Hadoop與MapReduce應用下的大數據處理系統設計
2021-10-28 13:27:28李紅麗
網絡安全技術與應用 2021年9期
◆李紅麗
Hadoop與MapReduce應用下的大數據處理系統設計
◆李紅麗
(陽泉師范高等專科學校 山西 045200)
移動互聯網、云計算與物聯網等信息技術應用日益廣泛的大范圍增加了數據的產生量,使得整個社會正加速步入“大數據”時代。采取何種技術進行大數據處理系統的高效構建,對各種類型的數據源進行集成,讓用戶無障礙地訪問這些數據,進而完成對大數據價值的充分挖掘,成為業界與學者共同關注的問題。
Hadoop;MapReduce;ETL;大數據處理系統
近年來,諸多大數據處理技術與框架吸引了人們的高度關注,其中,以Hadoop開源計算平臺得到的關注與應用最廣。它是一種具有分布式特點的系統架構,基于自身所表現出來的數據提取、轉換與清洗以及加載(ETL)強大優勢而在大數據處理中發揮重要作用。本文進行一種以Hadoop和MapReduce為基礎的大數據處理系統的構建,該系統可以整合數據處理的全部流程,涉及從分布異構數據源處進行各種相關數據的收集、對信息進行清洗以將冗余或是無用信息剔除、重構有用的各項數據、對數據進行向數據倉庫等的加載等一系列任務,以期為今后大數據處理工作更加順利與有效的開展提供一種可供參考的計算架構。
1 Hadoop平臺與MapReduce技術
分析Hadoop平臺的總體構成,主要對HDFS、MapReduce以及Hive等重要組件予以涉及。
1.1 HDFS
這是一種分布式文件系統,在一個集群網絡中,通常會有很多臺計算機,而每臺計算機內又會存儲大量不同的數據,借助該系統,可以完成對這些數據的管理任務。HDFS可在普通商用服務器節點上部署,容錯性能強,可靠性高。為了在極短的時間內實現對數據的快速訪問,HDFS對流式數據訪問的設計理念及其思路予以遵循,對大數據的處理執行的為一次寫入與多次讀取模式。
1.2 MapReduce
這是一種數據模型(主要框架如圖1所示),具有對數據進行并行化處理的功能,在多個計算節點上,該數據模型可以執行對大規模計算分析任務的分配操作,能夠在較大的程度上為統計分析任務效率的提升提供可靠保證。在完成數據輸入之后,系統會對所輸入的各項數據執行分片處理操作,對于各輸入分片,它們都會進行一個Map任務的單獨啟動,并在此基礎之上生成并得到一些鍵值對,并在本地硬盤中執行對這些鍵值對的存儲任務。Map處理之后所得結果,會在網絡傳輸的支持作用下由對Reduce任務予以運行的相應節點接收,在此過程中,Reduce函數的功能在于對它們進行合并處理,并以此操作為基礎將得到的最終處理結果在HDFS中存儲下來。

圖1 MapReduce計算模型
1.3 Hive
構建于Hadoop上的數據倉庫框架,可將HiveQL查詢有效地轉換為MapReduce任務,減小HiveQL程序向Hadoop平臺移植難度。
2 系統設計
系統主要包括4個層次,圖1所示為本文設計的系統整體框架。
(1)數據采集層。主要利用各類采集設備,在設備接口的支持下獲取各種類型的數據,在這些數據中,包括結構化、半結構化以及非結構化多種類型的數據,同時,還有可能涉及錯誤、冗余或者是用處不大的數據,因此需要先對這些數據執行數據的清洗任務,為干凈可用數據的獲取提供便利,同時,保障數據安全存取。
(2)數據存取與計算層。涉及大數據倉庫、Hadoop平臺與ETL計算框架。數據倉庫與Hadoop之間具有互補的關系,前者中的數據能夠在后者中轉存,這可實現對用戶在多種不同場景下業務需求的有效滿足。ETL計算框架同Hadoop結合可以執行對數據的一系列處理,為后期的數據查詢、分析以及挖掘提供強有力的平臺支持。
(3)數據服務層。以ETL計算框架與Hadoop平臺為基礎,提供對數據的管理、分析以及挖掘服務。為了達到數據的共享目的,該層同時提供統一接口,供平臺及其他相關應用使用。
(4)數據應用層。基于數據服務層接口的支持,執行預警預測、知識發現以及決策支持等多種大數據應用。
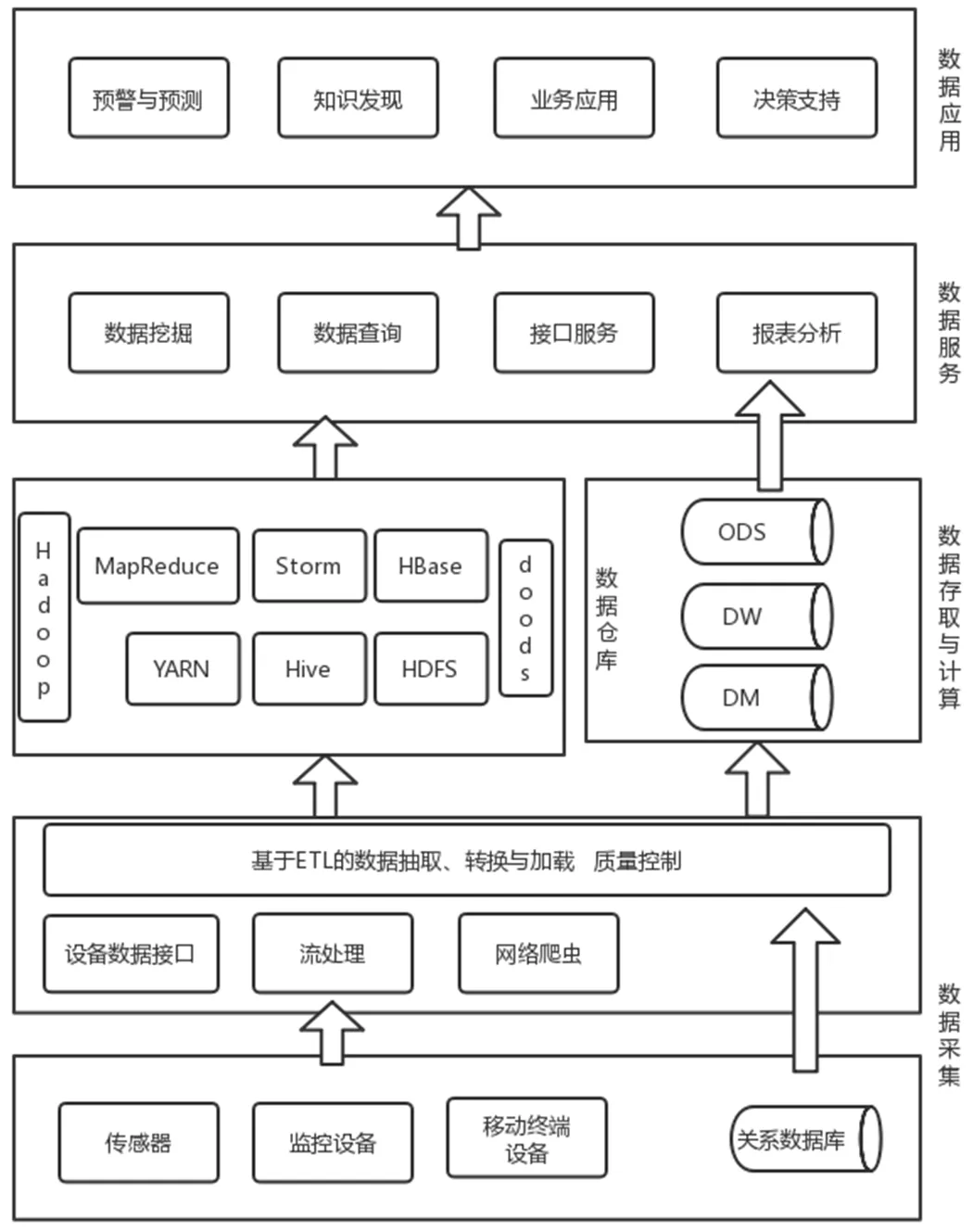
圖1 大數據處理系統總體架構
3 系統分布式ETL框架(圖2)
第一,考慮到Hadoop HDFS可以分布式存取文件,對其這一功能加以應用,從邏輯層面上整合之前那些物理上相互隔離的各類數據;第二,遵循事先制定好的業務規則,在Hive組件的支持下,執行對HiveQl腳本的編寫任務,同時,有效地發揮Hadoop MapReduce所具有的對數據進行處理的強大功能,進一步執行對HDFS中相關數據的轉換與處理操作,最終獲取所需要的Hive數據表;第三,為了盡可能地將時間的消耗降到最低程度,發揮Sqoop工具的作用,對Hive表進行批量加載,并將其存儲至關系型數據庫中。
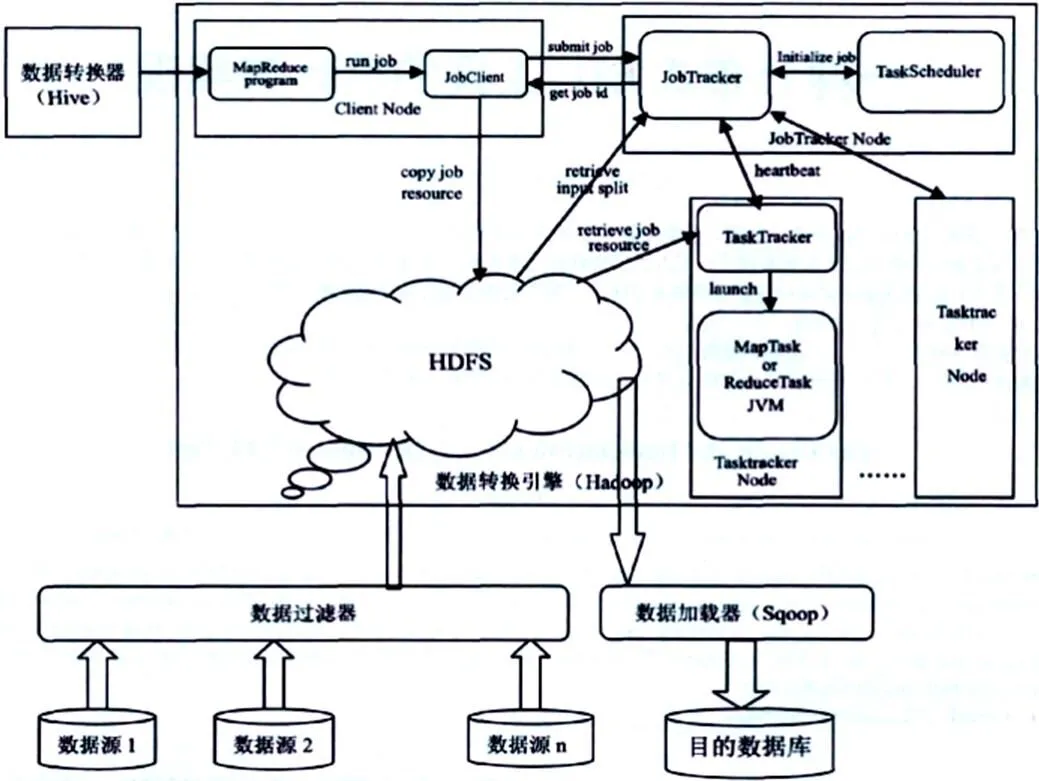
圖2 分布式ETL框架圖
在數據抽取模塊中,又可以進一步分為兩個子模塊,分別為數據源與數據過濾器。而在這兩個子模塊中,后者的功能在于執行對數據的初步清洗與過濾任務。
數據轉換模塊主要由數據轉換器(Hive)與數據轉換引擎(Hadoop)2個子模塊共同構成,其中,前者的功能表現為對轉換規則進行制定,并執行對規則的輸入任務;后者主要運行具體轉換規則并得到最終的結果,是整個ETL部件的核心,內部工作流程在圖2中已給出。
在關系型數據庫中,數據加載模塊存在的意義表現為可執行對最終結果表的批量加載任務,而該項操作會進一步在Sqoop的支持下來完成。
4 基于MapReduce計算模型的HDFS數據轉換實現
在對數據進行抽取、轉換以及執行對程序的加載任務等各個環節,ETL程序均會同Hadoop MapReduce庫建立起相應的鏈接關系,此過程會調用Map以及Reduce這兩個最為基本的函數,以此轉換HDFS數據,得到Hive數據表。圖3所示為其順序執行流程圖。
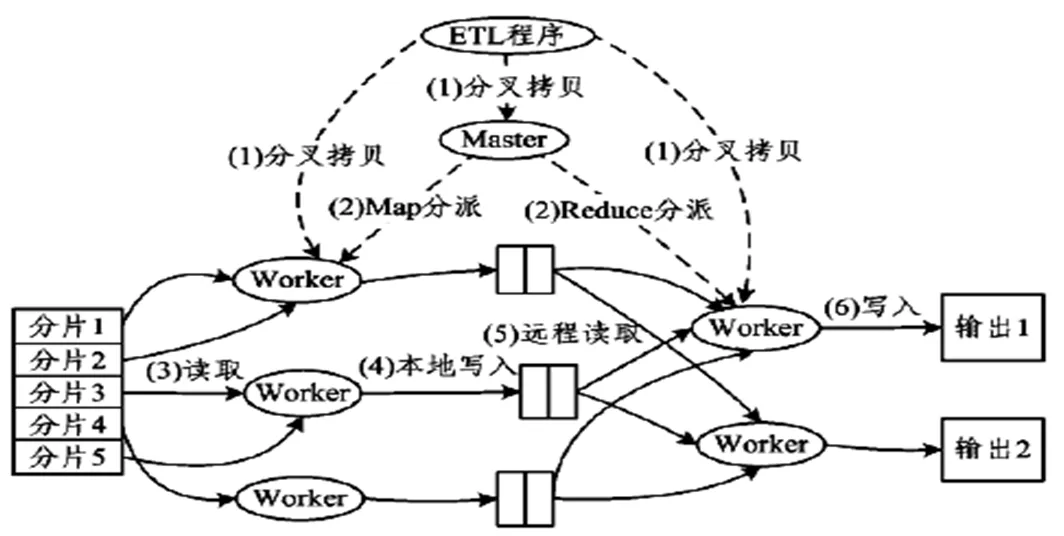
圖3 基于MapReduce的HDFS數據轉換流程圖
(1)MapReduce庫先對HDFS數據進行M份劃分(M由用戶定義),每1份為16~64M,之后利用分叉拷貝在集群內的其他機器上進行用戶進程的拷貝。
(2)在ETL程序副本分配的機器中,有一個是Master,負責調度,其他的都是Worker,數量亦由用戶制定。Master為空閑的Worker分配Map作業或Reduce作業。
(3)對于Worker而言,如果其被分配的是Map作業,則需執行對所對應的分片中輸入數據的讀取任務,Map作業數量并不是固定的,M會對其產生決定性影響,也就是說,Map作業同分片之間存在著一一對應的關系;在所輸入的所有數據中,Map作業會執行相應的鍵值對抽取操作,在此基礎上,會通過參數的形式將所抽取到的鍵值對傳遞給Map函數,而接下來,Map函數會基于接收到的鍵值對而產生對應的中間鍵值對,這些中間鍵值對會在內存中被緩存下來。
(4)當有一定數量的中間鍵值對被緩存下來之后,它們會被寫入到本地磁盤之中,而磁盤又會進一步將它們劃分為R個區,用戶自行定義R的大小,后期,每個區均會與一個Reduce作業相對應;另外,寫入本地磁盤的中間鍵值對位置會經由Master向Reduce Worker轉發。
(5)Mater會對Worker被分配到的作業性質進行判斷,如果是Reduce作業,這時,Worker會向Worker下達相應的通知,讓其知曉自身所負責的具體區域所處的位置,當Reduce Worker完成自身的初步任務,亦即將由自己負責的所有中間鍵值對讀取完畢以后,會進一步地對它們進行排序處理,將有著相同鍵的鍵值對集聚起來。
(6)Reduce Worker遍歷按順序排列之后的中間鍵值對,針對每一個唯一的鍵,均向Reduce函數執行鍵及其關聯值的傳遞任務,在此過程中,Reduce函數會有相應的輸出產生,而這些輸出會添加到該分區的輸出文件中。
(7)當全部的Map作業以及Reduce作業均被完成之后,Master會進一步執行對ETL程序的喚醒操作,在此過程中,MapReduce函數又會調用向ETL程序返回的相關代碼。
基于上述所有操作的完成,MapReduce輸出會放于R個分區的輸出文件中,用戶可將它們作為輸入交由另一個MapReduce程序,最終得到Hive數據表。
5 應用測試與性能比較
系統設計完成之后,需要對其可應用性進行測試,以確定系統是否具有價值,對此,本文圍繞系統的具體應用及其在應用過程中表現出來的相關性能展開具體的測試工作。
5.1 應用測試
在測試過程中,將加速比(單機完成某一應用所耗費的時間同多機并行完成某一應用所耗費的時間的比值)作為指標分析系統可應用性,也就是測試系統在對各種數據進行處理的過程中表現出來的實際加速比,對此實際加速比同理想的加速比進行比較分析。具體地,將在實驗室中采集到的訓練數據作為實驗數據,根據測試結果進行加速比變化曲線的繪制,圖4(a)為隨數據變化的加速比變化曲線,(b)為隨計算節點變化的加速比變化曲線。
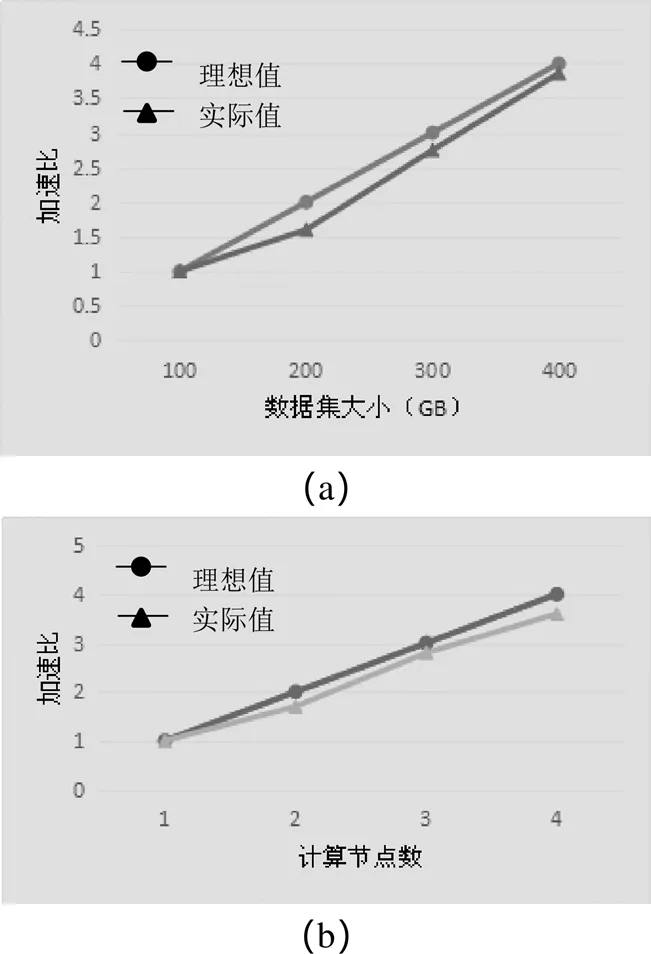
圖4 加速比變化曲線圖
根據圖4(a),在數據集不斷變大的過程中,加速比呈現出逐漸上升之勢,究其原因,在于系統設計最初時的目的在于對龐大而又復雜的數據進行處理,這一處理通常情況下都以一次性的處理為主。以Hadoop與MapReduce為基礎的大數據處理系統在運行過程中無須執行對數據的預處理操作,同時,也不必將它們寫入數據庫,系統直接在平面文件的基礎之上將相應的分析工作展開,最小化分析延遲,因此,數據集的增大可在一定程度上提高其處理效率。
根據圖4(b),在計算節點數量不斷增加的過程中,加速比的變化趨勢為先上升,后下降,其原因在于網絡通信過程中所需支付的費用會在計算節點數量不斷增加的過程中而逐漸增加,由于Hadoop MapReduce對以掃描為基礎的數據處理模式以及對中間結果不斷物化的執行策略予以采用,因此這會在較大程度上提高I/O代價,同時,增加網絡傳輸的任務量,在數據集并非特別大的前提條件下,節點數量的增加會對處理效率產生相應的影響。
5.2 基于不同平臺的系統性能比較(表1)
對于大數據處理系統,以往學者已經作了相應的研究,設計出基于SOA平臺的大數據處理系統以及基于多Agent的大數據系統等,為確定本文所設計的基于Hadoop MapReduce的大數據處理系統的優越性,本文從系統交互性、靈活性、擴展性、穩定性以及有效性5個方面對本文系統以及基于SOA平臺的系統和基于多Agent的系統進行對比分析,得到如表1所示對比分析結果。
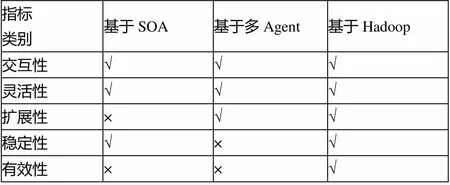
表1 三種平臺下的系統性能比較
注:“√”表明系統可滿足此項性能要求,“×”表示不可滿足。
根據表1,基于SOA方式的系統設計以對緊耦合問題的解決為目的,可提高ETL之間的交互性,但未較好地解決擴展性與有效性問題,故對于大數據來說,其效率相對不高;采用多Agent技術的系統以對Agent之間負載均衡問題的解決為目的,但無法確保各Agent之間的穩定性,當其中任意1個Agent出現故障之時,整個系統均會面臨癱瘓的風險,且無法有效地對大數據進行處理;Hadoop平臺對數據復制的方式予以采用,可提升節點之間訪問數據的效率,對數據丟失的可能性予以降低,因此基于Hadoop平臺的大數據處理系統具有很好的穩定性、擴展性與有效性,適用性很高。
6 結語
文章進行了一種基于Hadoop與MapReduce的大數據處理系統的設計,給出其框架設計方案,并對各模塊的功能進行了介紹,同時,針對其最為核心的部分,分析了基于MapReduce計算模型的HDFS數據轉換實現。系統可對分布于不同主機上的數據執行簡單且高效的數據抽取、轉換與加載操作,實驗顯示,系統可靠性、可擴展性、負載平衡性能良好,執行效率高,且在對海量數據的處理中表現出了優于采用SOA方式與采用多Agent方式的系統性能。
[1]楊杉,蘇飛,程新洲,等.面向運營商大數據的分布式ETL研究與設計[J].郵電設計技術,2016(8):47-52.
[2]崔蔚,周力,吳凱峰,等.基于Hadoop平臺的并行線損分析系統研究與實現[J].電力信息與通信技術,2014,12(2):60-63.
[3]王艷,蔣義然,劉永立.基于Hadoop的大數據處理技術及發展[J].信息記錄材料,2020,21(11):146-147.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
藝術啟蒙(2018年7期)2018-08-23 09:14:18
家庭影院技術(2017年9期)2017-09-26 03:41:45
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
故事大王(2016年7期)2016-09-22 17:30:08
兒童故事畫報(2013年3期)2013-06-24 05:40:30
