
基于多類型池化卷積神經網絡的文本分類
2021-10-18 09:47:26張菊玲楊曉梅
無線互聯科技 2021年16期
關鍵詞:特征提取
張菊玲 楊曉梅

摘 要:為了解決傳統的基于機器學習方法的文本分類耗時耗力、不具備通用性、效果不好的問題及提高短文本分類的效果,文章提出了一種基于多類型池化的卷積神經網絡分類方法。文章首先使用CNN(卷積神經網絡)提取短文本的特征信息,然后利用多種類型的池化操作對提取的特征信息進行篩選,得到最終的分類依據。通過實驗表明,文章提出的方法在短文本分類上要優于其他CNN分類模型和一些傳統的機器學習方法。
關鍵詞:自然語言處理;文本分類;卷積神經網絡;特征提取;池化操作
0 引言
文本分類問題是自然語言處理領域中一個非常經典的問題,也是實際應用中管理文本信息的一種重要方法,并在信息過濾、信息組織管理、文本信息異常檢測、語義辨析和情感分析等領域得到廣泛的應用和發展。本文提出一種基于多類型池化的卷積神經網絡模型對短文本進行分類,實驗結果表明,基于多類型池化的神經網絡結構在短文本分類上表現效果良好。
1 卷積神經網絡
卷積神經網絡(Convolutional Neural Network,CNN)是一種前饋神經網絡,它是一種深度學習的經典方法。一般的,CNN的基本結構包括3種類型的網絡層:卷積層、激活函數層、池化層。卷積層是CNN中必不可少的一種網絡層,是構成卷積神經網絡的基本框架。在視覺中,卷積層的輸入一般是一個二維的張量I,相應的,在張量I上進行卷積操作就需要一個二維的卷積核K,設m和n分別為卷積核的長和寬,且卷積核一般小于輸入張量大小,每個卷積核的參數在訓練過程中都是通過BP算法[1]優化得到的。卷積運算是一種特殊的矩陣乘法運算,通過公式(1)或公式(2)的卷積運算得到包含數據信息的特征圖S。
(1)
(2)
由于m和n的有效取值范圍比較小,故一般采用公式(2)的實現方式。
激活函數層主要用來引入非線性因素,常用的激活函數有ReLU函數[2]、Tanh函數等。激活函數中線性整流單元ReLU是最常用的,其數學公式見公式(3)。
(3)
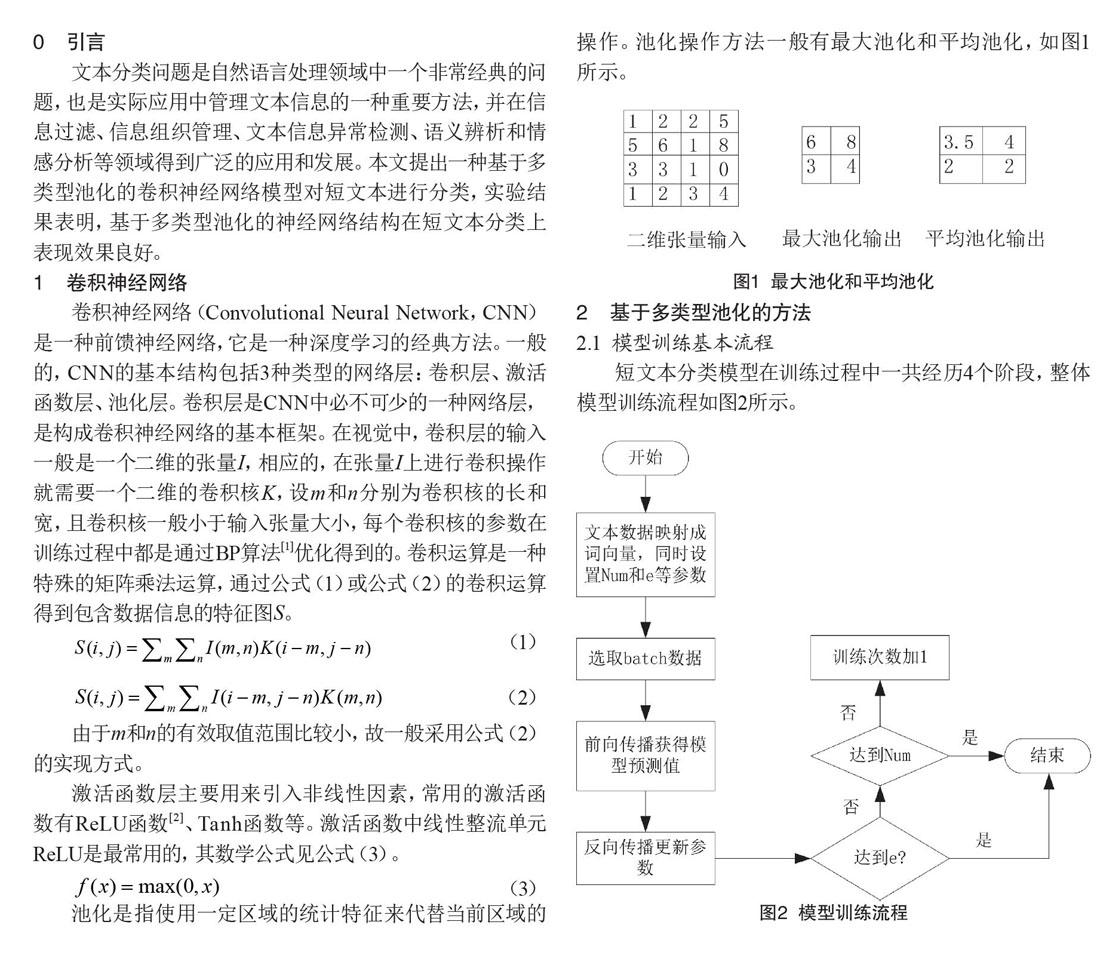
池化是指使用一定區域的統計特征來代替當前區域的操作。池化操作方法一般有最大池化和平均池化,如圖1所示。
2 基于多類型池化的方法
2.1 模型訓練基本流程
短文本分類模型在訓練過程中一共經歷4個階段,整體模型訓練流程如圖2所示。
首先設置訓練迭代次數Num和訓練目標e;每次迭代開始,選取一小部分訓練數據通過詞向量矩陣映射成連續稠密的連續詞向量數組;再將數據傳入卷積神經網絡層,進行特征提取、組合和特征篩選,得到模型的預測結果;再進行反向傳播算法,更新相應的神經網絡參數,訓練次數加1,判斷訓練次數是否達到總訓練次數Num或目標是否達到e。如果上述兩個條件都沒有達到就繼續進行模型訓練,否則模型訓練結束。
2.2 詞向量
進行文本分類時,得到的數據是由多個單詞所組成的多個語句。顯然這樣的數據不能直接拿來使用,必須要對它們進行處理。傳統的做法是使用one-hot編碼[3]來對每個句子進行編碼,假設詞典的大小為vocab_size,文本中出現的每個詞都在詞典中,其中第i個詞用向量x=[0,0, … ,0,1,0, … ,0]表示,向量x中第i位為1,其余位全為0,用one-hot編碼表示文本很簡單。
如公式(4)所示,word為文本單詞,v為詞向量化后所對應的詞向量,d為向量v的維數:
(4)
2.3 多尺寸卷積
設卷積前的輸入為xi(i=1,2,…,n),卷積核權重為wj(j=1,2,…,k),卷積輸出為yj(l=1,2,…,m),L為對應的損失函數,卷積可以分為前向傳播和后向傳播兩個過程,如公式(5)和(6)所示。
(5)
(6)
本文引入多尺寸的卷積核,在進行短文本的卷積時,可以捕獲更多的文本信息。
2.4 多類型池化
卷積層提取到對應的特征信息后,需要對這些特征信息進一步篩選。本文使用多種類型的池化操作對特征信息篩選。
設池化前的輸入是xi(i=1,2,…,n),池化核權重是wj(j=1,2,…,k),池化輸出是yl(l=1,2,…,m),由公式(7)計算池化輸出。
yj=max(wj×xi)(7)
池化層的作用是固定句子長度和特征篩選,多類型池化操作如圖3所示。
3 實驗結果
本文使用上述方法進行了TREC數據分類,基本學習率lr=0.025,衰減系數=0.95。本文使用stop-early的優化技巧,防止模型訓練的過擬合。本研究設置了一組對比實驗,只使用最大池化方式訓練的模型Only-maxPooling,只使用平均池化方式訓練的模型Only-argPooling和多類型池化方式Multi-typePool(見圖3)。
TREC數據集涉及6類不同的問題類型,訓練數據集包含 5 452條帶標簽問題,同時包含500條測試問題數據。在該數據集上,各個模型表現效果如表1所示。
從實驗結果可以看出,本文所提出的模型在TREC數據集上的表現效果要優于其他的網絡模型。
4 結語
本文所提出的基于多類型池化的卷積神經網絡結構在短文本分類上相對于其他CNN系網絡結構和傳統機器學習方法來說優勢明顯。下一步可以對數據集和詞向量進行操作。
[參考文獻]
[1]JAAFAR H, RAMLI N H, NASIR A S A. An improvement to the k-nearest neighbor classifier for ECG database[J].IOP Conference Series Materials Science and Engineering,2018(1):12046.
[2]LI X,GUO Y. Active learning with Multi-Label SVM classi?cation[C]//Beijing:Proceedings of Twenty-Third International Joint Conference on Artificial Intelligence,2013.
[3]ASADI R,REGAN A. A spatial-temporal decomposition based deep neural network for time series forecasting[EB/OL].(2014-11-28)[2018-10-20].https://arxiv.org/pdf/1902.00636.
(編輯?王永超)
Text classification based on multi-type pooling convolution neural network
Zhang Juling, Yang Xiaomei
(School of Information Management, Xinjiang University of Finance and Economics, Urumqi 830000, China)
Abstract:To solve the problems of traditional text classification based on machine learning method, such as time consuming, labor consuming, lack of generality and poor effect, and to improve the effect of short text classification, a CNN(Convolution Neural Network)classification method based on multi-type pooling was proposed. Firstly, CNN is used to extract the feature information of the short text, and then various types of pooling operations are used to screen the extracted feature information to obtain the final classification basis. Experiments show that the short text classification in this paper is superior to other CNN classification models and some traditional machine learning methods.
Key words:natural language processing; text classification; convolutional neural network; feature extraction; pooling operation
基金項目:新疆自然科學基金項目;項目編號:2019D01A27。新疆財經大學校級一般項目;項目編號:2019XYB005。
作者簡介:張菊玲(1977— ),女,四川簡陽人,副教授,博士;研究方向:大數據,邏輯綜合,信息安全風險評估。
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
