基于CNN-GRU SA模型的短期電力負(fù)荷預(yù)測研究
2021-10-16 16:30:00葛夫勇雷景生
現(xiàn)代信息科技 2021年7期
葛夫勇 雷景生

摘要:為了解決預(yù)測模型無法充分挖掘特征等問題,提出一種基于CNN-GRU SA混合模型的短期電力負(fù)荷預(yù)測方法。通過CNN模型提取輸入數(shù)據(jù)的向量特征,利用雙層GRU模型學(xué)習(xí)輸入特征,掌握其特征規(guī)律,Self-attention機制充分挖掘輸入的特征信息,最后預(yù)測出負(fù)荷值。實驗采用英格蘭公開數(shù)據(jù)集,實驗結(jié)果表明,相較于CNN-GRU、GRU和CNN基線模型,該模型的預(yù)測精度更高,證明了該方法的有效性。
關(guān)鍵詞:電力負(fù)荷預(yù)測;CNN;GRU;Self-attention
中圖分類號:TM715? ? ? 文獻標(biāo)識碼:A? ? ? 文章編號:2096-4706(2021)07-0150-05
Research on Short Term Electric Load Forecasting Based on CNN-GRU SA Model
GE Fuyong,LEI Jingsheng
(Shanghai University of Electric Power,Shanghai? 200090,China)
Abstract:In order to solve the problem that the forecasting model can not fully mine features,a short term electric load forecasting method based on CNN-GRU SA hybrid model is proposed. The vector features of input data are extracted by CNN model,and the double layer GRU model is used to learn the input features and master the feature rules. The Self-attention mechanism fully mines the input feature information,and finally predicts the load value. The experiment is based on England? public data set,and the results show that compared with the CNN-GRU,GRU and CNN baseline models,the prediction accuracy of this model is higher,which proves the effectiveness of this method.
Keywords:electric load forecasting;CNN;GRU;Self-attention
收稿日期:2021-03-06
0? 引? 言
近年來,隨著智能電網(wǎng)、微電網(wǎng)等新興電網(wǎng)的出現(xiàn),人們對用電質(zhì)量的要求不斷提高。電力負(fù)荷精準(zhǔn)預(yù)測對提升用電質(zhì)量具有舉足輕重的作用。如何選擇一種負(fù)荷預(yù)測精準(zhǔn)度高的模型,成為一個重要課題,因此,筆者將深度學(xué)習(xí)方法應(yīng)用于負(fù)荷預(yù)測中,以提高電力負(fù)荷預(yù)測的精準(zhǔn)度。
電力負(fù)荷預(yù)測按照預(yù)測時間長短可分為短期、中期和長期,其中短期是預(yù)測未來一個小時的電力負(fù)荷值,中期是預(yù)測未來一個月的電力負(fù)荷值,長期是預(yù)測未來一年或更長時間的電力負(fù)荷值[1]。電力負(fù)荷預(yù)測是一個時間序列問題,由單變量或多變量要素組成[2]。如果僅將歷史電力負(fù)荷數(shù)據(jù)用作預(yù)測模型的輸入,則稱為單變量預(yù)測。在多變量預(yù)測中,其他因素也輸入預(yù)測模型中。這些因素本身可以是不同的時間序列,例如天氣屬性(溫度或濕度)、鄰近區(qū)域的負(fù)載數(shù)據(jù)、電力價格,甚至是經(jīng)濟數(shù)據(jù)(國內(nèi)生產(chǎn)總值(GDP))。就迄今為止所實施的大多數(shù)電力負(fù)荷預(yù)測模型而言,基本上采用多變量預(yù)測。
電力負(fù)荷預(yù)測方法大致分為三種,即傳統(tǒng)的統(tǒng)計方法、基于機器學(xué)習(xí)的方法和基于深度學(xué)習(xí)的方法[3]。傳統(tǒng)的統(tǒng)計方法是以時間序列為重復(fù)的固有模式,通過捕獲這些模式,可以預(yù)測未來電力負(fù)荷的變化趨勢。其中包括指數(shù)平滑法:最早通過采用單變量數(shù)據(jù)進行預(yù)測的方法之一。預(yù)測結(jié)果是過去觀測結(jié)果的加權(quán)總和,隨著觀測結(jié)果的增大,加權(quán)值會以指數(shù)形式變小。自回歸綜合移動平均模型(ARIMA):一個比指數(shù)平滑更復(fù)雜的模型,它可以通過遞歸方式以預(yù)測值作為模型的輸入來進行多步預(yù)測。但隨著預(yù)測步驟的增多,ARIMA的效果急劇下滑。這些統(tǒng)計方法對數(shù)據(jù)質(zhì)量具有較高的要求,對于受較多因素影響的數(shù)據(jù)表現(xiàn)為預(yù)測效果差、精度低。基于機器學(xué)習(xí)預(yù)測方法所涉及的開發(fā)模型,僅僅是通過用戶提供的數(shù)據(jù)進行學(xué)習(xí)。與統(tǒng)計方法不同,輸入輸出映射不一定是預(yù)定義的。在訓(xùn)練過程中學(xué)習(xí)其方法。例如多重線性回歸模型(Multiple Linear Regression,MLR)、支持矢量回歸(Support Vector Regression,SVR)[4]等。機器學(xué)習(xí)模型多為淺層模型,很難更深層次地去挖掘數(shù)據(jù)特征,又存在人為干擾問題,誤差較大,預(yù)測精度較差。近年來,深度學(xué)習(xí)方法在計算機視覺、自然語言處理等領(lǐng)域取得較好的成果,因此,這也成為負(fù)荷預(yù)測領(lǐng)域最新研究的方向,其中應(yīng)用較多的深度學(xué)習(xí)算法有人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Networks,ANN)、卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)和循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)等[5],CNN特別設(shè)計用于圖像、文本分類任務(wù)中,其中網(wǎng)絡(luò)接受二維數(shù)據(jù)。CNN用于時間序列分析,時間序列是一維數(shù)據(jù)。CNN具有權(quán)值共享和內(nèi)部連接的特點,在非線性問題上有較好的性能。RNN可以解決負(fù)荷預(yù)測時序問題,具有長期依賴性。GRU(Gated Recurrent Unit)是RNN的改進模型,解決了RNN梯度爆炸和消失問 題。文獻[6]為更好地挖掘數(shù)據(jù)中時序特征的聯(lián)系,提高負(fù)荷預(yù)測的精度,提出一種基于卷積神經(jīng)網(wǎng)絡(luò)和門控循環(huán)單元混合神經(jīng)網(wǎng)絡(luò)的負(fù)荷預(yù)測方法,實驗證明了該方法的有效性。深度學(xué)習(xí)算法中,Self-Attention機制屬于Transformer的主要功能單元[7],Self-Attention機制會產(chǎn)生一個向量,該向量在其鄰近向量上加權(quán)求和,其中權(quán)重是由數(shù)據(jù)之間關(guān)系決定的。
通過以上研究,本文提出一種基于CNN-GRU SA的短期電力負(fù)荷預(yù)測混合模型,利用CNN有效提取負(fù)荷數(shù)據(jù)的內(nèi)部相鄰高維特征,輸入到雙層GRU模型中,GRU動態(tài)提取特征規(guī)律,最后Self-Attention機制將輸入的特征向量合理地進行權(quán)重分配,更好地挖掘數(shù)據(jù)之間的聯(lián)系,精準(zhǔn)預(yù)測出負(fù)荷值,實驗表明,相較于其他的基線模型,該模型的負(fù)荷預(yù)測效果更好。
1? CNN-GRU SA混合模型
1.1? 卷積神經(jīng)網(wǎng)絡(luò)模型
CNN是深度學(xué)習(xí)領(lǐng)域的典型算法模型,其優(yōu)點是局部連接和共享權(quán)值,可以高效提取數(shù)據(jù)特征,其結(jié)構(gòu)一般是由卷積層、池化層和完全連接層組成。其中的關(guān)鍵部分是卷積層,卷積層中大小各異的卷積核可以提取輸入數(shù)據(jù)不同的相鄰特征關(guān)系。其卷積層具有權(quán)值共享的功能,這可使權(quán)值的數(shù)量減少,降低提取輸入數(shù)據(jù)特征的難度,使特征提取更加高效[8]。在卷積層之后,池化層運用掃描采樣對所獲取的特征圖進行建模,并將其轉(zhuǎn)換為隱藏層和存儲單元之間更為抽象的特征。池化層在降低數(shù)據(jù)維度的情況下,減少模型參數(shù)。最后通過全連接層將之前所有特征向量連接起來,一般采用ReLU函數(shù)來激活全連接層。其結(jié)構(gòu)如圖1所示。
1.2? GRU模型
RNN易產(chǎn)生梯度爆炸和消失的問題。梯度爆炸是循環(huán)神經(jīng)網(wǎng)絡(luò)所存在的一個問題,其中“長期”時序分量梯度的增長是“短期”時序分量梯度增長的幾倍。GRU和LSTM(Long Short Term Memory Network)是改進后的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)類型。與CNN不同,RNN具有向后連接的特點,以反饋方式極大地影響模型的精度,這些問題皆可由LSTM模型予以解決。在RNN的高級體系結(jié)構(gòu)中,是為了解決時序特征中長期依賴問題而采用的。LSTM的內(nèi)部由單元塊構(gòu)成。單元狀態(tài)和隱藏狀態(tài)從一個單元塊傳輸?shù)搅硪粋€單元塊,而內(nèi)存塊用于表達記憶門狀態(tài)。LSTM架構(gòu)包括三個門:輸入門、遺忘門和輸出門[9],而GRU只有兩個門:重置門和更新門。更新門用于檢查較早的單元內(nèi)存以保持當(dāng)前時間步的活動狀態(tài),重置門用于將下一個單元格的輸入序列與前面單元格的內(nèi)存組合在一起。然而,LSTM在某些方面有所不同,首先,GRU單元由兩個門組成,用以替代LSTM的三個門[10]。其次,將LSTM中的輸入門和遺忘門合并為更新門,并直接應(yīng)用于隱藏狀態(tài)的復(fù)位門中。GRU結(jié)構(gòu)如圖2所示。其中,×為矩陣乘積,σ為激活函數(shù)sigmod,?為激活函數(shù)tanh。
圖中輸入是xt,上一時刻狀態(tài)變量為ht-1,實時狀態(tài)變量為ht, 為實時候選集狀態(tài)。GRU單元的數(shù)學(xué)表達方程為:
rt=σ[Wr·(ht-1,xt)]? ? ? ? ? ? ? ? ? ? ? ? ? ?(1)
Zt=σ[Wz·(ht-1,xt)]? ? ? ? ? ? ? ? ? ? ? ? ? ?(2)
=?[·(rt·ht-1,xt)]? ? ? ? ? ? ? ? ? ? ? ? (3)
ht=(I-zt)·ht-1+zt·? ? ? ? ? ? ? ? ? ? ? ? ? (4)
其中,單位矩陣是I,Wr、Wz、 為GRU的各個權(quán)重參數(shù)。
1.3? Self-Attention模型
在傳統(tǒng)編碼器-解碼器網(wǎng)絡(luò)中,當(dāng)輸入序列很長時,很難獲得全部重要信息。注意機制打破了傳統(tǒng)編碼器-解碼器結(jié)構(gòu)的限制,使解碼器僅依賴于具有固定長度的矢量。注意機制是用以獲取相關(guān)信息的一種有效方法。一方面,它允許解碼器在解碼過程中的每一步查詢最相關(guān)的信息;另一方面,它大大縮短了信息流的距離。解碼器可以通過一步操作獲得任何時刻所需的所有信息。這些優(yōu)點的存在,使得注意機制已廣泛應(yīng)用于各種模型。Vaswani等人提出了Transformer模型[7],它摒棄了使用循環(huán)神經(jīng)網(wǎng)絡(luò)或卷積神經(jīng)網(wǎng)絡(luò)作為編碼器和解碼器的傳統(tǒng)方法,完全利用注意機制在不同的網(wǎng)絡(luò)層之間傳輸信息,稱為自我注意機制,在自然語言領(lǐng)域取得了良好的效果。
自我注意機制是用以計算相關(guān)性的一種方法。其結(jié)構(gòu)圖如圖3所示。可以理解為將名為Query的矩陣作為查詢對象,將名為Key的矩陣作為匹配對象,將名為Value的矩陣作為目標(biāo)。
查詢(Q)、鍵(K)和權(quán)值(V)可以從式(5)、式(6)和式(7)中獲得,它們是訓(xùn)練過程中的重要權(quán)值矩陣。首先,計算輸入向量的查詢與其他輸入向量(包括其本身)鍵值之間的相似度,將其作為權(quán)重。然后取一個加權(quán)平均值(包括其本身),得到自我注意輸出向量。總之,將輸入序列的每個向量與其他向量進行加權(quán)平均,融合所有的輸入信息生成新的向量,增強原始序列信息的表達。因此,自我注意力的輸出序列是輸入本身,但通過計算每個輸入向量與其他輸入向量之間的關(guān)系,可以增強原始信息的表達。此外,自我注意機制為了保持輸入信息空間特征向量之間的聯(lián)系,通過每個自我注意機制以線性組合的方式獲得最終輸出。
Q=X·WQ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(5)
K=X·WK? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(6)
V=X·WV? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (7)
自我注意機制中各個輸入序列之間的關(guān)聯(lián)度是通過以下步驟實現(xiàn)的。首先,通過點乘計算查詢與鍵的相似度,通過softmax函數(shù)獲得權(quán)值。然后,將權(quán)重加權(quán)到該值,得到自我注意的輸出向量。與注意機制略有不同,自我注意機制在計算時有一個附加的比例因子,當(dāng)內(nèi)部產(chǎn)品過大時可以避免重疊。通常,鍵的維度作為值。自我注意機制中計算方法可通過式(8)來表示[11]:
Attention(Q,K,V)=soft max()·V? ? ? (8)
1.4? CNN-GRU SA混合模型
基于CNN-GRU SA混合模型的負(fù)荷預(yù)測框架如圖4所示,其包含輸入層、CNN、GRU、Self-attention和輸出層。將之前的多變量一維數(shù)據(jù)輸入到CNN中。本文所用的CNN模型是選擇一個卷積層和一個池化層為一組,選取兩組進行特征提取,這樣可以充分提取歷史時間序列中的特征,并通過池化層得到最大特征向量。進行兩組卷積和池化操作提取的特征更徹底,將提取出的最大特征向量輸入到連接層進行權(quán)值分配,以獲取更優(yōu)的數(shù)據(jù)特征。GRU對CNN輸出的特征進行迭代學(xué)習(xí),更好地學(xué)習(xí)特征內(nèi)部規(guī)律,獲取特征之間的長期依賴關(guān)系,并能減少訓(xùn)練時間,由于負(fù)荷數(shù)據(jù)為時間序列,其數(shù)據(jù)序列距離過長,GRU模型在學(xué)習(xí)訓(xùn)練過程中也會造成部分信息丟失,不能全面學(xué)習(xí)整個時間序列數(shù)據(jù),以致降低預(yù)測精準(zhǔn)度。Self-attention模型輸出序列是輸入本身,通過計算每個輸入向量與其他輸入向量之間的關(guān)系,分配不同的權(quán)重因子,由于不是按照時間序列去計算,因此可以通過不同位置信息進行學(xué)習(xí)。在長距離依賴上,由于Self-attention是每個數(shù)據(jù)都要計算attention,不管他們之間的距離有多長,最大的路徑長度也都只有1,因此可以捕獲長距離依賴關(guān)系。因此,基于CNN-GRU SA電力負(fù)荷預(yù)測模型,通過多個模型的融合,對歷史數(shù)據(jù)進行全面深入的挖掘,以獲得更好的負(fù)荷預(yù)測效果。
2? 實驗與結(jié)果分析
2.1? 實驗數(shù)據(jù)集與預(yù)處理
實驗數(shù)據(jù)來自ISO-NE上進行了區(qū)域/系統(tǒng)級負(fù)載預(yù)測案例研究的負(fù)荷數(shù)據(jù)集。ISO-NE是一個獨立的區(qū)域輸電組織(RTO),服務(wù)于新英格蘭六個州,本實驗選用新英格蘭某一個州2014年1月1日至2015年12月31日2年內(nèi)的負(fù)荷數(shù)據(jù),一天采集24個負(fù)荷點。其中抽取歷史數(shù)據(jù)中的日期、溫度以及負(fù)荷值作為實驗數(shù)據(jù),按8:2的比例將其劃分為訓(xùn)練集和測試集。
數(shù)據(jù)集中缺失的數(shù)據(jù)用之前相同日期的數(shù)據(jù)來代替,數(shù)據(jù)異常問題可通過水平和垂直處理法進行修正,從而使預(yù)測結(jié)果更加精準(zhǔn)。由于數(shù)據(jù)集中的數(shù)據(jù)單位不同,無法進行同一量綱處理,因此對數(shù)據(jù)進行歸一化處理:
xn=? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(9)
其中,x為歷史負(fù)荷數(shù)據(jù),xmax為歷史負(fù)荷數(shù)據(jù)最大值,xmin為歷史負(fù)荷數(shù)據(jù)最小值。將數(shù)據(jù)值歸一到[0,1]中。
2.2? 實驗評價標(biāo)準(zhǔn)
本實驗采用平均絕對誤差(Mean Absolute Error,MAE)、平均絕對百分比誤差(Mean Absolute Percentage Error,MAPE)和均方根誤差(Root Mean Square Error,RMSE)為實驗結(jié)果評價指標(biāo),計算公式為:
MAE=? ? ? ? ? ? ? ? ? ? ? ? ? (10)
MAPE=? ? ? ? ? ? ? ? ? ? ? ? (11)
RMSE=? ? ? ? ? ? ? ? ? ? (12)
其中,為預(yù)測值,yi為真實值,MAE利用預(yù)測值和真實值的絕對平均值去判斷,MAE、MAPE是判斷模型預(yù)測的好壞,RMSE是判斷模型預(yù)測的精度,這些判斷指標(biāo)值越小越好。
2.3? 實驗環(huán)境
本實驗環(huán)境配置如表1所示。
2.4? 模型介紹和預(yù)測結(jié)果分析
本文所選的基線模型為CNN、GRU和CNN-GRU混合模型,其中,CNN選擇兩層卷積層和池化層,卷積深度為32和64,卷積核的尺寸為2×2×2×32與2×2×2×64,卷積步長為1,激活函數(shù)為ReLU。GRU的神經(jīng)單位數(shù)量為64、32。
表2是選取測試集中三個月的預(yù)測誤差結(jié)果,不同月份的預(yù)測精度因受本月氣候、節(jié)假日等因素的影響也會有所不同,由表2可知CNN-GRU SA模型MAE最低為75.33、最高為76.31;MAPE最低為0.026 3,最高為0.031 2;RMSE最低為94.11,最高為97.78。CNN-GRU SA模型MAE、MAPE、RMSE誤差指標(biāo)較其他模型更低,預(yù)測更加準(zhǔn)確。其中Self-attention機制具有更長期依賴和不按順序進行權(quán)重因子分配的特點,對提升CNN-GRU SA模型的精度起到關(guān)鍵作用。
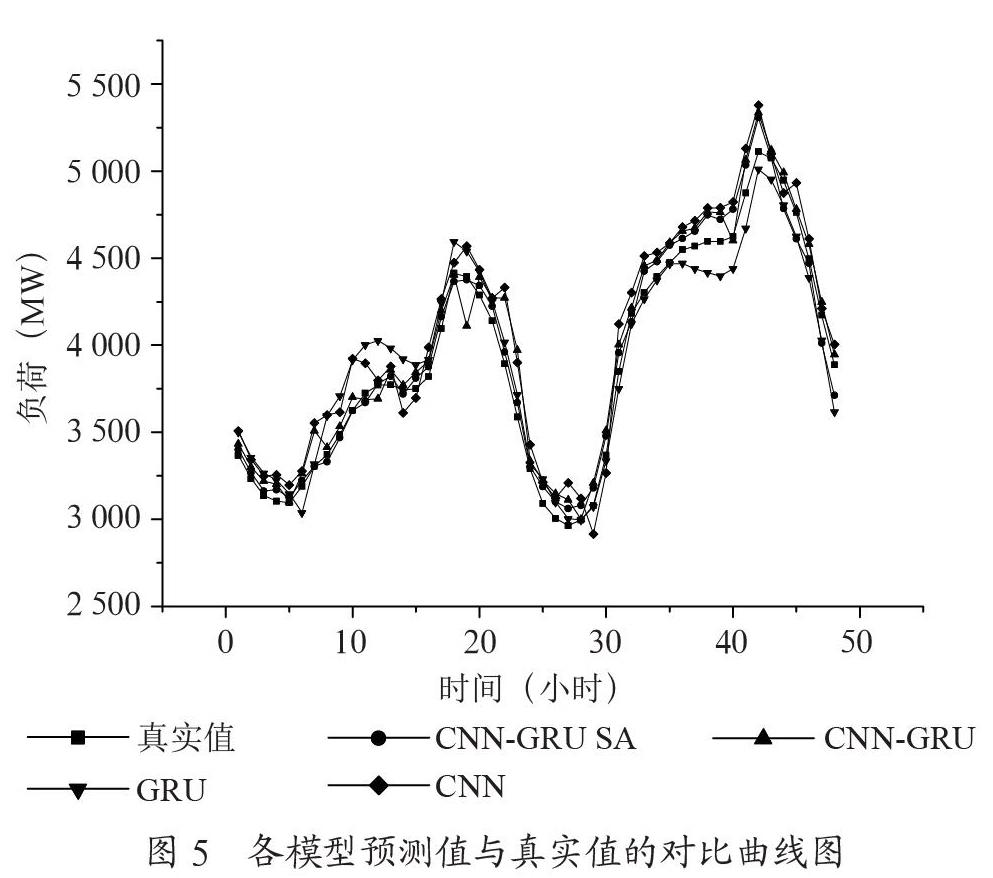
為了更加直觀地了解各模型短期預(yù)測值與真實值之間的差別情況,選取新英格蘭某州2015年10月中某兩天的數(shù)據(jù)為研究對象,以小時為單位,對48個預(yù)測點進行對比,如圖5所示,一天中1:00~6:00為負(fù)荷低谷期,16:00~22:00為負(fù)荷高峰期,這兩個階段,負(fù)荷變化幅度較大,各模型在此時的預(yù)測精度相較于其他時間段的精度要低一些,其中CNN-GRU SA模型在這兩個時刻的預(yù)測值更接近真實值,比其他模型更精準(zhǔn),其中CNN模型的預(yù)測精度最差。其他時刻CNN-GRU SA模型的預(yù)測值也更靠近真實值,通過觀察48小時負(fù)荷預(yù)測曲線,可以看出本文提出的CNN-GRU SA模型的預(yù)測值相較于其他模型的預(yù)測值,整體上更加平穩(wěn),更靠近真實值。
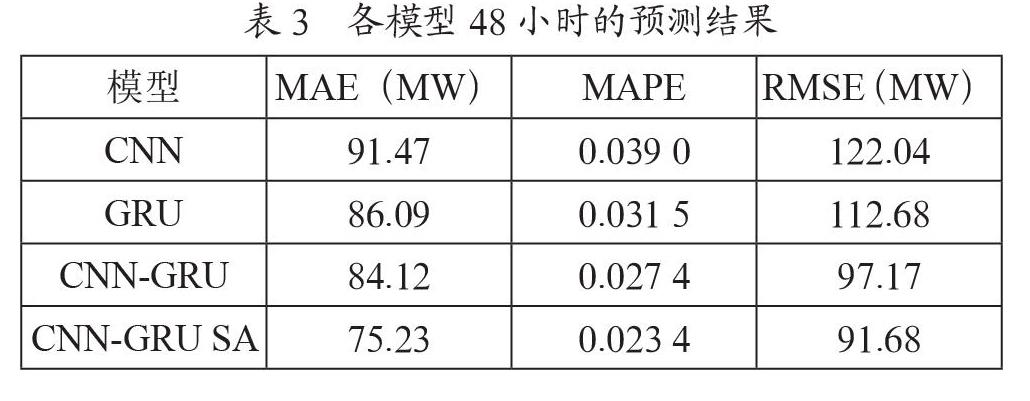
表3是由圖5計算出來的預(yù)測結(jié)果,由表3可知,CNN-GRU SA模型MAE值為75.23、MAPE值為0.023 4、RMSE值為91.68,較CNN-CRU基線模型分別降低了8.89、0.004和5.49;較GRU基線模型分別降低了10.86、0.008 1和21;較CNN基線模型分別降低了16.24、0.015 6和30.36,可以看出在48小時實驗數(shù)據(jù)負(fù)荷預(yù)測中,CNN-GRU SA模型各個預(yù)測誤差指標(biāo)都比其他模型小,預(yù)測精度更高。
3? 結(jié)? 論
本文提出一種基于CNN-GRU SA混合模型的負(fù)荷短期預(yù)測方法,采用英格蘭某州公開的數(shù)據(jù)集,其中包含負(fù)荷、日期和氣候數(shù)據(jù),先通過改進后的CNN模型進行特征提取,雙層GRU對輸入特征做進一步的特征提取,最后通過Self-attention機制對GRU輸出的特征按不同權(quán)重進行配置,并根據(jù)順序序列進行計算,充分提取出不同位置的重要信息,獲得更長期依賴的特征,最后預(yù)測出更接近真實數(shù)據(jù)的負(fù)荷值。實驗結(jié)果表明,本文提出的CNN-GRU SA模型較其他基線模型的預(yù)測誤差更小,預(yù)測精度更好。接下來的工作是研究Self-attention機制,改進或結(jié)合其他模型,對公開數(shù)據(jù)集進行測試,以開發(fā)出預(yù)測效果更好的負(fù)荷預(yù)測模型。
參考文獻:
[1] 洪發(fā).基于深度學(xué)習(xí)的短期電力負(fù)荷預(yù)測方法 [D].廣州:廣東工業(yè)大學(xué),2020.
[2] 王文卿.基于卷積神經(jīng)網(wǎng)絡(luò)的電力系統(tǒng)短期負(fù)荷預(yù)測研究 [D].青島:青島大學(xué),2020.
[3] 康重慶,夏清,張伯明.電力系統(tǒng)負(fù)荷預(yù)測研究綜述與發(fā)展方向的探討 [J].電力系統(tǒng)自動化,2004(17):1-11.
[4] 翟永杰,王靜嫻,周黎輝.基于模糊支持向量機的電力系統(tǒng)中期負(fù)荷預(yù)測 [J].華北電力大學(xué)學(xué)報(自然科學(xué)版),2008(2):70-73.
[5] 姚棟方,吳瀛,羅磊,等.基于深度學(xué)習(xí)的短期電力負(fù)荷預(yù)測 [J].國外電子測量技術(shù),2020,39(1):44-48.
[6] 姚程文,楊蘋,劉澤健.基于CNN-GRU混合神經(jīng)網(wǎng)絡(luò)的負(fù)荷預(yù)測方法 [J].電網(wǎng)技術(shù),2020,44(9):3416-3424.
[7] VASWANI A,NOAM S,PARMAR N,et al. Attention is all you need [C]//NIPS17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Red Hook:Curran Associates,2017:6000-6010.
[8] 陸繼翔,張琪培,楊志宏,等.基于CNN-LSTM混合神經(jīng)網(wǎng)絡(luò)模型的短期負(fù)荷預(yù)測方法 [J].電力系統(tǒng)自動化,2019,43(8):131-137.
[9] 王永志,劉博,李鈺.一種基于LSTM神經(jīng)網(wǎng)絡(luò)的電力負(fù)荷預(yù)測方法 [J].實驗室研究與探索,2020,39(5):41-45.
[10] 鄧帶雨,李堅,張真源,等.基于EEMD-GRU-MLR的短期電力負(fù)荷預(yù)測 [J].電網(wǎng)技術(shù),2020,44(2):593-602.
[11] 閆雄,段躍興,張澤華.采用自注意力機制和CNN融合的實體關(guān)系抽取 [J].計算機工程與科學(xué),2020,42(11):2059-2066.
作者簡介:葛夫勇(1994—),男,漢族,江蘇徐州人,碩士研究生在讀,研究方向:電力大數(shù)據(jù);雷景生(1966—),男,漢族,陜西韓城人,教授,博士,研究方向:人工智能、電力大數(shù)據(jù)。
