基于決策樹挖掘算法的水利信息化數據共享系統設計
2021-11-02 08:04:40梁志剛
水利科技與經濟 2021年10期
梁志剛
(張掖市龍渠三級水電有限責任公司,甘肅 張掖 734000)
0 引 言
水利是支撐當前社會發展的重要工程,不斷幫助人類適應、利用、改造和保護水環境,用來滿足發展需求[1]。隨著城市化程度的提高,水利工程的需求不斷增加,對信息的實時性要求也在不斷提高,既可以避免工程重復投資,也可以在建設過程中查找相關工程資料,進一步降低工程建設成本。因此,水利數據共享已經成為工程建設的基本需求。
目前,國內外為應對“信息孤島”現象,采用云計算、Hadoop、XML等技術,設計數據共享系統,實現數據集成共享[2]。在此研究基礎上,文獻[3]在原有系統數據的基礎上,建立一個共享交換中心,調整數據交換的耦合性,實現數據共享,但該方法挖掘到的數據集數據質量差[3]。文獻[4]在原有共享系統基礎上,針對系統存在的數據安全問題,采用區塊鏈技術,形成私鏈與公鏈雙層結構,增強系統數據查詢的規范性和數據解析難度,實現數據安全共享,但該方法挖掘到的數據集數據質量差[4]。文獻[5]針對數據共享存在的共享數據整理時間長,共享數據查閱困難等問題,提出大數據管理技術,實現數據資源共享,但該方法挖掘到的數據集數據質量差[5]。針對這一問題,此次研究采用決策樹挖掘算法,深入挖掘水利信息化數據,保障水利共享數據的質量,提出基于決策樹挖掘算法的水利信息化數據共享系統硬件設計。
1 基于決策樹挖掘算法的水利信息化數據共享系統硬件設計
此次設計水利信息化數據共享系統,將在前人確定的硬件設備基礎上,考慮系統主要功能,設計系統運行網絡體系,保障水利信息化數據存儲安全,采用決策樹挖掘算法,深入挖掘水利信息化數據,構建的數據共享模型中,按照模型的數據共享傳輸協議與傳輸控制,實現水利信息化數據共享,完成水利信息化數據共享系統軟件設計。
1.1 設計系統網絡體系
數據共享系統共享數據時,與系統網絡運行速度具有直接聯系[6]。為此采用100/1 000 M的3COM型號交換機,作為系統網絡運行的核心交換機,所設計的網絡拓撲結構見圖1。
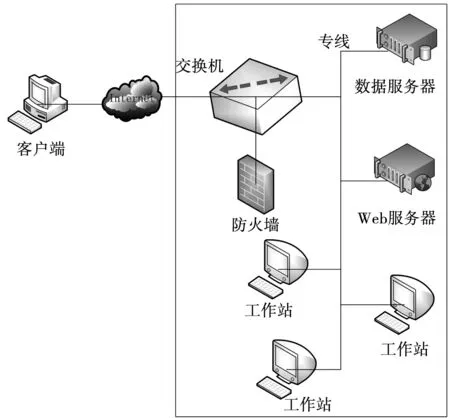
圖1 網絡拓撲結構
從圖1中可以看出,此次設計的水利信息化數據共享系統主要由數據庫和web服務器、工作站組成系統外網,分別用于存儲水利信息化數據、控制系統運行和數據共享控制。基于此,系統中心局域網包括客戶端部分,與3COM型號交換機相連接;連接局域網和外網時,在局域網和外網之間增添防火墻和磁盤陣列,保障系統數據運行安全。系統網絡體系的主干部分采用100 M雙絞線聯接,在保障系統數據安全運行的同時,將系統運行數據的吞吐率增加至100 Mbps,保障系統的運行速率。
1.2 基于決策樹挖掘算法挖掘水利信息化數據
在此次設計的系統網絡拓撲結構基礎上,采用決策樹挖掘算法,深入挖掘水利信息化數據,以此保障系統中共享的水利信息化數據質量。
假設,決策樹挖掘算法挖掘水利信息化數據集對為(O1,O2),根據數據集對(O1,O2)構建數據挖掘決策樹I,對水利信息化數據集O1和O2進行分類。此時,假設決策樹I對水利信息化數據集O1和O2分類的準確度A(I)為:
A(I)=min(AO1(I),AO2(I))
(1)
式中:AO1(I)和AO2(I)分別為決策樹I對數據集O1、O2的分類準確度[7]。
假設決策樹I計算節點總數為m;數據集Oi存儲在決策樹I計算節點j上的被錯誤分類的元組數為Ej,則決策樹I對數據集Oi(i=1,2)的分類準確度A(Oi)為:
(2)
式中:j為決策樹I計算節點;NOi為數據集Oi的元數據組總數。
此時,需要計算決策樹I分類挖掘數據的相似性,從而確定數據集的質量評價標準和分裂指標,以保證挖掘到的數據質量。為此,計算決策樹I在節點上挖掘數據集數據的類分布向量Vi(u),確定節點分布相似性D(u),從而得到數據分布相似性S(I),則有:
(3)
式中:M為集群中計算節點的數量;Vij(u)為在節點u上的計算節點i的非根節點j的類分布向量;‖·‖ 為向量模;uij為存儲在計算節點i的非根節點j;V1(u)和V2(u)分別為在節點u上的數據集O1、O2的類分布向量;n為決策樹I的非根節點數;α為數據平滑指數[8]。
綜合上述3個公式,得到的決策樹I質量評價標準Q(I)和分裂指標P(C,cu)計算公式如下:
Q(I)=min(A(I),S(I))avg(A(I),S(I))
P(C,cu)=wG·G(C,cu)+wD·D(C,cu)
(4)
式中:(C,cu)為屬性C中存在的一個可能分裂點cu;avg為求取(A(I),S(I))的平均數;G(C,cu)為信息增益;wG為G(C,cu)的權重;D(C,cu)為(C,cu)將節點劃分后的兩個子節點的節點分布相似性D(u)值的平均值;wD為D(C,cu)的權重。
綜合上述4個公式計算過程,采用決策樹按照數據集屬性,不斷循環分裂水利信息化數據集對,并不斷重新排列新分裂的數據,輸出最終挖掘到的水利信息化數據。
1.3 構建水利信息化數據共享模型
基于此次設計,采用決策樹挖掘算法挖掘到的水利信息化數據,采用NOSQL數據庫和云計算,構建水利信息化數據共享模型,增強系統對水利信息化數據處理能力,實現水利信息化數據共享。見圖2。
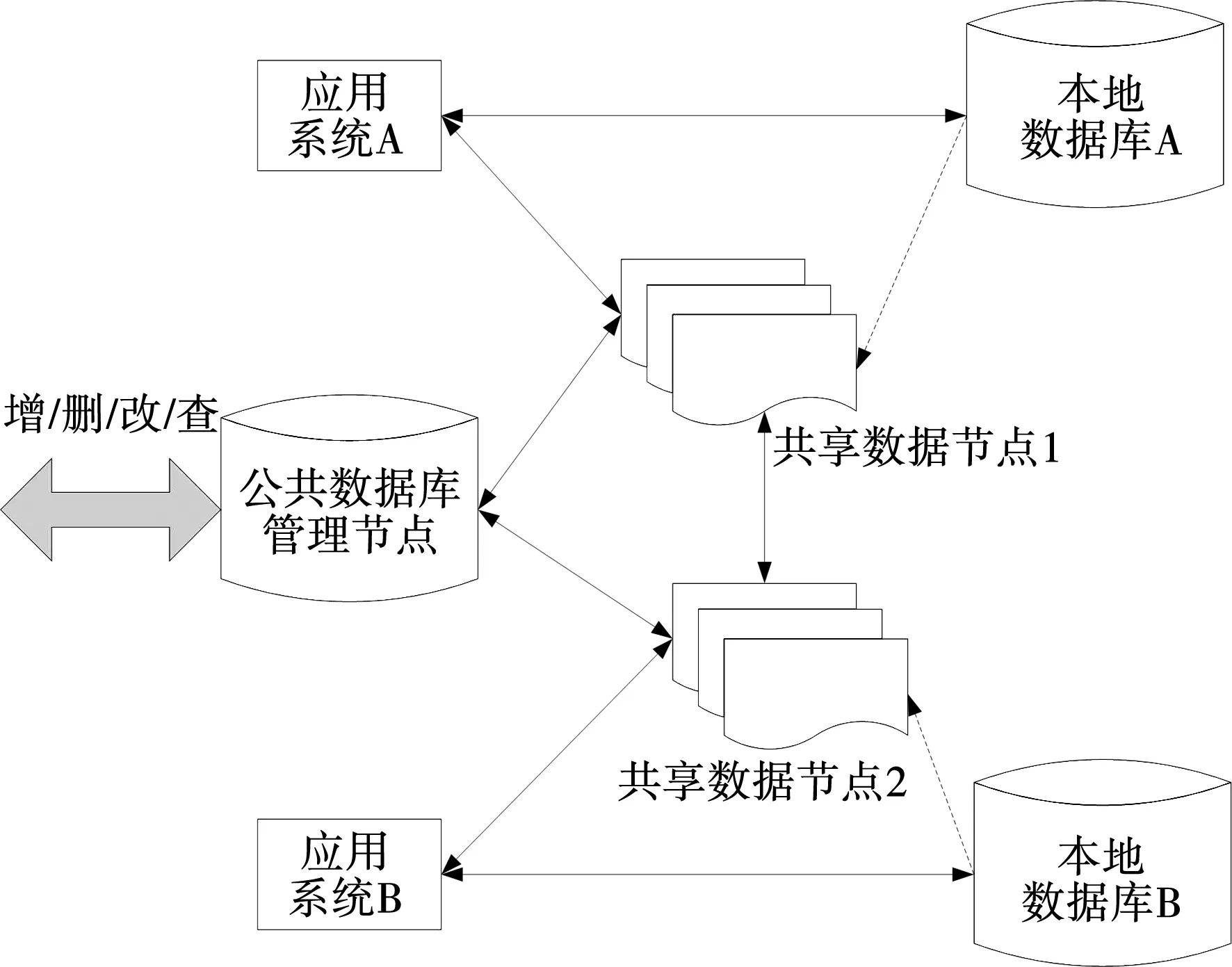
圖2 水利信息化數據共享模型
圖2中的箭頭方向表示數據的遷移方向。圖2所示的水利信息化數據共享模型,將NOSQL中的HBase型號數據庫作為系統共享數據庫,統一數據的存儲格式,并在本地數據庫的基礎上,實現多副本存儲數據,保障數據存儲的隱私性,從而充分發揮決策樹挖掘算法的優勢。
1.4 數據共享傳輸格式與傳輸控制
若要在此次構建的模型中實現水利信息化數據共享,需要在模型中設置共享數據傳輸格式,并控制數據共享傳輸過程、網絡體系產生的擁塞和差錯問題。
1.4.1 數據共享傳輸格式
此次設計的系統數據共享模型,將依據數據接收和傳輸兩方生成8位字符串,組成363字節的數據包,在MIT-BIH的數據共享傳輸格式下,單獨存儲水利信息化數據,最終形成數據共享傳輸格式。見圖3。
圖3中,將數據分為頭部、類型、編號、校驗和360字節數據5部分,其中0-7位數據編碼,360字節數據包含其他4部分。即0-7位數據編碼中,存在一個頭部字節、一個編號字節和一個校驗字節。除頭部字節外,剩下的6個字節會隨機生成8位字符串,生成360字節數據,正好是363字節的數據包,提出一個頭部字節、一個編號字節和一個校驗字節后的字節數據[9]。
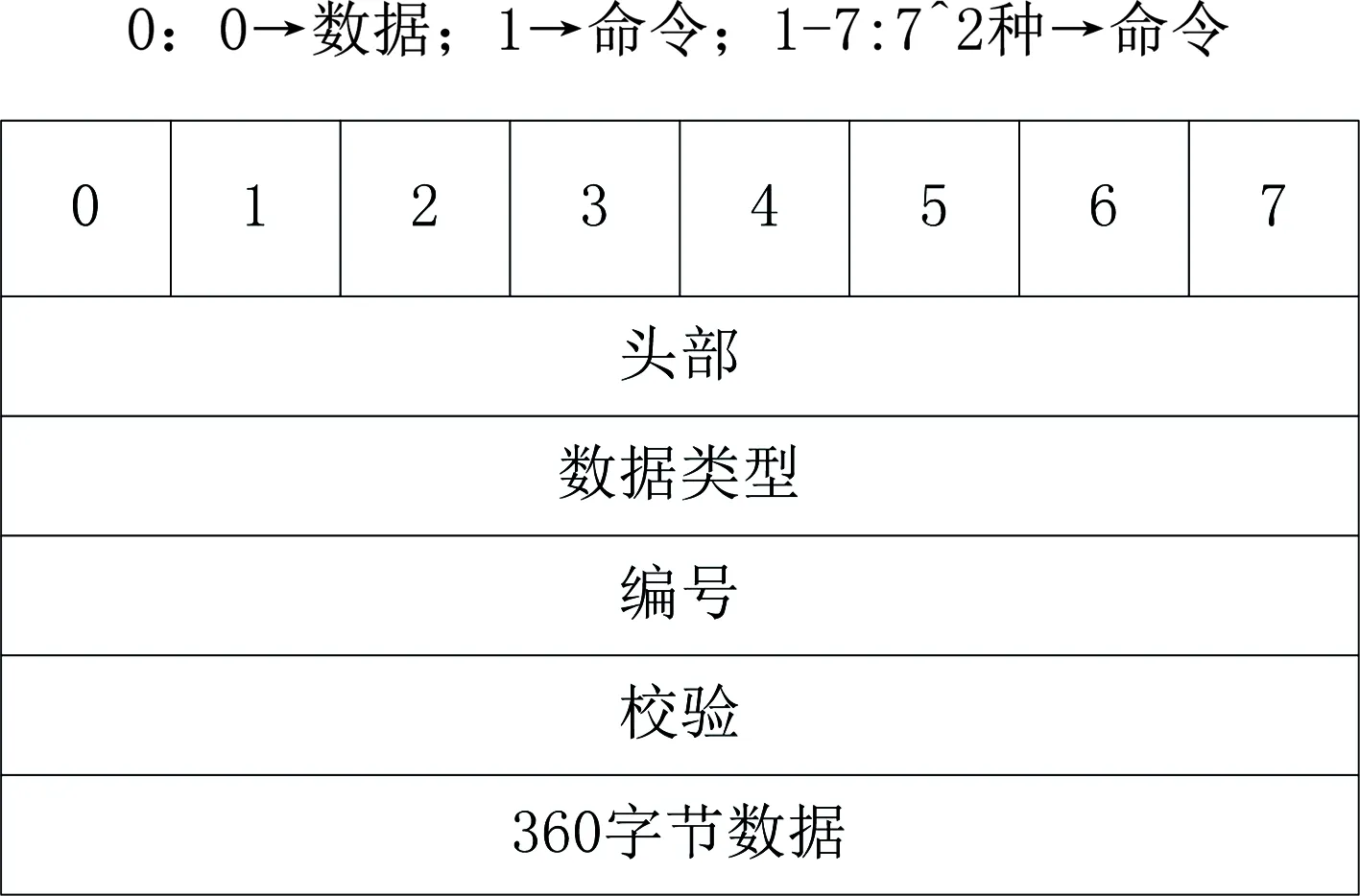
圖3 數據共享傳輸格式
1.4.2 數據傳輸控制
數據在傳輸過程中,主要存在擁塞和差錯兩種問題。針對這兩種問題,所設計的控制步驟如下:
1) 擁塞控制:①在數據傳輸方,設置“擁塞窗口”;②在數據傳輸方傳輸數據時,會自動發送一字節的試探包;查看網絡運行情況,判斷網絡是否存在擁塞問題;③數據接收方接收到一字節的數據試探包后,會再次發送兩字節的報文,按照2的指數級遞增,不斷重復步驟2,檢測網絡擁塞情況;④當試探結果滿足預設數據傳輸值,即停止試探,傳輸共享數據。
2) 差錯控制:①系統接收到數據待發送序號,根據需要要求,裝配共享數據,準備發送;②在發送數據的過程中,設置數據發送定時器;③等待計時器計時,并判斷計時器是否超時;④若計時器超時,則返回步驟3,重新設置計時器;⑤若計時器未曾超時,則進入步驟6;⑥判斷是否收到共享數據,此時需要獲取數據確認序號,其序號確定過程如下:a.期待接收需要;b.等待數據到達;c.針對數據進行校驗;d.數據校驗通過,直接使用數據,期待接收下一序號,確認數據接收序號;e. 數據校驗不通過,直接確認數據接收序號,并返回步驟b,為下一次需要確認做準備[10]。⑦確認序號正確,發送下一序號,并返回步驟1,準備控制下一次數據發送差錯。
2 系統測試
選擇兩組常規數據共享系統,采用對比測試的方式,以某區域的水利信息化數據,作為此次設計的系統測試實驗對象,驗證此次設計的水利信息化數據共享系統,比較3組數據共享系統挖掘算法的挖掘數據集數據質量、系統可擴展性和數據共享實時性。
2.1 實驗準備
此次設計的系統測試實驗,設計的系統軟硬件環境見圖4。
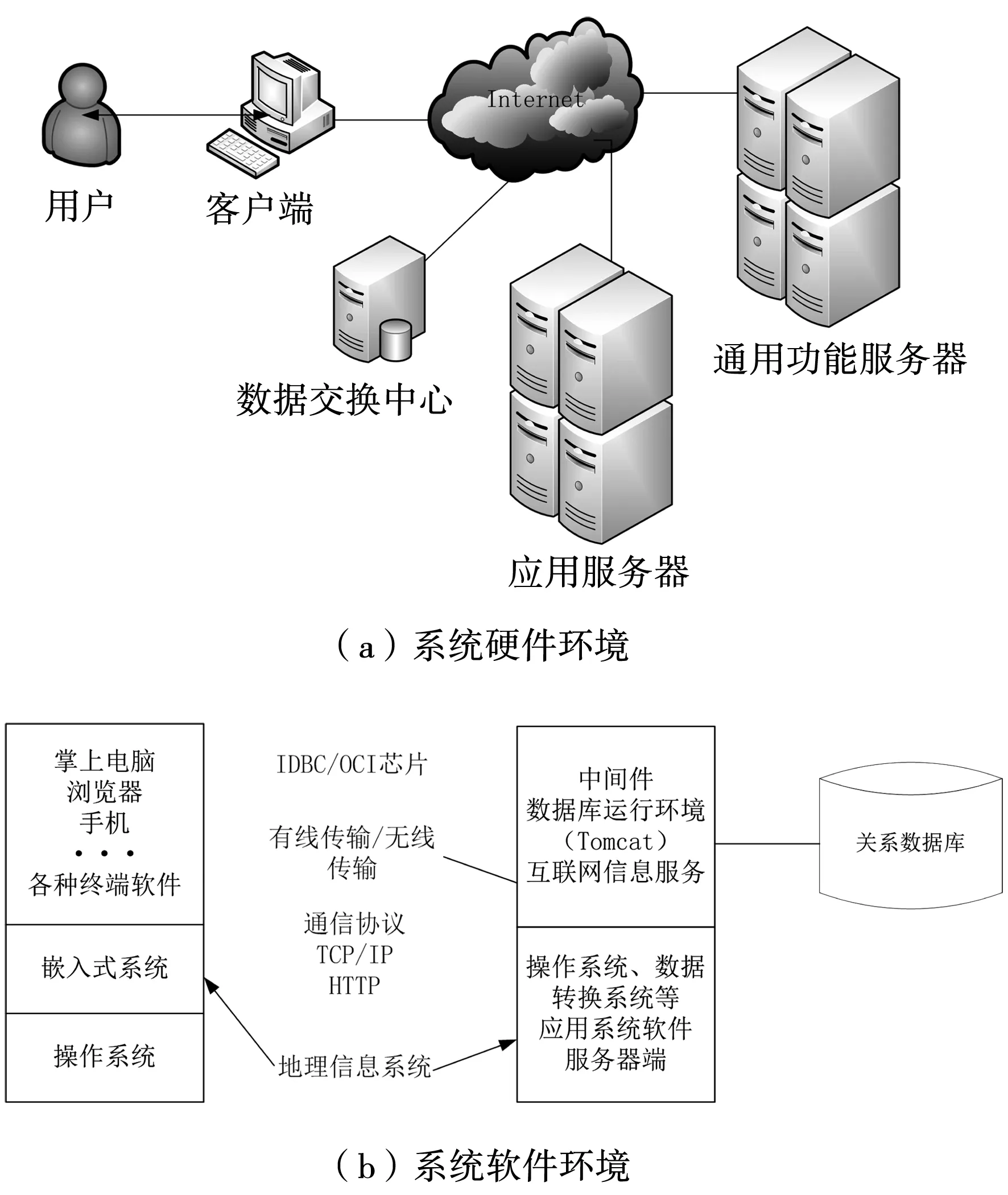
圖4 系統軟硬件環境
在圖4所示的系統運行環境下,使用1 000 M的自適應網絡傳輸數據,測試此次實驗選擇的3組系統。選擇某區域數據庫中存儲的水利信息化數據,總共被分為A、B、C、D、E共5個數據集,其基本信息見表1。
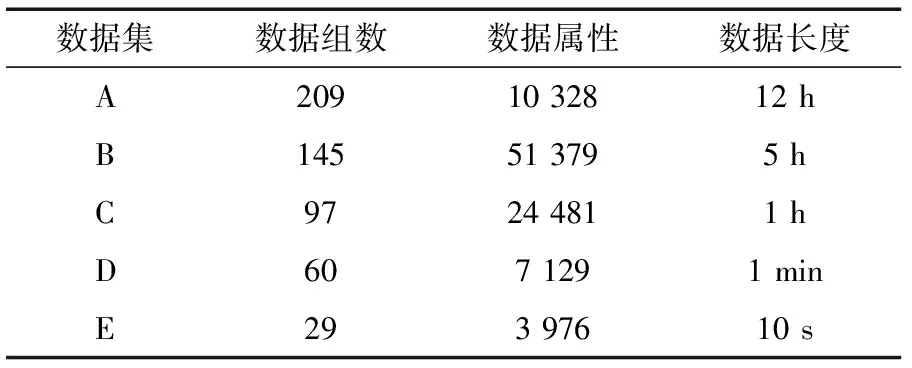
表1 數據集基本信息
2.2 實驗結果
2.2.1 第一組實驗結果
基于此次實驗選擇的5個數據集,在系統的系統共享數據庫與客戶端之間傳輸不同長度的水利信息化數據,并將數據傳輸結果與發送前的數據進行對比,采用數據傳輸正確率檢測3組共享系統所存儲的不同長度數據質量,其實驗結果見圖5。
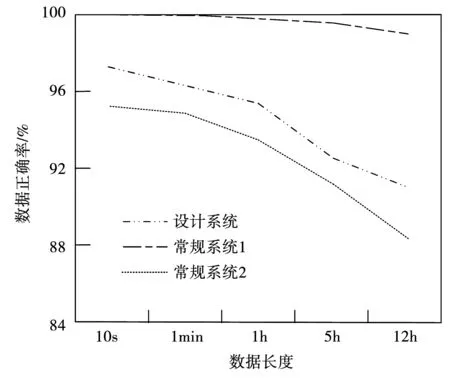
圖5 數據共享質量檢測
從圖5中可以看出,隨著數據長度的增加,數據傳輸正確率在不斷下降,表明共享數據質量也在下降。其中,常規系統2隨著數據長度的增加,數據正確率下降速度較快,其平均正確率為92.76%;常規系統1隨著數據長度的增加,數據正確率下降速度較常規系統2慢,其平均正確率為94.58%,同樣高于常規系統2;設計系統隨著數據長度的增加,數據正確率下降速度明顯較兩組常規系統慢,其平均正確率為98.88%,較兩組常規系統正確率分別高6.12%、4.3%。可見,此次設計系統具有較高的數據質量。
2.2.2 第二組實驗結果
在第一組實驗的基礎上,檢測數據共享的實時性,即系統在傳輸數據時所產生的延時時間。其實時性檢測流程如下:①在即將傳輸的水利信息數據集上,添加時間標記;②系統準備傳輸數據;③系統數據庫發送數據;④系統客戶端接收數據;⑤將接收到的數據重新上傳至系統數據庫;⑥計算數據在客戶端和數據庫之間傳輸時間差。其計算結果見表2。
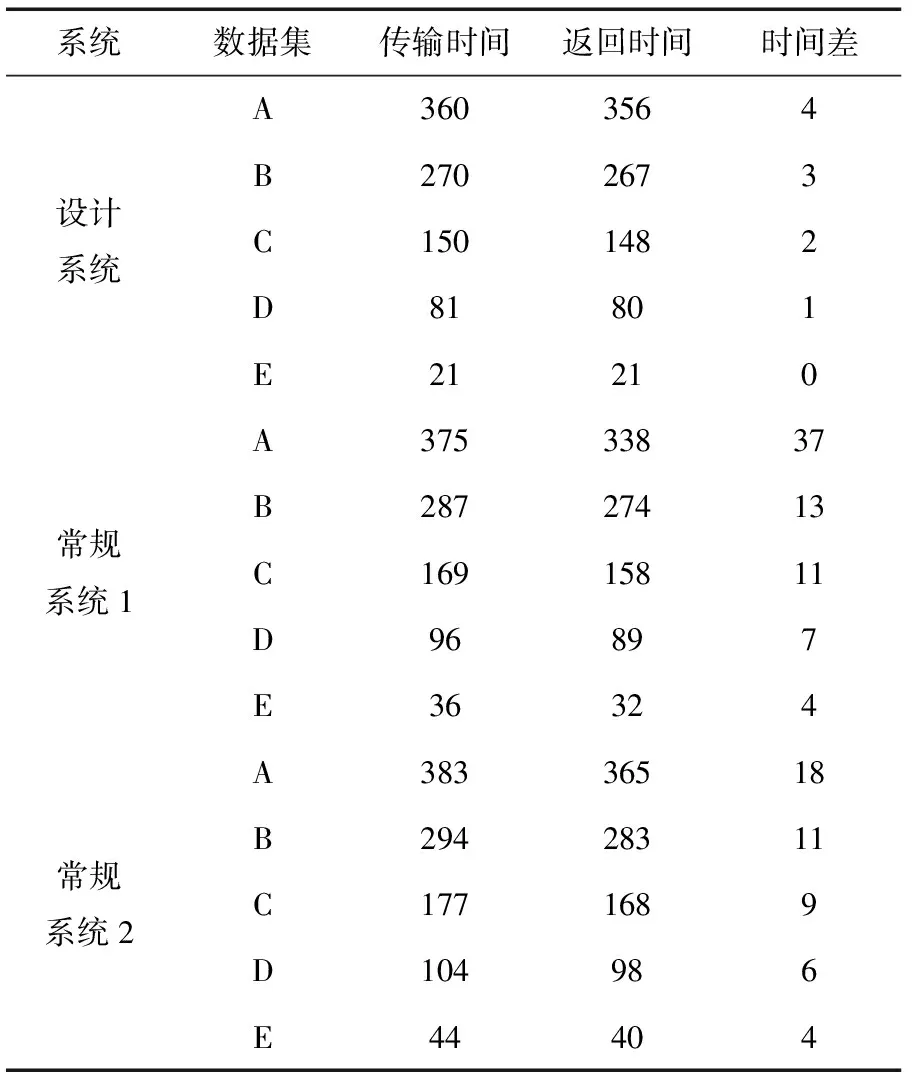
表2 數據共享實時性 /ms
從表2中可以看出,隨著數據集數據組數的增加,數據共享的延時時間增加,表明數據共享實時性降低。其中,常規系統1產生的時間差最大,設計系統產生的時間差最小。在5個數據集中,設計系統較常規系統2產生的時間差分別小14、8、7、5和4 ms,較常規系統1產生的時間差分別小33 、10、9、6和4 ms。可見,此次設計系統具有較優的數據共享實時性。
2.2.3 第三組實驗結果
在前兩組實驗的基礎上,測試3組系統對數據的可擴展性。在此次實驗選擇的數據集基礎上,增添F、G兩組水利信息化數據集,其數據組數目、屬性、長度如下:①F數據集:數目256,屬性15678,長度17 h;②G數據集:數目349,屬性20173,長度28 h。在7組數據集上,分別檢測3組系統算法挖掘數據集數據的運行時間,驗證3組系統的可擴展性。其實驗結果見圖6。
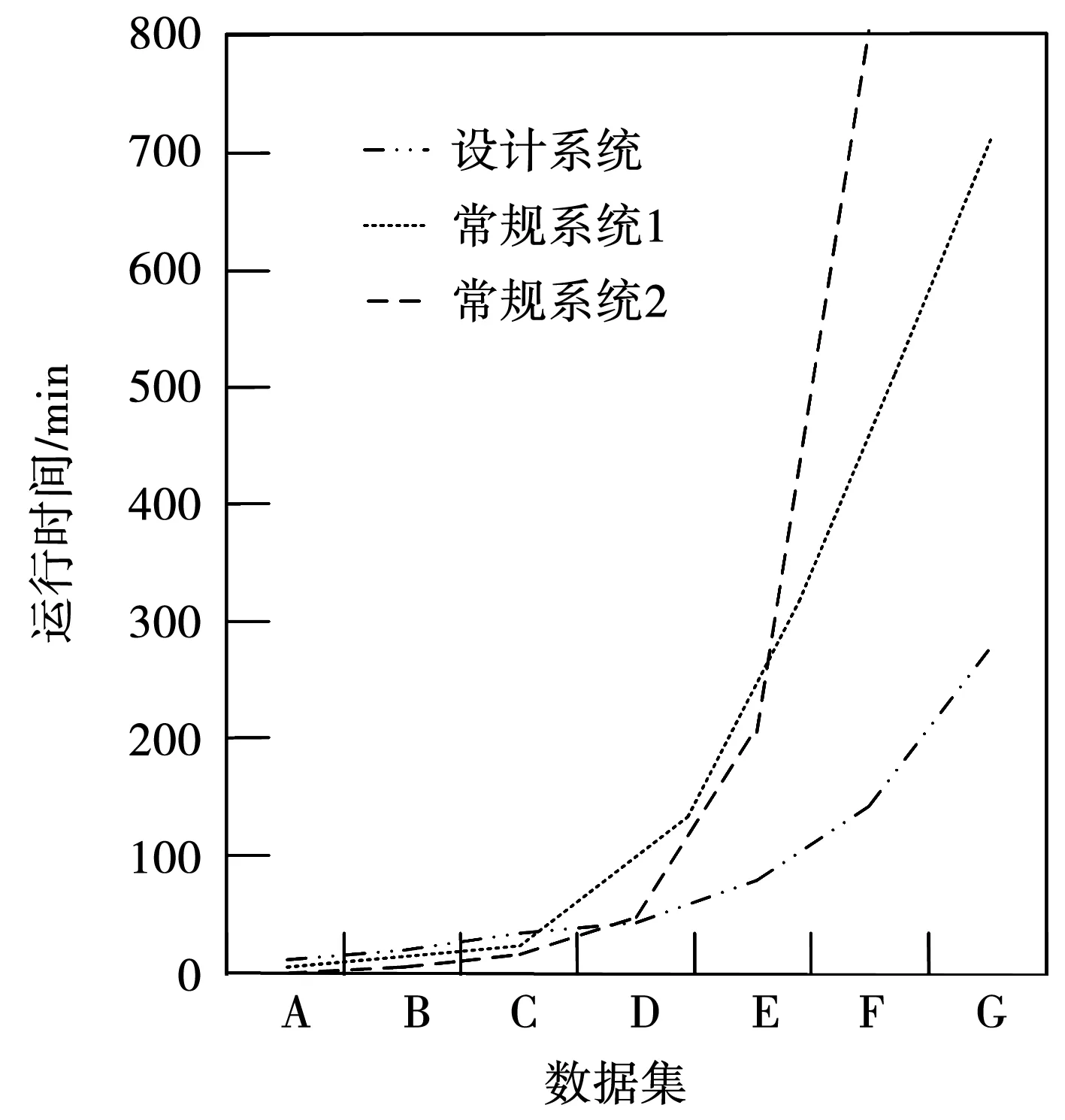
圖6 系統擴展性檢測
從圖6中可以看出,常規系統1的算法挖掘F數據集數據時,算法運行時間急劇上升,已經難以繼續運行,表明常規系統1僅能挖掘F數據集大小的數據;常規系統2的算法挖掘G數據集數據時,算法運行時間急劇上升,已經難以繼續運行,表明常規系統2僅能挖掘G數據集大小的數據;設計系統的算法挖掘7組數據集數據時,系統運行平穩,在E數據集處,較兩組常規系統所用運行時間分別小340、660 min。可見,此次設計系統具有較優的擴展性。
3 結 語
此次設計基于決策樹挖掘算法的水利信息化數據共享系統,充分考慮水利建設工程,對水利信息化數據共享系統需求,從系統的網絡運行體系出發,增強數據傳輸安全性。并且在系統中,引入決策樹挖掘算法,充分利用決策樹挖掘算法,挖掘水利信息化數據集數據,提高系統的擴展性、質量和實時性。但是,此次設計的水利信息化共享數據系統,在建模的模型材質、種類劃分等方面,還需進一步加強研究,需要結合水利工程建設,以及相關人員對水利信息的需求,構建數據共享模型的基礎框架,通過實際應用探索模型種類劃分原則,進一步完善系統中的數據共享模型。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中小學信息技術教育(2021年8期)2021-09-10 17:59:45
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
甘肅教育(2020年18期)2020-10-28 09:06:02
水利建設與管理(2020年6期)2020-07-08 08:37:34
水利建設與管理(2020年6期)2020-07-08 08:32:40
河南水利年鑒(2020年0期)2020-06-09 05:43:40
家庭影院技術(2017年9期)2017-09-26 03:41:45
中國衛生(2014年1期)2014-11-12 13:16:34
