基于STM32的智能備忘錄研究
2021-10-29 08:28:26單成桐唐淵歐陽洪波郭慶堃鄒博勝劉文濤吳瓊發
電子制作 2021年18期
關鍵詞:智能
單成桐,唐淵,歐陽洪波,郭慶堃,鄒博勝,劉文濤,吳瓊發
(湖南工業大學電氣與信息工程學院,湖南株洲,412000)
1 總體方案設計
智能備忘錄以STM32 為核心,對其他各模塊進行控制,手機傳輸語音到服務器,服務器提供語音解析和關鍵字存貯。最后實現智能備忘錄在脫離手機的情況下,能夠給使用者進行事項提醒的功能。
該系統由STM32、藍牙傳輸模塊、震動馬達、顯示模塊、雙麥克風陣列模塊和LED 模塊構成。用戶可對智能備忘錄進行語音輸入,在設備與手機通過藍牙連接后,將語音傳輸給手機,再由手機將語音上傳服務器解析,最后將解析結果通過手機與智能備忘錄進行交互,由STM32 對返回的參數進行判斷后,控制馬達、顯示器、功放對用戶進行提醒。
2 硬件電路設計及分析
硬件部分的連接組成如圖1 所示。
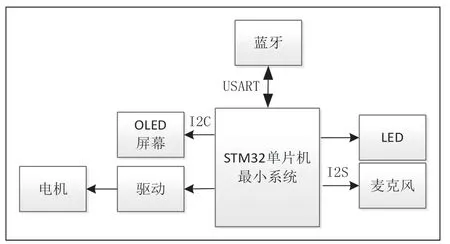
圖1 單片機控制系統
■2.1 模塊的選型
2.1.1 麥克風陣列模塊
語音采集模塊采用麥克風雙陣列。能更好地實現聲音的定位、錄入,以及智能喚醒功。麥克風單元在小空間中進行有規則的排列即可形成麥克風陣列,在噪聲環境下有良好的信號采集性,具有對遠場干擾噪聲很強的抑制作用,因此把它應用于強噪聲環境。
2.1.2 BL04 藍牙傳輸模塊
藍牙雙模包含經典藍牙和低功耗藍牙兩個部分。經典藍牙與低功耗藍牙的結合即可實現快速連接與斷開連接、音頻的傳輸、高鏈接范圍,并且所有連接使用高級低耗電監聽模式,從而實現超低工作周期、低功耗、高穩定性、智能化的控制、強大的網絡安全。
2.1.3 其他常見模塊
考慮到載體的集成度,單片機采用STM32F4 系列,主要實現輸入信息數據的分析和處理,并輸出相應的指令,實現多模塊指令協調與多模塊控制。顯示模塊采用OLED 屏,通過I2C 協議與STM32 進行連接,實現關鍵字的顯示。震動馬達采用微型貼片震動馬達BRE-3728,LED 模塊采用貼片LED。
■2.2 硬件的部分原理
2.2.1 麥克風模塊
麥克風雙陣列算法應用于語音采集模塊。
麥克風陣列組合成的麥克風,擁有形成“波束”的強指向特性。經由特殊電路或程序算法軟件可以控制麥克風陣列的波束,使其指向聲源方向,獲得對采集目標的采集增強效果。處理后的指向性波束能精確形成一個錐狀窄波束,在接受說話人的聲音同時抑制環境中的噪音與干擾。
當我們把一對麥克風同步采集到的信號進行互相關聯,尋找互相關信號的最大值時,若兩信號之間延時為τ,將此值乘以聲波傳播速度C0 可以得到這對麥克風的相對位置間距,如公式1 所示。
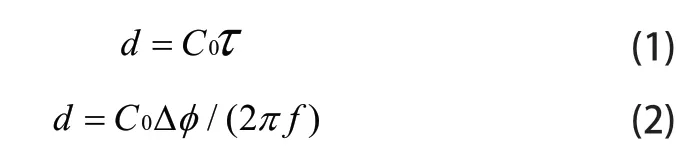
測量一對麥克風同步采集信號相位差ΔΦ,根據頻率和聲傳播速度可知一對麥克風的位置間隔,如公式2 所示。
公式中d 是陣列中兩個麥克風元件的間距。寬邊麥克風陣列是指一系列麥克風的排列方向與要拾取的聲波方向垂直。
經過計算及試驗驗證,相位法分析麥克風相對位置差的精度要比互相關法分析的精度高。
2.2.2 藍牙模塊
藍牙的核心協議由基帶,鏈路管理,邏輯鏈路控制與適應協議和服務搜索協議等4 部分組成。基帶層與射頻層一起構成藍牙的物理層,作為一個鏈接控制器,描述了基帶鏈路控制器的數字信號處理規范,并與鏈路管理器協同工作,負責執行像連接建立和功率控制等鏈路層。藍牙數據傳輸通過數據分組來防止數據丟失和傳輸擁堵。還通過白化和糾錯,來確保分組包數據正確傳輸。
2.2.3 其他硬件模塊
其他硬件模塊包括STM32 模塊、OLED 顯示模塊、微型貼片震動馬達BRE-3728、貼片LED。
STM32 作為核心控制器,通過USART 連接藍牙模塊,通過I2C 連接OLED 顯示模塊。STM32 通過高低電平控制馬達和貼片LED。
OLED 顯示模塊為自發光材料制作,為一種固態半導體設備。當來自陰極的電子沖擊發光層的聚芴聚合物時,聚合物發光,OLED 開始顯示。
震動馬達和貼片LED 作為提示模塊,當接通電源后,馬達震動,LED 常亮,起到提示作用。
3 系統軟件設計及流程
■3.1 軟件設計流程圖
軟件設計泳道圖如圖2 所示。
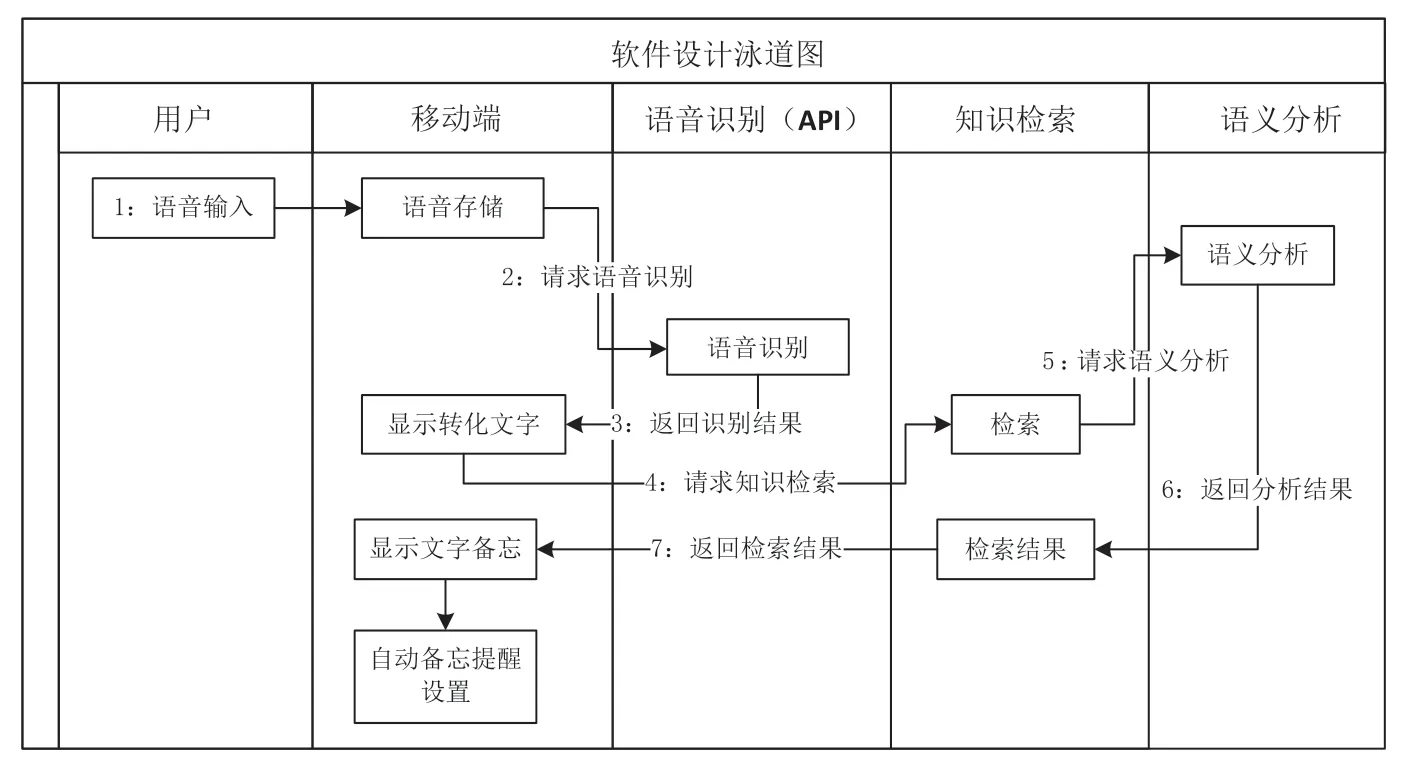
圖2 軟件設計泳道圖
3.2 語音識別
整體語音識別采用百度語音識別,通過在官網注冊成為百度開發者,創建應用,得到API Key 和 Secret Key,然后開通語音識別服務。中文分詞系統采用NLPIR 系統。中文分詞簡單理解就是使用空格或其它邊界標記把中文文本中的詞和詞之間分隔開。NLPIR 是中國科學院計算技術研究研制出的漢語詞法分析系統,該系統采用基于HMM的層疊隱馬爾可夫模型(cascaded hidden Markov model,CHMM)將中文分詞、詞性標注、歧義切分以及未登錄詞識別等功能集成到一個理論模型中。
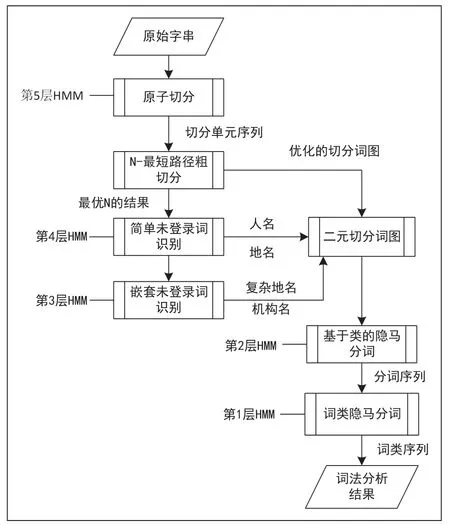
圖3 基于CHMM的漢語詞分框架
■3.3 關鍵詞提取與TextRank 算法
關鍵詞通過TextRank 算法提取。TextRank 算法基本思想來源于谷歌的PageRank 算法,其一般模型可以表示為一個有向有權圖G=(V,E),由點集合V 和邊集合E 組成,E 是V×V的子集。圖中任兩點Vi,Vj 之間邊的權重為Wji,對于一個給定的點Vi,In(Vi)為指向該點的點集合,Out(Vi)為點Vi 指向的點集合。點Vi的得分定義如下:
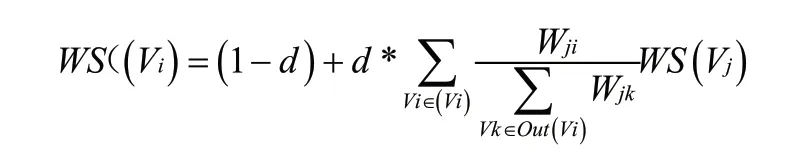
其中,d 為阻尼系數,d ∈[0,1],表示從圖中某一特定點都有 1-d的概率指向其他任意點。
簡單來說,TextRank 算法的取詞方式,就是將一段已知文本進行分割,再從中抽取若干有義詞語。然后根據共現關系對后續的詞語進行排序,從文本中進行抽取詞語,以其作為頂點,進行一個隨機游走。最后根據詞語的投票得分高低,篩選出應得到的關鍵詞。其步驟如下:
通過接口獲取的錄音集合文本T,分割成完整的句子,即:
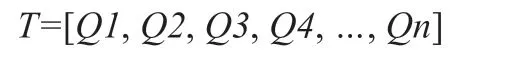
對于每個句子Qi ∈T,先對文本進行分詞、確定詞性,剩下指定詞性的單詞作為關鍵詞的候選詞,即:
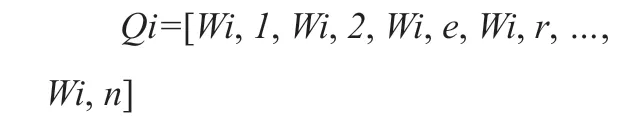
其中Wi,j ∈Qj 則是保留后的候選關鍵詞,構建候選關鍵詞圖G=(V,E),其中V 為節點集,生成的候選關鍵詞組成,由共現關系構造任兩點之間的邊,兩個節點之間存在邊僅當它們對應的詞匯在長度為K的窗口中共現,直至收斂。倒序排序各節點權重,得到最重要的T個單詞便是關鍵詞提取的結果。
根據詞庫已識別的關鍵詞,再通過自定義,即可實現自定義詞庫的關鍵詞提取,篩選出相關度最高的樣本。其算法概念和步驟已在上文進行了闡述。
最終在app 中只顯示關鍵字作為備忘錄。
■3.4 APP 端設計與開發
APP的集成開發環境為Android Studio3.0,數據庫采用SQLite 數據庫,使用Java 語言和C 語言進行編碼。備忘錄采用模塊化設計,由新建備忘界面、查看備忘界面、單獨備忘界面等界面構成,其中查看界面由ListView 視圖構建,其主要功能有新建、查看、修改、刪除、個性化設置等功能。
APP 端功能簡介如圖4 所示。
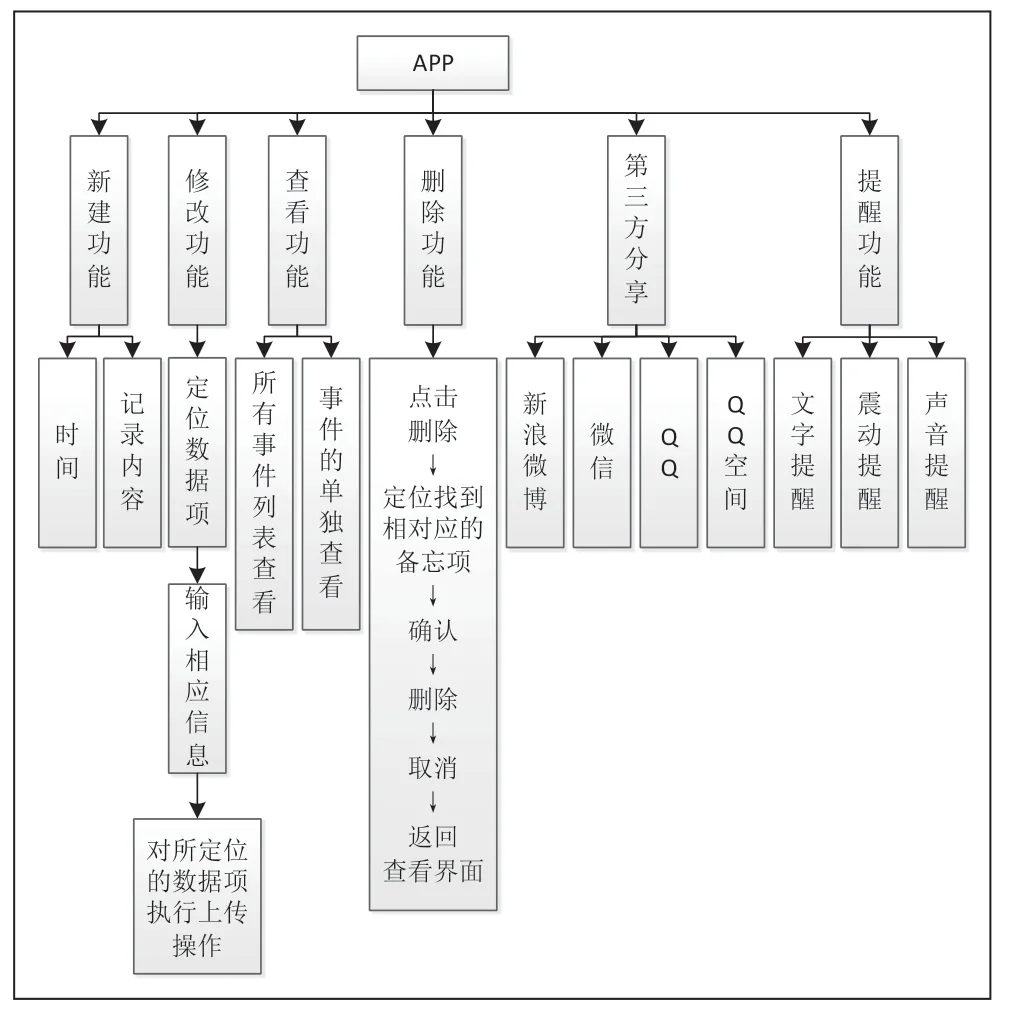
圖4 app 端功能簡介

圖5 各模塊的連接原理圖
4 系統整體連接與調試
智能備忘錄可獲取用戶的語音輸入,當連接到Android時,在Android 端存儲為本地文件。由Android 向服務器發送語音識別請求。服務器對語義、關鍵字等解析完成后,獲得時間、地點、事件等關鍵字,傳回Android 端。Android端在自身APP 顯示的同時,可通過藍牙更改智能備忘錄中的參數,以此設定智能備忘錄的提醒時間以及關鍵字顯示。
至此,用戶可在智能備忘錄單機工作的情況下,在設定時間獲得提醒,得到提取到的關鍵字信息。

圖6 硬件運行測試結果
5 硬件運行測試結果和軟件運行測試結果
硬件部分,STM32 在通過藍牙與Android 連接后,獲得時間、地點、日期、關鍵字等重要數據,通過貼片LED 亮燈提示,震動馬達震動提示,并且在OLED 屏上顯示獲取的關鍵字。
軟件部分,智能備忘錄與Android 建立藍牙連接后,語音輸入可獲得文本形式的輸入內容,并且自動提取關鍵字添加到行程安排,可新建、刪改、可查看、可第三方分享。
6 結論
本文對智能化語音識別系統進行研究,基于語音識別、提取技術,通過NLPIR 系統、TextRank 算法,由STM32 系列單片機、藍牙模組、麥克風陣列等設備,提取關鍵字進行智能化的語音轉文本處理;基于已普及的移動端Android系統,通過硬件設備、APP、應用服務器的結合設計出可以語音識別的智能備忘錄。在對象輸入語音時,可判斷對象語義并自動添加行程安排或備忘錄,設備可以單機工作,在不方便攜帶手機的時候,獲得提醒,不會錯過重要行程。
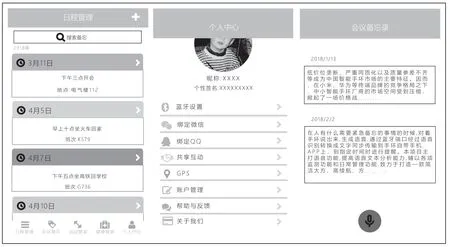
圖7 軟件運行測試結果
猜你喜歡
開放教育研究(2021年3期)2021-05-25 02:41:06
小學科學(學生版)(2020年12期)2021-01-08 09:28:04
裝備制造技術(2020年4期)2020-12-25 05:26:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
能源(2018年4期)2018-05-19 01:53:44
