高性能流場并行粒子追蹤數據管理系統
2021-10-20 02:27:24楊昌和李彥達張江王昉袁曉如
航空學報 2021年9期
楊昌和,李彥達,張江,王昉,袁曉如,*
1.北京大學 信息科學技術學院 機器感知與智能教育部重點實驗室,北京 100871
2.北京大學 大數據分析與應用技術國家工程實驗室,北京 100871
3. 北京大學,北京 100871
4. 中國空氣動力研究與發展中心 計算空氣動力研究所,綿陽 621000
隨著科學、工程、生物醫學等領域的不斷發展,研究者們往往需要面對大量基于模擬和觀測的科學數據,尤其在空氣動力學領域,需要從中發現有意義的規律。科學數據包括標量場數據和矢量場數據,通常具有時變、多變量等特性,且體量龐大,特征復雜多變,因而用戶直接對于數據本身進行演算和觀測十分困難,需要十分龐大的理解代價。在此背景下,科學可視化方法應運而生。科學可視化是可視化研究領域中十分重要的組成部分,該技術賦予了科學數據具體又可操作的直觀形態,幫助科學家們在圖形世界中直接對信息進行操作和處理,賦予科學家們一種仿真的實時交互能力。科學家們通過對數據進行有效的可視化并分析出其中存在的特征,從而解釋現象或者驗證假設。
流場可視化是科學可視化中的重要組成部分,能夠有效地幫助人們理解現實世界流場數據的復雜現象和動態演變的復雜現象和動態演變,是近年來科學研究中的重點問題,被廣泛應用于燃燒、氣候、航空等科學模擬和分析。國家數值風洞(NNW)工程[1]針對該方面進行了深入的研究。流場數據可視化方法可以分為4類,即直接可視化方法、基于紋理的可視化方法[2]、基于幾何的可視化方法[3]以及特征提取方法[4]。其中,直接可視化和基于紋理的可視化方法分別通過使用箭頭等符號形式和條紋狀紋理來表示流場,基于幾何的可視化方法使用點線面等幾何形式對流場進行可視化,特征提取方法則通過提取流場中的重要特征對流場進行探索。在這些方法中,通過粒子追蹤生成場線又是一種最基本的技術,其在各種各樣的流場可視化和分析任務,特別是基于幾何和特征提取的可視化方法中,得到了廣泛的應用。
隨著科學家通過計算流體學(CFD)等數值模擬方法得到的流場數據愈加復雜多變,傳統的流場可視化方法遇到了越來越多的挑戰,先進的流場可視化系統的提出成為了十分迫切的需求。縱觀流場可視化框架的發展方向,該工作總結出如下兩個趨勢。一方面,科學家通過數值模擬等方式得到的流場數據規模越來越大,其內部結構也越來越復雜,甚至以幾何級數的速度增長,這給流場可視化的計算性能提出了新的考驗。現實應用中單臺處理機由于內存和計算能力等的限制,很難滿足這種大規模粒子追蹤的計算需求。而早前研究者所使用的核外(Out-of-core)技術[5-6],也因其I/O瓶頸在大規模流場數據中變得越來越不適用。研究者們考慮粒子追蹤生成場線中任務的高度可并行性,采用并行計算模式提升性能,成為了一種十分行之有效的解決方案,基于并行粒子追蹤的大規模場線可視化逐漸成為流場可視化的主流趨勢。尤其是近年來隨著高性能計算技術的發展,研究者可以更多地利用超級計算機或者并行計算集群等強大的計算資源來進行并行計算,有效地提升了計算結果產出的效率。另一方面,流場本身相關的分析任務也呈現出越來越復雜的趨勢,這給流場可視化技術提出了新的設計要求。例如在一些諸如線積分卷積[7-8]、基于有限時間李雅普諾夫指數計算的拉格朗日擬序結構提取[9-10]以及流場曲面計算[11]、源匯查詢[12]等基于場線的應用中,需要進行復雜的粒子追蹤計算,也引發了更加復雜多變的數據分析任務。
然而,當下的流場可視化系統框架下仍然存在一些問題。首先,基于并行粒子追蹤性能優化的大規模流場可視化引發了新的困難和問題討論。具體地說,即傳統并行計算框架下的任務優化和數據管理策略如何較好地遷移至流場可視化應用中。例如,在并行計算的過程中,負載均衡問題顯得尤為重要,需要設計精細的任務分配和調度策略,每個計算節點都始終被分配有較為均衡的任務量,才能最大化地利用計算資源,達到效率的最優化。但是,粒子追蹤的并行化本身存在著粒子的運行時間和軌跡難以預測的復雜問題,對粒子的初始劃分很難保證進程的負載均衡,需要合理而精細的預估模型。其次,現有的流場可視化系統下,粒子追蹤過程對于用戶難以理解和干預,因而對于已有算法難以進行評估、校驗和診斷優化,這也對新方法的試驗、應用帶來了一定困難。用戶對于粒子追蹤的過程難以顯示地獲得理解,難以獲取過程中數據塊、任務調度和進程負載變化等核心信息,這使得占據整個流場可視化應用中巨大時間、存儲消耗的過程難以進行合理地優化。流場可視化系統同樣需要對這一過程采用系統化的可視化技術動態展現,提升系統運行效率,以增加流場可視化系統的可用性。
針對這些問題,結合在流場可視化領域的研究、應用和實踐,本文研究團隊主導設計并開發了高性能流場并行粒子追蹤數據管理系統,幫助領域用戶使用最新發展的可視化方法和技術理解、分析和探索流場數據,同時促進可視化和領域研究的發展。和現有的可視化系統相比,本文研究的系統關注于采用先進科學的并行數據管理方法提升流場可視化應用中粒子追蹤的效率,同時支持先進的流場數據可視化算法的診斷和分析,能夠有效地應用于不同的流場數據,并廣泛地支持流場中的分析任務。
1 相關工作概述
在科學可視化針對大規模流場的可視化任務中,基于粒子追蹤的流場可視化需要從原始數據出發生成場線。流場可視化粒子追蹤的計算過程十分復雜,涉及大量的數據讀取訪問、密集型積分計算。而通過采用并行計算的模式,將工作負載分布到成百上千上萬甚至更多的計算節點單元,由這些節點單元協作計算大規模粒子的軌跡,粒子追蹤的效率會大大提高。這也使得并行粒子追蹤成為了目前基于場線的大規模流場可視化的主流趨勢。其主要工作流程包括基于分析任務需要生成初始粒子的分布和基于初始粒子分布進行積分跡線生成。初始粒子的數目由流場規模、局部特征和性能的平衡綜合決定。針對大規模流場數據可視化的并行粒子追蹤方法主要分為兩類,即任務并行和數據并行。最近也有一些將兩者進行結合的并行方法,即混合并行方法。不同類別的并行計算方式如下:
1) 任務并行:初始粒子種子被靜態劃分為若干組并被分配給不同的進程,每個進程負責其所分配到的粒子的追蹤計算。
2) 數據并行:流場數據被靜態劃分為若干數據塊并分配給不同的進程,每個進程負責在其所分配到的數據塊內進行粒子追蹤計算。
基于不同類別的并行計算策略,多種先進的數據管理策略被應用以提升計算效率,包括數據預取策略、負載均衡化策略和數據約減策略等。已有工作中主要關注于如何使用有效的數據劃分、分配和移動等數據管理策略,盡量使進程負載均衡并減小通信和I/O等方面的開銷,優化數據訪問性能,以下部分將簡述已有工作中針對不同并行計算策略采取的數據管理優化策略。
1.1 任務并行的粒子追蹤算法中的數據管理策略
任務并行的粒子追蹤算法將每個粒子的追蹤計算看成是一個任務,其在初始時將所有種子靜態地分配給所有的進程,同時在粒子追蹤過程中由進程按需載入數據。為了保證負載均衡性,任務并行算法需要在初始時給每個進程預估并分配較為均衡的負載,或者在多輪運行的過程中實現動態任務重分配。在已有方法中,動態任務重分配主要通過工作竊取(Work Stealing)、工作請求(Work Requesting)或者k-d樹分解來完成。工作竊取是一種常見的動態平衡負載方法,其原理是當某一個工作進程(稱為竊取進程)完成所負責的任務時,會從其他繁忙進程(稱為被竊取進程)處“偷取”一部分任務給自己執行。竊取目標的選擇可以基于隨機選擇[13],然后從被竊取進程的任務隊列末端開始轉移任務,該方法被證明具有良好的效率[14]。Pugmire等[15]提出一種基于主-輔(Master-slave)模式的混合調度方法,也是基于這個思想。Lu等[16]針對流面計算也使用了工作竊取來平衡動態過程中的任務負載。Müller等[17]提出了一種類似工作竊取的方法,稱作工作請求,該方法會帶來更多的通信,但是更易于實現,更適合于分布式內存系統。基于k-d樹分解的負載均衡思想被成功地運用到了針對Delaunay曲面細分(Delaunay Tessellation)的負載平衡中[18]。Zhang等提出了一種新穎的基于帶有約束的k-d樹分解的方法[19],可以在可用內存限制下盡量對未完成粒子進行重分配。
任務并行的粒子追蹤算法中通常采用按需載入的數據訪問策略,I/O問題是制約并行粒子追蹤計算性能的一個非常重要的瓶頸。數據預取的思想是在載入所需要的數據時,將之后粒子追蹤可能訪問到的數據也一并提前載入,這樣可以降低I/O操作次數,減少進程因為數據不在內存中而必須等待的時間。早在2005年,Rhodes等[20]就將訪問模式作為先驗知識,使用緩存和預取機制來動態提高I/O性能。近年來,俄亥俄州立大學的可視化小組針對流場可視化中流線和跡線等的計算,提出了一系列基于數據訪問依賴的數據預取方法[21-22]。在預處理階段,他們將數據劃分為小塊形式,然后根據粒子追蹤的數據訪問關系生成數據塊之間的訪問依賴圖。需要注意的是,數據預取應該適度進行,過度的預取不僅會降低預測的準確性,還會飽和系統的帶寬[23],造成適得其反的效果。
1.2 數據并行的粒子追蹤算法中的數據管理策略
數據并行的粒子追蹤算法在初始時將整個數據劃分為若干數據塊,并將這些數據塊分配給各個進程。在粒子追蹤的過程中,當粒子離開對應進程負責的數據塊時,會被發送給目標數據塊對應的進程繼續追蹤計算。一般情況下,該方法假設數據可以被所有進程一次性載入到內存中,所以具有較小的I/O開銷。但由于需要頻繁地在進程之間交換粒子,密集的通信帶來的耗費對性能也具有較大的影響。相關的數據管理策略主要包括兩類:靜態負載平衡方法(例如根據某些劃分規則的數據靜態分配策略)以及動態負載平衡方法。
一種最直接的靜態數據劃分方法為規則數據劃分,其中最直接的劃分方法是靜態輪轉(Round-robin)法[24]。對于n個進程和m個數據塊,該方法中第i個進程被分配到編號為i,i+m/n,i+2m/n,…的這些數據塊。輪轉法可以確保每個進程被分到空間位置不連續的相等數量的數據塊。該方法的一個典型應用是在Nouanesengsy等[25]提出的基于有限時間李雅普諾夫指數(Finite-Time Lyapunov Exponents,FTLE)計算方法中。為了更進一步地解決負載不平衡的瓶頸, Nouanesengsy等[26]提出了一種負載感知的方法,即靜態評估每個數據塊的負載,并據此對數據塊進行分配。該方法允許同一數據塊被重復分配給多個進程,每個進程只負責重復數據塊中一部分的粒子追蹤工作量,但總的負載比較均等。另一類數據劃分方法即不規則的數據劃分。Chen和Fujishiro[27]提出了一種根據流場方向的數據劃分方法,考慮了種子的分布和諸如漩渦等流場的局部特征。另一種不規則的劃分是利用層次聚類進行自適應網格區域劃分[28]。數據首先被分解成單位網格,即最小的簇,然后具有類似模式的相鄰網格會被兩兩合并,自下而上迭代地形成二叉樹的層次結構。
在動態負載平衡優化算法中,Peterka等[24]提出了一種基于遞歸坐標二分(Recursive Coordinate Bisection, RCB)[29]動態數據重劃分方法。在他們的方法中,每個數據塊中追蹤的積分步數被記錄為其歷史負載,這種歷史負載信息被用做數據重劃分的依據。該方法的理論假設是,相鄰時間步相同空間位置上每個數據塊的負載可以認為是相似的。因此在數據重劃分后,進程可以被重新分配到負載近似相等的數據塊,然后在下一階段進行計算。這里數據重劃分通過RCB算法[29]實現。除了RCB,類似的算法包括遞歸慣性二分(Recursive Inertial Bisection, RIB)[30]以及基于圖拓撲的劃分[31-32]。
2 系統特性和功能設計支持
高性能流場并行粒子追蹤數據管理系統具有以下特性:
1) 對于數據的支持
系統支持定義在線性網格上的二維、三維定常和時變的矢量場數據形式,并支持多種不同的常見數據格式,例如NetCDF、HDF5以及系統定義的XML數據描述等。系統提供不同體量的撒種規模,支持遠超內存量的流場數據。系統支持多種典型的流場數據分析,包括Geos5全球風場數據、Isabel颶風數據、Nek5000熱力水工數據等。
2) 對于常用分析任務的支持
系統支持流場數據的通用分析任務,包括流場中源匯查詢、線積分卷積、基于有限時間李雅普諾夫指數計算的拉格朗日擬序結構提取、流場曲面計算等典型分析任務,為流場數據分析提供有力的支持。
3) 對于高性能的支持
系統支持高性能的流場可視化應用,支持針對大規模數據和任務,能夠在不同的計算平臺上針對并行粒子追蹤算法進行并行計算效率加速。
4) 對于高可擴展性的支持
該系統在小型并行集群及超算平臺上均具有良好的適應性,能夠支持高度可擴展的并行加速,最高對于1 K核規模的并行集群仍然表現出良好的可擴展性。
5) 對于可視分析進行性能診斷方法的支持
系統支持對于先進的粒子追蹤算法性能數據的可視分析技術,能夠針對算法在運行過程中的數據、任務交換的行為模式進行比較和分析,幫助用戶深入理解該復雜的計算過程。同時支持定位并行粒子追蹤算法在計算過程中的性能桎梏,尤其針對負載不平衡的原因的探究,實現對于算法性能的診斷,以幫助專家學者進一步優化和改良已有的算法。
3 系統軟件架構與實現
3.1 系統概覽
高性能流場并行粒子追蹤數據管理系統的整體工作流水線如圖1所示。該系統支持的計算和操作流程依據其部署的不同操作平臺和計算任務目標可拆分為在超算平臺與本地平臺運行的兩個相互分離的階段,共同支持大規模流場數據可視化的構建和優化分析。
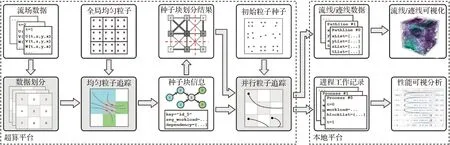
圖1 高性能流場并行粒子追蹤數據管理系統工作流水線 Fig.1 Workflow of high-performance flow parallel particle tracing data management system
部署在超算平臺上的高性能流場并行粒子追蹤數據管理系統主要支持高性能流場并行粒子追蹤算法的實現和基于大規模科學數據管理的優化策略。該過程中,系統根據用戶設定的分析任務目標和撒種初始化,使用一些諸如四階龍格-庫塔(Fourth-order Runge-Kutta, RK4)等數值積分算法計算追蹤這些粒子在流場中的運行軌跡。為了進一步提升計算效率,系統關注于粒子積分算法中固有的天然可并行性,采用多進程并行優化計算的方式提升計算的效率,以適應粒子追蹤本身的計算復雜性帶來的挑戰。引入并行計算機制在潛在提升計算效率的同時,使得算法具有更加復雜的流程,也使得負載均衡問題成為效率提升的關鍵所在。由于并行粒子追蹤問題中,粒子的軌跡和粒子的運行時間難以預測,如何預估不同計算進程的負載情況,合理設計和實現負載均衡算法成為了十分重要的問題。而隨著大規模流場數據對粒子追蹤過程提出的更高要求,由于實際應用中有限的計算資源,并行粒子追蹤過程中內存和I/O帶寬的限制被進一步放大。如何有效地利用有限的計算資源并設計出合理的數據管理策略來改善內存和I/O帶寬等資源的使用成為了另一個亟待解決的問題,這同樣有助于提升計算的整體效率。
面對上述挑戰和問題,高性能流場并行粒子追蹤數據管理系統在優化策略上通過設計高效的數據管理策略,結合大規模流場可視化的特點,充分利用計算資源,從數據存儲組織方式、數據訪問以及在并行粒子追蹤過程中對數據的劃分和調度管理等方面進行考慮。在優化目標方面,高性能流場并行粒子追蹤數據管理系統關注于并行粒子追蹤流程中的兩大性能桎梏,即負載均衡問題和大規模I/O問題。負載均衡問題和大規模I/O問題兩者相互聯系,相互制約。該系統通過先進的評估和劃分算法,同時權衡優化兩大目標,以達到實際性能的最大化。
支持本地平臺運行的高性能流場并行粒子追蹤數據管理系統能對并行粒子追蹤過程產生跡線數據,系統支持靈活多變的本地端多種跡線可視化與可視分析方法,用于幫助用戶理解與探索原始流場的特性。進一步地,高性能流場并行粒子追蹤數據管理系統能對并行粒子追蹤過程中產生的進程工作記錄數據,系統支持用戶對該過程中進程的負載與進程間數據塊轉移情況進行可視分析,在有效增強過程理解的同時,用戶據此可對并行計算過程做出診斷。
3.2 流場并行粒子追蹤數據管理模塊構建
3.2.1 基于鍵值對存儲的并行粒子追蹤框架實現
在大規模流場可視化并行粒子追蹤計算過程中,數據訪問的效率是提升計算性能、可擴展性和存儲空間效率的已知最大瓶頸。因而高效的數據存儲管理、計算框架、底層架構實現成為十分重要的部分,是高效、高可擴展性計算性能的有力保證。究其原因,是因為大規模科學可視化構建所需要的可用計算資源十分有限,遠遠小于原始模擬的計算和數據規模,需要在有限地條件下平衡諸方面的因素,實現性能的提升。
高性能流場并行粒子追蹤數據管理系統基于一種鍵值對(Key-value)存儲的并行粒子追蹤框架底層實現[33],旨在提升數據訪問的效率。在流場可視化并行粒子追蹤過程中,盡管流場可視化整體數據集十分龐大,但單次使用的工作集卻非常小,因此從粗粒度分區到細粒度劃分和調用是可行的。由于粒子追蹤過程中粒子的軌跡難以預測性,基于按需載入的存儲操作基本方法能夠最有效地適應數據訪問的實現模式。同時先進的粒子追蹤方式越來越多地采用本地任務隊列來管理局部粒子追蹤任務的啟動、停止和通信狀態。基于先進的并行粒子追蹤技術現狀,該工作發現基于鍵值對存儲的稀疏數據管理可以大大減少并行粒子追蹤運行的內存占用,很好地適應按需數據訪問需求,并且可以在不妨礙性能和擴展性的前提下進行高效管理。
在該方法的實現中,運行時的數據以初始劃分的多個數據小塊為基本的管理粒度,包含單個單元或更細粒度的單元塊。該方法同時包含兩個模塊的組件:① 一個并行的鍵值對存儲模塊,支持統籌集中地進行數據塊的I/O操作,以最大限度地將I/O延遲隱藏在并行粒子追蹤積分計算的過程背后;② 一組完全獨立的任務并行的追蹤器。每個并行粒子追蹤計算任務都被分配到一個追蹤器,而每個追蹤器擁有并管理著大量的追蹤任務,通過任務隊列的管理方式執行和管理待處理的任務集。追蹤器通過訪問和查詢并行鍵值對存儲的方式來請求計算過程中的數據,并將收到的數據塊保存在本地基于最近最少使用(Least Recently Used, LRU)策略的緩存中,該緩存機制采用一個簡單的隨機存取存儲器(Random Access Memory, RAM)鍵值存儲實現。為了實現上述并行化模塊組件,任務管理中包含兩種不同的進程,即鍵值對存儲進程和粒子追蹤進程,分別處理不同的任務,數據主要從鍵值對存儲流向粒子追蹤進程。鍵值對存儲進程負責數據請求的通信接收和載入處理,粒子追蹤進程的任務則不涉及數據的訪問,僅進行數值計算的過程。
在當前的實現中,由粒子追蹤進程進行數據訪問的過程與具有多層高速緩存的CPU上的數據訪問非常相似。粒子追蹤進程首先檢查所需的數據是否緩存在本地,若本地緩存未命中,則粒子追蹤進程向對應的并行鍵值對存儲請求,若并行鍵值對存儲仍然沒有所需要的數據,則將花費更長的時間從文件系統中載入所需的數據并返回。并行鍵值對存儲系統可以依據一定的數據預取策略,利用已有的信息積極地進行數據預取以避免緩存丟失,同時實現流控制以避免I/O系統的擁塞。基于三級緩存機制實現的數據訪問過程和所需時間如圖2所示。
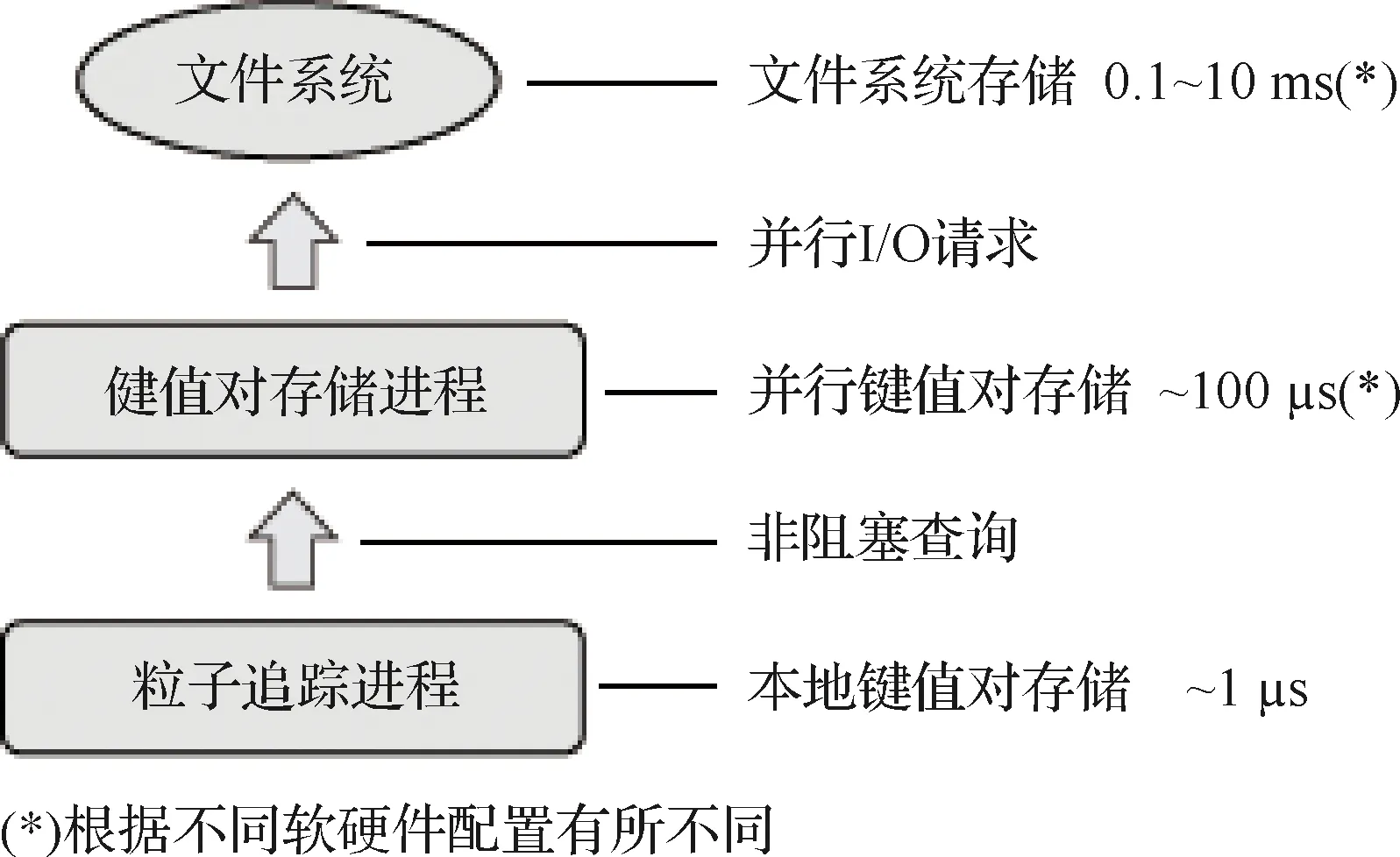
圖2 流場并行粒子追蹤數據管理模塊軟件邏輯架構Fig.2 Software logic architecture of flow field parallel particle tracing data management module
每個鍵值對存儲進程負責一系列粒子追蹤計算進程的數據訪問請求。為了實現負載平衡,需要合理設計進程間任務負責的映射方法。該實現中通過散列的方法來劃分整體的索引空間,并通過輪轉法[24]來進行負責進程的分配。一個密鑰k根據公式i=hash(k)modn,被分配給一個鍵值對存儲進程,其中n為鍵值對存儲進程數。粒子追蹤進程發出的數據請求通過點對點通信,直接發送到相應的鍵值對進程實現交流。
該系統開發基于C++語言,混合了MPI/線程并行。所有的數據通信都是通過消息傳遞,同時粒子追蹤進程和鍵值對存儲進程被劃分在同一個MPI通信組中。在該方法實現的框架中,有3種類型的進程間通信,即粒子追蹤和鍵值對存儲進程間通信,鍵值對存儲和粒子追蹤進程之間通信,鍵值對存儲進程之間的通信,粒子追蹤進程之間不支持建立通信。一般情況下,粒子追蹤進程向相應的鍵值對存儲進程發送請求,然后將數據條目發回給粒子追蹤進程。數據預取是通過存儲到存儲的通信來完成的。實現中預定義了一系列運行時程序應用接口(Application Programming Interface, API),以及其他消息用于傳遞數據條目、處理狀態和統計。所有的消息都會被入隊,使用谷歌protobuf庫序列化后發送至目的地進程。目的地進程在接收到消息后,將消息反序列化后進行后續處理。該系統利用異步通信來降低延遲。
3.2.2 基于訪問依賴的大規模數據訪問模式建模
流場可視化并行粒子追蹤技術中數據I/O的代價十分龐大,減輕I/O負擔的關鍵在于提高數據計算和利用中的局部性。其中主要的解決方案是將數據訪問模式結合到粒子追蹤中。但是,在流場可視化中,由于數據訪問模式是由流場特性隱式決定的,對其進行建模十分具有挑戰性。究其原因,粒子的軌跡難以預測。基于上述的特點,建立數據訪問模式模型的一種方法是使用馬爾可夫鏈。在隨機模型中,訪問下一個數據塊的概率只建立在剛被訪問過的那個數據塊上。通過計算每對數據塊的狀態轉移概率,一階訪問模式可以被記錄下來。然后在場線追蹤的過程中,根據粒子當前所在的數據塊位置,可以提前評估下一個可能訪問到的數據塊。這種一階的馬爾可夫模型已經被有效地應用在了計算流體動力學和流場可視化的應用和分析之中[34],但仍然存在一定缺陷。由于狀態(數據訪問)從一個數據塊可能會轉移到多種不同的數據塊,隨著一階馬爾可夫鏈的增長,算法難以進行準確的預測。
高性能流場并行粒子追蹤數據管理系統中集成了一種新穎的基于高階馬爾可夫鏈[35]的訪問依賴模型[36]。這種高階的訪問依賴將歷史訪問信息也考慮進去,計算下一步的數據塊訪問是建立在當前的數據塊和一系列過去已經被訪問的數據塊之上,可以更加準確地對數據訪問進行預測性,從而相比于一階訪問模式的建模方法[21-34],進一步提高了數據局部性以提升流場可視化粒子追蹤場線計算的效率。
高性能流場并行粒子追蹤數據管理系統基于不同的用戶任務設計和實際需求針對該數據訪問依賴的建模形式設計了兩種不同的實現方式,即一種基于預處理統計建模鍵值對存儲查詢的實現方式和基于機器學習進行訪問序列建模預測的實現方式。
基于預處理統計建模鍵值對存儲查詢的實現方式通過進行一次預處理化得全局撒種并行粒子追蹤過程,產生高度可重用的數據記錄,為后續并行粒子追蹤應用提供有效的輔助建模。整個數據全域被均勻劃分為若干數據塊,每個塊都包含各個維度上相等大小的范圍,并且使用均勻撒種的方式在不同位置上放置粒子。由于高階訪問對于依賴歷史訪問信息的需求,該方法從起始位置開始同時正向和反向進行追蹤計算。對應生成的跡線分別叫做正向跡線和反向跡線,其區別在于在跡線追蹤過程中前者每一步增加時間,而后者每一步減少時間。始于同一個位置的正向和反向跡線可以看成是一條完整的同時包含歷史和下一步訪問信息的跡線。在跡線追蹤過程中,該方法使用一階龍格-庫塔(RK1)數值積分算法,并設置了較大的積分步長來優化預處理性能。為了生成指定m階的訪問依賴數據,該方法考慮歷史訪問數據塊序列長度為m-1的所有合并跡線。該方法針對這些歷史訪問信息有所不同將跡線進行分組。算法進一步計算下一個訪問包含每個數據塊的所有跡線數量與訪問所有可能數據塊的跡線總數的比值,作為訪問轉移概率。其計算公式為

(1)
式中:Bp為訪問歷史數據塊序列;Bc為當前訪問數據塊;Bfi為下一步可能訪問的數據塊;N為對應跡線支持的數量。
該算法的偽代碼如算法1所示。通過該方法,只要一輪預處理計算,就可以得到不同階數訪問依賴結果。例如,如果階數設為m,階數為m,m-1,…,1的依賴都會被計算出來。為了高性能的數據訪問模式和存儲,高性能流場并行粒子追蹤數據管理系統使用谷歌protobuf庫所提供的數據結構。圖3為高階訪問依賴計算過程的示意圖。
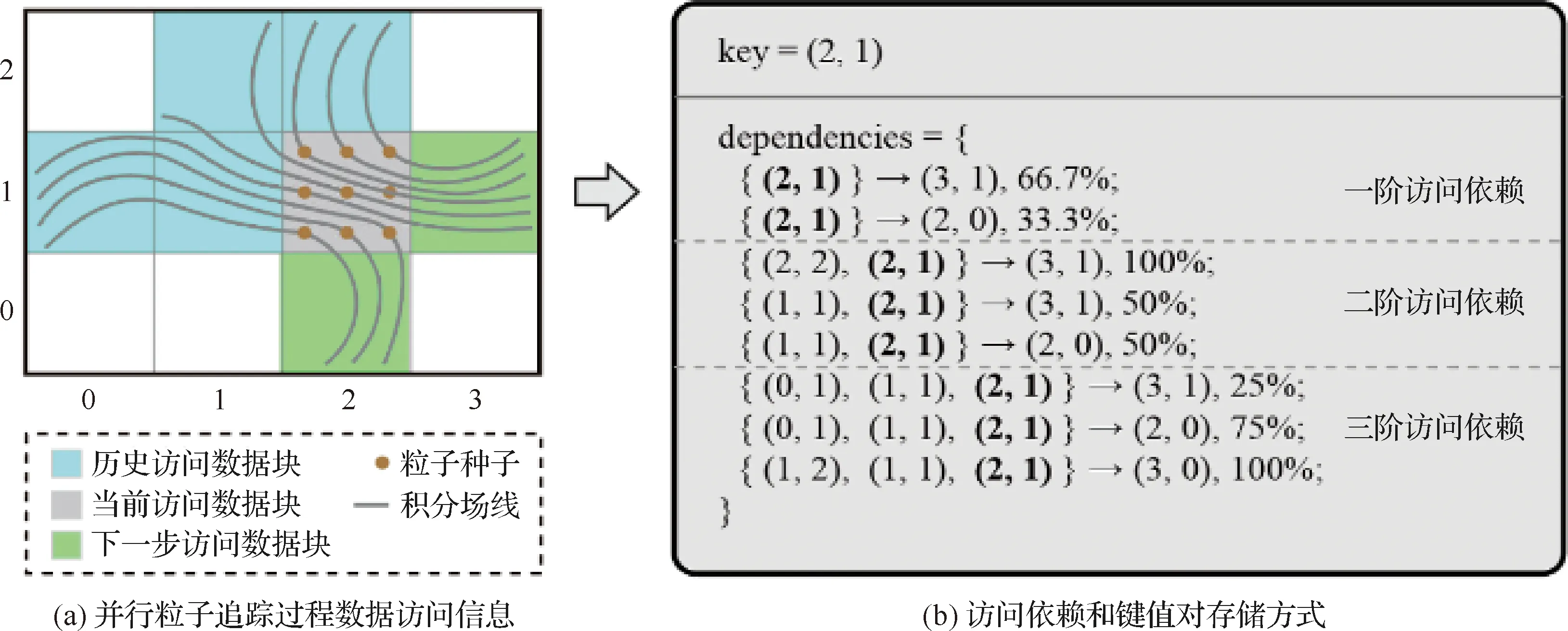
圖3 高階訪問依賴計算過程示意圖Fig.3 Computation process of high-order access dependency
隨著機器學習技術的飛速發展,深度學習和可視化領域的結合日漸成為了研究熱點。高性能流場并行粒子追蹤數據管理系統關注于基于機器學習進行數據管理策略的研究領域下的潛力,提出了一種基于深度學習模型進行流場數據訪問模式的分析、提取和建模預測的新方法[37],并據此采用先進的數據管理策略優化過程,支持靈活地嵌入流場可視化并行粒子追蹤的框架中。該方法提出了一種新的使用泛化能力更強的長短時記憶模型[38]來對數據訪問模式進行建模。通過在數據空間域中放置若干粒子,積分計算它們的軌跡,并將它們作為訓練數據來訓練模型,學習數據塊之間的訪問模式。首先將數據塊索引序列轉化為粒子移動方向的序列,圖4為由粒子軌跡轉化為數據塊訪問模式序列的過程示意圖。高性能流場并行粒子追蹤數據管理系統進一步集成了一個先進的機器學習模型,通過接受一個基于移動表示的序列,輸出一個概率分布的序列,表示為考慮粒子所有之前移動和起始數據塊后,預測得到下次移動的分布情況。
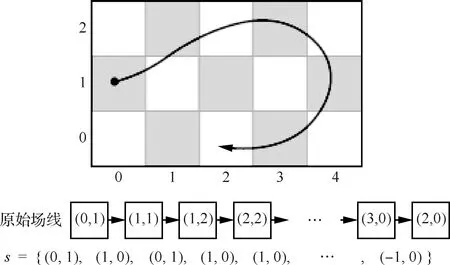
圖4 粒子軌跡轉化為數據塊訪問模式序列示意圖Fig.4 Process of transferring pathline into sequence of data block access pattern

算法1 高階訪問依賴的提取算法MPI_Init()if RankID in tracer_list then local_db_initialize() ∥初始化本地記錄 data_initialize()∥根據初始均勻劃分載入數據 seed_placing() ∥根據初始均勻撒種獲取任務 tracing_particle(); ∥正向粒子追蹤 inverse_tracing_particle() ∥反向粒子追蹤 if pathline in local_db then increase_record_num(pathline)∥增加對應記錄的數量 else new_record(pathline) ∥添加新記錄 end ifend ifglobal_db_initialize()gather_stastics(global_db, local_db)∥收集各個進程流線記錄信息while order ≤ max_order do calculate_frequency(order, global_db)∥迭代計算各種流線模式頻率end whileMPI_Finalize()
圖5展示了該方法中進行數據訪問模式建模采用的機器學習模型結構,其中D為粒子所有可能移動到的數據塊運動方向。其輸入是一個長度為n的移動序列s={s0,s1,…,sn-1},代表數據塊訪問的歷史和當前信息。序列中每一項被嵌入層轉化為一個實值向量。在嵌入層中,所有元素都被投影嵌入到另一個空間中。在嵌入層之后,高維向量的序列作為輸入,進入到LSTM層。LSTM層輸出一個由hidden_size維向量構成的序列。為了讓LSTM層的輸出能支持在待處理集合上的分類任務,網絡結構中還添加了一個全連接層將輸出序列的每一項轉化為向量,并通過一個ReLU激活層將向量中的負數值整流為0。最后通過一個softmax層對這些權重進行重新調整,使得同一個向量里的值全部變換到(0, 1)之間并且和為1。對于每個輸入項,其對應的輸出向量可以看作一個所有元素的概率分布Pi,作為預測下一步數據訪問數據塊訪問模式方向的概率分布。該模型使用負對數概率函數來作為損失函數支持訓練,具體計算公式為
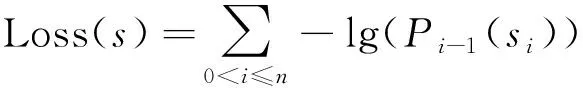
(2)

圖5 數據訪問模式建模采用的機器學習模型結構Fig.5 Machine learning model structure applied in data access pattern modeling
對于優化器的合理選擇問題,該工作選擇了小批量梯度下降算法,也就是每次更新模型只計算并考慮在一個小訓練集上的損失函數之和。小批量梯度下降算法可以看作是隨機梯度下降和全批量隨機梯度的折中方案,具有更新次數更少,計算效率更高,模型更新頻率更高,收斂過程也更加聯邦魯棒,更容易避免局部最小值的優勢。RMSProp因為在已有工作中的優異性能,而被選擇為模型參數的學習器。它能夠自適應地調節學習率,使其在梯度的同一個量級上。該機器學習方法可以內嵌于并行粒子追蹤的流程中,實現數據塊預取技術,實現一種嶄新的、具有潛力的CPU/GPU合作進行粒子追蹤任務的形式,僅需要很少量的數據在主存和顯存中傳輸。
高性能流場并行粒子追蹤數據管理系統基于上述基于訪問依賴的大規模數據訪問模式建模實現,能夠高效地支持并行粒子追蹤流程中的數據局部性,結合大規模數據預取的有效數據管理策略,能夠有效提升數據I/O過程中的性能指標,為實現高性能并行粒子追蹤流程構建流場可視化提供有力的技術模塊支持。
3.2.3 基于訪問模式的負載動態負載評估策略
為了進一步提升計算效率,現有算法關注于粒子追蹤算法中固有的天然可并行性,采用多進程并行優化計算的方式提升效率,以適應粒子追蹤本身的計算復雜性帶來的挑戰。引入并行計算的機制在潛在提升計算效率的同時,使得算法具有更加復雜的流程,使得并行計算中負載均衡問題成為效率提升的關鍵所在。由于并行粒子追蹤計算過程的復雜性中,粒子的軌跡和粒子的運行時間難以預測,如何預估不同計算進程的負載情況,從而合理設計和實現負載均衡算法成為了十分重要的問題。
高性能流場并行粒子追蹤數據管理系統集成了一種基于訪問模式的負載動態負載評估策略[39]。該策略使用粒子追蹤的積分步數來衡量不同進程的工作負載。在每一輪粒子追蹤計算過程中,數據塊的負載被定義為所有粒子在該輪中在此數據塊內被追蹤的步數總和。由于不同進程基于劃分的策略負責多個不同的數據塊中包含的粒子計算任務,因此其負載也是這些數據塊的負載之和。該方法同時將粒子數目和其歷史負載進行考慮,用于預估數據塊在一輪中的負載。
首先記錄在每個數據塊中追蹤過的粒子數目和積分步數,并將其作為歷史追蹤信息附加在這個數據塊中。當一輪粒子追蹤結束時,算法可以計算每個數據塊中粒子的平均負載。同時,根據未完成粒子的坐標,算法可以獲知它們接下來在所有數據塊中的分布數量。因此,每個數據塊將來包含的負載可以用如下方法評估得到。假設在第j-1輪追蹤結束之后,對于每一個數據塊k,如果在第j輪有nk,j個粒子以它為起始塊,那么第j輪預估負載可以使用如下公式進行計算:
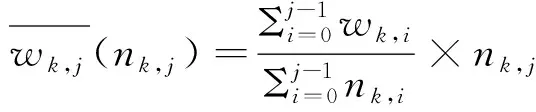
(3)
式中:wk,i是數據塊k在前面的第i輪中的實際負載;nk,i是在前面的第i輪中經過數據塊k的實際粒子數目(i 算法在運行時動態地建立了一個一階訪問依賴圖的數據結構,來便捷地表達粒子在多個數據塊之間的轉移概率。每個數據塊以多個鍵值對的形式保有訪問依賴圖的一部分,其中key是該數據塊的鄰接塊索引,value是對應的訪問轉移概率,用來提升查詢的效率。該方法根據從初始數據塊的訪問轉移關系,可以預測在第2級追蹤深度層次上要訪問的數據塊。基于訪問轉移概率,算法可以預測粒子在這些數據塊中的粒子分布數量。之后,根據式(3)可以計算得到在每個數據塊中的負載。從這些數據塊出發,算法可以進一步預測在下一級追蹤深度層次上要訪問的數據塊,直至追蹤到第N級追蹤深度層次。圖6展示了追蹤深度為3時的負載評估流程。 圖6 基于訪問模式的負載動態負載評估策略Fig.6 Dynamic data block load estimation strategy based on access pattern 高性能流場并行粒子追蹤數據管理系統采用基于訪問模式的負載動態負載評估策略實現對不同計算進程的準確負載預估,結合后續提出的負載均衡化調度算法實現數據和任務的合理分配,能夠有效地改善并行粒子追蹤流程中計算效率,減少空閑進程的占比,為實現高性能并行粒子追蹤流程構建流場可視化提供有力的技術模塊支持。 3.3.1 基于圖劃分算法整合實現的靜態高性能 并行粒子追蹤優化高性能并行粒子追蹤器為了實現并行粒子追蹤計算效率的最優化,復用了上述已有工作中多樣化的流場并行粒子追蹤數據管理模塊化的技術,并加以合理應用、集成和精簡,提出一種新穎的高性能并行粒子追蹤優化算法框架。算法框架基于靜態任務劃分的并行優化方法。靜態的任務劃分方法僅在初始的輪次對于任務生成初始的劃分,能夠最小化地減少算法的額外計算和開銷,使得并行粒子追蹤過程更加簡潔可控,也為進一步的算法優化提供了便利。該方法提出的框架仍在優化和迭代過程中。 算法構建了一個基于圖的數據結構,用以描述并行粒子追蹤任務的分配信息,并通過圖劃分的算法實現各個進程的數據和任務的分配。算法框架的主要流程包括兩個部分:預處理階段和運行時階段。其中,運行階段又由兩個子階段組成,分別是任務劃分和隨后的任務并行粒子追蹤。 算法框架預處理階段將流場轉化為高階訪問依賴和負載信息的形式進行表達。首先將給定的流場數據在空間維度上均勻分塊,在各個數據分塊上均勻撒種,進行一輪的并行粒子追蹤,并記錄下追蹤信息。該過程應用3.2.2節中基于訪問依賴的大規模數據訪問模式建模技術,與其預處理步驟較為一致,同時對每個種子點進行正向和反向追蹤。只要一輪預處理計算,算法就可以得到不同階數訪問依賴結果。與上述基本技術模塊的不同之處在于,該方法不僅收集粒子的歷史訪問信息以構建數據塊訪問依賴的建模關系,還記錄了粒子在數據塊內的負載信息(即積分步數)。框架又進一步結合3.2.3節中基于訪問模式的負載動態負載評估策略,計算每個數據塊內粒子的平均負載信息。其具體計算過程與上述算法一致。新增加的這一步平均粒子負載計算直接利用了粒子追蹤的中間結果,并不會顯著提高預處理開銷。基于該預處理過程中生成的每個數據塊信息,會在后續的任務劃分和運行時并行粒子追蹤過程中得到應用,基于上述方法生成的單個數據塊數據信息以<數據索引,平均負載,訪問依賴>的模型結構形式對其進行組織。 算法框架任務劃分階段旨在通過構建種子塊圖結構,實現兼具負載均衡性和高I/O效率的任務劃分,以進行后續的并行粒子追蹤過程。該階段首先同樣將流場數據在空間維度上均勻劃分為數據塊。給定基于任務定義的種子點分布,遵循流場分塊結果,算法將其組織成多個種子塊,每個種子塊和一個數據塊及其包含的種子點相對應,使得粒子追蹤任務和數據更緊密地結合起來。對于每一個種子塊,算法根據預處理的結果預測其中的種子在后續粒子追蹤過程中會訪問哪些數據塊,同時預估其負載,并據此進行圖構建算法。 對種子塊的數據塊訪問進行預測是一個遞歸的過程。從某一個種子塊出發,可以得到該對應數據塊訪問依賴中的一階訪問依賴,并找出所有可能在下一步訪問的數據塊。這個預測過程可以一直循環迭代,直至預先定義的粒子最多可以經過的數據塊數量。上述算法可以得到種子塊中的種子點可能經過的所有數據塊序列。對于不同的種子塊,算法可以計算任意兩個種子塊中的粒子跡線計算需要的數據塊的相似性。同時根據預測到的數據塊序列,該方法還可以評估初始粒子種子在這些數據塊中進行追蹤計算時產生的負載,并計算出對應種子塊中粒子的總預估負載。 算法框架構建的圖結構是一個無向圖G=(V,E),節點和邊分別映射了種子塊的負載信息和種子塊之間數據訪問的關聯。圖結構中的每個節點表示一個種子塊,其權重表示該種子塊的負載。節點之間的邊表示對應的兩個種子塊在數據訪問路徑的相似度。基于該表示下的流場和初始種子數據,需要通過圖劃分的方式,將不同的種子塊節點分配給不同的進程,以實現負載均衡和I/O效率的優化。基于上述優化目標,該圖劃分的優化任務需要將種子塊圖劃分成若干節點權重之和相近的子圖。每個子圖對應一部分的種子塊并被分配給一個進程。圖劃分的另一個目標是確保劃分后相同子圖中的種子塊具有盡量相似的數據訪問,同時不同子圖中種子塊訪問的數據塊重復性最小。因此,需要在種子塊圖劃分中,最小化需要的切割代價的大小。該方法使用ParMETIS庫[40]所提供的圖劃分算法來解決上述種子塊圖的劃分和分配問題,結果如圖7所示。 圖7 圖劃分算法結果示意圖Fig.7 Result of graph partition-based algorithm 任務劃分之后,每個進程可以被分配到若干個種子塊中的粒子種子,并進行任務并行的粒子追蹤。并行粒子追蹤框架的數據管理基于3.2.1節中的鍵值對存儲框架高效實現。在運行并行粒子追蹤過程中,高性能流場并行粒子追蹤數據管理系統實現了面向數據塊的粒子追蹤管理和高階數據預取技術,以進一步提升計算的效率。該框架使用了數據預取來提高I/O效率。當從外存中載入所需要的數據項時,根據其訪問依賴部分,預測下一步可能訪問的數據塊,并將其對應的數據項一同載入到內存中。 3.3.2 可視分析技術支持的并行粒子追蹤過程 理解和優化并行粒子追蹤過程及相應的算法十分復雜,其中涉及較大的并行計算規模和不斷變化的數據行為。為了理解這一復雜的并行計算過程,從中整合并行計算進程間的行為模式、數據遷移、任務交換等信息十分必要,用戶可以據此提出深刻的見解。可視分析技術能有效地幫助用戶理解該過程,通過圖形化的高效編碼方式,降低用戶的認知負擔。高性能流場并行粒子追蹤數據管理系統集成了一套交互式的可視分析工具[41],以幫助用戶探索和診斷流場可視化并行粒子跟蹤過程中動態負載平衡過程(數據和任務劃分)。整個并行粒子追蹤的流程被通用地建模為包含多個輪次的過程,在每個輪次中,每個粒子在流場中分別進行積分計算,直至達到最大步長或離開定義的流場邊界。 交互式可視分析工具的系統界面如圖8所示,共包括3個視圖:整體視圖、節點-鏈接圖視圖和空間視圖。這3個視圖通過交互手段鏈接在一起,供研究人員從整體到細節進行探索。在整體視圖中,系統利用折線圖來顯示并行粒子追蹤中各個進程負載平衡過程的概述。其中橫軸表示執行時間,其上標記出運行的輪數。縱軸表示負載平衡指標,該指標按此輪中進程最大工作負載與平均進程工作負載之比計算得出。節點-鏈接圖作為該可視分析工具的主要視圖,可視化整個并行粒子追蹤流程的數據行為,包含數據塊的傳輸以及各個計算進程之間的任務交換。其中每個節點代表某一個輪次中的一個計算進程,節點的大小編碼了在相應的輪次進程中分配的數據塊的總數,同時應用顏色對每個進程的負載進行編碼。節點之間的鏈接表示數據塊的移動或任務從一輪中的一個進程到下一輪中的另一個進程的交換。系統還對分配給每個過程的數據塊進行編碼以顯示詳細信息。每個數據塊都可視化為一個正方形。對于每個進程,其分配的數據塊將在相應節點上方水平顯示。節點-鏈接圖視圖設計采用了類似矩陣的總體布局。視圖中從上到下顯示多行節點,表示連續的并行粒子追蹤輪次。每列中的節點表示在不同的輪次中的同一進程。空間視圖用來繪制指定數據塊中的粒子跡線,以幫助用戶診斷異常。 圖8 交互式可視分析工具的系統界面Fig.8 System interface of interactive visual analytics tool 流場數據全局分析任務目的是研究流場的綜合性特征。流場可視化典型的全局分析應用包括有限時間李雅普諾夫指數(FTLE)的計算,用來衡量非定常流場的分離特性。FTLE計算使用了全局密集撒種策略,需要追蹤大量的粒子,對流場并行粒子追蹤的性能提出了較高的要求。本次測試分析任務采用的颶風Isabel數據自于美國國家大氣研究中心對颶風的模擬結果,由若干時變的標量和矢量變量組成。數據時空分辨率為500×500×100×48。 測試分析利用國家超算廣州中心的天河2號超級計算機平臺。該測試最多使用了512個進程,每個進程的緩存被設置為512 MB。采用的數據塊劃分粒度為16×16×16×1,追蹤總數為54 000個的粒子。實驗的性能基準為強可擴展性測試,同時分析負載均衡性以及I/O效率。強可擴展性是測量在固定數量粒子下總執行時間如何隨進程數的變化而變化。其通過對所有進程上分配一個總規模大小固定的問題來測試方法的效率。該實驗中采用的基線方法為不施加優化的并行粒子追蹤算法,與高性能流場并行粒子追蹤數據管理系統采用的并行粒子追蹤算法形成對比。實驗結果如圖9所示,驗證了高性能流場可視化粒子追蹤器在性能、負載平衡、I/O效率上的優勢,達到了預期的目標。 圖9 基于Isabel數據集進行的強可擴展性測試結果Fig.9 Strong scalability test results based on Isabel dataset 已有的流場可視化并行粒子追蹤中負載均衡化算法進行了多樣化優化設計,從不同的角度提升負載均衡指標。案例分析采用高性能流場并行粒子追蹤數據管理系統中集成的交互式可視分析工具針對不同的負載均衡算法進行詳細的探索,幫助理解和比較不同算法設計和對并行粒子追蹤過程的干預方式,以待研究人員進行針對性的診斷和進一步地改進。測試中主要關注的是通過數據塊和任務的轉移來進行動態負載平衡算法。通過在這個動態過程中嵌入中間數據提取代碼,轉儲相關性能信息,進行可視化和可視分析。在每一輪并行粒子追蹤過程中,系統都會獲得兩種類型的性能數據。第1種是數據塊和任務在不同進程和運行輪次的分布情況。第2種涉及與源/目的進程有關的流入/流出的數據塊和任務數據。 測試中采用的熱工水力學數據是Nek5000求解器的輸出結果,來自于美國阿貢國家實驗室開發的大渦Navier-Stokes模擬。本次測試使用單個時間步的數據,分辨率為512×512×512,數據規模為1.5 GB。測試分析利用國家超算廣州中心的天河2號超級計算機平臺,使用32個進程進行并行粒子追蹤。共對比分析運行了3種不同的算法,如圖10所示。基于負載竊取的優化算法的基本思想是在每輪追蹤之后將任務從繁忙的進程發送到空閑的進程。基于動態數據重劃分的優化算法則定期執行數據重劃分,然后在每輪粒子追蹤后根據劃分結果重新分配數據塊。圖10展示了使用Nek5000數據和多種優化算法實現的并行粒子追蹤過程中進程間數據行為比較可視化。 圖10 使用Nek5000數據和多種優化算法實現的并行粒子追蹤過程中進程間數據行為可視化比較Fig.10 Comparison visualization of data behavior among processes in parallel particle tracing implemented by multiple optimization methods based on Nek5000 dataset 在基線算法中,每個進程都保持最初分配的數據塊,并且在運行時數據不在進程之間移動,進程0和進程3始終具有很高的負載,未實現負載均衡化。基于動態數據重劃分的優化算法流程中則出現了頻繁的數據遷移和調度,盡管有一些進程被分配了較多的數據塊,系統卻實現了較為良好的負載均衡,這得益于良好的負載預估和動態數據塊重分配算法。基于負載竊取的優化算法同樣具有較多的數據遷移行為,但數據遷移大多發生在并行粒子多輪追蹤的后期,且集中于多個固定的進程。由于并行計算任務在初始幾輪大多難以觸發結束跳出條件,同時數據初始按空間劃分分配的相對均勻性,大多數進程未出現空閑的時間,因而不符合負載竊取的觸發條件。相比于基于動態數據重劃分的優化算法,其負載均衡指標略遜一籌。案例證明了基于該可視分析工具可以有效幫助用戶發現不同并行粒子追蹤算法的特征。 1) 高性能流場并行粒子追蹤數據管理系統包括超算服務器平臺上部署的基于先進數據管理策略優化的并行粒子追蹤器,能幫助用戶高效地生成流場中的跡線。 2) 高性能流場并行粒子追蹤數據管理系統包括在本地端的可視分析理解診斷工具,能幫助用戶理解、分析、診斷并行粒子追蹤負載均衡算法。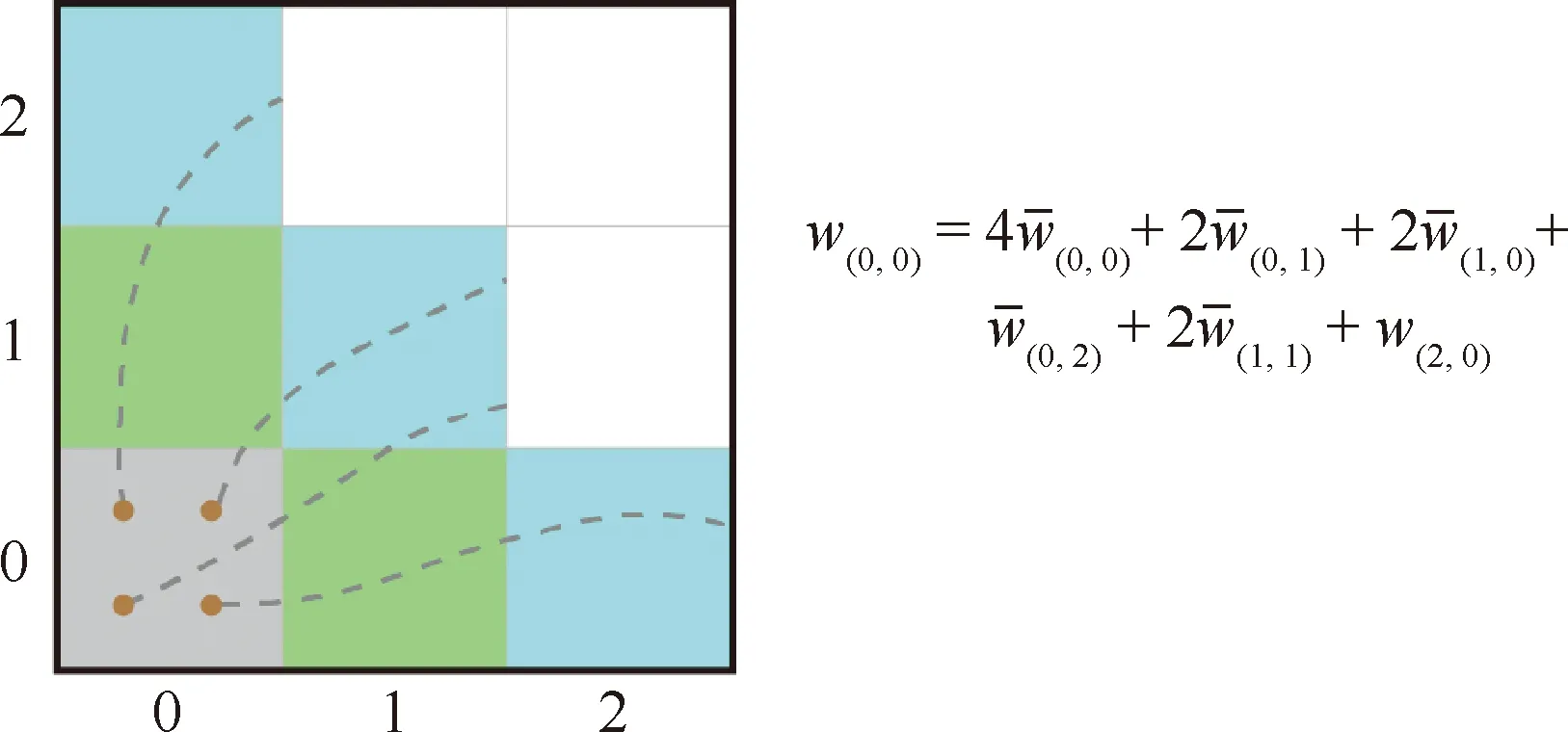
3.3 高性能并行粒子追蹤全流程


4 應用實例
4.1 基于颶風Isabel模擬數據的流場全局分析并行粒子追蹤性能測試

4.2 可視分析技術支持的基于Nek5000熱工水力學模擬數據多種動態負載平衡算法比較

5 結 論
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
中國外匯(2019年20期)2019-11-25 09:54:58
傳媒評論(2019年4期)2019-07-13 05:49:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
