變化的數值,為了實現對k最優解的計算,應首先對數組中的單次勘測周期進行描述。表達式為:
(3)
其中,t為礦山地質單次數據勘測周期,e為最佳閾值范圍。將e的實際值代入計算過程中,并根據錯誤可能發生的概率性,將t代入k的計算公式中,計算過程為:
(4)
其中,G為礦山地質勘測數組中的基因值,ρ為散列表。按照上述計算公式,輸入k值,得到勘測數組中的可信度數據集合。刪除可信度較低的數據值,按照邏輯層數據編碼規則,對可信度較低的數組與礦山地質成像中的信息進行光學描述。為了確保數組對應的數組滿足勘測需求,可將對應的數組與圖像進行計算機終端成像放大處理,并在Web端檢查數組序列與圖像是否匹配,對于不匹配的數據,可通過旋轉、重疊、縮放等處理方式進行校正。通過這種方式完成對礦山地質勘測數據的糾錯。
2? 實驗論證分析
上文結合貝葉斯糾錯器的使用,設計了一種針對礦山地質勘測數據的糾錯方法,在完成對方法的設計后,本章介紹了基于ASEC算法的糾錯方法,將此方法與本文設計的方法進行對比,并希望通過此次實驗可以證明本文所設計方法的糾錯結果更為準確。
為確保實驗結果的真實可靠,選擇某地質勘測工作單位近三個月的地質勘測數據,作為此次實驗的數據組。對實驗數據的描述如表2所示。
在完成對礦山地質勘測錯誤數組的描述后,將表1提出的錯誤數組與正確數組進行打亂處理,控制輸入端的數組數量為50 000.0 bit。將數據集合上傳到終端計算機設備,在相同的操作環境下,分別使用本文設計的方法與傳統方法對數據集合中的錯誤數據組進行糾錯處理。并根據終端輸出的錯誤數組與糾錯結果,對方法進行可行性評估,實驗結果如表3所示。
綜合表3的結果可知,兩種糾錯方法均可以實現對錯誤數組的識別,但基于ASEC算法的糾錯方法,在校正錯誤數組時,僅能校正部分錯誤數組,無法完全校正錯誤數據組,而本文設計的糾錯方法在進行錯誤數組糾錯時,可以實現對所有錯誤數組的準確校正。
3? 結? 論
本文從生成候選數據集合、設定錯誤數據編碼規則、重組錯誤數據序列三個方面,對基于貝葉斯糾錯的礦山地質勘測數據糾錯方法展開設計,并通過對比實驗證明,本文設計的糾錯方法可以實現對所有錯誤數組的準確校正,而傳統方法僅能實現對錯誤數組的校正。
參考文獻:
[1] 文豐,雷武偉,劉東海.基于CY7B923/933的可糾錯HOTLink數據傳輸方案設計 [J].兵器裝備工程學報,2020,41(2):134-138.
[2] 李貴良,歐陽琴,唐標,等.基于反饋糾錯機制的數據遠程傳輸優化技術研究 [J].信息技術,2021(5):141-146+152.
[3] 肖文磊,鄒捷,馮江偉,等.基于貝葉斯糾錯的AR輔助飛機裝配數據糾錯方法 [J].航空制造技術,2020,63(6):14-22.
[4] 景文芳.嵌入式光網絡傳輸數據自動糾錯系統設計 [J].激光雜志,2020,41(1):181-184.
[5] 鄭穆,羅鐵威.一種用于光盤數據存儲的冗余恢復碼糾錯方法 [J].光電工程,2019,46(3):110-117.
[6] 寇馬可,鐘升,唐磊.一種基于小波變換的數據位迭代糾錯算法設計與Matlab實現 [J].微電子學與計算機,2019,36(6):60-63.
作者簡介:陳弓(1988—),男,漢族,江蘇南京人,工程師,學士,研究方向:測繪、地理信息系統、信息化。
猜你喜歡
現代礦業(2021年12期)2022-01-17 07:30:32
河北地質(2021年2期)2021-08-21 02:43:50
神劍(2021年3期)2021-08-14 02:30:08
昆鋼科技(2021年2期)2021-07-22 07:47:06
礦產勘查(2020年7期)2020-12-25 02:43:42
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
