基于雙注意力機制的臺風軌跡預測模型
2021-10-20 08:03:08賀琪劉東旭宋巍黃冬梅杜艷玲
海洋通報 2021年4期
賀琪,劉東旭,宋巍,黃冬梅,杜艷玲
(1.上海海洋大學 信息學院,上海 201306;2.上海電力大學,上海 200090)
臺風是一種典型的熱帶天氣系統,是海洋-大氣相互作用的重要形式之一(張志偉,2019)。它嚴重威脅著沿海地區人民的生命財產安全和經濟的發展。因此,及時地對臺風軌跡進行預測可以為防災部門提供有效的信息支持,從而減少人員傷亡和經濟損失。然而影響臺風軌跡的因素眾多,如臺風熱力學、臺風動力學和臺風期間環境場等(黃小燕等,2013)。并且在臺風登陸之后,臺風軌跡還會受到陸地地形地貌,以及海岸線水深的影響(余錦華等,2012)。所以,臺風軌跡預測是一個十分重要而又充滿挑戰的研究課題。
早期的臺風軌跡預測主要依靠熱力學和空氣動力學對臺風環境場進行分析,結合臺風登陸點對沿海地區復雜的海岸線以及陸地地形地貌影響因素的分析,建立臺風軌跡預測領域特有的經驗法則(王瀚,2020)。然而這種主觀經驗法,效率低下,并且需要大量人力物力,預測的精度和時效性都難以滿足需求。隨著臺風監測技術和計算機技術的發展,為了解決臺風軌跡預測精度不足和時效性滯后的問題,臺風領域的專家提出了數值預報方法。袁炳等(2010)提出一種非對稱臺風Bogus 方法,提升了臺風強度預報精度。王康玲等(1996)提出了一套解決臺風數值預報初始場的方案,并且已將其應用于中國南海臺風預報。錢傳海等(2012)討論了不同初始場和一些邊界條件對臺風數值預報精度的影響。李澤椿等(2002)回顧了國家氣象中心集合數值預報系統的開發過程,概述了國家氣象中心現有的中期集合數值預報系統的組成、應用和發展趨勢。雖然數值預報在預報性能上要遠遠優于主觀經驗法,但是數值預報的精度相較于主觀經驗法并沒有明顯提升(陳國民等,2019)。進一步提高數值預報模型的預報精度仍然是一個挑戰。
目前,世界各國的氣象局基本都建立了氣象衛星、海洋觀測站,以及地面觀測站等臺風三維觀測系統。從1949 年至今已經積累了大量臺風數據(Gao et al,2018)。隨著臺風數據的收集整理,部分研究者對臺風軌跡數據的時空特征進行了分析,認為可以將臺風軌跡數據視為時間序列數據,因此提出了將臺風軌跡預測和時間序列預測技術相結合的方法,希望獲得更好的預測效果。
循環神經網絡(Recurrent Neural Networks,RNN) (Tokg觟z et al,2018)是一種適用于處理時間序列數據的神經網絡,已經在許多領域被廣泛應用,但在迭代后期會出現“梯度消失”的問題。于是,Hochreiter 等(1997)最早提出了長短時記憶網絡(Long Short-Term Memory,LSTM),通過增加輸入門、遺忘門和輸出門,使得網絡自循環的權重可以變化,從而避免了“梯度消失”問題,適合處理和預報時間序列中延遲較長的事件。Ranzato等(2014) 提出了一種基于LSTM 的視頻解釋算法。Sutskever 等(2014)采用了LSTM 算法對時間序列進行預測,得到了很好的效果。研究表明,深度學習算法特別是LSTM 算法,可以很好地應用在天氣預報和海洋預報領域中。徐高揚等(2019)將LSTM 網絡應用在臺風軌跡預測中,與動態時間規整算法(Dynamic Time Warping,DTW) 相結合,在預測6h 臺風軌跡中效果很好。
隨著神經網絡的廣泛應用(如金融、醫學等),其包含的數據信息成指數增長,數據的長度、影響因子各有不同。傳統的LSTM 已經無法完美地解決數據不定長或者數據影響因子較多的分類或預測問題。在此基礎上,20 世紀90 年代,Forcada 等(1997)提出了一種編碼器-解碼器結構用來實現機器翻譯。編碼器-解碼器網絡結構無論輸入和輸出的長度是什么,中間的向量長度都是固定的,根據不同的任務可以選擇不同的編碼器和解碼器。這種靈活性使得編碼器-解碼器網絡迅速發展并且應用在各個領域。Chen 等(2018)提出了一種帶可分離卷積的編碼器-解碼器網絡并成功應用在圖像分割上。Malhotra 等(2016)將編碼器-解碼器網絡應用在時間序列的異常檢測上,并取得很好的效果。Ekambaram 等(2020)利用編碼器-解碼器網絡進行新產品的銷售時間序列預測,得到了比較準確的預測結果。然而,隨著時間序列的長度和特征數量增加,編碼器-解碼器網絡的中間變量可能存儲不了那么多信息,會造成精度下降,于是,一種基于注意力機制的編碼器-解碼器網絡被提出。該注意力機制可以使網絡更加集中于重要的特征,同時能夠存儲更長久的信息,亦有許多學者將其應用于時間序列預測領域,如:查鋮等(2020)提出了一種結合注意力機制的區域海表面溫度預報算法,明顯提升了預報精度。Qin 等(2017)提出了一種雙階段的注意力機制模型,并將其應用在時間序列預測上,取得了很好的預測效果。Du 等(2020)將注意力機制和編碼器-解碼器網絡結合,對空氣質量時間序列數據進行預測,取得了很好的效果。Sutskever(2014)等針對注意力機制中的時間關系學習存在的問題,將注意力機制和編碼器-解碼器網絡結合,發現使用注意力機制可以明顯提高基于LSTM 的編碼器-解碼器網絡的預測能力。
雖然上述研究方法皆在一定程度上提高了預測精度問題,但目前針對臺風軌跡預測還未考慮到臺風軌跡數據的特征相關性和深層的時間相關性。為了解決該問題,本文基于長短時記憶網絡和注意力機制,提出一種結合雙注意力機制的編碼器、解碼器網絡模型(Dual-Attention-Encoder-Decoder,DA-Encoder-Decoder),首先使用臺風軌跡數據計算得到臺風曲率序列,充分考慮了臺風軌跡數據中隱藏的轉向和偏折信息。將曲率作為新的特征輸入,然后通過特征注意力機制對輸入特征分配權重,隨后編碼器將輸入特征編碼作為中間變量,而后再通過時間注意力機制對時間步長分配權重,最后通過解碼器進行映射輸出,得到預測結果。
1 DA-Encoder-Decoder 模型

圖1 給出了DA-Encoder-Decoder 模型的流程圖,兩個灰色矩陣從上到下分別表示臺風軌跡時間序列矩陣和臺風軌跡曲率矩陣,綠色矩陣表示融合臺風軌跡矩陣和曲率矩陣的輸入矩陣。藍色矩陣表示經過特征注意力加權的特征矩陣,橙色矩陣表示經過時間注意力加權的特征矩陣。D,D1,D2表示矩陣寬度,即臺風序列數據的特征個數,H 表示矩陣高度。DA-Encoder-Decoder 模型的具體步驟如下:
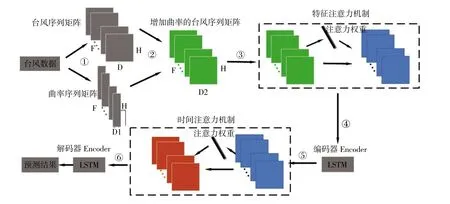
圖1 DA-Encoder-Decoder 模型流程圖
步驟淤:將西北太平洋臺風數據庫處理成臺風軌跡矩陣和曲率矩陣。
步驟于:將臺風軌跡矩陣和臺風曲率矩陣合并,依次按照臺風軌跡時間先后進行排列,構成矩陣序列,作為DA-Encoder-Decoder 模型的輸入。
步驟盂:利用注意力機制為獲得的輸入矩陣特征分配注意力權重,然后將注意力權重乘上對應的特征,得到加權的特征矩陣。
步驟榆:將特征矩陣輸入編碼器,得到隱藏狀態特征,保存特征信息。
步驟虞:利用時間注意力對隱藏狀態特征按照時間步長進行權重分配,然后將注意力權重乘上對應的特征,得到加權的隱藏狀態特征。
步驟愚:對獲得的隱藏狀態進行解碼,通過映射,最終獲得預測結果。
1.1 曲率特征的構建
本文中每一條臺風序列可表示為Si= [x1,x2,x3,…,xn],每一個xt沂Si表示臺風序列的一個時間步長的輸入[a,b],其中a 表示緯度坐標,b 表示經度坐標。然后將臺風軌跡抽象到二維坐標系中,可以看作是一系列坐標點,通過二維坐標系中三點定圓原理,可以求得臺風軌跡對應的曲率變化序列,求解步驟如下:
步驟1:首先設所求圓的半徑為R,圓心坐標為(x,y),則可由圓公式得:

根據上述步驟求得每條臺風軌跡的曲率序列,加入輸入軌跡序列中作為第三個特征。得到新的輸入序列Si= [x1,x2,x3,…,xn],每一個xt沂Si表示臺風序列的一個時間步長的輸入[a,b,c],其中a 表示緯度坐標,b 表示經度坐標,c 表示當前坐標點對應的曲率。
1.2 編碼器-解碼器模型
1.2.1 編碼器
編碼器在本質上是一種循環神經網絡,它將我們的輸入序列編碼轉化為一種特征。對于時間序列來說,給定輸入序列X=(x1,x2,x3,…,x栽),編碼器可以利用下面公式學習從x 到隱藏狀態的映射。

其中ht沂Rm,Rm是t 時刻編碼器的隱藏狀態,m 是隱藏狀態的大小,f1是一個非線性激活函數,在本文中我們使用LSTM(長短時記憶網絡)。每一個LSTM 單元都有一個記憶細胞來記錄t 時刻的狀態St。對于這個記憶細胞將會通過三個門:遺忘門ft,輸入門it以及輸出門ot。LSTM 三個門的更新機制如下:
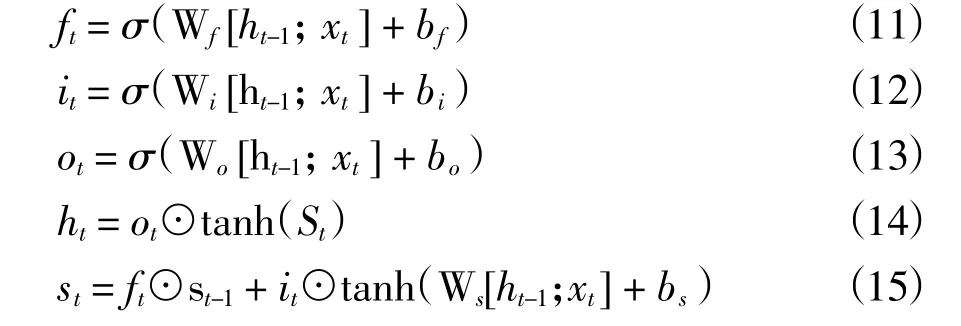
上式中[ht-1;xt] 表示當前輸入和之前的隱藏層的連接。Wf、Wi、Wo、bf、bi、bo、bs是需要學習的參數。滓和已分別表示邏輯sigmoid 函數和對應元素的相乘。
相較于傳統的循環神經網絡,LSTM 的細胞狀態可以對一段時間內的活動進行求和,可以克服梯度消失、梯度爆炸等問題,并且能夠更好地捕獲時間序列的時序依賴問題。
1.2.2 解碼器
為了預測輸出經緯度,本文使用了另外一個基于LSTM 的循環神經網絡去解碼已編碼的輸入信息。然而Cho 等(2014)提出,隨著輸入時間序列長度的增加,編碼器-解碼器結構網絡的性能會下降。因此本文在解碼之前結合了一個時間注意力機制,針對時間步長去訓練相應的注意力權重。簡單地說,就是根據前一個時間步的解碼器隱藏狀態計算當前編碼器隱藏狀態的權重。最終計算出我們期望的目標預測值。
1.3 注意力機制
注意力機制(Attention mechanism)是一種模仿人們視覺神經的方法,當人們觀看某個東西時,會將視線主要集中在重點關注的部分周圍,獲取這個部分更多的相關信息,減少對無用信息的獲取。所以,注意力機制最早應用在圖像分析領域,且表現出色。隨后慢慢地應用到了自然語言處理領域,與深度學習相結合,顯著地提升了模型的效果。目前,注意力機制經常會和Encoder-Decoder 一起應用。注意力機制可以應用在多個領域,它們所作用的對象不同,對模型的性能提升也不盡相同,本文利用特征注意力機制和時間注意力機制來為輸入特征和時間步長分配權重。
1.3.1 特征注意力機制
在使用編碼器之前,使用特征注意力主要是為了獲得輸入特征對預測結果的影響大小的關聯關系,以獲得更好的預測結果。本文特征注意力的學習流程如圖2,對t 時刻的第n(1臆n臆k,n沂Z)個特征向量的隱藏狀態的特征注意力權重表示方法如下:
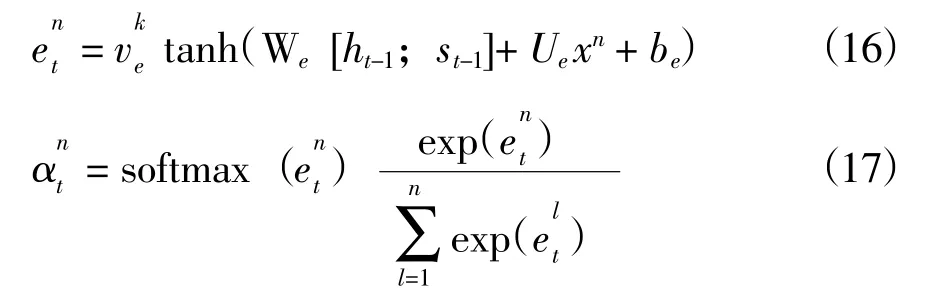

1.3.2 時間注意力機制
輸入數據經過編碼器編碼后,將會得到一系列隱藏狀態,為了得到預測結果,需要對隱藏狀態進行解碼。本文使用LSTM 網絡作為編碼器和解碼器。然而,編碼器中輸入序列長度過長的時候,解碼器的性能會下降。所以,本文在解碼器之前利用時間注意力機制來盡量提升解碼器的性能。對編碼器生成的隱藏狀態來說,其對時間依賴性的關注不足,需要利用時間注意力機制來對編碼器的隱藏狀態進行權重分配,以提升網絡整體性能。簡單地說,時間序列的長期依賴性可以通過加權編碼器中目標值最相關的隱含狀態來學習(Sagheer et al,2019)。本文時間注意力的學習流程如圖2,對t時刻的第i(1臆i臆T,i沂Z)個隱藏狀態的時間注意力權重表示方法如下:
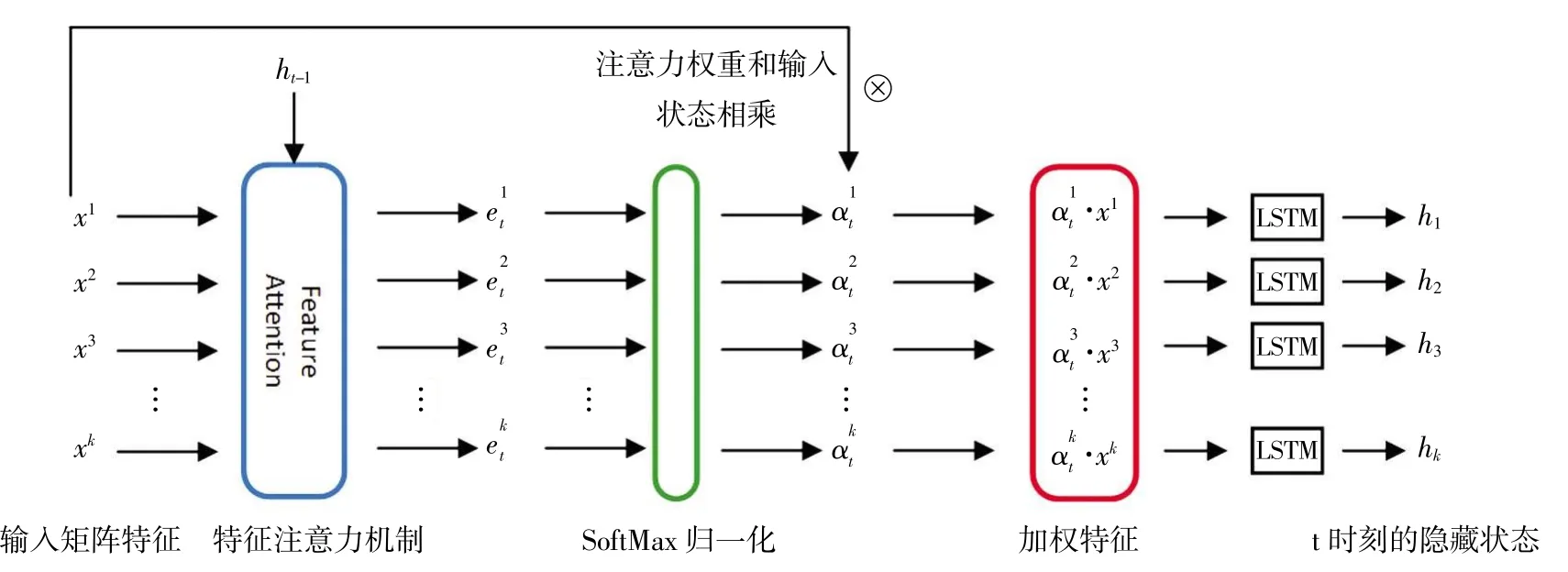
圖2 特征注意力機制流程圖
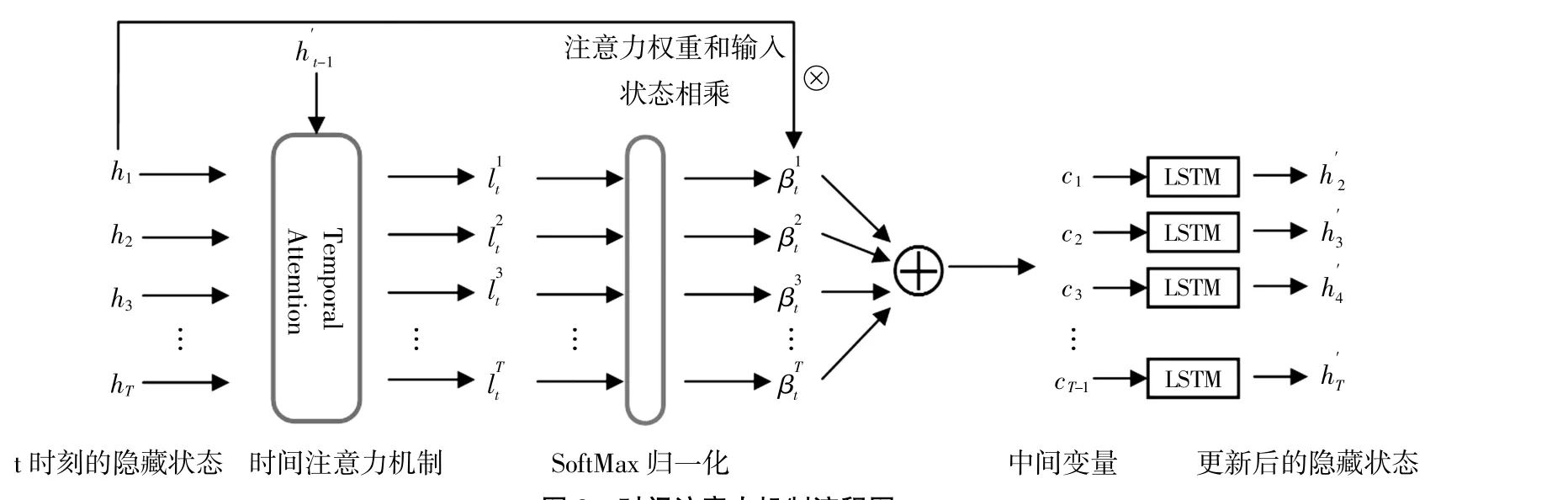
圖3 時間注意力機制流程圖

2 實驗
2.1 實驗數據

本文實驗使用Keras 框架搭建,Keras 是一個高度模塊化的神經網絡庫,可以基于Theano 或者tensorflow 搭建,并且支持擴展開發。實驗硬件環境平臺是Windows10,Intel Corei7,3.0 Hz,8GBRAM。
2.2 精度評價指標
在使用模型進行預報時,由于誤差的計算是根據預測坐標和實際坐標的差值,均方根誤差(Root Mean Square Error,RMSE)能夠很好地反應坐標點的偏移,也是一種常用的精度評價指標。實際誤差距離(ErrDis)(km)則是根據預測坐標點和實際坐標點來計算兩點之間地理上的實際誤差距離。能夠更加明確清晰地體現預測誤差,對實際業務應用也有一定的作用。
因此,為驗證DA-Encoder-Decoder 模型的有效性,本實驗使用RMSE 和ErrDis 來評估不同預報方法的性能,RMSE 和ErrDis 的公式如下表示:


對于RMSE 和ErrDis 來說,它們的值越小越好。當模型訓練使得RMSE 和ErrDis 最小的時候,就是最優模型。訓練時,通過觀察RMSE 和ErrDis的變化來確定合適的模型結構和模型參數。
2.3 實驗結果分析
由于臺風預測需要時效性,實驗選取訓練時間步長為一天(24 h)的數據。然后將全部的臺風軌跡數據進行劃分,將75%的數據作為訓練集,用于訓練DA-Encoder-Decoder 預測模型的參數,剩下的25%的數據作為驗證集,用于驗證模型的學習效果。
確定輸入特征:前文中提到利用臺風軌跡計算出曲率序列。增加曲率的特征主要是為了模擬出臺風的軌跡的曲線運動趨勢,包含了臺風的轉折角度和未來方向等信息。為了確定曲率特征對預測性能的提升能力,使用臺風軌跡原始數據和增加曲率特征的數據集分別預報24 h、48 h、72 h 的軌跡坐標。對比了曲率在編碼器-解碼器(Encoder-Decoder)和基于雙注意力機制的編碼器解碼器模型(DAEncoder-Decoder)預測模型的作用。根據表1 預測結果,可以看到在Encoder-Decoder 模型和DAEncoder-Decoder 模型上,增加了曲率特征之后對RMSE 和ErrDis 都有一定的降低作用,有利于提高臺風軌跡預測的精度。因此,本文在輸入特征中增加曲率特征。

表1 增加曲率特征性能對比
確定注意力機制:針對Encoder-Decoder 模型,增加不同的注意力機制,來記錄性能變化。從表2 可以看到,增加了注意力機制的模型預測精度要優于未增加的注意力機制的模型。增加了時間注意力的TA-Encoder-Decoder(Temporal-Attention-Encoder-Decoder)模型要優于增加了特征注意力的FA-Encoder-Decoder (Feature-Attention-Encoder-Decoder)模型。而本文提出的基于雙注意力機制的DA-Encoder-Decoder 模型效果明顯優于其他注意力機制。因為利用特征注意力機制去計算輸入特征的注意力權重會在更大程度上修正輸入特征對預測結果的影響。第二部分的時間注意力機制會針對每次輸入的樣本計算時間步長的注意力權重,盡管LSTM 也具備這種能力,但是在編碼器解碼器結構下,長序列會大大降低模型預測精度,而時間注意力機制能夠解決這個問題,可以對輸入數據進行長時期的權重計算,將之前的信息存儲在隱藏層中。
表2 是針對不同的注意力機制與預測模型結合的預測結果。預測模型分別對24 h、48 h、72 h 臺風軌跡進行預測。可以看出,增加了時間注意力的模型(TA-Encoder-Decoder)精度比單純的Encoder-Decoder 模型高,證明了在時間維度上的注意力權重訓練能夠提高模型的預測精度。同理,在特征維度上的注意力權重訓練也能夠提高模型預測精度。因此,特征相關性和時間相關性對臺風軌跡預測的精度均有影響。本文的DA-Encoder-Decoder模型既考慮了特征相關性,又考慮了時間相關性,從表2 可以看出,DA-Encoder-Decoder 模型的精度要明顯優于其他同類模型的預測精度。

表2 增加不同注意力機制性能對比(輸入包含曲率特征)
預報方法對比:確定了預測模型的輸入特征、注意力機制,預報模型基本上已經確定,為了驗證本文提出的DA-Encoder-Decoder 模型的有效性,分別與傳統預測方法以及神經網絡方法進行了對比。對比方法包括:BP、SVR、LSTM、ELM。對于SVR 網絡使用的是徑向基核函數(Radial Basis Function,RBF),該核函數能夠實現非線性映射并且需要學習的參數較少。以上對比試驗均采用Keras 庫函數進行搭建。訓練數據使用數據集的75%,驗證數據使用25%。通過預測24 h、48 h、72 h 的臺風軌跡,對比模型的RMSE 和ErrDis 指標來比較模型之間的預測性能的差異。
表3 是所有對比模型和本文模型的預測結果。可以看出,在預測24 h 臺風軌跡時,BP、SVR、LSTM、ELM、DA-Encoder-Decoder 模型的RMSE指標分別為3.48、2.96、2.81、5.62、1.82,ErrDis指標分別為330.6 km、279.24 km、263.14 km、539.55 km 和172.03 km。在24 h、48 h、72 h 上的預測中,與其他機器學習、深度學習預測模型相比DA-Encoder-Decoder 模型降低了預測誤差,具備最好的預測性能。

表3 不同模型性能對比(輸入包含曲率特征)
3 結束語
本文提出的DA-Encoder-Decoder 模型在臺風軌跡預測上的應用具有一定的研究意義,它充分挖掘了臺風軌跡數據的特征和時間信息,在輸入上結合了臺風軌跡的曲率序列,包含臺風軌跡的轉向、偏折等隱藏信息,與同類臺風軌跡預測模型相比,提高了預測準確性。
本文主要的結論有三點:
(1)之前的臺風軌跡預測都是只單純考慮臺風時間序列經緯度之間的關系,而本文將包含轉向、偏折信息的曲率特征作為預測特征,考慮了臺風轉向等隱藏因素對臺風軌跡的影響。
(2)利用了特征注意力機制為特征分配權重,得到不同的特征對要預測的軌跡點在特征維度上的影響。特征與權重相乘得到加權特征,突出了關鍵特征,提升了預測精度。
(3)利用了時間注意力機制為特征分配權重,反映出歷史臺風軌跡數據對要預測的軌跡點在時間維度上的影響,歷史臺風軌跡數據距離預測的軌跡點的時間遠近不同,對其的影響也不相同;特征與權重相乘可得到加權特征,使得關鍵信息被突出,加權特征包含的信息越明顯,預報精度便越高。
對比不同方法在同一數據集下的預測結果,DA-Encoder-Decoder 分別預測24 h、48 h、72 h臺風軌跡,誤差分別為172.03 km、245.14 km、403.6 km,實驗結果表明DA-Encoder-Decoder 模型在臺風軌跡預測方面獲得了一定的精度提升,從而驗證了本文方法的有效性,該模型值得更深入地研究和應用。由于臺風軌跡所受到的影響因子眾多,如風速、壓強、降雨量等,這些因子對臺風軌跡的變化具有一定的影響,因此在后續的研究中也應該充分考慮其他相關要素對臺風軌跡的影響。在下一步工作中,利用要素相關性或關聯規則去篩選對臺風軌跡影響較大的要素,利用這些要素建立多要素預測模型,從而進一步提高臺風軌跡預測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
